- Python 数据持久化教程
- Python 数据持久化 - 首页
- Python 数据持久化 - 简介
- Python 数据持久化 - 文件 API
- 使用 os 模块处理文件
- Python 数据持久化 - 对象序列化
- Python 数据持久化 - Pickle 模块
- Python 数据持久化 - Marshal 模块
- Python 数据持久化 - Shelve 模块
- Python 数据持久化 - dbm 包
- Python 数据持久化 - CSV 模块
- Python 数据持久化 - JSON 模块
- Python 数据持久化 - XML 解析器
- Python 数据持久化 - Plistlib 模块
- Python 数据持久化 - Sqlite3 模块
- Python 数据持久化 - SQLAlchemy
- Python 数据持久化 - PyMongo 模块
- Python 数据持久化 - Cassandra 驱动程序
- 数据持久化 - ZODB
- 数据持久化 - Openpyxl 模块
- Python 数据持久化资源
- Python 数据持久化 - 快速指南
- Python 数据持久化 - 有用资源
- Python 数据持久化 - 讨论
Python 数据持久化 - 快速指南
Python 数据持久化 - 简介
Python - 数据持久化概述
在使用任何软件应用程序的过程中,用户会提供一些数据进行处理。数据可以通过标准输入设备(键盘)或其他设备(如磁盘文件、扫描仪、相机、网络电缆、WiFi 连接等)输入。
接收到的数据以各种数据结构(如变量和对象)的形式存储在计算机的主内存(RAM)中,直到应用程序运行。之后,RAM 中的内存内容将被擦除。
但是,很多时候,希望以某种方式存储变量和/或对象的值,以便在需要时检索,而不是再次输入相同的数据。
“持久化”一词表示“在原因消除后效果的持续”。数据持久化表示即使在应用程序结束之后,数据也仍然存在。因此,存储在非易失性存储介质(如磁盘文件)中的数据是持久性数据存储。
在本教程中,我们将探索各种内置和第三方 Python 模块,以将数据存储到和从各种格式(如文本文件、CSV、JSON 和 XML 文件以及关系和非关系数据库)中检索数据。
使用 Python 的内置 File 对象,可以将字符串数据写入磁盘文件并从中读取。Python 的标准库提供了模块来以各种数据结构(如 JSON 和 XML)存储和检索序列化数据。
Python 的 DB-API 提供了一种与关系数据库交互的标准方法。其他第三方 Python 包提供了与 MongoDB 和 Cassandra 等 NoSQL 数据库交互的功能。
本教程还介绍了 ZODB 数据库,它是 Python 对象的持久化 API。Microsoft Excel 格式是一种非常流行的数据文件格式。在本教程中,我们将学习如何通过 Python 处理 .xlsx 文件。
Python 数据持久化 - 文件 API
Python 使用内置的 input() 和 print() 函数执行标准输入/输出操作。input() 函数从标准输入流设备(即键盘)读取字节。
另一方面,print() 函数将数据发送到标准输出流设备(即显示器)。Python 程序通过 sys 模块中定义的标准流对象 stdin 和 stdout 与这些 IO 设备交互。
input() 函数实际上是 sys.stdin 对象的 readline() 方法的包装器。从输入流接收所有击键,直到按下“Enter”键。
>>> import sys >>> x=sys.stdin.readline() Welcome to TutorialsPoint >>> x 'Welcome to TutorialsPoint\n'
请注意,readline() 函数会留下一个尾随的“\n”字符。还有一个 read() 方法,它会从标准输入流读取数据,直到它被 Ctrl+D 字符终止。
>>> x=sys.stdin.read() Hello Welcome to TutorialsPoint >>> x 'Hello\nWelcome to TutorialsPoint\n'
类似地,print() 是一个模拟 stdout 对象的 write() 方法的便捷函数。
>>> x='Welcome to TutorialsPoint\n' >>> sys.stdout.write(x) Welcome to TutorialsPoint 26
就像 stdin 和 stdout 预定义的流对象一样,Python 程序可以从磁盘文件或网络套接字读取数据并向其发送数据。它们也是流。任何具有 read() 方法的对象都是输入流。任何具有 write() 方法的对象都是输出流。通过使用内置的 open() 函数获取对流对象的引用来建立与流的通信。
open() 函数
此内置函数使用以下参数:
f=open(name, mode, buffering)
name 参数是磁盘文件或字节字符串的名称,mode 是可选的单字符字符串,用于指定要执行的操作类型(读取、写入、追加等),buffering 参数为 0、1 或 -1,表示缓冲区关闭、打开或系统默认值。
文件打开模式根据下表列出。默认模式为“r”
| 序号 | 参数及说明 |
|---|---|
| 1 |
R 打开以进行读取(默认) |
| 2 |
W 打开以进行写入,首先截断文件 |
| 3 |
X 创建一个新文件并将其打开以进行写入 |
| 4 |
A 打开以进行写入,如果文件存在则追加到文件末尾 |
| 5 |
B 二进制模式 |
| 6 |
T 文本模式(默认) |
| 7 |
+ 打开磁盘文件以进行更新(读取和写入) |
为了将数据保存到文件,必须以“w”模式打开它。
f=open('test.txt','w')
此文件对象充当输出流,并可以访问 write() 方法。write() 方法将字符串发送到此对象,并将其存储在底层文件中。
string="Hello TutorialsPoint\n" f.write(string)
关闭流非常重要,以确保缓冲区中任何剩余的数据都完全传输到它。
file.close()
尝试使用任何文本编辑器(如记事本)打开“test.txt”,以确认文件已成功创建。
要以编程方式读取“test.txt”的内容,必须以“r”模式打开它。
f=open('test.txt','r')
此对象充当输入流。Python 可以使用 read() 方法从流中获取数据。
string=f.read() print (string)
文件的内容显示在 Python 控制台上。File 对象还支持 readline() 方法,该方法能够读取字符串,直到遇到 EOF 字符。
但是,如果以“w”模式打开同一个文件以在其存储其他文本,则先前的内容将被擦除。每当以写入权限打开文件时,都会将其视为新文件。要将数据添加到现有文件,请使用“a”表示追加模式。
f=open('test.txt','a')
f.write('Python Tutorials\n')
现在,文件具有先前以及新添加的字符串。文件对象还支持 writelines() 方法将列表对象中的每个字符串写入文件。
f=open('test.txt','a')
lines=['Java Tutorials\n', 'DBMS tutorials\n', 'Mobile development tutorials\n']
f.writelines(lines)
f.close()
示例
readlines() 方法返回一个字符串列表,每个字符串代表文件中的一个行。还可以逐行读取文件,直到到达文件末尾。
f=open('test.txt','r')
while True:
line=f.readline()
if line=='' : break
print (line, end='')
f.close()
输出
Hello TutorialsPoint Python Tutorials Java Tutorials DBMS tutorials Mobile development tutorials
二进制模式
默认情况下,文件对象上的读/写操作对文本字符串数据执行。如果我们要处理不同其他类型的文件,例如媒体 (mp3)、可执行文件 (exe)、图片 (jpg) 等,我们需要在读/写模式中添加“b”前缀。
以下语句会将字符串转换为字节并写入文件。
f=open('test.bin', 'wb')
data=b"Hello World"
f.write(data)
f.close()
也可以使用 encode() 函数将文本字符串转换为字节。
data="Hello World".encode('utf-8')
我们需要使用 'rb' 模式读取二进制文件。在打印之前,首先对 read() 方法的返回值进行解码。
f=open('test.bin', 'rb')
data=f.read()
print (data.decode(encoding='utf-8'))
为了在二进制文件中写入整数数据,应使用 to_bytes() 方法将整数对象转换为字节。
n=25
n.to_bytes(8,'big')
f=open('test.bin', 'wb')
data=n.to_bytes(8,'big')
f.write(data)
要从二进制文件读取回数据,请使用 from_bytes() 函数将 read() 函数的输出转换为整数。
f=open('test.bin', 'rb')
data=f.read()
n=int.from_bytes(data, 'big')
print (n)
对于浮点数数据,我们需要使用 Python 标准库中的 struct 模块。
import struct
x=23.50
data=struct.pack('f',x)
