- Gensim 教程
- Gensim - 首页
- Gensim - 简介
- Gensim - 入门
- Gensim - 文档与语料库
- Gensim - 向量与模型
- Gensim - 创建字典
- 创建词袋 (BoW) 语料库
- Gensim - 变换
- Gensim - 创建 TF-IDF 矩阵
- Gensim - 主题建模
- Gensim - 创建 LDA 主题模型
- Gensim - 使用 LDA 主题模型
- Gensim - 创建 LDA Mallet 模型
- Gensim - 文档与 LDA 模型
- Gensim - 创建 LSI 和 HDP 主题模型
- Gensim - 开发词嵌入
- Gensim - Doc2Vec 模型
- Gensim 有用资源
- Gensim 快速指南
- Gensim - 有用资源
- Gensim - 讨论
Gensim 快速指南
Gensim - 简介
本章将帮助您了解 Gensim 的历史和特性,以及它的用途和优势。
什么是 Gensim?
Gensim = “Generate Similar” 是一个流行的开源自然语言处理 (NLP) 库,用于无监督主题建模。它使用顶尖的学术模型和现代统计机器学习来执行各种复杂的任务,例如:
- 构建文档或词向量
- 语料库
- 执行主题识别
- 执行文档比较(检索语义相似的文档)
- 分析纯文本文档的语义结构
除了执行上述复杂任务外,Gensim 使用 Python 和 Cython 实现,旨在使用数据流和增量在线算法处理大型文本集合。这使其区别于那些仅针对内存处理的机器学习软件包。
历史
2008 年,Gensim 最初是一组用于捷克数字数学的各种 Python 脚本的集合。在那里,它用于生成与特定给定文章最相似的文章的简短列表。但在 2009 年,RARE Technologies Ltd. 发布了其初始版本。然后,在 2019 年 7 月,我们获得了它的稳定版本 (3.8.0)。
各种特性
以下是 Gensim 提供的一些特性和功能:
可扩展性
Gensim 可以通过使用其增量在线训练算法轻松处理大型和 Web 规模的语料库。它本质上是可扩展的,因为不需要在任何时间点将整个输入语料库完全驻留在随机存取存储器 (RAM) 中。换句话说,其所有算法在语料库大小方面都是内存无关的。
健壮性
Gensim 本质上是健壮的,并且已经在各种系统中被各种人员和组织使用了四年多。我们可以轻松插入我们自己的输入语料库或数据流。也很容易扩展到其他向量空间算法。
平台无关性
众所周知,Python 是一种非常通用的语言,作为纯 Python 的 Gensim 可以在所有支持 Python 和 NumPy 的平台(如 Windows、Mac OS、Linux)上运行。
高效的多核实现
为了加快机器集群上的处理和检索速度,Gensim 提供了各种流行算法的高效多核实现,例如 潜在语义分析 (LSA)、潜在狄利克雷分配 (LDA)、随机投影 (RP)、分层狄利克雷过程 (HDP)。
开源和丰富的社区支持
Gensim 采用 OSI 批准的 GNU LGPL 许可证授权,允许免费用于个人和商业用途。对 Gensim 做出的任何修改都会开源,并且拥有丰富的社区支持。
Gensim 的用途
Gensim 已被用于并被引用于超过一千个商业和学术应用中。它也被各种研究论文和学生论文引用。它包括以下内容的流式并行实现:
fastText
fastText 使用神经网络进行词嵌入,是一个用于学习词嵌入和文本分类的库。它由 Facebook 的 AI 研究 (FAIR) 实验室创建。该模型基本上允许我们创建一个有监督或无监督算法来获得单词的向量表示。
Word2vec
Word2vec 用于生成词嵌入,是一组浅层和两层神经网络模型。这些模型基本上经过训练以重建单词的语言上下文。
LSA(潜在语义分析)
它是 NLP(自然语言处理)中的一种技术,允许我们分析一组文档及其包含的术语之间的关系。这是通过生成与文档和术语相关的概念集来完成的。
LDA(潜在狄利克雷分配)
它是 NLP 中的一种技术,允许通过未观察到的组来解释观测值的集合。这些未观察到的组解释了为什么数据的一些部分是相似的。这就是为什么它是一个生成式统计模型的原因。
tf-idf(词频-逆文档频率)
tf-idf,信息检索中的一个数值统计量,反映了一个词在一个语料库中的文档中的重要程度。搜索引擎经常使用它来根据用户查询对文档的相关性进行评分和排名。它还可以用于文本摘要和分类中的停用词过滤。
所有这些都将在接下来的章节中详细解释。
优势
Gensim 是一个进行主题建模的 NLP 包。Gensim 的重要优势如下:
我们可以在其他包(如 ‘scikit-learn’ 和 ‘R’)中获得主题建模和词嵌入的功能,但 Gensim 提供的构建主题模型和词嵌入的功能是无与伦比的。它还为文本处理提供了更便捷的功能。
Gensim 的另一个最重要的优点是,它允许我们处理大型文本文件,即使不将整个文件加载到内存中。
Gensim 不需要代价高昂的注释或文档的手工标记,因为它使用无监督模型。
Gensim - 入门
本章阐明了安装 Gensim 的先决条件,其核心依赖项以及有关其当前版本的信息。
先决条件
为了安装 Gensim,我们必须在计算机上安装 Python。您可以访问链接 www.python.org/downloads/ 并为您的操作系统(即 Windows 和 Linux/Unix)选择最新版本。您可以参考链接 www.tutorialspoint.com/python3/index.htm 获取关于 Python 的基本教程。Gensim 支持 Linux、Windows 和 Mac OS X。
代码依赖项
Gensim 应该在支持 Python 2.7 或 3.5+ 和 NumPy 的任何平台上运行。它实际上依赖于以下软件:
Python
Gensim 已在 Python 2.7、3.5、3.6 和 3.7 版本上进行了测试。
Numpy
众所周知,NumPy 是一个用于 Python 科学计算的包。它也可以用作通用数据的有效多维容器。Gensim 依赖于 NumPy 包进行数值计算。有关 Python 的基本教程,您可以参考链接 www.tutorialspoint.com/numpy/index.htm。
smart_open
smart_open,一个 Python 2 和 Python 3 库,用于高效地流式传输非常大的文件。它支持从/到 S3、HDFS、WebHDFS、HTTP、HTTPS、SFTP 或本地文件系统等存储的流式传输。Gensim 依赖于 smart_open Python 库来透明地打开远程存储上的文件以及压缩文件。
当前版本
Gensim 的当前版本为 3.8.0,于 2019 年 7 月发布。
使用终端安装
安装 Gensim 的最简单方法之一是在终端中运行以下命令:
pip install --upgrade gensim
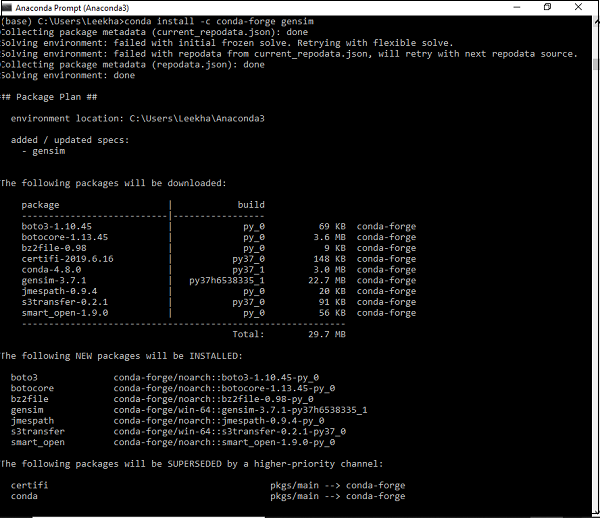
使用Conda环境安装
下载 Gensim 的另一种方法是使用 conda 环境。在您的 conda 终端中运行以下命令:
conda install –c conda-forge gensim
使用源代码包安装
假设您已下载并解压缩了源代码包,则需要运行以下命令:
python setup.py test python setup.py install
Gensim - 文档与语料库
在这里,我们将学习 Gensim 的核心概念,重点关注文档和语料库。
Gensim 的核心概念
以下是理解和使用 Gensim 所需的核心概念和术语:
文档 - 指的是一些文本。
语料库 - 指的是文档的集合。
向量 - 文档的数学表示称为向量。
模型 - 指的是用于将向量从一种表示转换为另一种表示的算法。
什么是文档?
如上所述,它指的是一些文本。如果我们详细介绍一下,它是一个文本序列类型的对象,在 Python 3 中称为 ‘str’。例如,在 Gensim 中,文档可以是任何东西,例如:
- 140 个字符的简短推文
- 单个段落,即文章或研究论文摘要
- 新闻文章
- 书籍
- 小说
- 论文
文本序列
文本序列类型在 Python 3 中通常称为 ‘str’。众所周知,在 Python 中,文本数据使用字符串或更具体地说 ‘str’ 对象进行处理。字符串基本上是 Unicode 代码点的不可变序列,可以用以下方式编写:
单引号 - 例如,‘你好!你好吗?’。它也允许我们嵌入双引号。例如,‘你好!“你好”吗?’
双引号 - 例如,"你好!你好吗?"。它也允许我们嵌入单引号。例如,"你好!'你好'吗?"
三引号 - 它可以是三个单引号,例如,'''你好!你好吗?'''。或三个双引号,例如,"""你好!'你好'吗?"""
所有空格都将包含在字符串文字中。
示例
以下是 Gensim 中文档的一个示例:
Document = “Tutorialspoint.com is the biggest online tutorials library and it’s all free also”
什么是语料库?
语料库可以定义为在自然交流环境中产生的大型结构化机器可读文本集。在 Gensim 中,文档对象的集合称为语料库。语料库的复数是 corpora。
语料库在 Gensim 中的作用
Gensim 中的语料库扮演以下两个角色:
用作训练模型的输入
语料库在 Gensim 中扮演的第一个也是最重要的角色是作为训练模型的输入。为了初始化模型的内部参数,在训练期间,模型会从训练语料库中寻找一些共同的主题和主题。如上所述,Gensim 侧重于无监督模型,因此它不需要任何人工干预。
用作主题提取器
一旦模型训练完成,它就可以用于从新文档中提取主题。这里,新文档是在训练阶段未使用的文档。
示例
语料库可以包含特定人员的所有推文、报纸的所有文章列表或特定主题的所有研究论文等。
收集语料库
以下是一个小型语料库的示例,其中包含 5 个文档。这里,每个文档都是由单个句子组成的字符串。
t_corpus = [ "A survey of user opinion of computer system response time", "Relation of user perceived response time to error measurement", "The generation of random binary unordered trees", "The intersection graph of paths in trees", "Graph minors IV Widths of trees and well quasi ordering", ]
预处理收集语料库
收集语料库后,应执行一些预处理步骤以简化语料库。我们可以简单地移除一些常用的英语单词,例如“the”。我们还可以移除语料库中只出现一次的单词。
例如,以下 Python 脚本用于将每个文档小写化,按空格分割,并过滤掉停用词:
示例
import pprint
t_corpus = [
"A survey of user opinion of computer system response time",
"Relation of user perceived response time to error measurement",
"The generation of random binary unordered trees",
"The intersection graph of paths in trees",
"Graph minors IV Widths of trees and well quasi ordering",
]
stoplist = set('for a of the and to in'.split(' '))
processed_corpus = [[word for word in document.lower().split() if word not in stoplist]
for document in t_corpus]
pprint.pprint(processed_corpus)
]
输出
[['survey', 'user', 'opinion', 'computer', 'system', 'response', 'time'], ['relation', 'user', 'perceived', 'response', 'time', 'error', 'measurement'], ['generation', 'random', 'binary', 'unordered', 'trees'], ['intersection', 'graph', 'paths', 'trees'], ['graph', 'minors', 'iv', 'widths', 'trees', 'well', 'quasi', 'ordering']]
有效的预处理
Gensim 还提供更有效的语料库预处理函数。在这种预处理中,我们可以将文档转换为小写标记列表。我们还可以忽略过短或过长的标记。此函数为gensim.utils.simple_preprocess(doc, deacc=False, min_len=2, max_len=15)。
gensim.utils.simple_preprocess() 函数
Gensim 提供此函数,用于将文档转换为小写标记列表,以及忽略过短或过长的标记。它具有以下参数:
doc(str)
它指的是应该应用预处理的输入文档。
deacc(bool, 可选)
此参数用于从标记中删除重音符号。它使用deaccent() 来执行此操作。
min_len(int, 可选)
借助此参数,我们可以设置标记的最小长度。长度短于定义长度的标记将被丢弃。
max_len(int, 可选)
借助此参数,我们可以设置标记的最大长度。长度长于定义长度的标记将被丢弃。
此函数的输出将是从输入文档中提取的标记。
Gensim - 向量与模型
在这里,我们将学习 Gensim 的核心概念,主要关注向量和模型。
什么是向量?
如果我们想推断语料库中的潜在结构怎么办?为此,我们需要以一种可以进行数学运算的方式来表示文档。一种流行的表示方式是将语料库的每个文档表示为特征向量。这就是为什么我们可以说向量是文档的一种数学上的便捷表示。
举个例子,让我们将上述语料库的单个特征表示为问答对:
问 - 单词Hello 在文档中出现了多少次?
答 - 零 (0)。
问 - 文档中有多少个段落?
答 - 两个 (2)
问题通常由其整数 ID 表示,因此此文档的表示是一系列类似 (1, 0.0), (2, 2.0) 的对。这种向量表示称为稠密向量。为什么是稠密的?因为它包含了对上述所有问题的明确答案。
如果我们预先知道所有问题,则表示可以简单地表示为 (0, 2)。这种答案序列(当然,如果问题预先已知)就是我们文档的向量。
另一种流行的表示方式是词袋 (BoW) 模型。在这种方法中,每个文档基本上都由一个向量表示,该向量包含字典中每个单词的频率计数。
举个例子,假设我们有一个包含单词 [‘Hello’, ‘How’, ‘are’, ‘you’] 的字典。包含字符串“How are you how”的文档将由向量 [0, 2, 1, 1] 表示。这里,向量的条目按“Hello”、“How”、“are”和“you”出现的顺序排列。
向量与文档
从上述向量解释中,文档和向量之间的区别几乎可以理解。但是,为了更清楚起见,文档是文本,向量是该文本的数学上的便捷表示。不幸的是,有时许多人会互换使用这些术语。
例如,假设我们有一些任意文档 A,那么他们通常会说“文档 A 对应的向量”,而不是说“与文档 A 对应的向量”。这会导致很大的歧义。这里需要注意的另一重要事项是,两篇不同的文档可能具有相同的向量表示。
将语料库转换为向量列表
在进行将语料库转换为向量列表的实现示例之前,我们需要将语料库中的每个单词与唯一的整数 ID 关联起来。为此,我们将扩展上一章中使用的示例。
示例
from gensim import corpora dictionary = corpora.Dictionary(processed_corpus) print(dictionary)
输出
Dictionary(25 unique tokens: ['computer', 'opinion', 'response', 'survey', 'system']...)
它表明,在我们的语料库中,这个gensim.corpora.Dictionary中有 25 个不同的标记。
实现示例
我们可以使用字典将标记化的文档转换为这些 5 维向量,如下所示:
pprint.pprint(dictionary.token2id)
输出
{
'binary': 11,
'computer': 0,
'error': 7,
'generation': 12,
'graph': 16,
'intersection': 17,
'iv': 19,
'measurement': 8,
'minors': 20,
'opinion': 1,
'ordering': 21,
'paths': 18,
'perceived': 9,
'quasi': 22,
'random': 13,
'relation': 10,
'response': 2,
'survey': 3,
'system': 4,
'time': 5,
'trees': 14,
'unordered': 15,
'user': 6,
'well': 23,
'widths': 24
}
同样,我们可以为文档创建词袋表示,如下所示:
BoW_corpus = [dictionary.doc2bow(text) for text in processed_corpus] pprint.pprint(BoW_corpus)
输出
[ [(0, 1), (1, 1), (2, 1), (3, 1), (4, 1), (5, 1), (6, 1)], [(2, 1), (5, 1), (6, 1), (7, 1), (8, 1), (9, 1), (10, 1)], [(11, 1), (12, 1), (13, 1), (14, 1), (15, 1)], [(14, 1), (16, 1), (17, 1), (18, 1)], [(14, 1), (16, 1), (19, 1), (20, 1), (21, 1), (22, 1), (23, 1), (24, 1)] ]
什么是模型?
一旦我们对语料库进行了向量化,接下来该怎么做?现在,我们可以使用模型对其进行转换。模型可以指用于将一种文档表示转换为另一种的算法。
正如我们所讨论的,在 Gensim 中,文档表示为向量,因此,我们可以将模型视为两个向量空间之间的转换。总会有一个训练阶段,模型在该阶段学习这种转换的细节。模型在训练阶段读取训练语料库。
初始化模型
让我们初始化tf-idf模型。此模型将向量从 BoW(词袋)表示转换为另一个向量空间,其中频率计数根据语料库中每个单词的相对稀有度进行加权。
实现示例
在下面的示例中,我们将初始化tf-idf模型。我们将在语料库上对其进行训练,然后转换字符串“trees graph”。
示例
from gensim import models tfidf = models.TfidfModel(BoW_corpus) words = "trees graph".lower().split() print(tfidf[dictionary.doc2bow(words)])
输出
[(3, 0.4869354917707381), (4, 0.8734379353188121)]
现在,一旦我们创建了模型,我们就可以通过 tfidf 转换整个语料库并对其进行索引,以及查询我们的查询文档(我们提供了查询文档“trees system”)与语料库中每个文档的相似度:
示例
from gensim import similarities index = similarities.SparseMatrixSimilarity(tfidf[BoW_corpus],num_features=5) query_document = 'trees system'.split() query_bow = dictionary.doc2bow(query_document) simils = index[tfidf[query_bow]] print(list(enumerate(simils)))
输出
[(0, 0.0), (1, 0.0), (2, 1.0), (3, 0.4869355), (4, 0.4869355)]
从上面的输出可以看出,文档 4 和文档 5 的相似度得分约为 49%。
此外,我们还可以对输出进行排序以提高可读性,如下所示:
示例
for doc_number, score in sorted(enumerate(sims), key=lambda x: x[1], reverse=True): print(doc_number, score)
输出
2 1.0 3 0.4869355 4 0.4869355 0 0.0 1 0.0
Gensim - 创建字典
在上一章中,我们讨论了向量和模型,您了解了字典。在这里,我们将更详细地讨论字典对象。
什么是字典?
在深入了解字典的概念之前,让我们了解一些简单的 NLP 概念:
标记 - 标记表示一个“单词”。
文档 - 文档指的是句子或段落。
语料库 - 它指的是作为词袋 (BoW) 的文档集合。
对于所有文档,语料库始终包含每个单词的标记 ID 以及其在文档中的频率计数。
让我们转到 Gensim 中的字典概念。为了处理文本文档,Gensim 还需要将单词(即标记)转换为其唯一 ID。为了实现这一点,它为我们提供了字典对象的功能,该对象将每个单词映射到其唯一的整数 ID。它通过将输入文本转换为单词列表,然后将其传递给corpora.Dictionary()对象来实现。
字典的需求
现在问题出现了,字典对象的实际需求是什么,以及在哪里可以使用它?在 Gensim 中,字典对象用于创建词袋 (BoW) 语料库,该语料库进一步用作主题建模和其他模型的输入。
文本输入的形式
我们可以向 Gensim 提供三种不同的输入文本形式:
作为存储在 Python 原生列表对象中的句子(在 Python 3 中称为str)
作为单个文本文件(可以是小文件或大文件)
多个文本文件
使用 Gensim 创建字典
如前所述,在 Gensim 中,字典包含所有单词(即标记)及其唯一整数 ID 的映射。我们可以从句子列表、一个或多个文本文件(包含多行文本的文本文件)创建字典。因此,首先让我们从创建使用句子列表的字典开始。
从句子列表
在下面的示例中,我们将从句子列表创建字典。当我们有句子列表或可以说是多个句子时,我们必须将每个句子转换为单词列表,而列表推导式是执行此操作的非常常见的方法之一。
实现示例
首先,导入所需的包,如下所示:
import gensim from gensim import corpora from pprint import pprint
接下来,从句子/文档列表创建列表推导式,以将其用于创建字典:
doc = [ "CNTK formerly known as Computational Network Toolkit", "is a free easy-to-use open-source commercial-grade toolkit", "that enable us to train deep learning algorithms to learn like the human brain." ]
接下来,我们需要将句子拆分为单词。这称为标记化。
text_tokens = [[text for text in doc.split()] for doc in doc]
现在,借助以下脚本,我们可以创建字典:
dict_LoS = corpora.Dictionary(text_tokens)
现在让我们获取更多信息,例如字典中的标记数量:
print(dict_LoS)
输出
Dictionary(27 unique tokens: ['CNTK', 'Computational', 'Network', 'Toolkit', 'as']...)
我们还可以看到单词到唯一整数的映射,如下所示:
print(dict_LoS.token2id)
输出
{
'CNTK': 0, 'Computational': 1, 'Network': 2, 'Toolkit': 3, 'as': 4,
'formerly': 5, 'known': 6, 'a': 7, 'commercial-grade': 8, 'easy-to-use': 9,
'free': 10, 'is': 11, 'open-source': 12, 'toolkit': 13, 'algorithms': 14,
'brain.': 15, 'deep': 16, 'enable': 17, 'human': 18, 'learn': 19, 'learning': 20,
'like': 21, 'that': 22, 'the': 23, 'to': 24, 'train': 25, 'us': 26
}
完整的实现示例
import gensim from gensim import corpora from pprint import pprint doc = [ "CNTK formerly known as Computational Network Toolkit", "is a free easy-to-use open-source commercial-grade toolkit", "that enable us to train deep learning algorithms to learn like the human brain." ] text_tokens = [[text for text in doc.split()] for doc in doc] dict_LoS = corpora.Dictionary(text_tokens) print(dict_LoS.token2id)
从单个文本文件
在下面的示例中,我们将从单个文本文件创建字典。同样,我们也可以从多个文本文件(即文件目录)创建字典。
为此,我们将前面示例中使用的文档保存在名为doc.txt的文本文件中。Gensim 将逐行读取文件,并使用simple_preprocess一次处理一行。这样,它不需要一次将整个文件加载到内存中。
实现示例
首先,导入所需的包,如下所示:
import gensim from gensim import corpora from pprint import pprint from gensim.utils import simple_preprocess from smart_open import smart_open import os
接下来的代码行将使用名为 doc.txt 的单个文本文件创建 gensim 字典:
dict_STF = corpora.Dictionary( simple_preprocess(line, deacc =True) for line in open(‘doc.txt’, encoding=’utf-8’) )
现在让我们获取更多信息,例如字典中的标记数量:
print(dict_STF)
输出
Dictionary(27 unique tokens: ['CNTK', 'Computational', 'Network', 'Toolkit', 'as']...)
我们还可以看到单词到唯一整数的映射,如下所示:
print(dict_STF.token2id)
输出
{
'CNTK': 0, 'Computational': 1, 'Network': 2, 'Toolkit': 3, 'as': 4,
'formerly': 5, 'known': 6, 'a': 7, 'commercial-grade': 8, 'easy-to-use': 9,
'free': 10, 'is': 11, 'open-source': 12, 'toolkit': 13, 'algorithms': 14,
'brain.': 15, 'deep': 16, 'enable': 17, 'human': 18, 'learn': 19,
'learning': 20, 'like': 21, 'that': 22, 'the': 23, 'to': 24, 'train': 25, 'us': 26
}
完整的实现示例
import gensim from gensim import corpora from pprint import pprint from gensim.utils import simple_preprocess from smart_open import smart_open import os dict_STF = corpora.Dictionary( simple_preprocess(line, deacc =True) for line in open(‘doc.txt’, encoding=’utf-8’) ) dict_STF = corpora.Dictionary(text_tokens) print(dict_STF.token2id)
从多个文本文件
现在让我们从多个文件(即保存在同一目录中的多个文本文件)创建字典。对于此示例,我们创建了三个不同的文本文件,名为first.txt、second.txt和third.txt,其中包含我们之前示例中使用的文本文件 (doc.txt) 的三行。这三个文本文件都保存在名为ABC的目录下。
实现示例
为了实现这一点,我们需要定义一个类,其中包含一个方法,该方法可以迭代目录 (ABC) 中的所有三个文本文件 (First、Second 和 Third.txt) 并生成已处理的单词标记列表。
让我们定义名为Read_files的类,其中包含名为__iteration__()的方法,如下所示:
class Read_files(object):
def __init__(self, directoryname):
elf.directoryname = directoryname
def __iter__(self):
for fname in os.listdir(self.directoryname):
for line in open(os.path.join(self.directoryname, fname), encoding='latin'):
yield simple_preprocess(line)
接下来,我们需要提供目录的路径,如下所示:
path = "ABC"
# 请根据您保存目录的计算机系统提供路径.
接下来的步骤与我们在前面示例中所做的类似。接下来的代码行将使用包含三个文本文件的目录创建 Gensim 字典:
dict_MUL = corpora.Dictionary(Read_files(path))
输出
Dictionary(27 unique tokens: ['CNTK', 'Computational', 'Network', 'Toolkit', 'as']...)
现在我们还可以看到单词到唯一整数的映射,如下所示:
print(dict_MUL.token2id)
输出
{
'CNTK': 0, 'Computational': 1, 'Network': 2, 'Toolkit': 3, 'as': 4,
'formerly': 5, 'known': 6, 'a': 7, 'commercial-grade': 8, 'easy-to-use': 9,
'free': 10, 'is': 11, 'open-source': 12, 'toolkit': 13, 'algorithms': 14,
'brain.': 15, 'deep': 16, 'enable': 17, 'human': 18, 'learn': 19,
'learning': 20, 'like': 21, 'that': 22, 'the': 23, 'to': 24, 'train': 25, 'us': 26
}
保存和加载 Gensim 字典
Gensim 支持其自身原生的 save() 方法将字典保存到磁盘,以及 load() 方法从磁盘加载回字典。
例如,我们可以使用以下脚本保存字典:
Gensim.corpora.dictionary.save(filename)
# 指定要保存字典的路径.
类似地,我们可以使用 load() 方法加载已保存的字典。以下脚本可以实现此功能:
Gensim.corpora.dictionary.load(filename)
# 指定已保存字典的路径。
Gensim - 创建词袋 (BoW) 语料库
我们已经了解了如何从文档列表和文本文件(一个或多个)创建字典。在本节中,我们将创建一个词袋 (BoW) 语料库。对于使用 Gensim,这是我们需要熟悉的最重要的对象之一。基本上,它是包含每个文档中单词 ID 及其频率的语料库。
创建 BoW 语料库
如前所述,在 Gensim 中,语料库包含每个文档中单词 ID 及其频率。我们可以从简单的文档列表和文本文件创建 BoW 语料库。我们需要做的就是将标记化的单词列表传递给名为 Dictionary.doc2bow() 的对象。所以首先,让我们从使用简单的文档列表创建 BoW 语料库开始。
从简单的句子列表
在下面的示例中,我们将从包含三个句子的简单列表创建 BoW 语料库。
首先,我们需要导入所有必要的包,如下所示:
import gensim import pprint from gensim import corpora from gensim.utils import simple_preprocess
现在提供包含句子的列表。我们的列表中有三个句子:
doc_list = [ "Hello, how are you?", "How do you do?", "Hey what are you doing? yes you What are you doing?" ]
接下来,对句子进行标记化,如下所示:
doc_tokenized = [simple_preprocess(doc) for doc in doc_list]
创建 corpora.Dictionary() 对象,如下所示:
dictionary = corpora.Dictionary()
现在将这些标记化的句子传递给 dictionary.doc2bow() 对象,如下所示:
BoW_corpus = [dictionary.doc2bow(doc, allow_update=True) for doc in doc_tokenized]
最后,我们可以打印词袋语料库:
print(BoW_corpus)
输出
[ [(0, 1), (1, 1), (2, 1), (3, 1)], [(2, 1), (3, 1), (4, 2)], [(0, 2), (3, 3), (5, 2), (6, 1), (7, 2), (8, 1)] ]
上述输出显示,ID 为 0 的单词在第一个文档中出现一次(因为我们在输出中得到了 (0,1)),以此类推。
上述输出对于人类来说难以阅读。我们也可以将这些 ID 转换为单词,为此我们需要使用字典进行转换,如下所示:
id_words = [[(dictionary[id], count) for id, count in line] for line in BoW_corpus] print(id_words)
输出
[
[('are', 1), ('hello', 1), ('how', 1), ('you', 1)],
[('how', 1), ('you', 1), ('do', 2)],
[('are', 2), ('you', 3), ('doing', 2), ('hey', 1), ('what', 2), ('yes', 1)]
]
现在上述输出对人类来说比较易读。
完整的实现示例
import gensim import pprint from gensim import corpora from gensim.utils import simple_preprocess doc_list = [ "Hello, how are you?", "How do you do?", "Hey what are you doing? yes you What are you doing?" ] doc_tokenized = [simple_preprocess(doc) for doc in doc_list] dictionary = corpora.Dictionary() BoW_corpus = [dictionary.doc2bow(doc, allow_update=True) for doc in doc_tokenized] print(BoW_corpus) id_words = [[(dictionary[id], count) for id, count in line] for line in BoW_corpus] print(id_words)
从文本文件
在下面的示例中,我们将从文本文件创建 BoW 语料库。为此,我们将前面示例中使用的文档保存在名为 doc.txt 的文本文件中。
Gensim 将逐行读取文件,并使用 simple_preprocess 一次处理一行。这样,它不需要一次将整个文件加载到内存中。
实现示例
首先,导入所需的包,如下所示:
import gensim from gensim import corpora from pprint import pprint from gensim.utils import simple_preprocess from smart_open import smart_open import os
接下来,以下代码行将读取 doc.txt 中的文档并对其进行标记化:
doc_tokenized = [ simple_preprocess(line, deacc =True) for line in open(‘doc.txt’, encoding=’utf-8’) ] dictionary = corpora.Dictionary()
现在我们需要将这些标记化的单词传递给 dictionary.doc2bow() 对象(如前一个示例中所做的那样)。
BoW_corpus = [ dictionary.doc2bow(doc, allow_update=True) for doc in doc_tokenized ] print(BoW_corpus)
输出
[
[(9, 1), (10, 1), (11, 1), (12, 1), (13, 1), (14, 1), (15, 1)],
[
(15, 1), (16, 1), (17, 1), (18, 1), (19, 1), (20, 1), (21, 1),
(22, 1), (23, 1), (24, 1)
],
[
(23, 2), (25, 1), (26, 1), (27, 1), (28, 1), (29, 1),
(30, 1), (31, 1), (32, 1), (33, 1), (34, 1), (35, 1), (36, 1)
],
[(3, 1), (18, 1), (37, 1), (38, 1), (39, 1), (40, 1), (41, 1), (42, 1), (43, 1)],
[
(18, 1), (27, 1), (31, 2), (32, 1), (38, 1), (41, 1), (43, 1),
(44, 1), (45, 1), (46, 1), (47, 1), (48, 1), (49, 1), (50, 1), (51, 1), (52, 1)
]
]
doc.txt 文件的内容如下:
CNTK,以前称为计算网络工具包,是一个免费的、易于使用的、开源的、商用级的工具包,它使我们能够训练深度学习算法,使其像人脑一样学习。
您可以在 tutorialspoint.com 上找到它的免费教程,该网站还免费提供关于人工智能、深度学习、机器学习等技术的最佳技术教程。
完整的实现示例
import gensim from gensim import corpora from pprint import pprint from gensim.utils import simple_preprocess from smart_open import smart_open import os doc_tokenized = [ simple_preprocess(line, deacc =True) for line in open(‘doc.txt’, encoding=’utf-8’) ] dictionary = corpora.Dictionary() BoW_corpus = [dictionary.doc2bow(doc, allow_update=True) for doc in doc_tokenized] print(BoW_corpus)
保存和加载 Gensim 语料库
我们可以使用以下脚本保存语料库:
corpora.MmCorpus.serialize(‘/Users/Desktop/BoW_corpus.mm’, bow_corpus)
# 提供语料库的路径和名称。语料库的名称为 BoW_corpus,我们将其保存为 Matrix Market 格式。
类似地,我们可以使用以下脚本加载已保存的语料库:
corpus_load = corpora.MmCorpus(‘/Users/Desktop/BoW_corpus.mm’) for line in corpus_load: print(line)
Gensim - 变换
本章将帮助您了解 Gensim 中的各种转换。让我们从了解文档转换开始。
转换文档
转换文档意味着以一种可以进行数学运算的方式来表示文档。除了推断语料库的潜在结构外,转换文档还将实现以下目标:
它发现单词之间的关系。
它揭示了语料库中隐藏的结构。
它以一种新的、更语义的方式描述文档。
它使文档的表示更紧凑。
它提高了效率,因为新的表示消耗更少的资源。
它提高了功效,因为在新表示中忽略了边际数据趋势。
在新文档表示中也减少了噪声。
让我们看看将文档从一种向量空间表示转换为另一种向量空间表示的实现步骤。
实施步骤
为了转换文档,我们必须遵循以下步骤:
步骤 1:创建语料库
第一步也是最基本的一步是从文档中创建语料库。我们已经在前面的示例中创建了语料库。让我们再创建一个,并进行一些增强(去除常用词和只出现一次的词):
import gensim import pprint from collections import defaultdict from gensim import corpora
现在提供用于创建语料库的文档:
t_corpus = ["CNTK formerly known as Computational Network Toolkit", "is a free easy-to-use open-source commercial-grade toolkit", "that enable us to train deep learning algorithms to learn like the human brain.", "You can find its free tutorial on tutorialspoint.com", "Tutorialspoint.com also provide best technical tutorials on technologies like AI deep learning machine learning for free"]
接下来,我们需要进行标记化,同时还要去除常用词:
stoplist = set('for a of the and to in'.split(' '))
processed_corpus = [
[
word for word in document.lower().split() if word not in stoplist
]
for document in t_corpus
]
以下脚本将删除只出现一次的单词:
frequency = defaultdict(int)
for text in processed_corpus:
for token in text:
frequency[token] += 1
processed_corpus = [
[token for token in text if frequency[token] > 1]
for text in processed_corpus
]
pprint.pprint(processed_corpus)
输出
[ ['toolkit'], ['free', 'toolkit'], ['deep', 'learning', 'like'], ['free', 'on', 'tutorialspoint.com'], ['tutorialspoint.com', 'on', 'like', 'deep', 'learning', 'learning', 'free'] ]
现在将其传递给 corpora.dictionary() 对象以获取语料库中的唯一对象:
dictionary = corpora.Dictionary(processed_corpus) print(dictionary)
输出
Dictionary(7 unique tokens: ['toolkit', 'free', 'deep', 'learning', 'like']...)
