- Python网络爬取教程
- Python网络爬取 - 首页
- 介绍
- Python入门
- 用于网络爬取的Python模块
- 网络爬取的合法性
- 数据提取
- 数据处理
- 处理图像和视频
- 处理文本
- 爬取动态网站
- 爬取基于表单的网站
- 处理验证码
- 使用爬虫进行测试
- Python网络爬取资源
- Python网络爬取 - 快速指南
- Python网络爬取 - 资源
- Python网络爬取 - 讨论
网络爬取的合法性
使用Python,我们可以爬取任何网站或网页的特定元素,但您是否知道这是否合法?在爬取任何网站之前,我们必须了解网络爬取的合法性。本章将解释与网络爬取合法性相关的概念。
介绍
通常,如果您要将爬取的数据用于个人用途,那么可能不会有任何问题。但是,如果您要重新发布该数据,那么在这样做之前,您应该向所有者发出下载请求,或对您要爬取的数据的策略进行一些背景调查。
爬取前所需的研究
如果您要针对某个网站进行数据爬取,我们需要了解其规模和结构。以下是我们在开始网络爬取之前需要分析的一些文件。
分析robots.txt
实际上,大多数发布者允许程序员在一定程度上抓取他们的网站。换句话说,发布者希望抓取网站的特定部分。为了定义这一点,网站必须制定一些规则来声明哪些部分可以抓取,哪些部分不可以抓取。这些规则定义在一个名为robots.txt的文件中。
robots.txt是一个人类可读的文件,用于识别爬虫允许和不允许抓取的网站部分。robots.txt文件没有标准格式,网站发布者可以根据需要进行修改。我们可以通过在该网站的URL后添加斜杠和robots.txt来检查特定网站的robots.txt文件。例如,如果我们要检查Google.com,则需要输入https://www.google.com/robots.txt,我们将得到如下内容:
User-agent: * Disallow: /search Allow: /search/about Allow: /search/static Allow: /search/howsearchworks Disallow: /sdch Disallow: /groups Disallow: /index.html? Disallow: /? Allow: /?hl= Disallow: /?hl=*& Allow: /?hl=*&gws_rd=ssl$ and so on……..
网站的robots.txt文件中定义的一些最常见的规则如下:
User-agent: BadCrawler Disallow: /
上述规则意味着robots.txt文件要求用户代理为BadCrawler的爬虫不要抓取其网站。
User-agent: * Crawl-delay: 5 Disallow: /trap
上述规则意味着robots.txt文件将所有用户代理的爬虫在下载请求之间的延迟设置为5秒,以避免服务器过载。/trap链接将尝试阻止遵循不允许链接的恶意爬虫。发布者可以根据需要定义更多规则。其中一些规则在此处讨论:
分析站点地图文件
如果您想爬取网站以获取更新的信息,您应该怎么做?您将爬取每个网页以获取更新的信息,但这将增加特定网站的服务器流量。这就是为什么网站提供站点地图文件来帮助爬虫定位更新内容,而无需爬取每个网页。站点地图标准在http://www.sitemaps.org/protocol.html中定义。
站点地图文件的内容
以下是https://www.microsoft.com/robots.txt的站点地图文件的内容,该文件在robot.txt文件中发现:
Sitemap: https://www.microsoft.com/en-us/explore/msft_sitemap_index.xml Sitemap: https://www.microsoft.com/learning/sitemap.xml Sitemap: https://www.microsoft.com/en-us/licensing/sitemap.xml Sitemap: https://www.microsoft.com/en-us/legal/sitemap.xml Sitemap: https://www.microsoft.com/filedata/sitemaps/RW5xN8 Sitemap: https://www.microsoft.com/store/collections.xml Sitemap: https://www.microsoft.com/store/productdetailpages.index.xml Sitemap: https://www.microsoft.com/en-us/store/locations/store-locationssitemap.xml
上述内容显示,站点地图列出了网站上的URL,并进一步允许网站管理员为每个URL指定一些其他信息,例如上次更新日期、内容更改、与其他URL相关的URL重要性等。
网站的大小是多少?
