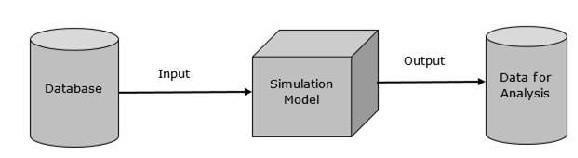
建模与仿真 - 数据库
建模与仿真中数据库的目标是提供数据表示及其关系,以用于分析和测试目的。第一个数据模型由 Edgar Codd 于 1980 年提出。以下是该模型的主要特征。
数据库是不同数据对象的集合,定义了信息及其关系。
规则用于定义对象中数据的约束。
操作可以应用于对象以检索信息。
最初,数据建模基于实体与关系的概念,其中实体是数据信息类型,关系表示实体之间的关联。
最新的数据建模概念是面向对象的设计,其中实体表示为类,在计算机编程中用作模板。一个类具有其名称、属性、约束以及与其他类对象的关系。
其基本表示如下所示:
数据表示
事件的数据表示
仿真事件具有其属性,例如事件名称及其关联的时间信息。它表示使用与输入文件参数关联的一组输入数据执行提供的仿真,并将其结果作为一组输出数据提供,存储在与数据文件关联的多个文件中。
输入文件的数据表示
每个仿真过程都需要一组不同的输入数据及其关联的参数值,这些值在输入数据文件中表示。输入文件与处理仿真的软件相关联。数据模型通过与数据文件的关联来表示引用的文件。
输出文件的数据表示
仿真过程完成后,它会生成各种输出文件,每个输出文件都表示为一个数据文件。每个文件都有其名称、描述和通用因子。数据文件分为两类。第一个文件包含数值,第二个文件包含数值文件内容的描述信息。
建模与仿真中的神经网络
神经网络是人工智能的一个分支。神经网络是由许多称为单元的处理器组成的网络,每个单元都有其小的本地存储器。每个单元都通过称为连接的单向通信通道连接,这些通道携带数值数据。每个单元仅在其本地数据和从连接接收的输入上工作。
历史
仿真的历史视角按时间顺序排列如下。
第一个神经模型由 McCulloch & Pitts 于 **1940** 年开发。
在 **1949** 年,唐纳德·赫布写了一本书“行为的组织”,指出了神经元的概念。
在 **1950** 年,随着计算机的进步,根据这些理论建立模型成为可能。这是由 IBM 研究实验室完成的。然而,这项工作失败了,后来的尝试取得了成功。
在 **1959** 年,Bernard Widrow 和 Marcian Hoff 开发了名为 ADALINE 和 MADALINE 的模型。这些模型具有多个自适应线性元素。MADALINE 是第一个应用于现实世界问题的**神经网络**。
在 **1962** 年,Rosenblatt 开发了感知器模型,该模型能够解决简单的模式分类问题。
在 **1969** 年,Minsky & Papert 提供了感知器模型在计算方面局限性的数学证明。据说感知器模型无法解决异或问题。这些缺点导致神经网络暂时衰落。
在 **1982** 年,加州理工学院的 John Hopfield 向美国国家科学院提交了他的论文,提出使用双向线路创建机器。以前使用的是单向线路。
当涉及符号方法的传统人工智能技术失败时,就出现了使用神经网络的必要性。神经网络具有其大规模并行技术,这提供了解决此类问题所需的计算能力。
应用领域
神经网络可用于语音合成机、模式识别、检测诊断问题、机器人控制板和医疗设备中。
建模与仿真中的模糊集
如前所述,连续仿真的每个过程都依赖于微分方程及其参数,例如 a、b、c、d > 0。通常,计算点估计并在模型中使用。但是,有时这些估计是不确定的,因此我们需要在微分方程中使用模糊数,这提供了未知参数的估计。
什么是模糊集?
在经典集合中,一个元素要么是集合的成员,要么不是。模糊集根据经典集合 **X** 定义为:
A = {(x,μA(x))| x ∈ X}
**情况 1** - 函数 **μA(x)** 具有以下属性:
∀x ∈ X μA(x) ≥ 0
sup x ∈ X {μA(x)} = 1
**情况 2** - 令模糊集 **B** 定义为 **A = {(3, 0.3), (4, 0.7), (5, 1), (6, 0.4)}**,则其标准模糊表示法写为 **A = {0.3/3, 0.7/4, 1/5, 0.4/6}**
任何隶属度为零的值都不会出现在集合的表达式中。
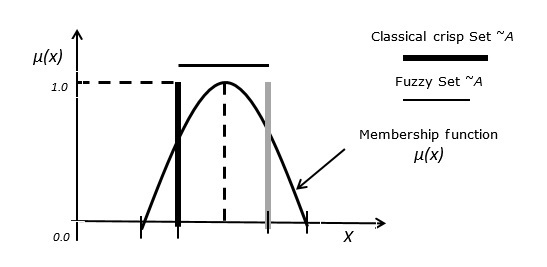
**情况 3** - 模糊集与经典清晰集之间的关系。
下图描述了模糊集与经典清晰集之间的关系。