f=open('test.bin', 'wb')
f.write(data)
解压缩 read() 函数的字符串,以从二进制文件中检索浮点数数据。
f=open('test.bin', 'rb')
data=f.read()
x=struct.unpack('f', data)
print (x)
同时读写
当文件以写入方式打开(使用“w”或“a”)时,无法从中读取,反之亦然。这样做会引发 UnSupportedOperation 错误。我们需要在执行其他操作之前关闭文件。
为了同时执行这两个操作,我们必须在 mode 参数中添加“+”字符。因此,“w+”或“r+”模式允许使用 write() 和 read() 方法,而无需关闭文件。File 对象还支持 seek() 函数将流倒回至任何所需的字节位置。
f=open('test.txt','w+')
f.write('Hello world')
f.seek(0,0)
data=f.read()
print (data)
f.close()
下表总结了文件类对象可用的所有方法。
| 序号 | 方法及说明 |
|---|---|
| 1 |
close() 关闭文件。关闭的文件无法再读取或写入。 |
| 2 |
flush() 刷新内部缓冲区。 |
| 3 |
fileno() 返回整数文件描述符。 |
| 4 |
next() 每次调用时都返回文件中的下一行。在 Python 3 中使用 next() 迭代器。 |
| 5 |
read([size]) 最多从文件读取 size 个字节(如果读取在获取 size 个字节之前遇到 EOF,则读取更少的字节)。 |
| 6 |
readline([size]) 从文件读取整行。字符串中保留尾随换行符。 |
| 7 |
readlines([sizehint]) 使用 readline() 读取直到 EOF 并返回包含这些行的列表。 |
| 8 |
seek(offset[, whence]) 设置文件当前位置。0-开头 1-当前 2-结尾。 |
| 9 |
seek(offset[, whence]) 设置文件当前位置。0-开头 1-当前 2-结尾。 |
| 10 |
tell() 返回文件当前位置 |
| 11 |
truncate([size]) 截断文件大小。 |
| 12 |
write(str) 将字符串写入文件。没有返回值。 |
使用 os 模块处理文件
除了 open() 函数返回的 File 对象之外,还可以使用 Python 的内置库执行文件 IO 操作,该库具有 os 模块,该模块提供了有用的操作系统相关函数。这些函数对文件执行低级读/写操作。
os 模块中的 open() 函数类似于内置的 open()。但是,它不返回文件对象,而是返回文件描述符,即对应于打开文件的唯一整数。文件描述符的值 0、1 和 2 分别表示 stdin、stdout 和 stderr 流。其他文件将从 2 开始获得递增的文件描述符。
与 open() 内置函数一样,os.open() 函数也需要指定文件访问模式。下表列出了 os 模块中定义的各种模式。
| 序号 | Os 模块及说明 |
|---|---|
| 1 |
os.O_RDONLY 仅打开以进行读取 |
| 2 |
os.O_WRONLY 仅打开以进行写入 |
| 3 |
os.O_RDWR 打开以进行读取和写入 |
| 4 |
os.O_NONBLOCK 打开时不要阻塞 |
| 5 |
os.O_APPEND 每次写入时追加 |
| 6 |
os.O_CREAT 如果文件不存在则创建文件 |
| 7 |
os.O_TRUNC 将大小截断为 0 |
| 8 |
os.O_EXCL 如果创建且文件存在则出错 |
要打开一个新文件以在其写入数据,请通过插入管道 (|) 运算符指定 O_WRONLY 和 O_CREAT 模式。os.open() 函数返回文件描述符。
f=os.open("test.dat", os.O_WRONLY|os.O_CREAT)
请注意,数据以字节字符串的形式写入磁盘文件。因此,普通字符串通过使用 encode() 函数(如前所述)转换为字节字符串。
data="Hello World".encode('utf-8')
os 模块中的 write() 函数接受此字节字符串和文件描述符。
os.write(f,data)
不要忘记使用 close() 函数关闭文件。
os.close(f)
要使用 os.read() 函数读取文件内容,请使用以下语句
f=os.open("test.dat", os.O_RDONLY)
data=os.read(f,20)
print (data.decode('utf-8'))
请注意,os.read() 函数需要文件描述符和要读取的字节数(字节字符串的长度)。
如果要打开文件以进行同时读写操作,请使用 O_RDWR 模式。下表显示了 os 模块中重要的文件操作相关函数。
| 序号 | 函数及说明 |
|---|---|
| 1 |
os.close(fd) 关闭文件描述符。 |
| 2 |
os.open(file, flags[, mode]) 打开文件并根据 flags 设置各种标志,并可能根据 mode 设置其模式。 |
| 3 |
os.read(fd, n) 从文件描述符 fd 读取最多 n 个字节。返回一个包含读取的字节的字符串。如果已到达 fd 引用的文件的末尾,则返回空字符串。 |
| 4 |
os.write(fd, str) 将字符串 str 写入文件描述符 fd。返回实际写入的字节数。 |
Python 数据持久化 - 对象序列化
Python 内置的 open() 函数返回的文件对象有一个重要的缺点。当以 'w' 模式打开时,write() 方法只接受字符串对象。
这意味着,如果您的数据以任何非字符串形式表示,无论是内置类(数字、字典、列表或元组)的对象还是其他用户定义类的对象,都无法直接写入文件。在写入之前,您需要将其转换为字符串表示形式。
numbers=[10,20,30,40]
file=open('numbers.txt','w')
file.write(str(numbers))
file.close()
对于二进制文件,write() 方法的参数必须是字节对象。例如,整数列表通过 bytearray() 函数转换为字节,然后写入文件。
numbers=[10,20,30,40] data=bytearray(numbers) file.write(data) file.close()
要从文件中读取回相应数据类型的数据,需要进行反向转换。
file=open('numbers.txt','rb')
data=file.read()
print (list(data))
这种将对象手动转换为字符串或字节格式(反之亦然)的过程非常繁琐且乏味。可以将 Python 对象的状态以字节流的形式直接存储到文件或内存流中,并检索回其原始状态。此过程称为序列化和反序列化。
Python 的内置库包含各种用于序列化和反序列化过程的模块。
| 序号 | 名称和描述 |
|---|---|
| 1 |
pickle Python 特定的序列化库 |
| 2 |
marshal 内部用于序列化的库 |
| 3 |
shelve Pythonic 对象持久化 |
| 4 |
dbm 提供与 Unix 数据库接口的库 |
| 5 |
csv 用于将 Python 数据存储和检索到 CSV 格式的库 |
| 6 |
json 用于序列化到通用 JSON 格式的库 |
Python 数据持久化 - Pickle 模块
Python 将序列化和反序列化分别称为 pickling 和 unpickling。Python 库中的 pickle 模块使用非常 Python 特定的数据格式。因此,非 Python 应用程序可能无法正确地反序列化 pickled 数据。建议不要从未经身份验证的来源反序列化数据。
序列化(pickled)的数据可以存储在字节字符串或二进制文件中。此模块定义了 dumps() 和 loads() 函数,分别用于使用字节字符串对数据进行 pickling 和 unpickling。对于基于文件的处理,该模块具有 dump() 和 load() 函数。
Python 的 pickle 协议是在将 Python 对象构造和解构为/从二进制数据中使用的约定。目前,pickle 模块定义了 5 种不同的协议,如下所示:
| 序号 | 名称和描述 |
|---|---|
| 1 |
协议版本 0 原始的“人类可读”协议,与早期版本向后兼容。 |
| 2 |
协议版本 1 旧的二进制格式,也与早期版本的 Python 兼容。 |
| 3 |
协议版本 2 在 Python 2.3 中引入,提供了对新式类的有效 pickling。 |
| 4 |
协议版本 3 在 Python 3.0 中添加。当需要与其他 Python 3 版本兼容时推荐使用。 |
| 5 |
协议版本 4 在 Python 3.4 中添加。它增加了对非常大的对象的支持。 |
示例
pickle 模块包含 dumps() 函数,该函数返回 pickled 数据的字符串表示形式。
from pickle import dump
dct={"name":"Ravi", "age":23, "Gender":"M","marks":75}
dctstring=dumps(dct)
print (dctstring)
输出
b'\x80\x03}q\x00(X\x04\x00\x00\x00nameq\x01X\x04\x00\x00\x00Raviq\x02X\x03\x00\x00\x00ageq\x03K\x17X\x06\x00\x00\x00Genderq\x04X\x01\x00\x00\x00Mq\x05X\x05\x00\x00\x00marksq\x06KKu.
