Keras——深度学习概述
深度学习是机器学习中一个不断发展的分支。深度学习涉及逐层分析输入,其中每一层逐渐提取关于输入的更高级别的信息。
让我们以分析图像为例。假设您的输入图像被分成一个矩形的像素网格。现在,第一层抽象出像素。第二层理解图像中的边缘。下一层从边缘构建节点。然后,下一层将从节点中找到分支。最后,输出层将检测完整的物体。在这里,特征提取过程从一层输出到下一层的输入。
通过这种方法,我们可以处理海量特征,这使得深度学习成为一个非常强大的工具。深度学习算法也适用于非结构化数据的分析。让我们在本章中学习深度学习的基础知识。
人工神经网络
深度学习最流行和主要的方法是使用“人工神经网络”(ANN)。它们受到人脑模型的启发,人脑是我们身体最复杂的器官。人脑由超过900亿个被称为“神经元”的微小细胞组成。“神经元”通过称为“轴突”和“树突”的神经纤维相互连接。轴突的主要作用是从一个神经元传递信息到它连接的另一个神经元。
同样,树突的主要作用是接收由它连接的另一个神经元的轴突传递的信息。每个神经元处理少量信息,然后将结果传递给另一个神经元,这个过程持续进行。这是我们人脑处理大量信息(如语音、视觉等)并从中提取有用信息的基本方法。
基于此模型,第一个人工神经网络 (ANN) 由心理学家Frank Rosenblatt于1958年发明。ANN 由多个类似于神经元的节点组成。节点紧密相连并组织成不同的隐藏层。输入层接收输入数据,数据依次通过一个或多个隐藏层,最后输出层预测关于输入数据的某些有用信息。例如,输入可以是图像,输出可以是图像中识别的物体,例如“猫”。
单个神经元(在ANN中称为感知器)可以表示如下:
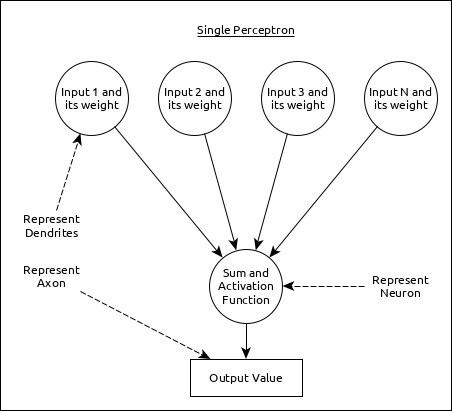
这里:
多个输入以及权重代表树突。
输入之和以及激活函数代表神经元。和实际上是指所有输入的计算值,激活函数表示一个函数,它将和的值修改为0、1或0到1。
实际输出代表轴突,输出将被下一层的神经元接收。
让我们在本节中了解不同类型的人工神经网络。
多层感知器
多层感知器是最简单的人工神经网络形式。它由一个输入层、一个或多个隐藏层和一个输出层组成。一层由多个感知器组成。输入层基本上是输入数据的一个或多个特征。每个隐藏层包含一个或多个神经元,处理特征的某些方面并将处理后的信息发送到下一个隐藏层。输出层处理接收来自最后一个隐藏层的数据,最终输出结果。

卷积神经网络 (CNN)
卷积神经网络是最流行的人工神经网络之一。它广泛应用于图像和视频识别领域。它基于卷积的概念,这是一个数学概念。它与多层感知器几乎相同,只是在全连接隐藏神经元层之前包含一系列卷积层和池化层。它具有三个重要的层:
