- XML DOM 基础
- XML DOM - 首页
- XML DOM - 概述
- XML DOM - 模型
- XML DOM - 节点
- XML DOM - 节点树
- XML DOM - 方法
- XML DOM - 加载
- XML DOM - 遍历
- XML DOM - 导航
- XML DOM - 访问
- XML DOM 操作
- XML DOM - 获取节点
- XML DOM - 设置节点
- XML DOM - 创建节点
- XML DOM - 添加节点
- XML DOM - 替换节点
- XML DOM - 删除节点
- XML DOM - 克隆节点
- XML DOM 对象
- DOM - 节点对象
- DOM - 节点列表对象
- DOM - 命名节点映射对象
- DOM - DOMImplementation
- DOM - DocumentType 对象
- DOM - 处理指令
- DOM - 实体对象
- DOM - 实体引用对象
- DOM - 符号对象
- DOM - 元素对象
- DOM - 属性对象
- DOM - CDATASection 对象
- DOM - 注释对象
- DOM - XMLHttpRequest 对象
- DOM - DOMException 对象
- XML DOM 有用资源
- XML DOM 快速指南
- XML DOM - 有用资源
- XML DOM - 讨论
XML DOM 快速指南
XML DOM - 概述
Document Object Model (DOM) 是 W3C 标准。它定义了访问 HTML 和 XML 等文档的标准。
W3C 给出的 DOM 定义如下:W3C
文档对象模型 (DOM) 是 HTML 和 XML 文档的应用程序编程接口 (API)。它定义了文档的逻辑结构以及访问和操作文档的方式。
DOM 定义了访问所有 XML 元素的对象、属性和方法(接口)。它分为三个不同的部分/级别:
核心 DOM - 任何结构化文档的标准模型
XML DOM - XML 文档的标准模型
HTML DOM - HTML 文档的标准模型
XML DOM 是 XML 的标准对象模型。XML 文档具有称为节点的信息单元层次结构;DOM 是描述这些节点及其之间关系的标准编程接口。
XML DOM 还提供了一个 API,允许开发人员在树的任何位置添加、编辑、移动或删除节点,以创建应用程序。
以下是 DOM 结构图。该图显示了解析器通过遍历每个节点来将 XML 文档评估为 DOM 结构。
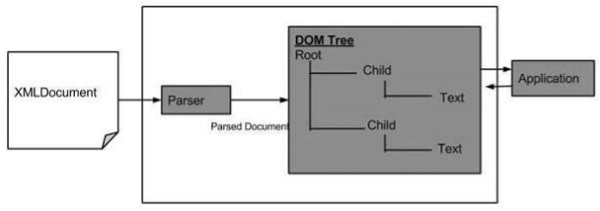
XML DOM 的优点
以下是 XML DOM 的优点。
XML DOM 与语言和平台无关。
XML DOM 是可遍历的 - XML DOM 中的信息以层次结构组织,允许开发人员在层次结构中导航以查找特定信息。
XML DOM 是可修改的 - 它具有动态特性,为开发人员提供在树的任何位置添加、编辑、移动或删除节点的范围。
XML DOM 的缺点
如果 XML 结构很大,它会消耗更多内存,因为编写的程序会一直驻留在内存中,除非显式删除。
由于大量使用内存,与 SAX 相比,其运行速度较慢。
XML DOM - 模型
现在我们知道了 DOM 的含义,让我们看看 DOM 结构是什么。DOM 文档是节点或信息的集合,以层次结构组织。某些类型的节点可能具有各种类型的子节点,而其他节点是叶节点,在文档结构中其下不能有任何内容。以下是节点类型的列表,以及它们可能作为子节点具有的节点类型列表:
文档 - 元素(最多一个)、处理指令、注释、文档类型(最多一个)
文档片段 - 元素、处理指令、注释、文本、CDATASection、实体引用
实体引用 - 元素、处理指令、注释、文本、CDATASection、实体引用
元素 - 元素、文本、注释、处理指令、CDATASection、实体引用
属性 - 文本、实体引用
处理指令 - 没有子节点
注释 - 没有子节点
文本 - 没有子节点
CDATASection - 没有子节点
实体 - 元素、处理指令、注释、文本、CDATASection、实体引用
符号 - 没有子节点
示例
考虑以下 XML 文档node.xml的 DOM 表示。
<?xml version = "1.0"?>
<Company>
<Employee category = "technical">
<FirstName>Tanmay</FirstName>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
</Employee>
<Employee category = "non-technical">
<FirstName>Taniya</FirstName>
<LastName>Mishra</LastName>
<ContactNo>1234667898</ContactNo>
</Employee>
</Company>
上述 XML 文档的文档对象模型如下:
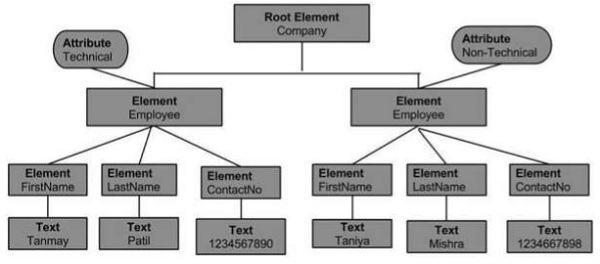
从上面的流程图中,我们可以推断:
节点对象只能有一个父节点对象。它位于所有节点之上。这里它是Company。
父节点可以有多个节点,称为子节点。这些子节点可以有附加的节点,称为属性节点。在上面的示例中,我们有两个属性节点Technical和Non-technical。属性节点实际上并不是元素节点的子节点,但仍然与之关联。
这些子节点又可以有多个子节点。节点内的文本称为文本节点。
同一级别的节点对象称为兄弟节点。
DOM 识别:
表示接口并操作文档的对象。
对象和接口之间的关系。
XML DOM - 节点
在本节中,我们将学习 XML DOM 节点。每个 XML DOM 都以称为节点的层次单元维护信息,而 DOM 描述这些节点及其之间的关系。
节点类型
下图显示了所有节点类型:
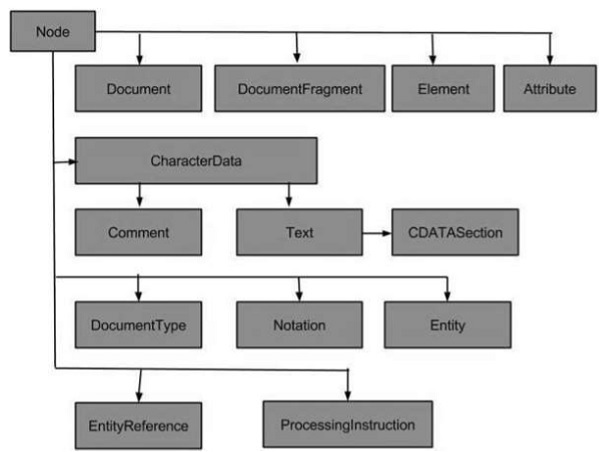
XML 中最常见的节点类型是:
文档节点 - 完整的 XML 文档结构是一个文档节点。
元素节点 - 每个 XML 元素都是一个元素节点。这也是唯一可以具有属性的节点类型。
属性节点 - 每个属性都被认为是一个属性节点。它包含有关元素节点的信息,但实际上并不被认为是元素的子节点。
文本节点 - 文档文本被认为是文本节点。它可以包含更多信息或只是空格。
一些不太常见的节点类型是:
CDATA 节点 - 此节点包含解析器不应分析的信息。相反,它应该只作为纯文本传递。
注释节点 - 此节点包含有关数据的信息,通常会被应用程序忽略。
处理指令节点 - 此节点包含专门针对应用程序的信息。
文档片段节点
实体节点
实体引用节点
符号节点
XML DOM - 节点树
在本节中,我们将学习 XML DOM 节点树。在 XML 文档中,信息以层次结构维护;此层次结构称为节点树。此层次结构允许开发人员在树中导航以查找特定信息,因此允许访问节点。然后可以更新这些节点的内容。
节点树的结构从根元素开始,一直扩展到子元素,直到最低级别。
示例
以下示例演示了一个简单的 XML 文档,其节点树结构如下所示:
<?xml version = "1.0"?>
<Company>
<Employee category = "Technical">
<FirstName>Tanmay</FirstName>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
</Employee>
<Employee category = "Non-Technical">
<FirstName>Taniya</FirstName>
<LastName>Mishra</LastName>
<ContactNo>1234667898</ContactNo>
</Employee>
</Company>
如上例所示,其图示表示(其 DOM)如下:
树的最顶层节点称为根。根节点是 <Company>,它又包含 <Employee> 的两个节点。这些节点称为子节点。
根节点 <Company> 的子节点 <Employee> 又包含它自己的子节点(<FirstName>、<LastName>、<ContactNo>)。
根节点 <Company> 的两个子节点 <Employee> 具有属性值 Technical 和 Non-Technical,称为属性节点。
每个节点内的文本称为文本节点。
XML DOM - 方法
DOM 作为 API 包含表示 XML 文档中可以找到的不同类型信息(例如元素和文本)的接口。这些接口包括使用这些对象所需的方法和属性。属性定义节点的特性,而方法提供操作节点的方式。
下表列出了 DOM 类和接口:
| 序号 | 接口和描述 |
|---|---|
| 1 | DOMImplementation 它提供许多方法来执行独立于文档对象模型任何特定实例的操作。 |
| 2 | DocumentFragment 它是“轻量级”或“最小”文档对象,它(作为 Document 的超类)在成熟的文档中锚定 XML/HTML 树。 |
| 3 | Document 它表示 XML 文档的顶级节点,它提供对文档中所有节点(包括根元素)的访问。 |
| 4 | Node 它表示 XML 节点。 |
| 5 | NodeList 它表示Node对象的只读列表。 |
| 6 | NamedNodeMap 它表示可以按名称访问的节点集合。 |
| 7 | Data 它通过一组属性和方法扩展Node,用于访问 DOM 中的字符数据。 |
| 8 | Attribute 它表示 Element 对象中的属性。 |
| 9 | Element 它表示元素节点。派生自 Node。 |
| 10 | Text 它表示文本节点。派生自 CharacterData。 |
| 11 | Comment 它表示注释节点。派生自 CharacterData。 |
| 12 | ProcessingInstruction 它表示“处理指令”。它在 XML 中用作在文档文本中保留处理器特定信息的一种方式。 |
| 13 | CDATA Section 它表示 CDATA 部分。派生自 Text。 |
| 14 | Entity 它表示实体。派生自 Node。 |
| 15 | EntityReference 这表示树中的实体引用。派生自 Node。 |
我们将在各自的章节中讨论上述每个接口的方法和属性。
XML DOM - 加载
在本节中,我们将学习 XML 的加载和解析。
为了描述 API 提供的接口,W3C 使用了一种称为接口定义语言 (IDL) 的抽象语言。使用 IDL 的优点是开发人员可以学习如何使用自己喜欢的语言使用 DOM,并且可以轻松切换到不同的语言。
缺点是,由于它是抽象的,因此 Web 开发人员无法直接使用 IDL。由于编程语言之间的差异,它们需要在抽象接口及其具体语言之间进行映射——或绑定——。DOM 已映射到 JavaScript、JScript、Java、C、C++、PLSQL、Python 和 Perl 等编程语言。
在接下来的章节中,我们将使用 Javascript 作为编程语言来加载 XML 文件。
解析器
解析器是一个软件应用程序,它被设计用来分析文档(在本例中为 XML 文档)并对信息执行特定操作。一些基于 DOM 的解析器列在下面的表格中:
| 序号 | 解析器及描述 |
|---|---|
| 1 |
JAXP Sun Microsystem 的 Java API for XML Parsing (JAXP) |
| 2 | XML4J IBM 的 Java XML 解析器 (XML4J) |
| 3 | msxml Microsoft 的 XML 解析器 (msxml) 2.0 版本内置于 Internet Explorer 5.5 中 |
| 4 | 4DOM 4DOM 是 Python 编程语言的解析器 |
| 5 | XML::DOM XML::DOM 是一个 Perl 模块,用于使用 Perl 操作 XML 文档 |
| 6 | Xerces Apache 的 Xerces Java 解析器 |
在像 DOM 这样的基于树的 API 中,解析器遍历 XML 文件并创建相应的 DOM 对象。然后您可以来回遍历 DOM 结构。
加载和解析 XML
加载 XML 文档时,XML 内容可以有两种形式:
- 直接作为 XML 文件
- 作为 XML 字符串
内容作为 XML 文件
下面的例子演示了如何使用 Ajax 和 Javascript 加载 XML (node.xml) 数据,当 XML 内容作为 XML 文件接收时。在这里,Ajax 函数获取 xml 文件的内容并将其存储在 XML DOM 中。一旦创建了 DOM 对象,它就会被解析。
<!DOCTYPE html>
<html>
<body>
<div>
<b>FirstName:</b> <span id = "FirstName"></span><br>
<b>LastName:</b> <span id = "LastName"></span><br>
<b>ContactNo:</b> <span id = "ContactNo"></span><br>
<b>Email:</b> <span id = "Email"></span>
</div>
<script>
//if browser supports XMLHttpRequest
if (window.XMLHttpRequest) { // Create an instance of XMLHttpRequest object.
