
 数据结构
数据结构 网络
网络 RDBMS
RDBMS 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 编程
C 编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP如何使用 Matplotlib 绘制 PySpark SQL 结果?
要使用 Matplotlib 绘制 PySpark SQL 结果,我们可以采取以下步骤:
- 设置图形大小并调整子图之间和周围的边距。
- 获取 Spark 功能的主要入口点的实例。
- 获取与存储在 Hive 中的数据集成的 Spark SQL 变体的实例。
- 将记录列表作为元组。
- 分发本地 Python 集合以形成 RDD。
- 将列表记录映射为 DB 架构。
- 获取架构实例以在"my_table" 中进行条目。
- 在表中插入记录。
- 读取 SQL 查询,检索记录。
- 将获取的记录转换成数据帧。
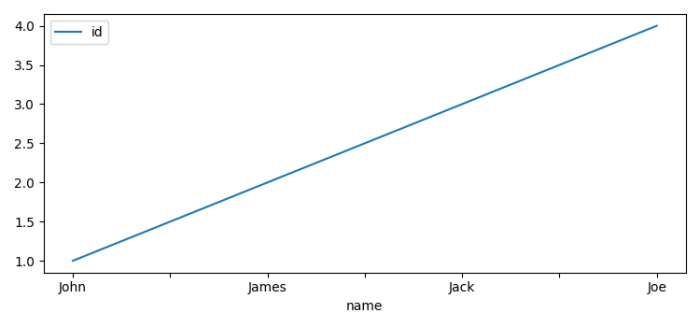
- 使用name 属性设置索引并绘制它们。
- 要显示图形,使用show() 方法。
示例
from pyspark.sql import Row
from pyspark.sql import HiveContext
import pyspark
import matplotlib.pyplot as plt
plt.rcParams["figure.figsize"] = [7.50, 3.50]
plt.rcParams["figure.autolayout"] = True
sc = pyspark.SparkContext()
sqlContext = HiveContext(sc)
test_list = [(1, 'John'), (2, 'James'), (3, 'Jack'), (4, 'Joe')]
rdd = sc.parallelize(test_list)
people = rdd.map(lambda x: Row(id=int(x[0]), name=x[1]))
schemaPeople = sqlContext.createDataFrame(people)
sqlContext.registerDataFrameAsTable(schemaPeople, "my_table")
df = sqlContext.sql("Select * from my_table")
df = df.toPandas()
df.set_index('name').plot()
plt.show()输出

更新时间:07-Jul-2021
3K+ 浏览量

广告