卷积层——它是主要的构建块,并根据卷积函数执行计算任务。
池化层——它位于卷积层旁边,用于通过去除不必要的信息来减小输入的大小,以便可以更快地进行计算。
全连接层——它位于一系列卷积层和池化层之后,并将输入分类到不同的类别。
一个简单的CNN可以表示如下:
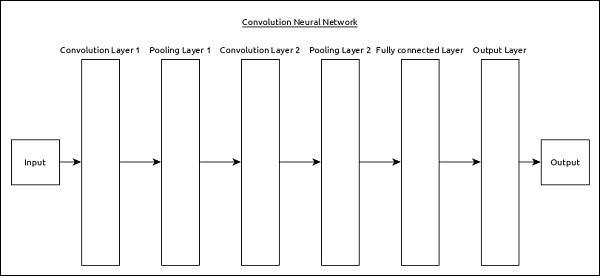
这里:
使用2个系列的卷积层和池化层,它接收并处理输入(例如图像)。
使用单个全连接层,用于输出数据(例如图像分类)。
循环神经网络 (RNN)
循环神经网络 (RNN) 用于解决其他ANN模型中的缺陷。大多数ANN不记得先前情况的步骤,并学习根据训练中的上下文做出决策。同时,RNN存储过去的信息,其所有决策都是根据过去学到的知识做出的。
这种方法主要用于图像分类。有时,我们可能需要展望未来以解决过去的问题。在这种情况下,双向RNN有助于从过去学习并预测未来。例如,我们在多个输入中具有手写样本。假设在一个输入中存在混淆,那么我们需要再次检查其他输入以识别正确的上下文,该上下文根据过去做出决策。
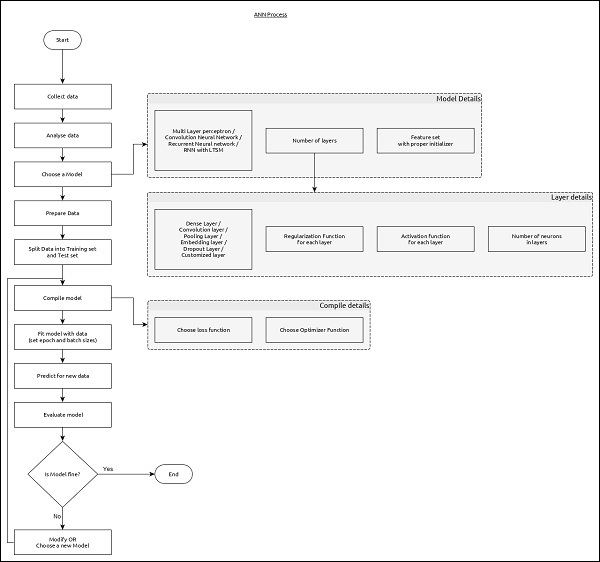
ANN 的工作流程
让我们首先了解深度学习的不同阶段,然后学习 Keras 如何帮助深度学习过程。
收集所需数据
深度学习需要大量输入数据才能成功地学习和预测结果。因此,首先收集尽可能多的数据。
分析数据
分析数据并充分了解数据。需要更好地理解数据才能选择正确的人工神经网络算法。
选择算法(模型)
选择最适合学习过程类型(例如图像分类、文本处理等)和可用输入数据的算法。算法在 Keras 中由模型表示。算法包括一个或多个层。ANN中的每一层都可以在Keras中由Keras层表示。
准备数据——处理、过滤并仅从数据中选择所需信息。
分割数据——将数据分割成训练数据和测试数据集。测试数据将用于评估算法/模型的预测(机器学习后)并交叉检查学习过程的效率。
编译模型——编译算法/模型,以便可以进一步用于通过训练进行学习,并最终进行预测。此步骤需要我们选择损失函数和优化器。损失函数和优化器用于学习阶段查找误差(与实际输出的偏差)并进行优化,以便将误差最小化。
拟合模型——实际学习过程将在此阶段使用训练数据集完成。
预测未知值的成果——预测未知输入数据(除现有的训练和测试数据之外)的输出。
评估模型——通过预测测试数据的输出并将预测与测试数据的实际结果进行交叉比较来评估模型。
冻结、修改或选择新的算法——检查模型的评估是否成功。如果是,则保存算法以备将来预测使用。如果不是,则修改或选择新的算法/模型,最后再次训练、预测和评估模型。重复此过程,直到找到最佳算法(模型)。
上述步骤可以使用下面的流程图表示: