- Keras 教程
- Keras - 首页
- Keras - 简介
- Keras - 安装
- Keras - 后端配置
- Keras - 深度学习概述
- Keras - 深度学习
- Keras - 模块
- Keras - 层
- Keras - 自定义层
- Keras - 模型
- Keras - 模型编译
- Keras - 模型评估和预测
- Keras - 卷积神经网络
- Keras - 使用MPL进行回归预测
- Keras - 使用LSTM RNN进行时间序列预测
- Keras - 应用
- Keras - 使用ResNet模型进行实时预测
- Keras - 预训练模型
- Keras 有用资源
- Keras - 快速指南
- Keras - 有用资源
- Keras - 讨论
Keras - 卷积神经网络
让我们将模型从MPL修改为卷积神经网络(CNN),用于我们之前的数字识别问题。
CNN 可以表示如下:
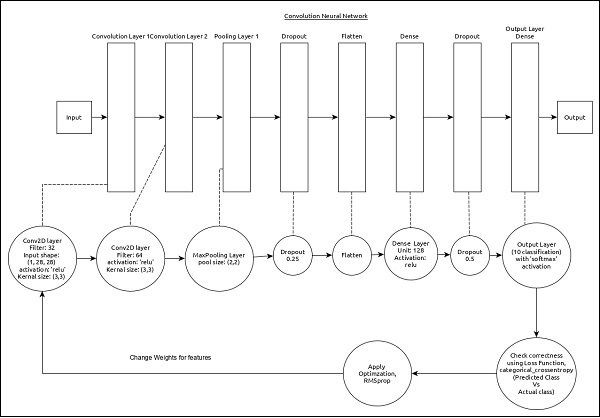
模型的核心特征如下:
输入层包含 (1, 8, 28) 个值。
第一层,Conv2D 包含 32 个过滤器和‘relu’激活函数,内核大小为 (3,3)。
第二层,Conv2D 包含 64 个过滤器和‘relu’激活函数,内核大小为 (3,3)。
第三层,MaxPooling 的池大小为 (2, 2)。
第五层,Flatten 用于将所有输入展平为单一维度。
第六层,Dense 包含 128 个神经元和‘relu’激活函数。
第七层,Dropout 的值为 0.5。
第八层也是最后一层包含 10 个神经元和‘softmax’激活函数。
使用categorical_crossentropy作为损失函数。
使用Adadelta()作为优化器。
使用accuracy作为指标。
使用 128 作为批量大小。
使用 20 个 epochs。
步骤 1 - 导入模块
让我们导入必要的模块。
import keras from keras.datasets import mnist from keras.models import Sequential from keras.layers import Dense, Dropout, Flatten from keras.layers import Conv2D, MaxPooling2D from keras import backend as K import numpy as np
步骤 2 - 加载数据
让我们导入 mnist 数据集。
(x_train, y_train), (x_test, y_test) = mnist.load_data()
步骤 3 - 处理数据
让我们根据我们的模型更改数据集,以便可以将其馈送到我们的模型中。
img_rows, img_cols = 28, 28
if K.image_data_format() == 'channels_first':
x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols)
x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols)
input_shape = (1, img_rows, img_cols)
else:
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)
数据处理与MPL模型类似,只是输入数据的形状和图像格式配置不同。
步骤 4 - 创建模型
让我们创建实际的模型。
model = Sequential() model.add(Conv2D(32, kernel_size = (3, 3), activation = 'relu', input_shape = input_shape)) model.add(Conv2D(64, (3, 3), activation = 'relu')) model.add(MaxPooling2D(pool_size = (2, 2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(128, activation = 'relu')) model.add(Dropout(0.5)) model.add(Dense(10, activation = 'softmax'))
步骤 5 - 编译模型
让我们使用选择的损失函数、优化器和指标来编译模型。
model.compile(loss = keras.losses.categorical_crossentropy, optimizer = keras.optimizers.Adadelta(), metrics = ['accuracy'])
步骤 6 - 训练模型
让我们使用fit()方法训练模型。
model.fit( x_train, y_train, batch_size = 128, epochs = 12, verbose = 1, validation_data = (x_test, y_test) )
执行应用程序将输出以下信息:
Train on 60000 samples, validate on 10000 samples Epoch 1/12 60000/60000 [==============================] - 84s 1ms/step - loss: 0.2687 - acc: 0.9173 - val_loss: 0.0549 - val_acc: 0.9827 Epoch 2/12 60000/60000 [==============================] - 86s 1ms/step - loss: 0.0899 - acc: 0.9737 - val_loss: 0.0452 - val_acc: 0.9845 Epoch 3/12 60000/60000 [==============================] - 83s 1ms/step - loss: 0.0666 - acc: 0.9804 - val_loss: 0.0362 - val_acc: 0.9879 Epoch 4/12 60000/60000 [==============================] - 81s 1ms/step - loss: 0.0564 - acc: 0.9830 - val_loss: 0.0336 - val_acc: 0.9890 Epoch 5/12 60000/60000 [==============================] - 86s 1ms/step - loss: 0.0472 - acc: 0.9861 - val_loss: 0.0312 - val_acc: 0.9901 Epoch 6/12 60000/60000 [==============================] - 83s 1ms/step - loss: 0.0414 - acc: 0.9877 - val_loss: 0.0306 - val_acc: 0.9902 Epoch 7/12 60000/60000 [==============================] - 89s 1ms/step - loss: 0.0375 -acc: 0.9883 - val_loss: 0.0281 - val_acc: 0.9906 Epoch 8/12 60000/60000 [==============================] - 91s 2ms/step - loss: 0.0339 - acc: 0.9893 - val_loss: 0.0280 - val_acc: 0.9912 Epoch 9/12 60000/60000 [==============================] - 89s 1ms/step - loss: 0.0325 - acc: 0.9901 - val_loss: 0.0260 - val_acc: 0.9909 Epoch 10/12 60000/60000 [==============================] - 89s 1ms/step - loss: 0.0284 - acc: 0.9910 - val_loss: 0.0250 - val_acc: 0.9919 Epoch 11/12 60000/60000 [==============================] - 86s 1ms/step - loss: 0.0287 - acc: 0.9907 - val_loss: 0.0264 - val_acc: 0.9916 Epoch 12/12 60000/60000 [==============================] - 86s 1ms/step - loss: 0.0265 - acc: 0.9920 - val_loss: 0.0249 - val_acc: 0.9922
步骤 7 - 评估模型
让我们使用测试数据评估模型。
score = model.evaluate(x_test, y_test, verbose = 0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
执行以上代码将输出以下信息:
Test loss: 0.024936060590433316 Test accuracy: 0.9922
测试精度为 99.22%。我们创建了一个最佳模型来识别手写数字。
步骤 8 - 预测
最后,从图像中预测数字,如下所示:
pred = model.predict(x_test) pred = np.argmax(pred, axis = 1)[:5] label = np.argmax(y_test,axis = 1)[:5] print(pred) print(label)
以上应用程序的输出如下:
[7 2 1 0 4] [7 2 1 0 4]
两个数组的输出相同,这表明我们的模型正确预测了前五个图像。