- Python 数据持久化教程
- Python 数据持久化 - 首页
- Python 数据持久化 - 简介
- Python 数据持久化 - 文件 API
- 使用 os 模块进行文件处理
- Python 数据持久化 - 对象序列化
- Python 数据持久化 - Pickle 模块
- Python 数据持久化 - Marshal 模块
- Python 数据持久化 - Shelve 模块
- Python 数据持久化 - dbm 包
- Python 数据持久化 - CSV 模块
- Python 数据持久化 - JSON 模块
- Python 数据持久化 - XML 解析器
- Python 数据持久化 - Plistlib 模块
- Python 数据持久化 - Sqlite3 模块
- Python 数据持久化 - SQLAlchemy
- Python 数据持久化 - PyMongo 模块
- Python 数据持久化 - Cassandra 驱动程序
- 数据持久化 - ZODB
- 数据持久化 - Openpyxl 模块
- Python 数据持久化资源
- Python 数据持久化 - 快速指南
- Python 数据持久化 - 有用资源
- Python 数据持久化 - 讨论
Python 数据持久化 - Cassandra 驱动程序
Cassandra 是另一个流行的 NoSQL 数据库。高可扩展性、一致性和容错性——这些是 Cassandra 的一些重要特性。这是一个列存储数据库。数据存储在许多商品服务器上。因此,数据高度可用。
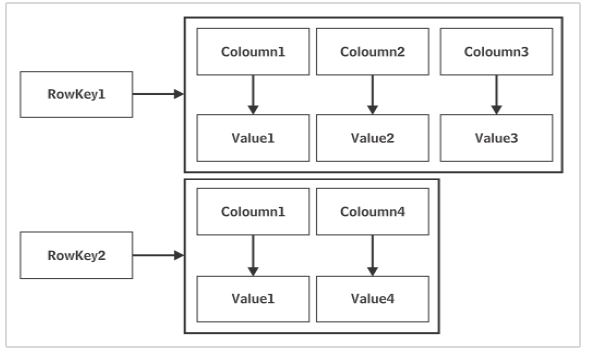
Cassandra 是 Apache 软件基金会的产品。数据以分布式方式存储在多个节点上。每个节点都是由键空间组成的单个服务器。Cassandra 数据库的基本构建块是键空间,可以将其视为类似于数据库。
Cassandra 一个节点中的数据会在节点的点对点网络中的其他节点上进行复制。这使得 Cassandra 成为一个万无一失的数据库。该网络称为数据中心。多个数据中心可以互连以形成集群。复制的性质是在创建键空间时通过设置复制策略和复制因子来配置的。
一个键空间可以拥有多个列族——就像一个数据库可以包含多个表一样。Cassandra 的键空间没有预定义的模式。Cassandra 表中的每一行可能包含名称不同且数量可变的列。
Cassandra 软件也有两个版本:社区版和企业版。Cassandra 的最新企业版可从https://cassandra.apache.org/download/下载。
Cassandra 有自己的查询语言,称为Cassandra 查询语言 (CQL)。CQL 查询可以从 CQLASH shell 内部执行——类似于 MySQL 或 SQLite shell。CQL 语法类似于标准 SQL。
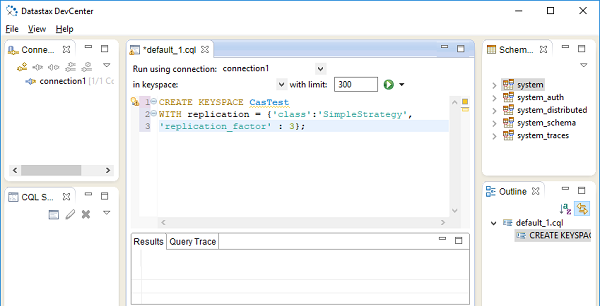
Datastax 社区版还带有一个 Develcenter IDE,如下图所示:
用于处理 Cassandra 数据库的 Python 模块称为Cassandra 驱动程序。它也是由 Apache 基金会开发的。此模块包含一个 ORM API,以及一个类似于关系数据库 DB-API 的核心 API。
可以使用pip 工具轻松安装 Cassandra 驱动程序。
pip3 install cassandra-driver
与 Cassandra 数据库的交互是通过 Cluster 对象进行的。Cassandra.cluster 模块定义了 Cluster 类。我们首先需要声明 Cluster 对象。
from cassandra.cluster import Cluster clstr=Cluster()
所有事务(例如插入/更新等)都是通过与键空间启动会话来执行的。
session=clstr.connect()
要创建一个新的键空间,请使用会话对象的execute()方法。execute() 方法采用一个字符串参数,该参数必须是一个查询字符串。CQL 具有如下所示的 CREATE KEYSPACE 语句。完整代码如下:
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect()
session.execute(“create keyspace mykeyspace with replication={
'class': 'SimpleStrategy', 'replication_factor' : 3
};”
这里,SimpleStrategy 是复制策略的值,复制因子设置为 3。如前所述,键空间包含一个或多个表。每个表都以其数据类型为特征。Python 数据类型会根据下表自动解析为相应的 CQL 数据类型:
| Python 类型 | CQL 类型 |
|---|---|
| None | NULL |
| Bool | Boolean |
| Float | float, double |
| int, long | int, bigint, varint, smallint, tinyint, counter |
| decimal.Decimal | Decimal |
| str, Unicode | ascii, varchar, text |
| buffer, bytearray | Blob |
| Date | Date |
| Datetime | Timestamp |
| Time | Time |
| list, tuple, generator | List |
| set, frozenset | Set |
| dict, OrderedDict | Map |
| uuid.UUID | timeuuid, uuid |
要创建表,请使用会话对象执行创建表的 CQL 查询。
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect('mykeyspace')
qry= '''
create table students (
studentID int,
name text,
age int,
marks int,
primary key(studentID)
);'''
session.execute(qry)
创建的键空间可进一步用于插入行。INSERT 查询的 CQL 版本类似于 SQL Insert 语句。以下代码在 students 表中插入一行。
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect('mykeyspace')
session.execute("insert into students (studentID, name, age, marks) values
(1, 'Juhi',20, 200);"
正如您所预期的那样,SELECT 语句也用于 Cassandra。对于包含 SELECT 查询字符串的 execute() 方法,它会返回一个结果集对象,可以使用循环遍历该对象。
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect('mykeyspace')
rows=session.execute("select * from students;")
for row in rows:
print (StudentID: {} Name:{} Age:{} price:{} Marks:{}'
.format(row[0],row[1], row[2], row[3]))
Cassandra 的 SELECT 查询支持使用 WHERE 子句对要获取的结果集应用过滤器。识别传统的逻辑运算符,如 <、> == 等。要仅从 students 表中检索年龄 > 20 的名称的行,execute() 方法中的查询字符串应如下所示:
rows=session.execute("select * from students WHERE age>20 allow filtering;")
请注意ALLOW FILTERING 的使用。此语句的 ALLOW FILTERING 部分允许显式允许(某些)需要过滤的查询。
Cassandra 驱动程序 API 在其 cassendra.query 模块中定义了以下 Statement 类型的类。
SimpleStatement
一个简单的、未准备好的 CQL 查询,包含在查询字符串中。以上所有示例都是 SimpleStatement 的示例。
BatchStatement
多个查询(例如 INSERT、UPDATE 和 DELETE)被放入批处理中并一次执行。每一行首先被转换为 SimpleStatement,然后添加到批处理中。
让我们将要添加到 Students 表中的行以元组列表的形式放入,如下所示:
studentlist=[(1,'Juhi',20,100), ('2,'dilip',20, 110),(3,'jeevan',24,145)]
要使用 BathStatement 添加上述行,请运行以下脚本:
from cassandra.query import SimpleStatement, BatchStatement
batch=BatchStatement()
for student in studentlist:
batch.add(SimpleStatement("INSERT INTO students
(studentID, name, age, marks) VALUES
(%s, %s, %s %s)"), (student[0], student[1],student[2], student[3]))
session.execute(batch)
PreparedStatement
Prepared statement 类似于 DB-API 中的参数化查询。它的查询字符串由 Cassandra 保存以供以后使用。Session.prepare() 方法返回一个 PreparedStatement 实例。
对于我们的 students 表,INSERT 查询的 PreparedStatement 如下所示:
stmt=session.prepare("INSERT INTO students (studentID, name, age, marks) VALUES (?,?,?)")
随后,它只需要发送要绑定的参数值即可。例如:
qry=stmt.bind([1,'Ram', 23,175])
最后,执行上面的绑定语句。
session.execute(qry)
这减少了网络流量和 CPU 利用率,因为 Cassandra 不必每次都重新解析查询。