- Python 网络爬取教程
- Python 网络爬取 - 首页
- 介绍
- Python 入门
- 用于网络爬取的 Python 模块
- 网络爬取的合法性
- 数据提取
- 数据处理
- 处理图像和视频
- 处理文本
- 爬取动态网站
- 爬取基于表单的网站
- 处理验证码
- 使用爬虫进行测试
- Python 网络爬取资源
- Python 网络爬取 - 快速指南
- Python 网络爬取 - 资源
- Python 网络爬取 - 讨论
Python 网络爬取 - 快速指南
Python 网络爬取 - 介绍
网络爬取是从网络中自动提取信息的过程。本章将深入介绍网络爬取,将其与网络爬虫进行比较,并说明为什么要选择网络爬取。您还将了解网络爬虫的组件和工作原理。
什么是网络爬取?
“爬取”一词的字典含义是指从网络获取某些东西。这里出现两个问题:我们能从网络中获取什么以及如何获取。
第一个问题的答案是“数据”。数据对于任何程序员来说都是不可或缺的,每个编程项目的首要需求都是大量有用的数据。
第二个问题的答案有点棘手,因为获取数据的方法有很多。通常,我们可以从数据库或数据文件以及其他来源获取数据。但是,如果我们需要大量在线可用的数据呢?获取此类数据的一种方法是手动搜索(在网页浏览器中点击)并保存(复制粘贴到电子表格或文件中)所需数据。这种方法非常繁琐且耗时。另一种获取此类数据的方法是使用网络爬取。
网络爬取,也称为网络数据挖掘或网络采集,是构建一个能够自动提取、解析、下载和整理网络上有用信息的代理的过程。换句话说,我们可以说,与其手动从网站保存数据,不如让网络爬取软件根据我们的要求自动加载和提取来自多个网站的数据。
网络爬取的起源
网络爬取起源于屏幕抓取,用于集成非基于网络的应用程序或本机 Windows 应用程序。最初,屏幕抓取在万维网 (WWW) 广泛使用之前就被使用,但它无法扩展 WWW 的扩展。这使得自动化屏幕抓取方法成为必要,并出现了名为“网络爬取”的技术。
网络爬虫与网络爬取
术语“网络爬虫”和“网络爬取”通常可以互换使用,因为它们的根本概念都是提取数据。但是,它们彼此之间存在差异。我们可以从它们的定义中了解基本区别。
网络爬虫基本上用于使用机器人(即爬虫)索引页面上的信息。它也称为索引。另一方面,网络爬取是使用机器人(即爬虫)自动提取信息的一种方式。它也称为数据提取。
为了理解这两个术语之间的区别,让我们看一下下面给出的比较表:
| 网络爬虫 | 网络爬取 |
|---|---|
| 指下载和存储大量网站的内容。 | 指通过使用特定于站点的结构从网站提取单个数据元素。 |
| 主要在大规模进行。 | 可以在任何规模上实施。 |
| 产生通用信息。 | 产生特定信息。 |
| 由 Google、Bing、Yahoo 等主要搜索引擎使用。Googlebot 是网络爬虫的一个示例。 | 使用网络爬取提取的信息可以用于复制到其他网站,也可以用于执行数据分析。例如,数据元素可以是姓名、地址、价格等。 |
网络爬取的用途
使用网络爬取的用途和原因与万维网的用途一样多。网络爬虫可以执行任何操作,例如在线订购食物、为您扫描在线购物网站以及在门票可用时立即购买比赛门票等,就像人类可以做的那样。这里讨论了一些网络爬取的重要用途:
电子商务网站 - 网络爬虫可以从各种电子商务网站收集与特定产品价格相关的数据,以便进行比较。
内容聚合器 - 网络爬取被新闻聚合器和工作聚合器等内容聚合器广泛使用,以便为其用户提供更新的数据。
营销和销售活动 - 网络爬虫可以用于获取电子邮件、电话号码等数据,用于销售和营销活动。
搜索引擎优化 (SEO) - 网络爬取被 SEMRush、Majestic 等 SEO 工具广泛使用,以告知企业他们在对其重要的搜索关键词方面的排名。
机器学习项目的数据 - 机器学习项目的检索数据依赖于网络爬取。
研究数据 - 研究人员可以通过此自动化流程节省时间,收集对其研究工作有用的数据。
网络爬虫的组件
网络爬虫包括以下组件:
网络爬虫模块
网络爬虫模块是网络爬虫的一个非常必要的组件,用于通过向 URL 发出 HTTP 或 HTTPS 请求来导航目标网站。爬虫下载非结构化数据(HTML 内容)并将其传递给提取器,即下一个模块。
提取器
提取器处理获取的 HTML 内容并将数据提取为半结构化格式。这也被称为解析器模块,并使用不同的解析技术(如正则表达式、HTML 解析、DOM 解析或人工智能)来实现其功能。
数据转换和清理模块
上面提取的数据不适合直接使用。它必须通过一些清理模块,以便我们可以使用它。字符串操作或正则表达式等方法可用于此目的。请注意,提取和转换也可以在一个步骤中完成。
存储模块
提取数据后,我们需要根据我们的要求存储它。存储模块将以标准格式输出数据,该格式可以存储在数据库或 JSON 或 CSV 格式中。
网络爬虫的工作原理
网络爬虫可以定义为用于下载多个网页的内容并从中提取数据的软件或脚本。
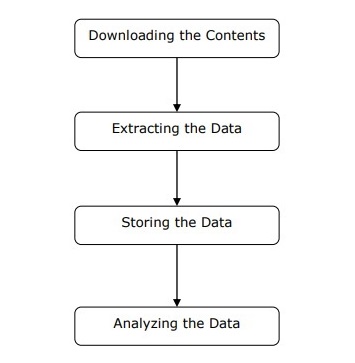
我们可以按照上面给出的图中所示的简单步骤来了解网络爬虫的工作原理。
步骤 1:从网页下载内容
在此步骤中,网络爬虫将从多个网页下载请求的内容。
步骤 2:提取数据
网站上的数据是 HTML,并且大部分是非结构化的。因此,在此步骤中,网络爬虫将解析并从下载的内容中提取结构化数据。
步骤 3:存储数据
在这里,网络爬虫将以 CSV、JSON 或数据库等任何格式存储和保存提取的数据。
步骤 4:分析数据
在所有这些步骤成功完成后,网络爬虫将分析获得的数据。
Python 入门
在第一章中,我们学习了网络爬取的基本知识。在本章中,让我们看看如何使用 Python 实现网络爬取。
为什么选择 Python 进行网络爬取?
Python 是实现网络爬取的常用工具。Python 编程语言还用于其他与网络安全、渗透测试以及数字取证应用程序相关的有用项目。使用 Python 的基础编程,可以在不使用任何其他第三方工具的情况下执行网络爬取。
Python 编程语言正在迅速普及,以下是一些使 Python 非常适合网络爬取项目的原因:
语法简单
与其他编程语言相比,Python 具有最简单的结构。Python 的这一特性使测试更容易,开发人员可以更加专注于编程。
内置模块
使用 Python 进行网络爬取的另一个原因是它拥有内置的和外部的有用库。我们可以使用 Python 作为编程基础来执行许多与网络爬取相关的实现。
开源编程语言
由于 Python 是一种开源编程语言,因此它得到了社区的大力支持。
广泛的应用范围
Python 可用于各种编程任务,从小型 shell 脚本到企业 Web 应用程序。
Python 的安装
Python 发行版适用于 Windows、MAC 和 Unix/Linux 等平台。我们只需要下载适用于我们平台的二进制代码即可安装 Python。但是,如果我们的平台没有可用的二进制代码,则我们必须拥有 C 编译器,以便手动编译源代码。
我们可以在各种平台上安装 Python,如下所示:
在 Unix 和 Linux 上安装 Python
您需要按照以下步骤在 Unix/Linux 机器上安装 Python:
步骤 1 - 转到链接 https://pythonlang.cn/downloads/
步骤 2 - 下载上面链接中提供的适用于 Unix/Linux 的压缩源代码。
步骤 3 - 将文件解压缩到您的计算机上。
步骤 4 - 使用以下命令完成安装:
run ./configure script make make install
您可以在标准位置/usr/local/bin找到已安装的 Python,并在/usr/local/lib/pythonXX找到其库,其中 XX 是 Python 的版本。
在 Windows 上安装 Python
您需要按照以下步骤在 Windows 机器上安装 Python:
步骤 1 - 转到链接 https://pythonlang.cn/downloads/
步骤 2 - 下载 Windows 安装程序python-XYZ.msi文件,其中 XYZ 是我们需要安装的版本。
步骤 3 - 现在,将安装程序文件保存到本地计算机并运行 MSI 文件。
步骤 4 - 最后,运行下载的文件以调出 Python 安装向导。
在 Macintosh 上安装 Python
我们必须使用Homebrew在 Mac OS X 上安装 Python 3。Homebrew 易于安装,是一个很棒的软件包安装程序。
也可以使用以下命令安装 Homebrew:
$ ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
要更新软件包管理器,我们可以使用以下命令:
$ brew update
借助以下命令,我们可以在 MAC 机器上安装 Python3:
$ brew install python3
设置 PATH
您可以使用以下说明在各种环境中设置路径:
在 Unix/Linux 上设置路径
使用以下命令使用各种命令 shell 设置路径:
对于 csh shell
setenv PATH "$PATH:/usr/local/bin/python".
对于 bash shell (Linux)
ATH="$PATH:/usr/local/bin/python".
对于 sh 或 ksh shell
PATH="$PATH:/usr/local/bin/python".
在 Windows 上设置路径
在Windows上设置路径,可以在命令提示符下使用路径%path%;C:\Python,然后按Enter键。
运行Python
我们可以通过以下三种方式之一启动Python:
交互式解释器
可以使用提供命令行解释器或shell的操作系统(如UNIX和DOS)来启动Python。
我们可以按照以下步骤在交互式解释器中开始编码:
步骤1 - 在命令行中输入python。
步骤2 - 然后,我们可以在交互式解释器中立即开始编码。
$python # Unix/Linux or python% # Unix/Linux or C:> python # Windows/DOS
从命令行运行脚本
我们可以通过调用解释器在命令行中执行Python脚本。可以理解为:
$python script.py # Unix/Linux or python% script.py # Unix/Linux or C: >python script.py # Windows/DOS
集成开发环境
如果系统具有支持Python的GUI应用程序,我们也可以从GUI环境中运行Python。以下是一些在各种平台上支持Python的IDE:
UNIX的IDE - UNIX的Python IDE是IDLE。
Windows的IDE - Windows的Python IDE是PythonWin,它也具有GUI。
Macintosh的IDE - Macintosh的Python IDE是IDLE,可以从主网站下载MacBinary或BinHex'd文件。
用于网络爬取的 Python 模块
在本章中,让我们学习各种可用于网页抓取的Python模块。
使用virtualenv的Python开发环境
Virtualenv是一个创建隔离的Python环境的工具。借助virtualenv,我们可以创建一个包含所有必要可执行文件的文件夹,以使用Python项目所需的包。它还允许我们添加和修改Python模块,而无需访问全局安装。
可以使用以下命令安装virtualenv:
(base) D:\ProgramData>pip install virtualenv Collecting virtualenv Downloading https://files.pythonhosted.org/packages/b6/30/96a02b2287098b23b875bc8c2f58071c3 5d2efe84f747b64d523721dc2b5/virtualenv-16.0.0-py2.py3-none-any.whl (1.9MB) 100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 1.9MB 86kB/s Installing collected packages: virtualenv Successfully installed virtualenv-16.0.0
现在,我们需要使用以下命令创建一个目录,该目录将代表项目:
(base) D:\ProgramData>mkdir webscrap
现在,使用以下命令进入该目录:
(base) D:\ProgramData>cd webscrap
现在,我们需要按照以下方式初始化我们选择的虚拟环境文件夹:
(base) D:\ProgramData\webscrap>virtualenv websc Using base prefix 'd:\\programdata' New python executable in D:\ProgramData\webscrap\websc\Scripts\python.exe Installing setuptools, pip, wheel...done.
现在,使用以下命令激活虚拟环境。激活成功后,您将在左侧括号中看到其名称。
(base) D:\ProgramData\webscrap>websc\scripts\activate
我们可以按照以下方式在此环境中安装任何模块:
(websc) (base) D:\ProgramData\webscrap>pip install requests Collecting requests Downloading https://files.pythonhosted.org/packages/65/47/7e02164a2a3db50ed6d8a6ab1d6d60b69 c4c3fdf57a284257925dfc12bda/requests-2.19.1-py2.py3-none-any.whl (9 1kB) 100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 92kB 148kB/s Collecting chardet<3.1.0,>=3.0.2 (from requests) Downloading https://files.pythonhosted.org/packages/bc/a9/01ffebfb562e4274b6487b4bb1ddec7ca 55ec7510b22e4c51f14098443b8/chardet-3.0.4-py2.py3-none-any.whl (133 kB) 100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 143kB 369kB/s Collecting certifi>=2017.4.17 (from requests) Downloading https://files.pythonhosted.org/packages/df/f7/04fee6ac349e915b82171f8e23cee6364 4d83663b34c539f7a09aed18f9e/certifi-2018.8.24-py2.py3-none-any.whl (147kB) 100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 153kB 527kB/s Collecting urllib3<1.24,>=1.21.1 (from requests) Downloading https://files.pythonhosted.org/packages/bd/c9/6fdd990019071a4a32a5e7cb78a1d92c5 3851ef4f56f62a3486e6a7d8ffb/urllib3-1.23-py2.py3-none-any.whl (133k B) 100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 143kB 517kB/s Collecting idna<2.8,>=2.5 (from requests) Downloading https://files.pythonhosted.org/packages/4b/2a/0276479a4b3caeb8a8c1af2f8e4355746 a97fab05a372e4a2c6a6b876165/idna-2.7-py2.py3-none-any.whl (58kB) 100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 61kB 339kB/s Installing collected packages: chardet, certifi, urllib3, idna, requests Successfully installed certifi-2018.8.24 chardet-3.0.4 idna-2.7 requests-2.19.1 urllib3-1.23
要停用虚拟环境,可以使用以下命令:
(websc) (base) D:\ProgramData\webscrap>deactivate (base) D:\ProgramData\webscrap>
您可以看到(websc)已停用。
用于网络爬取的 Python 模块
网页抓取是构建一个代理的过程,该代理可以自动从网络中提取、解析、下载和组织有用的信息。换句话说,网页抓取软件会根据我们的需求自动加载和提取来自多个网站的数据,而不是手动从网站保存数据。
在本节中,我们将讨论一些有用的Python库,用于网页抓取。
Requests
这是一个简单的Python网页抓取库。它是一个高效的HTTP库,用于访问网页。借助Requests,我们可以获取网页的原始HTML,然后对其进行解析以检索数据。在使用requests之前,让我们了解其安装。
安装Requests
我们可以将其安装在虚拟环境或全局安装中。借助pip命令,我们可以轻松地按如下方式安装它:
(base) D:\ProgramData> pip install requests Collecting requests Using cached https://files.pythonhosted.org/packages/65/47/7e02164a2a3db50ed6d8a6ab1d6d60b69 c4c3fdf57a284257925dfc12bda/requests-2.19.1-py2.py3-none-any.whl Requirement already satisfied: idna<2.8,>=2.5 in d:\programdata\lib\sitepackages (from requests) (2.6) Requirement already satisfied: urllib3<1.24,>=1.21.1 in d:\programdata\lib\site-packages (from requests) (1.22) Requirement already satisfied: certifi>=2017.4.17 in d:\programdata\lib\sitepackages (from requests) (2018.1.18) Requirement already satisfied: chardet<3.1.0,>=3.0.2 in d:\programdata\lib\site-packages (from requests) (3.0.4) Installing collected packages: requests Successfully installed requests-2.19.1
示例
在此示例中,我们正在对网页发出GET HTTP请求。为此,我们需要首先导入requests库,如下所示:
In [1]: import requests
在以下代码行中,我们使用requests对URL:https://authoraditiagarwal.com/ 发出GET HTTP请求。
In [2]: r = requests.get('https://authoraditiagarwal.com/')
现在,我们可以使用.text属性检索内容,如下所示:
In [5]: r.text[:200]
请注意,在以下输出中,我们获得了前200个字符。
Out[5]: '<!DOCTYPE html>\n<html lang="en-US"\n\titemscope \n\titemtype="http://schema.org/WebSite" \n\tprefix="og: http://ogp.me/ns#" >\n<head>\n\t<meta charset ="UTF-8" />\n\t<meta http-equiv="X-UA-Compatible" content="IE'
Urllib3
它是另一个Python库,可用于从URL检索数据,类似于requests库。您可以在其技术文档https://urllib3.readthedocs.io/en/latest/中了解更多信息。
安装Urllib3
使用pip命令,我们可以将urllib3安装到虚拟环境或全局安装中。