接下来,以下代码行将为我们的语料库创建词袋模型:
BoW_corpus = [dictionary.doc2bow(text) for text in processed_corpus] pprint.pprint(BoW_corpus)
输出
[ [(0, 1)], [(0, 1), (1, 1)], [(2, 1), (3, 1), (4, 1)], [(1, 1), (5, 1), (6, 1)], [(1, 1), (2, 1), (3, 2), (4, 1), (5, 1), (6, 1)] ]
步骤 2:创建转换
转换是一些标准的 Python 对象。我们可以使用经过训练的语料库来初始化这些转换,即 Python 对象。这里我们将使用 tf-idf 模型来创建我们训练过的语料库 BoW_corpus 的转换。
首先,我们需要从 gensim 导入 models 包。
from gensim import models
现在,我们需要初始化模型,如下所示:
tfidf = models.TfidfModel(BoW_corpus)
步骤 3:转换向量
现在,在最后一步中,向量将从旧表示转换为新表示。由于我们在上述步骤中初始化了 tfidf 模型,因此 tfidf 现在将被视为只读对象。在这里,我们将使用这个 tfidf 对象将我们的向量从词袋表示(旧表示)转换为 Tfidf 实值权重(新表示)。
doc_BoW = [(1,1),(3,1)] print(tfidf[doc_BoW]
输出
[(1, 0.4869354917707381), (3, 0.8734379353188121)]
我们将转换应用于语料库的两个值,但我们也可以将其应用于整个语料库,如下所示:
corpus_tfidf = tfidf[BoW_corpus] for doc in corpus_tfidf: print(doc)
输出
[(0, 1.0)] [(0, 0.8734379353188121), (1, 0.4869354917707381)] [(2, 0.5773502691896257), (3, 0.5773502691896257), (4, 0.5773502691896257)] [(1, 0.3667400603126873), (5, 0.657838022678017), (6, 0.657838022678017)] [ (1, 0.19338287240886842), (2, 0.34687949360312714), (3, 0.6937589872062543), (4, 0.34687949360312714), (5, 0.34687949360312714), (6, 0.34687949360312714) ]
完整的实现示例
import gensim
import pprint
from collections import defaultdict
from gensim import corpora
t_corpus = [
"CNTK formerly known as Computational Network Toolkit",
"is a free easy-to-use open-source commercial-grade toolkit",
"that enable us to train deep learning algorithms to learn like the human brain.",
"You can find its free tutorial on tutorialspoint.com",
"Tutorialspoint.com also provide best technical tutorials on
technologies like AI deep learning machine learning for free"
]
stoplist = set('for a of the and to in'.split(' '))
processed_corpus = [
[word for word in document.lower().split() if word not in stoplist]
for document in t_corpus
]
frequency = defaultdict(int)
for text in processed_corpus:
for token in text:
frequency[token] += 1
processed_corpus = [
[token for token in text if frequency[token] > 1]
for text in processed_corpus
]
pprint.pprint(processed_corpus)
dictionary = corpora.Dictionary(processed_corpus)
print(dictionary)
BoW_corpus = [dictionary.doc2bow(text) for text in processed_corpus]
pprint.pprint(BoW_corpus)
from gensim import models
tfidf = models.TfidfModel(BoW_corpus)
doc_BoW = [(1,1),(3,1)]
print(tfidf[doc_BoW])
corpus_tfidf = tfidf[BoW_corpus]
for doc in corpus_tfidf:
print(doc)
Gensim 中的各种转换
使用 Gensim,我们可以实现各种流行的转换,即向量空间模型算法。其中一些如下:
Tf-Idf(词频-逆文档频率)
在初始化期间,此 tf-idf 模型算法期望一个具有整数值的训练语料库(例如词袋模型)。然后,在转换时,它采用向量表示并返回另一个向量表示。
输出向量将具有相同的维度,但稀有特征的值(在训练时)将增加。它基本上将整数值向量转换为实值向量。以下是 Tf-idf 转换的语法:
Model=models.TfidfModel(corpus, normalize=True)
LSI(潜在语义索引)
LSI 模型算法可以将文档从整数值向量模型(例如词袋模型)或 Tf-Idf 加权空间转换为潜在空间。输出向量的维度将更低。以下是 LSI 转换的语法:
Model=models.LsiModel(tfidf_corpus, id2word=dictionary, num_topics=300)
LDA(潜在狄利克雷分配)
LDA 模型算法是另一种将文档从词袋模型空间转换为主题空间的算法。输出向量的维度将更低。以下是 LSI 转换的语法:
Model=models.LdaModel(corpus, id2word=dictionary, num_topics=100)
随机投影 (RP)
RP 是一种非常有效的方法,旨在降低向量空间的维度。这种方法基本上近似于文档之间的 Tf-Idf 距离。它通过引入一些随机性来实现这一点。
Model=models.RpModel(tfidf_corpus, num_topics=500)
分层狄利克雷过程 (HDP)
HDP 是一种非参数贝叶斯方法,是 Gensim 的新增功能。使用它时需要注意。
Model=models.HdpModel(corpus, id2word=dictionary
Gensim - 创建 TF-IDF 矩阵
在这里,我们将学习如何使用 Gensim 创建词频-逆文档频率 (TF-IDF) 矩阵。
什么是 TF-IDF?
它是词频-逆文档频率模型,也是一种词袋模型。它与常规语料库不同,因为它降低了跨文档频繁出现的标记(即单词)的权重。在初始化期间,此 tf-idf 模型算法期望一个具有整数值的训练语料库(例如词袋模型)。
然后,在转换时,它采用向量表示并返回另一个向量表示。输出向量将具有相同的维度,但稀有特征的值(在训练时)将增加。它基本上将整数值向量转换为实值向量。
它是如何计算的?
TF-IDF 模型使用以下两个简单步骤计算 tfidf:
步骤 1:将局部组件和全局组件相乘
在第一步中,模型将局部组件(如 TF(词频))与全局组件(如 IDF(逆文档频率))相乘。
步骤 2:标准化结果
完成乘法后,在下一步中,TFIDF 模型将结果标准化为单位长度。
由于上述两个步骤,跨文档频繁出现的单词将被降低权重。
如何获得 TF-IDF 权重?
在这里,我们将实现一个示例,以了解如何获得 TF-IDF 权重。基本上,为了获得 TF-IDF 权重,首先我们需要训练语料库,然后将该语料库应用于 tfidf 模型。
训练语料库
如上所述,要获得 TF-IDF,我们首先需要训练我们的语料库。首先,我们需要导入所有必要的包,如下所示:
import gensim import pprint from gensim import corpora from gensim.utils import simple_preprocess
现在提供包含句子的列表。我们的列表中有三个句子:
doc_list = [ "Hello, how are you?", "How do you do?", "Hey what are you doing? yes you What are you doing?" ]
接下来,对句子进行标记化,如下所示:
doc_tokenized = [simple_preprocess(doc) for doc in doc_list]
创建 corpora.Dictionary() 对象,如下所示:
dictionary = corpora.Dictionary()
现在将这些标记化的句子传递给 dictionary.doc2bow() 对象,如下所示:
BoW_corpus = [dictionary.doc2bow(doc, allow_update=True) for doc in doc_tokenized]
接下来,我们将获得文档中单词 ID 及其频率。
for doc in BoW_corpus: print([[dictionary[id], freq] for id, freq in doc])
输出
[['are', 1], ['hello', 1], ['how', 1], ['you', 1]] [['how', 1], ['you', 1], ['do', 2]] [['are', 2], ['you', 3], ['doing', 2], ['hey', 1], ['what', 2], ['yes', 1]]
这样我们就训练了我们的语料库(词袋语料库)。
接下来,我们需要将这个训练过的语料库应用于 tfidf 模型 models.TfidfModel()。
首先导入 numpay 包:
import numpy as np
现在将我们训练过的语料库 (BoW_corpus) 应用于 models.TfidfModel() 的方括号中。
tfidf = models.TfidfModel(BoW_corpus, smartirs='ntc')
接下来,我们将获得 tfidf 模型化语料库中单词 ID 及其频率:
for doc in tfidf[BoW_corpus]: print([[dictionary[id], np.around(freq,decomal=2)] for id, freq in doc])
输出
[['are', 0.33], ['hello', 0.89], ['how', 0.33]] [['how', 0.18], ['do', 0.98]] [['are', 0.23], ['doing', 0.62], ['hey', 0.31], ['what', 0.62], ['yes', 0.31]] [['are', 1], ['hello', 1], ['how', 1], ['you', 1]] [['how', 1], ['you', 1], ['do', 2]] [['are', 2], ['you', 3], ['doing', 2], ['hey', 1], ['what', 2], ['yes', 1]] [['are', 0.33], ['hello', 0.89], ['how', 0.33]] [['how', 0.18], ['do', 0.98]] [['are', 0.23], ['doing', 0.62], ['hey', 0.31], ['what', 0.62], ['yes', 0.31]]
从上述输出中,我们可以看到文档中单词频率的差异。
完整的实现示例
import gensim import pprint from gensim import corpora from gensim.utils import simple_preprocess doc_list = [ "Hello, how are you?", "How do you do?", "Hey what are you doing? yes you What are you doing?" ] doc_tokenized = [simple_preprocess(doc) for doc in doc_list] dictionary = corpora.Dictionary() BoW_corpus = [dictionary.doc2bow(doc, allow_update=True) for doc in doc_tokenized] for doc in BoW_corpus: print([[dictionary[id], freq] for id, freq in doc]) import numpy as np tfidf = models.TfidfModel(BoW_corpus, smartirs='ntc') for doc in tfidf[BoW_corpus]: print([[dictionary[id], np.around(freq,decomal=2)] for id, freq in doc])
单词权重的差异
如上所述,在文档中更频繁出现的单词将获得更小的权重。让我们从上述两个输出中了解单词权重的差异。“are”这个词出现在两个文档中,并且权重被降低了。类似地,“you”这个词出现在所有文档中,并且被完全删除了。
Gensim - 主题建模
本章讨论了关于 Gensim 的主题建模。
为了标注我们的数据并理解句子结构,最好的方法之一是使用计算语言学算法。毫无疑问,借助这些计算语言学算法,我们可以理解数据的一些细微之处,但是,
我们能否知道哪些词在语料库中出现的频率高于其他词?
我们能否对数据进行分组?
我们能否找出数据中潜在的主题?
借助主题建模,我们可以实现所有这些目标。所以让我们深入探讨主题模型的概念。
什么是主题模型?
主题模型可以定义为包含文本中主题信息的概率模型。但是,这里出现了两个重要的问题:
首先,什么是主题?
顾名思义,主题是文本中表达的潜在思想或主题。举个例子,包含报纸文章的语料库将包含与金融、天气、政治、体育、各州新闻等相关的主题。
其次,主题模型在文本处理中的重要性是什么?
