KNIME - 探索工作流
如果您查看工作流中的节点,您会发现它包含以下内容:
文件读取器,
颜色管理器
分区
决策树学习器
决策树预测器
评分
交互式表格
散点图
统计
这些在大纲视图中很容易看到,如下所示:
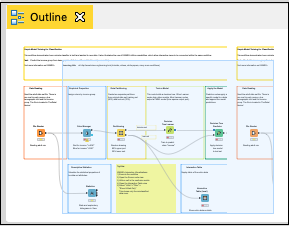
每个节点在工作流中提供特定的功能。我们现在将探讨如何配置这些节点以满足所需的功能。请注意,我们只讨论与我们当前探索工作流的上下文相关的节点。
文件读取器
文件读取器节点在下面的屏幕截图中显示:

窗口顶部有一些由工作流创建者提供的描述。它说明此节点读取成人数据集。从节点符号下方的描述中可以看出,文件名为adult.csv。文件读取器有两个输出 - 一个连接到颜色管理器节点,另一个连接到统计节点。
如果您右键单击文件管理器,将显示如下弹出菜单:
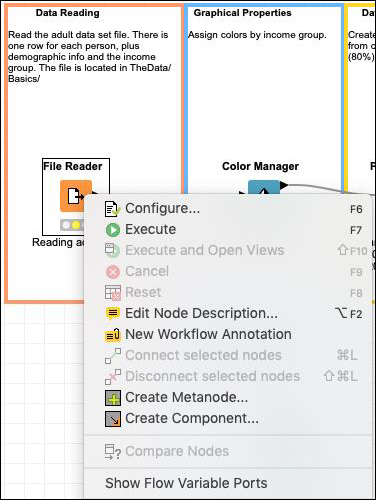
配置菜单选项允许节点配置。执行菜单运行节点。请注意,如果节点已经运行并且处于绿色状态,则此菜单将被禁用。此外,请注意编辑注释描述菜单选项的存在。这允许您为您的节点编写描述。
现在,选择配置菜单选项,它将显示包含来自 adult.csv 文件的数据的屏幕,如此处屏幕截图所示:
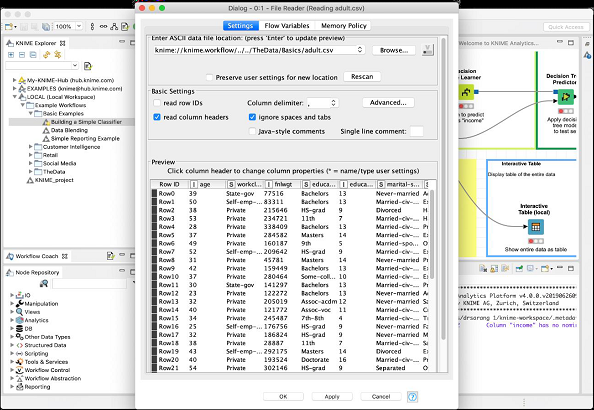
当您执行此节点时,数据将加载到内存中。整个数据加载程序代码对用户隐藏。您现在可以理解此类节点的有用性 - 无需编码。
我们的下一个节点是颜色管理器。
颜色管理器
选择颜色管理器节点,然后右键单击它进入其配置。将出现颜色设置对话框。从下拉列表中选择收入列。
您的屏幕将如下所示:
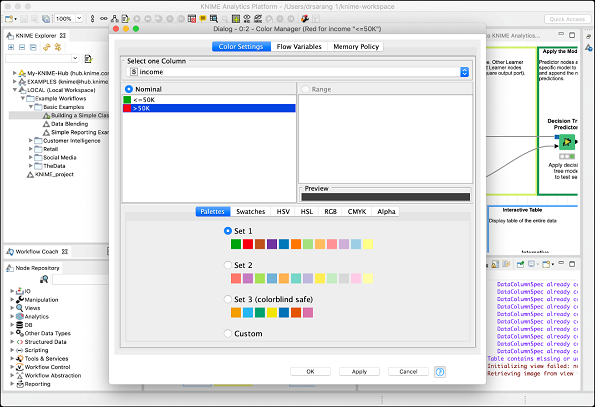
注意两个约束的存在。如果收入低于 50K,则数据点将获得绿色;如果高于 50K,则获得红色。当我们稍后在本章中查看散点图时,您将看到数据点映射。
分区
在机器学习中,我们通常将所有可用数据分成两部分。较大部分用于训练模型,而较小部分用于测试。有不同的策略用于对数据进行分区。
要定义所需的分区,请右键单击分区节点并选择配置选项。您将看到以下屏幕:
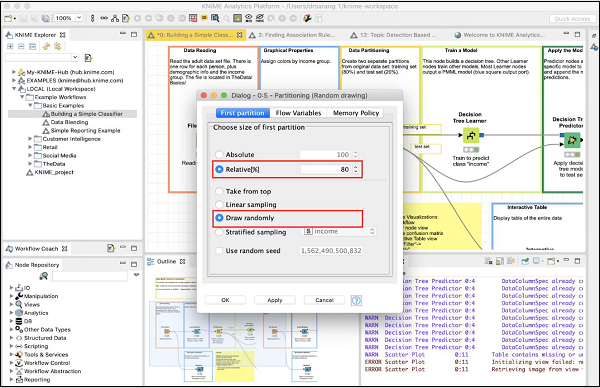
在本例中,系统建模者使用了相对(%)模式,数据以 80:20 的比例分割。在进行拆分时,数据点是随机选择的。这确保您的测试数据可能不会有偏差。在进行线性采样时,用于测试的剩余 20% 数据可能无法正确地表示训练数据,因为它在收集过程中可能完全有偏差。
如果您确定在数据收集过程中保证了随机性,那么您可以选择线性采样。一旦您的数据准备好用于训练模型,请将其馈送到下一个节点,即决策树学习器。
决策树学习器
顾名思义,决策树学习器节点使用训练数据并构建模型。查看此节点的配置设置,如下面的屏幕截图所示:
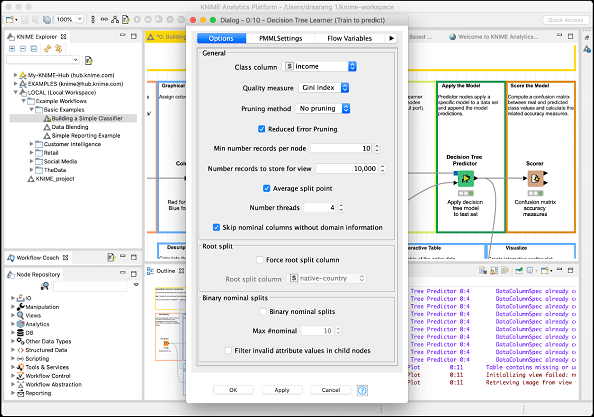
如您所见,类别为收入。因此,树将基于收入列构建,这就是我们试图在此模型中实现的目标。我们希望将收入高于或低于 50K 的人分开。
此节点成功运行后,您的模型将准备好进行测试。
决策树预测器
决策树预测器节点将开发的模型应用于测试数据集并附加模型预测。
预测器的输出馈送到两个不同的节点 - 评分器和散点图。接下来,我们将检查预测的输出。
评分器
此节点生成混淆矩阵。要查看它,请右键单击节点。您将看到以下弹出菜单:
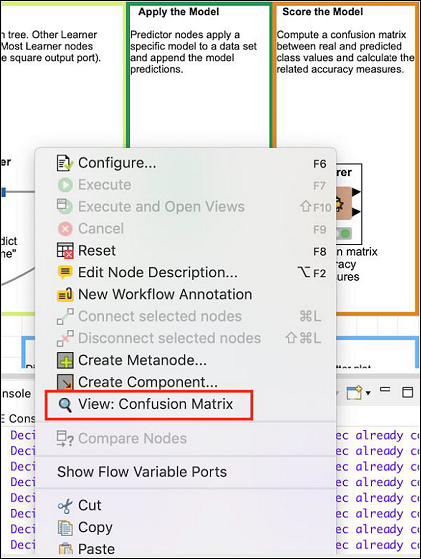
单击查看:混淆矩阵菜单选项,矩阵将在单独的窗口中弹出,如此处屏幕截图所示:
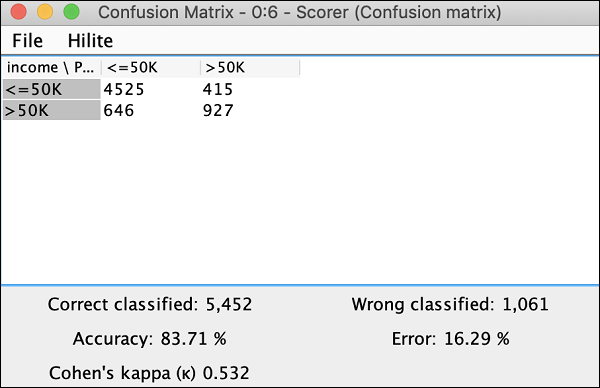
这表明我们开发的模型的准确率为 83.71%。如果您对此不满意,您可以尝试更改模型构建中的其他参数,特别是,您可能希望重新审视和清理您的数据。
散点图
要查看数据分布的散点图,请右键单击散点图节点并选择菜单选项交互式视图:散点图。您将看到以下图表:
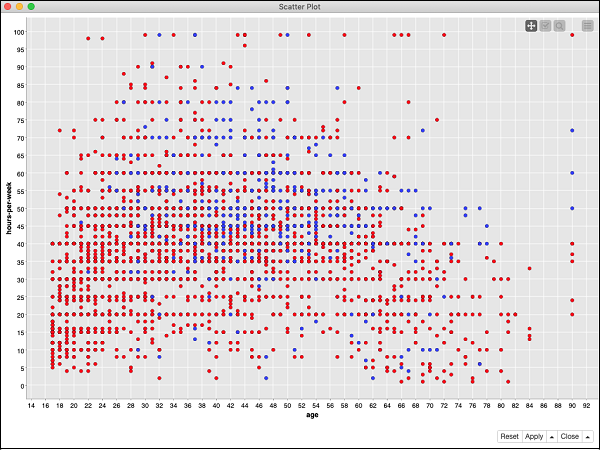
该图根据 50K 的阈值,以两种不同颜色的点(红色和蓝色)显示不同收入群体人员的分布。这些是在我们的颜色管理器节点中设置的颜色。分布相对于绘制在 x 轴上的年龄。您可以通过更改节点的配置来为 x 轴选择不同的特征。
此处显示配置对话框,我们已选择婚姻状况作为 x 轴的特征。
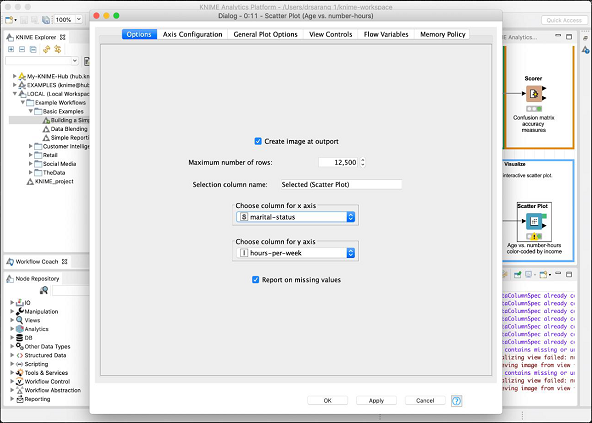
这完成了我们对 KNIME 提供的预定义模型的讨论。我们建议您自行学习模型中的其他两个节点(统计和交互式表格)。
现在让我们继续本教程最重要的部分——创建您自己的模型。