建模与仿真 - 快速指南
建模与仿真 - 引言
建模是表示模型的过程,包括模型的构建和运作。该模型类似于真实系统,帮助分析师预测系统变化的影响。换句话说,建模就是创建代表系统及其属性的模型。这是一个构建模型的行为。
仿真是对系统在时间或空间上的操作,有助于分析现有或拟议系统的性能。换句话说,仿真就是使用模型来研究系统性能的过程。这是一个使用模型进行仿真的行为。
仿真的历史
仿真的历史视角按时间顺序排列如下。
1940年 - 一种名为“蒙特卡洛”的方法由参与曼哈顿计划的研究人员(约翰·冯·诺依曼、斯坦尼斯瓦夫·乌兰、爱德华·泰勒、赫尔曼·卡恩)和物理学家开发,用于研究中子散射。
1960年 - 开发了第一批专用仿真语言,例如兰德公司Harry Markowitz开发的SIMSCRIPT。
1970年 - 在此期间,开始了对仿真数学基础的研究。
1980年 - 在此期间,开发了基于PC的仿真软件、图形用户界面和面向对象的编程。
1990年 - 在此期间,开发了基于Web的仿真、精美动画图形、基于仿真的优化、马尔可夫链蒙特卡洛方法。
开发仿真模型
仿真模型由以下组件组成:系统实体、输入变量、性能指标和功能关系。以下是开发仿真模型的步骤。
步骤1 - 识别现有系统的问题或提出系统需求。
步骤2 - 在考虑现有系统因素和限制的情况下设计问题。
步骤3 - 收集并开始处理系统数据,观察其性能和结果。
步骤4 - 使用网络图开发模型,并使用各种验证技术对其进行验证。
步骤5 - 通过比较其在各种条件下的性能与真实系统来验证模型。
步骤6 - 为将来使用创建模型文档,其中包括详细的目标、假设、输入变量和性能。
步骤7 - 根据要求选择合适的实验设计。
步骤8 - 对模型施加实验条件并观察结果。
进行仿真分析
以下是进行仿真分析的步骤。
步骤1 - 准备问题陈述。
步骤2 - 选择输入变量并为仿真过程创建实体。变量有两种类型:决策变量和不可控变量。决策变量由程序员控制,而不可控变量是随机变量。
步骤3 - 通过将决策变量分配给仿真过程来创建约束。
步骤4 - 确定输出变量。
步骤5 - 从真实系统收集数据输入到仿真中。
步骤6 - 创建一个流程图,显示仿真过程的进度。
步骤7 - 选择合适的仿真软件来运行模型。
步骤8 - 通过将其结果与实时系统进行比较来验证仿真模型。
步骤9 - 通过更改变量值对模型进行实验以找到最佳解决方案。
步骤10 - 最后,将这些结果应用到实时系统中。
建模与仿真 ─ 优点
以下是使用建模与仿真的优点:
易于理解 - 允许理解系统如何真正运行,而无需在实时系统上工作。
易于测试 - 允许对系统进行更改以及对其输出的影响,而无需在实时系统上工作。
易于升级 - 允许通过应用不同的配置来确定系统需求。
易于识别约束 - 允许执行瓶颈分析,找出导致工作流程、信息等延迟的原因。
易于诊断问题 - 某些系统非常复杂,难以同时理解其相互作用。但是,建模与仿真允许理解所有相互作用并分析其影响。此外,可以探索新的策略、操作和程序,而不会影响真实系统。
建模与仿真 ─ 缺点
以下是使用建模与仿真的缺点:
设计模型是一门艺术,需要领域知识、培训和经验。
使用随机数对系统进行操作,因此难以预测结果。
仿真需要人力,是一个耗时的过程。
仿真结果难以翻译,需要专家理解。
仿真过程成本高昂。
建模与仿真 ─ 应用领域
建模与仿真可以应用于以下领域:军事应用、培训与支持、半导体设计、电信、土木工程设计与演示以及电子商务模型。
此外,它还用于研究复杂系统的内部结构,例如生物系统。它用于优化系统设计,例如路由算法、装配线等。它用于测试新设计和策略。它用于验证分析解决方案。
概念与分类
本章将讨论建模的各种概念和分类。
模型与事件
以下是建模与仿真的基本概念。
对象是真实世界中存在的实体,用于研究模型的行为。
基础模型是对对象属性及其行为的假设性解释,在整个模型中有效。
系统是在特定条件下清晰表达的对象,存在于现实世界中。
实验框架用于在现实世界中研究系统,例如实验条件、方面、目标等。基本实验框架由两组变量组成:框架输入变量和框架输出变量,它们与系统或模型端子匹配。框架输入变量负责匹配应用于系统或模型的输入。框架输出变量负责将输出值与系统或模型匹配。
集总模型是对遵循给定实验框架指定条件的系统的精确解释。
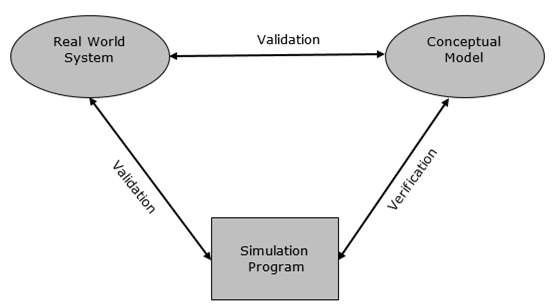
验证是比较两个或多个项目以确保其准确性的过程。在建模与仿真中,可以通过比较仿真程序和集总模型的一致性来确保其性能。有各种方法可以执行验证过程,我们将在单独的章节中介绍。
确认是比较两个结果的过程。在建模与仿真中,确认是通过在实验框架的上下文中比较实验测量值与仿真结果来执行的。如果结果不匹配,则模型无效。有各种方法可以执行确认过程,我们将在单独的章节中介绍。
系统状态变量
系统状态变量是一组数据,需要在给定时间点定义系统内的内部过程。
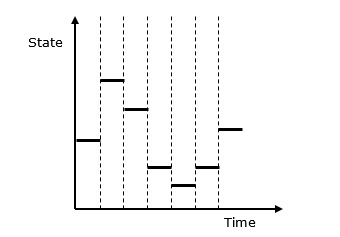
在离散事件模型中,系统状态变量在一段时间内保持不变,其值在称为事件时间的定义点发生变化。
在连续事件模型中,系统状态变量由微分方程结果定义,其值随时间连续变化。
以下是一些系统状态变量:
实体与属性 - 实体表示一个对象,其值可以是静态的或动态的,这取决于与其他实体的过程。属性是实体使用的局部值。
资源 - 资源是一个实体,一次可以为一个或多个动态实体提供服务。动态实体可以请求一个或多个资源单元;如果接受,则实体可以使用资源并在完成时释放。如果被拒绝,实体可以加入队列。
列表 - 列表用于表示实体和资源使用的队列。根据过程的不同,队列有各种可能性,例如LIFO、FIFO等。
延迟 - 这是由某些系统条件组合引起的无限期持续时间。
模型分类
系统可以分为以下几类。
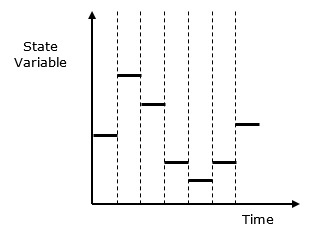
离散事件仿真模型 - 在此模型中,状态变量值仅在事件发生的一些离散时间点发生变化。事件只会在定义的活动时间和延迟时发生。
随机系统与确定性系统 - 随机系统不受随机性影响,其输出不是随机变量,而确定性系统受随机性影响,其输出是随机变量。
静态仿真与动态仿真 - 静态仿真包括不受时间影响的模型。例如:蒙特卡洛模型。动态仿真包括受时间影响的模型。
离散系统与连续系统 - 离散系统受状态变量在离散时间点发生变化的影响。其行为在下面的图形表示中描述。
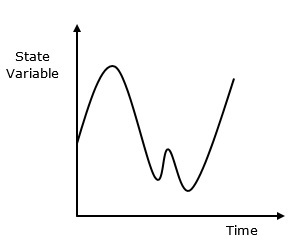
连续系统受状态变量的影响,状态变量作为时间的函数而连续变化。其行为在下面的图形表示中描述。
建模过程
建模过程包括以下步骤。
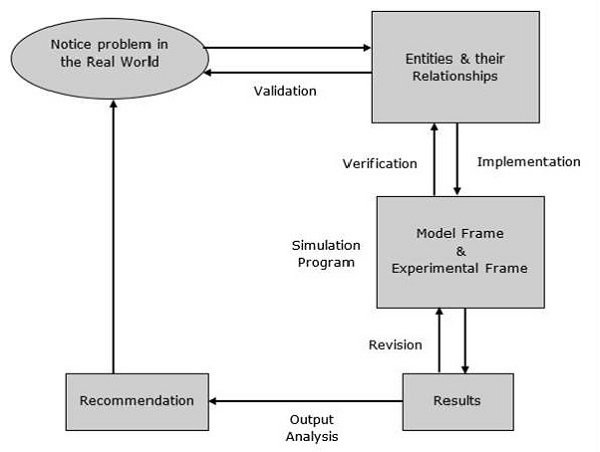
步骤1 - 检查问题。在此阶段,我们必须理解问题并相应地选择其分类,例如确定性或随机性。
步骤2 - 设计模型。在此阶段,我们必须执行以下简单的任务,这些任务有助于我们设计模型:
根据系统行为和未来需求收集数据。
分析系统特性、其假设以及为使模型成功而需要采取的必要措施。
确定模型中使用的变量名称、函数、单位、关系及其应用。
使用合适的技术求解模型,并使用验证方法验证结果。接下来,验证结果。
准备一份报告,其中包括结果、解释、结论和建议。