(base) D:\ProgramData>pip install urllib3 Collecting urllib3 Using cached https://files.pythonhosted.org/packages/bd/c9/6fdd990019071a4a32a5e7cb78a1d92c5 3851ef4f56f62a3486e6a7d8ffb/urllib3-1.23-py2.py3-none-any.whl Installing collected packages: urllib3 Successfully installed urllib3-1.23
示例:使用Urllib3和BeautifulSoup进行抓取
在以下示例中,我们使用Urllib3和BeautifulSoup来抓取网页。我们使用Urllib3代替requests库从网页获取原始数据(HTML)。然后,我们使用BeautifulSoup解析该HTML数据。
import urllib3
from bs4 import BeautifulSoup
http = urllib3.PoolManager()
r = http.request('GET', 'https://authoraditiagarwal.com')
soup = BeautifulSoup(r.data, 'lxml')
print (soup.title)
print (soup.title.text)
这是运行此代码时将观察到的输出:
<title>Learn and Grow with Aditi Agarwal</title> Learn and Grow with Aditi Agarwal
Selenium
它是一个开源的Web应用程序自动化测试套件,适用于不同的浏览器和平台。它不是单个工具,而是一套软件。我们有适用于Python、Java、C#、Ruby和JavaScript的Selenium绑定。在这里,我们将使用selenium及其Python绑定执行网页抓取。您可以在链接Selenium上了解有关Selenium与Java的更多信息。
Selenium Python绑定提供了一个方便的API来访问Selenium WebDrivers,如Firefox、IE、Chrome、Remote等。当前支持的Python版本为2.7、3.5及以上。
安装Selenium
使用pip命令,我们可以将urllib3安装到虚拟环境或全局安装中。
pip install selenium
由于selenium需要一个驱动程序来与所选浏览器交互,因此我们需要下载它。下表显示了不同的浏览器及其下载链接。
Chrome |
|
Edge |
|
Firefox |
|
Safari |
示例
此示例演示了使用selenium进行网页抓取。它也可用于测试,称为selenium测试。
下载特定浏览器指定版本的驱动程序后,我们需要用Python进行编程。
首先,需要从selenium导入webdriver,如下所示:
from selenium import webdriver
现在,提供我们根据需要下载的Web驱动程序的路径:
path = r'C:\\Users\\gaurav\\Desktop\\Chromedriver' browser = webdriver.Chrome(executable_path = path)
现在,提供我们希望在现在由Python脚本控制的Web浏览器中打开的URL。
browser.get('https://authoraditiagarwal.com/leadershipmanagement')
我们还可以通过提供lxml中提供的xpath来抓取特定元素。
browser.find_element_by_xpath('/html/body').click()
您可以检查由Python脚本控制的浏览器以获取输出。
Scrapy
Scrapy是一个用Python编写的快速、开源的Web爬取框架,用于借助基于XPath的选择器从网页中提取数据。Scrapy于2008年6月26日首次发布,根据BSD许可,并在2015年6月发布了1.0里程碑版本。它为我们提供了从网站提取、处理和构建数据所需的所有工具。
安装Scrapy
使用pip命令,我们可以将urllib3安装到虚拟环境或全局安装中。
pip install scrapy
有关Scrapy的更多详细研究,您可以访问链接Scrapy
网络爬取的合法性
使用Python,我们可以抓取任何网站或网页的特定元素,但您是否知道这是否合法?在抓取任何网站之前,我们必须了解网页抓取的合法性。本章将解释与网页抓取的合法性相关的概念。
介绍
通常,如果您要将抓取的数据用于个人用途,则可能不会有任何问题。但是,如果您要重新发布该数据,则在执行此操作之前,应向所有者发出下载请求或对相关政策以及您要抓取的数据进行一些背景调查。
抓取前所需的调查
如果您要针对某个网站进行数据抓取,我们需要了解其规模和结构。以下是在开始网页抓取之前需要分析的一些文件。
分析robots.txt
实际上,大多数发布者允许程序员在一定程度上抓取其网站。换句话说,发布者希望抓取网站的特定部分。为了定义这一点,网站必须制定一些规则来说明哪些部分可以抓取,哪些部分不能抓取。此类规则定义在一个名为robots.txt的文件中。
robots.txt是一个人类可读的文件,用于识别爬虫允许和不允许抓取的网站部分。robots.txt文件没有标准格式,网站发布者可以根据需要进行修改。我们可以通过在网站URL后提供斜杠和robots.txt来检查特定网站的robots.txt文件。例如,如果要检查Google.com,则需要键入https://www.google.com/robots.txt,我们将获得如下内容:
User-agent: * Disallow: /search Allow: /search/about Allow: /search/static Allow: /search/howsearchworks Disallow: /sdch Disallow: /groups Disallow: /index.html? Disallow: /? Allow: /?hl= Disallow: /?hl=*& Allow: /?hl=*&gws_rd=ssl$ and so on……..
网站robots.txt文件中定义的一些最常见的规则如下:
User-agent: BadCrawler Disallow: /
以上规则表示robots.txt文件要求具有BadCrawler用户代理的爬虫不要抓取其网站。
User-agent: * Crawl-delay: 5 Disallow: /trap
以上规则表示robots.txt文件将所有用户代理的下载请求之间的延迟设置为5秒,以避免服务器过载。/trap链接将尝试阻止遵循禁止链接的恶意爬虫。发布者可以根据其需求定义更多规则。其中一些在此处讨论:
分析Sitemap文件
如果您想抓取网站以获取更新的信息,应该怎么做?您将抓取每个网页以获取该更新的信息,但这会增加特定网站的服务器流量。这就是为什么网站提供sitemap文件以帮助爬虫定位更新内容,而无需抓取每个网页。Sitemap标准定义在http://www.sitemaps.org/protocol.html。
Sitemap文件的内容
以下是https://www.microsoft.com/robots.txt的sitemap文件的内容,该文件是在robot.txt文件中发现的:
Sitemap: https://www.microsoft.com/en-us/explore/msft_sitemap_index.xml Sitemap: https://www.microsoft.com/learning/sitemap.xml Sitemap: https://www.microsoft.com/en-us/licensing/sitemap.xml Sitemap: https://www.microsoft.com/en-us/legal/sitemap.xml Sitemap: https://www.microsoft.com/filedata/sitemaps/RW5xN8 Sitemap: https://www.microsoft.com/store/collections.xml Sitemap: https://www.microsoft.com/store/productdetailpages.index.xml Sitemap: https://www.microsoft.com/en-us/store/locations/store-locationssitemap.xml
以上内容表明sitemap列出了网站上的URL,并进一步允许网站管理员为每个URL指定一些其他信息,例如上次更新日期、内容更改、与其他URL相关的URL重要性等。
网站的大小是多少?
网站的大小(即网站的网页数量)是否会影响我们的抓取方式?当然是的。因为如果我们要抓取的网页数量较少,那么效率不会成为严重问题,但假设我们的网站有数百万个网页,例如Microsoft.com,那么按顺序下载每个网页将需要几个月的时间,然后效率就会成为严重问题。
检查网站的大小
通过检查Google爬虫结果的大小,我们可以估计网站的大小。在进行Google搜索时,可以使用关键字site过滤我们的结果。例如,下面给出了估计https://authoraditiagarwal.com/大小的方法:
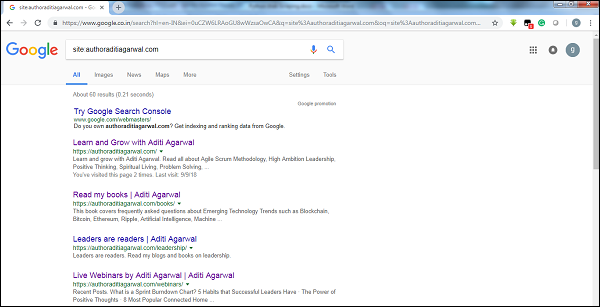
您可以看到大约有60个结果,这意味着它不是一个大型网站,抓取不会导致效率问题。
网站使用什么技术?
另一个重要的问题是,网站使用的技术是否会影响我们的爬取方式?答案是会的。但是我们如何检查网站使用的技术呢?有一个名为builtwith的Python库可以帮助我们找出网站使用的技术。
示例
在这个例子中,我们将使用Python库builtwith来检查网站https://authoraditiagarwal.com使用的技术。但在使用此库之前,我们需要按照以下步骤安装它:
(base) D:\ProgramData>pip install builtwith Collecting builtwith Downloading https://files.pythonhosted.org/packages/9b/b8/4a320be83bb3c9c1b3ac3f9469a5d66e0 2918e20d226aa97a3e86bddd130/builtwith-1.3.3.tar.gz Requirement already satisfied: six in d:\programdata\lib\site-packages (from builtwith) (1.10.0) Building wheels for collected packages: builtwith Running setup.py bdist_wheel for builtwith ... done Stored in directory: C:\Users\gaurav\AppData\Local\pip\Cache\wheels\2b\00\c2\a96241e7fe520e75093898b f926764a924873e0304f10b2524 Successfully built builtwith Installing collected packages: builtwith Successfully installed builtwith-1.3.3
现在,借助以下几行简单的代码,我们可以检查特定网站使用的技术:
In [1]: import builtwith
In [2]: builtwith.parse('http://authoraditiagarwal.com')
Out[2]:
{'blogs': ['PHP', 'WordPress'],
'cms': ['WordPress'],
'ecommerce': ['WooCommerce'],
'font-scripts': ['Font Awesome'],
'javascript-frameworks': ['jQuery'],
'programming-languages': ['PHP'],
'web-servers': ['Apache']}
网站的所有者是谁?
网站的所有者也很重要,因为如果所有者以阻止爬虫而闻名,那么爬虫在从网站抓取数据时必须小心。有一个名为Whois的协议可以帮助我们找到网站的所有者。
示例
在这个例子中,我们将使用Whois来检查网站microsoft.com的所有者。但在使用此库之前,我们需要按照以下步骤安装它:
(base) D:\ProgramData>pip install python-whois Collecting python-whois Downloading https://files.pythonhosted.org/packages/63/8a/8ed58b8b28b6200ce1cdfe4e4f3bbc8b8 5a79eef2aa615ec2fef511b3d68/python-whois-0.7.0.tar.gz (82kB) 100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 92kB 164kB/s Requirement already satisfied: future in d:\programdata\lib\site-packages (from python-whois) (0.16.0) Building wheels for collected packages: python-whois Running setup.py bdist_wheel for python-whois ... done Stored in directory: C:\Users\gaurav\AppData\Local\pip\Cache\wheels\06\cb\7d\33704632b0e1bb64460dc2b 4dcc81ab212a3d5e52ab32dc531 Successfully built python-whois Installing collected packages: python-whois Successfully installed python-whois-0.7.0
现在,借助以下几行简单的代码,我们可以检查特定网站使用的技术:
In [1]: import whois
In [2]: print (whois.whois('microsoft.com'))
{
"domain_name": [
"MICROSOFT.COM",
"microsoft.com"
],
-------
"name_servers": [
"NS1.MSFT.NET",
"NS2.MSFT.NET",
"NS3.MSFT.NET",
"NS4.MSFT.NET",
"ns3.msft.net",
"ns1.msft.net",
"ns4.msft.net",
"ns2.msft.net"
],
"emails": [
"abusecomplaints@markmonitor.com",
"domains@microsoft.com",
"msnhst@microsoft.com",
"whoisrelay@markmonitor.com"
],
}
Python网页抓取 - 数据提取
分析网页意味着理解其结构。现在,问题出现了,为什么这对网页抓取很重要?在本章中,让我们详细了解一下。
网页分析
网页分析很重要,因为如果不进行分析,我们就无法知道在提取后,我们将以何种形式(结构化或非结构化)从该网页接收数据。我们可以通过以下方式进行网页分析:
查看页面源代码
这是一种通过检查页面源代码来了解网页结构的方式。要实现这一点,我们需要右键单击页面,然后选择“查看页面源代码”选项。然后,我们将以HTML的形式从该网页获取我们感兴趣的数据。但主要问题是关于空格和格式,这对于我们来说很难格式化。
通过单击“检查元素”选项检查页面源代码
这是另一种分析网页的方式。但不同之处在于,它将解决网页源代码中格式和空格的问题。您可以通过右键单击,然后从菜单中选择“检查”或“检查元素”选项来实现此功能。它将提供有关该网页特定区域或元素的信息。
从网页提取数据的不同方法
以下方法主要用于从网页提取数据:
正则表达式
它们是嵌入在Python中的高度专业化的编程语言。我们可以通过Python的re模块使用它。它也称为RE、regexes或regex模式。借助正则表达式,我们可以为我们想要从数据中匹配的可能的字符串集指定一些规则。
如果您想更全面地了解正则表达式,请访问链接https://tutorialspoint.com/automata_theory/regular_expressions.htm,如果您想了解更多关于re模块或Python中正则表达式的知识,您可以访问链接https://tutorialspoint.com/python/python_reg_expressions.htm。
示例
在下面的示例中,我们将使用正则表达式匹配<td>的内容,从http://example.webscraping.com 抓取有关印度的数据。
import re
import urllib.request
response =
urllib.request.urlopen('http://example.webscraping.com/places/default/view/India-102')
html = response.read()
text = html.decode()
re.findall('<td class="w2p_fw">(.*?)</td>',text)
输出
相应的输出将如下所示:
[
'<img src="/places/static/images/flags/in.png" />',
'3,287,590 square kilometres',
'1,173,108,018',
'IN',
'India',
'New Delhi',
'<a href="/places/default/continent/AS">AS</a>',
'.in',
'INR',
'Rupee',
'91',
'######',
'^(\\d{6})$',
'enIN,hi,bn,te,mr,ta,ur,gu,kn,ml,or,pa,as,bh,sat,ks,ne,sd,kok,doi,mni,sit,sa,fr,lus,inc',
'<div>
<a href="/places/default/iso/CN">CN </a>
<a href="/places/default/iso/NP">NP </a>
<a href="/places/default/iso/MM">MM </a>
<a href="/places/default/iso/BT">BT </a>
<a href="/places/default/iso/PK">PK </a>
<a href="/places/default/iso/BD">BD </a>
</div>'
]
观察上面输出,您可以看到使用正则表达式获取的关于印度国家的信息。
Beautiful Soup
假设我们想从网页中收集所有超链接,那么我们可以使用一个名为BeautifulSoup的解析器,可以在https://www.crummy.com/software/BeautifulSoup/bs4/doc/.中详细了解。简单来说,BeautifulSoup是一个用于从HTML和XML文件中提取数据的Python库。它可以与requests一起使用,因为它需要一个输入(文档或URL)来创建soup对象,因为它本身无法获取网页。您可以使用以下Python脚本收集网页标题和超链接。
安装Beautiful Soup
使用pip命令,我们可以在虚拟环境或全局安装中安装beautifulsoup。
(base) D:\ProgramData>pip install bs4 Collecting bs4 Downloading https://files.pythonhosted.org/packages/10/ed/7e8b97591f6f456174139ec089c769f89 a94a1a4025fe967691de971f314/bs4-0.0.1.tar.gz Requirement already satisfied: beautifulsoup4 in d:\programdata\lib\sitepackages (from bs4) (4.6.0) Building wheels for collected packages: bs4 Running setup.py bdist_wheel for bs4 ... done Stored in directory: C:\Users\gaurav\AppData\Local\pip\Cache\wheels\a0\b0\b2\4f80b9456b87abedbc0bf2d 52235414c3467d8889be38dd472 Successfully built bs4 Installing collected packages: bs4 Successfully installed bs4-0.0.1
示例
请注意,在这个例子中,我们扩展了之前用requests python模块实现的例子。我们使用r.text来创建一个soup对象,该对象将进一步用于获取网页标题等详细信息。
首先,我们需要导入必要的Python模块:
import requests from bs4 import BeautifulSoup
在以下代码行中,我们使用requests对URL:https://authoraditiagarwal.com/发出GET HTTP请求。
r = requests.get('https://authoraditiagarwal.com/')
现在我们需要创建一个Soup对象,如下所示:
soup = BeautifulSoup(r.text, 'lxml') print (soup.title) print (soup.title.text)
输出
相应的输出将如下所示:
<title>Learn and Grow with Aditi Agarwal</title> Learn and Grow with Aditi Agarwal
Lxml
我们将要讨论的另一个用于网页抓取的Python库是lxml。它是一个高性能的HTML和XML解析库。它相对快速且简单。您可以在https://lxml.de/上了解更多信息。
安装lxml
使用pip命令,我们可以在虚拟环境或全局安装中安装lxml。
(base) D:\ProgramData>pip install lxml Collecting lxml Downloading https://files.pythonhosted.org/packages/b9/55/bcc78c70e8ba30f51b5495eb0e 3e949aa06e4a2de55b3de53dc9fa9653fa/lxml-4.2.5-cp36-cp36m-win_amd64.whl (3. 6MB) 100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 3.6MB 64kB/s Installing collected packages: lxml Successfully installed lxml-4.2.5
示例:使用lxml和requests提取数据
在以下示例中,我们使用lxml和requests从authoraditiagarwal.com抓取网页的特定元素:
首先,我们需要导入requests和来自lxml库的html,如下所示:
import requests from lxml import html
现在我们需要提供要抓取的网页的URL
url = https://authoraditiagarwal.com/leadershipmanagement/
现在我们需要提供到该网页特定元素的路径(Xpath):
path = '//*[@id="panel-836-0-0-1"]/div/div/p[1]' response = requests.get(url) byte_string = response.content source_code = html.fromstring(byte_string) tree = source_code.xpath(path) print(tree[0].text_content())
输出
相应的输出将如下所示:
The Sprint Burndown or the Iteration Burndown chart is a powerful tool to communicate daily progress to the stakeholders. It tracks the completion of work for a given sprint or an iteration. The horizontal axis represents the days within a Sprint. The vertical axis represents the hours remaining to complete the committed work.