我们知道,为了识别文本中的相似性,我们可以使用词语进行信息检索和搜索。但是,借助主题模型,我们现在可以使用主题而不是词语来搜索和组织我们的文本文件。
从这个意义上说,我们可以说主题是词语的概率分布。这就是为什么使用主题模型,我们可以将文档描述为主题的概率分布。
主题模型的目标
如上所述,主题建模的重点是潜在的思想和主题。其主要目标如下:
主题模型可用于文本摘要。
它们可用于组织文档。例如,我们可以使用主题建模将新闻文章分组到一个组织的/相互关联的部分中,例如组织所有与板球相关的新闻文章。
它们可以改善搜索结果。如何?对于搜索查询,我们可以使用主题模型来显示包含不同关键词组合但主题相同的文档。
推荐的概念对于营销非常有用。它被各种在线购物网站、新闻网站等等使用。主题模型有助于推荐购买什么、接下来阅读什么等等。它们通过查找列表中具有共同主题的材料来实现。
Gensim中的主题建模算法
毫无疑问,Gensim是最流行的主题建模工具包。它的免费可用性和Python语言使其更受欢迎。在本节中,我们将讨论一些最流行的主题建模算法。在这里,我们将关注“是什么”而不是“如何”,因为Gensim 为我们很好地抽象了它们。
潜在狄利克雷分配 (LDA)
潜在狄利克雷分配 (LDA) 是目前使用最普遍和流行的主题建模技术。它是 Facebook 研究人员在 2013 年发表的研究论文中使用的一种技术。它最初由 David Blei、Andrew Ng 和 Michael Jordan 于 2003 年提出。他们在题为潜在狄利克雷分配的论文中提出了 LDA。
LDA 的特点
让我们通过其特点来了解这种精彩的技术:
概率主题建模技术
LDA 是一种概率主题建模技术。如上所述,在主题建模中,我们假设在任何相互关联的文档集合中(可以是学术论文、报纸文章、Facebook 帖子、推文、电子邮件等等),每个文档中都包含一些主题组合。
概率主题建模的主要目标是发现相互关联的文档集合的隐藏主题结构。主题结构通常包括以下三点:
主题
文档中主题的统计分布
构成主题的文档中的词语
以无监督的方式工作
LDA 以无监督的方式工作。这是因为 LDA 使用条件概率来发现隐藏的主题结构。它假设主题在相互关联的文档集合中分布不均。
在 Gensim 中非常易于创建
在 Gensim 中,创建 LDA 模型非常容易。我们只需要指定语料库、字典映射以及我们希望在模型中使用的主题数量。
Model=models.LdaModel(corpus, id2word=dictionary, num_topics=100)
可能会面临计算上棘手的问题
计算每种可能的主题结构的概率是 LDA 面临的一个计算挑战。之所以具有挑战性,是因为它需要计算每种可能的主题结构下每个观察到的词的概率。如果我们有大量的主题和词语,LDA 可能会面临计算上棘手的问题。
潜在语义索引 (LSI)
第一个在 Gensim 中实现的主题建模算法是潜在狄利克雷分配 (LDA),另一个是潜在语义索引 (LSI)。它也称为潜在语义分析 (LSA)。
它于 1988 年由 Scott Deerwester、Susan Dumais、George Furnas、Richard Harshman、Thomas Landaur、Karen Lochbaum 和 Lynn Streeter 获得专利。在本节中,我们将设置我们的 LSI 模型。这可以通过与设置 LDA 模型相同的方式完成。我们需要从gensim.models导入 LSI 模型。
LSI 的作用
实际上,LSI 是一种 NLP 技术,尤其是在分布式语义中。它分析文档集与其包含的术语之间的关系。如果我们谈论它的工作原理,那么它会构建一个矩阵,该矩阵包含大型文本中每个文档的词语计数。
构建完成后,为了减少行数,LSI 模型使用一种称为奇异值分解 (SVD) 的数学技术。除了减少行数外,它还保留列之间的相似性结构。在矩阵中,行代表唯一的词语,列代表每个文档。它基于分布式假设,即它假设含义相近的词语会出现在相同类型的文本中。
Model=models.LsiModel(corpus, id2word=dictionary, num_topics=100)
分层狄利克雷过程 (HDP)
LDA 和 LSI 等主题模型有助于总结和组织无法人工分析的大型文本档案。除了 LDA 和 LSI 之外,Gensim 中另一个强大的主题模型是 HDP(分层狄利克雷过程)。它基本上是一个用于对分组数据进行无监督分析的混合成员模型。与 LDA(它的有限对应物)不同,HDP 从数据中推断主题的数量。
Model=models.HdpModel(corpus, id2word=dictionary
Gensim - 创建 LDA 主题模型
本章将帮助您学习如何在 Gensim 中创建潜在狄利克雷分配 (LDA) 主题模型。
自动从大量文本中提取有关主题的信息是自然语言处理 (NLP) 的主要应用之一。大量文本可能是酒店评论、推文、Facebook 帖子、任何其他社交媒体渠道的 feed、电影评论、新闻报道、用户反馈、电子邮件等的 feed。
在这个数字时代,了解人们/客户在谈论什么、了解他们的意见和问题,对企业、政治活动和管理人员来说可能非常有价值。但是,是否可以手动阅读如此大量的文本,然后从主题中提取信息?
不可以。这需要一个可以自动阅读这些大量文本文档并自动提取从中讨论的所需信息/主题的算法。
LDA 的作用
LDA 对主题建模的方法是将文档中的文本分类到特定主题。LDA 以狄利克雷分布为模型,构建:
- 每个文档的主题模型和
- 每个主题的词语模型
提供 LDA 主题模型算法后,为了获得良好的主题关键词分布组合,它会重新排列:
- 文档内的主题分布和
- 主题内的关键词分布
在处理过程中,LDA 做出的一些假设是:
- 每个文档都被建模为主题的多项分布。
- 每个主题都被建模为词语的多项分布。
- 我们必须选择正确的数据语料库,因为 LDA 假设每个文本块都包含相关的词语。
- LDA 还假设文档是由主题混合产生的。
使用 Gensim 实现
在这里,我们将使用 LDA(潜在狄利克雷分配)从数据集中提取自然讨论的主题。
加载数据集
我们将使用的数据集是“20 个新闻组”的数据集,其中包含来自新闻报道各个部分的数千篇新闻文章。它可在Sklearn数据集下找到。我们可以轻松地使用以下 Python 脚本来下载:
from sklearn.datasets import fetch_20newsgroups newsgroups_train = fetch_20newsgroups(subset='train')
让我们借助以下脚本来查看一些示例新闻:
newsgroups_train.data[:4]
["From: lerxst@wam.umd.edu (where's my thing)\nSubject: WHAT car is this!?\nNntp-Posting-Host: rac3.wam.umd.edu\nOrganization: University of Maryland, College Park\nLines: 15\n\n I was wondering if anyone out there could enlighten me on this car I saw\nthe other day. It was a 2-door sports car, looked to be from the late 60s/\nearly 70s. It was called a Bricklin. The doors were really small. In addition,\nthe front bumper was separate from the rest of the body. This is \nall I know. If anyone can tellme a model name, engine specs, years\nof production, where this car is made, history, or whatever info you\nhave on this funky looking car, please e-mail.\n\nThanks, \n- IL\n ---- brought to you by your neighborhood Lerxst ----\n\n\n\n\n", "From: guykuo@carson.u.washington.edu (Guy Kuo)\nSubject: SI Clock Poll - Final Call\nSummary: Final call for SI clock reports\nKeywords: SI,acceleration,clock,upgrade\nArticle-I.D.: shelley.1qvfo9INNc3s\nOrganization: University of Washington\nLines: 11\nNNTP-Posting-Host: carson.u.washington.edu\n\nA fair number of brave souls who upgraded their SI clock oscillator have\nshared their experiences for this poll. Please send a brief message detailing\nyour experiences with the procedure. Top speed attained, CPU rated speed,\nadd on cards and adapters, heat sinks, hour of usage per day, floppy disk\nfunctionality with 800 and 1.4 m floppies are especially requested.\n\nI will be summarizing in the next two days, so please add to the network\nknowledge base if you have done the clock upgrade and haven't answered this\npoll. Thanks.\n\nGuy Kuo <;guykuo@u.washington.edu>\n", 'From: twillis@ec.ecn.purdue.edu (Thomas E Willis)\nSubject: PB questions...\nOrganization: Purdue University Engineering Computer Network\nDistribution: usa\nLines: 36\n\nwell folks, my mac plus finally gave up the ghost this weekend after\nstarting life as a 512k way back in 1985. sooo, i\'m in the market for a\nnew machine a bit sooner than i intended to be...\n\ni\'m looking into picking up a powerbook 160 or maybe 180 and have a bunch\nof questions that (hopefully) somebody can answer:\n\n* does anybody know any dirt on when the next round of powerbook\nintroductions are expected? i\'d heard the 185c was supposed to make an\nappearence "this summer" but haven\'t heard anymore on it - and since i\ndon\'t have access to macleak, i was wondering if anybody out there had\nmore info...\n\n* has anybody heard rumors about price drops to the powerbook line like the\nones the duo\'s just went through recently?\n\n* what\'s the impression of the display on the 180? i could probably swing\na 180 if i got the 80Mb disk rather than the 120, but i don\'t really have\na feel for how much "better" the display is (yea, it looks great in the\nstore, but is that all "wow" or is it really that good?). could i solicit\nsome opinions of people who use the 160 and 180 day-to-day on if its worth\ntaking the disk size and money hit to get the active display? (i realize\nthis is a real subjective question, but i\'ve only played around with the\nmachines in a computer store breifly and figured the opinions of somebody\nwho actually uses the machine daily might prove helpful).\n\n* how well does hellcats perform? ;)\n\nthanks a bunch in advance for any info - if you could email, i\'ll post a\nsummary (news reading time is at a premium with finals just around the\ncorner... : ( )\n--\nTom Willis \\ twillis@ecn.purdue.edu \\ Purdue Electrical Engineering\n---------------------------------------------------------------------------\ n"Convictions are more dangerous enemies of truth than lies." - F. W.\nNietzsche\n', 'From: jgreen@amber (Joe Green)\nSubject: Re: Weitek P9000 ?\nOrganization: Harris Computer Systems Division\nLines: 14\nDistribution: world\nNNTP-Posting-Host: amber.ssd.csd.harris.com\nX-Newsreader: TIN [version 1.1 PL9]\n\nRobert J.C. Kyanko (rob@rjck.UUCP) wrote:\n >abraxis@iastate.edu writes in article <abraxis.734340159@class1.iastate.edu >:\n> > Anyone know about the Weitek P9000 graphics chip?\n > As far as the low-level stuff goes, it looks pretty nice. It\'s got this\n> quadrilateral fill command that requires just the four points.\n\nDo you have Weitek\'s address/phone number? I\'d like to get some information\nabout this chip.\n\n--\nJoe Green\t\t\t\tHarris Corporation\njgreen@csd.harris.com\t\t\tComputer Systems Division\n"The only thing that really scares me is a person with no sense of humor. "\n\t\t\t\t\t\t-- Jonathan Winters\n']
先决条件
我们需要来自 NLTK 的停用词和来自 Scapy 的英语模型。两者都可以按如下方式下载:
import nltk;
nltk.download('stopwords')
nlp = spacy.load('en_core_web_md', disable=['parser', 'ner'])
导入必要的包
为了构建 LDA 模型,我们需要导入以下必要的包:
import re import numpy as np import pandas as pd from pprint import pprint import gensim import gensim.corpora as corpora from gensim.utils import simple_preprocess from gensim.models import CoherenceModel import spacy import pyLDAvis import pyLDAvis.gensim import matplotlib.pyplot as plt
准备停用词
现在,我们需要导入停用词并使用它们:
from nltk.corpus import stopwords
stop_words = stopwords.words('english')
stop_words.extend(['from', 'subject', 're', 'edu', 'use'])
清理文本
现在,借助 Gensim 的simple_preprocess(),我们需要将每个句子标记化为词语列表。我们还应该删除标点符号和不必要的字符。为此,我们将创建一个名为sent_to_words()的函数:
def sent_to_words(sentences):
for sentence in sentences:
yield(gensim.utils.simple_preprocess(str(sentence), deacc=True))
data_words = list(sent_to_words(data))
构建二元组和三元组模型
众所周知,二元组是文档中经常一起出现的两个词,三元组是文档中经常一起出现的三个词。借助 Gensim 的Phrases模型,我们可以做到这一点:
bigram = gensim.models.Phrases(data_words, min_count=5, threshold=100) trigram = gensim.models.Phrases(bigram[data_words], threshold=100) bigram_mod = gensim.models.phrases.Phraser(bigram) trigram_mod = gensim.models.phrases.Phraser(trigram)
过滤掉停用词
接下来,我们需要过滤掉停用词。除此之外,我们还将创建用于创建二元组、三元组和词形还原的函数:
def remove_stopwords(texts):
return [[word for word in simple_preprocess(str(doc))
if word not in stop_words] for doc in texts]
def make_bigrams(texts):
return [bigram_mod[doc] for doc in texts]
def make_trigrams(texts):
return [trigram_mod[bigram_mod[doc]] for doc in texts]
def lemmatization(texts, allowed_postags=['NOUN', 'ADJ', 'VERB', 'ADV']):
texts_out = []
for sent in texts:
doc = nlp(" ".join(sent))
texts_out.append([token.lemma_ for token in doc if token.pos_ in allowed_postags])
return texts_out
为主题模型构建字典和语料库
我们现在需要构建字典和语料库。我们之前也做过:
id2word = corpora.Dictionary(data_lemmatized) texts = data_lemmatized corpus = [id2word.doc2bow(text) for text in texts]
构建 LDA 主题模型
我们已经实现了训练 LDA 模型所需的一切。现在是构建 LDA 主题模型的时候了。对于我们的实现示例,可以使用以下几行代码来完成:
lda_model = gensim.models.ldamodel.LdaModel( corpus=corpus, id2word=id2word, num_topics=20, random_state=100, update_every=1, chunksize=100, passes=10, alpha='auto', per_word_topics=True )
实现示例
让我们看看构建 LDA 主题模型的完整实现示例:
import re
import numpy as np
import pandas as pd
from pprint import pprint
import gensim
import gensim.corpora as corpora
from gensim.utils import simple_preprocess
from gensim.models import CoherenceModel
import spacy
import pyLDAvis
import pyLDAvis.gensim
import matplotlib.pyplot as plt
from nltk.corpus import stopwords
stop_words = stopwords.words('english')
stop_words.extend(['from', 'subject', 're', 'edu', 'use'])
from sklearn.datasets import fetch_20newsgroups
newsgroups_train = fetch_20newsgroups(subset='train')
data = newsgroups_train.data
data = [re.sub('\S*@\S*\s?', '', sent) for sent in data]
data = [re.sub('\s+', ' ', sent) for sent in data]
data = [re.sub("\'", "", sent) for sent in data]
print(data_words[:4]) #it will print the data after prepared for stopwords
bigram = gensim.models.Phrases(data_words, min_count=5, threshold=100)
trigram = gensim.models.Phrases(bigram[data_words], threshold=100)
bigram_mod = gensim.models.phrases.Phraser(bigram)
trigram_mod = gensim.models.phrases.Phraser(trigram)
def remove_stopwords(texts):
return [[word for word in simple_preprocess(str(doc))
if word not in stop_words] for doc in texts]
def make_bigrams(texts):
return [bigram_mod[doc] for doc in texts]
def make_trigrams(texts):
[trigram_mod[bigram_mod[doc]] for doc in texts]
def lemmatization(texts, allowed_postags=['NOUN', 'ADJ', 'VERB', 'ADV']):
texts_out = []
for sent in texts:
doc = nlp(" ".join(sent))
texts_out.append([token.lemma_ for token in doc if token.pos_ in allowed_postags])
return texts_out
data_words_nostops = remove_stopwords(data_words)
data_words_bigrams = make_bigrams(data_words_nostops)
nlp = spacy.load('en_core_web_md', disable=['parser', 'ner'])
data_lemmatized = lemmatization(data_words_bigrams, allowed_postags=[
'NOUN', 'ADJ', 'VERB', 'ADV'
])
print(data_lemmatized[:4]) #it will print the lemmatized data.
id2word = corpora.Dictionary(data_lemmatized)
texts = data_lemmatized
corpus = [id2word.doc2bow(text) for text in texts]
print(corpus[:4]) #it will print the corpus we created above.