步骤3 - 完成与模型相关的整个过程后,提供建议。包括投资、资源、算法、技术等。
验证与确认
仿真分析人员面临的实际问题之一是验证模型。只有当模型是实际系统的准确表示时,仿真模型才有效,否则无效。
验证和确认是任何仿真项目中验证模型的两个步骤。
确认是比较两个结果的过程。在这个过程中,我们需要将概念模型的表示与真实系统进行比较。如果比较结果为真,则有效,否则无效。
验证是比较两个或多个结果以确保其准确性的过程。在这个过程中,我们必须将模型的实现及其相关数据与开发人员的概念描述和规范进行比较。
验证与确认技术
模拟模型的验证与确认有多种技术。以下是几种常用的技术:
模拟模型验证技术
以下是执行模拟模型验证的方法:
利用编程技能编写和调试子程序中的程序。
使用“结构化走查”策略,其中有多个人阅读程序。
跟踪中间结果并将其与观察到的结果进行比较。
使用各种输入组合检查模拟模型输出。
将最终模拟结果与分析结果进行比较。
模拟模型确认技术
步骤1 - 设计一个具有高有效性的模型。这可以通过以下步骤实现:
- 设计过程中必须与系统专家讨论模型。
- 模型必须在整个过程中与客户互动。
- 输出必须由系统专家监督。
步骤2 - 测试模型的假设数据。这可以通过将假设数据应用到模型中并进行定量测试来实现。还可以进行敏感性分析,以观察当输入数据发生重大变化时结果变化的影响。
步骤3 - 确定模拟模型的代表性输出。这可以通过以下步骤实现:
确定模拟输出与实际系统输出的接近程度。
可以使用图灵测试进行比较。它以系统格式呈现数据,只有专家才能解释。
可以使用统计方法将模型输出与实际系统输出进行比较。
模型数据与实际数据的比较
模型开发完成后,我们必须将其输出数据与实际系统数据进行比较。以下是执行此比较的两种方法。
验证现有系统
在这种方法中,我们使用模型的真实世界输入,将其输出与真实系统的真实世界输入进行比较。这个验证过程很简单,但是,在执行时可能会遇到一些困难,例如,如果输出要与平均长度、等待时间、空闲时间等进行比较,可以使用统计检验和假设检验进行比较。一些统计检验包括卡方检验、Kolmogorov-Smirnov检验、Cramer-von Mises检验和矩检验。
验证首次建模
假设我们必须描述一个目前不存在也从未存在过的拟议系统。因此,没有可用于与其性能进行比较的历史数据。因此,我们必须使用基于假设的假设系统。以下有用的提示将有助于提高效率。
子系统有效性 - 模型本身可能没有任何现有的系统可以与其进行比较,但它可能包含已知的子系统。每个有效性都可以单独测试。
内部有效性 - 具有高度内部方差的模型将被拒绝,因为由于其内部过程而具有高度方差的随机系统将隐藏由于输入变化而导致的输出变化。
敏感性分析 - 它提供有关系统中敏感参数的信息,我们需要对此给予更多关注。
表面有效性 - 当模型在相反的逻辑上运行时,即使它的行为像真实系统一样,也应该被拒绝。
离散系统仿真
在离散系统中,系统状态的变化是不连续的,系统状态的每一次变化都称为一个事件。离散系统模拟中使用的模型有一组数字来表示系统状态,称为状态描述符。在本章中,我们还将学习排队模拟,这是离散事件模拟以及时间共享系统模拟的一个非常重要的方面。
以下是离散系统模拟行为的图形表示。(此处应插入图形)
离散事件模拟——关键特征
离散事件模拟通常由用高级编程语言(如Pascal、C++或任何专门的模拟语言)设计的软件执行。以下是五个关键特征:
实体 - 这些是真实元素(例如机器部件)的表示。
关系 - 意思是将实体连接在一起。
模拟执行器 - 它负责控制时间推进和执行离散事件。
随机数生成器 - 它有助于模拟进入模拟模型的不同数据。
结果与统计 - 它验证模型并提供其性能指标。