网站的大小,即网站的网页数量,是否会影响我们的爬取方式?当然会。因为如果我们要爬取的网页数量较少,那么效率不会是一个严重的问题,但是如果我们的网站有数百万个网页,例如Microsoft.com,那么按顺序下载每个网页将需要几个月的时间,那么效率将是一个严重的问题。
检查网站的大小
通过检查Google爬虫结果的大小,我们可以估计网站的大小。在进行Google搜索时,我们可以使用关键字site来过滤我们的结果。例如,下面给出了对https://authoraditiagarwal.com/大小的估计:
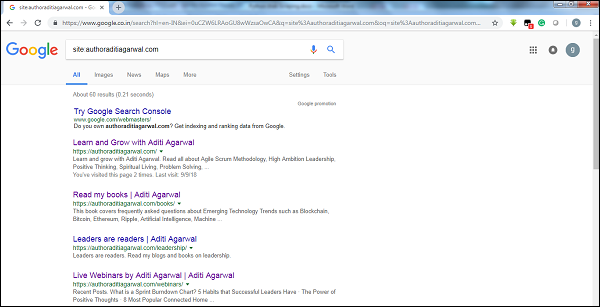
您可以看到大约有60个结果,这意味着它不是一个大型网站,爬取不会导致效率问题。
网站使用了什么技术?
另一个重要的问题是网站使用的技术是否会影响我们的爬取方式?是的,会影响。但是我们如何检查网站使用的技术呢?有一个名为builtwith的Python库,我们可以用它来找出网站使用的技术。
示例
在这个例子中,我们将使用Python库builtwith来检查网站https://authoraditiagarwal.com使用的技术。但在使用此库之前,我们需要安装它,方法如下:
(base) D:\ProgramData>pip install builtwith Collecting builtwith Downloading https://files.pythonhosted.org/packages/9b/b8/4a320be83bb3c9c1b3ac3f9469a5d66e0 2918e20d226aa97a3e86bddd130/builtwith-1.3.3.tar.gz Requirement already satisfied: six in d:\programdata\lib\site-packages (from builtwith) (1.10.0) Building wheels for collected packages: builtwith Running setup.py bdist_wheel for builtwith ... done Stored in directory: C:\Users\gaurav\AppData\Local\pip\Cache\wheels\2b\00\c2\a96241e7fe520e75093898b f926764a924873e0304f10b2524 Successfully built builtwith Installing collected packages: builtwith Successfully installed builtwith-1.3.3
现在,借助以下简单的几行代码,我们可以检查特定网站使用的技术:
In [1]: import builtwith
In [2]: builtwith.parse('http://authoraditiagarwal.com')
Out[2]:
{'blogs': ['PHP', 'WordPress'],
'cms': ['WordPress'],
'ecommerce': ['WooCommerce'],
'font-scripts': ['Font Awesome'],
'javascript-frameworks': ['jQuery'],
'programming-languages': ['PHP'],
'web-servers': ['Apache']}
网站的所有者是谁?
网站的所有者也很重要,因为如果所有者以阻止爬虫而闻名,那么爬虫在从网站爬取数据时必须小心。有一个名为Whois的协议,我们可以用它来找出网站的所有者。
示例
在这个例子中,我们将使用Whois来检查网站microsoft.com的所有者。但在使用此库之前,我们需要安装它,方法如下:
(base) D:\ProgramData>pip install python-whois Collecting python-whois Downloading https://files.pythonhosted.org/packages/63/8a/8ed58b8b28b6200ce1cdfe4e4f3bbc8b8 5a79eef2aa615ec2fef511b3d68/python-whois-0.7.0.tar.gz (82kB) 100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 92kB 164kB/s Requirement already satisfied: future in d:\programdata\lib\site-packages (from python-whois) (0.16.0) Building wheels for collected packages: python-whois Running setup.py bdist_wheel for python-whois ... done Stored in directory: C:\Users\gaurav\AppData\Local\pip\Cache\wheels\06\cb\7d\33704632b0e1bb64460dc2b 4dcc81ab212a3d5e52ab32dc531 Successfully built python-whois Installing collected packages: python-whois Successfully installed python-whois-0.7.0
现在,借助以下简单的几行代码,我们可以检查特定网站使用的技术:
In [1]: import whois
In [2]: print (whois.whois('microsoft.com'))
{
"domain_name": [
"MICROSOFT.COM",
"microsoft.com"
],
-------
"name_servers": [
"NS1.MSFT.NET",
"NS2.MSFT.NET",
"NS3.MSFT.NET",
"NS4.MSFT.NET",
"ns3.msft.net",
"ns1.msft.net",
"ns4.msft.net",
"ns2.msft.net"
],
"emails": [
"abusecomplaints@markmonitor.com",
"domains@microsoft.com",
"msnhst@microsoft.com",
"whoisrelay@markmonitor.com"
],
}