code for IE7+, Firefox, Chrome, Opera, Safari xmlhttp = new XMLHttpRequest();
} else { // code for IE6, IE5
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
// sets and sends the request for calling "node.xml"
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
// sets and returns the content as XML DOM
xmlDoc = xmlhttp.responseXML;
//parsing the DOM object
document.getElementById("FirstName").innerHTML =
xmlDoc.getElementsByTagName("FirstName")[0].childNodes[0].nodeValue;
document.getElementById("LastName").innerHTML =
xmlDoc.getElementsByTagName("LastName")[0].childNodes[0].nodeValue;
document.getElementById("ContactNo").innerHTML =
xmlDoc.getElementsByTagName("ContactNo")[0].childNodes[0].nodeValue;
document.getElementById("Email").innerHTML =
xmlDoc.getElementsByTagName("Email")[0].childNodes[0].nodeValue;
</script>
</body>
</html>
node.xml
<Company>
<Employee category = "Technical" id = "firstelement">
<FirstName>Tanmay</FirstName>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
<Email>tanmaypatil@xyz.com</Email>
</Employee>
<Employee category = "Non-Technical">
<FirstName>Taniya</FirstName>
<LastName>Mishra</LastName>
<ContactNo>1234667898</ContactNo>
<Email>taniyamishra@xyz.com</Email>
</Employee>
<Employee category = "Management">
<FirstName>Tanisha</FirstName>
<LastName>Sharma</LastName>
<ContactNo>1234562350</ContactNo>
<Email>tanishasharma@xyz.com</Email>
</Employee>
</Company>
大部分代码细节都在脚本代码中。
Internet Explorer 使用 ActiveXObject("Microsoft.XMLHTTP") 创建 XMLHttpRequest 对象的实例,其他浏览器使用 XMLHttpRequest() 方法。
responseXML 将 XML 内容直接转换为 XML DOM。
一旦 XML 内容转换为 JavaScript XML DOM,就可以使用 JS DOM 方法和属性访问任何 XML 元素。我们使用了 DOM 属性,例如 childNodes、nodeValue 和 DOM 方法,例如 getElementsById(ID)、getElementsByTagName(tags_name)。
执行
将此文件保存为 loadingexample.html 并将其在浏览器中打开。您将收到以下输出:

内容作为 XML 字符串
下面的例子演示了如何使用 Ajax 和 Javascript 加载 XML 数据,当 XML 内容作为 XML 文件接收时。在这里,Ajax 函数获取 xml 文件的内容并将其存储在 XML DOM 中。一旦创建了 DOM 对象,它就会被解析。
<!DOCTYPE html>
<html>
<head>
<script>
// loads the xml string in a dom object
function loadXMLString(t) { // for non IE browsers
if (window.DOMParser) {
// create an instance for xml dom object parser = new DOMParser();
xmlDoc = parser.parseFromString(t,"text/xml");
}
// code for IE
else { // create an instance for xml dom object
xmlDoc = new ActiveXObject("Microsoft.XMLDOM");
xmlDoc.async = false;
xmlDoc.loadXML(t);
}
return xmlDoc;
}
</script>
</head>
<body>
<script>
// a variable with the string
var text = "<Employee>";
text = text+"<FirstName>Tanmay</FirstName>";
text = text+"<LastName>Patil</LastName>";
text = text+"<ContactNo>1234567890</ContactNo>";
text = text+"<Email>tanmaypatil@xyz.com</Email>";
text = text+"</Employee>";
// calls the loadXMLString() with "text" function and store the xml dom in a variable
var xmlDoc = loadXMLString(text);
//parsing the DOM object
y = xmlDoc.documentElement.childNodes;
for (i = 0;i<y.length;i++) {
document.write(y[i].childNodes[0].nodeValue);
document.write("<br>");
}
</script>
</body>
</html>
大部分代码细节都在脚本代码中。
Internet Explorer 使用 ActiveXObject("Microsoft.XMLDOM") 将 XML 数据加载到 DOM 对象中,其他浏览器使用 DOMParser() 函数和 parseFromString(text, 'text/xml') 方法。
变量 text 应该包含一个包含 XML 内容的字符串。
一旦 XML 内容转换为 JavaScript XML DOM,就可以使用 JS DOM 方法和属性访问任何 XML 元素。我们使用了 DOM 属性,例如 childNodes、nodeValue。
执行
将此文件保存为 loadingexample.html 并将其在浏览器中打开。您将看到以下输出:

现在我们已经了解了 XML 内容如何转换为 JavaScript XML DOM,您现在可以使用 XML DOM 方法访问任何 XML 元素。
XML DOM - 遍历
在本章中,我们将讨论 XML DOM 遍历。我们在上一章学习了如何加载 XML 文档并解析由此获得的 DOM 对象。这个已解析的 DOM 对象可以被遍历。遍历是一个系统地循环遍历节点树中每个元素的过程。
示例
下面的例子 (traverse_example.htm) 演示了 DOM 遍历。在这里,我们遍历 <Employee> 元素的每个子节点。
<!DOCTYPE html>
<html>
<style>
table,th,td {
border:1px solid black;
border-collapse:collapse
}
</style>
<body>
<div id = "ajax_xml"></div>
<script>
//if browser supports XMLHttpRequest
if (window.XMLHttpRequest) {// Create an instance of XMLHttpRequest object.
