- Keras 教程
- Keras - 首页
- Keras - 简介
- Keras - 安装
- Keras - 后端配置
- Keras - 深度学习概述
- Keras - 深度学习
- Keras - 模块
- Keras - 层
- Keras - 自定义层
- Keras - 模型
- Keras - 模型编译
- Keras - 模型评估和预测
- Keras - 卷积神经网络
- Keras - 使用多层感知器 (MPL) 进行回归预测
- Keras - 使用 LSTM 循环神经网络 (RNN) 进行时间序列预测
- Keras - 应用
- Keras - 使用 ResNet 模型进行实时预测
- Keras - 预训练模型
- Keras 有用资源
- Keras 快速指南
- Keras - 有用资源
- Keras - 讨论
Keras 快速指南
Keras - 简介
深度学习是机器学习框架的一个主要子领域。机器学习是研究算法设计,其灵感来自于人脑模型。深度学习在数据科学领域越来越流行,例如机器人技术、人工智能 (AI)、音频和视频识别以及图像识别。人工神经网络是深度学习方法的核心。深度学习由各种库支持,例如 Theano、TensorFlow、Caffe、Mxnet 等。Keras 是一个最强大、最易于使用的 Python 库之一,它构建在 TensorFlow、Theano 等流行的深度学习库之上,用于创建深度学习模型。
Keras 概述
Keras 运行在 TensorFlow、Theano 或认知工具包 (CNTK) 等开源机器学习库之上。Theano 是一个用于快速数值计算任务的 Python 库。TensorFlow 是最著名的符号数学库,用于创建神经网络和深度学习模型。TensorFlow 非常灵活,主要优点是分布式计算。CNTK 是微软开发的深度学习框架。它使用 Python、C#、C++ 等库或独立的机器学习工具包。Theano 和 TensorFlow 非常强大的库,但对于创建神经网络来说难以理解。
Keras 基于最小的结构,提供了一种简洁易用的方法来创建基于 TensorFlow 或 Theano 的深度学习模型。Keras 旨在快速定义深度学习模型。Keras 是深度学习应用的最佳选择。
特性
Keras 利用各种优化技术,使高级神经网络 API 更易于使用且性能更高。它支持以下特性:
一致、简单且可扩展的 API。
结构简洁 - 易于实现结果,无需任何多余功能。
它支持多个平台和后端。
它是一个用户友好的框架,可在 CPU 和 GPU 上运行。
高度可扩展的计算。
优势
Keras 是一个功能强大且动态的框架,具有以下优点:
更大的社区支持。
易于测试。
Keras 神经网络是用 Python 编写的,这使得事情更简单。
Keras 支持卷积网络和循环网络。
深度学习模型是离散组件,因此您可以以多种方式组合它们。
Keras - 安装
本章介绍如何在您的机器上安装 Keras。在开始安装之前,让我们先了解 Keras 的基本要求。
先决条件
您必须满足以下要求:
- 任何类型的操作系统 (Windows、Linux 或 Mac)
- Python 3.5 或更高版本。
Python
Keras 是一个基于 Python 的神经网络库,因此您的机器上必须安装 Python。如果您的机器上已正确安装 Python,则打开您的终端并键入 python,您将看到类似于以下所示的响应:
Python 3.6.5 (v3.6.5:f59c0932b4, Mar 28 2018, 17:00:18) [MSC v.1900 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>>
目前最新版本为“3.7.2”。如果未安装 Python,请访问官方 Python 链接 - www.python.org 并根据您的操作系统下载最新版本并立即安装到您的系统上。
Keras 安装步骤
Keras 的安装非常简单。请按照以下步骤在您的系统上正确安装 Keras。
步骤 1:创建虚拟环境
Virtualenv 用于管理不同项目的 Python 包。这将有助于避免破坏其他环境中安装的包。因此,在开发 Python 应用程序时,始终建议使用虚拟环境。
Linux/Mac OS
Linux 或 Mac OS 用户,转到您的项目根目录并键入以下命令以创建虚拟环境:
python3 -m venv kerasenv
执行上述命令后,将在您的安装位置创建包含bin、lib 和 include 文件夹的“kerasenv”目录。
Windows
Windows 用户可以使用以下命令:
py -m venv keras
步骤 2:激活环境
此步骤将配置您 shell 路径中的 python 和 pip 可执行文件。
Linux/Mac OS
现在我们已经创建了一个名为“kerasvenv”的虚拟环境。移动到该文件夹并键入以下命令:
$ cd kerasvenv kerasvenv $ source bin/activate
Windows
Windows 用户移动到“kerasenv”文件夹并键入以下命令:
.\env\Scripts\activate
步骤 3:Python 库
Keras 依赖于以下 Python 库。
- NumPy
- Pandas
- Scikit-learn
- Matplotlib
- SciPy
- Seaborn
希望您已经在系统上安装了所有上述库。如果这些库未安装,则使用以下命令逐个安装。
numpy
pip install numpy
您将看到以下响应:
Collecting numpy
Downloading
https://files.pythonhosted.org/packages/cf/a4/d5387a74204542a60ad1baa84cd2d3353c330e59be8cf2d47c0b11d3cde8/
numpy-3.1.1-cp36-cp36m-macosx_10_6_intel.
macosx_10_9_intel.macosx_10_9_x86_64.
macosx_10_10_intel.macosx_10_10_x86_64.whl (14.4MB)
|████████████████████████████████| 14.4MB 2.8MB/s
pandas
pip install pandas
我们将看到以下响应:
Collecting pandas
Downloading
https://files.pythonhosted.org/packages/cf/a4/d5387a74204542a60ad1baa84cd2d3353c330e59be8cf2d47c0b11d3cde8/
pandas-3.1.1-cp36-cp36m-macosx_10_6_intel.
macosx_10_9_intel.macosx_10_9_x86_64.
macosx_10_10_intel.macosx_10_10_x86_64.whl (14.4MB)
|████████████████████████████████| 14.4MB 2.8MB/s
matplotlib
pip install matplotlib
我们将看到以下响应:
Collecting matplotlib
Downloading
https://files.pythonhosted.org/packages/cf/a4/d5387a74204542a60ad1baa84cd2d3353c330e59be8cf2d47c0b11d3cde8/
matplotlib-3.1.1-cp36-cp36m-macosx_10_6_intel.
macosx_10_9_intel.macosx_10_9_x86_64.
macosx_10_10_intel.macosx_10_10_x86_64.whl (14.4MB)
|████████████████████████████████| 14.4MB 2.8MB/s
scipy
pip install scipy
我们将看到以下响应:
Collecting scipy
Downloading
https://files.pythonhosted.org/packages/cf/a4/d5387a74204542a60ad1baa84cd2d3353c330e59be8cf2d47c0b11d3cde8
/scipy-3.1.1-cp36-cp36m-macosx_10_6_intel.
macosx_10_9_intel.macosx_10_9_x86_64.
macosx_10_10_intel.macosx_10_10_x86_64.whl (14.4MB)
|████████████████████████████████| 14.4MB 2.8MB/s
scikit-learn
这是一个开源机器学习库。它用于分类、回归和聚类算法。在开始安装之前,它需要以下内容:
- Python 3.5 或更高版本
- NumPy 1.11.0 或更高版本
- SciPy 0.17.0 或更高版本
- joblib 0.11 或更高版本。
现在,我们使用以下命令安装 scikit-learn:
pip install -U scikit-learn
Seaborn
Seaborn 是一个很棒的库,允许您轻松地可视化您的数据。使用以下命令安装:
pip install seaborn
您将看到类似于以下所示的消息:
Collecting seaborn Downloading https://files.pythonhosted.org/packages/a8/76/220ba4420459d9c4c9c9587c6ce607bf56c25b3d3d2de62056efe482dadc /seaborn-0.9.0-py3-none-any.whl (208kB) 100% |████████████████████████████████| 215kB 4.0MB/s Requirement already satisfied: numpy> = 1.9.3 in ./lib/python3.7/site-packages (from seaborn) (1.17.0) Collecting pandas> = 0.15.2 (from seaborn) Downloading https://files.pythonhosted.org/packages/39/b7/441375a152f3f9929ff8bc2915218ff1a063a59d7137ae0546db616749f9/ pandas-0.25.0-cp37-cp37m-macosx_10_9_x86_64. macosx_10_10_x86_64.whl (10.1MB) 100% |████████████████████████████████| 10.1MB 1.8MB/s Requirement already satisfied: scipy>=0.14.0 in ./lib/python3.7/site-packages (from seaborn) (1.3.0) Collecting matplotlib> = 1.4.3 (from seaborn) Downloading https://files.pythonhosted.org/packages/c3/8b/af9e0984f 5c0df06d3fab0bf396eb09cbf05f8452de4e9502b182f59c33b/ matplotlib-3.1.1-cp37-cp37m-macosx_10_6_intel. macosx_10_9_intel.macosx_10_9_x86_64 .macosx_10_10_intel.macosx_10_10_x86_64.whl (14.4MB) 100% |████████████████████████████████| 14.4MB 1.4MB/s ...................................... ...................................... Successfully installed cycler-0.10.0 kiwisolver-1.1.0 matplotlib-3.1.1 pandas-0.25.0 pyparsing-2.4.2 python-dateutil-2.8.0 pytz-2019.2 seaborn-0.9.0
使用 Python 安装 Keras
到现在为止,我们已经完成了 Keras 安装的基本要求。现在,使用以下指定的相同步骤安装 Keras:
pip install keras
退出虚拟环境
完成项目中的所有更改后,只需运行以下命令即可退出环境:
deactivate
Anaconda Cloud
我们相信您已经在机器上安装了 Anaconda Cloud。如果未安装 Anaconda,请访问官方链接 https://anaconda.net.cn/download 并根据您的操作系统选择下载。
创建一个新的 conda 环境
启动 Anaconda 提示符,这将打开基础 Anaconda 环境。让我们创建一个新的 conda 环境。此过程类似于 virtualenv。在您的 conda 终端中键入以下命令:
conda create --name PythonCPU
如果需要,您也可以使用 GPU 创建和安装模块。在本教程中,我们遵循 CPU 指令。
激活 conda 环境
要激活环境,请使用以下命令:
activate PythonCPU
安装 Spyder
Spyder 是一个用于执行 Python 应用程序的 IDE。让我们使用以下命令在我们的 conda 环境中安装此 IDE:
conda install spyder
安装 Python 库
我们已经了解了 Keras 所需的 Python 库 numpy、pandas 等。您可以使用以下语法安装所有模块:
语法
conda install -c anaconda <module-name>
例如,您想安装 pandas:
conda install -c anaconda pandas
使用相同的方法,尝试自己安装其余的模块。
安装 Keras
现在,一切看起来都很不错,因此您可以使用以下命令开始 Keras 安装:
conda install -c anaconda keras
启动 Spyder
最后,在您的 conda 终端中使用以下命令启动 Spyder:
spyder
为确保一切安装正确,导入所有模块,它将添加所有内容,如果出现任何错误,您将收到模块未找到错误消息。
Keras - 后端配置
本章详细解释了 Keras 后端实现 TensorFlow 和 Theano。让我们逐一了解每个实现。
TensorFlow
TensorFlow 是一个由 Google 开发的用于数值计算任务的开源机器学习库。Keras 是构建在 TensorFlow 或 Theano 之上的高级 API。我们已经知道如何使用 pip 安装 TensorFlow。
如果未安装,您可以使用以下命令安装:
pip install TensorFlow
一旦我们执行 keras,我们将看到配置文件位于您的主目录内部,然后转到 .keras/keras.json。
keras.json
{
"image_data_format": "channels_last",
"epsilon": 1e-07, "floatx": "float32", "backend": "tensorflow"
}
这里:
image_data_format 表示数据格式。
epsilon 表示数值常量。它用于避免除以零错误。
floatx 表示默认数据类型float32。您也可以使用set_floatx()方法将其更改为float16或float64。
image_data_format 表示数据格式。
假设,如果未创建文件,则移动到该位置并使用以下步骤创建:
> cd home > mkdir .keras > vi keras.json
记住,您应该指定 .keras 作为其文件夹名称,并将上述配置添加到 keras.json 文件中。我们可以执行一些预定义的操作来了解后端功能。
Theano
Theano 是一个开源深度学习库,允许您有效地评估多维数组。我们可以使用以下命令轻松安装:
pip install theano
默认情况下,keras 使用 TensorFlow 后端。如果要将后端配置从 TensorFlow 更改为 Theano,只需在 keras.json 文件中将 backend = theano 更改即可。如下所示:
keras.json
{
"image_data_format": "channels_last",
"epsilon": 1e-07,
"floatx": "float32",
"backend": "theano"
}
现在保存您的文件,重新启动您的终端并启动 keras,您的后端将被更改。
>>> import keras as k using theano backend.
