
 数据结构
数据结构 网络
网络 关系数据库管理系统
关系数据库管理系统 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 编程
C 编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP如何根据列名或行索引对 Pandas DataFrame 进行排序?
许多应用程序都受益于根据列名或行索引对 Pandas DataFrame 进行排序。例如,为了展示销售额随时间的变化情况,我们可以按日期对销售数据 DataFrame 进行排序。在 Python 中,我们有一些内置函数——DataFrame()、sort_index() 和 sort_values(),可用于根据列名或行索引对 Pandas DataFrame 进行排序。
语法
以下语法在示例中使用:
DataFrame(var_name, colums= ['col1', 'col2', and so on], index= ['1', '2', and so on])
DataFrame 是 Pandas 模块的一个库,它定义了不同行和列的二维结构。
sort_index()
sort_index 用于根据索引标签对序列进行排序。此方法对 Pandas DataFrame 进行排序
升序和降序。
sort_index(axis = 1)
此 sort_index 接受名为 axis = 1 的参数,用于排序列顺序。换句话说,我们可以说 axis = 1 指定列。[示例 3]
sort_values(by=["col1","col2","col3"])
sort_value 方法通过按升序对项目或序列进行排序来定义。以上表示形式接受三个列作为参数来排序其项目或序列。
sort_values(by=["row1","row2","row2"])
以上表示形式接受三行,通过使用列表数据类型的技术对其项目或序列进行排序。
示例 1
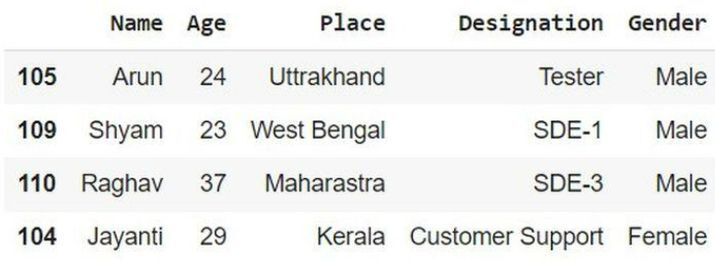
在以下示例中,我们将通过导入名为 pandas 的模块来启动程序。将 pd 作为其对象引用。然后使用列表推导式创建员工数据并将其存储在变量 Emp 中。然后使用列和行从元组列表创建 DataFrame 对象并将其存储在变量 info 中。接下来,提及变量 info 并获取数据的表格结构。
import pandas as pd
# List of Tuples
Emp = [('Arun', 24, 'Uttrakhand', 'Tester', 'Male'),
('Shyam', 23, 'West Bengal', 'SDE-1', 'Male'),
('Raghav', 37, 'Maharastra', 'SDE-3', 'Male'),
('Jayanti', 29, 'Kerala', 'Customer Support','Female')]
# Dataframe object from list of tuples using column and index
info = pd.DataFrame(Emp, columns =['Name', 'Age',
'Place', 'Designation','Gender'],
index =[ '105', '109', '110', '104'])
# Show the dataframe
info
输出
示例 2
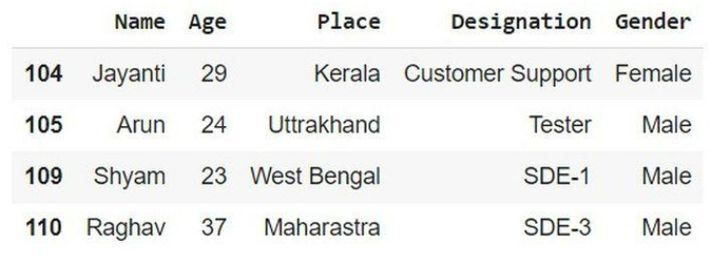
在以下示例中,以下代码使用下一个终端遵循代码的顺序。然后使用内置方法 sort_index(),它将按升序对行进行排序并将其存储在变量 sort_idx 中。最后,使用变量 sort_idx 根据给定的代码获取处理后的数据。
