- Gensim 教程
- Gensim - 首页
- Gensim - 简介
- Gensim - 快速入门
- Gensim - 文档和语料库
- Gensim - 向量和模型
- Gensim - 创建词典
- 创建词袋 (BoW) 语料库
- Gensim - 变换
- Gensim - 创建 TF-IDF 矩阵
- Gensim - 主题建模
- Gensim - 创建 LDA 主题模型
- Gensim - 使用 LDA 主题模型
- Gensim - 创建 LDA Mallet 模型
- Gensim - 文档和 LDA 模型
- Gensim - 创建 LSI 和 HDP 主题模型
- Gensim - 词嵌入开发
- Gensim - Doc2Vec 模型
- Gensim 有用资源
- Gensim - 快速指南
- Gensim - 有用资源
- Gensim - 讨论
Gensim - 词嵌入开发
本章将帮助我们理解如何在 Gensim 中开发词嵌入。
词嵌入是一种表示单词和文档的方法,它是一种密集的文本向量表示,其中具有相同含义的单词具有相似的表示。以下是词嵌入的一些特征:
它是一类技术,将单个单词表示为预定义向量空间中的实值向量。
这项技术通常被归入深度学习 (DL) 领域,因为每个单词都映射到一个向量,并且向量的值以与神经网络 (NN) 相同的方式学习。
词嵌入技术的主要方法是为每个单词提供密集的分布式表示。
不同的词嵌入方法/算法
如上所述,词嵌入方法/算法从文本语料库中学习实值向量表示。这个学习过程可以使用 NN 模型用于文档分类等任务,或者是一个无监督的过程,例如文档统计。在这里,我们将讨论两种可以用来从文本中学习词嵌入的方法/算法:
Google 的 Word2Vec
Word2Vec 由 Tomas Mikolov 等人在 Google 于 2013 年开发,是一种有效地从文本语料库学习词嵌入的统计方法。它实际上是为使基于 NN 的词嵌入训练更高效而开发的。它已成为词嵌入的事实标准。
Word2Vec 的词嵌入涉及对学习到的向量的分析以及对单词表示的向量数学的探索。以下是可以用作 Word2Vec 方法一部分的两种不同的学习方法:
- CBoW(连续词袋)模型
- 连续 Skip-Gram 模型
斯坦福大学的 GloVe
GloVe(用于单词表示的全局向量)是 Word2Vec 方法的扩展。它由斯坦福大学的 Pennington 等人开发。GloVe 算法是两者的混合:
- 矩阵分解技术的全局统计,例如 LSA(潜在语义分析)
- Word2Vec 中基于局部上下文的学习。
如果我们谈论它的工作原理,那么 GloVe 并没有使用窗口来定义局部上下文,而是使用跨整个文本语料库的统计数据来构建显式的词共现矩阵。
开发 Word2Vec 嵌入
在这里,我们将使用 Gensim 开发 Word2Vec 嵌入。为了使用 Word2Vec 模型,Gensim 为我们提供了Word2Vec 类,可以从models.word2vec导入。为了实现它,word2vec 需要大量的文本,例如整个亚马逊评论语料库。但是在这里,我们将把这个原理应用于小型内存文本。
实现示例
首先,我们需要从 gensim.models 中导入 Word2Vec 类,如下所示:
from gensim.models import Word2Vec
接下来,我们需要定义训练数据。与其采用大型文本文件,我们使用一些句子来实现这个原理。
sentences = [ ['this', 'is', 'gensim', 'tutorial', 'for', 'free'], ['this', 'is', 'the', 'tutorials' 'point', 'website'], ['you', 'can', 'read', 'technical','tutorials', 'for','free'], ['we', 'are', 'implementing','word2vec'], ['learn', 'full', 'gensim', 'tutorial'] ]
提供训练数据后,我们需要训练模型。可以按如下方式完成:
model = Word2Vec(sentences, min_count=1)
我们可以总结模型如下:
print(model)
我们可以总结词汇表如下:
words = list(model.wv.vocab) print(words)
接下来,让我们访问一个单词的向量。我们正在对单词“tutorial”进行操作。
print(model['tutorial'])
接下来,我们需要保存模型:
model.save('model.bin')
接下来,我们需要加载模型:
new_model = Word2Vec.load('model.bin')
最后,打印保存的模型如下:
print(new_model)
完整的实现示例
from gensim.models import Word2Vec
sentences = [
['this', 'is', 'gensim', 'tutorial', 'for', 'free'],
['this', 'is', 'the', 'tutorials' 'point', 'website'],
['you', 'can', 'read', 'technical','tutorials', 'for','free'],
['we', 'are', 'implementing','word2vec'],
['learn', 'full', 'gensim', 'tutorial']
]
model = Word2Vec(sentences, min_count=1)
print(model)
words = list(model.wv.vocab)
print(words)
print(model['tutorial'])
model.save('model.bin')
new_model = Word2Vec.load('model.bin')
print(new_model)
输出
