
 数据结构
数据结构 网络
网络 关系型数据库管理系统 (RDBMS)
关系型数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 编程
C 编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP鸢尾花数据集的探索性数据分析
介绍
在机器学习和数据科学中,探索性数据分析是检查数据集并总结其主要特征的过程。它可能包括可视化方法来更好地表示这些特征或对数据集有一个总体的了解。它是数据科学生命周期中非常重要的一步,通常会消耗一定的时间。
在本文中,我们将通过探索性数据分析了解鸢尾花数据集的一些特征。
鸢尾花数据集
鸢尾花数据集非常简单,通常被称为“Hello World”。数据集包含三种不同花卉(山鸢尾、维吉尼亚鸢尾和变色鸢尾)的 4 个特征。这些特征是萼片长度、萼片宽度、花瓣长度和花瓣宽度。数据集包含 150 个数据点,每个物种 50 个数据点。
鸢尾花数据集上的 EDA
首先,让我们使用 pandas 从 CSV 文件“iris_csv.csv”加载数据集,并对其进行总体概述。
数据集可以从以下链接下载。
https://datahub.io/machine-learning/iris/r/iris.csv
代码实现
示例 1
import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline df = pd.read_csv("/content/iris_csv.csv") df.head()
萼片长度 |
萼片宽度 |
花瓣长度 |
花瓣宽度 |
类别 |
|
|---|---|---|---|---|---|
0 |
5.1 |
3.5 |
1.4 |
0.2 |
山鸢尾 |
1 |
4.9 |
3.0 |
1.4 |
0.2 |
山鸢尾 |
3 |
4.6 |
3.1 |
1.5 |
0.2 |
山鸢尾 |
4 |
5.0 |
3.6 |
1.4 |
0.2 |
山鸢尾 |
示例 2
df.info() RangeIndex: 150 entries, 0 to 149 Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 sepallength 150 non-null float64 1 sepalwidth 150 non-null float64 2 petallength 150 non-null float64 3 petalwidth 150 non-null float64 4 class 150 non-null object dtypes: float64(4), object(1) memory usage: 6.0+ KB df.shape (150, 5) ## Statistics about dataset df.describe()
萼片长度 |
萼片宽度 |
花瓣长度 |
花瓣宽度 |
|
|---|---|---|---|---|
计数 |
150.000000 |
150.000000 |
150.000000 |
150.000000 |
平均值 |
5.843333 |
3.054000 |
3.758667 |
1.198667 |
标准差 |
0.828066 |
0.433594 |
1.764420 |
0.763161 |
最小值 |
4.300000 |
2.000000 |
1.000000 |
0.100000 |
25% |
5.100000 |
2.800000 |
1.600000 |
0.300000 |
50% |
5.800000 |
3.000000 |
4.350000 |
1.300000 |
最大值 |
7.900000 |
4.400000 |
6.900000 |
2.500000 |
示例 3
## checking for null values df.isnull().sum() sepallength 0 sepalwidth 0 petallength 0 petalwidth 0 class 0 dtype: int64 ## Univariate analysis df.groupby('class').agg(['mean', 'median']) # passing a list of recognized strings df.groupby('class').agg([np.mean, np.median])
| 萼片长度 | 萼片宽度 | 花瓣长度 | 花瓣宽度 | |||||
|---|---|---|---|---|---|---|---|---|
| 平均值 | 中位数 | 平均值 | 中位数 | 平均值 | 中位数 | 平均值 | 中位数 | |
| 类别 | ||||||||
| 山鸢尾 | 5.006 | 5.0 | 3.418 | 3.4 | 1.464 | 1.50 | 0.244 | 0.2 |
| 变色鸢尾 | 5.936 | 5.9 | 2.770 | 2.8 | 4.260 | 4.35 | 1.326 | 1.3 |
| 维吉尼亚鸢尾 | 6.588 | 6.5 | 2.974 | 3.0 | 5.552 | 5.55 | 2.026 | 2.0 |
示例 4