# sort the index row sort_idx = info.sort_index() sort_idx
输出
示例 3
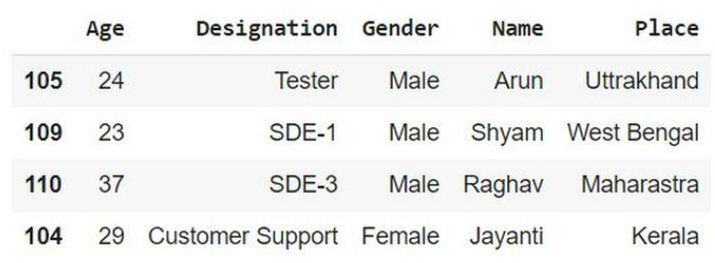
在以下示例中,以下代码使用下一个终端遵循上述代码的顺序。这里我们将根据列排序实现程序。然后导入 pandas 以启动程序(不一定需要)。接下来,使用内置方法 sort_index(),它将按升序对列进行排序。然后只需编写名为 sort_col 的变量即可以另一种形式获取结果。
# sort the column import pandas as pd sort_col = info.sort_index(axis = 1) sort_col
输出
示例 4
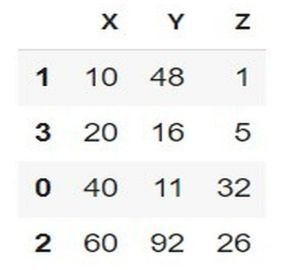
在以下示例中,通过导入名为 pandas 的模块开始程序,该模块将对象引用设置为 pd。然后使用字典数据类型设置三个列,即 X、Y 和 Z,并将其存储在变量 col 中。接下来,使用 pandas 模块的 DataFrame 并将其存储在一个名为 df 的新变量中。现在使用内置方法 sort_values 按升序对行进行排序,该方法遵循序列或项目,并将其存储在变量 sorted_df 中。然后只需编写 sorted_df 即可获得表格输出作为结果。
# Sort DataFrame rows based on multiple columns
import pandas as pd
# create the dictionary
col = {"X" : [40, 10, 60, 20], "Y":[11, 48, 92, 16], "Z":[32,1,26,5]}
df = pd.DataFrame(col)
#Mention the row for sorting
sorted_df=df.sort_values(by=["X","Y","Z"])
sorted_df
输出
示例 5
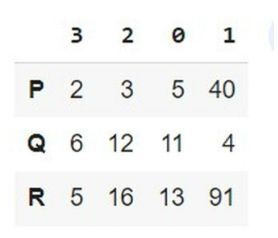
在以下示例中,通过导入名为 pandas 的模块开始程序。获取名为 pd 的对象引用,稍后将在内置方法 sort_values 中使用它。然后创建列表,该列表创建三行不同项目的行数据(即 P、Q 和 R),并将其存储在变量 list1 中。接下来,使用 pandas 模块的 DataFrame,它接受两个参数——list1(用于使用数据的先前变量名称)和 index(此参数使用内置方法列表设置所有列的值)。继续使用名为 sort_values 的内置方法,它接受以下参数:
by=['P','Q','R']:关键字 by 设置行数,即 P、Q 和 R。
axis = 1:标识列。
最后,我们借助变量 sorted_row 打印结果。
# Sort Dataframe based on multiple rows
import pandas as pd
list1 = [(5,40,3,2),(11,4,12,6),(13,91,16,5)]
df = pd.DataFrame(list1, index=list('PQR'))
sorted_row = df.sort_values(by=['P','Q','R'],axis=1)
sorted_row
输出
结论
我们讨论了使用 Pandas DataFrame 对列名或行索引进行排序的不同方法。第一个示例解释了行和列的简单表格结构,而第二个和第三个示例遵循顺序以完成数据集的有意义表示。第四个示例使用字典技术为多列创建数据,而第五个示例使用列表数据类型为多行创建数据,并生成了不同的输出作为结果。

3K+ 浏览量