Word2Vec(vocab=20, size=100, alpha=0.025) [ 'this', 'is', 'gensim', 'tutorial', 'for', 'free', 'the', 'tutorialspoint', 'website', 'you', 'can', 'read', 'technical', 'tutorials', 'we', 'are', 'implementing', 'word2vec', 'learn', 'full' ] [ -2.5256255e-03 -4.5352755e-03 3.9024993e-03 -4.9509313e-03 -1.4255195e-03 -4.0217536e-03 4.9407515e-03 -3.5925603e-03 -1.1933431e-03 -4.6682903e-03 1.5440651e-03 -1.4101702e-03 3.5070938e-03 1.0914479e-03 2.3334436e-03 2.4452661e-03 -2.5336299e-04 -3.9676363e-03 -8.5054158e-04 1.6443320e-03 -4.9968651e-03 1.0974540e-03 -1.1123562e-03 1.5393364e-03 9.8941079e-04 -1.2656028e-03 -4.4471184e-03 1.8309267e-03 4.9302122e-03 -1.0032534e-03 4.6892050e-03 2.9563988e-03 1.8730218e-03 1.5343715e-03 -1.2685956e-03 8.3664013e-04 4.1721235e-03 1.9445885e-03 2.4097660e-03 3.7517555e-03 4.9687522e-03 -1.3598346e-03 7.1032363e-04 -3.6595813e-03 6.0000515e-04 3.0872561e-03 -3.2115565e-03 3.2270295e-03 -2.6354722e-03 -3.4988276e-04 1.8574356e-04 -3.5757164e-03 7.5391348e-04 -3.5205986e-03 -1.9795434e-03 -2.8321696e-03 4.7155009e-03 -4.3349937e-04 -1.5320212e-03 2.7013756e-03 -3.7055744e-03 -4.1658725e-03 4.8034848e-03 4.8594419e-03 3.7129463e-03 4.2385766e-03 2.4612297e-03 5.4920948e-04 -3.8912550e-03 -4.8226118e-03 -2.2763973e-04 4.5571579e-03 -3.4609400e-03 2.7903817e-03 -3.2709218e-03 -1.1036445e-03 2.1492650e-03 -3.0384419e-04 1.7709908e-03 1.8429896e-03 -3.4038599e-03 -2.4872608e-03 2.7693063e-03 -1.6352943e-03 1.9182395e-03 3.7772327e-03 2.2769428e-03 -4.4629495e-03 3.3151123e-03 4.6509290e-03 -4.8521687e-03 6.7615538e-04 3.1034781e-03 2.6369948e-05 4.1454583e-03 -3.6932561e-03 -1.8769916e-03 -2.1958587e-04 6.3395966e-04 -2.4969708e-03 ] Word2Vec(vocab=20, size=100, alpha=0.025)
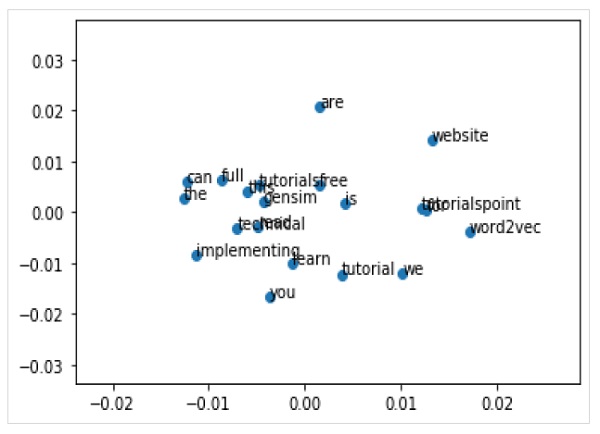
词嵌入的可视化
我们还可以通过可视化来探索词嵌入。这可以通过使用经典的投影方法(如 PCA)将高维词向量简化为二维图来完成。简化后,我们就可以将它们绘制到图表上。
使用 PCA 绘制词向量
首先,我们需要从训练好的模型中检索所有向量,如下所示:
Z = model[model.wv.vocab]
接下来,我们需要使用 PCA 类创建一个词向量的二维 PCA 模型,如下所示:
pca = PCA(n_components=2) result = pca.fit_transform(Z)
现在,我们可以使用 matplotlib 绘制结果投影,如下所示:
Pyplot.scatter(result[:,0],result[:,1])
我们还可以使用单词本身在图表上注释点。使用 matplotlib 绘制结果投影,如下所示:
words = list(model.wv.vocab) for i, word in enumerate(words): pyplot.annotate(word, xy=(result[i, 0], result[i, 1]))
完整的实现示例
from gensim.models import Word2Vec from sklearn.decomposition import PCA from matplotlib import pyplot sentences = [ ['this', 'is', 'gensim', 'tutorial', 'for', 'free'], ['this', 'is', 'the', 'tutorials' 'point', 'website'], ['you', 'can', 'read', 'technical','tutorials', 'for','free'], ['we', 'are', 'implementing','word2vec'], ['learn', 'full', 'gensim', 'tutorial'] ] model = Word2Vec(sentences, min_count=1) X = model[model.wv.vocab] pca = PCA(n_components=2) result = pca.fit_transform(X) pyplot.scatter(result[:, 0], result[:, 1]) words = list(model.wv.vocab) for i, word in enumerate(words): pyplot.annotate(word, xy=(result[i, 0], result[i, 1])) pyplot.show()
输出