## Box plot plt.figure(figsize=(8,4)) sns.boxplot(x='class',y='sepalwidth',data=df ,palette='YlGnBu')
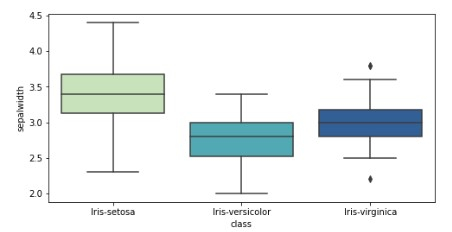
示例 5
## Distribution of particular species sns.distplot(a=df['petalwidth'], bins=40, color='b') plt.title('petal width distribution plot')
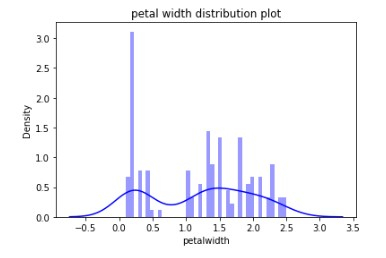
示例 6
## count of number of observation of each species sns.countplot(x='class',data=df)
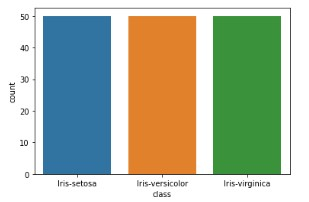
示例 7
## Correlation map using a heatmap matrix sns.heatmap(df.corr(), linecolor='white', linewidths=1)
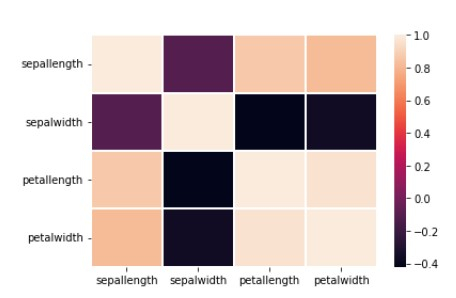
示例 8
## Multivariate analysis – analyis between two or more variable or features ## Scatter plot to see the relation between two or more features like sepal length, petal length,etc axis = plt.axes() axis.scatter(df.sepallength, df.sepalwidth) axis.set(xlabel='Sepal_Length (cm)', ylabel='Sepal_Width (cm)', title='Sepal-Length vs Width');
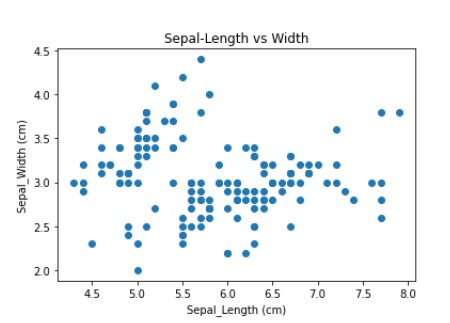
示例 9
sns.scatterplot(x='sepallength', y='sepalwidth', hue='class', data=df, plt.show()
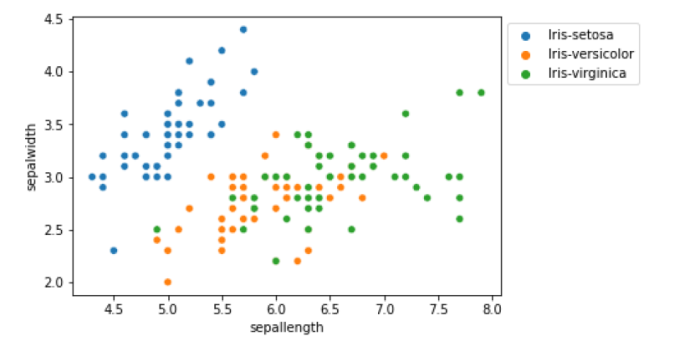
示例 10
## From the above graph we can see that # Iris-virginica has a longer sepal length while Iris-setosa has larger sepal width # For setosa sepal width is more than sepal length ## Below is the Frequency histogram plot of all features axis = df.plot.hist(bins=30, alpha=0.5) axis.set_xlabel('Size in cm');
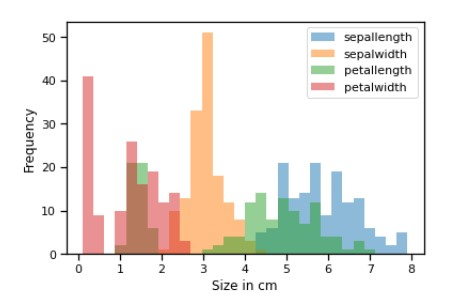
示例 11
# From the above graph we can see that sepalwidth is longer than any other feature followed by petalwidth ## examining correlation sns.pairplot(df, hue='class')

示例 12
figure, ax = plt.subplots(2, 2, figsize=(8,8)) ax[0,0].set_title("sepallength") ax[0,0].hist(df['sepallength'], bins=8) ax[0,1].set_title("sepalwidth") ax[0,1].hist(df['sepalwidth'], bins=6); ax[1,0].set_title("petallength") ax[1,0].hist(df['petallength'], bins=5); ax[1,1].set_title("petalwidth") ax[1,1].hist(df['petalwidth'], bins=5);
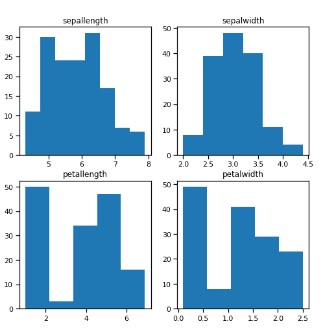
示例 13
# From the above plot we can see that – # - Sepal length highest freq lies between 5.5 cm to 6 cm which is 30-35 cm # - Petal length highest freq lies between 1 cm to 2 cm which is 50 cm # - Sepal width highest freq lies between 3 cm to 3.5 cm which is 70 cm # - Petal width highest freq lies between 0 cm to 0.5 cm which is 40-45 cm
结论
探索性数据分析被数据科学家和分析师广泛使用。它揭示了给定数据的许多特征、其分布以及它如何有用。

5K+ 浏览量