code for IE7+, Firefox, Chrome, Opera, Safari
var xmlhttp = new XMLHttpRequest();
} else {// code for IE6, IE5
var xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
// sets and sends the request for calling "node.xml"
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
// sets and returns the content as XML DOM
var xml_dom = xmlhttp.responseXML;
// this variable stores the code of the html table
var html_tab = '<table id = "id_tabel" align = "center">
<tr>
<th>Employee Category</th>
<th>FirstName</th>
<th>LastName</th>
<th>ContactNo</th>
<th>Email</th>
</tr>';
var arr_employees = xml_dom.getElementsByTagName("Employee");
// traverses the "arr_employees" array
for(var i = 0; i<arr_employees.length; i++) {
var employee_cat = arr_employees[i].getAttribute('category');
// gets the value of 'category' element of current "Element" tag
// gets the value of first child-node of 'FirstName'
// element of current "Employee" tag
var employee_firstName =
arr_employees[i].getElementsByTagName('FirstName')[0].childNodes[0].nodeValue;
// gets the value of first child-node of 'LastName'
// element of current "Employee" tag
var employee_lastName =
arr_employees[i].getElementsByTagName('LastName')[0].childNodes[0].nodeValue;
// gets the value of first child-node of 'ContactNo'
// element of current "Employee" tag
var employee_contactno =
arr_employees[i].getElementsByTagName('ContactNo')[0].childNodes[0].nodeValue;
// gets the value of first child-node of 'Email'
// element of current "Employee" tag
var employee_email =
arr_employees[i].getElementsByTagName('Email')[0].childNodes[0].nodeValue;
// adds the values in the html table
html_tab += '<tr>
<td>'+ employee_cat+ '</td>
<td>'+ employee_firstName+ '</td>
<td>'+ employee_lastName+ '</td>
<td>'+ employee_contactno+ '</td>
<td>'+ employee_email+ '</td>
</tr>';
}
html_tab += '</table>';
// adds the html table in a html tag, with id = "ajax_xml"
document.getElementById('ajax_xml').innerHTML = html_tab;
</script>
</body>
</html>
这段代码加载了 node.xml。
XML 内容被转换为 JavaScript XML DOM 对象。
使用 getElementsByTagName() 方法获得元素数组(带有标签 Element)。
接下来,我们遍历这个数组并在表格中显示子节点值。
执行
将此文件保存为 traverse_example.html 到服务器路径(此文件和 node.xml 应该在服务器的同一路径下)。您将收到以下输出:

XML DOM - 导航
到目前为止,我们学习了 DOM 结构、如何加载和解析 XML DOM 对象以及如何遍历 DOM 对象。在这里,我们将了解如何在一个 DOM 对象中导航节点之间。XML DOM 包含节点的各种属性,这些属性帮助我们遍历节点,例如:
- parentNode
- childNodes
- firstChild
- lastChild
- nextSibling
- previousSibling
以下是节点树的图表,显示了它与其他节点的关系。
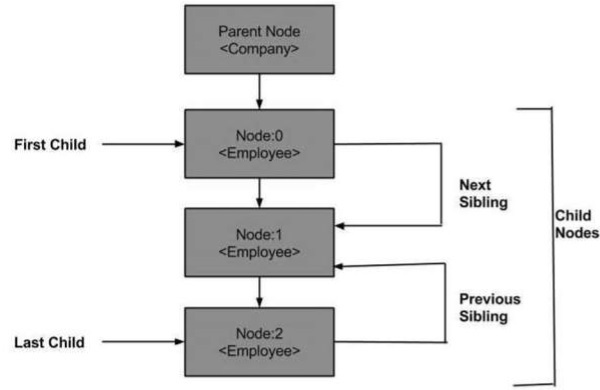
DOM - 父节点
此属性将父节点指定为节点对象。
示例
下面的例子 (navigate_example.htm) 将 XML 文档 (node.xml) 解析成 XML DOM 对象。然后通过子节点导航到父节点:
<!DOCTYPE html>
<html>
<body>
<script>
if (window.XMLHttpRequest) {
xmlhttp = new XMLHttpRequest();
} else {
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
var y = xmlDoc.getElementsByTagName("Employee")[0];
document.write(y.parentNode.nodeName);
</script>
</body>
</html>
正如您在上面的例子中看到的,子节点 Employee 导航到它的父节点。
执行
将此文件保存为 navigate_example.html 到服务器路径(此文件和 node.xml 应该在服务器的同一路径下)。在输出中,我们得到 Employee 的父节点,即 Company。
第一个子节点
此属性的类型为 Node,表示 NodeList 中存在的第一个子节点名称。
示例
下面的例子 (first_node_example.htm) 将 XML 文档 (node.xml) 解析成 XML DOM 对象,然后导航到 DOM 对象中存在的第一个子节点。
<!DOCTYPE html>
<html>
<body>
<script>
if (window.XMLHttpRequest) {
xmlhttp = new XMLHttpRequest();
} else {
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
function get_firstChild(p) {
a = p.firstChild;
while (a.nodeType != 1) {
a = a.nextSibling;
}
return a;
}
var firstchild = get_firstChild(xmlDoc.getElementsByTagName("Employee")[0]);
document.write(firstchild.nodeName);
</script>
</body>
</html>
函数 get_firstChild(p) 用于避免空节点。它有助于从节点列表中获取 firstChild 元素。
x = get_firstChild(xmlDoc.getElementsByTagName("Employee")[0]) 获取标签名称为 Employee 的第一个子节点。
执行
将此文件保存为 first_node_example.htm 到服务器路径(此文件和 node.xml 应该在服务器的同一路径下)。在输出中,我们得到 Employee 的第一个子节点,即 FirstName。
最后一个子节点
此属性的类型为 Node,表示 NodeList 中存在的最后一个子节点名称。
示例
下面的例子 (last_node_example.htm) 将 XML 文档 (node.xml) 解析成 XML DOM 对象,然后导航到 xml DOM 对象中存在的最后一个子节点。
<!DOCTYPE html>
<body>
<script>
if (window.XMLHttpRequest) {
xmlhttp = new XMLHttpRequest();
} else {
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
function get_lastChild(p) {
a = p.lastChild;
while (a.nodeType != 1){
a = a.previousSibling;
}
return a;
}
var lastchild = get_lastChild(xmlDoc.getElementsByTagName("Employee")[0]);
document.write(lastchild.nodeName);
</script>
</body>
</html>
执行
将此文件保存为 last_node_example.htm 到服务器路径(此文件和 node.xml 应该在服务器的同一路径下)。在输出中,我们得到 Employee 的最后一个子节点,即 Email。
下一个兄弟节点
此属性的类型为 Node,表示下一个子节点,即 NodeList 中存在的指定子元素的下一个兄弟节点。
示例
下面的例子 (nextSibling_example.htm) 将 XML 文档 (node.xml) 解析成 XML DOM 对象,然后立即导航到 xml 文档中存在的下一个节点。
<!DOCTYPE html>
<body>
<script>
if (window.XMLHttpRequest) {
xmlhttp = new XMLHttpRequest();
}
else {
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
function get_nextSibling(p) {
a = p.nextSibling;
while (a.nodeType != 1) {
a = a.nextSibling;
}
return a;
}
var nextsibling = get_nextSibling(xmlDoc.getElementsByTagName("FirstName")[0]);
document.write(nextsibling.nodeName);
</script>
</body>
</html>
执行
将此文件保存为 nextSibling_example.htm 到服务器路径(此文件和 node.xml 应该在服务器的同一路径下)。在输出中,我们得到 FirstName 的下一个兄弟节点,即 LastName。
上一个兄弟节点
此属性的类型为 Node,表示上一个子节点,即 NodeList 中存在的指定子元素的上一个兄弟节点。
示例
下面的例子 (previoussibling_example.htm) 将 XML 文档 (node.xml) 解析成 XML DOM 对象,然后导航到 xml 文档中最后一个子节点之前的节点。
<!DOCTYPE html>
<body>
<script>
if (window.XMLHttpRequest)
{
xmlhttp = new XMLHttpRequest();
} else {
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
function get_previousSibling(p) {
a = p.previousSibling;
while (a.nodeType != 1) {
a = a.previousSibling;
}
return a;
}
prevsibling = get_previousSibling(xmlDoc.getElementsByTagName("Email")[0]);
document.write(prevsibling.nodeName);
</script>
</body>
</html>
执行
将此文件保存为 previoussibling_example.htm 到服务器路径(此文件和 node.xml 应该在服务器的同一路径下)。在输出中,我们得到 Email 的上一个兄弟节点,即 ContactNo。
XML DOM - 访问
在本章中,我们将学习如何访问 XML DOM 节点,这些节点被认为是 XML 文档的信息单元。XML DOM 的节点结构允许开发人员在树中查找特定信息,同时访问信息。
访问节点
您可以通过以下三种方式访问节点:
使用 getElementsByTagName () 方法
通过循环或遍历节点树
通过使用节点关系导航节点树
getElementsByTagName ()
此方法允许通过指定节点名称来访问节点的信息。它还允许访问节点列表和节点列表长度的信息。
语法
getElementByTagName() 方法具有以下语法:
node.getElementByTagName("tagname");
其中,
node - 是文档节点。
tagname - 包含要获取其值的节点的名称。
示例
以下是一个简单的程序,它说明了 getElementByTagName 方法的用法。
<!DOCTYPE html>
<html>
<body>
<div>
<b>FirstName:</b> <span id = "FirstName"></span><br>
<b>LastName:</b> <span id = "LastName"></span><br>
<b>Category:</b> <span id = "Employee"></span><br>
</div>
<script>
if (window.XMLHttpRequest) {// code for IE7+, Firefox, Chrome, Opera, Safari
xmlhttp = new XMLHttpRequest();
} else {// code for IE6, IE5
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
document.getElementById("FirstName").innerHTML =
xmlDoc.getElementsByTagName("FirstName")[0].childNodes[0].nodeValue;
document.getElementById("LastName").innerHTML =
xmlDoc.getElementsByTagName("LastName")[0].childNodes[0].nodeValue;
document.getElementById("Employee").innerHTML =