Python网页抓取 - 数据处理
在前面的章节中,我们学习了如何使用各种Python模块从网页或网页抓取数据。在本章中,让我们深入了解处理已抓取数据的各种技术。
介绍
要处理已抓取的数据,我们必须以特定的格式(如电子表格(CSV)、JSON或有时是像MySQL这样的数据库)将数据存储在本地机器上。
CSV和JSON数据处理
首先,我们将从网页抓取的信息写入CSV文件或电子表格。让我们首先通过一个简单的示例来理解,在这个示例中,我们将首先使用BeautifulSoup模块(如前所述)抓取信息,然后使用Python CSV模块将文本信息写入CSV文件。
首先,我们需要导入必要的Python库,如下所示:
import requests from bs4 import BeautifulSoup import csv
在以下代码行中,我们使用requests对URL:https://authoraditiagarwal.com/ 发出GET HTTP请求。
r = requests.get('https://authoraditiagarwal.com/')
现在,我们需要创建一个Soup对象,如下所示:
soup = BeautifulSoup(r.text, 'lxml')
现在,借助以下几行代码,我们将抓取的数据写入名为dataprocessing.csv的CSV文件。
f = csv.writer(open(' dataprocessing.csv ','w'))
f.writerow(['Title'])
f.writerow([soup.title.text])
运行此脚本后,网页的文本信息或标题将保存在您本地机器上上述CSV文件中。
类似地,我们可以将收集到的信息保存在JSON文件中。以下是易于理解的Python脚本,用于执行相同的操作,其中我们将抓取与上一个Python脚本中相同的信息,但这次抓取的信息使用JSON Python模块保存在JSONfile.txt中。
import requests
from bs4 import BeautifulSoup
import csv
import json
r = requests.get('https://authoraditiagarwal.com/')
soup = BeautifulSoup(r.text, 'lxml')
y = json.dumps(soup.title.text)
with open('JSONFile.txt', 'wt') as outfile:
json.dump(y, outfile)
运行此脚本后,抓取的信息(即网页标题)将保存在您本地机器上上述文本文件中。
使用AWS S3进行数据处理
有时我们可能希望将抓取的数据保存在本地存储中以供存档。但是,如果我们需要大规模存储和分析这些数据怎么办?答案是名为Amazon S3或AWS S3(简单存储服务)的云存储服务。基本上,AWS S3是一个对象存储,旨在从任何地方存储和检索任意数量的数据。
我们可以按照以下步骤将数据存储在AWS S3中:
步骤1 - 首先,我们需要一个AWS账户,它将为我们在Python脚本中存储数据时提供密钥。它将在其中我们可以存储数据的S3存储桶中创建。
步骤2 - 接下来,我们需要安装boto3 Python库来访问S3存储桶。可以使用以下命令安装:
pip install boto3
步骤3 - 接下来,我们可以使用以下Python脚本从网页抓取数据并将其保存到AWS S3存储桶中。
首先,我们需要导入用于抓取的Python库,这里我们使用requests,以及boto3将数据保存到S3存储桶中。
import requests import boto3
现在我们可以从我们的URL抓取数据。
data = requests.get("Enter the URL").text
现在为了将数据存储到S3存储桶,我们需要创建S3客户端,如下所示:
s3 = boto3.client('s3')
bucket_name = "our-content"
下一行代码将创建S3存储桶,如下所示:
s3.create_bucket(Bucket = bucket_name, ACL = 'public-read') s3.put_object(Bucket = bucket_name, Key = '', Body = data, ACL = "public-read")
现在您可以从您的AWS账户中检查名为our-content的存储桶。
使用MySQL进行数据处理
让我们学习如何使用MySQL处理数据。如果您想了解MySQL,可以访问链接https://tutorialspoint.com/mysql/.
借助以下步骤,我们可以将抓取的数据处理到MySQL表中:
步骤1 - 首先,使用MySQL我们需要创建一个数据库和一个表,我们希望将抓取的数据保存到其中。例如,我们使用以下查询创建表:
CREATE TABLE Scrap_pages (id BIGINT(7) NOT NULL AUTO_INCREMENT, title VARCHAR(200), content VARCHAR(10000),PRIMARY KEY(id));
步骤2 - 接下来,我们需要处理Unicode。请注意,MySQL默认不处理Unicode。我们需要使用以下命令打开此功能,这将更改数据库、表和两个列的默认字符集:
ALTER DATABASE scrap CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci; ALTER TABLE Scrap_pages CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci; ALTER TABLE Scrap_pages CHANGE title title VARCHAR(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci; ALTER TABLE pages CHANGE content content VARCHAR(10000) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
步骤3 - 现在,将MySQL与Python集成。为此,我们需要PyMySQL,它可以使用以下命令安装
pip install PyMySQL
步骤4 - 现在,我们之前创建的名为Scrap的数据库已准备好保存从网页抓取的数据,并将数据保存到名为Scrap_pages的表中。在我们的示例中,我们将从维基百科抓取数据,并将数据保存到我们的数据库中。
首先,我们需要导入所需的Python模块。
from urllib.request import urlopen from bs4 import BeautifulSoup import datetime import random import pymysql import re
现在,建立连接,也就是将其与Python集成。
conn = pymysql.connect(host='127.0.0.1',user='root', passwd = None, db = 'mysql',
charset = 'utf8')
cur = conn.cursor()
cur.execute("USE scrap")
random.seed(datetime.datetime.now())
def store(title, content):
cur.execute('INSERT INTO scrap_pages (title, content) VALUES ''("%s","%s")', (title, content))
cur.connection.commit()
现在,连接到维基百科并获取数据。
def getLinks(articleUrl):
html = urlopen('http://en.wikipedia.org'+articleUrl)
bs = BeautifulSoup(html, 'html.parser')
title = bs.find('h1').get_text()
content = bs.find('div', {'id':'mw-content-text'}).find('p').get_text()
store(title, content)
return bs.find('div', {'id':'bodyContent'}).findAll('a',href=re.compile('^(/wiki/)((?!:).)*$'))
links = getLinks('/wiki/Kevin_Bacon')
try:
while len(links) > 0:
newArticle = links[random.randint(0, len(links)-1)].attrs['href']
print(newArticle)
links = getLinks(newArticle)
最后,我们需要关闭游标和连接。
finally: cur.close() conn.close()
这将把从维基百科收集到的数据保存到名为scrap_pages的表中。如果您熟悉MySQL和网页抓取,那么上述代码不难理解。
使用PostgreSQL进行数据处理
PostgreSQL 由全球志愿者团队开发,是一个开源的关系型数据库管理系统 (RDMS)。使用 PostgreSQL 处理抓取数据的过程类似于 MySQL。会有两个变化:首先,命令与 MySQL 不同;其次,这里我们将使用psycopg2 Python 库来执行它与 Python 的集成。
如果您不熟悉 PostgreSQL,可以在 https://tutorialspoint.com/postgresql/. 学习。并且可以通过以下命令安装 psycopg2 Python 库:
pip install psycopg2
处理图像和视频
网页抓取通常涉及下载、存储和处理网页媒体内容。在本章中,让我们了解如何处理从网络下载的内容。
介绍
我们在抓取过程中获得的网页媒体内容可以是图像、音频和视频文件,也可以是非网页页面以及数据文件。但是,我们能否信任下载的数据,特别是我们打算下载并存储在计算机内存中的数据扩展名?这使得了解我们要本地存储的数据类型变得至关重要。
从网页获取媒体内容
在本节中,我们将学习如何下载媒体内容,这些内容根据 Web 服务器的信息正确表示媒体类型。我们可以借助 Python 的requests模块来实现,就像我们在上一章中所做的那样。
首先,我们需要导入必要的 Python 模块,如下所示:
import requests
现在,提供我们要下载并本地存储的媒体内容的 URL。
url = "https://authoraditiagarwal.com/wpcontent/uploads/2018/05/MetaSlider_ThinkBig-1080x180.jpg"
使用以下代码创建 HTTP 响应对象。
r = requests.get(url)
借助以下代码行,我们可以将接收到的内容保存为 .png 文件。
with open("ThinkBig.png",'wb') as f:
f.write(r.content)
运行上述 Python 脚本后,我们将获得一个名为 ThinkBig.png 的文件,其中包含下载的图像。
从 URL 中提取文件名
从网站下载内容后,我们还想将其保存在一个文件中,文件名在 URL 中找到。但我们也可以检查 URL 中是否存在多个额外片段。为此,我们需要从 URL 中找到实际的文件名。
借助以下 Python 脚本,使用urlparse,我们可以从 URL 中提取文件名:
import urllib3 import os url = "https://authoraditiagarwal.com/wpcontent/uploads/2018/05/MetaSlider_ThinkBig-1080x180.jpg" a = urlparse(url) a.path
您可以观察到如下所示的输出:
'/wp-content/uploads/2018/05/MetaSlider_ThinkBig-1080x180.jpg' os.path.basename(a.path)
您可以观察到如下所示的输出:
'MetaSlider_ThinkBig-1080x180.jpg'
运行上述脚本后,我们将从 URL 中获取文件名。
关于 URL 内容类型的信息
在通过 GET 请求从 Web 服务器提取内容时,我们还可以检查 Web 服务器提供的信息。借助以下 Python 脚本,我们可以确定 Web 服务器对内容类型的含义:
首先,我们需要导入必要的 Python 模块,如下所示:
import requests
现在,我们需要提供我们要下载并本地存储的媒体内容的 URL。
url = "https://authoraditiagarwal.com/wpcontent/uploads/2018/05/MetaSlider_ThinkBig-1080x180.jpg"
以下代码行将创建 HTTP 响应对象。
r = requests.get(url, allow_redirects=True)
现在,我们可以获取 Web 服务器可以提供的关于内容的哪种类型的信息。
for headers in r.headers: print(headers)
您可以观察到如下所示的输出:
Date Server Upgrade Connection Last-Modified Accept-Ranges Content-Length Keep-Alive Content-Type
借助以下代码行,我们可以获取关于内容类型的特定信息,例如 content-type:
print (r.headers.get('content-type'))
您可以观察到如下所示的输出:
image/jpeg
借助以下代码行,我们可以获取关于内容类型的特定信息,例如 EType:
print (r.headers.get('ETag'))
您可以观察到如下所示的输出:
None
观察以下命令:
print (r.headers.get('content-length'))
您可以观察到如下所示的输出:
12636
借助以下代码行,我们可以获取关于内容类型的特定信息,例如 Server:
print (r.headers.get('Server'))
您可以观察到如下所示的输出:
Apache
为图像生成缩略图
缩略图是一个非常小的描述或表示。用户可能只想保存大型图像的缩略图,或者同时保存图像和缩略图。在本节中,我们将为名为ThinkBig.png的图像创建缩略图,该图像在上一节“从网页获取媒体内容”中下载。
对于此 Python 脚本,我们需要安装名为 Pillow 的 Python 库,它是 Python 图像库的一个分支,具有用于处理图像的有用功能。它可以通过以下命令安装:
pip install pillow
以下 Python 脚本将创建图像的缩略图,并将其保存到当前目录,并在缩略图文件名前添加Th_前缀。
import glob
from PIL import Image
for infile in glob.glob("ThinkBig.png"):
img = Image.open(infile)
img.thumbnail((128, 128), Image.ANTIALIAS)
if infile[0:2] != "Th_":
img.save("Th_" + infile, "png")
以上代码非常易于理解,您可以在当前目录中检查缩略图文件。
网站截图
在网页抓取中,一个非常常见的任务是截取网站的屏幕截图。为了实现这一点,我们将使用 selenium 和 webdriver。以下 Python 脚本将截取网站的屏幕截图,并将其保存到当前目录。
From selenium import webdriver
path = r'C:\\Users\\gaurav\\Desktop\\Chromedriver'
browser = webdriver.Chrome(executable_path = path)
browser.get('https://tutorialspoint.com/')
screenshot = browser.save_screenshot('screenshot.png')
browser.quit
您可以观察到如下所示的输出:
DevTools listening on ws://127.0.0.1:1456/devtools/browser/488ed704-9f1b-44f0- a571-892dc4c90eb7 <bound method WebDriver.quit of <selenium.webdriver.chrome.webdriver.WebDriver (session="37e8e440e2f7807ef41ca7aa20ce7c97")>>
运行脚本后,您可以在当前目录中检查screenshot.png文件。
视频缩略图生成
假设我们从网站下载了视频,并希望为它们生成缩略图,以便可以根据其缩略图单击特定的视频。为了生成视频的缩略图,我们需要一个名为ffmpeg的简单工具,可以从www.ffmpeg.org下载。下载后,我们需要根据操作系统的规格进行安装。
以下 Python 脚本将生成视频的缩略图,并将其保存到我们的本地目录:
import subprocess video_MP4_file = “C:\Users\gaurav\desktop\solar.mp4 thumbnail_image_file = 'thumbnail_solar_video.jpg' subprocess.call(['ffmpeg', '-i', video_MP4_file, '-ss', '00:00:20.000', '- vframes', '1', thumbnail_image_file, "-y"])
运行上述脚本后,我们将获得名为thumbnail_solar_video.jpg的缩略图,并将其保存在本地目录中。
将 MP4 视频转换为 MP3
假设您从网站下载了一些视频文件,但您只需要其中的音频来满足您的目的,那么可以使用 Python 库moviepy在 Python 中完成此操作,该库可以通过以下命令安装:
pip install moviepy
现在,成功使用以下脚本安装 moviepy 后,我们可以将 MP4 转换为 MP3。
import moviepy.editor as mp
clip = mp.VideoFileClip(r"C:\Users\gaurav\Desktop\1234.mp4")
clip.audio.write_audiofile("movie_audio.mp3")
您可以观察到如下所示的输出:
[MoviePy] Writing audio in movie_audio.mp3 100%|¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦ ¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 674/674 [00:01<00:00, 476.30it/s] [MoviePy] Done.
以上脚本将音频 MP3 文件保存到本地目录。
Python 网页抓取 - 处理文本
在上一章中,我们已经了解了如何处理作为网页抓取内容一部分获得的视频和图像。在本章中,我们将使用 Python 库处理文本分析,并将详细了解这一点。
介绍
您可以使用名为自然语言工具包 (NLTK) 的 Python 库进行文本分析。在深入了解 NLTK 的概念之前,让我们了解文本分析和网页抓取之间的关系。
分析文本中的单词可以让我们了解哪些单词很重要,哪些单词不寻常,单词是如何分组的。这种分析简化了网页抓取的任务。
开始使用 NLTK
自然语言工具包 (NLTK) 是 Python 库的集合,专门用于识别和标记自然语言(如英语)文本中发现的词性。
安装 NLTK
您可以使用以下命令在 Python 中安装 NLTK:
pip install nltk
如果您使用的是 Anaconda,则可以使用以下命令构建 NLTK 的 conda 包:
conda install -c anaconda nltk
下载 NLTK 的数据
安装 NLTK 后,我们必须下载预设的文本存储库。但在下载文本预设存储库之前,我们需要使用import命令导入 NLTK,如下所示:
mport nltk
现在,借助以下命令可以下载 NLTK 数据:
nltk.download()
安装所有可用的 NLTK 包将需要一些时间,但始终建议安装所有包。
安装其他必要的包
我们还需要一些其他 Python 包,如gensim和pattern,用于进行文本分析以及使用 NLTK 构建自然语言处理应用程序。
gensim - 一个强大的语义建模库,对许多应用程序很有用。它可以通过以下命令安装:
pip install gensim
pattern - 用于使gensim包正常工作。它可以通过以下命令安装:
pip install pattern
分词
将给定的文本分解成称为标记的较小单元的过程称为分词。这些标记可以是单词、数字或标点符号。它也称为词语切分。
示例

NLTK 模块提供了不同的分词包。我们可以根据需要使用这些包。这里描述了一些包:
sent_tokenize 包 - 此包将输入文本划分为句子。您可以使用以下命令导入此包:
from nltk.tokenize import sent_tokenize
word_tokenize 包 - 此包将输入文本划分为单词。您可以使用以下命令导入此包:
from nltk.tokenize import word_tokenize
WordPunctTokenizer 包 - 此包将输入文本以及标点符号划分为单词。您可以使用以下命令导入此包:
from nltk.tokenize import WordPuncttokenizer
词干提取
在任何语言中,单词都有不同的形式。由于语法原因,语言包含大量变化。例如,考虑单词democracy、democratic和democratization。对于机器学习以及网页抓取项目,机器理解这些不同单词具有相同的词干形式非常重要。因此,我们可以说在分析文本时提取单词的词干形式可能很有用。
这可以通过词干提取来实现,词干提取可以定义为通过去除单词末尾来提取单词词干形式的启发式过程。
NLTK 模块提供了不同的词干提取包。我们可以根据需要使用这些包。这里描述了其中一些包:
PorterStemmer 包 - 此 Python 词干提取包使用 Porter 算法来提取词干形式。您可以使用以下命令导入此包:
from nltk.stem.porter import PorterStemmer
例如,在将单词‘writing’作为输入提供给此词干提取器后,词干提取后的输出将是单词‘write’。
LancasterStemmer 包 - 此 Python 词干提取包使用 Lancaster 算法来提取词干形式。您可以使用以下命令导入此包:
from nltk.stem.lancaster import LancasterStemmer
例如,如果将单词“writing”作为输入提供给这个词干提取器,那么词干提取后的输出将是单词“writ”。
SnowballStemmer 包 - 这个 Python 词干提取包使用 Snowball 算法来提取词的基本形式。可以使用以下命令导入此包:
from nltk.stem.snowball import SnowballStemmer
例如,如果将单词“writing”作为输入提供给这个词干提取器,那么词干提取后的输出将是单词“write”。
词形还原
另一种提取单词基本形式的方法是词形还原,通常旨在通过使用词汇和形态分析来去除词尾变化。任何单词词形还原后的基本形式称为词形。
NLTK 模块提供以下用于词形还原的包:
WordNetLemmatizer 包 - 它将根据单词是用作名词还是动词来提取单词的基本形式。可以使用以下命令导入此包:
from nltk.stem import WordNetLemmatizer
分块
分块,即把数据分成小块,是自然语言处理中一个重要的过程,用于识别词性并识别名词短语等短语。分块是对标记进行标注。借助分块过程,我们可以得到句子的结构。
示例
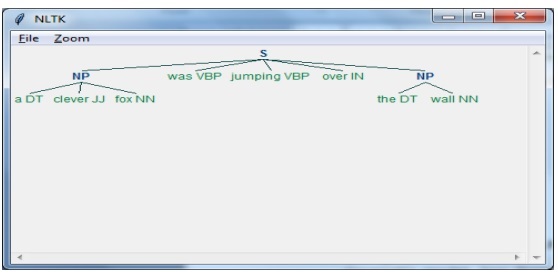
在这个例子中,我们将使用 NLTK Python 模块来实现名词短语分块。NP 分块是一种分块类别,它将在句子中查找名词短语块。
实现名词短语分块的步骤
要实现名词短语分块,需要按照以下步骤操作:
步骤 1 - 分块语法定义
在第一步中,我们将定义分块的语法。它将包含我们需要遵循的规则。
步骤 2 - 分块解析器创建
现在,我们将创建一个分块解析器。它将解析语法并给出输出。
步骤 3 - 输出
在最后一步中,输出将以树状格式生成。
首先,我们需要导入 NLTK 包,如下所示:
import nltk
接下来,我们需要定义句子。这里 DT:限定词,VBP:动词,JJ:形容词,IN:介词,NN:名词。
sentence = [("a", "DT"),("clever","JJ"),("fox","NN"),("was","VBP"),("jumping","VBP"),("over","IN"),("the","DT"),("wall","NN")]
接下来,我们以正则表达式的形式给出语法。
grammar = "NP:{<DT>?<JJ>*<NN>}"
现在,下一行代码将定义一个用于解析语法的解析器。
parser_chunking = nltk.RegexpParser(grammar)
现在,解析器将解析句子。
parser_chunking.parse(sentence)
接下来,我们将输出保存在变量中。
Output = parser_chunking.parse(sentence)
借助以下代码,我们可以将输出绘制成树状图,如下所示。
output.draw()
词袋 (BoW) 模型 提取和将文本转换为数值形式
词袋 (BoW) 是自然语言处理中一个有用的模型,主要用于从文本中提取特征。从文本中提取特征后,可以将其用于机器学习算法中的建模,因为原始数据不能用于 ML 应用。
BoW 模型的工作原理
最初,模型从文档中的所有单词中提取词汇表。之后,使用文档词矩阵构建模型。这样,BoW 模型仅将文档表示为词袋,而丢弃了顺序或结构。
示例
假设我们有以下两个句子:
句子 1 - 这是一个词袋模型的例子。
句子 2 - 我们可以使用词袋模型提取特征。
现在,考虑到这两个句子,我们有以下 14 个不同的单词:
- This
- is
- an
- example
- bag
- of
- words
- model
- we
- can
- extract
- features
- by
- using
在 NLTK 中构建词袋模型
让我们看看以下 Python 脚本,它将在 NLTK 中构建一个 BoW 模型。
首先,导入以下包:
from sklearn.feature_extraction.text import CountVectorizer
接下来,定义句子集:
Sentences=['This is an example of Bag of Words model.', ' We can extract features by using Bag of Words model.'] vector_count = CountVectorizer() features_text = vector_count.fit_transform(Sentences).todense() print(vector_count.vocabulary_)
输出
它表明以上两个句子中共有 14 个不同的单词。
{
'this': 10, 'is': 7, 'an': 0, 'example': 4, 'of': 9,
'bag': 1, 'words': 13, 'model': 8, 'we': 12, 'can': 3,
'extract': 5, 'features': 6, 'by': 2, 'using':11
}
主题建模:识别文本数据中的模式
通常将文档分组到主题中,主题建模是一种识别文本中与特定主题相对应的模式的技术。换句话说,主题建模用于揭示给定文档集中抽象的主题或隐藏的结构。
可以在以下场景中使用主题建模:
文本分类
主题建模可以改进分类,因为它将相似的单词组合在一起,而不是将每个单词单独用作特征。
推荐系统
我们可以使用相似性度量来构建推荐系统。
主题建模算法
可以使用以下算法实现主题建模:
潜在狄利克雷分配 (LDA) - 它是使用概率图模型实现主题建模的最流行算法之一。
潜在语义分析 (LDA) 或潜在语义索引 (LSI) - 它基于线性代数,并在文档词矩阵上使用 SVD (奇异值分解) 的概念。
非负矩阵分解 (NMF) - 它也像 LDA 一样基于线性代数。
上述算法将具有以下元素:
- 主题数量:参数
- 文档词矩阵:输入
- WTM(词主题矩阵)和 TDM(主题文档矩阵):输出
Python 网页抓取 - 动态网站
介绍
网页抓取是一项复杂的任务,如果网站是动态的,复杂性就会成倍增加。根据联合国全球网页无障碍审计,超过 70% 的网站本质上是动态的,它们依赖 JavaScript 来实现其功能。
动态网站示例
让我们来看一个动态网站的例子,并了解为什么它很难抓取。这里我们将以从名为 http://example.webscraping.com/places/default/search 的网站搜索为例。但是我们如何说这个网站是动态的呢?可以通过以下 Python 脚本的输出判断,该脚本将尝试从上述网页抓取数据:
import re
import urllib.request
response = urllib.request.urlopen('http://example.webscraping.com/places/default/search')
html = response.read()
text = html.decode()
re.findall('(.*?)',text)
输出
[ ]
上述输出表明,示例抓取器未能提取信息,因为我们尝试查找的 <div> 元素为空。
从动态网站抓取数据的方法
我们已经看到,抓取器无法从动态网站抓取信息,因为数据是使用 JavaScript 动态加载的。在这种情况下,我们可以使用以下两种技术从依赖于动态 JavaScript 的网站抓取数据:
- 反向工程 JavaScript
- 渲染 JavaScript
反向工程 JavaScript
称为反向工程的过程将非常有用,并让我们了解网页如何动态加载数据。
为此,我们需要为指定的 URL 单击检查元素选项卡。接下来,我们将单击网络选项卡以查找为此网页发出的所有请求,包括路径为/ajax 的 search.json。除了通过浏览器或通过网络选项卡访问 AJAX 数据之外,我们也可以借助以下 Python 脚本实现:
import requests
url=requests.get('http://example.webscraping.com/ajax/search.json?page=0&page_size=10&search_term=a')
url.json()
示例
上述脚本允许我们使用 Python json 方法访问 JSON 响应。类似地,我们可以下载原始字符串响应,并使用 python 的 json.loads 方法加载它。我们借助以下 Python 脚本执行此操作。它基本上将通过搜索字母“a”来抓取所有国家/地区,然后迭代 JSON 响应的结果页面。
import requests
import string
PAGE_SIZE = 15
url = 'http://example.webscraping.com/ajax/' + 'search.json?page={}&page_size={}&search_term=a'
countries = set()
for letter in string.ascii_lowercase:
print('Searching with %s' % letter)
page = 0
while True:
response = requests.get(url.format(page, PAGE_SIZE, letter))
data = response.json()
print('adding %d records from the page %d' %(len(data.get('records')),page))
for record in data.get('records'):countries.add(record['country'])
page += 1
if page >= data['num_pages']:
break
with open('countries.txt', 'w') as countries_file:
countries_file.write('n'.join(sorted(countries)))
运行上述脚本后,我们将获得以下输出,并且记录将保存在名为 countries.txt 的文件中。
输出
Searching with a adding 15 records from the page 0 adding 15 records from the page 1 ...
渲染 JavaScript
在上一节中,我们对网页进行了反向工程,了解了 API 的工作原理以及如何使用它在一个请求中检索结果。但是,在进行反向工程时,可能会遇到以下困难:
有时网站可能非常复杂。例如,如果网站是使用高级浏览器工具(如 Google Web Toolkit (GWT))制作的,那么生成的 JS 代码将是机器生成的,难以理解和反向工程。
一些更高级别的框架(如React.js)可以通过抽象已经很复杂的 JavaScript 逻辑来使反向工程变得困难。
解决上述困难的办法是使用浏览器渲染引擎,该引擎解析 HTML、应用 CSS 格式并执行 JavaScript 以显示网页。
示例
在这个例子中,为了渲染 Java Script,我们将使用一个熟悉的 Python 模块 Selenium。以下 Python 代码将借助 Selenium 渲染网页:
首先,我们需要从 selenium 导入 webdriver,如下所示:
from selenium import webdriver
现在,提供我们根据需要下载的Web驱动程序的路径:
path = r'C:\\Users\\gaurav\\Desktop\\Chromedriver' driver = webdriver.Chrome(executable_path = path)
现在,提供我们希望在现在由Python脚本控制的Web浏览器中打开的URL。
driver.get('http://example.webscraping.com/search')
现在,我们可以使用搜索工具箱的 ID 来设置要选择的元素。
driver.find_element_by_id('search_term').send_keys('.')