[[(id2word[id], freq) for id, freq in cp] for cp in corpus[:4]]
#it will print the words with their frequencies.
lda_model = gensim.models.ldamodel.LdaModel(
corpus=corpus, id2word=id2word, num_topics=20, random_state=100,
update_every=1, chunksize=100, passes=10, alpha='auto', per_word_topics=True
)
我们现在可以使用上面创建的 LDA 模型来获取主题,并计算模型困惑度。
Gensim - 使用 LDA 主题模型
在本章中,我们将了解如何使用潜在狄利克雷分配 (LDA) 主题模型。
查看 LDA 模型中的主题
我们上面创建的 LDA 模型 (lda_model) 可用于查看文档中的主题。这可以使用以下脚本来完成:
pprint(lda_model.print_topics()) doc_lda = lda_model[corpus]
输出
[ (0, '0.036*"go" + 0.027*"get" + 0.021*"time" + 0.017*"back" + 0.015*"good" + ' '0.014*"much" + 0.014*"be" + 0.013*"car" + 0.013*"well" + 0.013*"year"'), (1, '0.078*"screen" + 0.067*"video" + 0.052*"character" + 0.046*"normal" + ' '0.045*"mouse" + 0.034*"manager" + 0.034*"disease" + 0.031*"processor" + ' '0.028*"excuse" + 0.028*"choice"'), (2, '0.776*"ax" + 0.079*"_" + 0.011*"boy" + 0.008*"ticket" + 0.006*"red" + ' '0.004*"conservative" + 0.004*"cult" + 0.004*"amazing" + 0.003*"runner" + ' '0.003*"roughly"'), (3, '0.086*"season" + 0.078*"fan" + 0.072*"reality" + 0.065*"trade" + ' '0.045*"concept" + 0.040*"pen" + 0.028*"blow" + 0.025*"improve" + ' '0.025*"cap" + 0.021*"penguin"'), (4, '0.027*"group" + 0.023*"issue" + 0.016*"case" + 0.016*"cause" + ' '0.014*"state" + 0.012*"whole" + 0.012*"support" + 0.011*"government" + ' '0.010*"year" + 0.010*"rate"'), (5, '0.133*"evidence" + 0.047*"believe" + 0.044*"religion" + 0.042*"belief" + ' '0.041*"sense" + 0.041*"discussion" + 0.034*"atheist" + 0.030*"conclusion" + ' '0.029*"explain" + 0.029*"claim"'), (6, '0.083*"space" + 0.059*"science" + 0.031*"launch" + 0.030*"earth" + ' '0.026*"route" + 0.024*"orbit" + 0.024*"scientific" + 0.021*"mission" + ' '0.018*"plane" + 0.017*"satellite"'), (7, '0.065*"file" + 0.064*"program" + 0.048*"card" + 0.041*"window" + ' '0.038*"driver" + 0.037*"software" + 0.034*"run" + 0.029*"machine" + ' '0.029*"entry" + 0.028*"version"'), (8, '0.078*"publish" + 0.059*"mount" + 0.050*"turkish" + 0.043*"armenian" + ' '0.027*"western" + 0.026*"russian" + 0.025*"locate" + 0.024*"proceed" + ' '0.024*"electrical" + 0.022*"terrorism"'), (9, '0.023*"people" + 0.023*"child" + 0.021*"kill" + 0.020*"man" + 0.019*"death" ' '+ 0.015*"die" + 0.015*"live" + 0.014*"attack" + 0.013*"age" + ' '0.011*"church"'), (10, '0.092*"cpu" + 0.085*"black" + 0.071*"controller" + 0.039*"white" + ' '0.028*"water" + 0.027*"cold" + 0.025*"solid" + 0.024*"cool" + 0.024*"heat" ' '+ 0.023*"nuclear"'), (11, '0.071*"monitor" + 0.044*"box" + 0.042*"option" + 0.041*"generate" + ' '0.038*"vote" + 0.032*"battery" + 0.029*"wave" + 0.026*"tradition" + ' '0.026*"fairly" + 0.025*"task"'), (12, '0.048*"send" + 0.045*"mail" + 0.036*"list" + 0.033*"include" + ' '0.032*"price" + 0.031*"address" + 0.027*"email" + 0.026*"receive" + ' '0.024*"book" + 0.024*"sell"'), (13, '0.515*"drive" + 0.052*"laboratory" + 0.042*"blind" + 0.020*"investment" + ' '0.011*"creature" + 0.010*"loop" + 0.005*"dialog" + 0.000*"slave" + ' '0.000*"jumper" + 0.000*"sector"'), (14, '0.153*"patient" + 0.066*"treatment" + 0.062*"printer" + 0.059*"doctor" + ' '0.036*"medical" + 0.031*"energy" + 0.029*"study" + 0.029*"probe" + ' '0.024*"mph" + 0.020*"physician"'), (15, '0.068*"law" + 0.055*"gun" + 0.039*"government" + 0.036*"right" + ' '0.029*"state" + 0.026*"drug" + 0.022*"crime" + 0.019*"person" + ' '0.019*"citizen" + 0.019*"weapon"'), (16, '0.107*"team" + 0.102*"game" + 0.078*"play" + 0.055*"win" + 0.052*"player" + ' '0.051*"year" + 0.030*"score" + 0.025*"goal" + 0.023*"wing" + 0.023*"run"'), (17, '0.031*"say" + 0.026*"think" + 0.022*"people" + 0.020*"make" + 0.017*"see" + ' '0.016*"know" + 0.013*"come" + 0.013*"even" + 0.013*"thing" + 0.013*"give"'), (18, '0.039*"system" + 0.034*"use" + 0.023*"key" + 0.016*"bit" + 0.016*"also" + ' '0.015*"information" + 0.014*"source" + 0.013*"chip" + 0.013*"available" + ' '0.010*"provide"'), (19, '0.085*"line" + 0.073*"write" + 0.053*"article" + 0.046*"organization" + ' '0.034*"host" + 0.023*"be" + 0.023*"know" + 0.017*"thank" + 0.016*"want" + ' '0.014*"help"') ]
计算模型困惑度
我们上面创建的 LDA 模型 (lda_model) 可用于计算模型的困惑度,即模型的好坏。分数越低,模型越好。这可以使用以下脚本来完成:
print('\nPerplexity: ', lda_model.log_perplexity(corpus))
输出
Perplexity: -12.338664984332151
计算一致性得分
我们上面创建的 LDA 模型(lda_model) 可用于计算模型的一致性得分,即主题中词语的成对词语相似度得分的平均值/中位数。这可以使用以下脚本来完成:
coherence_model_lda = CoherenceModel(
model=lda_model, texts=data_lemmatized, dictionary=id2word, coherence='c_v'
)
coherence_lda = coherence_model_lda.get_coherence()
print('\nCoherence Score: ', coherence_lda)
输出
Coherence Score: 0.510264381411751
可视化主题关键词
我们上面创建的 LDA 模型(lda_model) 可用于检查生成的主题和相关的关键词。可以使用pyLDAvis包对其进行可视化,如下所示:
pyLDAvis.enable_notebook() vis = pyLDAvis.gensim.prepare(lda_model, corpus, id2word) vis
输出
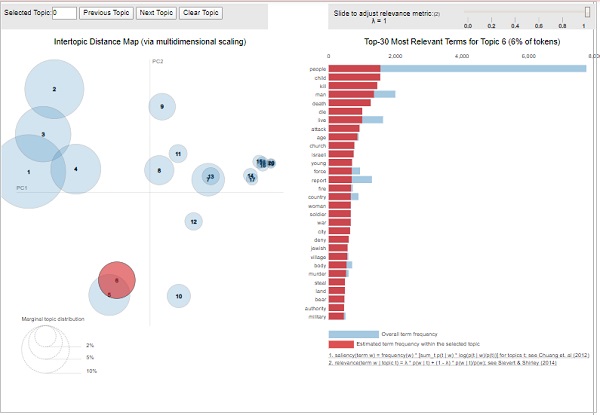
从上面的输出中,左侧的泡泡代表一个主题,泡泡越大,该主题就越普遍。如果主题模型具有散布在图表中的大型、非重叠泡泡,则该主题模型会很好。
Gensim - 创建 LDA Mallet 模型
本章将解释什么是潜在狄利克雷分配 (LDA) Mallet 模型以及如何在 Gensim 中创建相同的模型。
在上一节中,我们已经实现了 LDA 模型,并从 20Newsgroup 数据集的文档中获得了主题。那是 Gensim 自带的 LDA 算法版本。Gensim 也存在 Mallet 版本,它提供更高质量的主题。在这里,我们将对之前已经实现的示例应用 Mallet 的 LDA。
什么是 LDA Mallet 模型?
Mallet 是一个开源工具包,由 Andrew McCullum 编写。它基本上是一个基于 Java 的包,用于 NLP、文档分类、聚类、主题建模以及许多其他机器学习文本应用程序。它为我们提供了 Mallet 主题建模工具包,其中包含 LDA 以及分层 LDA 的高效基于采样的实现。
Mallet 2.0 是 MALLET(Java 主题建模工具包)的当前版本。在开始将其与 Gensim 一起用于 LDA 之前,我们必须将 mallet-2.0.8.zip 包下载到我们的系统上并解压缩它。安装并解压缩后,手动或通过我们将提供的代码(在下一步使用 Mallet 实现 LDA 时),将环境变量 %MALLET_HOME% 设置为指向 MALLET 目录。
Gensim 包装器
Python 为潜在狄利克雷分配 (LDA) 提供了 Gensim 包装器。该包装器的语法为 **gensim.models.wrappers.LdaMallet**。此模块(来自 MALLET 的折叠吉布斯采样)允许从训练语料库估计 LDA 模型,并对新的、未见过的文档推断主题分布。
实现示例
我们将对之前构建的 LDA 模型使用 LDA Mallet,并通过计算一致性分数来检查性能差异。
提供 Mallet 文件的路径
在将 Mallet LDA 模型应用于我们在前面示例中构建的语料库之前,我们必须更新环境变量并提供 Mallet 文件的路径。这可以使用以下代码完成:
import os
from gensim.models.wrappers import LdaMallet
os.environ.update({'MALLET_HOME':r'C:/mallet-2.0.8/'})
#You should update this path as per the path of Mallet directory on your system.
mallet_path = r'C:/mallet-2.0.8/bin/mallet'
#You should update this path as per the path of Mallet directory on your system.
一旦我们提供了 Mallet 文件的路径,我们现在就可以在语料库上使用它了。这可以使用 **ldamallet.show_topics()** 函数完成,如下所示:
ldamallet = gensim.models.wrappers.LdaMallet( mallet_path, corpus=corpus, num_topics=20, id2word=id2word ) pprint(ldamallet.show_topics(formatted=False))
输出
[
(4,
[('gun', 0.024546225966016102),
('law', 0.02181426826996709),
('state', 0.017633545129043606),
('people', 0.017612848479831116),
('case', 0.011341763768445888),
('crime', 0.010596684396796159),
('weapon', 0.00985160502514643),
('person', 0.008671896020034356),
('firearm', 0.00838214293105946),
('police', 0.008257963035784506)]),
(9,
[('make', 0.02147966482730431),
('people', 0.021377478029838543),
('work', 0.018557122419783363),
('money', 0.016676885346413244),
('year', 0.015982015123646026),
('job', 0.012221540976905783),
('pay', 0.010239117106069897),
('time', 0.008910688739014919),
('school', 0.0079092581238504),
('support', 0.007357449417535254)]),
(14,
[('power', 0.018428398507941996),
('line', 0.013784244460364121),
('high', 0.01183271164249895),
('work', 0.011560979224821522),
('ground', 0.010770484918850819),
('current', 0.010745781971789235),
('wire', 0.008399002000938712),
('low', 0.008053160742076529),
('water', 0.006966231071366814),
('run', 0.006892122230182061)]),
(0,
[('people', 0.025218349201353372),
('kill', 0.01500904870564167),
('child', 0.013612400660948935),
('armenian', 0.010307655991816822),
('woman', 0.010287984892595798),
('start', 0.01003226060272248),
('day', 0.00967818081674404),
('happen', 0.009383114328428673),
('leave', 0.009383114328428673),
('fire', 0.009009363443229208)]),
(1,
[('file', 0.030686386604212003),
('program', 0.02227713642901929),
('window', 0.01945561169918489),
('set', 0.015914874783314277),
('line', 0.013831003577619592),
('display', 0.013794120901412606),
('application', 0.012576992586582082),
('entry', 0.009275993066056873),
('change', 0.00872275292295209),
('color', 0.008612104894331132)]),
(12,
[('line', 0.07153810971508515),
('buy', 0.02975597944523662),
('organization', 0.026877236406682988),
('host', 0.025451316957679788),
('price', 0.025182275552207485),
('sell', 0.02461728860071565),
('mail', 0.02192687454599263),
('good', 0.018967419085797303),
('sale', 0.017998870026097017),
('send', 0.013694207538540181)]),
(11,
[('thing', 0.04901329901329901),
('good', 0.0376018876018876),
('make', 0.03393393393393394),
('time', 0.03326898326898327),
('bad', 0.02664092664092664),
('happen', 0.017696267696267698),
('hear', 0.015615615615615615),
('problem', 0.015465465465465466),
('back', 0.015143715143715144),
('lot', 0.01495066495066495)]),
(18,
[('space', 0.020626317374284855),
('launch', 0.00965716006366413),
('system', 0.008560244332602057),
('project', 0.008173097603991913),
('time', 0.008108573149223556),
('cost', 0.007764442723792318),
('year', 0.0076784101174345075),
('earth', 0.007484836753129436),
('base', 0.0067535595990880545),
('large', 0.006689035144319697)]),
(5,
[('government', 0.01918437232469453),
('people', 0.01461203206475212),
('state', 0.011207097828624796),
('country', 0.010214802708381975),
('israeli', 0.010039691804809714),
('war', 0.009436532025838587),
('force', 0.00858043427504086),
('attack', 0.008424780138532182),
('land', 0.0076659662230523775),
('world', 0.0075103120865437)]),
(2,
[('car', 0.041091194044470564),
('bike', 0.015598981291017729),
('ride', 0.011019688510138114),
('drive', 0.010627877363110981),
('engine', 0.009403467528651191),
('speed', 0.008081104907434616),
('turn', 0.007738270153785875),
('back', 0.007738270153785875),
('front', 0.007468899990204721),
('big', 0.007370947203447938)])
]
评估性能
现在我们还可以通过计算一致性分数来评估其性能,如下所示:
ldamallet = gensim.models.wrappers.LdaMallet( mallet_path, corpus=corpus, num_topics=20, id2word=id2word ) pprint(ldamallet.show_topics(formatted=False))
输出
Coherence Score: 0.5842762900901401
Gensim - 文档与 LDA 模型
本章讨论了 Gensim 中的文档和 LDA 模型。
查找 LDA 的最佳主题数量
我们可以通过创建许多具有不同主题值的 LDA 模型来找到 LDA 的最佳主题数量。在这些 LDA 中,我们可以选择一个具有最高一致性值的那个。
名为 **coherence_values_computation()** 的以下函数将训练多个 LDA 模型。它还将提供模型及其相应的一致性分数:
def coherence_values_computation(dictionary, corpus, texts, limit, start=2, step=3):
coherence_values = []
model_list = []
for num_topics in range(start, limit, step):
model = gensim.models.wrappers.LdaMallet(
mallet_path, corpus=corpus, num_topics=num_topics, id2word=id2word
)
model_list.append(model)
coherencemodel = CoherenceModel(
model=model, texts=texts, dictionary=dictionary, coherence='c_v'
)
coherence_values.append(coherencemodel.get_coherence())
return model_list, coherence_values
现在,借助以下代码,我们可以获得最佳的主题数量,我们也可以用图表来显示:
model_list, coherence_values = coherence_values_computation (
dictionary=id2word, corpus=corpus, texts=data_lemmatized,
start=1, limit=50, step=8
)
limit=50; start=1; step=8;
x = range(start, limit, step)
plt.plot(x, coherence_values)
plt.xlabel("Num Topics")
plt.ylabel("Coherence score")
plt.legend(("coherence_values"), loc='best')
plt.show()
输出
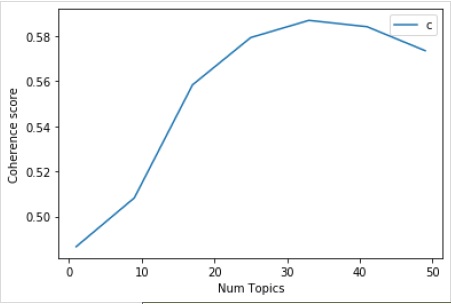
接下来,我们还可以打印各种主题的一致性值,如下所示:
for m, cv in zip(x, coherence_values):
print("Num Topics =", m, " is having Coherence Value of", round(cv, 4))
输出
Num Topics = 1 is having Coherence Value of 0.4866 Num Topics = 9 is having Coherence Value of 0.5083 Num Topics = 17 is having Coherence Value of 0.5584 Num Topics = 25 is having Coherence Value of 0.5793 Num Topics = 33 is having Coherence Value of 0.587 Num Topics = 41 is having Coherence Value of 0.5842 Num Topics = 49 is having Coherence Value of 0.5735
现在,问题出现了,我们现在应该选择哪个模型?一个好的做法是选择在变平之前给出最高一致性值的模型。因此,我们将选择具有 25 个主题的模型,在上面的列表中排名第 4。
optimal_model = model_list[3] model_topics = optimal_model.show_topics(formatted=False) pprint(optimal_model.print_topics(num_words=10)) [ (0, '0.018*"power" + 0.011*"high" + 0.010*"ground" + 0.009*"current" + ' '0.008*"low" + 0.008*"wire" + 0.007*"water" + 0.007*"work" + 0.007*"design" ' '+ 0.007*"light"'), (1, '0.036*"game" + 0.029*"team" + 0.029*"year" + 0.028*"play" + 0.020*"player" ' '+ 0.019*"win" + 0.018*"good" + 0.013*"season" + 0.012*"run" + 0.011*"hit"'), (2, '0.020*"image" + 0.019*"information" + 0.017*"include" + 0.017*"mail" + ' '0.016*"send" + 0.015*"list" + 0.013*"post" + 0.012*"address" + ' '0.012*"internet" + 0.012*"system"'), (3, '0.986*"ax" + 0.002*"_" + 0.001*"tm" + 0.000*"part" + 0.000*"biz" + ' '0.000*"mb" + 0.000*"mbs" + 0.000*"pne" + 0.000*"end" + 0.000*"di"'), (4, '0.020*"make" + 0.014*"work" + 0.013*"money" + 0.013*"year" + 0.012*"people" ' '+ 0.011*"job" + 0.010*"group" + 0.009*"government" + 0.008*"support" + ' '0.008*"question"'), (5, '0.011*"study" + 0.011*"drug" + 0.009*"science" + 0.008*"food" + ' '0.008*"problem" + 0.008*"result" + 0.008*"effect" + 0.007*"doctor" + ' '0.007*"research" + 0.007*"patient"'), (6, '0.024*"gun" + 0.024*"law" + 0.019*"state" + 0.015*"case" + 0.013*"people" + ' '0.010*"crime" + 0.010*"weapon" + 0.010*"person" + 0.008*"firearm" + ' '0.008*"police"'), (7, '0.012*"word" + 0.011*"question" + 0.011*"exist" + 0.011*"true" + ' '0.010*"religion" + 0.010*"claim" + 0.008*"argument" + 0.008*"truth" + ' '0.008*"life" + 0.008*"faith"'), (8, '0.077*"time" + 0.029*"day" + 0.029*"call" + 0.025*"back" + 0.021*"work" + ' '0.019*"long" + 0.015*"end" + 0.015*"give" + 0.014*"year" + 0.014*"week"'), (9, '0.048*"thing" + 0.041*"make" + 0.038*"good" + 0.037*"people" + ' '0.028*"write" + 0.019*"bad" + 0.019*"point" + 0.018*"read" + 0.018*"post" + ' '0.016*"idea"'), (10, '0.022*"book" + 0.020*"_" + 0.013*"man" + 0.012*"people" + 0.011*"write" + ' '0.011*"find" + 0.010*"history" + 0.010*"armenian" + 0.009*"turkish" + ' '0.009*"number"'), (11, '0.064*"line" + 0.030*"buy" + 0.028*"organization" + 0.025*"price" + ' '0.025*"sell" + 0.023*"good" + 0.021*"host" + 0.018*"sale" + 0.017*"mail" + ' '0.016*"cost"'), (12, '0.041*"car" + 0.015*"bike" + 0.011*"ride" + 0.010*"engine" + 0.009*"drive" ' '+ 0.008*"side" + 0.008*"article" + 0.007*"turn" + 0.007*"front" + ' '0.007*"speed"'), (13, '0.018*"people" + 0.011*"attack" + 0.011*"state" + 0.011*"israeli" + ' '0.010*"war" + 0.010*"country" + 0.010*"government" + 0.009*"live" + ' '0.009*"give" + 0.009*"land"'), (14, '0.037*"file" + 0.026*"line" + 0.021*"read" + 0.019*"follow" + ' '0.018*"number" + 0.015*"program" + 0.014*"write" + 0.012*"entry" + ' '0.012*"give" + 0.011*"check"'), (15, '0.196*"write" + 0.172*"line" + 0.165*"article" + 0.117*"organization" + ' '0.086*"host" + 0.030*"reply" + 0.010*"university" + 0.008*"hear" + ' '0.007*"post" + 0.007*"news"'), (16, '0.021*"people" + 0.014*"happen" + 0.014*"child" + 0.012*"kill" + ' '0.011*"start" + 0.011*"live" + 0.010*"fire" + 0.010*"leave" + 0.009*"hear" ' '+ 0.009*"home"'), (17, '0.038*"key" + 0.018*"system" + 0.015*"space" + 0.015*"technology" + ' '0.014*"encryption" + 0.010*"chip" + 0.010*"bit" + 0.009*"launch" + ' '0.009*"public" + 0.009*"government"'), (18, '0.035*"drive" + 0.031*"system" + 0.027*"problem" + 0.027*"card" + ' '0.020*"driver" + 0.017*"bit" + 0.017*"work" + 0.016*"disk" + ' '0.014*"monitor" + 0.014*"machine"'), (19, '0.031*"window" + 0.020*"run" + 0.018*"color" + 0.018*"program" + ' '0.017*"application" + 0.016*"display" + 0.015*"set" + 0.015*"version" + ' '0.012*"screen" + 0.012*"problem"') ]
查找句子中的主要主题
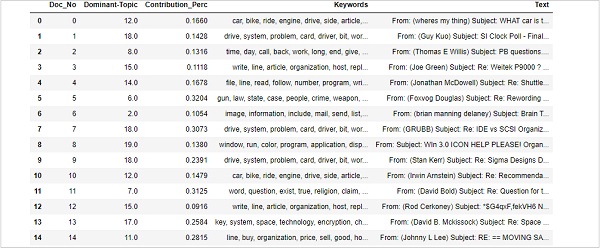
查找句子中的主要主题是主题建模最有用的一些实际应用之一。它确定给定文档的主题。在这里,我们将找到在该特定文档中贡献百分比最高的主题编号。为了汇总表格中的信息,我们将创建一个名为 **dominant_topics()** 的函数:
def dominant_topics(ldamodel=lda_model, corpus=corpus, texts=data): sent_topics_df = pd.DataFrame()
接下来,我们将获取每个文档中的主要主题:
for i, row in enumerate(ldamodel[corpus]): row = sorted(row, key=lambda x: (x[1]), reverse=True)
接下来,我们将获取每个文档的主要主题、百分比贡献和关键词:
for j, (topic_num, prop_topic) in enumerate(row):
if j == 0: # => dominant topic
wp = ldamodel.show_topic(topic_num)
topic_keywords = ", ".join([word for word, prop in wp])
sent_topics_df = sent_topics_df.append(
pd.Series([int(topic_num), round(prop_topic,4), topic_keywords]), ignore_index=True
)
else:
break
sent_topics_df.columns = ['Dominant_Topic', 'Perc_Contribution', 'Topic_Keywords']
借助以下代码,我们将原始文本添加到输出的结尾:
contents = pd.Series(texts) sent_topics_df = pd.concat([sent_topics_df, contents], axis=1) return(sent_topics_df) df_topic_sents_keywords = dominant_topics( ldamodel=optimal_model, corpus=corpus, texts=data )
现在,对句子中的主题进行格式化,如下所示:
df_dominant_topic = df_topic_sents_keywords.reset_index() df_dominant_topic.columns = [ 'Document_No', 'Dominant_Topic', 'Topic_Perc_Contrib', 'Keywords', 'Text' ]
最后,我们可以显示主要主题,如下所示:
df_dominant_topic.head(15)
查找最具代表性的文档
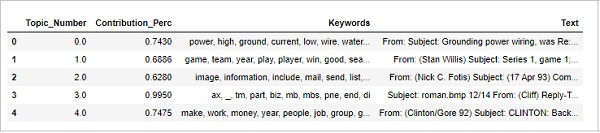
为了更多地了解主题,我们还可以找到给定主题贡献最多的文档。我们可以通过阅读该特定文档来推断该主题。
sent_topics_sorteddf_mallet = pd.DataFrame()
sent_topics_outdf_grpd = df_topic_sents_keywords.groupby('Dominant_Topic')
for i, grp in sent_topics_outdf_grpd:
sent_topics_sorteddf_mallet = pd.concat([sent_topics_sorteddf_mallet,
grp.sort_values(['Perc_Contribution'], ascending=[0]).head(1)], axis=0)
sent_topics_sorteddf_mallet.reset_index(drop=True, inplace=True)
sent_topics_sorteddf_mallet.columns = [
'Topic_Number', "Contribution_Perc", "Keywords", "Text"
]
sent_topics_sorteddf_mallet.head()
输出
主题的卷和分布
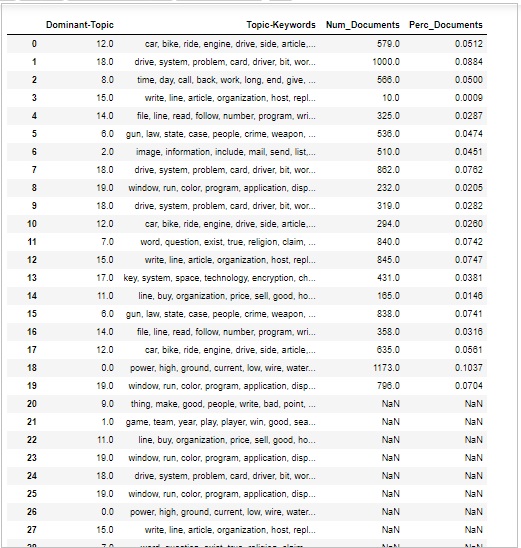
有时我们还想判断主题在文档中的讨论范围。为此,我们需要了解主题在文档中的数量和分布。
首先计算每个主题的文档数量,如下所示:
topic_counts = df_topic_sents_keywords['Dominant_Topic'].value_counts()
接下来,计算每个主题的文档百分比,如下所示:
topic_contribution = round(topic_counts/topic_counts.sum(), 4)
现在找到主题编号和关键词,如下所示:
topic_num_keywords = df_topic_sents_keywords[['Dominant_Topic', 'Topic_Keywords']]
现在,按列连接它们,如下所示:
df_dominant_topics = pd.concat( [topic_num_keywords, topic_counts, topic_contribution], axis=1 )
接下来,我们将更改列名,如下所示:
df_dominant_topics.columns = [ 'Dominant-Topic', 'Topic-Keywords', 'Num_Documents', 'Perc_Documents' ] df_dominant_topics
输出
Gensim - 创建 LSI 和 HDP 主题模型
本章介绍了使用 Gensim 创建潜在语义索引 (LSI) 和分层狄利克雷过程 (HDP) 主题模型。
首先在 Gensim 中使用潜在狄利克雷分配 (LDA) 实现的主题建模算法是 **潜在语义索引 (LSI)**。它也称为 **潜在语义分析 (LSA)**。它于 1988 年由 Scott Deerwester、Susan Dumais、George Furnas、Richard Harshman、Thomas Landaur、Karen Lochbaum 和 Lynn Streeter 获得专利。
在本节中,我们将设置我们的 LSI 模型。这可以通过与设置 LDA 模型相同的方式完成。我们需要从 **gensim.models** 导入 LSI 模型。
LSI 的作用
实际上,LSI 是一种 NLP 技术,尤其是在分布式语义中。它分析一组文档及其包含的术语之间的关系。如果我们谈论它的工作原理,那么它会构建一个矩阵,该矩阵包含来自大量文本的每个文档的词数。
构建后,为了减少行数,LSI 模型使用称为奇异值分解 (SVD) 的数学技术。除了减少行数外,它还保留列之间的相似性结构。
在矩阵中,行表示唯一单词,列表示每个文档。它基于分布式假设工作,即它假设含义相近的词会出现在相同类型的文本中。
使用 Gensim 实现
在这里,我们将使用 LSI(潜在语义索引)从数据集中提取自然讨论的主题。
加载数据集
我们将使用的数据集是“20 个新闻组”的数据集,其中包含来自新闻报道各个部分的数千篇新闻文章。它可在Sklearn数据集下找到。我们可以轻松地使用以下 Python 脚本来下载:
from sklearn.datasets import fetch_20newsgroups newsgroups_train = fetch_20newsgroups(subset='train')
让我们借助以下脚本来查看一些示例新闻:
newsgroups_train.data[:4] ["From: lerxst@wam.umd.edu (where's my thing)\nSubject: WHAT car is this!?\nNntp-Posting-Host: rac3.wam.umd.edu\nOrganization: University of Maryland, College Park\nLines: 15\n\n I was wondering if anyone out there could enlighten me on this car I saw\nthe other day. It was a 2-door sports car, looked to be from the late 60s/\nearly 70s. It was called a Bricklin. The doors were really small. In addition,\nthe front bumper was separate from the rest of the body. This is \nall I know. If anyone can tellme a model name, engine specs, years\nof production, where this car is made, history, or whatever info you\nhave on this funky looking car, please e-mail.\n\nThanks,\n- IL\n ---- brought to you by your neighborhood Lerxst ----\n\n\n\n\n", "From: guykuo@carson.u.washington.edu (Guy Kuo)\nSubject: SI Clock Poll - Final Call\nSummary: Final call for SI clock reports\nKeywords: SI,acceleration,clock,upgrade\nArticle-I.D.: shelley.1qvfo9INNc3s\nOrganization: University of Washington\nLines: 11\nNNTP-Posting-Host: carson.u.washington.edu\n\nA fair number of brave souls who upgraded their SI clock oscillator have\nshared their experiences for this poll. Please send a brief message detailing\nyour experiences with the procedure. Top speed attained, CPU rated speed,\nadd on cards and adapters, heat sinks, hour of usage per day, floppy disk\nfunctionality with 800 and 1.4 m floppies are especially requested.\n\nI will be summarizing in the next two days, so please add to the network\nknowledge base if you have done the clock upgrade and haven't answered this\npoll. Thanks.\n\nGuy Kuo <guykuo@u.washington.edu>\n", 'From: twillis@ec.ecn.purdue.edu (Thomas E Willis)\nSubject: PB questions...\nOrganization: Purdue University Engineering Computer Network\nDistribution: usa\nLines: 36\n\nwell folks, my mac plus finally gave up the ghost this weekend after\nstarting life as a 512k way back in 1985. sooo, i\'m in the market for a\nnew machine a bit sooner than i intended to be...\n\ni\'m looking into picking up a powerbook 160 or maybe 180 and have a bunch\nof questions that (hopefully) somebody can answer:\n\n* does anybody know any dirt on when the next round of powerbook\nintroductions are expected? i\'d heard the 185c was supposed to make an\nappearence "this summer" but haven\'t heard anymore on it - and since i\ndon\'t have access to macleak, i was wondering if anybody out there had\nmore info...\n\n* has anybody heard rumors about price drops to the powerbook line like the\nones the duo\'s just went through recently?\n\n* what\'s the impression of the display on the 180? i could probably swing\na 180 if i got the 80Mb disk rather than the 120, but i don\'t really have\na feel for how much "better" the display is (yea, it looks great in the\nstore, but is that all "wow" or is it really that good?). could i solicit\nsome opinions of people who use the 160 and 180 day-to-day on if its worth\ntaking the disk size and money hit to get the active display? (i realize\nthis is a real subjective question, but i\'ve only played around with the\nmachines in a computer store breifly and figured the opinions of somebody\nwho actually uses the machine daily might prove helpful).\n\n* how well does hellcats perform? ;)\n\nthanks a bunch in advance for any info - if you could email, i\'ll post a\nsummary (news reading time is at a premium with finals just around the\ncorner... :( )\n--\nTom Willis \\ twillis@ecn.purdue.edu \\ Purdue Electrical Engineering\n---------------------------------------------------------------------------\ n"Convictions are more dangerous enemies of truth than lies." - F. W.\nNietzsche\n', 'From: jgreen@amber (Joe Green)\nSubject: Re: Weitek P9000 ?\nOrganization: Harris Computer Systems Division\nLines: 14\nDistribution: world\nNNTP-Posting-Host: amber.ssd.csd.harris.com\nX-Newsreader: TIN [version 1.1 PL9]\n\nRobert J.C. Kyanko (rob@rjck.UUCP) wrote:\n > abraxis@iastate.edu writes in article < abraxis.734340159@class1.iastate.edu>:\n> > Anyone know about the Weitek P9000 graphics chip?\n > As far as the low-level stuff goes, it looks pretty nice. It\'s got this\n > quadrilateral fill command that requires just the four points.\n\nDo you have Weitek\'s address/phone number? I\'d like to get some information\nabout this chip.\n\n--\nJoe Green\t\t\t\tHarris Corporation\njgreen@csd.harris.com\t\t\tComputer Systems Division\n"The only thing that really scares me is a person with no sense of humor."\n\t\t\t\t\t\t-- Jonathan Winters\n']
先决条件
我们需要来自 NLTK 的停用词和来自 Scapy 的英语模型。两者都可以按如下方式下载:
import nltk;
nltk.download('stopwords')
nlp = spacy.load('en_core_web_md', disable=['parser', 'ner'])
导入必要的包
为了构建 LSI 模型,我们需要导入以下必要的包:
import re import numpy as np import pandas as pd from pprint import pprint import gensim import gensim.corpora as corpora from gensim.utils import simple_preprocess from gensim.models import CoherenceModel import spacy import matplotlib.pyplot as plt
准备停用词
现在我们需要导入停用词并使用它们:
from nltk.corpus import stopwords
stop_words = stopwords.words('english')
stop_words.extend(['from', 'subject', 're', 'edu', 'use'])
清理文本
现在,借助 Gensim 的simple_preprocess(),我们需要将每个句子标记化为词语列表。我们还应该删除标点符号和不必要的字符。为此,我们将创建一个名为sent_to_words()的函数:
def sent_to_words(sentences):
for sentence in sentences:
yield(gensim.utils.simple_preprocess(str(sentence), deacc=True))
data_words = list(sent_to_words(data))
构建二元组和三元组模型
众所周知,双词是文档中经常一起出现的两个词,三词是文档中经常一起出现的三个词。借助 Gensim 的 Phrases 模型,我们可以做到这一点:
bigram = gensim.models.Phrases(data_words, min_count=5, threshold=100) trigram = gensim.models.Phrases(bigram[data_words], threshold=100) bigram_mod = gensim.models.phrases.Phraser(bigram) trigram_mod = gensim.models.phrases.Phraser(trigram)
过滤掉停用词
接下来,我们需要过滤掉停用词。除此之外,我们还将创建用于创建二元组、三元组和词形还原的函数:
def remove_stopwords(texts):
return [[word for word in simple_preprocess(str(doc))
if word not in stop_words] for doc in texts]
def make_bigrams(texts):
return [bigram_mod[doc] for doc in texts]
def make_trigrams(texts):
return [trigram_mod[bigram_mod[doc]] for doc in texts]
def lemmatization(texts, allowed_postags=['NOUN', 'ADJ', 'VERB', 'ADV']):
texts_out = []
for sent in texts:
doc = nlp(" ".join(sent))
texts_out.append([token.lemma_ for token in doc if token.pos_ in allowed_postags])
return texts_out
为主题模型构建字典和语料库
我们现在需要构建字典和语料库。我们之前也做过:
id2word = corpora.Dictionary(data_lemmatized) texts = data_lemmatized corpus = [id2word.doc2bow(text) for text in texts]
构建 LSI 主题模型
我们已经实现了训练 LSI 模型所需的一切。现在,是时候构建 LSI 主题模型了。对于我们的实现示例,这可以使用以下几行代码完成:
lsi_model = gensim.models.lsimodel.LsiModel( corpus=corpus, id2word=id2word, num_topics=20,chunksize=100 )
实现示例
让我们看看构建 LDA 主题模型的完整实现示例:
import re
import numpy as np
import pandas as pd
from pprint import pprint
import gensim
import gensim.corpora as corpora
from gensim.utils import simple_preprocess
from gensim.models import CoherenceModel
import spacy
import matplotlib.pyplot as plt
from nltk.corpus import stopwords
stop_words = stopwords.words('english')
stop_words.extend(['from', 'subject', 're', 'edu', 'use'])
from sklearn.datasets import fetch_20newsgroups
newsgroups_train = fetch_20newsgroups(subset='train')
data = newsgroups_train.data
data = [re.sub('\S*@\S*\s?', '', sent) for sent in data]
data = [re.sub('\s+', ' ', sent) for sent in data]
data = [re.sub("\'", "", sent) for sent in data]
print(data_words[:4]) #it will print the data after prepared for stopwords
bigram = gensim.models.Phrases(data_words, min_count=5, threshold=100)
trigram = gensim.models.Phrases(bigram[data_words], threshold=100)
bigram_mod = gensim.models.phrases.Phraser(bigram)
trigram_mod = gensim.models.phrases.Phraser(trigram)
def remove_stopwords(texts):
return [[word for word in simple_preprocess(str(doc))
if word not in stop_words] for doc in texts]
def make_bigrams(texts):
return [bigram_mod[doc] for doc in texts]
def make_trigrams(texts):
return [trigram_mod[bigram_mod[doc]] for doc in texts]
def lemmatization(texts, allowed_postags=['NOUN', 'ADJ', 'VERB', 'ADV']):
texts_out = []
for sent in texts:
doc = nlp(" ".join(sent))
texts_out.append([token.lemma_ for token in doc if token.pos_ in allowed_postags])
return texts_out
data_words_nostops = remove_stopwords(data_words)
data_words_bigrams = make_bigrams(data_words_nostops)
nlp = spacy.load('en_core_web_md', disable=['parser', 'ner'])
data_lemmatized = lemmatization(
data_words_bigrams, allowed_postags=['NOUN', 'ADJ', 'VERB', 'ADV']
)
print(data_lemmatized[:4]) #it will print the lemmatized data.
id2word = corpora.Dictionary(data_lemmatized)
texts = data_lemmatized
corpus = [id2word.doc2bow(text) for text in texts]
print(corpus[:4]) #it will print the corpus we created above.
[[(id2word[id], freq) for id, freq in cp] for cp in corpus[:4]]
#it will print the words with their frequencies.
lsi_model = gensim.models.lsimodel.LsiModel(
corpus=corpus, id2word=id2word, num_topics=20,chunksize=100
)
我们现在可以使用上面创建的 LSI 模型来获取主题。
查看 LSI 模型中的主题
我们上面创建的 LSI 模型 **(lsi_model)** 可用于查看文档中的主题。这可以使用以下脚本完成:
pprint(lsi_model.print_topics()) doc_lsi = lsi_model[corpus]
输出
[ (0, '1.000*"ax" + 0.001*"_" + 0.000*"tm" + 0.000*"part" + 0.000*"pne" + ' '0.000*"biz" + 0.000*"mbs" + 0.000*"end" + 0.000*"fax" + 0.000*"mb"'), (1, '0.239*"say" + 0.222*"file" + 0.189*"go" + 0.171*"know" + 0.169*"people" + ' '0.147*"make" + 0.140*"use" + 0.135*"also" + 0.133*"see" + 0.123*"think"') ]
分层狄利克雷过程 (HPD)
LDA 和 LSI 等主题模型有助于总结和组织无法手动分析的大型文本档案。除了 LDA 和 LSI 之外,Gensim 中另一个强大的主题模型是 HDP(分层狄利克雷过程)。它基本上是用于分组数据的无监督分析的混合成员模型。与 LDA(其有限对应物)不同,HDP 从数据中推断主题数量。
使用 Gensim 实现
要在 Gensim 中实现 HDP,我们需要训练语料库和字典(如在上面实现 LDA 和 LSI 主题模型的示例中所做的那样)我们可以从 gensim.models.HdpModel 导入 HDP 主题模型。在这里,我们还将在 20Newsgroup 数据上实现 HDP 主题模型,步骤也相同。
对于我们的语料库和字典(在上面为 LSI 和 LDA 模型创建的示例中),我们可以按如下方式导入 HdpModel:
Hdp_model = gensim.models.hdpmodel.HdpModel(corpus=corpus, id2word=id2word)
查看 LSI 模型中的主题
HDP 模型 **(Hdp_model)** 可用于查看文档中的主题。这可以使用以下脚本完成:
pprint(Hdp_model.print_topics())
输出
[ (0, '0.009*line + 0.009*write + 0.006*say + 0.006*article + 0.006*know + ' '0.006*people + 0.005*make + 0.005*go + 0.005*think + 0.005*be'), (1, '0.016*line + 0.011*write + 0.008*article + 0.008*organization + 0.006*know ' '+ 0.006*host + 0.006*be + 0.005*get + 0.005*use + 0.005*say'), (2, '0.810*ax + 0.001*_ + 0.000*tm + 0.000*part + 0.000*mb + 0.000*pne + ' '0.000*biz + 0.000*end + 0.000*wwiz + 0.000*fax'), (3, '0.015*line + 0.008*write + 0.007*organization + 0.006*host + 0.006*know + ' '0.006*article + 0.005*use + 0.005*thank + 0.004*get + 0.004*problem'), (4, '0.004*line + 0.003*write + 0.002*believe + 0.002*think + 0.002*article + ' '0.002*belief + 0.002*say + 0.002*see + 0.002*look + 0.002*organization'), (5, '0.005*line + 0.003*write + 0.003*organization + 0.002*article + 0.002*time ' '+ 0.002*host + 0.002*get + 0.002*look + 0.002*say + 0.001*number'), (6, '0.003*line + 0.002*say + 0.002*write + 0.002*go + 0.002*gun + 0.002*get + ' '0.002*organization + 0.002*bill + 0.002*article + 0.002*state'), (7, '0.003*line + 0.002*write + 0.002*article + 0.002*organization + 0.001*none ' '+ 0.001*know + 0.001*say + 0.001*people + 0.001*host + 0.001*new'), (8, '0.004*line + 0.002*write + 0.002*get + 0.002*team + 0.002*organization + ' '0.002*go + 0.002*think + 0.002*know + 0.002*article + 0.001*well'), (9, '0.004*line + 0.002*organization + 0.002*write + 0.001*be + 0.001*host + ' '0.001*article + 0.001*thank + 0.001*use + 0.001*work + 0.001*run'), (10, '0.002*line + 0.001*game + 0.001*write + 0.001*get + 0.001*know + ' '0.001*thing + 0.001*think + 0.001*article + 0.001*help + 0.001*turn'), (11, '0.002*line + 0.001*write + 0.001*game + 0.001*organization + 0.001*say + ' '0.001*host + 0.001*give + 0.001*run + 0.001*article + 0.001*get'), (12, '0.002*line + 0.001*write + 0.001*know + 0.001*time + 0.001*article + ' '0.001*get + 0.001*think + 0.001*organization + 0.001*scope + 0.001*make'), (13, '0.002*line + 0.002*write + 0.001*article + 0.001*organization + 0.001*make ' '+ 0.001*know + 0.001*see + 0.001*get + 0.001*host + 0.001*really'), (14, '0.002*write + 0.002*line + 0.002*know + 0.001*think + 0.001*say + ' '0.001*article + 0.001*argument + 0.001*even + 0.001*card + 0.001*be'), (15, '0.001*article + 0.001*line + 0.001*make + 0.001*write + 0.001*know + ' '0.001*say + 0.001*exist + 0.001*get + 0.001*purpose + 0.001*organization'), (16, '0.002*line + 0.001*write + 0.001*article + 0.001*insurance + 0.001*go + ' '0.001*be + 0.001*host + 0.001*say + 0.001*organization + 0.001*part'), (17, '0.001*line + 0.001*get + 0.001*hit + 0.001*go + 0.001*write + 0.001*say + ' '0.001*know + 0.001*drug + 0.001*see + 0.001*need'), (18, '0.002*option + 0.001*line + 0.001*flight + 0.001*power + 0.001*software + ' '0.001*write + 0.001*add + 0.001*people + 0.001*organization + 0.001*module'), (19, '0.001*shuttle + 0.001*line + 0.001*roll + 0.001*attitude + 0.001*maneuver + ' '0.001*mission + 0.001*also + 0.001*orbit + 0.001*produce + 0.001*frequency') ]
Gensim - 开发词嵌入
本章将帮助我们理解在 Gensim 中开发词嵌入。
词嵌入,表示词和文档的方法,是文本的密集向量表示,其中具有相同含义的词具有相似的表示。以下是词嵌入的一些特征:
它是一类技术,它将单个词表示为预定义向量空间中的实值向量。
这种技术通常被归入深度学习 (DL) 领域,因为每个词都映射到一个向量,并且向量的值以与神经网络 (NN) 相同的方式学习。
词嵌入技术的关键方法是每个词的密集分布式表示。
不同的词嵌入方法/算法
如上所述,词嵌入方法/算法从文本语料库中学习实值向量表示。这种学习过程可以使用 NN 模型进行文档分类等任务,或者是一个无监督过程,例如文档统计。在这里,我们将讨论两种可以用来从文本中学习词嵌入的方法/算法:
Google 的 Word2Vec
Word2Vec 由 Tomas Mikolov 等人在 Google 于 2013 年开发,是一种从文本语料库有效学习词嵌入的统计方法。它实际上是作为对使基于 NN 的词嵌入训练更高效的回应而开发的。它已成为词嵌入的事实标准。
Word2Vec 词向量嵌入涉及对学习到的向量的分析以及对单词表示的向量数学的探索。以下是可以用作 Word2Vec 方法一部分的两种不同的学习方法:
- CBoW(连续词袋)模型
- 连续 Skip-Gram 模型
斯坦福大学的 GloVe
GloVe(用于单词表示的全局向量)是 Word2Vec 方法的扩展。它由斯坦福大学的 Pennington 等人开发。GloVe 算法结合了以下两种方法:
- 矩阵分解技术的全局统计,例如 LSA(潜在语义分析)
- Word2Vec 中基于局部上下文的学习。
如果我们谈论它的工作原理,那么 GloVe 不是使用窗口来定义局部上下文,而是使用整个文本语料库的统计数据来构建显式的词共现矩阵。
开发 Word2Vec 嵌入
在这里,我们将使用 Gensim 开发 Word2Vec 嵌入。为了使用 Word2Vec 模型,Gensim 为我们提供了Word2Vec 类,可以从models.word2vec导入。为了实现它,word2vec 需要大量的文本,例如整个亚马逊评论语料库。但是在这里,我们将这个原理应用于小型内存文本。
实现示例
首先,我们需要从 gensim.models 导入 Word2Vec 类,如下所示:
from gensim.models import Word2Vec
接下来,我们需要定义训练数据。我们不是使用大型文本文件,而是使用一些句子来实现这个原理。
sentences = [ ['this', 'is', 'gensim', 'tutorial', 'for', 'free'], ['this', 'is', 'the', 'tutorials' 'point', 'website'], ['you', 'can', 'read', 'technical','tutorials', 'for','free'], ['we', 'are', 'implementing','word2vec'], ['learn', 'full', 'gensim', 'tutorial'] ]
一旦提供训练数据,我们就需要训练模型。可以按如下方式进行:
model = Word2Vec(sentences, min_count=1)
我们可以对模型进行如下总结:
print(model)
我们可以对词汇表进行如下总结:
words = list(model.wv.vocab) print(words)
接下来,让我们访问一个单词的向量。我们正在对单词“tutorial”进行操作。
print(model['tutorial'])
接下来,我们需要保存模型:
model.save('model.bin')
接下来,我们需要加载模型:
new_model = Word2Vec.load('model.bin')
最后,打印保存的模型,如下所示:
print(new_model)
完整的实现示例
from gensim.models import Word2Vec
sentences = [
['this', 'is', 'gensim', 'tutorial', 'for', 'free'],
['this', 'is', 'the', 'tutorials' 'point', 'website'],
['you', 'can', 'read', 'technical','tutorials', 'for','free'],
['we', 'are', 'implementing','word2vec'],
['learn', 'full', 'gensim', 'tutorial']
]
model = Word2Vec(sentences, min_count=1)
print(model)
words = list(model.wv.vocab)
print(words)
print(model['tutorial'])
model.save('model.bin')
new_model = Word2Vec.load('model.bin')
print(new_model)
输出
Word2Vec(vocab=20, size=100, alpha=0.025) [ 'this', 'is', 'gensim', 'tutorial', 'for', 'free', 'the', 'tutorialspoint', 'website', 'you', 'can', 'read', 'technical', 'tutorials', 'we', 'are', 'implementing', 'word2vec', 'learn', 'full' ] [ -2.5256255e-03 -4.5352755e-03 3.9024993e-03 -4.9509313e-03 -1.4255195e-03 -4.0217536e-03 4.9407515e-03 -3.5925603e-03 -1.1933431e-03 -4.6682903e-03 1.5440651e-03 -1.4101702e-03 3.5070938e-03 1.0914479e-03 2.3334436e-03 2.4452661e-03 -2.5336299e-04 -3.9676363e-03 -8.5054158e-04 1.6443320e-03 -4.9968651e-03 1.0974540e-03 -1.1123562e-03 1.5393364e-03 9.8941079e-04 -1.2656028e-03 -4.4471184e-03 1.8309267e-03 4.9302122e-03 -1.0032534e-03 4.6892050e-03 2.9563988e-03 1.8730218e-03 1.5343715e-03 -1.2685956e-03 8.3664013e-04 4.1721235e-03 1.9445885e-03 2.4097660e-03 3.7517555e-03 4.9687522e-03 -1.3598346e-03 7.1032363e-04 -3.6595813e-03 6.0000515e-04 3.0872561e-03 -3.2115565e-03 3.2270295e-03 -2.6354722e-03 -3.4988276e-04 1.8574356e-04 -3.5757164e-03 7.5391348e-04 -3.5205986e-03 -1.9795434e-03 -2.8321696e-03 4.7155009e-03 -4.3349937e-04 -1.5320212e-03 2.7013756e-03 -3.7055744e-03 -4.1658725e-03 4.8034848e-03 4.8594419e-03 3.7129463e-03 4.2385766e-03 2.4612297e-03 5.4920948e-04 -3.8912550e-03 -4.8226118e-03 -2.2763973e-04 4.5571579e-03 -3.4609400e-03 2.7903817e-03 -3.2709218e-03 -1.1036445e-03 2.1492650e-03 -3.0384419e-04 1.7709908e-03 1.8429896e-03 -3.4038599e-03 -2.4872608e-03 2.7693063e-03 -1.6352943e-03 1.9182395e-03 3.7772327e-03 2.2769428e-03 -4.4629495e-03 3.3151123e-03 4.6509290e-03 -4.8521687e-03 6.7615538e-04 3.1034781e-03 2.6369948e-05 4.1454583e-03 -3.6932561e-03 -1.8769916e-03 -2.1958587e-04 6.3395966e-04 -2.4969708e-03 ] Word2Vec(vocab=20, size=100, alpha=0.025)
可视化词向量嵌入
我们还可以通过可视化来探索词向量嵌入。这可以通过使用经典的投影方法(如 PCA)将高维词向量降维到二维图来完成。降维后,我们就可以将它们绘制在图表上。
使用 PCA 绘制词向量
首先,我们需要从训练好的模型中检索所有向量,如下所示:
Z = model[model.wv.vocab]
接下来,我们需要使用 PCA 类创建一个词向量的二维 PCA 模型,如下所示:
pca = PCA(n_components=2) result = pca.fit_transform(Z)
现在,我们可以使用 matplotlib 绘制生成的投影,如下所示:
Pyplot.scatter(result[:,0],result[:,1])
我们还可以用单词本身来注释图表上的点。使用 matplotlib 绘制生成的投影,如下所示:
words = list(model.wv.vocab) for i, word in enumerate(words): pyplot.annotate(word, xy=(result[i, 0], result[i, 1]))
完整的实现示例
from gensim.models import Word2Vec from sklearn.decomposition import PCA from matplotlib import pyplot sentences = [ ['this', 'is', 'gensim', 'tutorial', 'for', 'free'], ['this', 'is', 'the', 'tutorials' 'point', 'website'], ['you', 'can', 'read', 'technical','tutorials', 'for','free'], ['we', 'are', 'implementing','word2vec'], ['learn', 'full', 'gensim', 'tutorial'] ] model = Word2Vec(sentences, min_count=1) X = model[model.wv.vocab] pca = PCA(n_components=2) result = pca.fit_transform(X) pyplot.scatter(result[:, 0], result[:, 1]) words = list(model.wv.vocab) for i, word in enumerate(words): pyplot.annotate(word, xy=(result[i, 0], result[i, 1])) pyplot.show()
输出
Gensim - Doc2Vec 模型
与 Word2Vec 模型相反,Doc2Vec 模型用于创建对作为单个单元整体获取的一组单词的向量化表示。它不仅仅是对句子中单词的简单平均。
使用 Doc2Vec 创建文档向量
在这里,为了使用 Doc2Vec 创建文档向量,我们将使用 text8 数据集,可以从gensim.downloader下载。
下载数据集
我们可以使用以下命令下载 text8 数据集:
import gensim
import gensim.downloader as api
dataset = api.load("text8")
data = [d for d in dataset]
下载 text8 数据集需要一些时间。
训练 Doc2Vec
为了训练模型,我们需要标记的文档,可以使用models.doc2vec.TaggedDocument()创建,如下所示:
def tagged_document(list_of_list_of_words):
for i, list_of_words in enumerate(list_of_list_of_words):
yield gensim.models.doc2vec.TaggedDocument(list_of_words, [i])
data_for_training = list(tagged_document(data))
我们可以打印训练好的数据集,如下所示:
print(data_for_training [:1])
输出
[TaggedDocument(words=['anarchism', 'originated', 'as', 'a', 'term', 'of', 'abuse', 'first', 'used', 'against', 'early', 'working', 'class', 'radicals', 'including', 'the', 'diggers', 'of', 'the', 'english', 'revolution', 'and', 'the', 'sans', 'culottes', 'of', 'the', 'french', 'revolution', 'whilst', 'the', 'term', 'is', 'still', 'used', 'in', 'a', 'pejorative', 'way', 'to', 'describe', 'any', 'act', 'that', 'used', 'violent', 'means', 'to', 'destroy', 'the', 'organization', 'of', 'society', 'it', 'has', 'also', 'been' , 'taken', 'up', 'as', 'a', 'positive', 'label', 'by', 'self', 'defined', 'anarchists', 'the', 'word', 'anarchism', 'is', 'derived', 'from', 'the', 'greek', 'without', 'archons', 'ruler', 'chief', 'king', 'anarchism', 'as', 'a', 'political', 'philosophy', 'is', 'the', 'belief', 'that', 'rulers', 'are', 'unnecessary', 'and', 'should', 'be', 'abolished', 'although', 'there', 'are', 'differing', 'interpretations', 'of', 'what', 'this', 'means', 'anarchism', 'also', 'refers', 'to', 'related', 'social', 'movements', 'that', 'advocate', 'the', 'elimination', 'of', 'authoritarian', 'institutions', 'particularly', 'the', 'state', 'the', 'word', 'anarchy', 'as', 'most', 'anarchists', 'use', 'it', 'does', 'not', 'imply', 'chaos', 'nihilism', 'or', 'anomie', 'but', 'rather', 'a', 'harmonious', 'anti', 'authoritarian', 'society', 'in', 'place', 'of', 'what', 'are', 'regarded', 'as', 'authoritarian', 'political', 'structures', 'and', 'coercive', 'economic', 'institutions', 'anarchists', 'advocate', 'social', 'relations', 'based', 'upon', 'voluntary', 'association', 'of', 'autonomous', 'individuals', 'mutual', 'aid', 'and', 'self', 'governance', 'while', 'anarchism', 'is', 'most', 'easily', 'defined', 'by', 'what', 'it', 'is', 'against', 'anarchists', 'also', 'offer', 'positive', 'visions', 'of', 'what', 'they', 'believe', 'to', 'be', 'a', 'truly', 'free', 'society', 'however', 'ideas', 'about', 'how', 'an', 'anarchist', 'society', 'might', 'work', 'vary', 'considerably', 'especially', 'with', 'respect', 'to', 'economics', 'there', 'is', 'also', 'disagreement', 'about', 'how', 'a', 'free', 'society', 'might', 'be', 'brought', 'about', 'origins', 'and', 'predecessors', 'kropotkin', 'and', 'others', 'argue', 'that', 'before', 'recorded', 'history', 'human', 'society', 'was', 'organized', 'on', 'anarchist', 'principles', 'most', 'anthropologists', 'follow', 'kropotkin', 'and', 'engels', 'in', 'believing', 'that', 'hunter', 'gatherer', 'bands', 'were', 'egalitarian', 'and', 'lacked', 'division', 'of', 'labour', 'accumulated', 'wealth', 'or', 'decreed', 'law', 'and', 'had', 'equal', 'access', 'to', 'resources', 'william', 'godwin', 'anarchists', 'including', 'the', 'the', 'anarchy', 'organisation', 'and', 'rothbard', 'find', 'anarchist', 'attitudes', 'in', 'taoism', 'from', 'ancient', 'china', 'kropotkin', 'found', 'similar', 'ideas', 'in', 'stoic', 'zeno', 'of', 'citium', 'according', 'to', 'kropotkin', 'zeno', 'repudiated', 'the', 'omnipotence', 'of', 'the', 'state', 'its', 'intervention', 'and', 'regimentation', 'and', 'proclaimed', 'the', 'sovereignty', 'of', 'the', 'moral', 'law', 'of', 'the', 'individual', 'the', 'anabaptists', 'of', 'one', 'six', 'th', 'century', 'europe', 'are', 'sometimes', 'considered', 'to', 'be', 'religious', 'forerunners', 'of', 'modern', 'anarchism', 'bertrand', 'russell', 'in', 'his', 'history', 'of', 'western', 'philosophy', 'writes', 'that', 'the', 'anabaptists', 'repudiated', 'all', 'law', 'since', 'they', 'held', 'that', 'the', 'good', 'man', 'will', 'be', 'guided', 'at', 'every', 'moment', 'by', 'the', 'holy', 'spirit', 'from', 'this', 'premise', 'they', 'arrive', 'at', 'communism', 'the', 'diggers', 'or', 'true', 'levellers', 'were', 'an', 'early', 'communistic', 'movement', (truncated…)
初始化模型
训练完成后,现在我们需要初始化模型。可以按如下方式进行:
model = gensim.models.doc2vec.Doc2Vec(vector_size=40, min_count=2, epochs=30)
现在,构建词汇表,如下所示:
model.build_vocab(data_for_training)
现在,让我们训练 Doc2Vec 模型,如下所示:
model.train(data_for_training, total_examples=model.corpus_count, epochs=model.epochs)
分析输出
最后,我们可以使用 model.infer_vector() 分析输出,如下所示:
print(model.infer_vector(['violent', 'means', 'to', 'destroy', 'the','organization']))
完整的实现示例
import gensim
import gensim.downloader as api
dataset = api.load("text8")
data = [d for d in dataset]
def tagged_document(list_of_list_of_words):
for i, list_of_words in enumerate(list_of_list_of_words):
yield gensim.models.doc2vec.TaggedDocument(list_of_words, [i])
data_for_training = list(tagged_document(data))
print(data_for_training[:1])
model = gensim.models.doc2vec.Doc2Vec(vector_size=40, min_count=2, epochs=30)
model.build_vocab(data_training)
model.train(data_training, total_examples=model.corpus_count, epochs=model.epochs)
print(model.infer_vector(['violent', 'means', 'to', 'destroy', 'the','organization']))
输出
[ -0.2556166 0.4829361 0.17081228 0.10879577 0.12525807 0.10077011 -0.21383236 0.19294572 0.11864349 -0.03227958 -0.02207291 -0.7108424 0.07165232 0.24221905 -0.2924459 -0.03543589 0.21840079 -0.1274817 0.05455418 -0.28968817 -0.29146606 0.32885507 0.14689675 -0.06913587 -0.35173815 0.09340707 -0.3803535 -0.04030455 -0.10004586 0.22192696 0.2384828 -0.29779273 0.19236489 -0.25727913 0.09140676 0.01265439 0.08077634 -0.06902497 -0.07175519 -0.22583418 -0.21653089 0.00347822 -0.34096122 -0.06176808 0.22885063 -0.37295452 -0.08222228 -0.03148199 -0.06487323 0.11387568 ]