KNIME - 构建你自己的模型
在本章中,你将构建你自己的机器学习模型,根据一些观察到的特征对植物进行分类。我们将为此目的使用来自UCI 机器学习库的著名iris数据集。该数据集包含三种不同的植物类别。我们将训练我们的模型将未知植物分类到这三个类别中的一个。
我们将从在 KNIME 中创建一个新的工作流开始,用于创建我们的机器学习模型。
创建工作流
要创建一个新的工作流,请在 KNIME 工作台中选择以下菜单选项。
File → New
你将看到以下屏幕:
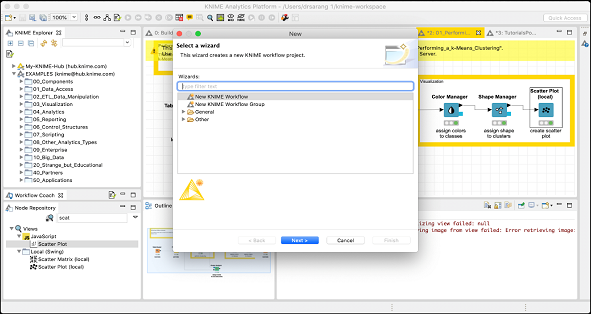
选择新建 KNIME 工作流选项,然后单击下一步按钮。在下一个屏幕上,系统将询问你工作流的所需名称以及保存它的目标文件夹。根据需要输入此信息,然后单击完成以创建一个新的工作区。
一个具有给定名称的新工作区将添加到工作区视图中,如下所示:
你现在将在此工作区中添加各种节点以创建你的模型。在添加节点之前,你必须下载并准备iris数据集以供我们使用。
准备数据集
从 UCI 机器学习库网站下载 iris 数据集 下载 Iris 数据集。下载的 iris.data 文件为 CSV 格式。我们将对其进行一些更改以添加列名。
在您喜欢的文本编辑器中打开下载的文件,并在开头添加以下行:
sepal length, petal length, sepal width, petal width, class
当我们的文件读取器节点读取此文件时,它将自动将上述字段作为列名。
现在,你将开始添加各种节点。
添加文件读取器
转到节点资源库视图,在搜索框中输入“file”以查找文件读取器节点。这在下面的屏幕截图中可以看到:
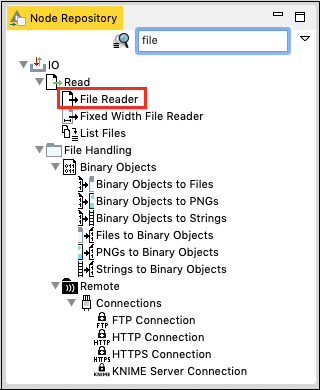
选择并双击文件读取器将节点添加到工作区。或者,你可以使用拖放功能将节点添加到工作区。添加节点后,你必须对其进行配置。右键单击节点并选择配置菜单选项。你已经在上一课中完成了此操作。
加载数据文件后,设置屏幕如下所示。
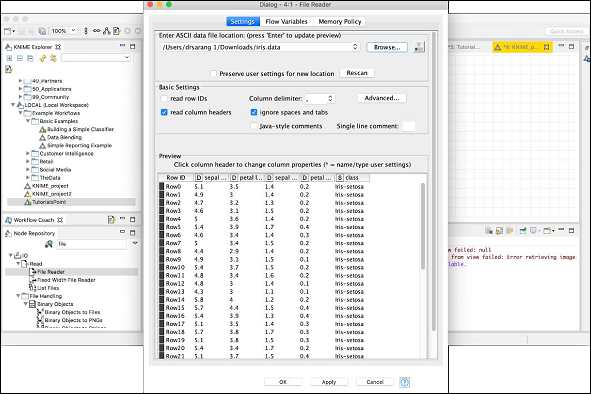
要加载你的数据集,请单击浏览按钮并选择 iris.data 文件的位置。该节点将加载文件的内容,这些内容显示在配置框的下部。一旦你确认数据文件已正确定位并加载,请单击确定按钮关闭配置对话框。
你现在将为此节点添加一些注释。右键单击节点并选择新建工作流注释菜单选项。屏幕上将出现一个注释框,如下面的屏幕截图所示
单击框内并添加以下注释:
Reads iris.data
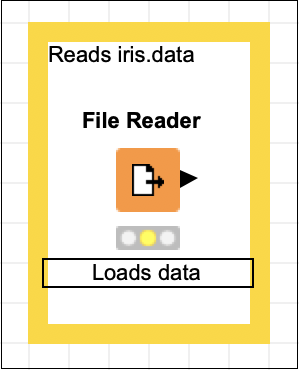
单击框外的任何位置以退出编辑模式。根据需要调整框的大小并将其放置在节点周围。最后,双击节点下方的节点 1文本,将其更改为:
Loads data
此时,你的屏幕将如下所示:
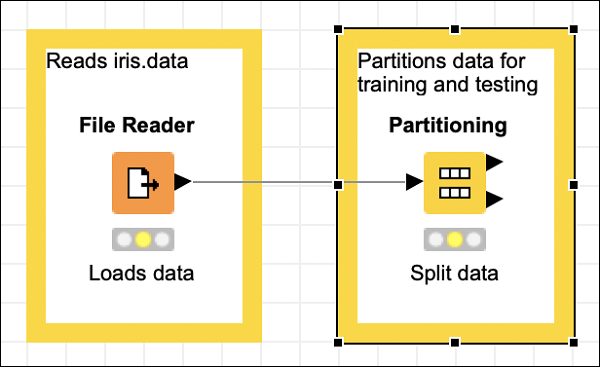
我们现在将添加一个新的节点,用于将我们加载的数据集划分为训练集和测试集。
添加分区节点
在节点资源库搜索窗口中,输入几个字符以找到分区节点,如下面的屏幕截图所示:
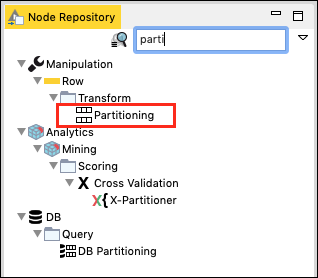
将节点添加到我们的工作区。设置其配置如下:
Relative (%) : 95 Draw Randomly
以下屏幕截图显示了配置参数。
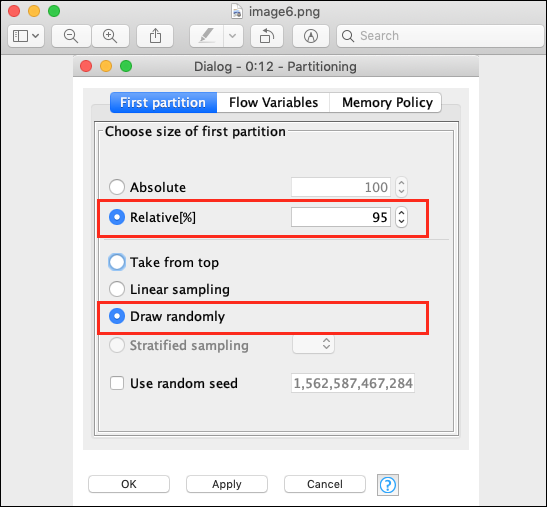
接下来,在两个节点之间建立连接。为此,请单击文件读取器节点的输出,按住鼠标按钮,会出现一个橡皮筋线,将其拖动到分区节点的输入,然后释放鼠标按钮。现在在两个节点之间建立了连接。
添加注释,更改描述,根据需要放置节点和注释视图。在此阶段,你的屏幕应如下所示:
接下来,我们将添加k-Means节点。
添加 k-Means 节点
从资源库中选择k-Means节点并将其添加到工作区。如果你想复习 k-Means 算法的知识,只需在工作台的描述视图中查找其描述。这在下面的屏幕截图中显示:

顺便说一句,你可以在做出最终决定使用哪个算法之前,在描述窗口中查找不同算法的描述。
打开节点的配置对话框。我们将使用此处显示的所有字段的默认值:
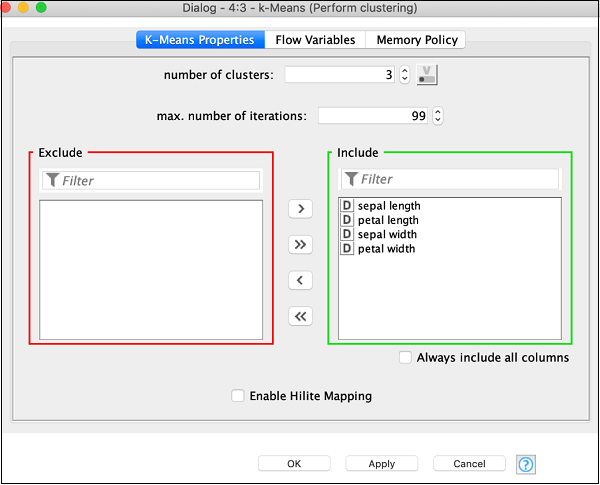
单击确定以接受默认值并关闭对话框。
将注释和描述设置为以下内容:
注释:分类集群
描述:执行聚类
将分区节点的顶部输出连接到k-Means节点的输入。重新定位你的项目,你的屏幕应如下所示:
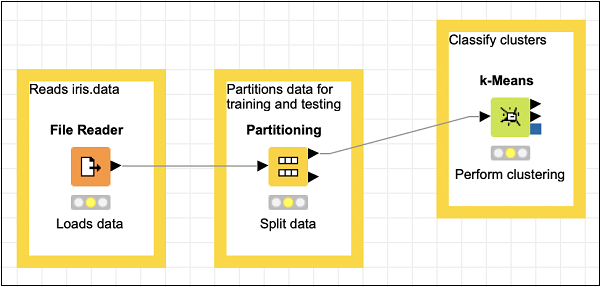
接下来,我们将添加一个聚类分配器节点。
添加聚类分配器
聚类分配器将新数据分配给一组现有的原型。它有两个输入——原型模型和包含输入数据的datatable。在下面的屏幕截图中描述了节点的描述:
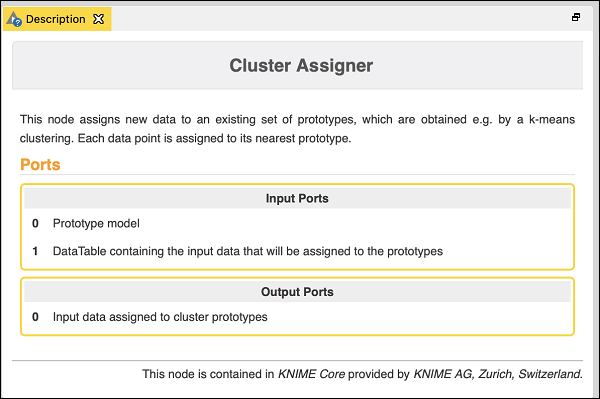
因此,对于此节点,你必须进行两个连接:
分区节点的 PMML 聚类模型输出→聚类分配器的原型输入
分区节点的第二个分区输出→聚类分配器的输入数据
这两个连接在下面的屏幕截图中显示:
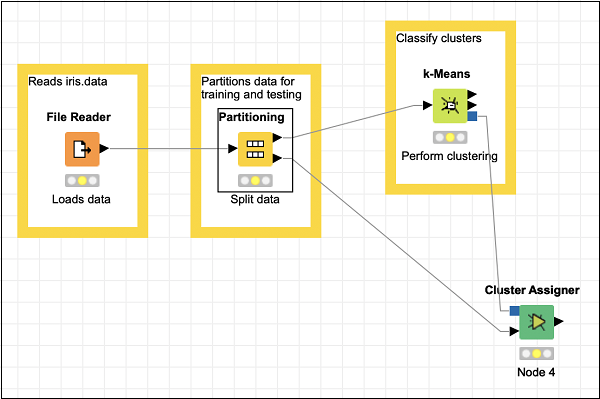
聚类分配器不需要任何特殊配置。只需接受默认值即可。
现在,为此节点添加一些注释和描述。重新排列你的节点。你的屏幕应如下所示:
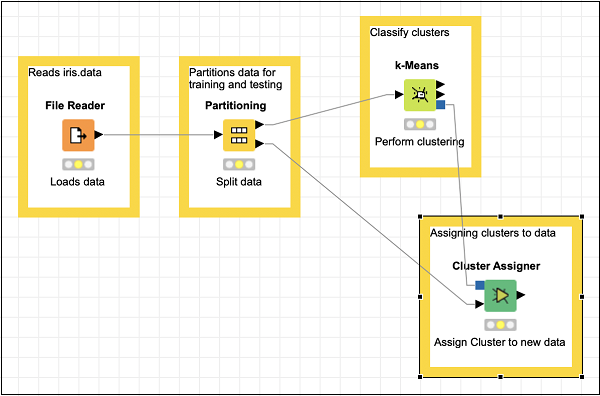
此时,我们的聚类已完成。我们需要以图形方式可视化输出。为此,我们将添加一个散点图。我们将在散点图中为三个类别设置不同的颜色和形状。因此,我们将首先通过颜色管理器节点,然后通过形状管理器节点过滤k-Means节点的输出。
添加颜色管理器
在资源库中找到颜色管理器节点。将其添加到工作区。将配置保留为默认值。请注意,你必须打开配置对话框并点击确定以接受默认值。设置节点的描述文本。
从k-Means的输出到颜色管理器的输入建立连接。在此阶段,你的屏幕将如下所示:
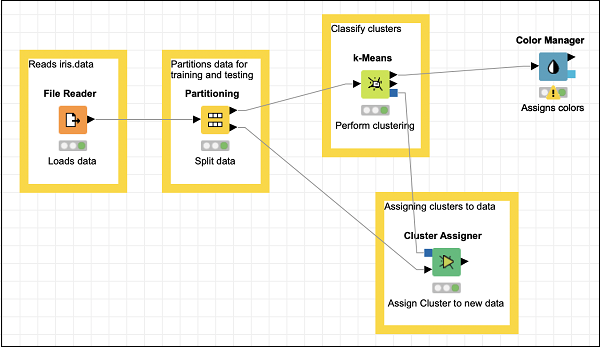
添加形状管理器
在资源库中找到形状管理器并将其添加到工作区。将配置保留为默认值。与前一个一样,你必须打开配置对话框并点击确定以设置默认值。从颜色管理器的输出到形状管理器的输入建立连接。设置节点的描述。
你的屏幕应如下所示:
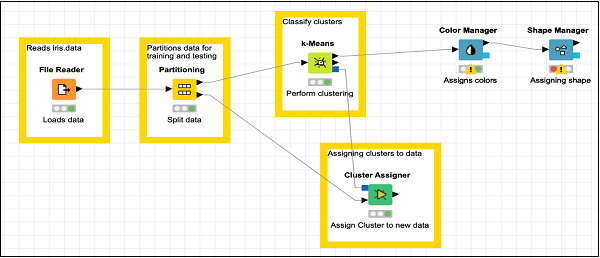
现在,你将在我们的模型中添加最后一个节点,那就是散点图。
添加散点图
在资源库中找到散点图节点并将其添加到工作区。将形状管理器的输出连接到散点图的输入。将配置保留为默认值。设置描述。
最后,为最近添加的三个节点添加一个组注释
注释:可视化
根据需要重新定位节点。在此阶段,你的屏幕应如下所示。
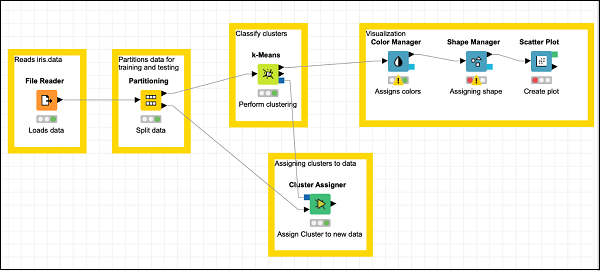
这完成了模型构建的任务。