xmlDoc.getElementsByTagName("Employee")[0].attributes[0].nodeValue;
</script>
</body>
</html>
在上面的例子中,我们正在访问 FirstName、LastName 和 Employee 节点的信息。
xmlDoc.getElementsByTagName("FirstName")[0].childNodes[0].nodeValue; 此行使用 getElementByTagName() 方法访问子节点 FirstName 的值。
xmlDoc.getElementsByTagName("Employee")[0].attributes[0].nodeValue; 此行使用 getElementByTagName() 方法访问节点 Employee 的属性值。
遍历节点
这在章节DOM 遍历中用例子进行了讲解。
导航节点
这在章节DOM 导航中用例子进行了讲解。
XML DOM - 获取节点
在本章中,我们将学习如何获取 XML DOM 对象的节点值。XML 文档具有称为节点的信息单元的层次结构。节点对象有一个属性 nodeValue,它返回元素的值。
在接下来的章节中,我们将讨论:
获取元素的节点值
获取节点的属性值
以下所有示例中使用的 node.xml 如下:
<Company>
<Employee category = "Technical">
<FirstName>Tanmay</FirstName>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
<Email>tanmaypatil@xyz.com</Email>
</Employee>
<Employee category = "Non-Technical">
<FirstName>Taniya</FirstName>
<LastName>Mishra</LastName>
<ContactNo>1234667898</ContactNo>
<Email>taniyamishra@xyz.com</Email>
</Employee>
<Employee category = "Management">
<FirstName>Tanisha</FirstName>
<LastName>Sharma</LastName>
<ContactNo>1234562350</ContactNo>
<Email>tanishasharma@xyz.com</Email>
</Employee>
</Company>
获取节点值
getElementsByTagName() 方法返回文档中所有具有给定标签名称的 Elements 的 NodeList,按文档顺序排列。
示例
下面的例子 (getnode_example.htm) 将 XML 文档 (node.xml) 解析成 XML DOM 对象,并提取子节点 Firstname(索引为 0)的节点值:
<!DOCTYPE html>
<html>
<body>
<script>
if (window.XMLHttpRequest) {
xmlhttp = new XMLHttpRequest();
} else{
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
x = xmlDoc.getElementsByTagName('FirstName')[0]
y = x.childNodes[0];
document.write(y.nodeValue);
</script>
</body>
</html>
执行
将此文件保存为 getnode_example.htm 到服务器路径(此文件和 node.xml 应该在服务器的同一路径下)。在输出中,我们得到节点值 Tanmay。
获取属性值
属性是 XML 节点元素的一部分。一个节点元素可以有多个唯一的属性。属性提供了关于 XML 节点元素的更多信息。更准确地说,它们定义了节点元素的属性。XML 属性始终是名称-值对。属性的值称为属性节点。
getAttribute() 方法通过元素名称检索属性值。
示例
下面的示例 (get_attribute_example.htm) 将 XML 文档 (node.xml) 解析为 XML DOM 对象,并提取类别Employee(索引为 2)的属性值:
<!DOCTYPE html>
<html>
<body>
<script>
if (window.XMLHttpRequest) {
xmlhttp = new XMLHttpRequest();
} else {
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
x = xmlDoc.getElementsByTagName('Employee')[2];
document.write(x.getAttribute('category'));
</script>
</body>
</html>
执行
将此文件保存为服务器路径上的get_attribute_example.htm(此文件和 node.xml 应位于服务器上的同一路径)。在输出中,我们得到属性值为Management。
XML DOM - 设置节点
在本章中,我们将学习如何在 XML DOM 对象中更改节点的值。节点值可以按如下方式更改:
var value = node.nodeValue;
如果node是Attribute,则value变量将是属性的值;如果node是Text节点,它将是文本内容;如果node是Element,它将为null。
以下部分将演示每种节点类型(属性、文本节点和元素)的节点值设置。
以下所有示例中使用的 node.xml 如下:
<Company>
<Employee category = "Technical">
<FirstName>Tanmay</FirstName>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
<Email>tanmaypatil@xyz.com</Email>
</Employee>
<Employee category = "Non-Technical">
<FirstName>Taniya</FirstName>
<LastName>Mishra</LastName>
<ContactNo>1234667898</ContactNo>
<Email>taniyamishra@xyz.com</Email>
</Employee>
<Employee category = "Management">
<FirstName>Tanisha</FirstName>
<LastName>Sharma</LastName>
<ContactNo>1234562350</ContactNo>
<Email>tanishasharma@xyz.com</Email>
</Employee>
</Company>
更改文本节点的值
当我们说更改节点元素的值时,我们的意思是编辑元素的文本内容(也称为文本节点)。下面的示例演示如何更改元素的文本节点。
示例
下面的示例 (set_text_node_example.htm) 将 XML 文档 (node.xml) 解析为 XML DOM 对象,并更改元素文本节点的值。在本例中,将每个Employee的Email更改为support@xyz.com并打印值。
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
x = xmlDoc.getElementsByTagName("Email");
for(i = 0;i<x.length;i++) {
x[i].childNodes[0].nodeValue = "support@xyz.com";
document.write(i+');
document.write(x[i].childNodes[0].nodeValue);
document.write('<br>');
}
</script>
</body>
</html>
执行
将此文件保存为服务器路径上的set_text_node_example.htm(此文件和node.xml应位于服务器上的同一路径)。您将收到以下输出:
0) support@xyz.com 1) support@xyz.com 2) support@xyz.com
更改属性节点的值
下面的示例演示如何更改元素的属性节点。
示例
下面的示例 (set_attribute_example.htm) 将 XML 文档 (node.xml) 解析为 XML DOM 对象,并更改元素属性节点的值。在本例中,将每个Employee的Category分别更改为admin-0, admin-1, admin-2并打印值。
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
x = xmlDoc.getElementsByTagName("Employee");
for(i = 0 ;i<x.length;i++){
newcategory = x[i].getAttributeNode('category');
newcategory.nodeValue = "admin-"+i;
document.write(i+');
document.write(x[i].getAttributeNode('category').nodeValue);
document.write('<br>');
}
</script>
</body>
</html>
执行
将此文件保存为服务器路径上的set_node_attribute_example.htm(此文件和node.xml应位于服务器上的同一路径)。结果如下:
0) admin-0 1) admin-1 2) admin-2
XML DOM - 创建节点
在本章中,我们将讨论如何使用文档对象的几种方法创建新节点。这些方法提供了一个范围来创建新的元素节点、文本节点、注释节点、CDATA 节点和属性节点。如果新创建的节点已存在于元素对象中,则它将被新的节点替换。以下部分将通过示例演示这一点。
创建新的Element节点
createElement()方法创建一个新的元素节点。如果新创建的元素节点已存在于元素对象中,则它将被新的节点替换。
语法
使用createElement()方法的语法如下:
var_name = xmldoc.createElement("tagname");
其中,
var_name - 是保存新元素名称的用户定义变量名。
("tagname") - 是要创建的新元素节点的名称。
示例
下面的示例 (createnewelement_example.htm) 将 XML 文档 (node.xml) 解析为 XML DOM 对象,并在 XML 文档中创建一个新的元素节点PhoneNo。
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
new_element = xmlDoc.createElement("PhoneNo");
x = xmlDoc.getElementsByTagName("FirstName")[0];
x.appendChild(new_element);
document.write(x.getElementsByTagName("PhoneNo")[0].nodeName);
</script>
</body>
</html>
new_element = xmlDoc.createElement("PhoneNo"); 创建新的元素节点<PhoneNo>
x.appendChild(new_element); x保存指定子节点<FirstName>的名称,新元素节点将附加到该子节点。
执行
将此文件保存为服务器路径上的createnewelement_example.htm(此文件和node.xml应位于服务器上的同一路径)。在输出中,我们得到属性值为PhoneNo。
创建新的Text节点
createTextNode()方法创建一个新的文本节点。
语法
使用createTextNode()的语法如下:
var_name = xmldoc.createTextNode("tagname");
其中,
var_name - 是保存新文本节点名称的用户定义变量名。
("tagname") - 括号内是要创建的新文本节点的名称。
示例
下面的示例 (createtextnode_example.htm) 将 XML 文档 (node.xml) 解析为 XML DOM 对象,并在 XML 文档中创建一个新的文本节点Im new text node。
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
create_e = xmlDoc.createElement("PhoneNo");
create_t = xmlDoc.createTextNode("Im new text node");
create_e.appendChild(create_t);
x = xmlDoc.getElementsByTagName("Employee")[0];
x.appendChild(create_e);
document.write(" PhoneNO: ");
document.write(x.getElementsByTagName("PhoneNo")[0].childNodes[0].nodeValue);
</script>
</body>
</html>
上面代码的详细信息如下:
create_e = xmlDoc.createElement("PhoneNo"); 创建一个新的元素<PhoneNo>。
create_t = xmlDoc.createTextNode("Im new text node"); 创建一个新的文本节点"Im new text node"。
x.appendChild(create_e); 文本节点"Im new text node"附加到元素<PhoneNo>。
document.write(x.getElementsByTagName("PhoneNo")[0].childNodes[0].nodeValue); 将新文本节点的值写入元素<PhoneNo>。
执行
将此文件保存为服务器路径上的createtextnode_example.htm(此文件和 node.xml 应位于服务器上的同一路径)。在输出中,我们得到属性值,即PhoneNO: Im new text node。
创建新的Comment节点
createComment()方法创建一个新的注释节点。注释节点包含在程序中是为了方便理解代码功能。
语法
使用createComment()的语法如下:
var_name = xmldoc.createComment("tagname");
其中,
var_name - 是保存新注释节点名称的用户定义变量名。
("tagname") - 是要创建的新注释节点的名称。
示例
下面的示例 (createcommentnode_example.htm) 将 XML 文档 (node.xml) 解析为 XML DOM 对象,并在 XML 文档中创建一个新的注释节点"Company is the parent node"。
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
}
else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
create_comment = xmlDoc.createComment("Company is the parent node");
x = xmlDoc.getElementsByTagName("Company")[0];
x.appendChild(create_comment);
document.write(x.lastChild.nodeValue);
</script>
</body>
</html>
在上面的示例中:
create_comment = xmlDoc.createComment("Company is the parent node") **创建指定的注释行**。
x.appendChild(create_comment) 在这一行中,'x'保存元素<Company>的名称,注释行将附加到该元素。
执行
将此文件保存为服务器路径上的createcommentnode_example.htm(此文件和node.xml应位于服务器上的同一路径)。在输出中,我们得到属性值为Company is the parent node。
创建新的CDATA Section节点
createCDATASection()方法创建一个新的 CDATA 节点。如果新创建的 CDATA 节点已存在于元素对象中,则它将被新的节点替换。
语法
使用createCDATASection()的语法如下:
var_name = xmldoc.createCDATASection("tagname");
其中,
var_name - 是保存新 CDATA 节点名称的用户定义变量名。
("tagname") - 是要创建的新 CDATA 节点的名称。
示例
下面的示例 (createcdatanode_example.htm) 将 XML 文档 (node.xml) 解析为 XML DOM 对象,并在 XML 文档中创建一个新的 CDATA 节点"Create CDATA Example"。
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
}
else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
create_CDATA = xmlDoc.createCDATASection("Create CDATA Example");
x = xmlDoc.getElementsByTagName("Employee")[0];
x.appendChild(create_CDATA);
document.write(x.lastChild.nodeValue);
</script>
</body>
</html>
在上面的示例中:
create_CDATA = xmlDoc.createCDATASection("Create CDATA Example") 创建一个新的 CDATA 节点"Create CDATA Example"
x.appendChild(create_CDATA) 在这里,x保存索引为 0 的指定元素<Employee>,CDATA 节点值将附加到该元素。
执行
将此文件保存为服务器路径上的createcdatanode_example.htm(此文件和 node.xml 应位于服务器上的同一路径)。在输出中,我们得到属性值为Create CDATA Example。
创建新的Attribute节点
要创建新的属性节点,可以使用setAttributeNode()方法。如果新创建的属性节点已存在于元素对象中,则它将被新的节点替换。
语法
使用createElement()方法的语法如下:
var_name = xmldoc.createAttribute("tagname");
其中,
var_name - 是保存新属性节点名称的用户定义变量名。
("tagname") - 是要创建的新属性节点的名称。
示例
下面的示例 (createattributenode_example.htm) 将 XML 文档 (node.xml) 解析为 XML DOM 对象,并在 XML 文档中创建一个新的属性节点section。
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
create_a = xmlDoc.createAttribute("section");
create_a.nodeValue = "A";
x = xmlDoc.getElementsByTagName("Employee");
x[0].setAttributeNode(create_a);
document.write("New Attribute: ");
document.write(x[0].getAttribute("section"));
</script>
</body>
</html>
在上面的示例中:
create_a=xmlDoc.createAttribute("Category") 创建一个名为<section>的属性。
create_a.nodeValue="Management" 为属性<section>创建值"A"。
x[0].setAttributeNode(create_a) 此属性值被设置为索引为 0 的节点元素<Employee>。
XML DOM - 添加节点
在本章中,我们将讨论将节点添加到现有元素。它提供了一种方法来:
在现有子节点之前或之后附加新的子节点
在文本节点内插入数据
添加属性节点
可以使用以下方法将节点添加到/附加到 DOM 中的元素:
- appendChild()
- insertBefore()
- insertData()
appendChild()
appendChild()方法在现有子节点之后添加新的子节点。
语法
appendChild()方法的语法如下:
Node appendChild(Node newChild) throws DOMException
其中,
newChild - 要添加的节点
此方法返回添加的Node。
示例
下面的示例 (appendchildnode_example.htm) 将 XML 文档 (node.xml) 解析为 XML DOM 对象,并将新的子节点PhoneNo附加到元素<FirstName>。
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
create_e = xmlDoc.createElement("PhoneNo");
x = xmlDoc.getElementsByTagName("FirstName")[0];
x.appendChild(create_e);
document.write(x.getElementsByTagName("PhoneNo")[0].nodeName);
</script>
</body>
</html>
在上面的示例中:
使用 createElement() 方法创建一个新的元素PhoneNo。
使用 appendChild() 方法将新的元素PhoneNo添加到元素FirstName。
执行
将此文件保存为服务器路径上的appendchildnode_example.htm(此文件和 node.xml 应位于服务器上的同一路径)。在输出中,我们得到属性值为PhoneNo。
insertBefore()
insertBefore()方法在指定的子节点之前插入新的子节点。
语法
insertBefore()方法的语法如下:
Node insertBefore(Node newChild, Node refChild) throws DOMException
其中,
newChild - 要插入的节点
refChild - 参考节点,即必须在该节点之前插入新节点的节点。
此方法返回正在插入的Node。
示例
下面的示例 (insertnodebefore_example.htm) 将 XML 文档 (node.xml) 解析为 XML DOM 对象,并在指定的元素<Email>之前插入新的子节点Email。
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
create_e = xmlDoc.createElement("Email");
x = xmlDoc.documentElement;
y = xmlDoc.getElementsByTagName("Email");
document.write("No of Email elements before inserting was: " + y.length);
document.write("<br>");
x.insertBefore(create_e,y[3]);
y=xmlDoc.getElementsByTagName("Email");
document.write("No of Email elements after inserting is: " + y.length);
</script>
</body>
</html>
在上面的示例中:
使用 createElement() 方法创建一个新的元素Email。
使用 insertBefore() 方法在元素Email之前添加新的元素Email。
y.length给出在新的元素之前和之后添加的元素的总数。
执行
将此文件保存为服务器路径上的insertnodebefore_example.htm(此文件和 node.xml 应位于服务器上的同一路径)。我们将收到以下输出:
No of Email elements before inserting was: 3 No of Email elements after inserting is: 4
insertData()
insertData() 方法在指定的 16 位单元偏移量处插入字符串。
语法
insertData() 方法具有以下语法:
void insertData(int offset, java.lang.String arg) throws DOMException
其中,
offset − 要插入字符的偏移量。
arg − 要插入数据的关键字。它用括号括起 offset 和 string 两个参数,并用逗号分隔。
示例
下面的示例 (addtext_example.htm) 将 XML 文档 ("node.xml") 解析为 XML DOM 对象,并在指定位置将新数据 MiddleName 插入到 <FirstName> 元素中。
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
x = xmlDoc.getElementsByTagName("FirstName")[0].childNodes[0];
document.write(x.nodeValue);
x.insertData(6,"MiddleName");
document.write("<br>");
document.write(x.nodeValue);
</script>
</body>
</html>
x.insertData(6,"MiddleName"); − 这里,x 保存指定子节点名称,即 <FirstName>。然后,我们从位置 6 开始,将数据 "MiddleName" 插入到此文本节点中。
执行
将此文件保存为服务器路径上的 addtext_example.htm(此文件和 node.xml 应位于服务器上的同一路径)。输出结果如下:
Tanmay TanmayMiddleName
XML DOM - 替换节点
本章将学习 XML DOM 对象中的替换节点操作。众所周知,DOM 中的所有内容都维护在一个称为节点的分层信息单元中,替换节点提供了另一种更新这些指定节点或文本节点的方法。
以下是替换节点的两种方法:
- replaceChild()
- replaceData()
replaceChild()
replaceChild() 方法用新节点替换指定的节点。
语法
insertData() 方法具有以下语法:
Node replaceChild(Node newChild, Node oldChild) throws DOMException
其中,
newChild − 要添加到子列表中的新节点。
oldChild − 要替换的节点。
此方法返回被替换的节点。
示例
下面的示例 (replacenode_example.htm) 将 XML 文档 (node.xml) 解析为 XML DOM 对象,并将指定的节点 <FirstName> 替换为新节点 <Name>。
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
x = xmlDoc.documentElement;
z = xmlDoc.getElementsByTagName("FirstName");
document.write("<b>Content of FirstName element before replace operation</b><br>");
for (i=0;i<z.length;i++) {
document.write(z[i].childNodes[0].nodeValue);
document.write("<br>");
}
//create a Employee element, FirstName element and a text node
newNode = xmlDoc.createElement("Employee");
newTitle = xmlDoc.createElement("Name");
newText = xmlDoc.createTextNode("MS Dhoni");
//add the text node to the title node,
newTitle.appendChild(newText);
//add the title node to the book node
newNode.appendChild(newTitle);
y = xmlDoc.getElementsByTagName("Employee")[0]
//replace the first book node with the new node
x.replaceChild(newNode,y);
z = xmlDoc.getElementsByTagName("FirstName");
document.write("<b>Content of FirstName element after replace operation</b><br>");
for (i = 0;i<z.length;i++) {
document.write(z[i].childNodes[0].nodeValue);
document.write("<br>");
}
</script>
</body>
</html>
执行
将此文件保存为服务器路径上的 replacenode_example.htm(此文件和 node.xml 应位于服务器上的同一路径)。输出结果如下:
Content of FirstName element before replace operation Tanmay Taniya Tanisha Content of FirstName element after replace operation Taniya Tanisha
replaceData()
replaceData() 方法用指定的字符串替换从指定的 16 位单元偏移量开始的字符。
语法
replaceData() 方法具有以下语法:
void replaceData(int offset, int count, java.lang.String arg) throws DOMException
其中
offset − 开始替换的偏移量。
count − 要替换的 16 位单元数。如果 offset 和 count 的总和超过长度,则替换数据末尾的所有 16 位单元。
arg − 必须替换范围的 DOMString。
示例
下面的示例 (replacedata_example.htm) 将 XML 文档 (node.xml) 解析为 XML DOM 对象并进行替换。
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
x = xmlDoc.getElementsByTagName("ContactNo")[0].childNodes[0];
document.write("<b>ContactNo before replace operation:</b> "+x.nodeValue);
x.replaceData(1,5,"9999999");
document.write("<br>");
document.write("<b>ContactNo after replace operation:</b> "+x.nodeValue);
</script>
</body>
</html>
在上面的示例中:
x.replaceData(2,3,"999"); − 这里 x 保存指定元素 <ContactNo> 的文本,其文本将被新文本 "9999999" 替换,从位置 1 开始到长度为 5 的位置。
执行
将此文件保存为服务器路径上的 replacedata_example.htm(此文件和 node.xml 应位于服务器上的同一路径)。输出结果如下:
ContactNo before replace operation: 1234567890 ContactNo after replace operation: 199999997890
XML DOM - 删除节点
本章将学习 XML DOM 的 删除节点 操作。删除节点操作将从文档中删除指定的节点。此操作可用于删除文本节点、元素节点或属性节点。
以下是用于删除节点操作的方法:
removeChild()
removeAttribute()
removeChild()
removeChild() 方法从子节点列表中删除由 oldChild 指定的子节点,并将其返回。删除子节点等同于删除与其关联的文本节点。因此,删除子节点会删除与其关联的文本节点。
语法
使用 removeChild() 的语法如下:
Node removeChild(Node oldChild) throws DOMException
其中,
oldChild − 要删除的节点。
此方法返回被删除的节点。
示例 - 删除当前节点
下面的示例 (removecurrentnode_example.htm) 将 XML 文档 (node.xml) 解析为 XML DOM 对象,并从父节点中删除指定的节点 <ContactNo>。
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
document.write("<b>Before remove operation, total ContactNo elements: </b>");
document.write(xmlDoc.getElementsByTagName("ContactNo").length);
document.write("<br>");
x = xmlDoc.getElementsByTagName("ContactNo")[0];
x.parentNode.removeChild(x);
document.write("<b>After remove operation, total ContactNo elements: </b>");
document.write(xmlDoc.getElementsByTagName("ContactNo").length);
</script>
</body>
</html>
在上面的示例中:
x = xmlDoc.getElementsByTagName("ContactNo")[0] 获取索引为 0 的 <ContactNo> 元素。
x.parentNode.removeChild(x); 从父节点中删除索引为 0 的 <ContactNo> 元素。
执行
将此文件保存为服务器路径上的 removecurrentnode_example.htm(此文件和 node.xml 应位于服务器上的同一路径)。结果如下:
Before remove operation, total ContactNo elements: 3 After remove operation, total ContactNo elements: 2
示例 - 删除文本节点
下面的示例 (removetextNode_example.htm) 将 XML 文档 (node.xml) 解析为 XML DOM 对象,并删除指定的子节点 <FirstName>。
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
x = xmlDoc.getElementsByTagName("FirstName")[0];
document.write("<b>Text node of child node before removal is:</b> ");
document.write(x.childNodes.length);
document.write("<br>");
y = x.childNodes[0];
x.removeChild(y);
document.write("<b>Text node of child node after removal is:</b> ");
document.write(x.childNodes.length);
</script>
</body>
</html>
在上面的示例中:
x = xmlDoc.getElementsByTagName("FirstName")[0]; − 将索引为 0 的第一个 <FirstName> 元素获取到 x 中。
y = x.childNodes[0]; − 在此行中,y 保存要删除的子节点。
x.removeChild(y); − 删除指定的子节点。
执行
将此文件保存为服务器路径上的 removetextNode_example.htm(此文件和 node.xml 应位于服务器上的同一路径)。结果如下:
Text node of child node before removal is: 1 Text node of child node after removal is: 0
removeAttribute()
removeAttribute() 方法按名称删除元素的属性。
语法
使用 removeAttribute() 的语法如下:
void removeAttribute(java.lang.String name) throws DOMException
其中,
name − 要删除的属性的名称。
示例
下面的示例 (removeelementattribute_example.htm) 将 XML 文档 (node.xml) 解析为 XML DOM 对象,并删除指定的属性节点。
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
x = xmlDoc.getElementsByTagName('Employee');
document.write(x[1].getAttribute('category'));
document.write("<br>");
x[1].removeAttribute('category');
document.write(x[1].getAttribute('category'));
</script>
</body>
</html>
在上面的示例中:
document.write(x[1].getAttribute('category')); − 调用索引为 1 的属性 category 的值。
x[1].removeAttribute('category'); − 删除属性值。
执行
将此文件保存为服务器路径上的 removeelementattribute_example.htm(此文件和 node.xml 应位于服务器上的同一路径)。结果如下:
Non-Technical null
XML DOM - 克隆节点
本章将讨论 XML DOM 对象上的 克隆节点 操作。克隆节点操作用于创建指定节点的副本。cloneNode() 用于此操作。
cloneNode()
此方法返回此节点的副本,即充当节点的通用复制构造函数。副本节点没有父节点 (parentNode 为 null) 也没有用户数据。
语法
cloneNode() 方法具有以下语法:
Node cloneNode(boolean deep)
deep − 如果为 true,则递归克隆指定节点下的子树;如果为 false,则仅克隆节点本身(及其属性,如果它是元素)。
此方法返回副本节点。
示例
下面的示例 (clonenode_example.htm) 将 XML 文档 (node.xml) 解析为 XML DOM 对象,并创建第一个 Employee 元素的深层副本。
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
x = xmlDoc.getElementsByTagName('Employee')[0];
clone_node = x.cloneNode(true);
xmlDoc.documentElement.appendChild(clone_node);
firstname = xmlDoc.getElementsByTagName("FirstName");
lastname = xmlDoc.getElementsByTagName("LastName");
contact = xmlDoc.getElementsByTagName("ContactNo");
email = xmlDoc.getElementsByTagName("Email");
for (i = 0;i < firstname.length;i++) {
document.write(firstname[i].childNodes[0].nodeValue+'
'+lastname[i].childNodes[0].nodeValue+',
'+contact[i].childNodes[0].nodeValue+', '+email[i].childNodes[0].nodeValue);
document.write("<br>");
}
</script>
</body>
</html>
正如你在上面的示例中看到的,我们已将 cloneNode() 参数设置为 true。因此,Employee 元素下的每个子元素都被复制或克隆。
执行
将此文件保存为服务器路径上的 clonenode_example.htm(此文件和 node.xml 应位于服务器上的同一路径)。输出结果如下:
Tanmay Patil, 1234567890, tanmaypatil@xyz.com Taniya Mishra, 1234667898, taniyamishra@xyz.com Tanisha Sharma, 1234562350, tanishasharma@xyz.com Tanmay Patil, 1234567890, tanmaypatil@xyz.com
你会注意到,第一个 Employee 元素被完整克隆。
DOM - 节点对象
Node 接口是整个文档对象模型的主要数据类型。节点用于表示整个文档树中的单个 XML 元素。
节点可以是任何类型的节点,例如属性节点、文本节点或任何其他节点。属性 nodeName、nodeValue 和 attributes 作为一种机制包含在内,用于在不向下转换为特定派生接口的情况下获取节点信息。
属性
下表列出了 Node 对象的属性:
| Attribute | 类型 | 描述 |
|---|---|---|
| attributes | NamedNodeMap | 这是 NamedNodeMap 类型,包含此节点的属性(如果它是元素),否则为 null。此属性已被移除。请参考 规范 |
| baseURI | DOMString | 用于指定节点的绝对基本 URI。 |
| childNodes | NodeList | 这是一个 NodeList,包含此节点的所有子节点。如果没有子节点,则这是一个不包含任何节点的 NodeList。 |
| firstChild | Node | 指定节点的第一个子节点。 |
| lastChild | Node | 指定节点的最后一个子节点。 |
| localName | DOMString | 用于指定节点局部名称。此属性已被移除。请参考 规范。 |
| namespaceURI | DOMString | 指定节点的命名空间 URI。此属性已被移除。请参考 规范 |
| nextSibling | Node | 返回紧跟在此节点后的节点。如果没有这样的节点,则返回 null。 |
| nodeName | DOMString | 此节点的名称,取决于其类型。 |
| nodeType | 无符号短整型 | 表示底层对象类型的代码。 |
| nodeValue | DOMString | 用于指定节点的值,取决于其类型。 |
| ownerDocument | Document | 指定与节点关联的 Document 对象。 |
| parentNode | Node | 此属性指定节点的父节点。 |
| prefix | DOMString | 此属性返回节点的命名空间前缀。此属性已被移除。请参考 规范 |
| previousSibling | Node | 指定紧在此节点之前的节点。 |
| textContent | DOMString | 指定节点的文本内容。 |
节点类型
我们已列出节点类型如下:
- ELEMENT_NODE
- ATTRIBUTE_NODE
- ENTITY_NODE
- ENTITY_REFERENCE_NODE
- DOCUMENT_FRAGMENT_NODE
- TEXT_NODE
- CDATA_SECTION_NODE
- COMMENT_NODE
- PROCESSING_INSTRUCTION_NODE
- DOCUMENT_NODE
- DOCUMENT_TYPE_NODE
- NOTATION_NODE
方法
下表列出了不同的 Node 对象方法:
| 序号 | 方法和描述 |
|---|---|
| 1 | appendChild(Node newChild) 此方法在指定元素节点的最后一个子节点之后添加一个节点。它返回添加的节点。 |
| 2 | cloneNode(boolean deep) 此方法用于在派生类中被重写时创建重复节点。它返回重复的节点。 |
| 3 | compareDocumentPosition(Node other) 此方法用于根据文档顺序比较当前节点相对于指定节点的位置。返回 无符号短整型,说明节点相对于参考节点的位置。 |
| 4 | getFeature(DOMString feature, DOMString version) 返回实现指定功能和版本的专用 API 的 DOM 对象(如果有),如果没有对象则返回 null。此属性已被移除。请参考 规范。 |
| 5 | getUserData(DOMString key) 检索此节点上与某个键关联的对象。必须首先通过调用 setUserData 和相同的键将对象设置为此节点。返回与此节点上给定键关联的 DOMUserData,如果不存在则返回 null。此方法已被移除。请参考 规范。 |
| 6 | hasAttributes() 返回此节点(如果它是元素)是否具有任何属性。如果指定节点中存在任何属性,则返回 true;否则返回 false。此方法已被移除。请参考 规范。 |
| 7 | hasChildNodes() 返回此节点是否具有任何子节点。如果当前节点具有子节点,则此方法返回 true,否则返回 false。 |
| 8 | insertBefore(Node newChild, Node refChild) 此方法用于将新节点作为此节点的子节点插入,直接位于此节点的现有子节点之前。它返回正在插入的节点。 |