时间图表示
每个系统都依赖于时间参数。在图形表示中,它被称为时钟时间或时间计数器,最初设置为零。时间根据以下两个因素更新:
时间切片 - 这是模型为每个事件定义的时间,直到没有事件出现。
下一个事件 - 这是模型为下一个要执行的事件定义的事件,而不是时间间隔。它比时间切片更有效。
排队系统的模拟
队列是系统中所有正在服务的实体以及那些等待轮到的实体的组合。
参数
以下是排队系统中使用的参数列表。
| 符号 | 描述 |
|---|---|
| λ | 表示到达率,即每秒到达的数量 |
| Ts | 表示每次到达的平均服务时间,不包括在队列中的等待时间 |
| σTs | 表示服务时间的标准差 |
| ρ | 表示服务器时间利用率,包括空闲和繁忙时 |
| u | 表示流量强度 |
| r | 表示系统中项目的平均数量 |
| R | 表示系统中项目的总数 |
| Tr | 表示系统中项目的平均时间 |
| TR | 表示系统中项目的总时间 |
| σr | 表示r的标准差 |
| σTr | 表示Tr的标准差 |
| w | 表示队列中等待项目的平均数量 |
| σw | 表示w的标准差 |
| Tw | 表示所有项目的平均等待时间 |
| Td | 表示队列中等待项目的平均等待时间 |
| N | 表示系统中的服务器数量 |
| mx(y) | 表示第y个百分位数,这意味着x值小于y百分比时间的y值 |
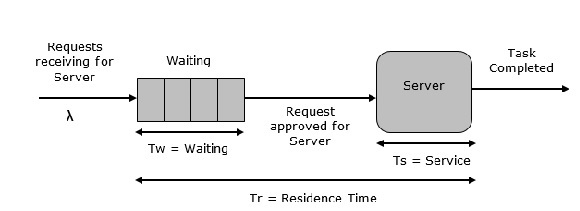
单服务器队列
这是最简单的排队系统,如下图所示。系统的核心元素是一个服务器,它为连接的设备或项目提供服务。项目请求系统进行服务,如果服务器空闲,则立即服务,否则加入等待队列。服务器完成任务后,项目离开。
多服务器队列
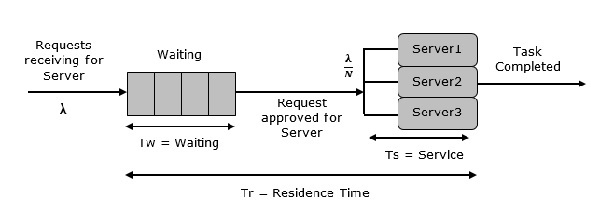
顾名思义,该系统由多个服务器和所有项目的公共队列组成。当任何项目请求服务器时,如果至少有一个服务器可用,则会分配给它。否则,队列开始启动,直到服务器空闲。在这个系统中,我们假设所有服务器都是相同的,即选择的服务器与哪个项目无关。
利用率有一个例外。令N为相同的服务器,则ρ为每个服务器的利用率。考虑Nρ为整个系统的利用率;则最大利用率为N*100%,最大输入率为:
$λmax = \frac{\text{N}}{\text{T}s}$
排队关系
下表显示了一些基本的排队关系。
| 一般术语 | 单服务器 | 多服务器 |
|---|---|---|
| r = λTr Little公式 | ρ = λTs | ρ = λTs/N |
| w = λTw Little公式 | r = w + ρ | u = λTs = ρN |
| Tr = Tw + Ts | r = w + Nρ |
时间共享系统的模拟
时间共享系统的设计方式是,每个用户使用在系统上共享的一小部分时间,这导致多个用户同时共享系统。每个用户的切换速度如此之快,以至于每个用户都感觉像是在使用自己的系统一样。它基于CPU调度和多编程的概念,在该概念中,可以通过在系统上同时执行多个作业来有效地利用多个资源。
示例 - SimOS模拟系统。
它由斯坦福大学设计,用于研究复杂的计算机硬件设计,分析应用程序性能以及研究操作系统。SimOS包含现代计算机系统所有硬件组件的软件模拟,即处理器、内存管理单元(MMU)、缓存等。
建模与模拟 - 连续
连续系统是指系统的重要活动平稳完成而没有任何延迟的系统,即没有事件队列,没有时间模拟排序等。当连续系统用数学建模时,表示属性的变量由连续函数控制。
什么是连续模拟?
