
 数据结构
数据结构 网络
网络 关系数据库管理系统 (RDBMS)
关系数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C语言编程
C语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP如何在 Python Pandas 中合并多个列?
Pandas 是 Python 中一个流行的数据处理库,广泛用于处理结构化数据。处理数据时,常见的任务之一是清理和转换数据,以便为分析做好准备。
有时,数据可能包含多个具有相似信息或彼此相关的列。在这种情况下,为了简化分析或可视化,将这些列合并成一列可能很有用。
Pandas 提供了几种将多列合并成一列的方法。在本教程中,我们将详细探讨这些方法,并提供示例来演示如何使用它们。在本教程结束时,您将更好地理解如何在 Pandas 中合并多列,并能够将这些技术应用到您自己的数据集中。
现在让我们讨论两种不同的方法,我们可以使用它们来合并 Pandas 中的多列。
使用 Pandas 中的 melt() 方法合并多列
Pandas 中的 melt() 方法是一个强大的工具,用于将宽数据转换为长数据。我们可以使用此方法将多列合并成一列。
要使用 melt() 方法,我们需要使用 value_vars 参数指定要保留为标识符变量的列和要合并成一列的列。
结果 DataFrame 将包含一个新列,其中包含来自合并列的值,旧列将转换为两列,一列用于标识符变量,另一列用于值变量。
以下是使用 melt() 方法合并多列的步骤:
导入 Pandas 库。
将数据集加载到 DataFrame 中。
在 DataFrame 上使用 melt() 方法,并使用 id_vars 参数指定标识符变量,使用 value_vars 参数指定要合并的列。
根据需要重命名列。
示例
现在让我们来看一下相应的代码。
import pandas as pd
from tabulate import tabulate
data = {
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'income_2019': [50000, 60000, 70000],
'income_2020': [55000, 65000, 75000]}
df = pd.DataFrame(data)
print(tabulate(df, headers='keys', tablefmt='psql'))
print("\n Data Frame After Collapsing Similar Columns")
melted_df = df.melt(
id_vars=['name', 'age'],
value_vars=['income_2019', 'income_2020'],
var_name='year',
value_name='income')
print(tabulate(melted_df, headers = 'keys', tablefmt = 'psql'))
输出
执行此代码后,您将获得以下输出:
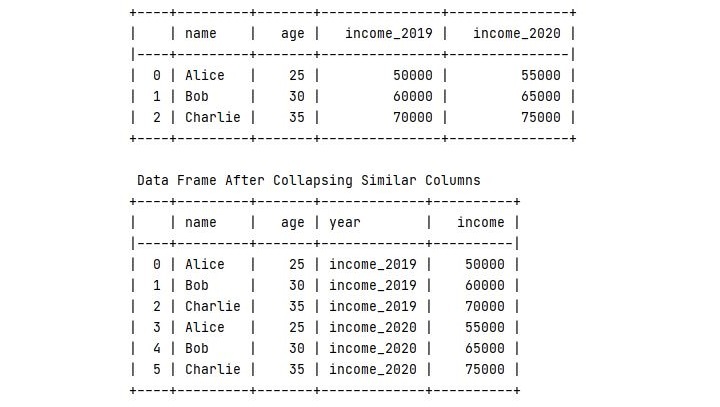
观察原始表格以及合并相似列后的外观。
使用 Pandas 中的 stack() 方法合并多列
Pandas 中的 stack() 方法是将多列合并成一列的另一种方法。当要合并的列具有分层索引时,我们可以使用此方法。
要使用 stack() 方法,我们首先需要使用 set_index() 方法在 DataFrame 上创建多索引。
然后,我们可以使用 stack() 方法合并列并创建一个 Series 对象。
以下是使用 stack() 方法合并多列的步骤:
导入 Pandas 库。
将数据集加载到 DataFrame 中。
使用 set_index() 方法使用要保留为标识符变量的列在 DataFrame 上创建多索引。
使用 stack() 方法合并列。
使用 reset_index() 方法将生成的 Series 对象转换回 DataFrame。
根据需要重命名列。
示例
请考虑以下代码。
import pandas as pd
from tabulate import tabulate
data = {
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'income': [(50000, 55000), (60000, 65000), (70000, 75000)]
}
df = pd.DataFrame(data)
print(tabulate(df, headers='keys', tablefmt='fancy_grid'))
df.set_index(['name', 'age'], inplace=True)
stacked_df = df['income'].apply(pd.Series)
print(tabulate(stacked_df, headers='keys', tablefmt='fancy_grid'))
输出
执行此代码后,您将获得以下输出:
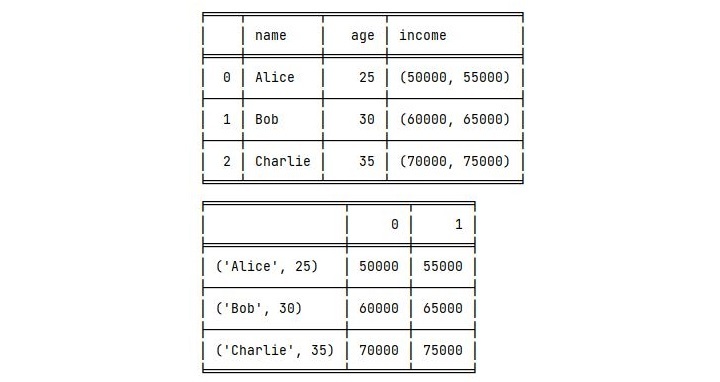
观察使用 stack() 方法合并一些列后 Pandas DataFrame 的外观。
结论
总而言之,合并 Pandas 中的多列可以使用多种方法完成,例如使用 melt() 和 stack() 方法。这两种方法都是将宽数据转换为长数据的强大工具,它们可以用于将多列合并成一列。方法的选择取决于特定的数据集和需要合并的列的结构。通过使用这些方法,我们可以创建一个更有条理且更高效的数据集,这对于数据分析和机器学习应用至关重要。
Pandas 提供了各种强大的数据处理工具,掌握这些工具可以大大提高您分析和处理数据的能力。

2K+ 次浏览