Keras - 深度学习概述
深度学习是机器学习不断发展的子领域。深度学习涉及逐层分析输入,其中每一层逐渐提取关于输入的更高级别的信息。
让我们来看一个简单的图像分析场景。假设你的输入图像被分割成一个矩形的像素网格。第一层对像素进行抽象。第二层理解图像中的边缘。下一层从边缘构建节点。然后,下一层从节点中找到分支。最后,输出层将检测完整的物体。在这里,特征提取过程从一层输出到下一层的输入。
通过这种方法,我们可以处理海量特征,这使得深度学习成为一个非常强大的工具。深度学习算法也适用于非结构化数据的分析。本章我们将学习深度学习的基础知识。
人工神经网络
深度学习最流行和主要的方法是使用“人工神经网络”(ANN)。它们受到人脑模型的启发,人脑是我们身体最复杂的器官。人脑由超过900亿个被称为“神经元”的微小细胞组成。神经元通过称为“轴突”和“树突”的神经纤维相互连接。轴突的主要作用是将信息从一个神经元传递到它连接的另一个神经元。
同样,树突的主要作用是接收另一个神经元(它连接到的)的轴突传递的信息。每个神经元处理少量信息,然后将结果传递给另一个神经元,这个过程持续进行。这是我们人脑处理大量信息(如语音、视觉等)并从中提取有用信息的基本方法。
基于此模型,第一个人工神经网络(ANN)由心理学家弗兰克·罗森布拉特于1958年发明。ANN由多个节点组成,类似于神经元。节点紧密相连并组织成不同的隐藏层。输入层接收输入数据,数据依次通过一个或多个隐藏层,最后输出层预测关于输入数据的有用信息。例如,输入可以是一张图像,输出可以是图像中识别出的物体,例如“猫”。
单个神经元(在ANN中称为感知器)可以表示如下:
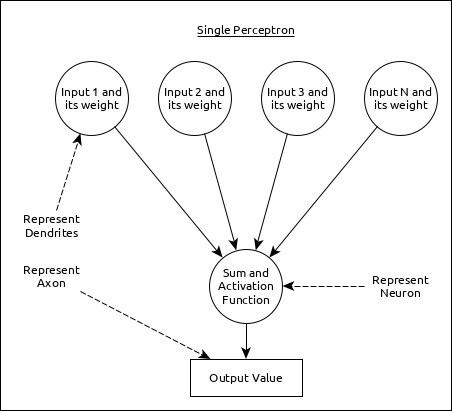
这里:
多个输入以及权重代表树突。
输入之和以及激活函数代表神经元。总和实际上是指所有输入的计算值,激活函数代表一个函数,它将总和值修改为0、1或0到1。
实际输出代表轴突,输出将被下一层的神经元接收。
在本节中,让我们了解不同类型的人工神经网络。
多层感知器
多层感知器是最简单形式的ANN。它由一个输入层、一个或多个隐藏层以及一个输出层组成。一层由多个感知器组成。输入层基本上是输入数据的一个或多个特征。每个隐藏层包含一个或多个神经元,处理特征的某些方面并将处理后的信息发送到下一个隐藏层。输出层处理接收来自最后一个隐藏层的数据,并最终输出结果。

卷积神经网络 (CNN)
卷积神经网络是最流行的ANN之一。它广泛用于图像和视频识别领域。它基于卷积的概念,这是一个数学概念。它与多层感知器几乎相同,只是在全连接隐藏神经元层之前包含一系列卷积层和池化层。它具有三个重要的层:
卷积层 - 它是主要的构建块,并根据卷积函数执行计算任务。
池化层 - 它位于卷积层旁边,用于通过去除不必要的信息来减小输入的大小,以便可以更快地执行计算。
全连接层 - 它位于一系列卷积层和池化层之后,并将输入分类到不同的类别。
一个简单的CNN可以表示如下:
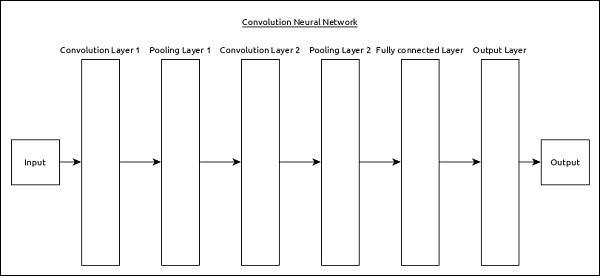
这里:
使用了2个系列的卷积和池化层,它接收并处理输入(例如图像)。
使用单个全连接层,用于输出数据(例如图像分类)。
循环神经网络 (RNN)
循环神经网络 (RNN) 用于解决其他ANN模型中的缺陷。大多数ANN不记得之前情况的步骤,并学习根据训练中的上下文做出决策。同时,RNN存储过去的信息,其所有决策都是根据过去学到的知识做出的。
这种方法主要用于图像分类。有时,我们可能需要展望未来才能解决过去的问题。在这种情况下,双向RNN有助于从过去学习并预测未来。例如,我们在多个输入中具有手写样本。假设在一个输入中存在混淆,那么我们需要再次检查其他输入以识别正确的上下文,该上下文根据过去做出决策。
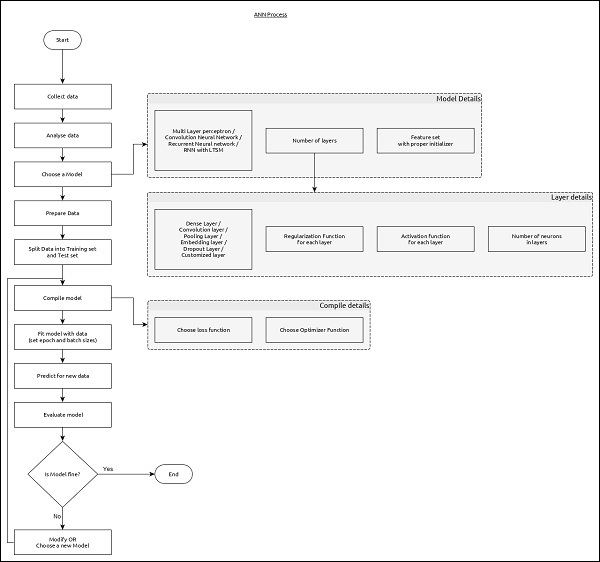
ANN 的工作流程
让我们首先了解深度学习的不同阶段,然后学习Keras如何在深度学习过程中提供帮助。
收集所需数据
深度学习需要大量的输入数据才能成功学习并预测结果。因此,首先尽可能多地收集数据。
分析数据
分析数据并对数据有很好的理解。需要更好地理解数据才能选择正确的ANN算法。
选择算法(模型)
选择最适合学习过程类型(例如图像分类、文本处理等)和可用输入数据的算法。算法在Keras中由模型表示。算法包括一个或多个层。ANN中的每一层都可以由Keras中的Keras层表示。
准备数据 - 处理、过滤并仅从数据中选择所需信息。
分割数据 - 将数据分割成训练和测试数据集。测试数据将用于评估算法/模型的预测(一旦机器学习)并交叉检查学习过程的效率。
编译模型 - 编译算法/模型,以便可以进一步使用它来通过训练进行学习,最终进行预测。此步骤要求我们选择损失函数和优化器。损失函数和优化器用于学习阶段以查找误差(与实际输出的偏差)并进行优化,以便最大限度地减少误差。
拟合模型 - 实际学习过程将在此阶段使用训练数据集完成。
预测未知值的結果 - 预测未知输入数据(现有训练和测试数据以外)的输出。
评估模型 - 通过预测测试数据的输出并将预测与测试数据的实际结果进行交叉比较来评估模型。
冻结、修改或选择新算法 - 检查模型的评估是否成功。如果是,则保存算法以备将来预测使用。如果不是,则修改或选择新的算法/模型,最后再次训练、预测和评估模型。重复此过程,直到找到最佳算法(模型)。
上述步骤可以用下面的流程图表示:
Keras - 深度学习
Keras提供了一个完整的框架来创建任何类型的神经网络。Keras既创新又易于学习。它支持从简单的神经网络到非常大和复杂的神经网络模型。本章让我们了解Keras框架的架构以及Keras如何在深度学习中提供帮助。
Keras 的架构
Keras API可以分为三大类:
- 模型
- 层
- 核心模块
在Keras中,每个ANN都由Keras模型表示。反过来,每个Keras模型都是Keras层的组合,并表示ANN层,例如输入层、隐藏层、输出层、卷积层、池化层等。Keras模型和层访问Keras模块以实现激活函数、损失函数、正则化函数等。使用Keras模型、Keras层和Keras模块,可以简单有效地表示任何ANN算法(CNN、RNN等)。
下图描述了模型、层和核心模块之间的关系:

让我们看看Keras模型、Keras层和Keras模块的概述。
模型
Keras模型有两种类型,如下所示:
顺序模型 - 顺序模型基本上是Keras层的线性组合。顺序模型简单、最小,并且能够表示几乎所有可用的神经网络。
一个简单的顺序模型如下所示:
from keras.models import Sequential from keras.layers import Dense, Activation model = Sequential() model.add(Dense(512, activation = 'relu', input_shape = (784,)))
其中:
第1行从Keras模型导入Sequential模型
第2行导入Dense层和Activation模块
第4行使用Sequential API创建一个新的顺序模型
第5行添加一个具有relu激活(使用Activation模块)函数的密集层(Dense API)。
Sequential模型公开Model类以创建自定义模型。我们可以使用子类化概念来创建我们自己的复杂模型。
函数式API - 函数式API主要用于创建复杂的模型。
层
Keras模型中的每个Keras层都代表实际提出的神经网络模型中的相应层(输入层、隐藏层和输出层)。Keras提供了许多预构建的层,以便可以轻松创建任何复杂的神经网络。一些重要的Keras层如下所示:
- 核心层
- 卷积层
- 池化层
- 循环层
使用sequential模型表示神经网络模型的简单python代码如下:
from keras.models import Sequential from keras.layers import Dense, Activation, Dropout model = Sequential() model.add(Dense(512, activation = 'relu', input_shape = (784,))) model.add(Dropout(0.2)) model.add(Dense(512, activation = 'relu')) model.add(Dropout(0.2)) model.add(Dense(num_classes, activation = 'softmax'))
其中:
第1行从Keras模型导入Sequential模型
第2行导入Dense层和Activation模块
第4行使用Sequential API创建一个新的顺序模型
第5行添加一个具有relu激活(使用Activation模块)函数的密集层(Dense API)。
第6行添加一个dropout层(Dropout API)来处理过拟合。
第7行添加另一个具有relu激活(使用Activation模块)函数的密集层(Dense API)。
第8行添加另一个dropout层(Dropout API)来处理过拟合。
第9行添加具有softmax激活(使用Activation模块)函数的最终密集层(Dense API)。
Keras还提供选项来创建我们自己的自定义层。自定义层可以通过子类化Keras.Layer类来创建,这类似于子类化Keras模型。
核心模块
Keras还提供许多内置的神经网络相关函数来正确创建Keras模型和Keras层。一些函数如下:
激活模块 - 激活函数是ANN中的一个重要概念,激活模块提供了许多激活函数,例如softmax、relu等。
损失模块 - 损失模块提供损失函数,例如mean_squared_error、mean_absolute_error、poisson等。
优化器模块 - 优化器模块提供优化器函数,例如adam、sgd等。
正则化器 - 正则化器模块提供函数,例如L1正则化器、L2正则化器等。
让我们在接下来的章节中详细学习Keras模块。
Keras - 模块
正如我们前面所学,Keras模块包含预定义的类、函数和变量,这些对于深度学习算法非常有用。本章让我们学习Keras提供的模块。
可用模块
让我们首先查看Keras中可用的模块列表。
初始化器 - 提供初始化器函数列表。我们可以在Keras的 *层章节* 中详细学习它。在机器学习的模型创建阶段。
正则化器 (Regularizers) − 提供一系列正则化函数。详情请参阅Keras 层章节。
约束 (Constraints) − 提供一系列约束函数。详情请参阅Keras 层章节。
激活函数 (Activations) − 提供一系列激活函数。详情请参阅Keras 层章节。
损失函数 (Losses) − 提供一系列损失函数。详情请参阅模型训练章节。
度量指标 (Metrics) − 提供一系列度量函数。详情请参阅模型训练章节。
优化器 (Optimizers) − 提供一系列优化器函数。详情请参阅模型训练章节。
回调函数 (Callback) − 提供一系列回调函数。可在训练过程中使用它们来打印中间数据,并根据某些条件停止训练(EarlyStopping 方法)。
文本处理 (Text processing) − 提供将文本转换为适用于机器学习的 NumPy 数组的函数。可将其用于机器学习的数据准备阶段。
图像处理 (Image processing) − 提供将图像转换为适用于机器学习的 NumPy 数组的函数。可将其用于机器学习的数据准备阶段。
序列处理 (Sequence processing) − 提供根据给定输入数据生成基于时间的函数。可将其用于机器学习的数据准备阶段。
后端 (Backend) − 提供后端库(如 TensorFlow 和 Theano)的函数。
实用工具 (Utilities) − 提供许多深度学习中常用的实用函数。
本章将介绍后端模块和实用工具模块。
后端模块
后端模块用于 Keras 后端操作。默认情况下,Keras 运行在 TensorFlow 后端之上。如果需要,可以切换到其他后端,如 Theano 或 CNTK。默认后端配置定义在根目录下的 .keras/keras.json 文件中。
可以使用以下代码导入 Keras 后端模块:
>>> from keras import backend as k
如果使用默认后端 TensorFlow,则以下函数将返回如下所示的基于 TensorFlow 的信息:
>>> k.backend() 'tensorflow' >>> k.epsilon() 1e-07 >>> k.image_data_format() 'channels_last' >>> k.floatx() 'float32'
让我们简要了解一些用于数据分析的重要后端函数:
get_uid()
这是默认图的标识符。定义如下:
>>> k.get_uid(prefix='') 1 >>> k.get_uid(prefix='') 2
reset_uids
用于重置 uid 值。
>>> k.reset_uids()
现在,再次执行 get_uid()。这将被重置,并再次更改为 1。
>>> k.get_uid(prefix='') 1
placeholder
用于实例化一个占位符张量。下面显示了一个简单的用于保存 3 维形状的占位符:
>>> data = k.placeholder(shape = (1,3,3)) >>> data <tf.Tensor 'Placeholder_9:0' shape = (1, 3, 3) dtype = float32> If you use int_shape(), it will show the shape. >>> k.int_shape(data) (1, 3, 3)
dot
用于将两个张量相乘。假设 a 和 b 是两个张量,c 将是 ab 相乘的结果。假设 a 的形状为 (4,2),b 的形状为 (2,3)。定义如下:
>>> a = k.placeholder(shape = (4,2)) >>> b = k.placeholder(shape = (2,3)) >>> c = k.dot(a,b) >>> c <tf.Tensor 'MatMul_3:0' shape = (4, 3) dtype = float32> >>>
ones
用于初始化所有值为一。
>>> res = k.ones(shape = (2,2)) #print the value >>> k.eval(res) array([[1., 1.], [1., 1.]], dtype = float32)
batch_dot
用于对批量数据执行乘积。输入维度必须为 2 或更高。如下所示:
>>> a_batch = k.ones(shape = (2,3)) >>> b_batch = k.ones(shape = (3,2)) >>> c_batch = k.batch_dot(a_batch,b_batch) >>> c_batch <tf.Tensor 'ExpandDims:0' shape = (2, 1) dtype = float32>
variable
用于初始化一个变量。让我们在这个变量中执行简单的转置操作。
>>> data = k.variable([[10,20,30,40],[50,60,70,80]])
#variable initialized here
>>> result = k.transpose(data)
>>> print(result)
Tensor("transpose_6:0", shape = (4, 2), dtype = float32)
>>> print(k.eval(result))
[[10. 50.]
[20. 60.]
[30. 70.]
[40. 80.]]
如果要从 NumPy 访问:
>>> data = np.array([[10,20,30,40],[50,60,70,80]]) >>> print(np.transpose(data)) [[10 50] [20 60] [30 70] [40 80]] >>> res = k.variable(value = data) >>> print(res) <tf.Variable 'Variable_7:0' shape = (2, 4) dtype = float32_ref>
is_sparse(tensor)
用于检查张量是否是稀疏的。
>>> a = k.placeholder((2, 2), sparse=True)
>>> print(a) SparseTensor(indices =
Tensor("Placeholder_8:0",
shape = (?, 2), dtype = int64),
values = Tensor("Placeholder_7:0", shape = (?,),
dtype = float32), dense_shape = Tensor("Const:0", shape = (2,), dtype = int64))
>>> print(k.is_sparse(a)) True
to_dense()
用于将稀疏转换为稠密。
>>> b = k.to_dense(a)
>>> print(b) Tensor("SparseToDense:0", shape = (2, 2), dtype = float32)
>>> print(k.is_sparse(b)) False
random_uniform_variable
使用均匀分布的概念进行初始化。
k.random_uniform_variable(shape, mean, scale)
这里:
shape − 以元组的形式表示行和列。
mean − 均匀分布的均值。
scale − 均匀分布的标准差。
让我们看下面的示例用法:
>>> a = k.random_uniform_variable(shape = (2, 3), low=0, high = 1) >>> b = k. random_uniform_variable(shape = (3,2), low = 0, high = 1) >>> c = k.dot(a, b) >>> k.int_shape(c) (2, 2)
实用工具模块
utils 提供了深度学习中常用的实用函数。utils 模块提供的一些方法如下:
HDF5Matrix
用于以 HDF5 格式表示输入数据。
from keras.utils import HDF5Matrix data = HDF5Matrix('data.hdf5', 'data')
to_categorical
用于将类向量转换为二进制类矩阵。
>>> from keras.utils import to_categorical >>> labels = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] >>> to_categorical(labels) array([[1., 0., 0., 0., 0., 0., 0., 0., 0., 0.], [0., 1., 0., 0., 0., 0., 0., 0., 0., 0.], [0., 0., 1., 0., 0., 0., 0., 0., 0., 0.], [0., 0., 0., 1., 0., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 1., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 0., 1., 0., 0., 0., 0.], [0., 0., 0., 0., 0., 0., 1., 0., 0., 0.], [0., 0., 0., 0., 0., 0., 0., 1., 0., 0.], [0., 0., 0., 0., 0., 0., 0., 0., 1., 0.], [0., 0., 0., 0., 0., 0., 0., 0., 0., 1.]], dtype = float32) >>> from keras.utils import normalize >>> normalize([1, 2, 3, 4, 5]) array([[0.13483997, 0.26967994, 0.40451992, 0.53935989, 0.67419986]])
print_summary
用于打印模型的摘要。
from keras.utils import print_summary print_summary(model)
plot_model
用于创建模型的 dot 格式表示并将其保存到文件中。
from keras.utils import plot_model plot_model(model,to_file = 'image.png')
这个plot_model 将生成图像以了解模型的性能。
Keras - 层
如前所述,Keras 层是 Keras 模型的主要构建块。每个层接收输入信息,进行一些计算,最后输出转换后的信息。一层输出将作为下一层的输入。
介绍
Keras 层需要输入形状 (input_shape) 来理解输入数据的结构,初始化器 (initializer) 来为每个输入设置权重,以及激活函数来转换输出使其非线性。在此期间,约束限制并指定生成输入数据权重的范围,而正则化器将通过在优化过程中动态地对权重施加惩罚来尝试优化层(和模型)。
总而言之,Keras 层需要以下最少信息才能创建一个完整的层。
- 输入数据的形状
- 层中的神经元/单元数量
- 初始化器
- 正则化器
- 约束
- 激活函数
让我们在下一章了解基本概念。在了解基本概念之前,让我们使用 Sequential 模型 API 创建一个简单的 Keras 层,以了解 Keras 模型和层的工作原理。
from keras.models import Sequential from keras.layers import Activation, Dense from keras import initializers from keras import regularizers from keras import constraints model = Sequential() model.add(Dense(32, input_shape=(16,), kernel_initializer = 'he_uniform', kernel_regularizer = None, kernel_constraint = 'MaxNorm', activation = 'relu')) model.add(Dense(16, activation = 'relu')) model.add(Dense(8))
其中:
第 1-5 行导入必要的模块。
第 7 行使用 Sequential API 创建一个新模型。
第 9 行创建一个新的Dense 层并将其添加到模型中。Dense 是 Keras 提供的入门级层,它接受神经元或单元的数量 (32) 作为其必需参数。如果该层是第一层,则还需要提供Input Shape (16,)。否则,前一层的输出将用作下一层的输入。所有其他参数都是可选的。
第一个参数表示单元(神经元)的数量。
input_shape 表示输入数据的形状。
kernel_initializer 表示要使用的初始化器。he_uniform 函数设置为值。
kernel_regularizer 表示要使用的正则化器。设置为 None。
kernel_constraint 表示要使用的约束。MaxNorm 函数设置为值。
activation 表示要使用的激活函数。relu 函数设置为值。
第 10 行创建第二个具有 16 个单元的Dense 层,并将relu 设置为激活函数。
第 11 行创建具有 8 个单元的最终 Dense 层。
层的基本概念
让我们了解层的根本概念以及 Keras 如何支持每个概念。
输入形状
在机器学习中,所有类型的输入数据(如文本、图像或视频)都将首先转换为数字数组,然后馈送到算法中。输入数字可以是一维数组、二维数组(矩阵)或多维数组。可以使用shape(整数元组)指定维度信息。例如,(4,2) 表示具有四行两列的矩阵。
>>> import numpy as np >>> shape = (4, 2) >>> input = np.zeros(shape) >>> print(input) [ [0. 0.] [0. 0.] [0. 0.] [0. 0.] ] >>>
类似地,(3,4,2) 表示具有三个 4x2 矩阵集合(两行四列)的三维矩阵。
>>> import numpy as np >>> shape = (3, 4, 2) >>> input = np.zeros(shape) >>> print(input) [ [[0. 0.] [0. 0.] [0. 0.] [0. 0.]] [[0. 0.] [0. 0.] [0. 0.] [0. 0.]] [[0. 0.] [0. 0.] [0. 0.] [0. 0.]] ] >>>
要创建模型的第一层(或模型的输入层),应指定输入数据的形状。
初始化器
在机器学习中,将为所有输入数据分配权重。初始化器模块提供不同的函数来设置这些初始权重。一些Keras 初始化器函数如下:
Zeros
为所有输入数据生成0。
from keras.models import Sequential from keras.layers import Activation, Dense from keras import initializers my_init = initializers.Zeros() model = Sequential() model.add(Dense(512, activation = 'relu', input_shape = (784,), kernel_initializer = my_init))
其中,kernel_initializer 表示模型内核的初始化器。
Ones
为所有输入数据生成1。
from keras.models import Sequential from keras.layers import Activation, Dense from keras import initializers my_init = initializers.Ones() model.add(Dense(512, activation = 'relu', input_shape = (784,), kernel_initializer = my_init))
Constant
为所有输入数据生成用户指定的常数值(例如,5)。
from keras.models import Sequential from keras.layers import Activation, Dense from keras import initializers my_init = initializers.Constant(value = 0) model.add( Dense(512, activation = 'relu', input_shape = (784,), kernel_initializer = my_init) )
其中,value 表示常数值
RandomNormal
使用输入数据的正态分布生成值。
from keras.models import Sequential from keras.layers import Activation, Dense from keras import initializers my_init = initializers.RandomNormal(mean=0.0, stddev = 0.05, seed = None) model.add(Dense(512, activation = 'relu', input_shape = (784,), kernel_initializer = my_init))
其中:
mean 表示要生成的随机值的均值
stddev 表示要生成的随机值的标准差
seed 表示生成随机数的值
RandomUniform
使用输入数据的均匀分布生成值。
from keras import initializers my_init = initializers.RandomUniform(minval = -0.05, maxval = 0.05, seed = None) model.add(Dense(512, activation = 'relu', input_shape = (784,), kernel_initializer = my_init))
其中:
minval 表示要生成的随机值的较低界限
maxval 表示要生成的随机值的较高界限
TruncatedNormal
使用输入数据的截断正态分布生成值。
from keras.models import Sequential from keras.layers import Activation, Dense from keras import initializers my_init = initializers.TruncatedNormal(mean = 0.0, stddev = 0.05, seed = None model.add(Dense(512, activation = 'relu', input_shape = (784,), kernel_initializer = my_init))
VarianceScaling
根据层的输入形状和输出形状以及指定的比例生成值。
from keras.models import Sequential from keras.layers import Activation, Dense from keras import initializers my_init = initializers.VarianceScaling( scale = 1.0, mode = 'fan_in', distribution = 'normal', seed = None) model.add(Dense(512, activation = 'relu', input_shape = (784,), skernel_initializer = my_init))
其中:
scale 表示比例因子
mode 表示fan_in、fan_out 和fan_avg 值中的任意一个
distribution 表示normal 或uniform 之一
VarianceScaling
它使用以下公式查找正态分布的stddev 值,然后使用正态分布查找权重:
stddev = sqrt(scale / n)
其中n表示:
对于 mode = fan_in,输入单元的数量
对于 mode = fan_out,输出单元的数量
对于 mode = fan_avg,输入和输出单元的平均数量
类似地,它使用以下公式查找均匀分布的limit,然后使用均匀分布查找权重:
limit = sqrt(3 * scale / n)
lecun_normal
使用输入数据的 Lecun 正态分布生成值。
from keras.models import Sequential from keras.layers import Activation, Dense from keras import initializers my_init = initializers.RandomUniform(minval = -0.05, maxval = 0.05, seed = None) model.add(Dense(512, activation = 'relu', input_shape = (784,), kernel_initializer = my_init))
它使用以下公式查找stddev,然后应用正态分布
stddev = sqrt(1 / fan_in)
其中,fan_in 表示输入单元的数量。
lecun_uniform
使用输入数据的 Lecun 均匀分布生成值。
from keras.models import Sequential from keras.layers import Activation, Dense from keras import initializers my_init = initializers.lecun_uniform(seed = None) model.add(Dense(512, activation = 'relu', input_shape = (784,), kernel_initializer = my_init))
它使用以下公式查找limit,然后应用均匀分布
limit = sqrt(3 / fan_in)
其中:
fan_in 表示输入单元的数量
fan_out 表示输出单元的数量
glorot_normal
使用输入数据的 Glorot 正态分布生成值。
from keras.models import Sequential from keras.layers import Activation, Dense from keras import initializers my_init = initializers.glorot_normal(seed=None) model.add( Dense(512, activation = 'relu', input_shape = (784,), kernel_initializer = my_init) )
它使用以下公式查找stddev,然后应用正态分布
stddev = sqrt(2 / (fan_in + fan_out))
其中:
fan_in 表示输入单元的数量
fan_out 表示输出单元的数量
glorot_uniform
使用输入数据的 Glorot 均匀分布生成值。
from keras.models import Sequential from keras.layers import Activation, Dense from keras import initializers my_init = initializers.glorot_uniform(seed = None) model.add(Dense(512, activation = 'relu', input_shape = (784,), kernel_initializer = my_init))
它使用以下公式查找limit,然后应用均匀分布
limit = sqrt(6 / (fan_in + fan_out))
其中:
fan_in 表示输入单元的数量。
fan_out 表示输出单元的数量
he_normal
使用输入数据的 He 正态分布生成值。
from keras.models import Sequential from keras.layers import Activation, Dense from keras import initializers my_init = initializers.RandomUniform(minval = -0.05, maxval = 0.05, seed = None) model.add(Dense(512, activation = 'relu', input_shape = (784,), kernel_initializer = my_init))
它使用以下公式查找stddev,然后应用正态分布。
stddev = sqrt(2 / fan_in)
其中,fan_in 表示输入单元的数量。
he_uniform
使用输入数据的 He 均匀分布生成值。
from keras.models import Sequential from keras.layers import Activation, Dense from keras import initializers my_init = initializers.he_normal(seed = None) model.add(Dense(512, activation = 'relu', input_shape = (784,), kernel_initializer = my_init))
它使用以下公式查找limit,然后应用均匀分布。
limit = sqrt(6 / fan_in)
其中,fan_in 表示输入单元的数量。
Orthogonal
生成一个随机正交矩阵。
from keras.models import Sequential from keras.layers import Activation, Dense from keras import initializers my_init = initializers.Orthogonal(gain = 1.0, seed = None) model.add(Dense(512, activation = 'relu', input_shape = (784,), kernel_initializer = my_init))
其中,gain 表示矩阵的乘法因子。
单位矩阵
生成单位矩阵。
from keras.models import Sequential from keras.layers import Activation, Dense from keras import initializers my_init = initializers.Identity(gain = 1.0) model.add( Dense(512, activation = 'relu', input_shape = (784,), kernel_initializer = my_init) )
约束
在机器学习中,会在优化阶段对参数(权重)设置约束。<>约束模块提供不同的函数来设置层的约束。一些约束函数如下所示。
非负约束 (NonNeg)
约束权重为非负数。
from keras.models import Sequential from keras.layers import Activation, Dense from keras import initializers my_init = initializers.Identity(gain = 1.0) model.add( Dense(512, activation = 'relu', input_shape = (784,), kernel_initializer = my_init) )
其中,kernel_constraint 表示要用于该层的约束。
单位范数约束 (UnitNorm)
约束权重为单位范数。
from keras.models import Sequential from keras.layers import Activation, Dense from keras import constraints my_constrain = constraints.UnitNorm(axis = 0) model = Sequential() model.add(Dense(512, activation = 'relu', input_shape = (784,), kernel_constraint = my_constrain))
最大范数约束 (MaxNorm)
约束权重范数小于或等于给定值。
from keras.models import Sequential from keras.layers import Activation, Dense from keras import constraints my_constrain = constraints.MaxNorm(max_value = 2, axis = 0) model = Sequential() model.add(Dense(512, activation = 'relu', input_shape = (784,), kernel_constraint = my_constrain))
其中:
max_value 表示上限
axis 表示应用约束的维度。例如,在形状 (2,3,4) 中,axis 0 表示第一维度,1 表示第二维度,2 表示第三维度。
最小最大范数约束 (MinMaxNorm)
约束权重范数在指定的最小值和最大值之间。
from keras.models import Sequential from keras.layers import Activation, Dense from keras import constraints my_constrain = constraints.MinMaxNorm(min_value = 0.0, max_value = 1.0, rate = 1.0, axis = 0) model = Sequential() model.add(Dense(512, activation = 'relu', input_shape = (784,), kernel_constraint = my_constrain))
其中,rate 表示应用权重约束的速率。
正则化器
在机器学习中,正则化器用于优化阶段。它在优化过程中对层参数施加一些惩罚。Keras 正则化模块提供以下函数来设置层的惩罚。正则化仅按层应用。
L1 正则化器 (L1 Regularizer)
它提供基于 L1 的正则化。
from keras.models import Sequential from keras.layers import Activation, Dense from keras import regularizers my_regularizer = regularizers.l1(0.) model = Sequential() model.add(Dense(512, activation = 'relu', input_shape = (784,), kernel_regularizer = my_regularizer))
其中,kernel_regularizer 表示应用权重约束的速率。
L2 正则化器 (L2 Regularizer)
它提供基于 L2 的正则化。
from keras.models import Sequential from keras.layers import Activation, Dense from keras import regularizers my_regularizer = regularizers.l2(0.) model = Sequential() model.add(Dense(512, activation = 'relu', input_shape = (784,), kernel_regularizer = my_regularizer))
L1 和 L2 正则化器 (L1 and L2 Regularizer)
它同时提供基于 L1 和 L2 的正则化。
from keras.models import Sequential from keras.layers import Activation, Dense from keras import regularizers my_regularizer = regularizers.l2(0.) model = Sequential() model.add(Dense(512, activation = 'relu', input_shape = (784,), kernel_regularizer = my_regularizer))
激活函数
在机器学习中,激活函数是一种特殊的函数,用于确定特定神经元是否被激活。基本上,激活函数对输入数据进行非线性变换,从而使神经元能够更好地学习。神经元的输出取决于激活函数。
正如你回忆起单感知器的概念一样,感知器(神经元)的输出只是激活函数的结果,它接受所有输入与其对应权重的乘积之和,以及任何可用的整体偏差。
result = Activation(SUMOF(input * weight) + bias)
因此,激活函数在模型的成功学习中起着重要作用。Keras 在 activations 模块中提供了许多激活函数。让我们学习该模块中所有可用的激活函数。
线性 (linear)
应用线性函数。什么也不做。
from keras.models import Sequential from keras.layers import Activation, Dense model = Sequential() model.add(Dense(512, activation = 'linear', input_shape = (784,)))
其中,activation 指的是层的激活函数。它可以通过函数名简单地指定,层将使用相应的激活器。
指数线性单元 (elu)
应用指数线性单元。
from keras.models import Sequential from keras.layers import Activation, Dense model = Sequential() model.add(Dense(512, activation = 'elu', input_shape = (784,)))
缩放指数线性单元 (selu)
应用缩放指数线性单元。
from keras.models import Sequential from keras.layers import Activation, Dense model = Sequential() model.add(Dense(512, activation = 'selu', input_shape = (784,)))
修正线性单元 (relu)
应用修正线性单元。
from keras.models import Sequential from keras.layers import Activation, Dense model = Sequential() model.add(Dense(512, activation = 'relu', input_shape = (784,)))
Softmax (softmax)
应用 Softmax 函数。
from keras.models import Sequential from keras.layers import Activation, Dense model = Sequential() model.add(Dense(512, activation = 'softmax', input_shape = (784,)))
Softplus (softplus)
应用 Softplus 函数。
from keras.models import Sequential from keras.layers import Activation, Dense model = Sequential() model.add(Dense(512, activation = 'softplus', input_shape = (784,)))
Softsign (softsign)
应用 Softsign 函数。
from keras.models import Sequential from keras.layers import Activation, Dense model = Sequential() model.add(Dense(512, activation = 'softsign', input_shape = (784,)))
双曲正切 (tanh)
应用双曲正切函数。
from keras.models import Sequential from keras.layers import Activation, Dense model = Sequential() model.add(Dense(512, activation = 'tanh', input_shape = (784,)))
Sigmoid (sigmoid)
应用 Sigmoid 函数。
from keras.models import Sequential from keras.layers import Activation, Dense model = Sequential() model.add(Dense(512, activation = 'sigmoid', input_shape = (784,)))
硬 Sigmoid (hard_sigmoid)
应用硬 Sigmoid 函数。
from keras.models import Sequential from keras.layers import Activation, Dense model = Sequential() model.add(Dense(512, activation = 'hard_sigmoid', input_shape = (784,)))
指数 (exponential)
应用指数函数。
from keras.models import Sequential from keras.layers import Activation, Dense model = Sequential() model.add(Dense(512, activation = 'exponential', input_shape = (784,)))
| 序号 (Sr.No) | 层和描述 (Layers & Description) |
|---|---|
| 1 |
稠密层是常规的全连接神经网络层。 |
| 2 |
Dropout是机器学习中的一个重要概念。 |
| 3 |
Flatten 用于扁平化输入。 |
| 4 |
Reshape 用于更改输入的形状。 |
| 5 |
Permute 也用于使用模式更改输入的形状。 |
| 6 |
RepeatVector 用于将输入重复设定的次数 n。 |
| 7 |
Lambda 用于使用表达式或函数转换输入数据。 |
| 8 |
Keras 包含许多用于创建基于卷积的 ANN 的层,通常称为卷积神经网络 (CNN)。 |
| 9 |
它用于对时间数据执行最大池化操作。 |
| 10 |
局部连接层 (Locally connected layer) 局部连接层类似于 Conv1D 层,但不同之处在于 Conv1D 层的权重是共享的,而这里的权重是不共享的。 |
| 11 |
它用于合并输入列表。 |
| 12 |
它在输入层执行嵌入操作。 |
Keras - 自定义层
Keras 允许创建我们自己的自定义层。创建新层后,它可以在任何模型中使用,没有任何限制。让我们在本节学习如何创建新层。
Keras 提供了一个基本的层类 Layer,可以对其进行子类化以创建我们自己的自定义层。让我们创建一个简单的层,它将根据正态分布查找权重,然后在训练期间进行查找输入与其权重乘积之和的基本计算。
步骤 1:导入必要的模块
首先,让我们导入必要的模块:
from keras import backend as K from keras.layers import Layer
这里:
backend 用于访问dot 函数。
Layer 是基类,我们将对其进行子类化以创建我们的层。
步骤 2:定义层类
让我们通过子类化Layer 类创建一个新类MyCustomLayer:
class MyCustomLayer(Layer): ...
步骤 3:初始化层类
让我们按如下所示初始化我们的新类:
def __init__(self, output_dim, **kwargs): self.output_dim = output_dim super(MyCustomLayer, self).__init__(**kwargs)
这里:
第 2 行设置输出维度。
第 3 行调用基类或超类的init 函数。
步骤 4:实现 build 方法
build 是主要方法,其唯一目的是正确构建层。它可以执行与层的内部工作相关的任何操作。完成自定义功能后,我们可以调用基类的build 函数。我们的自定义build 函数如下所示:
def build(self, input_shape):
self.kernel = self.add_weight(name = 'kernel',
shape = (input_shape[1], self.output_dim),
initializer = 'normal', trainable = True)
super(MyCustomLayer, self).build(input_shape)
这里:
第 1 行定义了带有一个参数input_shape 的build 方法。输入数据的形状由 input_shape 指示。
第 2 行创建与输入形状对应的权重,并将其设置在 kernel 中。这是我们层的自定义功能。它使用“normal”初始化器创建权重。
第 6 行调用基类build 方法。
步骤 5:实现 call 方法
call 方法在训练过程中执行层的精确工作。
我们的自定义call 方法如下所示:
def call(self, input_data): return K.dot(input_data, self.kernel)
这里:
第 1 行定义了带有一个参数input_data 的call 方法。input_data 是我们层的输入数据。
第 2 行返回输入数据input_data 和我们层的内核self.kernel 的点积。
步骤 6:实现 compute_output_shape 方法
def compute_output_shape(self, input_shape): return (input_shape[0], self.output_dim)
这里:
第 1 行定义了带有一个参数input_shape 的compute_output_shape 方法。
第 2 行使用输入数据的形状和初始化层时设置的输出维度来计算输出形状。
实现build、call 和compute_output_shape 完成了创建自定义层。最终完整的代码如下所示:
from keras import backend as K from keras.layers import Layer
class MyCustomLayer(Layer):
def __init__(self, output_dim, **kwargs):
self.output_dim = output_dim
super(MyCustomLayer, self).__init__(**kwargs)
def build(self, input_shape): self.kernel =
self.add_weight(name = 'kernel',
shape = (input_shape[1], self.output_dim),
initializer = 'normal', trainable = True)
super(MyCustomLayer, self).build(input_shape) #
Be sure to call this at the end
def call(self, input_data): return K.dot(input_data, self.kernel)
def compute_output_shape(self, input_shape): return (input_shape[0], self.output_dim)
使用我们的自定义层
让我们使用我们的自定义层创建一个简单的模型,如下所示:
from keras.models import Sequential from keras.layers import Dense model = Sequential() model.add(MyCustomLayer(32, input_shape = (16,))) model.add(Dense(8, activation = 'softmax')) model.summary()
这里:
我们的MyCustomLayer 使用 32 个单元和(16,) 作为输入形状添加到模型中。
运行应用程序将打印如下所示的模型摘要:
Model: "sequential_1" _________________________________________________________________ Layer (type) Output Shape Param #================================================================ my_custom_layer_1 (MyCustomL (None, 32) 512 _________________________________________________________________ dense_1 (Dense) (None, 8) 264 ================================================================= Total params: 776 Trainable params: 776 Non-trainable params: 0 _________________________________________________________________
Keras - 模型
如前所述,Keras 模型表示实际的神经网络模型。Keras 提供两种模式来创建模型,简单易用的顺序 API 以及更灵活和高级的函数式 API。让我们在本节学习如何使用顺序和函数式 API 创建模型。
顺序 API (Sequential)
顺序 API 的核心思想是简单地按顺序排列 Keras 层,因此它被称为顺序 API。大多数 ANN 的层也是按顺序排列的,数据按给定顺序从一层流向另一层,直到数据最终到达输出层。
可以通过简单地调用Sequential() API 来创建一个 ANN 模型,如下所示:
from keras.models import Sequential model = Sequential()
添加层 (Add layers)
要添加一个层,只需使用 Keras 层 API 创建一个层,然后将该层通过 add() 函数传递,如下所示:
from keras.models import Sequential model = Sequential() input_layer = Dense(32, input_shape=(8,)) model.add(input_layer) hidden_layer = Dense(64, activation='relu'); model.add(hidden_layer) output_layer = Dense(8) model.add(output_layer)
在这里,我们创建了一个输入层、一个隐藏层和一个输出层。
访问模型 (Access the model)
Keras 提供了一些方法来获取模型信息,例如层、输入数据和输出数据。它们如下所示:
model.layers - 将模型的所有层作为列表返回。
>>> layers = model.layers >>> layers [ <keras.layers.core.Dense object at 0x000002C8C888B8D0>, <keras.layers.core.Dense object at 0x000002C8C888B7B8> <keras.layers.core.Dense object at 0x 000002C8C888B898> ]
model.inputs - 将模型的所有输入张量作为列表返回。
>>> inputs = model.inputs >>> inputs [<tf.Tensor 'dense_13_input:0' shape=(?, 8) dtype=float32>]
model.outputs - 将模型的所有输出张量作为列表返回。
>>> outputs = model.outputs >>> outputs <tf.Tensor 'dense_15/BiasAdd:0' shape=(?, 8) dtype=float32>]
model.get_weights - 将所有权重作为 NumPy 数组返回。
model.set_weights(weight_numpy_array) - 设置模型的权重。
序列化模型 (Serialize the model)
Keras 提供了将模型序列化为对象以及 json 并稍后再次加载它的方法。它们如下所示:
get_config() - 将模型作为对象返回。
config = model.get_config()
from_config() - 它接受模型配置对象作为参数,并相应地创建模型。
new_model = Sequential.from_config(config)
to_json() - 将模型作为 json 对象返回。
>>> json_string = model.to_json()
>>> json_string '{"class_name": "Sequential", "config":
{"name": "sequential_10", "layers":
[{"class_name": "Dense", "config":
{"name": "dense_13", "trainable": true, "batch_input_shape":
[null, 8], "dtype": "float32", "units": 32, "activation": "linear",
"use_bias": true, "kernel_initializer":
{"class_name": "Vari anceScaling", "config":
{"scale": 1.0, "mode": "fan_avg", "distribution": "uniform", "seed": null}},
"bias_initializer": {"class_name": "Zeros", "conf
ig": {}}, "kernel_regularizer": null, "bias_regularizer": null,
"activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null}},
{" class_name": "Dense", "config": {"name": "dense_14", "trainable": true,
"dtype": "float32", "units": 64, "activation": "relu", "use_bias": true,
"kern el_initializer": {"class_name": "VarianceScaling", "config":
{"scale": 1.0, "mode": "fan_avg", "distribution": "uniform", "seed": null}},
"bias_initia lizer": {"class_name": "Zeros",
"config": {}}, "kernel_regularizer": null, "bias_regularizer": null,
"activity_regularizer": null, "kernel_constraint" : null, "bias_constraint": null}},
{"class_name": "Dense", "config": {"name": "dense_15", "trainable": true,
"dtype": "float32", "units": 8, "activation": "linear", "use_bias": true,
"kernel_initializer": {"class_name": "VarianceScaling", "config":
{"scale": 1.0, "mode": "fan_avg", "distribution": " uniform", "seed": null}},
"bias_initializer": {"class_name": "Zeros", "config": {}},
"kernel_regularizer": null, "bias_regularizer": null, "activity_r egularizer":
null, "kernel_constraint": null, "bias_constraint":
null}}]}, "keras_version": "2.2.5", "backend": "tensorflow"}'
>>>
model_from_json() - 接受模型的 json 表示,并创建一个新模型。
from keras.models import model_from_json new_model = model_from_json(json_string)
to_yaml() - 将模型作为 yaml 字符串返回。
>>> yaml_string = model.to_yaml()
>>> yaml_string 'backend: tensorflow\nclass_name:
Sequential\nconfig:\n layers:\n - class_name: Dense\n config:\n
activation: linear\n activity_regular izer: null\n batch_input_shape:
!!python/tuple\n - null\n - 8\n bias_constraint: null\n bias_initializer:\n
class_name : Zeros\n config: {}\n bias_regularizer: null\n dtype:
float32\n kernel_constraint: null\n
kernel_initializer:\n cla ss_name: VarianceScaling\n config:\n
distribution: uniform\n mode: fan_avg\n
scale: 1.0\n seed: null\n kernel_regularizer: null\n name: dense_13\n
trainable: true\n units: 32\n
use_bias: true\n - class_name: Dense\n config:\n activation: relu\n activity_regularizer: null\n
bias_constraint: null\n bias_initializer:\n class_name: Zeros\n
config : {}\n bias_regularizer: null\n dtype: float32\n
kernel_constraint: null\n kernel_initializer:\n class_name: VarianceScalin g\n
config:\n distribution: uniform\n mode: fan_avg\n scale: 1.0\n
seed: null\n kernel_regularizer: nu ll\n name: dense_14\n trainable: true\n
units: 64\n use_bias: true\n - class_name: Dense\n config:\n
activation: linear\n activity_regularizer: null\n
bias_constraint: null\n bias_initializer:\n
class_name: Zeros\n config: {}\n bias_regu larizer: null\n
dtype: float32\n kernel_constraint: null\n
kernel_initializer:\n class_name: VarianceScaling\n config:\n
distribution: uniform\n mode: fan_avg\n
scale: 1.0\n seed: null\n kernel_regularizer: null\n name: dense _15\n
trainable: true\n units: 8\n
use_bias: true\n name: sequential_10\nkeras_version: 2.2.5\n'
>>>
model_from_yaml() - 接受模型的 yaml 表示,并创建一个新模型。
from keras.models import model_from_yaml new_model = model_from_yaml(yaml_string)
模型摘要 (Summarise the model)
了解模型对于正确使用它进行训练和预测非常重要。Keras 提供了一个简单的方法 summary,用于获取有关模型及其层的完整信息。
上一节中创建的模型的摘要如下所示:
>>> model.summary() Model: "sequential_10" _________________________________________________________________ Layer (type) Output Shape Param #================================================================ dense_13 (Dense) (None, 32) 288 _________________________________________________________________ dense_14 (Dense) (None, 64) 2112 _________________________________________________________________ dense_15 (Dense) (None, 8) 520 ================================================================= Total params: 2,920 Trainable params: 2,920 Non-trainable params: 0 _________________________________________________________________ >>>
训练和预测模型 (Train and Predict the model)
模型提供用于训练、评估和预测过程的函数。它们如下所示:
compile - 配置模型的学习过程。
fit - 使用训练数据训练模型。
evaluate - 使用测试数据评估模型。
predict - 预测新输入的结果。
函数式 API (Functional API)
顺序API用于逐层创建模型。函数式API是创建更复杂模型的另一种方法。在函数式模型中,您可以定义共享层的多个输入或输出。首先,我们为模型创建一个实例,并连接到各层以访问模型的输入和输出。本节简要介绍函数式模型。
创建模型
使用以下模块导入输入层:
>>> from keras.layers import Input
现在,使用以下代码创建指定模型输入维度形状的输入层:
>>> data = Input(shape=(2,3))
使用以下模块为输入定义层:
>>> from keras.layers import Dense
使用以下代码行为输入添加密集层:
>>> layer = Dense(2)(data)
>>> print(layer)
Tensor("dense_1/add:0", shape =(?, 2, 2), dtype = float32)
使用以下模块定义模型:
from keras.models import Model
通过指定输入层和输出层,以函数式方式创建模型:
model = Model(inputs = data, outputs = layer)
创建简单模型的完整代码如下所示:
from keras.layers import Input from keras.models import Model from keras.layers import Dense data = Input(shape=(2,3)) layer = Dense(2)(data) model = Model(inputs=data,outputs=layer) model.summary() _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_2 (InputLayer) (None, 2, 3) 0 _________________________________________________________________ dense_2 (Dense) (None, 2, 2) 8 ================================================================= Total params: 8 Trainable params: 8 Non-trainable params: 0 _________________________________________________________________
Keras - 模型编译
前面我们学习了如何使用顺序API和函数式API创建模型的基础知识。本章将解释如何编译模型。编译是创建模型的最后一步。编译完成后,我们可以进入训练阶段。
让我们学习一些有助于更好地理解编译过程的概念。
损失函数
在机器学习中,**损失函数**用于查找学习过程中的误差或偏差。Keras在模型编译过程中需要损失函数。
Keras在**losses**模块中提供了许多损失函数,如下所示:
- 均方误差 (mean_squared_error)
- 平均绝对误差 (mean_absolute_error)
- 平均绝对百分比误差 (mean_absolute_percentage_error)
- 均方对数误差 (mean_squared_logarithmic_error)
- 平方铰链损失 (squared_hinge)
- 铰链损失 (hinge)
- 分类铰链损失 (categorical_hinge)
- 对数余弦损失 (logcosh)
- Huber损失 (huber_loss)
- 分类交叉熵 (categorical_crossentropy)
- 稀疏分类交叉熵 (sparse_categorical_crossentropy)
- 二元交叉熵 (binary_crossentropy)
- Kullback-Leibler 散度 (kullback_leibler_divergence)
- 泊松损失 (poisson)
- 余弦相似度 (cosine_proximity)
- is_categorical_crossentropy
以上所有损失函数都接受两个参数:
**y_true** - 真实标签(张量)
**y_pred** - 预测值,形状与**y_true**相同
使用损失函数前,请按如下所示导入losses模块:
from keras import losses
优化器
在机器学习中,**优化**是一个重要的过程,它通过比较预测值和损失函数来优化输入权重。Keras提供了一些优化器模块, *optimizers* ,如下所示:
**SGD** - 随机梯度下降优化器。
keras.optimizers.SGD(learning_rate = 0.01, momentum = 0.0, nesterov = False)
**RMSprop** - RMSProp 优化器。
keras.optimizers.RMSprop(learning_rate = 0.001, rho = 0.9)
**Adagrad** - Adagrad 优化器。
keras.optimizers.Adagrad(learning_rate = 0.01)
**Adadelta** - Adadelta 优化器。
keras.optimizers.Adadelta(learning_rate = 1.0, rho = 0.95)
**Adam** - Adam 优化器。
keras.optimizers.Adam( learning_rate = 0.001, beta_1 = 0.9, beta_2 = 0.999, amsgrad = False )
**Adamax** - 来自Adam的Adamax优化器。
keras.optimizers.Adamax(learning_rate = 0.002, beta_1 = 0.9, beta_2 = 0.999)
**Nadam** - Nesterov Adam 优化器。
keras.optimizers.Nadam(learning_rate = 0.002, beta_1 = 0.9, beta_2 = 0.999)
使用优化器前,请按如下所示导入optimizers模块:
from keras import optimizers
评估指标
在机器学习中,**评估指标**用于评估模型的性能。它类似于损失函数,但不用于训练过程。Keras在**metrics**模块中提供了许多评估指标,如下所示:
- 准确率 (accuracy)
- 二元准确率 (binary_accuracy)
- 分类准确率 (categorical_accuracy)
- 稀疏分类准确率 (sparse_categorical_accuracy)
- Top-k 分类准确率 (top_k_categorical_accuracy)
- 稀疏 Top-k 分类准确率 (sparse_top_k_categorical_accuracy)
- 余弦相似度 (cosine_proximity)
- 克隆指标 (clone_metric)
与损失函数类似,评估指标也接受以下两个参数:
**y_true** - 真实标签(张量)
**y_pred** - 预测值,形状与**y_true**相同
使用评估指标前,请按如下所示导入metrics模块:
from keras import metrics
编译模型
Keras模型提供了一个方法**compile()**来编译模型。**compile()**方法的参数及其默认值如下所示:
compile( optimizer, loss = None, metrics = None, loss_weights = None, sample_weight_mode = None, weighted_metrics = None, target_tensors = None )
重要的参数如下:
- 损失函数
- 优化器
- 评估指标
编译模型的示例代码如下:
from keras import losses from keras import optimizers from keras import metrics model.compile(loss = 'mean_squared_error', optimizer = 'sgd', metrics = [metrics.categorical_accuracy])
其中:
损失函数设置为**mean_squared_error**
优化器设置为**sgd**
评估指标设置为**metrics.categorical_accuracy**
模型训练
模型使用NumPy数组通过**fit()**进行训练。此fit函数的主要目的是用于评估模型的训练效果。它也可以用于绘制模型性能图。其语法如下:
model.fit(X, y, epochs = , batch_size = )
这里:
**X, y** - 用于评估数据的元组。
**epochs** - 模型在训练期间需要评估的次数。
**batch_size** - 训练实例数。
让我们用一个简单的NumPy随机数据示例来演示这个概念。
创建数据
让我们使用以下命令使用NumPy创建x和y的随机数据:
import numpy as np x_train = np.random.random((100,4,8)) y_train = np.random.random((100,10))
现在,创建随机验证数据:
x_val = np.random.random((100,4,8)) y_val = np.random.random((100,10))
创建模型
让我们创建一个简单的顺序模型:
from keras.models import Sequential model = Sequential()
添加层 (Add layers)
创建要添加到模型的层:
from keras.layers import LSTM, Dense # add a sequence of vectors of dimension 16 model.add(LSTM(16, return_sequences = True)) model.add(Dense(10, activation = 'softmax'))
编译模型
现在模型已定义。您可以使用以下命令进行编译:
model.compile( loss = 'categorical_crossentropy', optimizer = 'sgd', metrics = ['accuracy'] )
应用fit()
现在我们应用fit()函数来训练我们的数据:
model.fit(x_train, y_train, batch_size = 32, epochs = 5, validation_data = (x_val, y_val))
创建多层感知器人工神经网络 (MLP ANN)
我们已经学习了如何创建、编译和训练Keras模型。
让我们运用我们的知识创建一个基于MLP的简单人工神经网络。
数据集模块
在创建模型之前,我们需要选择一个问题,收集所需的数据并将数据转换为NumPy数组。收集数据后,我们可以准备模型并使用收集到的数据对其进行训练。数据收集是机器学习中最困难的阶段之一。Keras提供了一个特殊的模块datasets,用于下载在线机器学习数据以进行训练。它从在线服务器获取数据,处理数据并将数据作为训练集和测试集返回。让我们检查Keras数据集模块提供的数据。该模块中可用的数据如下:
- CIFAR10 小型图像分类
- CIFAR100 小型图像分类
- IMDB 电影评论情感分类
- 路透社新闻主题分类
- MNIST 手写数字数据库
- Fashion-MNIST 时尚服装数据库
- 波士顿房价回归数据集
让我们使用**MNIST 手写数字数据库** (或minst)作为我们的输入。minst包含60,000张28x28的灰度图像。它包含10个数字。它还包含10,000张测试图像。
可以使用以下代码加载数据集:
from keras.datasets import mnist (x_train, y_train), (x_test, y_test) = mnist.load_data()
其中
**第1行**从keras数据集模块导入**minst**。
**第3行**调用**load_data**函数,该函数将从在线服务器获取数据,并将其作为2个元组返回。第一个元组**(x_train, y_train)**表示形状为**(样本数, 28, 28)**的训练数据及其形状为**(样本数,)**的数字标签。第二个元组**(x_test, y_test)**表示形状相同的测试数据。
其他数据集也可以使用类似的API获取,每个API返回的数据也类似,只是数据的形状不同。数据的形状取决于数据的类型。
创建模型
让我们选择一个简单的多层感知器(MLP),如下所示,并尝试使用Keras创建模型。

模型的核心特征如下:
输入层包含784个值 (28 x 28 = 784)。
第一隐藏层,**Dense**包含512个神经元和'relu'激活函数。
第二隐藏层,**Dropout**的值为0.2。
第三隐藏层,再次是Dense,包含512个神经元和'relu'激活函数。
第四隐藏层,**Dropout**的值为0.2。
第五层也是最后一层包含10个神经元和'softmax'激活函数。
使用**categorical_crossentropy**作为损失函数。
使用**RMSprop()**作为优化器。
使用**accuracy**作为评估指标。
使用128作为批量大小。
使用20作为迭代次数。
步骤1 - 导入模块
让我们导入必要的模块。
import keras from keras.datasets import mnist from keras.models import Sequential from keras.layers import Dense, Dropout from keras.optimizers import RMSprop import numpy as np
步骤2 - 加载数据
让我们导入mnist数据集。
(x_train, y_train), (x_test, y_test) = mnist.load_data()
步骤3 - 处理数据
让我们根据我们的模型更改数据集,以便它可以输入到我们的模型中。
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)
其中
**reshape**用于将输入从(28, 28)元组重塑为(784,)
**to_categorical**用于将向量转换为二元矩阵
步骤4 - 创建模型
让我们创建实际的模型。
model = Sequential() model.add(Dense(512, activation = 'relu', input_shape = (784,))) model.add(Dropout(0.2)) model.add(Dense(512, activation = 'relu')) model.add(Dropout(0.2)) model.add(Dense(10, activation = 'softmax'))
步骤5 - 编译模型
让我们使用选择的损失函数、优化器和评估指标来编译模型。
model.compile(loss = 'categorical_crossentropy', optimizer = RMSprop(), metrics = ['accuracy'])
步骤6 - 训练模型
让我们使用**fit()**方法训练模型。
history = model.fit( x_train, y_train, batch_size = 128, epochs = 20, verbose = 1, validation_data = (x_test, y_test) )
最终想法
我们已经创建了模型,加载了数据,并将数据训练到模型中。我们仍然需要评估模型并预测未知输入的输出,这将在接下来的章节中学习。
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import RMSprop
import numpy as np
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)
model = Sequential()
model.add(Dense(512, activation='relu', input_shape = (784,)))
model.add(Dropout(0.2))
model.add(Dense(512, activation = 'relu')) model.add(Dropout(0.2))
model.add(Dense(10, activation = 'softmax'))
model.compile(loss = 'categorical_crossentropy',
optimizer = RMSprop(),
metrics = ['accuracy'])
history = model.fit(x_train, y_train,
batch_size = 128, epochs = 20, verbose = 1, validation_data = (x_test, y_test))
执行应用程序将输出以下内容:
Train on 60000 samples, validate on 10000 samples Epoch 1/20 60000/60000 [==============================] - 7s 118us/step - loss: 0.2453 - acc: 0.9236 - val_loss: 0.1004 - val_acc: 0.9675 Epoch 2/20 60000/60000 [==============================] - 7s 110us/step - loss: 0.1023 - acc: 0.9693 - val_loss: 0.0797 - val_acc: 0.9761 Epoch 3/20 60000/60000 [==============================] - 7s 110us/step - loss: 0.0744 - acc: 0.9770 - val_loss: 0.0727 - val_acc: 0.9791 Epoch 4/20 60000/60000 [==============================] - 7s 110us/step - loss: 0.0599 - acc: 0.9823 - val_loss: 0.0704 - val_acc: 0.9801 Epoch 5/20 60000/60000 [==============================] - 7s 112us/step - loss: 0.0504 - acc: 0.9853 - val_loss: 0.0714 - val_acc: 0.9817 Epoch 6/20 60000/60000 [==============================] - 7s 111us/step - loss: 0.0438 - acc: 0.9868 - val_loss: 0.0845 - val_acc: 0.9809 Epoch 7/20 60000/60000 [==============================] - 7s 114us/step - loss: 0.0391 - acc: 0.9887 - val_loss: 0.0823 - val_acc: 0.9802 Epoch 8/20 60000/60000 [==============================] - 7s 112us/step - loss: 0.0364 - acc: 0.9892 - val_loss: 0.0818 - val_acc: 0.9830 Epoch 9/20 60000/60000 [==============================] - 7s 113us/step - loss: 0.0308 - acc: 0.9905 - val_loss: 0.0833 - val_acc: 0.9829 Epoch 10/20 60000/60000 [==============================] - 7s 112us/step - loss: 0.0289 - acc: 0.9917 - val_loss: 0.0947 - val_acc: 0.9815 Epoch 11/20 60000/60000 [==============================] - 7s 112us/step - loss: 0.0279 - acc: 0.9921 - val_loss: 0.0818 - val_acc: 0.9831 Epoch 12/20 60000/60000 [==============================] - 7s 112us/step - loss: 0.0260 - acc: 0.9927 - val_loss: 0.0945 - val_acc: 0.9819 Epoch 13/20 60000/60000 [==============================] - 7s 112us/step - loss: 0.0257 - acc: 0.9931 - val_loss: 0.0952 - val_acc: 0.9836 Epoch 14/20 60000/60000 [==============================] - 7s 112us/step - loss: 0.0229 - acc: 0.9937 - val_loss: 0.0924 - val_acc: 0.9832 Epoch 15/20 60000/60000 [==============================] - 7s 115us/step - loss: 0.0235 - acc: 0.9937 - val_loss: 0.1004 - val_acc: 0.9823 Epoch 16/20 60000/60000 [==============================] - 7s 113us/step - loss: 0.0214 - acc: 0.9941 - val_loss: 0.0991 - val_acc: 0.9847 Epoch 17/20 60000/60000 [==============================] - 7s 112us/step - loss: 0.0219 - acc: 0.9943 - val_loss: 0.1044 - val_acc: 0.9837 Epoch 18/20 60000/60000 [==============================] - 7s 112us/step - loss: 0.0190 - acc: 0.9952 - val_loss: 0.1129 - val_acc: 0.9836 Epoch 19/20 60000/60000 [==============================] - 7s 112us/step - loss: 0.0197 - acc: 0.9953 - val_loss: 0.0981 - val_acc: 0.9841 Epoch 20/20 60000/60000 [==============================] - 7s 112us/step - loss: 0.0198 - acc: 0.9950 - val_loss: 0.1215 - val_acc: 0.9828
Keras - 模型评估和模型预测
本章介绍Keras中的模型评估和模型预测。
让我们首先了解模型评估。
模型评估
评估是在模型开发过程中检查模型是否最适合给定问题和相应数据的一个过程。Keras模型提供了一个函数evaluate,用于执行模型评估。它有三个主要参数:
- 测试数据
- 测试数据标签
- verbose - true 或 false
让我们使用测试数据评估我们在上一章中创建的模型。
score = model.evaluate(x_test, y_test, verbose = 0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
执行上述代码将输出以下信息。
0
测试准确率为98.28%。我们已经创建了一个识别手写数字的最佳模型。积极的一面是,我们仍然可以改进我们的模型。
模型预测
**预测**是最后一步,也是我们期望的模型生成结果。Keras提供了一个方法predict来获取训练模型的预测结果。predict方法的签名如下:
predict( x, batch_size = None, verbose = 0, steps = None, callbacks = None, max_queue_size = 10, workers = 1, use_multiprocessing = False )
这里,除了第一个参数(指的是未知输入数据)外,所有参数都是可选的。为了获得正确的预测,应保持形状不变。
让我们使用以下代码对我们在上一章中创建的MLP模型进行预测:
pred = model.predict(x_test) pred = np.argmax(pred, axis = 1)[:5] label = np.argmax(y_test,axis = 1)[:5] print(pred) print(label)
这里:
**第1行**使用测试数据调用predict函数。
**第2行**获取前五个预测结果。
**第3行**获取测试数据的前五个标签。
**第5-6行**打印预测结果和实际标签。
上述应用程序的输出如下:
[7 2 1 0 4] [7 2 1 0 4]
两个数组的输出相同,这表明我们的模型正确预测了前五张图像。
Keras - 卷积神经网络
让我们将模型从MLP修改为**卷积神经网络 (CNN)**,用于我们之前的数字识别问题。
CNN可以表示为:
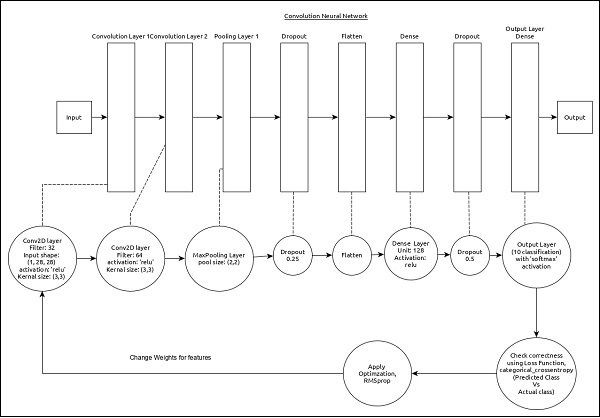
模型的核心特征如下:
输入层包含(1, 8, 28)个值。
第一层,Conv2D包含32个过滤器和‘relu’激活函数,内核大小为(3,3)。
第二层,Conv2D包含64个过滤器和‘relu’激活函数,内核大小为(3,3)。
第三层,MaxPooling池大小为(2, 2)。
第五层,使用Flatten将所有输入展平为一维。
第六层,Dense包含128个神经元和‘relu’激活函数。
第七层,Dropout值为0.5。
第八层也是最后一层包含10个神经元和‘softmax’激活函数。
使用**categorical_crossentropy**作为损失函数。
使用Adadelta()作为优化器。
使用**accuracy**作为评估指标。
使用128作为批量大小。
使用20作为迭代次数。
步骤1 - 导入模块
让我们导入必要的模块。
import keras from keras.datasets import mnist from keras.models import Sequential from keras.layers import Dense, Dropout, Flatten from keras.layers import Conv2D, MaxPooling2D from keras import backend as K import numpy as np
步骤2 - 加载数据
让我们导入mnist数据集。
(x_train, y_train), (x_test, y_test) = mnist.load_data()
步骤3 - 处理数据
让我们根据我们的模型更改数据集,以便它可以输入到我们的模型中。
img_rows, img_cols = 28, 28
if K.image_data_format() == 'channels_first':
x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols)
x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols)
input_shape = (1, img_rows, img_cols)
else:
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)
数据处理与MPL模型类似,只是输入数据形状和图像格式配置不同。
步骤4 - 创建模型
让我们创建实际模型。
model = Sequential() model.add(Conv2D(32, kernel_size = (3, 3), activation = 'relu', input_shape = input_shape)) model.add(Conv2D(64, (3, 3), activation = 'relu')) model.add(MaxPooling2D(pool_size = (2, 2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(128, activation = 'relu')) model.add(Dropout(0.5)) model.add(Dense(10, activation = 'softmax'))
步骤5 - 编译模型
让我们使用选择的损失函数、优化器和评估指标来编译模型。
model.compile(loss = keras.losses.categorical_crossentropy, optimizer = keras.optimizers.Adadelta(), metrics = ['accuracy'])
步骤6 - 训练模型
让我们使用fit()方法训练模型。
model.fit( x_train, y_train, batch_size = 128, epochs = 12, verbose = 1, validation_data = (x_test, y_test) )
执行应用程序将输出以下信息:
Train on 60000 samples, validate on 10000 samples Epoch 1/12 60000/60000 [==============================] - 84s 1ms/step - loss: 0.2687 - acc: 0.9173 - val_loss: 0.0549 - val_acc: 0.9827 Epoch 2/12 60000/60000 [==============================] - 86s 1ms/step - loss: 0.0899 - acc: 0.9737 - val_loss: 0.0452 - val_acc: 0.9845 Epoch 3/12 60000/60000 [==============================] - 83s 1ms/step - loss: 0.0666 - acc: 0.9804 - val_loss: 0.0362 - val_acc: 0.9879 Epoch 4/12 60000/60000 [==============================] - 81s 1ms/step - loss: 0.0564 - acc: 0.9830 - val_loss: 0.0336 - val_acc: 0.9890 Epoch 5/12 60000/60000 [==============================] - 86s 1ms/step - loss: 0.0472 - acc: 0.9861 - val_loss: 0.0312 - val_acc: 0.9901 Epoch 6/12 60000/60000 [==============================] - 83s 1ms/step - loss: 0.0414 - acc: 0.9877 - val_loss: 0.0306 - val_acc: 0.9902 Epoch 7/12 60000/60000 [==============================] - 89s 1ms/step - loss: 0.0375 -acc: 0.9883 - val_loss: 0.0281 - val_acc: 0.9906 Epoch 8/12 60000/60000 [==============================] - 91s 2ms/step - loss: 0.0339 - acc: 0.9893 - val_loss: 0.0280 - val_acc: 0.9912 Epoch 9/12 60000/60000 [==============================] - 89s 1ms/step - loss: 0.0325 - acc: 0.9901 - val_loss: 0.0260 - val_acc: 0.9909 Epoch 10/12 60000/60000 [==============================] - 89s 1ms/step - loss: 0.0284 - acc: 0.9910 - val_loss: 0.0250 - val_acc: 0.9919 Epoch 11/12 60000/60000 [==============================] - 86s 1ms/step - loss: 0.0287 - acc: 0.9907 - val_loss: 0.0264 - val_acc: 0.9916 Epoch 12/12 60000/60000 [==============================] - 86s 1ms/step - loss: 0.0265 - acc: 0.9920 - val_loss: 0.0249 - val_acc: 0.9922
步骤7 - 评估模型
让我们使用测试数据评估模型。
score = model.evaluate(x_test, y_test, verbose = 0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
执行以上代码将输出以下信息:
Test loss: 0.024936060590433316 Test accuracy: 0.9922
测试精度为99.22%。我们已经创建了一个最佳模型来识别手写数字。
步骤8 - 预测
最后,如下预测图像中的数字:
pred = model.predict(x_test) pred = np.argmax(pred, axis = 1)[:5] label = np.argmax(y_test,axis = 1)[:5] print(pred) print(label)
上述应用程序的输出如下:
[7 2 1 0 4] [7 2 1 0 4]
两个数组的输出相同,这表明我们的模型正确预测了前五张图像。
Keras - 使用多层感知器 (MPL) 进行回归预测
本章,让我们编写一个简单的基于MPL的ANN进行回归预测。到目前为止,我们只进行了基于分类的预测。现在,我们将尝试通过分析之前的(连续)值及其影响因素来预测下一个可能的值。
回归MPL可以表示如下:
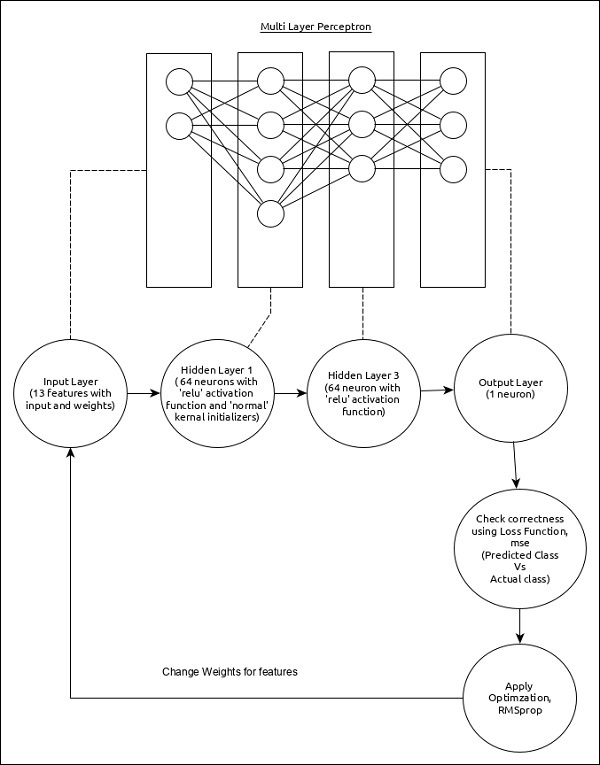
模型的核心特征如下:
输入层包含(13,)个值。
第一层,Dense包含64个单元和‘relu’激活函数,以及‘normal’内核初始化器。
第二层,Dense包含64个单元和‘relu’激活函数。
输出层,Dense包含1个单元。
使用mse作为损失函数。
使用RMSprop作为优化器。
使用**accuracy**作为评估指标。
使用128作为批量大小。
使用500个epochs。
步骤1 - 导入模块
让我们导入必要的模块。
import keras from keras.datasets import boston_housing from keras.models import Sequential from keras.layers import Dense from keras.optimizers import RMSprop from keras.callbacks import EarlyStopping from sklearn import preprocessing from sklearn.preprocessing import scale
步骤2 - 加载数据
让我们导入波士顿房价数据集。
(x_train, y_train), (x_test, y_test) = boston_housing.load_data()
这里:
boston_housing是Keras提供的数据集。它代表波士顿地区的一组住房信息,每个都有13个特征。
步骤3 - 处理数据
让我们根据我们的模型更改数据集,以便我们可以将其馈送到我们的模型中。数据可以使用以下代码更改:
x_train_scaled = preprocessing.scale(x_train) scaler = preprocessing.StandardScaler().fit(x_train) x_test_scaled = scaler.transform(x_test)
在这里,我们使用sklearn.preprocessing.scale函数对训练数据进行了归一化。preprocessing.StandardScaler().fit函数返回一个标量,其中包含训练数据的归一化均值和标准差,我们可以使用scalar.transform函数将其应用于测试数据。这也会使用与训练数据相同的设置来归一化测试数据。
步骤4 - 创建模型
让我们创建实际的模型。
model = Sequential() model.add(Dense(64, kernel_initializer = 'normal', activation = 'relu', input_shape = (13,))) model.add(Dense(64, activation = 'relu')) model.add(Dense(1))
步骤5 - 编译模型
让我们使用选择的损失函数、优化器和评估指标来编译模型。
model.compile( loss = 'mse', optimizer = RMSprop(), metrics = ['mean_absolute_error'] )
步骤6 - 训练模型
让我们使用fit()方法训练模型。
history = model.fit( x_train_scaled, y_train, batch_size=128, epochs = 500, verbose = 1, validation_split = 0.2, callbacks = [EarlyStopping(monitor = 'val_loss', patience = 20)] )
在这里,我们使用了回调函数EarlyStopping。此回调的目的是监控每个epoch期间的损失值,并将其与之前的epoch损失值进行比较,以找到训练的改进。如果在patience次内没有改进,则整个过程将停止。
执行应用程序将给出以下信息作为输出:
Train on 323 samples, validate on 81 samples Epoch 1/500 2019-09-24 01:07:03.889046: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not co mpiled to use: AVX2 323/323 [==============================] - 0s 515us/step - loss: 562.3129 - mean_absolute_error: 21.8575 - val_loss: 621.6523 - val_mean_absolute_erro r: 23.1730 Epoch 2/500 323/323 [==============================] - 0s 11us/step - loss: 545.1666 - mean_absolute_error: 21.4887 - val_loss: 605.1341 - val_mean_absolute_error : 22.8293 Epoch 3/500 323/323 [==============================] - 0s 12us/step - loss: 528.9944 - mean_absolute_error: 21.1328 - val_loss: 588.6594 - val_mean_absolute_error : 22.4799 Epoch 4/500 323/323 [==============================] - 0s 12us/step - loss: 512.2739 - mean_absolute_error: 20.7658 - val_loss: 570.3772 - val_mean_absolute_error : 22.0853 Epoch 5/500 323/323 [==============================] - 0s 9us/step - loss: 493.9775 - mean_absolute_error: 20.3506 - val_loss: 550.9548 - val_mean_absolute_error: 21.6547 .......... .......... .......... Epoch 143/500 323/323 [==============================] - 0s 15us/step - loss: 8.1004 - mean_absolute_error: 2.0002 - val_loss: 14.6286 - val_mean_absolute_error: 2. 5904 Epoch 144/500 323/323 [==============================] - 0s 19us/step - loss: 8.0300 - mean_absolute_error: 1.9683 - val_loss: 14.5949 - val_mean_absolute_error: 2. 5843 Epoch 145/500 323/323 [==============================] - 0s 12us/step - loss: 7.8704 - mean_absolute_error: 1.9313 - val_loss: 14.3770 - val_mean_absolute_error: 2. 4996
步骤7 - 评估模型
让我们使用测试数据评估模型。
score = model.evaluate(x_test_scaled, y_test, verbose = 0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
执行以上代码将输出以下信息:
Test loss: 21.928471583946077 Test accuracy: 2.9599233234629914
步骤7 - 评估模型
让我们使用测试数据评估模型。
score = model.evaluate(x_test_scaled, y_test, verbose = 0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
执行以上代码将输出以下信息:
Test loss: 21.928471583946077 Test accuracy: 2.9599233234629914
步骤8 - 预测
最后,使用测试数据进行预测,如下所示:
prediction = model.predict(x_test_scaled) print(prediction.flatten()) print(y_test)
上述应用程序的输出如下:
[ 7.5612316 17.583357 21.09344 31.859276 25.055613 18.673872 26.600405 22.403967 19.060272 22.264952 17.4191 17.00466 15.58924 41.624374 20.220217 18.985565 26.419338 19.837091 19.946192 36.43445 12.278508 16.330965 20.701359 14.345301 21.741161 25.050423 31.046402 27.738455 9.959419 20.93039 20.069063 14.518344 33.20235 24.735163 18.7274 9.148898 15.781284 18.556862 18.692865 26.045074 27.954073 28.106823 15.272034 40.879818 29.33896 23.714525 26.427515 16.483374 22.518442 22.425386 33.94826 18.831465 13.2501955 15.537227 34.639984 27.468002 13.474407 48.134598 34.39617 22.8503124.042334 17.747198 14.7837715 18.187277 23.655672 22.364983 13.858193 22.710032 14.371148 7.1272087 35.960033 28.247292 25.3014 14.477208 25.306196 17.891165 20.193708 23.585173 34.690193 12.200583 20.102983 38.45882 14.741723 14.408362 17.67158 18.418497 21.151712 21.157492 22.693687 29.809034 19.366991 20.072294 25.880817 40.814568 34.64087 19.43741 36.2591 50.73806 26.968863 43.91787 32.54908 20.248306 ] [ 7.2 18.8 19. 27. 22.2 24.5 31.2 22.9 20.5 23.2 18.6 14.5 17.8 50. 20.8 24.3 24.2 19.8 19.1 22.7 12. 10.2 20. 18.5 20.9 23. 27.5 30.1 9.5 22. 21.2 14.1 33.1 23.4 20.1 7.4 15.4 23.8 20.1 24.5 33. 28.4 14.1 46.7 32.5 29.6 28.4 19.8 20.2 25. 35.4 20.3 9.7 14.5 34.9 26.6 7.2 50. 32.4 21.6 29.8 13.1 27.5 21.2 23.1 21.9 13. 23.2 8.1 5.6 21.7 29.6 19.6 7. 26.4 18.9 20.9 28.1 35.4 10.2 24.3 43.1 17.6 15.4 16.2 27.1 21.4 21.5 22.4 25. 16.6 18.6 22. 42.8 35.1 21.5 36. 21.9 24.1 50. 26.7 25. ]
两个数组的输出大约有10-30%的差异,这表明我们的模型预测在合理的范围内。
Keras - 使用 LSTM 循环神经网络 (RNN) 进行时间序列预测
在本章中,让我们编写一个简单的基于长短期记忆 (LSTM) 的 RNN 来进行序列分析。序列是一组值,其中每个值对应于特定时间实例。让我们考虑一个阅读句子的简单示例。阅读和理解句子涉及按给定顺序阅读单词,并尝试理解每个单词及其在给定上下文中的含义,最后以积极或消极的情绪理解句子。
在这里,单词被视为值,第一个值对应于第一个单词,第二个值对应于第二个单词,依此类推,并且顺序将严格保持。序列分析经常用于自然语言处理中,以查找给定文本的情绪分析。
让我们创建一个LSTM模型来分析IMDB电影评论并找出其积极/消极情绪。
序列分析的模型可以表示如下:
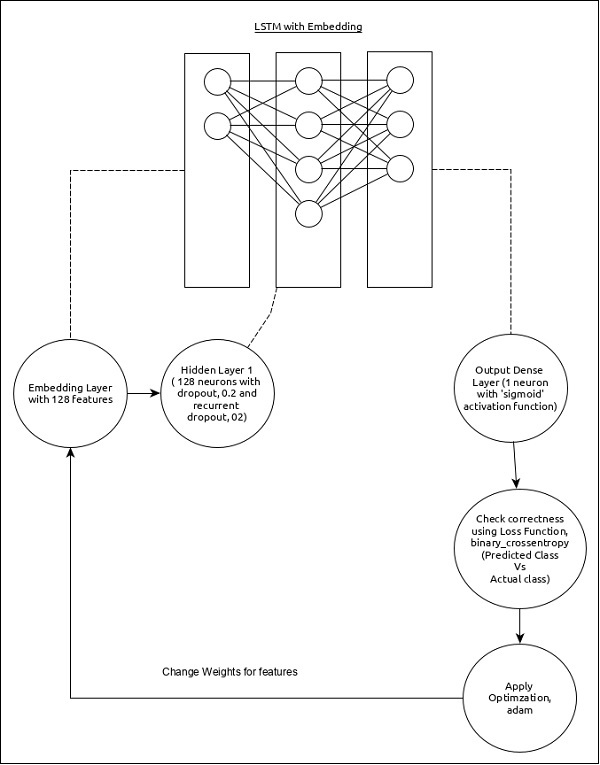
模型的核心特征如下:
使用具有128个特征的嵌入层作为输入层。
第一层,Dense包含128个单元,正常dropout和循环dropout设置为0.2。
输出层,Dense包含1个单元和‘sigmoid’激活函数。
使用binary_crossentropy作为损失函数。
使用adam作为优化器。
使用**accuracy**作为评估指标。
使用32作为批量大小。
使用15个epochs。
使用80作为单词的最大长度。
使用2000作为给定句子中单词的最大数量。
步骤1:导入模块
让我们导入必要的模块。
from keras.preprocessing import sequence from keras.models import Sequential from keras.layers import Dense, Embedding from keras.layers import LSTM from keras.datasets import imdb
步骤2:加载数据
让我们导入imdb数据集。
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words = 2000)
这里:
imdb是Keras提供的数据集。它代表电影及其评论的集合。
num_words代表评论中单词的最大数量。
步骤3:处理数据
让我们根据我们的模型更改数据集,以便可以将其馈送到我们的模型中。可以使用以下代码更改数据:
x_train = sequence.pad_sequences(x_train, maxlen=80) x_test = sequence.pad_sequences(x_test, maxlen=80)
这里:
sequence.pad_sequences将形状为(data)的输入数据列表转换为形状为(data, timesteps)的二维NumPy数组。基本上,它将timesteps概念添加到给定数据中。它生成长度为maxlen的timesteps。
步骤4:创建模型
让我们创建实际的模型。
model = Sequential() model.add(Embedding(2000, 128)) model.add(LSTM(128, dropout = 0.2, recurrent_dropout = 0.2)) model.add(Dense(1, activation = 'sigmoid'))
这里:
我们使用了Embedding层作为输入层,然后添加了LSTM层。最后,使用Dense层作为输出层。
步骤5:编译模型
让我们使用选择的损失函数、优化器和评估指标来编译模型。
model.compile(loss = 'binary_crossentropy', optimizer = 'adam', metrics = ['accuracy'])
步骤6:训练模型
让我们使用fit()方法训练模型。
model.fit( x_train, y_train, batch_size = 32, epochs = 15, validation_data = (x_test, y_test) )
执行应用程序将输出以下信息:
Epoch 1/15 2019-09-24 01:19:01.151247: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not co mpiled to use: AVX2 25000/25000 [==============================] - 101s 4ms/step - loss: 0.4707 - acc: 0.7716 - val_loss: 0.3769 - val_acc: 0.8349 Epoch 2/15 25000/25000 [==============================] - 95s 4ms/step - loss: 0.3058 - acc: 0.8756 - val_loss: 0.3763 - val_acc: 0.8350 Epoch 3/15 25000/25000 [==============================] - 91s 4ms/step - loss: 0.2100 - acc: 0.9178 - val_loss: 0.5065 - val_acc: 0.8110 Epoch 4/15 25000/25000 [==============================] - 90s 4ms/step - loss: 0.1394 - acc: 0.9495 - val_loss: 0.6046 - val_acc: 0.8146 Epoch 5/15 25000/25000 [==============================] - 90s 4ms/step - loss: 0.0973 - acc: 0.9652 - val_loss: 0.5969 - val_acc: 0.8147 Epoch 6/15 25000/25000 [==============================] - 98s 4ms/step - loss: 0.0759 - acc: 0.9730 - val_loss: 0.6368 - val_acc: 0.8208 Epoch 7/15 25000/25000 [==============================] - 95s 4ms/step - loss: 0.0578 - acc: 0.9811 - val_loss: 0.6657 - val_acc: 0.8184 Epoch 8/15 25000/25000 [==============================] - 97s 4ms/step - loss: 0.0448 - acc: 0.9850 - val_loss: 0.7452 - val_acc: 0.8136 Epoch 9/15 25000/25000 [==============================] - 95s 4ms/step - loss: 0.0324 - acc: 0.9894 - val_loss: 0.7616 - val_acc: 0.8162Epoch 10/15 25000/25000 [==============================] - 100s 4ms/step - loss: 0.0247 - acc: 0.9922 - val_loss: 0.9654 - val_acc: 0.8148 Epoch 11/15 25000/25000 [==============================] - 99s 4ms/step - loss: 0.0169 - acc: 0.9946 - val_loss: 1.0013 - val_acc: 0.8104 Epoch 12/15 25000/25000 [==============================] - 90s 4ms/step - loss: 0.0154 - acc: 0.9948 - val_loss: 1.0316 - val_acc: 0.8100 Epoch 13/15 25000/25000 [==============================] - 89s 4ms/step - loss: 0.0113 - acc: 0.9963 - val_loss: 1.1138 - val_acc: 0.8108 Epoch 14/15 25000/25000 [==============================] - 89s 4ms/step - loss: 0.0106 - acc: 0.9971 - val_loss: 1.0538 - val_acc: 0.8102 Epoch 15/15 25000/25000 [==============================] - 89s 4ms/step - loss: 0.0090 - acc: 0.9972 - val_loss: 1.1453 - val_acc: 0.8129 25000/25000 [==============================] - 10s 390us/step
步骤7 - 评估模型
让我们使用测试数据评估模型。
score, acc = model.evaluate(x_test, y_test, batch_size = 32)
print('Test score:', score)
print('Test accuracy:', acc)
执行以上代码将输出以下信息:
Test score: 1.145306069601178 Test accuracy: 0.81292
Keras - 应用
Keras应用程序模块用于为深度神经网络提供预训练模型。Keras模型用于预测、特征提取和微调。本章详细解释了Keras应用程序。
预训练模型
训练模型包含两部分:模型架构和模型权重。模型权重是大型文件,因此我们必须从ImageNet数据库下载并提取特征。一些流行的预训练模型列在下面:
- ResNet
- VGG16
- MobileNet
- InceptionResNetV2
- InceptionV3
加载模型
Keras预训练模型可以很容易地加载,如下所示:
import keras import numpy as np from keras.applications import vgg16, inception_v3, resnet50, mobilenet #Load the VGG model vgg_model = vgg16.VGG16(weights = 'imagenet') #Load the Inception_V3 model inception_model = inception_v3.InceptionV3(weights = 'imagenet') #Load the ResNet50 model resnet_model = resnet50.ResNet50(weights = 'imagenet') #Load the MobileNet model mobilenet_model = mobilenet.MobileNet(weights = 'imagenet')
加载模型后,我们可以立即将其用于预测目的。让我们在接下来的章节中检查每个预训练模型。
使用ResNet模型进行实时预测
ResNet是一个预训练模型。它使用ImageNet进行训练。ResNet模型权重在ImageNet上预训练。它具有以下语法:
keras.applications.resnet.ResNet50 ( include_top = True, weights = 'imagenet', input_tensor = None, input_shape = None, pooling = None, classes = 1000 )
这里:
include_top指的是网络顶部的全连接层。
weights指的是在ImageNet上进行预训练。
input_tensor指的是可选的Keras张量,用作模型的图像输入。
input_shape指的是可选的形状元组。此模型的默认输入大小为224x224。
classes指的是可选的用于对图像进行分类的类别数。
让我们通过编写一个简单的示例来了解模型:
步骤1:导入模块
让我们加载必要的模块,如下所示:
>>> import PIL >>> from keras.preprocessing.image import load_img >>> from keras.preprocessing.image import img_to_array >>> from keras.applications.imagenet_utils import decode_predictions >>> import matplotlib.pyplot as plt >>> import numpy as np >>> from keras.applications.resnet50 import ResNet50 >>> from keras.applications import resnet50
步骤2:选择输入
让我们选择一个输入图像,Lotus,如下所示:
>>> filename = 'banana.jpg'
>>> ## load an image in PIL format
>>> original = load_img(filename, target_size = (224, 224))
>>> print('PIL image size',original.size)
PIL image size (224, 224)
>>> plt.imshow(original)
<matplotlib.image.AxesImage object at 0x1304756d8>
>>> plt.show()
在这里,我们加载了一个图像(banana.jpg)并显示它。
步骤3:将图像转换为NumPy数组
让我们将我们的输入Banana转换为NumPy数组,以便可以将其传递给模型以进行预测。
>>> #convert the PIL image to a numpy array
>>> numpy_image = img_to_array(original)
>>> plt.imshow(np.uint8(numpy_image))
<matplotlib.image.AxesImage object at 0x130475ac8>
>>> print('numpy array size',numpy_image.shape)
numpy array size (224, 224, 3)
>>> # Convert the image / images into batch format
>>> image_batch = np.expand_dims(numpy_image, axis = 0)
>>> print('image batch size', image_batch.shape)
image batch size (1, 224, 224, 3)
>>>
步骤4:模型预测
让我们将我们的输入馈送到模型以获取预测
>>> prepare the image for the resnet50 model >>> >>> processed_image = resnet50.preprocess_input(image_batch.copy()) >>> # create resnet model >>>resnet_model = resnet50.ResNet50(weights = 'imagenet') >>> Downloavding data from https://github.com/fchollet/deep-learning-models/releas es/download/v0.2/resnet50_weights_tf_dim_ordering_tf_kernels.h5 102858752/102853048 [==============================] - 33s 0us/step >>> # get the predicted probabilities for each class >>> predictions = resnet_model.predict(processed_image) >>> # convert the probabilities to class labels >>> label = decode_predictions(predictions) Downloading data from https://storage.googleapis.com/download.tensorflow.org/ data/imagenet_class_index.json 40960/35363 [==================================] - 0s 0us/step >>> print(label)
输出
[
[
('n07753592', 'banana', 0.99229723),
('n03532672', 'hook', 0.0014551596),
('n03970156', 'plunger', 0.0010738898),
('n07753113', 'fig', 0.0009359837) ,
('n03109150', 'corkscrew', 0.00028538404)
]
]
在这里,模型正确地将图像预测为香蕉。
Keras - 预训练模型
在本章中,我们将学习Keras中的预训练模型。让我们从VGG16开始。
VGG16
VGG16是另一个预训练模型。它也使用ImageNet进行训练。加载模型的语法如下:
keras.applications.vgg16.VGG16( include_top = True, weights = 'imagenet', input_tensor = None, input_shape = None, pooling = None, classes = 1000 )
此模型的默认输入大小为224x224。
MobileNetV2
MobileNetV2是另一个预训练模型。它也使用ImageNet进行训练。
加载模型的语法如下:
keras.applications.mobilenet_v2.MobileNetV2 ( input_shape = None, alpha = 1.0, include_top = True, weights = 'imagenet', input_tensor = None, pooling = None, classes = 1000 )
这里:
alpha控制网络的宽度。如果值小于1,则减少每一层中的过滤器数量。如果值大于1,则增加每一层中的过滤器数量。如果alpha = 1,则每一层都使用论文中的默认过滤器数量。
此模型的默认输入大小为224x224。
InceptionResNetV2
InceptionResNetV2是另一个预训练模型。它也使用ImageNet进行训练。加载模型的语法如下:
keras.applications.inception_resnet_v2.InceptionResNetV2 ( include_top = True, weights = 'imagenet', input_tensor = None, input_shape = None, pooling = None, classes = 1000)
此模型可以使用“channels_first”数据格式(通道、高度、宽度)或“channels_last”数据格式(高度、宽度、通道)构建。
此模型的默认输入大小为299x299。
InceptionV3
InceptionV3是另一个预训练模型。它也使用ImageNet进行训练。加载模型的语法如下:
keras.applications.inception_v3.InceptionV3 ( include_top = True, weights = 'imagenet', input_tensor = None, input_shape = None, pooling = None, classes = 1000 )
这里:
此模型的默认输入大小为299x299。
结论
Keras是一个非常简单、可扩展且易于实现的神经网络API,可用于构建具有高级抽象的深度学习应用程序。Keras是深度学习模型的最佳选择。