连续模拟是一种模拟类型,其中状态变量相对于时间连续变化。以下是其行为的图形表示。(此处应插入图形)
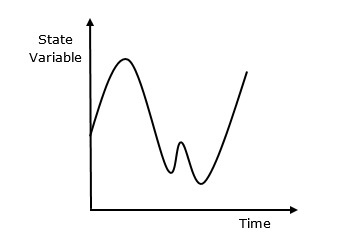
为什么要使用连续模拟?
我们必须使用连续模拟,因为它取决于与系统相关的各种参数的微分方程及其已知的估计结果。
应用领域
连续模拟用于以下行业:土木工程中的水坝堤坝和隧道建设;军事应用中的导弹弹道模拟、战斗机飞行训练模拟以及水下航行器智能控制器的设计与测试。
物流中的收费站设计、机场航站楼的旅客流量分析以及主动航班时刻表评估;业务发展中的产品开发规划、员工管理规划和市场研究分析。
蒙特卡洛仿真
蒙特卡罗模拟是一种计算机数学技术,用于基于某些已知分布生成随机样本数据以进行数值实验。此方法应用于风险定量分析和决策问题。此方法由各种领域的专业人士使用,例如金融、项目管理、能源、制造、工程、研发、保险、石油和天然气、运输等。
这种方法最早由1940年参与原子弹研发的科学家使用。在需要进行估计和不确定性决策的情况下,例如天气预报,可以使用此方法。
蒙特卡洛模拟——重要特性
以下是蒙特卡洛方法的三个重要特性:
- 其输出必须生成随机样本。
- 其输入分布必须已知。
- 进行实验时,其结果必须已知。
蒙特卡洛模拟——优点
- 易于实现。
- 利用计算机为数值实验提供统计抽样。
- 为数学问题提供近似解。
- 可用于随机问题和确定性问题。
蒙特卡洛模拟——缺点
耗时,因为需要生成大量的样本才能获得期望的输出。
此方法的结果只是真实值的近似值,而非精确值。
蒙特卡洛模拟方法——流程图
下图显示了蒙特卡洛模拟的通用流程图。(此处应插入流程图)
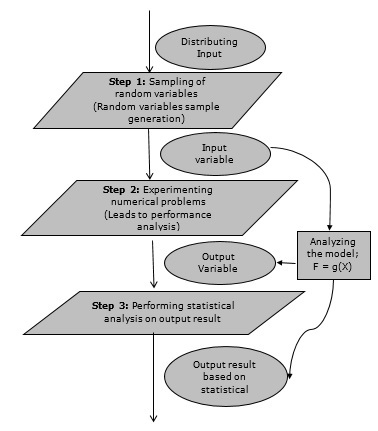
建模与仿真 - 数据库
建模与仿真中数据库的目标是提供数据表示及其关系,用于分析和测试目的。第一个数据模型由Edgar Codd于1980年提出。该模型的主要特点如下。
数据库是定义信息及其关系的不同数据对象的集合。
规则用于定义对象中数据的约束。
可以对对象应用操作以检索信息。
最初,数据建模基于实体与关系的概念,其中实体是数据信息的类型,关系表示实体之间的关联。
最新的数据建模概念是面向对象设计,其中实体表示为类,在计算机编程中用作模板。一个类具有其名称、属性、约束以及与其他类的对象的关系。
其基本表示如下:
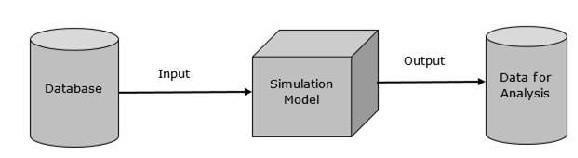
数据表示
事件的数据表示
仿真事件具有其属性,例如事件名称及其关联的时间信息。它表示使用与输入文件参数相关的一组输入数据执行提供的仿真,并将其结果作为一组输出数据提供,存储在与数据文件关联的多个文件中。
输入文件的数据表示
每个仿真过程都需要一组不同的输入数据及其关联的参数值,这些值在输入数据文件中表示。输入文件与处理仿真的软件相关联。数据模型通过与数据文件的关联来表示引用的文件。
