- MapReduce 教程
- MapReduce - 首页
- MapReduce - 简介
- MapReduce - 算法
- MapReduce - 安装
- MapReduce - API
- MapReduce - Hadoop 实现
- MapReduce - 分区器
- MapReduce - 合并器
- MapReduce - Hadoop 管理
- MapReduce 资源
- MapReduce - 快速指南
- MapReduce - 有用资源
- MapReduce - 讨论
MapReduce - 算法
MapReduce 算法包含两个重要的任务,即 Map 和 Reduce。
- map 任务通过 Mapper 类完成
- reduce 任务通过 Reducer 类完成。
Mapper 类接收输入,对其进行标记化、映射和排序。Mapper 类的输出被用作 Reducer 类的输入,后者依次搜索匹配的键值对并对其进行归约。
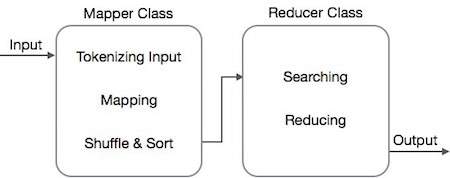
MapReduce 使用各种数学算法将任务分解成小部分并将其分配给多个系统。从技术角度讲,MapReduce 算法有助于将 Map 和 Reduce 任务发送到集群中相应的服务器。
这些数学算法可能包括以下内容 -
- 排序
- 搜索
- 索引
- TF-IDF
排序
排序是处理和分析数据的基本 MapReduce 算法之一。MapReduce 实现排序算法以根据其键自动对来自映射器的输出键值对进行排序。
排序方法在映射器类本身中实现。
在 Shuffle 和 Sort 阶段,在对映射器类中的值进行标记化后,Context 类(用户定义类)将匹配的值键作为集合收集。
为了收集类似的键值对(中间键),Mapper 类借助 RawComparator 类对键值对进行排序。
给定 Reducer 的中间键值对集合由 Hadoop 自动排序,以形成键值(K2,{V2,V2,…}),然后将其呈现给 Reducer。
搜索
搜索在 MapReduce 算法中起着重要作用。它有助于合并器阶段(可选)和 Reducer 阶段。让我们尝试通过一个例子来了解搜索是如何工作的。
示例
以下示例显示了 MapReduce 如何使用搜索算法查找给定员工数据集里薪资最高的员工的详细信息。
假设我们在四个不同的文件中拥有员工数据 - A、B、C 和 D。还假设由于从所有数据库表重复导入员工数据,因此所有四个文件中都存在重复的员工记录。请参阅以下插图。
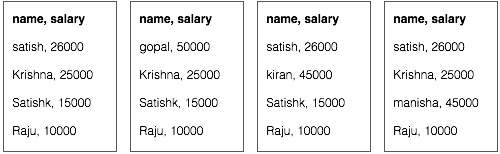
Map 阶段处理每个输入文件,并以键值对(<k, v> : <员工姓名, 薪资>)的形式提供员工数据。请参阅以下插图。

合并器阶段(搜索技术)将接收来自 Map 阶段的输入,作为带有员工姓名和薪资的键值对。使用搜索技术,合并器将检查所有员工的薪资,以查找每个文件中薪资最高的员工。请参阅以下代码片段。
<k: employee name, v: salary>
Max= the salary of an first employee. Treated as max salary
if(v(second employee).salary > Max){
Max = v(salary);
}
else{
Continue checking;
}
预期结果如下 -
|
Reducer 阶段 - 从每个文件中,您将找到薪资最高的员工。为了避免冗余,请检查所有 <k, v> 对并消除任何重复项。在来自四个输入文件的四个 <k, v> 对之间使用相同的算法。最终输出应如下 -
<gopal, 50000>
索引
通常使用索引来指向特定数据及其地址。它对特定映射器的输入文件执行批量索引。
MapReduce 中通常使用的索引技术称为倒排索引。像 Google 和 Bing 这样的搜索引擎使用倒排索引技术。让我们尝试通过一个简单的例子来了解索引是如何工作的。
示例
以下文本是倒排索引的输入。这里 T[0]、T[1] 和 t[2] 是文件名,它们的内容用双引号括起来。
T[0] = "it is what it is" T[1] = "what is it" T[2] = "it is a banana"
应用索引算法后,我们得到以下输出 -
"a": {2}
"banana": {2}
"is": {0, 1, 2}
"it": {0, 1, 2}
"what": {0, 1}
这里 "a": {2} 表示术语 "a" 出现在 T[2] 文件中。类似地,"is": {0, 1, 2} 表示术语 "is" 出现在 T[0]、T[1] 和 T[2] 文件中。
TF-IDF
TF-IDF 是一种文本处理算法,它是术语频率 - 逆文档频率的缩写。它是常见的 Web 分析算法之一。这里,“频率”一词是指某个术语在一个文档中出现的次数。
词频 (TF)
它衡量特定术语在一个文档中出现的频率。它是通过一个单词在一个文档中出现的次数除以该文档中的总单词数来计算的。
TF(the) = (Number of times term the ‘the’ appears in a document) / (Total number of terms in the document)
逆文档频率 (IDF)
它衡量术语的重要性。它是通过文本数据库中的文档总数除以特定术语出现的文档数来计算的。
在计算 TF 时,所有术语都被认为同等重要。这意味着,TF 计算像“is”、“a”、“what”等普通词的词频。因此,我们需要在按比例放大稀有词的同时了解常用词,方法是计算以下内容 -
IDF(the) = log_e(Total number of documents / Number of documents with term ‘the’ in it).
以下将通过一个小型示例来解释该算法。
示例
考虑一个包含 1000 个单词的文档,其中单词 hive 出现了 50 次。那么 hive 的 TF 为 (50 / 1000) = 0.05。
现在,假设我们有 1000 万个文档,并且单词 hive 出现在其中的 1000 个文档中。然后,IDF 计算为 log(10,000,000 / 1,000) = 4。
TF-IDF 权重是这些量的乘积 - 0.05 × 4 = 0.20。