示例
使用 loads() 函数,对字符串进行 unpickling 并获取原始字典对象。
from pickle import load dct=loads(dctstring) print (dct)
输出
{'name': 'Ravi', 'age': 23, 'Gender': 'M', 'marks': 75}
pickled 对象也可以使用 dump() 函数持久存储在磁盘文件中,并使用 load() 函数检索。
import pickle
f=open("data.txt","wb")
dct={"name":"Ravi", "age":23, "Gender":"M","marks":75}
pickle.dump(dct,f)
f.close()
#to read
import pickle
f=open("data.txt","rb")
d=pickle.load(f)
print (d)
f.close()
pickle 模块还提供面向对象的 API,用于以 Pickler 和 Unpickler 类形式实现序列化机制。
如上所述,与 Python 中的内置对象一样,用户定义类的对象也可以持久序列化到磁盘文件中。在下面的程序中,我们定义了一个 User 类,其名称和手机号码作为其实例属性。除了 __init__() 构造函数之外,该类还覆盖了 __str__() 方法,该方法返回其对象的字符串表示形式。
class User:
def __init__(self,name, mob):
self.name=name
self.mobile=mob
def __str__(self):
return ('Name: {} mobile: {} '. format(self.name, self.mobile))
要将上述类的对象 pickle 到文件中,我们使用 pickler 类及其 dump() 方法。
from pickle import Pickler
user1=User('Rajani', '[email protected]', '1234567890')
file=open('userdata','wb')
Pickler(file).dump(user1)
Pickler(file).dump(user2)
file.close()
相反,Unpickler 类具有 load() 方法,用于检索序列化的对象,如下所示:
from pickle import Unpickler
file=open('usersdata','rb')
user1=Unpickler(file).load()
print (user1)
Python 数据持久化 - Marshal 模块
Python 标准库中 marshal 模块的对象序列化功能类似于 pickle 模块。但是,此模块不用于通用数据。另一方面,它被 Python 本身用于 Python 的内部对象序列化,以支持对 Python 模块的编译版本(.pyc 文件)执行读/写操作。
marshal 模块使用的数据格式在 Python 版本之间不兼容。因此,一个版本的编译 Python 脚本(.pyc 文件)很可能无法在另一个版本上执行。
与 pickle 模块一样,marshal 模块也定义了 load() 和 dump() 函数,用于从文件读取和写入 marshalled 对象。
dump()
此函数将支持的 Python 对象的字节表示形式写入文件。该文件本身必须是具有写权限的二进制文件。
load()
此函数从二进制文件读取字节数据并将其转换为 Python 对象。
以下示例演示了如何使用 dump() 和 load() 函数处理 Python 的代码对象,这些对象用于存储预编译的 Python 模块。
该代码使用内置的 compile() 函数从包含 Python 指令的源字符串构建代码对象。
compile(source, file, mode)
file 参数应为从中读取代码的文件。如果它不是从文件读取的,则传递任何任意字符串。
如果源包含语句序列,则 mode 参数为 'exec';如果存在单个表达式,则为 'eval';如果它包含单个交互式语句,则为 'single'。
然后使用 dump() 函数将编译后的代码对象存储在 .pyc 文件中。
import marshal
script = """
a=10
b=20
print ('addition=',a+b)
"""
code = compile(script, "script", "exec")
f=open("a.pyc","wb")
marshal.dump(code, f)
f.close()
要从 .pyc 文件反序列化对象,请使用 load() 函数。由于它返回一个代码对象,因此可以使用 exec()(另一个内置函数)运行它。
import marshal
f=open("a.pyc","rb")
data=marshal.load(f)
exec (data)
Python 数据持久化 - Shelve 模块
Python 标准库中的 shelve 模块提供了一个简单但有效的对象持久化机制。此模块中定义的 shelf 对象是类似字典的对象,持久存储在磁盘文件中。这会创建一个类似于类 Unix 系统上 dbm 数据库的文件。
shelf 字典有一些限制。此特殊字典对象只能使用字符串数据类型作为键,而任何可 pickling 的 Python 对象都可以用作值。
shelve 模块定义了以下三个类:
| 序号 | Shelve 模块和描述 |
|---|---|
| 1 |
Shelf 这是 shelf 实现的基类。它使用类似字典的对象进行初始化。 |
| 2 |
BsdDbShelf 这是 Shelf 类的子类。传递给其构造函数的 dict 对象必须支持 first()、next()、previous()、last() 和 set_location() 方法。 |
| 3 |
DbfilenameShelf 这也是 Shelf 的子类,但它接受文件名作为其构造函数的参数,而不是 dict 对象。 |
shelve 模块中定义的 open() 函数返回 DbfilenameShelf 对象。
open(filename, flag='c', protocol=None, writeback=False)
filename 参数分配给创建的数据库。flag 参数的默认值为 'c',用于读/写访问。其他标志为 'w'(只写)、'r'(只读)和 'n'(新的读/写)。
序列化本身受 pickle 协议控制,默认为 none。最后一个参数 writeback 参数默认为 false。如果设置为 true,则缓存访问的条目。每次访问都会调用 sync() 和 close() 操作,因此进程可能会变慢。
以下代码创建了一个数据库并在其中存储字典条目。
import shelve
s=shelve.open("test")
s['name']="Ajay"
s['age']=23
s['marks']=75
s.close()
这将在当前目录中创建 test.dir 文件,并将键值数据以哈希形式存储。Shelf 对象具有以下可用方法:
| 序号 | 方法和描述 |
|---|---|
| 1 |
close() 同步并关闭持久化字典对象。 |
| 2 |
sync() 如果 shelf 以 writeback 设置为 True 打开,则写回缓存中的所有条目。 |
| 3 |
get() 返回与键关联的值 |
| 4 |
items() 元组列表 - 每个元组都是键值对 |
| 5 |
keys() shelf 键列表 |
| 6 |
pop() 删除指定的键并返回相应的值。 |
| 7 |
update() 从另一个 dict/iterable 更新 shelf |
| 8 |
values() shelf 值列表 |
要访问 shelf 中特定键的值,请执行以下操作:
s=shelve.open('test')
print (s['age']) #this will print 23
s['age']=25
print (s.get('age')) #this will print 25
s.pop('marks') #this will remove corresponding k-v pair
与内置字典对象一样,items()、keys() 和 values() 方法返回视图对象。
print (list(s.items()))
[('name', 'Ajay'), ('age', 25), ('marks', 75)]
print (list(s.keys()))
['name', 'age', 'marks']
print (list(s.values()))
['Ajay', 25, 75]
要将另一个字典的项目与 shelf 合并,请使用 update() 方法。
d={'salary':10000, 'designation':'manager'}
s.update(d)
print (list(s.items()))
[('name', 'Ajay'), ('age', 25), ('salary', 10000), ('designation', 'manager')]
Python 数据持久化 - dbm 包
dbm 包提供了一个类似字典的接口,用于 DBM 样式数据库。DBM 代表 DataBase Manager。它由 UNIX(和类 Unix)操作系统使用。dbbm 库是由 Ken Thompson 编写的简单数据库引擎。这些数据库使用二进制编码的字符串对象作为键以及值。
数据库通过使用单个键(主键)在固定大小的桶中存储数据,并使用哈希技术通过键快速检索数据。
dbm 包包含以下模块:
dbm.gnu 模块是 GNU 项目实现的 DBM 库版本的接口。
dbm.ndbm 模块提供与 UNIX nbdm 实现的接口。
dbm.dumb 用作后备选项,以防找不到其他 dbm 实现。这不需要外部依赖项,但速度比其他选项慢。
>>> dbm.whichdb('mydbm.db')
'dbm.dumb'
>>> import dbm
>>> db=dbm.open('mydbm.db','n')
>>> db['name']=Raj Deshmane'
>>> db['address']='Kirtinagar Pune'
>>> db['PIN']='431101'
>>> db.close()
open() 函数允许使用以下标志:
| 序号 | 值和含义 |
|---|---|
| 1 |
'r' 以只读方式打开现有数据库(默认值) |
| 2 | 'w' 以读写方式打开现有数据库 |
| 3 | 'c' 以读写方式打开数据库,如果它不存在则创建它 |
| 4 | 'n' 始终创建一个新的空数据库,以读写方式打开 |
dbm 对象是一个类似字典的对象,就像 shelf 对象一样。因此,可以执行所有字典操作。dbm 对象可以调用 get()、pop()、append() 和 update() 方法。以下代码使用 'r' 标志打开 'mydbm.db' 并迭代键值对的集合。
>>> db=dbm.open('mydbm.db','r')
>>> for k,v in db.items():
print (k,v)
b'name' : b'Raj Deshmane'
b'address' : b'Kirtinagar Pune'
b'PIN' : b'431101'
Python 数据持久化 - CSV 模块
CSV 代表逗号分隔值。此文件格式是在将数据导出/导入到/从电子表格和数据库中的数据表时常用的数据格式。csv 模块已集成到 Python 的标准库中,这是 PEP 305 的结果。它提供了类和方法,根据 PEP 305 的建议对 CSV 文件执行读/写操作。
CSV 是 Microsoft Excel 电子表格软件的首选导出数据格式。但是,csv 模块也可以处理其他方言表示的数据。
CSV API 接口包含以下写入器和读取器类:
writer()
csv 模块中的此函数返回一个写入器对象,该对象将数据转换为分隔的字符串并存储在文件对象中。该函数需要一个具有写权限的文件对象作为参数。写入文件中的每一行都会发出换行符。为了防止行之间出现额外的空格,newline 参数设置为 ''。
Writer 类包含以下方法:
writerow()
此方法将可迭代对象(列表、元组或字符串)中的项目写入文件,并使用逗号字符分隔它们。
writerows()
此方法将可迭代对象的列表作为参数,并将每个项目作为文件中的逗号分隔行写入。
示例
以下示例演示了 writer() 函数的使用。首先,以“w”模式打开一个文件。此文件用于获取 writer 对象。然后使用 writerow() 方法将元组列表中的每个元组写入文件。
import csv
persons=[('Lata',22,45),('Anil',21,56),('John',20,60)]
csvfile=open('persons.csv','w', newline='')
obj=csv.writer(csvfile)
for person in persons:
obj.writerow(person)
csvfile.close()
输出
这将在当前目录中创建“persons.csv”文件。它将显示以下数据。
Lata,22,45 Anil,21,56 John,20,60
无需遍历列表逐行写入,我们可以使用 writerows() 方法。
csvfile=open('persons.csv','w', newline='')
persons=[('Lata',22,45),('Anil',21,56),('John',20,60)]
obj=csv.writer(csvfile)
obj.writerows(persons)
obj.close()
reader()
此函数返回一个 reader 对象,该对象返回 **csv 文件**中各行的迭代器。使用常规的 for 循环,以下示例显示了文件中的所有行:
示例
csvfile=open('persons.csv','r', newline='')
obj=csv.reader(csvfile)
for row in obj:
print (row)
输出
['Lata', '22', '45'] ['Anil', '21', '56'] ['John', '20', '60']
reader 对象是一个迭代器。因此,它支持 next() 函数,该函数也可用于显示 csv 文件中的所有行,而不是使用 **for 循环**。
csvfile=open('persons.csv','r', newline='')
obj=csv.reader(csvfile)
while True:
try:
row=next(obj)
print (row)
except StopIteration:
break
如前所述,csv 模块使用 Excel 作为其默认方言。csv 模块还定义了一个方言类。方言是一组用于实现 CSV 协议的标准。可以使用 list_dialects() 函数获取可用的方言列表。
>>> csv.list_dialects() ['excel', 'excel-tab', 'unix']
除了可迭代对象之外,csv 模块还可以将字典对象导出到 CSV 文件并读取它以填充 Python 字典对象。为此,此模块定义了以下类:
DictWriter()
此函数返回一个 DictWriter 对象。它类似于 writer 对象,但行映射到字典对象。该函数需要具有写权限的文件对象以及字典中使用的键列表作为 fieldnames 参数。这用于将文件中的第一行作为标题写入。
writeheader()
此方法将字典中的键列表作为逗号分隔行写入文件的第一行。
在以下示例中,定义了一个字典项列表。列表中的每个项目都是一个字典。使用 writrows() 方法,它们以逗号分隔的方式写入文件。
persons=[
{'name':'Lata', 'age':22, 'marks':45},
{'name':'Anil', 'age':21, 'marks':56},
{'name':'John', 'age':20, 'marks':60}
]
csvfile=open('persons.csv','w', newline='')
fields=list(persons[0].keys())
obj=csv.DictWriter(csvfile, fieldnames=fields)
obj.writeheader()
obj.writerows(persons)
csvfile.close()
persons.csv 文件显示以下内容:
name,age,marks Lata,22,45 Anil,21,56 John,20,60
DictReader()
此函数从底层 CSV 文件返回一个 DictReader 对象。与 reader 对象一样,它也是一个迭代器,可以使用它来检索文件的内容。
csvfile=open('persons.csv','r', newline='')
obj=csv.DictReader(csvfile)
该类提供 fieldnames 属性,返回用作文件标题的字典键。
print (obj.fieldnames) ['name', 'age', 'marks']
使用循环遍历 DictReader 对象以获取各个字典对象。
for row in obj: print (row)
这将产生以下输出:
OrderedDict([('name', 'Lata'), ('age', '22'), ('marks', '45')])
OrderedDict([('name', 'Anil'), ('age', '21'), ('marks', '56')])
OrderedDict([('name', 'John'), ('age', '20'), ('marks', '60')])
要将 OrderedDict 对象转换为普通字典,我们必须首先从 collections 模块导入 OrderedDict。
from collections import OrderedDict
r=OrderedDict([('name', 'Lata'), ('age', '22'), ('marks', '45')])
dict(r)
{'name': 'Lata', 'age': '22', 'marks': '45'}
Python 数据持久化 - JSON 模块
JSON 代表 **JavaScript 对象表示法**。它是一种轻量级的数据交换格式。它是一种与语言无关且跨平台的文本格式,许多编程语言都支持它。此格式用于 Web 服务器和客户端之间的数据交换。
JSON 格式类似于 pickle。但是,pickle 序列化是特定于 Python 的,而 JSON 格式由许多语言实现,因此已成为通用标准。Python 标准库中 json 模块的功能和接口类似于 pickle 和 marshal 模块。
就像 pickle 模块一样,json 模块也提供了 **dumps()** 和 **loads()** 函数,用于将 Python 对象序列化为 JSON 编码字符串,以及 **dump()** 和 **load()** 函数,用于将序列化后的 Python 对象写入/读取到文件。
**dumps()** - 此函数将对象转换为 JSON 格式。
**loads()** - 此函数将 JSON 字符串转换回 Python 对象。
以下示例演示了这些函数的基本用法:
import json
data=['Rakesh',{'marks':(50,60,70)}]
s=json.dumps(data)
json.loads(s)
dumps() 函数可以接受可选的 sort_keys 参数。默认情况下,它为 False。如果设置为 True,则字典键将按排序顺序出现在 JSON 字符串中。
dumps() 函数还有另一个可选参数称为 indent,它接受一个数字作为值。它决定 json 字符串格式化表示的每个段的长度,类似于打印输出。
json 模块还具有与上述函数相对应的面向对象的 API。模块中定义了两个类 - JSONEncoder 和 JSONDecoder。
JSONEncoder 类
此类的对象是 Python 数据结构的编码器。每个 Python 数据类型都转换为相应的 JSON 类型,如下表所示:
| Python | JSON |
|---|---|
| Dict | 对象 |
| 列表,元组 | 数组 |
| Str | 字符串 |
| int,float,int- 和 float-派生的枚举 | 数字 |
| True | true |
| False | false |
| None | null |
JSONEncoder 类由 JSONEncoder() 构造函数实例化。编码器类中定义了以下重要方法:
| 序号 | 方法和描述 |
|---|---|
| 1 |
encode() 将 Python 对象序列化为 JSON 格式 |
| 2 |
iterencode() 对对象进行编码并返回一个迭代器,该迭代器生成对象中每个项目的编码形式。 |
| 3 |
缩进 确定编码字符串的缩进级别 |
| 4 |
sort_keys 为 true 或 false,使键按排序顺序显示或不显示。 |
| 5 |
Check_circular 如果为 True,则检查容器类型对象中的循环引用 |
以下示例对 Python 列表对象进行编码。
e=json.JSONEncoder() e.encode(data)
JSONDecoder 类
此类的对象有助于将 json 字符串解码回 Python 数据结构。此类中的主要方法是 decode()。以下示例代码从先前步骤中编码的字符串中检索 Python 列表对象。
d=json.JSONDecoder() d.decode(s)
json 模块定义了 **load()** 和 **dump()** 函数,用于将 JSON 数据写入文件类对象(可能是磁盘文件或字节流)并从中读取数据。
dump()
此函数将 JSON 化的 Python 对象数据写入文件。文件必须以“w”模式打开。
import json
data=['Rakesh', {'marks': (50, 60, 70)}]
fp=open('json.txt','w')
json.dump(data,fp)
fp.close()
此代码将在当前目录中创建“json.txt”。它显示以下内容:
["Rakesh", {"marks": [50, 60, 70]}]
load()
此函数从文件中加载 JSON 数据并从中返回 Python 对象。文件必须以读取权限打开(应具有“r”模式)。
示例
fp=open('json.txt','r')
ret=json.load(fp)
print (ret)
fp.close()
输出
['Rakesh', {'marks': [50, 60, 70]}]
**json.tool** 模块还具有命令行接口,该接口验证文件中的数据并以漂亮格式化的方式打印 JSON 对象。
C:\python37>python -m json.tool json.txt
[
"Rakesh",
{
"marks": [
50,
60,
70
]
}
]
Python 数据持久化 - XML 解析器
XML 是 **可扩展标记语言**的首字母缩写词。它是一种可移植的、开源的和跨平台的语言,非常类似于 HTML 或 SGML,并且由万维网联盟推荐。
它是一种众所周知的的数据交换格式,被大量应用程序使用,例如 Web 服务、办公工具和 **面向服务的体系结构** (SOA)。XML 格式既可由机器读取也可由人类读取。
标准 Python 库的 xml 包包含以下用于 XML 处理的模块:
| 序号 | 模块和说明 |
|---|---|
| 1 |
xml.etree.ElementTree ElementTree API,一个简单轻量级的 XML 处理器 |
| 2 |
xml.dom DOM API 定义 |
| 3 |
xml.dom.minidom 一个最小的 DOM 实现 |
| 4 |
xml.sax SAX2 接口实现 |
| 5 |
xml.parsers.expat Expat 解析器绑定 |
XML 文档中的数据以树状分层格式排列,从根和元素开始。每个元素都是树中的单个节点,并且具有包含在 <> 和 </> 标记中的属性。可以为每个元素分配一个或多个子元素。
以下是一个典型的 XML 文档示例:
<?xml version = "1.0" encoding = "iso-8859-1"?>
<studentlist>
<student>
<name>Ratna</name>
<subject>Physics</subject>
<marks>85</marks>
</student>
<student>
<name>Kiran</name>
<subject>Maths</subject>
<marks>100</marks>
</student>
<student>
<name>Mohit</name>
<subject>Biology</subject>
<marks>92</marks>
</student>
</studentlist>
在使用 **ElementTree** 模块时,第一步是设置树的根元素。每个元素都有一个标签和 attrib,它是一个 dict 对象。对于根元素,attrib 是一个空字典。
import xml.etree.ElementTree as xmlobj
root=xmlobj.Element('studentList')
现在,我们可以在根元素下添加一个或多个元素。每个元素对象可能具有 **子元素**。每个子元素都有一个属性和文本属性。
student=xmlobj.Element('student')
nm=xmlobj.SubElement(student, 'name')
nm.text='name'
subject=xmlobj.SubElement(student, 'subject')
nm.text='Ratna'
subject.text='Physics'
marks=xmlobj.SubElement(student, 'marks')
marks.text='85'
使用 append() 方法将此新元素追加到根元素。
root.append(student)
使用上述方法追加任意数量的元素。最后,将根元素对象写入文件。
tree = xmlobj.ElementTree(root)
file = open('studentlist.xml','wb')
tree.write(file)
file.close()
现在,我们看看如何解析 XML 文件。为此,在 ElementTree 构造函数中使用文件名作为文件参数构造文档树。
tree = xmlobj.ElementTree(file='studentlist.xml')
tree 对象具有 **getroot()** 方法以获取根元素,而 getchildren() 返回其下方的元素列表。
root = tree.getroot() children = root.getchildren()
通过迭代每个子节点的子元素集合,构造与每个子元素对应的字典对象。
for child in children:
student={}
pairs = child.getchildren()
for pair in pairs:
product[pair.tag]=pair.text
然后将每个字典追加到列表中,返回原始的字典对象列表。
**SAX** 是用于事件驱动的 XML 解析的标准接口。使用 SAX 解析 XML 需要通过子类化 xml.sax.ContentHandler 来创建 ContentHandler。您为感兴趣的事件注册回调,然后让解析器遍历文档。
当您的文档很大或内存有限时,SAX 很有用,因为它在从磁盘读取文件时对其进行解析,因此整个文件永远不会存储在内存中。
文档对象模型
(DOM) API 是万维网联盟的建议。在这种情况下,整个文件将读取到内存中并以分层(基于树)的形式存储,以表示 XML 文档的所有功能。
对于大型文件,SAX 的速度不如 DOM。另一方面,如果在许多小文件上使用 DOM,它可能会占用大量资源。SAX 是只读的,而 DOM 允许更改 XML 文件。
Python 数据持久化 - Plistlib 模块
plist 格式主要由 MAC OS X 使用。这些文件基本上是 XML 文档。它们存储和检索对象的属性。Python 库包含 plist 模块,用于读取和写入“属性列表”文件(它们通常具有“.plist”扩展名)。
**plistlib** 模块或多或少类似于其他序列化库,因为它也提供 dumps() 和 loads() 函数用于 Python 对象的字符串表示,以及 load() 和 dump() 函数用于磁盘操作。
以下字典对象维护属性(键)和相应的 value:
proplist = {
"name" : "Ganesh",
"designation":"manager",
"dept":"accts",
"salary" : {"basic":12000, "da":4000, "hra":800}
}
为了将这些属性写入磁盘文件,我们在 plist 模块中调用 dump() 函数。
import plistlib
fileName=open('salary.plist','wb')
plistlib.dump(proplist, fileName)
fileName.close()
相反,要读回属性值,请按如下方式使用 load() 函数:
fp= open('salary.plist', 'rb')
pl = plistlib.load(fp)
print(pl)
Python 数据持久化 - Sqlite3 模块
CSV、JSON、XML 等文件的最大缺点之一是它们对于随机访问和事务处理不是很有用,因为它们本质上很大程度上是非结构化的。因此,修改内容变得非常困难。
这些平面文件不适用于客户端-服务器环境,因为它们缺乏异步处理能力。使用非结构化数据文件会导致数据冗余和不一致。
这些问题可以通过使用关系数据库来克服。数据库是组织好的数据集合,用于消除冗余和不一致性,并维护数据完整性。关系数据库模型非常流行。
其基本概念是将数据排列在实体表(称为关系)中。实体表结构提供一个属性,该属性的值对于每一行都是唯一的。这样的属性称为 **“主键”**。
当一个表的 primary key 出现在其他表的结构中时,它被称为 **“外键”**,这构成了这两个表之间关系的基础。基于此模型,目前有许多流行的 RDBMS 产品可用:
- GadFly
- mSQL
- MySQL
- PostgreSQL
- Microsoft SQL Server 2000
- Informix
- Interbase
- Oracle
- Sybase
- SQLite
SQLite 是一种轻量级关系数据库,广泛应用于各种应用程序。它是一个自包含的、无服务器的、零配置的、事务性 SQL 数据库引擎。整个数据库是一个单一文件,可以放置在文件系统中的任何位置。它是一个开源软件,占用空间非常小,并且零配置。它在嵌入式设备、物联网和移动应用中很受欢迎。
所有关系型数据库都使用 SQL 来处理表中的数据。然而,早些时候,这些数据库中的每一个都通过特定于数据库类型的 Python 模块与 Python 应用程序连接。
因此,它们之间缺乏兼容性。如果用户想要更改到不同的数据库产品,将会非常困难。通过提出“Python 增强提案 (PEP 248)”来解决此兼容性问题,该提案建议使用一致的接口连接关系型数据库,称为 DB-API。最新的建议称为DB-API 2.0 版。(PEP 249)
Python 的标准库包含 sqlite3 模块,这是一个符合 DB-API 的模块,用于通过 Python 程序处理 SQLite 数据库。本章解释了 Python 与 SQLite 数据库的连接。
如前所述,Python 以 sqlite3 模块的形式内置支持 SQLite 数据库。对于其他数据库,需要使用 pip 工具安装相应的符合 DB-API 的 Python 模块。例如,要使用 MySQL 数据库,我们需要安装 PyMySQL 模块。
pip install pymysql
DB-API 建议以下步骤:
使用connect() 函数建立与数据库的连接并获取连接对象。
调用连接对象的cursor() 方法获取游标对象。
形成一个由要执行的 SQL 语句组成的查询字符串。
通过调用execute() 方法执行所需的查询。
关闭连接。
import sqlite3
db=sqlite3.connect('test.db')
这里,db 是代表 test.db 的连接对象。请注意,如果数据库不存在,则会创建它。连接对象 db 具有以下方法:
| 序号 | 方法和描述 |
|---|---|
| 1 |
cursor() 返回一个使用此连接的游标对象。 |
| 2 |
commit() 显式地将任何挂起的交易提交到数据库。 |
| 3 |
rollback() 此可选方法会导致事务回滚到起始点。 |
| 4 |
close() 永久关闭与数据库的连接。 |
游标充当给定 SQL 查询的句柄,允许检索结果的一行或多行。从连接中获取游标对象以使用以下语句执行 SQL 查询:
cur=db.cursor()
游标对象定义了以下方法:
| 序号 | 方法和描述 |
|---|---|
| 1 |
execute() 执行字符串参数中的 SQL 查询。 |
| 2 |
executemany() 使用元组列表中的一组参数执行 SQL 查询。 |
| 3 |
fetchone() 从查询结果集中获取下一行。 |
| 4 |
fetchall() 从查询结果集中获取所有剩余的行。 |
| 5 |
callproc() 调用存储过程。 |
| 6 |
close() 关闭游标对象。 |
以下代码在 test.db 中创建了一个表:
import sqlite3
db=sqlite3.connect('test.db')
cur =db.cursor()
cur.execute('''CREATE TABLE student (
StudentID INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT (20) NOT NULL,
age INTEGER,
marks REAL);''')
print ('table created successfully')
db.close()
数据库中所需的完整性数据是通过连接对象的commit() 和rollback() 方法实现的。SQL 查询字符串可能包含不正确的 SQL 查询,这可能会引发异常,应正确处理。为此,execute() 语句放置在 try 块中,如果成功,则使用 commit() 方法持久保存结果。如果查询失败,则使用 rollback() 方法撤消事务。
以下代码在 test.db 中的 student 表上执行 INSERT 查询。
import sqlite3
db=sqlite3.connect('test.db')
qry="insert into student (name, age, marks) values('Abbas', 20, 80);"
try:
cur=db.cursor()
cur.execute(qry)
db.commit()
print ("record added successfully")
except:
print ("error in query")
db.rollback()
db.close()
如果希望 INSERT 查询的 values 子句中的数据由用户输入动态提供,请按照 Python DB-API 中的建议使用参数替换。? 字符用作查询字符串中的占位符,并以元组的形式在 execute() 方法中提供值。以下示例使用参数替换方法插入记录。姓名、年龄和分数作为输入。
import sqlite3
db=sqlite3.connect('test.db')
nm=input('enter name')
a=int(input('enter age'))
m=int(input('enter marks'))
qry="insert into student (name, age, marks) values(?,?,?);"
try:
cur=db.cursor()
cur.execute(qry, (nm,a,m))
db.commit()
print ("one record added successfully")
except:
print("error in operation")
db.rollback()
db.close()
sqlite3 模块定义了executemany() 方法,该方法能够一次添加多条记录。要添加的数据应以元组列表的形式给出,每个元组包含一条记录。列表对象是 executemany() 方法的参数,以及查询字符串。但是,一些其他模块不支持 executemany() 方法。
UPDATE 查询通常包含由 WHERE 子句指定的逻辑表达式。execute() 方法中的查询字符串应包含 UPDATE 查询语法。要将 name='Anil' 的 'age' 值更新为 23,请将字符串定义如下
qry="update student set age=23 where name='Anil';"
为了使更新过程更加动态,我们使用上面描述的参数替换方法。
import sqlite3
db=sqlite3.connect('test.db')
nm=input(‘enter name’)
a=int(input(‘enter age’))
qry="update student set age=? where name=?;"
try:
cur=db.cursor()
cur.execute(qry, (a, nm))
db.commit()
print("record updated successfully")
except:
print("error in query")
db.rollback()
db.close()
类似地,DELETE 操作是通过使用包含 SQL DELETE 查询语法的字符串调用 execute() 方法来执行的。顺便说一句,DELETE 查询通常也包含WHERE 子句。
import sqlite3
db=sqlite3.connect('test.db')
nm=input(‘enter name’)
qry="DELETE from student where name=?;"
try:
cur=db.cursor()
cur.execute(qry, (nm,))
db.commit()
print("record deleted successfully")
except:
print("error in operation")
db.rollback()
db.close()
数据库表上的重要操作之一是从表中检索记录。SQL 提供SELECT 查询用于此目的。当包含 SELECT 查询语法的字符串传递给 execute() 方法时,会返回一个结果集对象。游标对象有两个重要方法,可以使用它们从结果集中检索一条或多条记录。
fetchone()
从结果集中获取下一条可用记录。它是一个元组,包含获取的记录的每一列的值。
fetchall()
以元组列表的形式获取所有剩余的记录。每个元组对应一条记录,并包含表中每一列的值。
以下示例列出了 student 表中的所有记录
import sqlite3
db=sqlite3.connect('test.db')
37
sql="SELECT * from student;"
cur=db.cursor()
cur.execute(sql)
while True:
record=cur.fetchone()
if record==None:
break
print (record)
db.close()
如果您计划使用 MySQL 数据库而不是 SQLite 数据库,则需要如上所述安装PyMySQL 模块。由于 MySQL 数据库安装在服务器上,因此连接过程中的所有步骤都相同,connect() 函数需要 URL 和登录凭据。
import pymysql
con=pymysql.connect('localhost', 'root', '***')
唯一可能与 SQLite 不同的方面是 MySQL 特定的数据类型。类似地,任何与 ODBC 兼容的数据库都可以通过安装 pyodbc 模块与 Python 一起使用。
Python 数据持久化 - SQLAlchemy
任何关系型数据库都将数据存储在表中。表结构定义属性的数据类型,这些属性基本上只是基本数据类型,这些数据类型映射到 Python 的相应内置数据类型。但是,Python 的用户定义对象无法持久存储和检索到/从 SQL 表中。
这是 SQL 类型和面向对象编程语言(如 Python)之间的差异。SQL 没有其他类型(如 dict、tuple、list 或任何用户定义的类)的等效数据类型。
如果必须将对象存储在关系型数据库中,则在执行 INSERT 查询之前,必须首先将其实例属性分解为 SQL 数据类型。另一方面,从 SQL 表中检索到的数据为基本类型。将不得不构造所需类型的 Python 对象以供 Python 脚本使用。这就是对象关系映射器有用的地方。
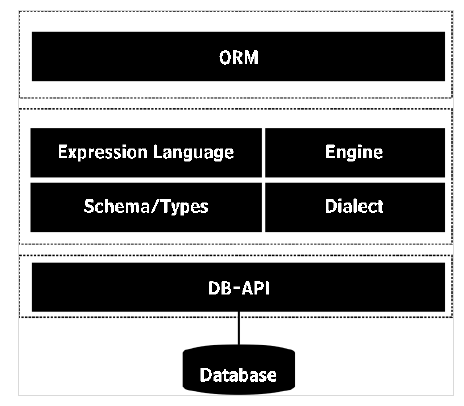
对象关系映射器 (ORM)
对象关系映射器 (ORM) 是类和 SQL 表之间的接口。Python 类映射到数据库中的某个表,以便自动执行对象和 SQL 类型之间的转换。
用 Python 代码编写的 Students 类映射到数据库中的 Students 表。因此,所有 CRUD 操作都是通过调用类的相应方法来完成的。这消除了在 Python 脚本中执行硬编码 SQL 查询的需要。
因此,ORM 库充当原始 SQL 查询的抽象层,有助于快速应用程序开发。SQLAlchemy 是一个流行的 Python 对象关系映射器。模型对象状态的任何操作都与其在数据库表中的相关行同步。
SQLALchemy 库包含ORM API 和 SQL 表达式语言(SQLAlchemy Core)。表达式语言直接执行关系数据库的基本结构。
ORM 是构建在 SQL 表达式语言之上的高级且抽象的使用模式。可以说 ORM 是表达式语言的应用用法。在本主题中,我们将讨论 SQLAlchemy ORM API 并使用 SQLite 数据库。
SQLAlchemy 通过其各自的 DBAPI 实现使用方言系统与各种类型的数据库进行通信。所有方言都需要安装相应的 DBAPI 驱动程序。包含以下类型数据库的方言:
- Firebird
- Microsoft SQL Server
- MySQL
- Oracle
- PostgreSQL
- SQLite
- Sybase
使用 pip 工具安装 SQLAlchemy 很容易且简单。
pip install sqlalchemy
要检查 SQLalchemy 是否已正确安装及其版本,请在 Python 提示符下输入以下内容:
>>> import sqlalchemy >>>sqlalchemy.__version__ '1.3.11'
与数据库的交互是通过作为create_engine() 函数返回值获取的 Engine 对象完成的。
engine =create_engine('sqlite:///mydb.sqlite')
SQLite 允许创建内存数据库。内存数据库的 SQLAlchemy 引擎创建如下:
from sqlalchemy import create_engine
engine=create_engine('sqlite:///:memory:')
如果您打算使用 MySQL 数据库,请使用其 DB-API 模块 – pymysql 和相应的方言驱动程序。
engine = create_engine('mysql+pymydsql://root@localhost/mydb')
create_engine 具有可选的 echo 参数。如果设置为 true,则引擎生成的 SQL 查询将在终端上回显。
SQLAlchemy 包含声明式基类。它充当模型类和映射表的目录。
from sqlalchemy.ext.declarative import declarative_base base=declarative_base()
下一步是定义模型类。它必须从基类派生——如上所示的 declarative_base 类的对象。
将__tablename__ 属性设置为要创建的数据库表的名。其他属性对应于字段。每个属性都是 SQLAlchemy 中的 Column 对象,其数据类型来自以下列表之一:
- BigInteger
- Boolean
- Date
- DateTime
- Float
- Integer
- Numeric
- SmallInteger
- String
- Text
- Time
以下代码是名为 Student 的模型类,它映射到 Students 表。
#myclasses.py from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column, Integer, String, Numeric base=declarative_base() class Student(base): __tablename__='Students' StudentID=Column(Integer, primary_key=True) name=Column(String) age=Column(Integer) marks=Column(Numeric)
要创建一个具有相应结构的 Students 表,请执行为基类定义的 create_all() 方法。
base.metadata.create_all(engine)
现在我们必须声明我们 Student 类的对象。所有数据库事务(例如添加、删除或从数据库检索数据等)都由 Session 对象处理。
from sqlalchemy.orm import sessionmaker Session = sessionmaker(bind=engine) sessionobj = Session()
存储在 Student 对象中的数据通过会话的 add() 方法在底层表中物理添加。
s1 = Student(name='Juhi', age=25, marks=200) sessionobj.add(s1) sessionobj.commit()
这是在 students 表中添加记录的完整代码。在执行时,相应的 SQL 语句日志将显示在控制台上。
from sqlalchemy import Column, Integer, String
from sqlalchemy import create_engine
from myclasses import Student, base
engine = create_engine('sqlite:///college.db', echo=True)
base.metadata.create_all(engine)
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine)
sessionobj = Session()
s1 = Student(name='Juhi', age=25, marks=200)
sessionobj.add(s1)
sessionobj.commit()
控制台输出
CREATE TABLE "Students" (
"StudentID" INTEGER NOT NULL,
name VARCHAR,
age INTEGER,
marks NUMERIC,
PRIMARY KEY ("StudentID")
)
INFO sqlalchemy.engine.base.Engine ()
INFO sqlalchemy.engine.base.Engine COMMIT
INFO sqlalchemy.engine.base.Engine BEGIN (implicit)
INFO sqlalchemy.engine.base.Engine INSERT INTO "Students" (name, age, marks) VALUES (?, ?, ?)
INFO sqlalchemy.engine.base.Engine ('Juhi', 25, 200.0)
INFO sqlalchemy.engine.base.Engine COMMIT
session 对象还提供 add_all() 方法,以便在单个事务中插入多个对象。
sessionobj.add_all([s2,s3,s4,s5]) sessionobj.commit()
现在,记录已添加到表中,我们希望像 SELECT 查询一样从中获取。session 对象具有 query() 方法来执行此任务。Query 对象由 Student 模型上的 query() 方法返回。
qry=seesionobj.query(Student)
使用此 Query 对象的 get() 方法获取对应于给定主键的对象。
S1=qry.get(1)
在执行此语句时,其在控制台上回显的相应 SQL 语句如下:
BEGIN (implicit) SELECT "Students"."StudentID" AS "Students_StudentID", "Students".name AS "Students_name", "Students".age AS "Students_age", "Students".marks AS "Students_marks" FROM "Students" WHERE "Products"."Students" = ? sqlalchemy.engine.base.Engine (1,)
query.all() 方法返回所有对象的列表,可以使用循环遍历这些对象。
from sqlalchemy import Column, Integer, String, Numeric
from sqlalchemy import create_engine
from myclasses import Student,base
engine = create_engine('sqlite:///college.db', echo=True)
base.metadata.create_all(engine)
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine)
sessionobj = Session()
qry=sessionobj.query(Students)
rows=qry.all()
for row in rows:
print (row)
更新映射表中的记录非常容易。您需要做的就是使用 get() 方法获取记录,为所需的属性分配新值,然后使用 session 对象提交更改。下面我们将 Juhi 学生的分数更改为 100。
S1=qry.get(1) S1.marks=100 sessionobj.commit()
删除记录也同样容易,方法是从会话中删除所需的对象。
S1=qry.get(1) Sessionobj.delete(S1) sessionobj.commit()
Python 数据持久化 - PyMongo 模块
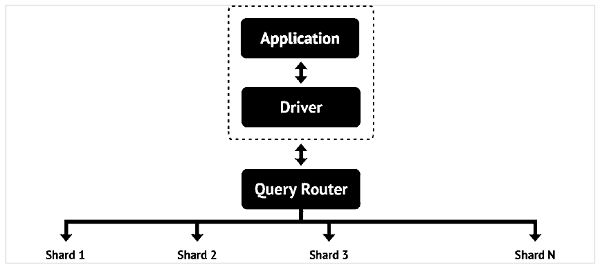
MongoDB 是面向文档的NoSQL 数据库。它是一个跨平台数据库,在服务器端公共许可证下分发。它使用类似 JSON 的文档作为模式。
为了提供存储海量数据的能力,多个物理服务器(称为分片)相互连接,从而实现水平可扩展性。MongoDB 数据库由文档组成。
文档类似于关系型数据库表中的一行。但是,它没有特定的模式。文档是键值对的集合——类似于字典。但是,每个文档中键值对的数量可能不同。就像关系型数据库中的表具有主键一样,MongoDB 数据库中的文档具有一个名为"_id" 的特殊键。
在了解如何将MongoDB数据库与Python一起使用之前,让我们简要了解如何安装和启动MongoDB。MongoDB有社区版和商业版两种版本。社区版可以从www.mongodb.com/download-center/community下载。
假设MongoDB安装在c:\mongodb目录下,可以使用以下命令启动服务器。
c:\mongodb\bin>mongod
默认情况下,MongoDB服务器在22017端口上运行。数据库默认存储在data/bin文件夹中,但可以通过–dbpath选项更改位置。
MongoDB有一套自己的命令,可以在MongoDB shell中使用。要启动shell,请使用Mongo命令。
x:\mongodb\bin>mongo
一个类似于MySQL或SQLite shell提示符的shell提示符将出现,在该提示符前可以执行本机NoSQL命令。但是,我们感兴趣的是将MongoDB数据库连接到Python。
PyMongo模块由MongoDB Inc本身开发,用于提供Python编程接口。使用众所周知的pip工具安装PyMongo。
pip3 install pymongo
假设MongoDB服务器已启动并正在运行(使用mongod命令)并在22017端口监听,我们首先需要声明一个MongoClient对象。它控制Python会话和数据库之间所有事务。
from pymongo import MongoClient client=MongoClient()
使用此客户端对象建立与MongoDB服务器的连接。
client = MongoClient('localhost', 27017)
使用以下命令创建一个新的数据库。
db=client.newdb
MongoDB数据库可以有多个集合,类似于关系数据库中的表。集合对象由Create_collection()函数创建。
db.create_collection('students')
现在,我们可以按如下方式在集合中添加一个或多个文档。
from pymongo import MongoClient
client=MongoClient()
db=client.newdb
db.create_collection("students")
student=db['students']
studentlist=[{'studentID':1,'Name':'Juhi','age':20, 'marks'=100},
{'studentID':2,'Name':'dilip','age':20, 'marks'=110},
{'studentID':3,'Name':'jeevan','age':24, 'marks'=145}]
student.insert_many(studentlist)
client.close()
要检索文档(类似于SELECT查询),我们应该使用find()方法。它返回一个游标,借助该游标可以获取所有文档。
students=db['students'] docs=students.find() for doc in docs: print (doc['Name'], doc['age'], doc['marks'] )
要查找集合中特定文档而不是所有文档,我们需要对find()方法应用过滤器。过滤器使用逻辑运算符。MongoDB有自己的一套逻辑运算符,如下所示:
| 序号 | MongoDB运算符 & 传统逻辑运算符 |
|---|---|
| 1 |
$eq 等于 (==) |
| 2 |
$gt 大于 (>) |
| 3 |
$gte 大于或等于 (>=) |
| 4 |
$in 如果等于数组中的任何值 |
| 5 |
$lt 小于 (<) |
| 6 |
$lte 小于或等于 (<=) |
| 7 |
$ne 不等于 (!=) |
| 8 |
$nin 如果不同于数组中的任何值 |
例如,我们有兴趣获取年龄大于21岁的学生列表。在find()方法的过滤器中使用$gt运算符,如下所示:
students=db['students']
docs=students.find({'age':{'$gt':21}})
for doc in docs:
print (doc.get('Name'), doc.get('age'), doc.get('marks'))
PyMongo模块提供了update_one()和update_many()方法,用于修改满足特定过滤器表达式的单个文档或多个文档。
让我们更新名为Juhi的文档的marks属性。
from pymongo import MongoClient
client=MongoClient()
db=client.newdb
doc=db.students.find_one({'Name': 'Juhi'})
db['students'].update_one({'Name': 'Juhi'},{"$set":{'marks':150}})
client.close()
Python 数据持久化 - Cassandra 驱动程序
Cassandra是另一个流行的NoSQL数据库。高可扩展性、一致性和容错性——这些是Cassandra的一些重要特性。这是一个列存储数据库。数据存储在许多商品服务器中。因此,数据高度可用。
Cassandra是Apache软件基金会的产品。数据以分布式方式存储在多个节点中。每个节点都是一个包含键空间的单个服务器。Cassandra数据库的基本构建块是键空间,它可以被认为类似于数据库。
Cassandra的一个节点中的数据会在节点的点对点网络中的其他节点中进行复制。这使得Cassandra成为一个万无一失的数据库。该网络称为数据中心。多个数据中心可以互连形成一个集群。复制的性质是在创建键空间时通过设置复制策略和复制因子来配置的。
一个键空间可以有多个列族——就像一个数据库可以包含多个表一样。Cassandra的键空间没有预定义的模式。Cassandra表中的每一行都可能具有不同名称和数量可变的列。
Cassandra软件也有两个版本:社区版和企业版。Cassandra的最新企业版可从https://cassandra.apache.org/download/下载。
Cassandra有自己的查询语言,称为Cassandra查询语言 (CQL)。CQL查询可以在CQLASH shell内部执行——类似于MySQL或SQLite shell。CQL语法看起来类似于标准SQL。
Datastax社区版还带有一个Develcenter IDE,如下所示:
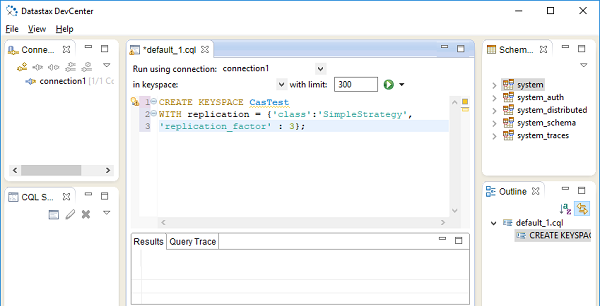
用于处理Cassandra数据库的Python模块称为Cassandra Driver。它也是由Apache基金会开发的。此模块包含一个ORM API,以及一个类似于关系数据库DB-API的内核API。
可以使用pip工具轻松安装Cassandra驱动程序。
pip3 install cassandra-driver
与Cassandra数据库的交互是通过Cluster对象进行的。Cassandra.cluster模块定义了Cluster类。我们首先需要声明Cluster对象。
from cassandra.cluster import Cluster clstr=Cluster()
所有事务(如插入/更新等)都是通过与键空间启动会话来执行的。
session=clstr.connect()
要创建一个新的键空间,请使用会话对象的execute()方法。execute()方法采用一个字符串参数,该参数必须是一个查询字符串。CQL有CREATE KEYSPACE语句,如下所示。完整代码如下:
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect()
session.execute(“create keyspace mykeyspace with replication={
'class': 'SimpleStrategy', 'replication_factor' : 3
};”
这里,SimpleStrategy是复制策略的值,复制因子设置为3。如前所述,一个键空间包含一个或多个表。每个表都以其数据类型为特征。Python数据类型会根据以下表格自动解析为相应的CQL数据类型:
| Python类型 | CQL类型 |
|---|---|
| None | NULL |
| Bool | Boolean |
| Float | float, double |
| int, long | int, bigint, varint, smallint, tinyint, counter |
| decimal.Decimal | Decimal |
| str, Unicode | ascii, varchar, text |
| buffer, bytearray | Blob |
| Date | Date |
| Datetime | Timestamp |
| Time | Time |
| list, tuple, generator | List |
| set, frozenset | Set |
| dict, OrderedDict | Map |
| uuid.UUID | timeuuid, uuid |
要创建一个表,请使用会话对象执行创建表的CQL查询。
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect('mykeyspace')
qry= '''
create table students (
studentID int,
name text,
age int,
marks int,
primary key(studentID)
);'''
session.execute(qry)
创建的键空间可进一步用于插入行。INSERT查询的CQL版本类似于SQL Insert语句。以下代码在students表中插入一行。
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect('mykeyspace')
session.execute("insert into students (studentID, name, age, marks) values
(1, 'Juhi',20, 200);"
正如您所期望的那样,SELECT语句也与Cassandra一起使用。如果execute()方法包含SELECT查询字符串,它将返回一个结果集对象,可以使用循环遍历该对象。
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect('mykeyspace')
rows=session.execute("select * from students;")
for row in rows:
print (StudentID: {} Name:{} Age:{} price:{} Marks:{}'
.format(row[0],row[1], row[2], row[3]))
Cassandra的SELECT查询支持使用WHERE子句对要获取的结果集应用过滤器。传统逻辑运算符(如<、>、==等)都得到识别。要仅从students表中检索名称年龄>20的行,execute()方法中的查询字符串应如下所示:
rows=session.execute("select * from students WHERE age>20 allow filtering;")
请注意,使用了ALLOW FILTERING。此语句的ALLOW FILTERING部分允许显式允许(某些)需要过滤的查询。
Cassandra驱动程序API在其cassendra.query模块中定义了以下Statement类型的类。
SimpleStatement
包含在查询字符串中的简单、未准备的CQL查询。上面所有示例都是SimpleStatement的示例。
BatchStatement
将多个查询(如INSERT、UPDATE和DELETE)放入批处理中并立即执行。每个行首先转换为SimpleStatement,然后添加到批处理中。
让我们将要添加到Students表中的行以元组列表的形式放入,如下所示:
studentlist=[(1,'Juhi',20,100), ('2,'dilip',20, 110),(3,'jeevan',24,145)]
要使用BathStatement添加上述行,请运行以下脚本:
from cassandra.query import SimpleStatement, BatchStatement
batch=BatchStatement()
for student in studentlist:
batch.add(SimpleStatement("INSERT INTO students
(studentID, name, age, marks) VALUES
(%s, %s, %s %s)"), (student[0], student[1],student[2], student[3]))
session.execute(batch)
PreparedStatement
Prepared语句类似于DB-API中的参数化查询。它的查询字符串由Cassandra保存以备后用。Session.prepare()方法返回一个PreparedStatement实例。
对于我们的students表,INSERT查询的PreparedStatement如下所示:
stmt=session.prepare("INSERT INTO students (studentID, name, age, marks) VALUES (?,?,?)")
随后,它只需要发送要绑定的参数值即可。例如:
qry=stmt.bind([1,'Ram', 23,175])
最后,执行上述绑定语句。
session.execute(qry)
这减少了网络流量和CPU利用率,因为Cassandra不必每次都重新解析查询。
数据持久化 - ZODB
ZODB(Zope对象数据库)是用于存储Python对象的数据库。它符合ACID——这是NOSQL数据库中没有的功能。ZODB也是开源的,水平可扩展的,并且像许多NoSQL数据库一样没有模式。但是,它不是分布式的,也不提供简单的复制功能。它为Python对象提供持久性机制。它是Zope应用程序服务器的一部分,但也可以独立使用。
ZODB是由Zope公司的Jim Fulton创建的。它最初是一个简单的持久对象系统。其当前版本为5.5.0,完全用Python编写。使用Python内置对象持久化(pickle)的扩展版本。
ZODB的一些主要特性包括:
- 事务
- 历史记录/撤消
- 可透明插入的存储
- 内置缓存
- 多版本并发控制 (MVCC)
- 跨网络的可扩展性
ZODB是一个分层数据库。在创建数据库时会初始化一个根对象。根对象用作Python字典,它可以包含其他对象(这些对象本身可以是字典式的)。要将对象存储在数据库中,只需将其分配给其容器内的新的键即可。
ZODB适用于数据具有层次结构并且读取次数可能多于写入次数的应用程序。ZODB是pickle对象的扩展。因此,它只能通过Python脚本进行处理。
要安装最新版本的ZODB,请使用pip工具:
pip install zodb
还将安装以下依赖项:
- BTrees==4.6.1
- cffi==1.13.2
- persistent==4.5.1
- pycparser==2.19
- six==1.13.0
- transaction==2.4.0
ZODB提供以下存储选项:
FileStorage
这是默认选项。所有内容都存储在一个大型Data.fs文件中,该文件本质上是一个事务日志。
DirectoryStorage
此选项为每个对象修订版存储一个文件。在这种情况下,它不需要在非正常关闭时重建Data.fs.index。
RelStorage
此选项将pickle存储在关系数据库中。支持PostgreSQL、MySQL和Oracle。
要创建ZODB数据库,我们需要一个存储、一个数据库以及最终的连接。
第一步是拥有存储对象。
import ZODB, ZODB.FileStorage
storage = ZODB.FileStorage.FileStorage('mydata.fs')
DB类使用此存储对象获取数据库对象。
db = ZODB.DB(storage)
将None传递给DB构造函数以创建内存数据库。
Db=ZODB.DB(None)
最后,我们建立与数据库的连接。
conn=db.open()
然后,连接对象使用‘root()’方法让您访问数据库的‘根’。‘根’对象是保存所有持久对象的字典。
root = conn.root()
例如,我们将学生列表添加到根对象,如下所示:
root['students'] = ['Mary', 'Maya', 'Meet']
在提交事务之前,此更改不会永久保存到数据库中。
import transaction transaction.commit()
要存储用户定义类的对象,该类必须继承自persistent.Persistent父类。
子类的优点
子类化Persistent类有以下优点:
数据库将通过设置属性来自动跟踪对象更改。
数据将保存在其自己的数据库记录中。
您可以保存不属于Persistent子类的的数据,但它将存储在引用它的任何持久对象的数据记录中。非持久对象由其包含的持久对象拥有,如果多个持久对象引用同一个非持久子对象,它们将获得自己的副本。
让我们定义一个名为 student 的类,它继承自 Persistent 类,如下所示:
import persistent
class student(persistent.Persistent):
def __init__(self, name):
self.name = name
def __repr__(self):
return str(self.name)
要添加此类的对象,我们首先需要像上面描述的那样建立连接。
import ZODB, ZODB.FileStorage
storage = ZODB.FileStorage.FileStorage('studentdata.fs')
db = ZODB.DB(storage)
conn=db.open()
root = conn.root()
声明对象并添加到根节点,然后提交事务。
s1=student("Akash")
root['s1']=s1
import transaction
transaction.commit()
conn.close()
添加到根节点的所有对象的列表可以通过 items() 方法作为视图对象检索,因为根对象类似于内置字典。
print (root.items())
ItemsView({'s1': Akash})
要从根节点获取特定对象的属性,
print (root['s1'].name) Akash
对象可以轻松更新。由于 ZODB API 是一个纯 Python 包,因此它不需要使用任何外部 SQL 类型语言。
root['s1'].name='Abhishek' import transaction transaction.commit()
数据库将立即更新。请注意,transaction 类还定义了 abort() 函数,它类似于 SQL 中的 rollback() 事务控制。
数据持久化 - Openpyxl 模块
微软的 Excel 是最流行的电子表格应用程序。它已经使用了超过 25 年。Excel 的后续版本使用**Office Open XML**(OOXML) 文件格式。因此,可以通过其他编程环境访问电子表格文件。
**OOXML** 是一个 ECMA 标准文件格式。Python 的**openpyxl** 包提供了读取/写入扩展名为 .xlsx 的 Excel 文件的功能。
openpyxl 包使用类似于 Microsoft Excel 术语的类命名法。Excel 文档称为工作簿,并以 .xlsx 扩展名保存在文件系统中。一个工作簿可以有多个工作表。工作表呈现一个大型的单元格网格,每个单元格可以存储值或公式。构成网格的行和列都有编号。列由字母标识,A、B、C、…、Z、AA、AB 等。行的编号从 1 开始。
一个典型的 Excel 工作表如下所示:
pip 工具足以安装 openpyxl 包。
pip install openpyxl
Workbook 类表示一个空的工作簿,其中包含一个空白的工作表。我们需要激活它,以便可以向工作表添加一些数据。
from openpyxl import Workbook wb=Workbook() sheet1=wb.active sheet1.title='StudentList'
众所周知,工作表中的单元格以 ColumnNameRownumber 格式命名。因此,左上角的单元格是 A1。我们将一个字符串分配给此单元格,如下所示:
sheet1['A1']= 'Student List'
或者,使用工作表的**cell()** 方法,该方法使用行号和列号来识别单元格。调用单元格对象的 value 属性来分配值。
cell1=sheet1.cell(row=1, column=1) cell1.value='Student List'
在用数据填充工作表后,通过调用工作簿对象的 save() 方法保存工作簿。
wb.save('Student.xlsx')
此工作簿文件在当前工作目录中创建。
以下 Python 脚本将元组列表写入工作簿文档。每个元组存储学生的学号、年龄和分数。
from openpyxl import Workbook
wb = Workbook()
sheet1 = wb.active
sheet1.title='Student List'
sheet1.cell(column=1, row=1).value='Student List'
studentlist=[('RollNo','Name', 'age', 'marks'),(1,'Juhi',20,100),
(2,'dilip',20, 110) , (3,'jeevan',24,145)]
for col in range(1,5):
for row in range(1,5):
sheet1.cell(column=col, row=1+row).value=studentlist[row-1][col-1]
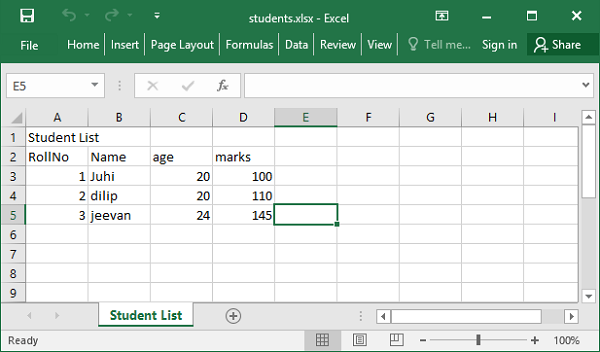
wb.save('students.xlsx')
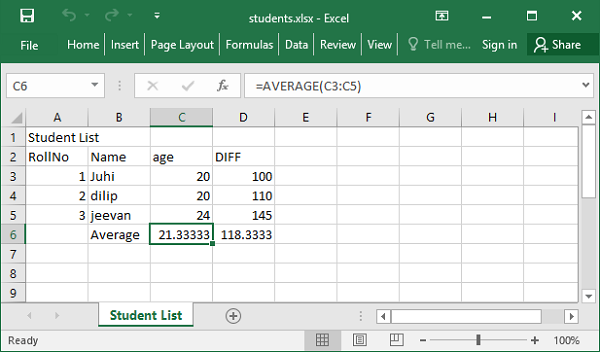
工作簿 students.xlsx 保存到当前工作目录中。如果使用 Excel 应用程序打开,则显示如下:
openpyxl 模块提供**load_workbook()** 函数,该函数有助于读取工作簿文档中的数据。
from openpyxl import load_workbook
wb=load_workbook('students.xlsx')
现在,您可以访问由行号和列号指定的任何单元格的值。
cell1=sheet1.cell(row=1, column=1) print (cell1.value) Student List
示例
以下代码使用工作表数据填充列表。
from openpyxl import load_workbook
wb=load_workbook('students.xlsx')
sheet1 = wb['Student List']
studentlist=[]
for row in range(1,5):
stud=[]
for col in range(1,5):
val=sheet1.cell(column=col, row=1+row).value
stud.append(val)
studentlist.append(tuple(stud))
print (studentlist)
输出
[('RollNo', 'Name', 'age', 'marks'), (1, 'Juhi', 20, 100), (2, 'dilip', 20, 110), (3, 'jeevan', 24, 145)]
Excel 应用程序的一个非常重要的功能是公式。要将公式分配给单元格,请将其分配给包含 Excel 公式语法的字符串。将 AVERAGE 函数分配给包含年龄的 C6 单元格。
sheet1['C6']= 'AVERAGE(C3:C5)'
Openpyxl 模块具有**Translate_formula()** 函数,用于将公式复制到一个范围内。以下程序在 C6 中定义 AVERAGE 函数,并将其复制到计算分数平均值的 C7。
from openpyxl import load_workbook
wb=load_workbook('students.xlsx')
sheet1 = wb['Student List']
from openpyxl.formula.translate import Translator#copy formula
sheet1['B6']='Average'
sheet1['C6']='=AVERAGE(C3:C5)'
sheet1['D6'] = Translator('=AVERAGE(C3:C5)', origin="C6").translate_formula("D6")
wb.save('students.xlsx')
更改后的工作表现在显示如下: