- Python 数据持久化教程
- Python 数据持久化 - 首页
- Python 数据持久化 - 简介
- Python 数据持久化 - 文件 API
- 使用 os 模块进行文件处理
- Python 数据持久化 - 对象序列化
- Python 数据持久化 - Pickle 模块
- Python 数据持久化 - Marshal 模块
- Python 数据持久化 - Shelve 模块
- Python 数据持久化 - dbm 包
- Python 数据持久化 - CSV 模块
- Python 数据持久化 - JSON 模块
- Python 数据持久化 - XML 解析器
- Python 数据持久化 - Plistlib 模块
- Python 数据持久化 - Sqlite3 模块
- Python 数据持久化 - SQLAlchemy
- Python 数据持久化 - PyMongo 模块
- Python 数据持久化 - Cassandra 驱动程序
- 数据持久化 - ZODB
- 数据持久化 - Openpyxl 模块
- Python 数据持久化资源
- Python 数据持久化 - 快速指南
- Python 数据持久化 - 有用资源
- Python 数据持久化 - 讨论
Python 数据持久化 - SQLAlchemy
任何关系型数据库都将数据存储在表中。表结构定义属性的数据类型,这些属性基本上只有基本数据类型,它们映射到 Python 的相应内置数据类型。但是,Python 的用户定义对象无法持久地存储和检索到/从 SQL 表中。
这是 SQL 类型和面向对象编程语言(如 Python)之间的差异。SQL 没有等效于字典、元组、列表或任何用户定义类的其他数据类型。
如果您必须将对象存储在关系数据库中,则应先将其实例属性分解为 SQL 数据类型,然后再执行 INSERT 查询。另一方面,从 SQL 表检索到的数据是基本类型。将必须使用 Python 脚本中使用的所需类型的 Python 对象进行构造。这就是对象关系映射器有用的地方。
对象关系映射器 (ORM)
对象关系映射器 (ORM) 是类和 SQL 表之间的接口。Python 类映射到数据库中的某个表,以便自动执行对象和 SQL 类型之间的转换。
用 Python 代码编写的 Students 类映射到数据库中的 Students 表。因此,所有 CRUD 操作都是通过调用类的相应方法来完成的。这消除了在 Python 脚本中执行硬编码 SQL 查询的需要。
因此,ORM 库充当原始 SQL 查询之上的抽象层,可以帮助加快应用程序开发。SQLAlchemy 是一个流行的 Python 对象关系映射器。模型对象的任何状态操作都与其在数据库表中的相关行同步。
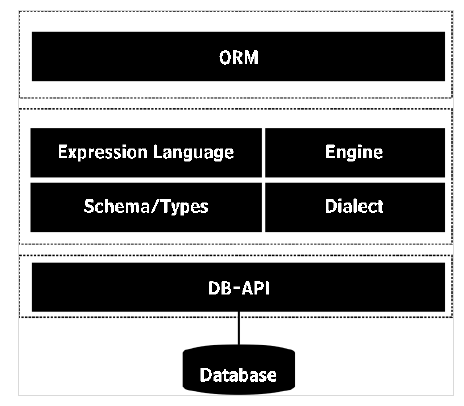
SQLALchemy 库包括ORM API 和 SQL 表达式语言(SQLAlchemy Core)。表达式语言直接执行关系数据库的原始结构。
ORM 是构建在 SQL 表达式语言之上的高级和抽象的使用模式。可以说 ORM 是表达式语言的一种应用用法。在本主题中,我们将讨论 SQLAlchemy ORM API 并使用 SQLite 数据库。
SQLAlchemy 通过其各自的 DBAPI 实现使用方言系统与各种类型的数据库进行通信。所有方言都需要安装相应的 DBAPI 驱动程序。包含以下类型数据库的方言:
- Firebird
- Microsoft SQL Server
- MySQL
- Oracle
- PostgreSQL
- SQLite
- Sybase
SQLAlchemy 的安装非常简单直接,可以使用 pip 实用程序。
pip install sqlalchemy
要检查 SQLalchemy 是否已正确安装及其版本,请在 Python 提示符下输入以下内容:
>>> import sqlalchemy >>>sqlalchemy.__version__ '1.3.11'
与数据库的交互是通过作为create_engine() 函数的返回值获得的 Engine 对象完成的。
engine =create_engine('sqlite:///mydb.sqlite')
SQLite 允许创建内存数据库。内存数据库的 SQLAlchemy 引擎创建如下:
from sqlalchemy import create_engine
engine=create_engine('sqlite:///:memory:')
如果您打算改用 MySQL 数据库,请使用其 DB-API 模块 – pymysql 和相应的方言驱动程序。
engine = create_engine('mysql+pymydsql://root@localhost/mydb')
create_engine 具有可选的 echo 参数。如果设置为 true,则引擎生成的 SQL 查询将在终端上回显。
SQLAlchemy 包含声明式基类。它充当模型类和映射表的目录。
from sqlalchemy.ext.declarative import declarative_base base=declarative_base()
下一步是定义模型类。它必须从基类派生——如上所述的 declarative_base 类的对象。
将__tablename__ 属性设置为要创建在数据库中的表的名称。其他属性对应于字段。每个属性都是 SQLAlchemy 中的 Column 对象,其数据类型来自以下列表中的一个:
- BigInteger
- Boolean
- Date
- DateTime
- Float
- Integer
- Numeric
- SmallInteger
- String
- Text
- Time
以下代码是名为 Student 的模型类,它映射到 Students 表。
#myclasses.py from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column, Integer, String, Numeric base=declarative_base() class Student(base): __tablename__='Students' StudentID=Column(Integer, primary_key=True) name=Column(String) age=Column(Integer) marks=Column(Numeric)
要创建一个具有相应结构的 Students 表,请执行为基类定义的 create_all() 方法。
base.metadata.create_all(engine)
现在我们必须声明我们的 Student 类的对象。所有数据库事务(例如添加、删除或从数据库检索数据等)都由 Session 对象处理。
from sqlalchemy.orm import sessionmaker Session = sessionmaker(bind=engine) sessionobj = Session()
存储在 Student 对象中的数据通过 session 的 add() 方法物理添加到底层表中。
s1 = Student(name='Juhi', age=25, marks=200) sessionobj.add(s1) sessionobj.commit()
这是在 students 表中添加记录的完整代码。在执行时,相应的 SQL 语句日志将显示在控制台中。
from sqlalchemy import Column, Integer, String
from sqlalchemy import create_engine
from myclasses import Student, base
engine = create_engine('sqlite:///college.db', echo=True)
base.metadata.create_all(engine)
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine)
sessionobj = Session()
s1 = Student(name='Juhi', age=25, marks=200)
sessionobj.add(s1)
sessionobj.commit()
控制台输出
CREATE TABLE "Students" (
"StudentID" INTEGER NOT NULL,
name VARCHAR,
age INTEGER,
marks NUMERIC,
PRIMARY KEY ("StudentID")
)
INFO sqlalchemy.engine.base.Engine ()
INFO sqlalchemy.engine.base.Engine COMMIT
INFO sqlalchemy.engine.base.Engine BEGIN (implicit)
INFO sqlalchemy.engine.base.Engine INSERT INTO "Students" (name, age, marks) VALUES (?, ?, ?)
INFO sqlalchemy.engine.base.Engine ('Juhi', 25, 200.0)
INFO sqlalchemy.engine.base.Engine COMMIT
session 对象还提供 add_all() 方法,以便在单个事务中插入多个对象。
sessionobj.add_all([s2,s3,s4,s5]) sessionobj.commit()
现在,记录已添加到表中,我们希望像 SELECT 查询一样从中提取记录。session 对象具有 query() 方法来执行此任务。Query 对象由 Student 模型上的 query() 方法返回。
qry=seesionobj.query(Student)
使用此 Query 对象的 get() 方法获取对应于给定主键的对象。
S1=qry.get(1)
执行此语句时,在控制台中回显的相应 SQL 语句如下:
BEGIN (implicit) SELECT "Students"."StudentID" AS "Students_StudentID", "Students".name AS "Students_name", "Students".age AS "Students_age", "Students".marks AS "Students_marks" FROM "Students" WHERE "Products"."Students" = ? sqlalchemy.engine.base.Engine (1,)
query.all() 方法返回所有对象的列表,可以使用循环遍历这些对象。
from sqlalchemy import Column, Integer, String, Numeric
from sqlalchemy import create_engine
from myclasses import Student,base
engine = create_engine('sqlite:///college.db', echo=True)
base.metadata.create_all(engine)
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine)
sessionobj = Session()
qry=sessionobj.query(Students)
rows=qry.all()
for row in rows:
print (row)
更新映射表中的记录非常容易。您只需使用 get() 方法获取记录,将新值赋给所需的属性,然后使用 session 对象提交更改。下面我们将 Juhi 学生的分数更改为 100。
S1=qry.get(1) S1.marks=100 sessionobj.commit()
删除记录也同样容易,只需从 session 中删除所需的对象即可。
S1=qry.get(1) Sessionobj.delete(S1) sessionobj.commit()