| 9 | isDefaultNamespace(DOMString namespaceURI) 此方法接受命名空间 URI 作为参数,如果命名空间是给定节点上的默认命名空间,则返回值为 true 的 布尔值;否则返回 false。 |
| 10 | isEqualNode(Node arg) 此方法测试两个节点是否相等。如果节点相等,则返回 true;否则返回 false。 |
| 11 | isSameNode(Node other) 此方法返回当前节点是否与给定节点相同。如果节点相同,则返回 true;否则返回 false。此方法已被移除。请参考 规范。 |
| 12 | isSupported(DOMString feature, DOMString version) 此方法返回当前节点是否支持指定的 DOM 模块。如果此节点上支持指定的特性,则返回 true;否则返回 false。此方法已被移除。请参考 规范。 |
| 13 | lookupNamespaceURI(DOMString prefix) 此方法获取与命名空间前缀关联的命名空间的 URI。 |
| 14 | lookupPrefix(DOMString namespaceURI) 此方法返回当前命名空间中为命名空间 URI 定义的最接近的前缀。如果找到关联的命名空间前缀,则返回该前缀;否则返回 null。 |
| 15 | normalize()
规范化添加所有文本节点,包括定义规范形式的属性节点,其中包含元素、注释、处理指令、CDATA 节和实体引用的节点结构将文本节点分开,即没有相邻的文本节点或空文本节点。 |
| 16 | removeChild(Node oldChild) 此方法用于从当前节点中移除指定的子节点。它返回被移除的节点。 |
| 17 | replaceChild(Node newChild, Node oldChild) 此方法用于将旧子节点替换为新节点。它返回被替换的节点。 |
| 18 | setUserData(DOMString key, DOMUserData data, UserDataHandler handler) 此方法将对象与此节点上的键关联。稍后可以通过调用 getUserData 和相同的键从此节点检索该对象。它返回先前与此节点上给定键关联的 DOMUserData。此方法已被移除。请参考 规范。 |
DOM - 节点列表对象
NodeList 对象指定有序节点集合的抽象。NodeList 中的项目可以通过整数索引访问,从 0 开始。
属性
下表列出了 NodeList 对象的属性:
| Attribute | 类型 | 描述 |
|---|---|---|
| length | 无符号长整数 | 它给出节点列表中节点的数量。 |
方法
以下是 NodeList 对象的唯一方法:
| 序号 | 方法和描述 |
|---|---|
| 1 |
item()
它返回集合中的第 index 个项目。如果 index 大于或等于列表中节点的数量,则返回 null。 |
DOM - 命名节点映射对象
NamedNodeMap 对象用于表示可以通过名称访问的节点集合。
属性
下表列出了 NamedNodeMap 对象的属性:
| Attribute | 类型 | 描述 |
|---|---|---|
| length | 无符号长整数 | 它给出此映射中节点的数量。有效的子节点索引范围是 0 到 length-1(包含)。 |
方法
下表列出了 NamedNodeMap 对象的方法:
| 序号 | 方法和描述 |
|---|---|
| 1 | getNamedItem () 检索按名称指定的节点。 |
| 2 | getNamedItemNS () 检索按局部名称和命名空间 URI 指定的节点。 |
| 3 | item () 返回映射中的第 index 个项目。如果 index 大于或等于此映射中节点的数量,则返回 null。 |
| 4 | removeNamedItem () 移除按名称指定的节点。 |
| 5 | removeNamedItemNS () 移除按局部名称和命名空间 URI 指定的节点。 |
| 6 | setNamedItem () 使用其 nodeName 属性添加节点。如果此映射中已存在具有该名称的节点,则将其替换为新的节点。 |
| 7 | setNamedItemNS () 使用其 namespaceURI 和 localName 添加节点。如果此映射中已存在具有该命名空间 URI 和该局部名称的节点,则将其替换为新的节点。用自身替换节点无效。 |
DOM - DOMImplementation 对象
DOMImplementation 对象提供许多方法来执行独立于文档对象模型任何特定实例的操作。
方法
下表列出了 DOMImplementation 对象的方法:
| 序号 | 方法和描述 |
|---|---|
| 1 | createDocument(namespaceURI, qualifiedName, doctype) 它创建指定类型的 DOM 文档对象及其文档元素。 |
| 2 | createDocumentType(qualifiedName, publicId, systemId) 它创建一个空的 DocumentType 节点。 |
| 3 | getFeature(feature, version) 此方法返回一个专门的对象,该对象实现指定特性和版本的专门 API。此方法已被移除。请参考 规范。 |
| 4 | hasFeature(feature, version)
此方法测试 DOM 实现是否实现特定特性和版本。 |
DOM - DocumentType 对象
DocumentType 对象是访问文档数据的关键,在文档中,doctype 属性可以具有 null 值或 DocumentType 对象值。这些 DocumentType 对象充当对 XML 文档中描述的实体的接口。
属性
下表列出了 DocumentType 对象的属性:
| Attribute | 类型 | 描述 |
|---|---|---|
| name | DOMString | 它返回 DTD 的名称,该名称紧跟在 !DOCTYPE 关键字之后。 |
| entities | NamedNodeMap | 它返回一个 NamedNodeMap 对象,其中包含在 DTD 中声明的外部和内部通用实体。 |
| notations | NamedNodeMap | 它返回一个包含在 DTD 中声明的符号的 NamedNodeMap。 |
| internalSubset | DOMString | 它将内部子集作为字符串返回,如果没有则返回 null。此属性已被移除。请参考 规范。 |
| publicId | DOMString | 它返回外部子集的公共标识符。 |
| systemId | DOMString | 它返回外部子集的系统标识符。这可以是绝对 URI,也可以不是。 |
方法
DocumentType 继承自其父节点 Node 的方法,并实现 ChildNode 接口。
DOM - ProcessingInstruction 对象
ProcessingInstruction 提供应用程序特定的信息,这些信息通常包含在 XML 文档的序言部分。
处理指令 (PI) 可用于将信息传递给应用程序。PI 可以出现在文档中标记之外的任何位置。它们可以出现在序言中,包括文档类型定义 (DTD),在文本内容中,或文档之后。
PI 以特殊的标记 <? 开始,以 ?> 结束。在遇到字符串 ?> 后,内容的处理立即结束。
属性
下表列出了 ProcessingInstruction 对象的属性:
DOM - 实体对象
Entity 接口表示 XML 文档中已知的实体,无论是已解析的还是未解析的。从 Node 继承的 nodeName 属性包含实体的名称。
Entity 对象没有任何父节点,并且其所有后继节点都是只读的。
属性
下表列出了 Entity 对象的属性:
| Attribute | 类型 | 描述 |
|---|---|---|
| inputEncoding | DOMString | 这指定外部已解析实体使用的编码。如果它是内部子集中的实体,或者未知,则其值为 null。 |
| notationName | DOMString | 对于未解析的实体,它给出符号的名称,对于已解析的实体,其值为 null。 |
| publicId | DOMString | 它给出与实体关联的公共标识符的名称。 |
| systemId | DOMString | 它给出与实体关联的系统标识符的名称。 |
| xmlEncoding | DOMString | 它给出作为外部已解析实体文本声明一部分包含的 xml 编码,否则为 null。 |
| xmlVersion | DOMString | 它给出作为外部已解析实体文本声明一部分包含的 xml 版本,否则为 null。 |
DOM - Entity Reference 对象
EntityReference 对象是插入到 XML 文档中的一般实体引用,提供替换文本的范围。EntityReference 对象不适用于预定义实体,因为它们被认为是由 HTML 或 XML 处理器扩展的。
此接口本身没有任何属性或方法,但继承自 Node。
DOM - 符号对象
在本章中,我们将学习 XML DOM 的 Notation 对象。notation 对象属性提供了一个范围来识别具有 notation 属性的元素、特定的处理指令或非 XML 数据的格式。Node 对象的属性和方法可以在 Notation 对象上执行,因为它也被视为一个 Node。
此对象继承自 Node 的方法和属性。其 nodeName 是符号名称。没有父节点。
属性
下表列出了 Notation 对象的属性:
DOM - 元素对象
XML 元素可以定义为 XML 的构建块。元素可以充当容器,用于保存文本、元素、属性、媒体对象或所有这些。每当解析器根据良构性解析 XML 文档时,解析器都会遍历元素节点。元素节点包含其中的文本,称为文本节点。
元素对象继承节点对象的属性和方法,因为元素对象也被视为节点。除了节点对象的属性和方法外,它还具有以下属性和方法。
属性
下表列出了Element 对象的属性:
| Attribute | 类型 | 描述 |
|---|---|---|
| tagName | DOMString | 它给出指定元素的标签名称。 |
| schemaTypeInfo | TypeInfo | 它表示与此元素关联的类型信息。此项已被移除。请参考 规范。 |
方法
下表列出了 Element 对象的方法:
| 方法 | 类型 | 描述 |
|---|---|---|
| getAttribute() | DOMString | 如果指定元素存在属性,则检索该属性的值。 |
| getAttributeNS() | DOMString | 通过局部名称和命名空间 URI 检索属性值。 |
| getAttributeNode() | Attr | 从当前元素检索属性节点的名称。 |
| getAttributeNodeNS() | Attr | 通过局部名称和命名空间 URI 检索 Attr 节点。 |
| getElementsByTagName() | NodeList | 返回所有具有给定标签名称的子代元素的 NodeList,按文档顺序排列。 |
| getElementsByTagNameNS() | NodeList | 返回所有具有给定局部名称和命名空间 URI 的子代元素的 NodeList,按文档顺序排列。 |
| hasAttribute() | 布尔值 | 当在此元素上指定了具有给定名称的属性或具有默认值时返回 true,否则返回 false。 |
| hasAttributeNS() | 布尔值 | 当在此元素上指定了具有给定局部名称和命名空间 URI 的属性或具有默认值时返回 true,否则返回 false。 |
| removeAttribute() | 无返回值 | 按名称移除属性。 |
| removeAttributeNS | 无返回值 | 按局部名称和命名空间 URI 移除属性。 |
| removeAttributeNode() | Attr | 从元素中移除指定的属性节点。 |
| setAttribute() | 无返回值 | 将新的属性值设置为现有元素。 |
| setAttributeNS() | 无返回值 | 添加新的属性。如果元素上已经存在具有相同局部名称和命名空间 URI 的属性,则其前缀将更改为 qualifiedName 的前缀部分,其值将更改为 value 参数。 |
| setAttributeNode() | Attr | 将新的属性节点设置为现有元素。 |
| setAttributeNodeNS | Attr | 添加新的属性。如果元素中已经存在具有该局部名称和该命名空间 URI 的属性,则将其替换为新的属性。 |
| setIdAttribute | 无返回值 | 如果参数 isId 为 true,则此方法声明指定的属性为用户确定的 ID 属性。此项已被移除。请参考 规范。 |
| setIdAttributeNS | 无返回值 | 如果参数 isId 为 true,则此方法声明指定的属性为用户确定的 ID 属性。此项已被移除。请参考 规范。 |
DOM - 属性对象
Attr 接口表示 Element 对象中的属性。通常,属性的允许值在与文档关联的模式中定义。Attr 对象不被视为文档树的一部分,因为它们实际上并不是其描述的元素的子节点。因此,对于子节点parentNode、previousSibling 和nextSibling,属性值为null。
属性
下表列出了Attribute 对象的属性:
| Attribute | 类型 | 描述 |
|---|---|---|
| name | DOMString | 它给出属性的名称。 |
| specified | 布尔值 | 这是一个布尔值,如果属性值存在于文档中,则返回 true。 |
| value | DOMString | 返回属性的值。 |
| ownerElement | Element | 它给出与属性关联的节点,如果属性未被使用则为 null。 |
| isId | 布尔值 | 它返回属性是否已知为 ID 类型(即包含其所有者元素的标识符)。 |
DOM - CDATASection 对象
在本章中,我们将学习 XML DOM CDATASection 对象。XML 文档中存在的文本根据其声明方式进行解析或未解析。如果文本声明为解析字符数据 (PCDATA),则解析器会对其进行解析,以将 XML 文档转换为 XML DOM 对象。另一方面,如果文本声明为未解析字符数据 (CDATA),则 XML 解析器不会解析其中的文本。这些不被视为标记,也不会扩展实体。
使用 CDATASection 对象的目的是转义包含字符的文本块,否则这些字符将被视为标记。"]]>",这是 CDATA 部分中唯一识别的分隔符,它结束 CDATA 部分。
CharacterData.data 属性保存 CDATA 部分包含的文本。此接口通过 Text 接口继承CharatcterData 接口。
CDATASection 对象没有定义方法和属性。它只直接实现Text 接口。
DOM - 注释对象
在本章中,我们将学习Comment 对象。注释作为笔记或行添加到 XML 代码中,以理解其用途。注释可用于包含相关链接、信息和术语。这些注释可能出现在 XML 代码的任何位置。
comment 接口继承CharacterData 接口,表示注释的内容。
语法
XML 注释具有以下语法:
<!-------Your comment----->
注释以 <!-- 开头,以 --> 结尾。您可以在字符之间添加文本注释作为注释。您不能将一个注释嵌套在另一个注释内。
Comment 对象没有定义方法和属性。它继承其父级CharacterData 的方法和属性,并间接继承Node 的方法和属性。