输出文件的数据表示
仿真过程完成后,它会生成各种输出文件,每个输出文件都表示为一个数据文件。每个文件都有其名称、描述和一个通用因子。数据文件分为两个文件。第一个文件包含数值,第二个文件包含数值文件内容的描述信息。
建模与仿真中的神经网络
神经网络是人工智能的一个分支。神经网络是由许多称为单元的处理器组成的网络,每个单元都有其小的局部存储器。每个单元都通过称为连接的单向通信通道连接,这些通道携带数值数据。每个单元只处理其局部数据和从连接接收到的输入。
历史
仿真的历史视角按时间顺序排列如下。
第一个神经模型是由1940年McCulloch & Pitts开发的。
1949年,Donald Hebb撰写了一本名为“行为的组织”的书,指出了神经元的概念。
1950年,随着计算机技术的进步,根据这些理论建立模型成为可能。这是由IBM研究实验室完成的。然而,这项努力失败了,后来的尝试才成功。
1959年,Bernard Widrow和Marcian Hoff开发了名为ADALINE和MADALINE的模型。这些模型具有多个自适应线性元件。MADALINE是第一个应用于实际问题的神经网络。
1962年,Rosenblatt开发了感知器模型,该模型能够解决简单的模式分类问题。
1969年,Minsky & Papert提供了感知器模型在计算方面的局限性的数学证明。据说感知器模型无法解决异或问题。这些缺点导致神经网络暂时衰落。
1982年,加州理工学院的John Hopfield向美国国家科学院提交了他的论文,提出利用双向线路创建机器。之前使用的是单向线路。
当涉及符号方法的传统人工智能技术失败时,就产生了使用神经网络的需要。神经网络具有其大规模并行技术,这提供了解决此类问题所需的计算能力。
应用领域
神经网络可用于语音合成机、模式识别、检测诊断问题、机器人控制板和医疗设备。
建模与仿真中的模糊集
如前所述,连续仿真的每个过程都依赖于微分方程及其参数,例如a、b、c、d > 0。通常,计算点估计并将其用于模型。然而,有时这些估计是不确定的,因此我们需要在微分方程中使用模糊数,这可以提供未知参数的估计。
什么是模糊集?
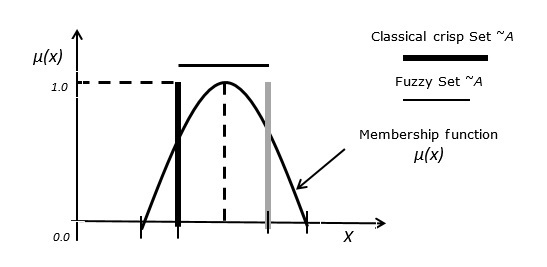
在经典集合中,一个元素要么是集合的成员,要么不是。模糊集是用经典集合X来定义的:
A = {(x,μA(x))| x ∈ X}
情况1 - 函数μA(x)具有以下属性:
∀x ∈ X μA(x) ≥ 0
sup x ∈ X {μA(x)} = 1
情况2 - 令模糊集B定义为A = {(3, 0.3), (4, 0.7), (5, 1), (6, 0.4)},则其标准模糊表示法写为A = {0.3/3, 0.7/4, 1/5, 0.4/6}
任何隶属度为零的值都不会出现在集合的表达式中。
情况3 - 模糊集与经典清晰集之间的关系。
下图描述了模糊集和经典清晰集之间的关系。(此处应插入图表)