DOM - XMLHttpRequest 对象
XMLHttpRequest 对象在网页的客户端和服务器端之间建立了一种媒介,许多脚本语言(如 JavaScript、JScript、VBScript 和其他 Web 浏览器)可以使用它来传输和操作 XML 数据。
使用 XMLHttpRequest 对象,可以更新网页的一部分而无需重新加载整个页面,在页面加载后请求和接收来自服务器的数据,以及向服务器发送数据。
语法
可以如下实例化 XMLHttpRequest 对象:
xmlhttp = new XMLHttpRequest();
为了处理所有浏览器,包括 IE5 和 IE6,请检查浏览器是否支持 XMLHttpRequest 对象,如下所示:
if(window.XMLHttpRequest) // for Firefox, IE7+, Opera, Safari, ... {
xmlHttp = new XMLHttpRequest();
} else if(window.ActiveXObject) // for Internet Explorer 5 or 6 {
xmlHttp = new ActiveXObject("Microsoft.XMLHTTP");
}
有关使用 XMLHttpRequest 对象加载 XML 文件的示例,请参见 此处
方法
下表列出了 XMLHttpRequest 对象的方法:
| 序号 | 方法和描述 |
|---|---|
| 1 | abort() 终止当前发出的请求。 |
| 2 | getAllResponseHeaders() 返回所有响应标头作为字符串,如果尚未收到响应则返回 null。 |
| 3 | getResponseHeader() 返回包含指定标头文本的字符串,如果尚未收到响应或响应中不存在该标头,则返回 null。 |
| 4 | open(method,url,async,uname,pswd) 它与 Send 方法结合使用,将请求发送到服务器。open 方法指定以下参数:
|
| 5 | send(string) 它用于发送与 Open 方法一起工作的请求。 |
| 6 | setRequestHeader() 标头包含发送请求的标签/值对。 |
属性
下表列出了 XMLHttpRequest 对象的属性:
| 序号 | 属性 & 说明 |
|---|---|
| 1 | onreadystatechange 这是一个基于事件的属性,在每次状态更改时都会设置。 |
| 2 | readyState 这描述了 XMLHttpRequest 对象的当前状态。readyState 属性有五种可能的状态:
|
| 3 | responseText 当服务器的响应是文本文件时,使用此属性。 |
| 4 | responseXML 当服务器的响应是 XML 文件时,使用此属性。 |
| 5 | status 将 Http 请求对象的状体作为数字给出。例如,“404”或“200”。 |
| 6 | statusText 将 Http 请求对象的状体作为字符串给出。例如,“未找到”或“确定”。 |
示例
node.xml 内容如下:
<?xml version = "1.0"?>
<Company>
<Employee category = "Technical">
<FirstName>Tanmay</FirstName>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
<Email>tanmaypatil@xyz.com</Email>
</Employee>
<Employee category = "Non-Technical">
<FirstName>Taniya</FirstName>
<LastName>Mishra</LastName>
<ContactNo>1234667898</ContactNo>
<Email>taniyamishra@xyz.com</Email>
</Employee>
<Employee category = "Management">
<FirstName>Tanisha</FirstName>
<LastName>Sharma</LastName>
<ContactNo>1234562350</ContactNo>
<Email>tanishasharma@xyz.com</Email>
</Employee>
</Company>
检索资源文件的特定信息
以下示例演示如何使用 getResponseHeader() 方法和 readState 属性检索资源文件的特定信息。
<!DOCTYPE html>
<html>
<head>
<meta http-equiv = "content-type" content = "text/html; charset = iso-8859-2" />
<script>
function loadXMLDoc() {
var xmlHttp = null;
if(window.XMLHttpRequest) // for Firefox, IE7+, Opera, Safari, ... {
xmlHttp = new XMLHttpRequest();
}
else if(window.ActiveXObject) // for Internet Explorer 5 or 6 {
xmlHttp = new ActiveXObject("Microsoft.XMLHTTP");
}
return xmlHttp;
}
function makerequest(serverPage, myDiv) {
var request = loadXMLDoc();
request.open("GET", serverPage);
request.send(null);
request.onreadystatechange = function() {
if (request.readyState == 4) {
document.getElementById(myDiv).innerHTML = request.getResponseHeader("Content-length");
}
}
}
</script>
</head>
<body>
<button type = "button" onclick="makerequest('/dom/node.xml', 'ID')">Click me to get the specific ResponseHeader</button>
<div id = "ID">Specific header information is returned.</div>
</body>
</html>
执行
将此文件另存为服务器路径上的elementattribute_removeAttributeNS.htm(此文件和 node_ns.xml 应位于服务器上的同一路径)。我们将得到如下所示的输出:
Before removing the attributeNS: en After removing the attributeNS: null
检索资源文件的标头信息
以下示例演示如何使用 getAllResponseHeaders() 方法和 readyState 属性检索资源文件的标头信息。
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="content-type" content="text/html; charset=iso-8859-2" />
<script>
function loadXMLDoc() {
var xmlHttp = null;
if(window.XMLHttpRequest) // for Firefox, IE7+, Opera, Safari, ... {
xmlHttp = new XMLHttpRequest();
} else if(window.ActiveXObject) // for Internet Explorer 5 or 6 {
xmlHttp = new ActiveXObject("Microsoft.XMLHTTP");
}
return xmlHttp;
}
function makerequest(serverPage, myDiv) {
var request = loadXMLDoc();
request.open("GET", serverPage);
request.send(null);
request.onreadystatechange = function() {
if (request.readyState == 4) {
document.getElementById(myDiv).innerHTML = request.getAllResponseHeaders();
}
}
}
</script>
</head>
<body>
<button type = "button" onclick = "makerequest('/dom/node.xml', 'ID')">
Click me to load the AllResponseHeaders</button>
<div id = "ID"></div>
</body>
</html>
执行
将此文件另存为服务器路径上的http_allheader.html(此文件和 node.xml 应位于服务器上的同一路径)。我们将得到如下所示的输出(取决于浏览器):
Date: Sat, 27 Sep 2014 07:48:07 GMT Server: Apache Last-Modified:
Wed, 03 Sep 2014 06:35:30 GMT Etag: "464bf9-2af-50223713b8a60" Accept-Ranges: bytes Vary: Accept-Encoding,User-Agent
Content-Encoding: gzip Content-Length: 256 Content-Type: text/xml
DOM - DOMException 对象
DOMException 表示在使用方法或属性时发生的异常事件。
属性
下表列出了 DOMException 对象的属性
| 序号 | 属性 & 说明 |
|---|---|
| 1 | name 返回一个 DOMString,其中包含与错误常量关联的字符串之一(如下表所示)。 |
错误类型
| 序号 | 类型 & 说明 |
|---|---|
| 1 | IndexSizeError 索引不在允许的范围内。例如,这可以由 Range 对象引发。(旧代码值:1 和旧常量名称:INDEX_SIZE_ERR) |
| 2 | HierarchyRequestError 节点树层次结构不正确。(旧代码值:3 和旧常量名称:HIERARCHY_REQUEST_ERR) |
| 3 | WrongDocumentError 对象在错误的文档中。(旧代码值:4 和旧常量名称:WRONG_DOCUMENT_ERR) |
| 4 | InvalidCharacterError 字符串包含无效字符。(旧代码值:5 和旧常量名称:INVALID_CHARACTER_ERR) |
| 5 | NoModificationAllowedError 无法修改对象。(旧代码值:7 和旧常量名称:NO_MODIFICATION_ALLOWED_ERR) |
| 6 | NotFoundError 在此找不到对象。(旧代码值:8 和旧常量名称:NOT_FOUND_ERR) |
| 7 | NotSupportedError 不支持此操作。(旧代码值:9 和旧常量名称:NOT_SUPPORTED_ERR) |
| 8 | InvalidStateError 对象处于无效状态。(旧代码值:11 和旧常量名称:INVALID_STATE_ERR) |
| 9 | SyntaxError 字符串与预期模式不匹配。(旧代码值:12 和旧常量名称:SYNTAX_ERR) |
| 10 | InvalidModificationError 无法以这种方式修改对象。(旧代码值:13 和旧常量名称:INVALID_MODIFICATION_ERR) |
| 11 | 命名空间错误 XML 的命名空间不允许此操作。(旧代码值:14,旧常量名称:NAMESPACE_ERR) |
| 12 | 无效访问错误 对象不支持此操作或参数。(旧代码值:15,旧常量名称:INVALID_ACCESS_ERR) |
| 13 | 类型不匹配错误 对象的类型与预期类型不匹配。(旧代码值:17,旧常量名称:TYPE_MISMATCH_ERR)此值已弃用,现在会引发 JavaScript TypeError 异常,而不是带有此值的 DOMException。 |
| 14 | 安全错误 此操作不安全。(旧代码值:18,旧常量名称:SECURITY_ERR) |
| 15 | 网络错误 发生网络错误。(旧代码值:19,旧常量名称:NETWORK_ERR) |
| 16 | 中止错误 操作已中止。(旧代码值:20,旧常量名称:ABORT_ERR) |
| 17 | URL 不匹配错误 给定的 URL 与另一个 URL 不匹配。(旧代码值:21,旧常量名称:URL_MISMATCH_ERR) |
| 18 | 配额超出错误 配额已超出。(旧代码值:22,旧常量名称:QUOTA_EXCEEDED_ERR) |
| 19 | 超时错误 操作超时。(旧代码值:23,旧常量名称:TIMEOUT_ERR) |
| 20 | 无效节点类型错误 此节点不正确,或其祖先节点对于此操作不正确。(旧代码值:24,旧常量名称:INVALID_NODE_TYPE_ERR) |
| 21 | 数据克隆错误 无法克隆对象。(旧代码值:25,旧常量名称:DATA_CLONE_ERR) |
| 22 | 编码错误 编码或解码操作失败(无旧代码值和常量名称)。 |
| 23 | 不可读错误 输入/输出读取操作失败(无旧代码值和常量名称)。 |
示例
以下示例演示了使用格式不正确的 XML 文档如何导致 DOMException。
error.xml 内容如下:
<?xml version = "1.0" encoding = "UTF-8" standalone = "no" ?>
<Company id = "companyid">
<Employee category = "Technical" id = "firstelement" type = "text/html">
<FirstName>Tanmay</first>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
<Email>tanmaypatil@xyz.com</Email>
</Employee>
</Company>
以下示例演示了name 属性的用法:
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
try {
xmlDoc = loadXMLDoc("/dom/error.xml");
var node = xmlDoc.getElementsByTagName("to").item(0);
var refnode = node.nextSibling;
var newnode = xmlDoc.createTextNode('That is why you fail.');
node.insertBefore(newnode, refnode);
} catch(err) {
document.write(err.name);
}
</script>
</body>
</html>
执行
将此文件另存为服务器路径上的domexcption_name.html(此文件和 error.xml 应位于服务器上的同一路径)。我们将获得如下所示的输出:
TypeError