接下来,我们可以使用 java 脚本将选择框内容设置为如下所示:
js = "document.getElementById('page_size').options[1].text = '100';"
driver.execute_script(js)
以下代码行显示搜索已准备好在网页上单击:
driver.find_element_by_id('search').click()
下一行代码显示它将等待 45 秒以完成 AJAX 请求。
driver.implicitly_wait(45)
现在,要选择国家/地区链接,我们可以使用 CSS 选择器,如下所示:
links = driver.find_elements_by_css_selector('#results a')
现在可以提取每个链接的文本以创建国家/地区列表:
countries = [link.text for link in links] print(countries) driver.close()
Python 网页抓取 - 基于表单的网站
在上一章中,我们学习了抓取动态网站。在本章中,让我们了解一下基于用户输入的网站,即基于表单的网站的抓取。
介绍
如今,万维网 (WWW) 正朝着社交媒体以及用户生成内容的方向发展。因此,问题就出现了,我们如何访问登录屏幕之外的此类信息?为此,我们需要处理表单和登录。
在前面的章节中,我们使用了 HTTP GET 方法来请求信息,但在本章中,我们将使用 HTTP POST 方法将信息推送到 Web 服务器以进行存储和分析。
与登录表单交互
在使用互联网时,您一定多次与登录表单交互过。它们可能非常简单,例如仅包含很少的 HTML 字段、一个提交按钮和一个操作页面,或者它们可能很复杂,并且具有一些其他字段,例如电子邮件、留言以及出于安全原因的验证码。
在本节中,我们将借助 Python requests 库处理一个简单的提交表单。
首先,我们需要导入 requests 库,如下所示:
import requests
现在,我们需要为登录表单的字段提供信息。
parameters = {‘Name’:’Enter your name’, ‘Email-id’:’Your Emailid’,’Message’:’Type your message here’}
在下一行代码中,我们需要提供表单操作将发生到的 URL。
r = requests.post(“enter the URL”, data = parameters) print(r.text)
运行脚本后,它将返回操作发生到的页面的内容。
假设您想使用表单提交任何图像,那么使用 requests.post() 非常简单。您可以通过以下 Python 脚本了解它:
import requests
file = {‘Uploadfile’: open(’C:\Usres\desktop\123.png’,‘rb’)}
r = requests.post(“enter the URL”, files = file)
print(r.text)
从 Web 服务器加载 Cookie
Cookie,有时称为 Web Cookie 或 Internet Cookie,是从网站发送的一小段数据,我们的计算机将其存储在位于 Web 浏览器内部的文件中。
在处理登录表单的上下文中,Cookie 可以分为两种类型。一种是我们在上节中处理的,它允许我们向网站提交信息;另一种允许我们在整个访问网站期间保持永久“登录”状态。对于第二种表单,网站使用 Cookie 来跟踪谁已登录以及谁未登录。
Cookie 的作用是什么?
如今,大多数网站都使用 Cookie 进行跟踪。我们可以通过以下步骤了解 Cookie 的工作原理:
步骤 1 - 首先,网站将验证我们的登录凭据并将其存储在浏览器的 Cookie 中。此 Cookie 通常包含服务器生成的令牌、超时和跟踪信息。
步骤 2 - 接下来,网站将使用 Cookie 作为身份验证的证明。每次访问网站时,都会始终显示此身份验证。
Cookie 对 Web 爬虫来说非常麻烦,因为如果 Web 爬虫不跟踪 Cookie,提交的表单会被发送回,并在下一页显示它们从未登录。借助 Python 的 **requests** 库,跟踪 Cookie 非常容易,如下所示:
import requests
parameters = {‘Name’:’Enter your name’, ‘Email-id’:’Your Emailid’,’Message’:’Type your message here’}
r = requests.post(“enter the URL”, data = parameters)
在上面的代码行中,URL 将是充当登录表单处理程序的页面。
print(‘The cookie is:’) print(r.cookies.get_dict()) print(r.text)
运行上述脚本后,我们将从上次请求的结果中检索 Cookie。
Cookie 还存在另一个问题,即有时网站会在没有警告的情况下频繁修改 Cookie。这种情况可以使用 **requests.Session()** 处理,如下所示:
import requests
session = requests.Session()
parameters = {‘Name’:’Enter your name’, ‘Email-id’:’Your Emailid’,’Message’:’Type your message here’}
r = session.post(“enter the URL”, data = parameters)
在上面的代码行中,URL 将是充当登录表单处理程序的页面。
print(‘The cookie is:’) print(r.cookies.get_dict()) print(r.text)
可以很容易地理解使用 Session 和不使用 Session 的脚本之间的区别。
使用 Python 自动化表单
在本节中,我们将使用名为 Mechanize 的 Python 模块来简化我们的工作并自动化表单填写过程。
Mechanize 模块
Mechanize 模块为我们提供了一个与表单交互的高级接口。在开始使用它之前,我们需要使用以下命令安装它:
pip install mechanize
请注意,它仅在 Python 2.x 中有效。
示例
在这个例子中,我们将自动化填写一个包含两个字段(电子邮件和密码)的登录表单的过程:
import mechanize brwsr = mechanize.Browser() brwsr.open(Enter the URL of login) brwsr.select_form(nr = 0) brwsr['email'] = ‘Enter email’ brwsr['password'] = ‘Enter password’ response = brwsr.submit() brwsr.submit()
上述代码非常容易理解。首先,我们导入了 mechanize 模块。然后创建了一个 Mechanize 浏览器对象。然后,我们导航到登录 URL 并选择了表单。之后,名称和值直接传递给浏览器对象。
Python Web 爬虫 - 处理验证码
在本章中,让我们了解如何执行 Web 爬虫和处理验证码,验证码用于测试用户是人类还是机器人。
什么是验证码?
CAPTCHA 的全称是 **Completely Automated Public Turing test to tell Computers and Humans Apart**,它清楚地表明这是一个确定用户是否为人类的测试。
验证码是一张扭曲的图像,通常不容易被计算机程序检测到,但人类可以设法理解它。大多数网站使用验证码来防止机器人进行交互。
使用 Python 加载验证码
假设我们想在一个网站上进行注册,并且有一个包含验证码的表单,那么在加载验证码图像之前,我们需要了解表单所需的特定信息。借助以下 Python 脚本,我们可以了解名为 http://example.webscrapping.com 网站上注册表单的表单要求。
import lxml.html
import urllib.request as urllib2
import pprint
import http.cookiejar as cookielib
def form_parsing(html):
tree = lxml.html.fromstring(html)
data = {}
for e in tree.cssselect('form input'):
if e.get('name'):
data[e.get('name')] = e.get('value')
return data
REGISTER_URL = '<a target="_blank" rel="nofollow"
href="http://example.webscraping.com/user/register">http://example.webscraping.com/user/register'</a>
ckj = cookielib.CookieJar()
browser = urllib2.build_opener(urllib2.HTTPCookieProcessor(ckj))
html = browser.open(
'<a target="_blank" rel="nofollow"
href="http://example.webscraping.com/places/default/user/register?_next">
http://example.webscraping.com/places/default/user/register?_next</a> = /places/default/index'
).read()
form = form_parsing(html)
pprint.pprint(form)
在上面的 Python 脚本中,我们首先定义了一个函数,该函数将使用 lxml Python 模块解析表单,然后打印表单要求,如下所示:
{
'_formkey': '5e306d73-5774-4146-a94e-3541f22c95ab',
'_formname': 'register',
'_next': '/places/default/index',
'email': '',
'first_name': '',
'last_name': '',
'password': '',
'password_two': '',
'recaptcha_response_field': None
}
从上面的输出中可以看出,除了 **recpatcha_response_field** 之外,所有信息都易于理解和直接。现在问题出现了,我们如何处理这些复杂信息并下载验证码?这可以通过 Pillow Python 库来实现,如下所示:
Pillow Python 包
Pillow 是 Python 图像库的一个分支,具有用于操作图像的有用函数。可以使用以下命令安装它:
pip install pillow
在下一个示例中,我们将使用它来加载验证码:
from io import BytesIO
import lxml.html
from PIL import Image
def load_captcha(html):
tree = lxml.html.fromstring(html)
img_data = tree.cssselect('div#recaptcha img')[0].get('src')
img_data = img_data.partition(',')[-1]
binary_img_data = img_data.decode('base64')
file_like = BytesIO(binary_img_data)
img = Image.open(file_like)
return img
上面的 Python 脚本使用了 **pillow** Python 包并定义了一个加载验证码图像的函数。它必须与前面脚本中定义的名为 **form_parser()** 的函数一起使用,以获取有关注册表单的信息。此脚本将以有用的格式保存验证码图像,该图像可以进一步提取为字符串。
OCR:使用 Python 从图像中提取文本
以有用的格式加载验证码后,我们可以借助光学字符识别 (OCR) 来提取它,OCR 是从图像中提取文本的过程。为此,我们将使用开源的 Tesseract OCR 引擎。可以使用以下命令安装它:
pip install pytesseract
示例
这里我们将扩展上面使用 Pillow Python 包加载验证码的 Python 脚本,如下所示:
import pytesseract
img = get_captcha(html)
img.save('captcha_original.png')
gray = img.convert('L')
gray.save('captcha_gray.png')
bw = gray.point(lambda x: 0 if x < 1 else 255, '1')
bw.save('captcha_thresholded.png')
上面的 Python 脚本将以黑白模式读取验证码,这将更加清晰易于传递给 tesseract,如下所示:
pytesseract.image_to_string(bw)
运行上述脚本后,我们将获得注册表单的验证码作为输出。
Python Web 爬虫 - 使用爬虫进行测试
本章介绍如何在 Python 中使用 Web 爬虫进行测试。
介绍
在大型 Web 项目中,会定期对网站的后端进行自动化测试,但前端测试却经常被跳过。其主要原因是网站的编程就像一个由各种标记语言和编程语言组成的网络。我们可以为一种语言编写单元测试,但如果交互是在另一种语言中进行的,那么就会变得具有挑战性。因此,我们必须有一套测试来确保我们的代码按照我们的预期执行。
使用 Python 进行测试
当我们谈论测试时,指的是单元测试。在深入探讨 Python 测试之前,我们必须了解单元测试。以下是单元测试的一些特点:
每个单元测试都将测试组件功能的至少一个方面。
每个单元测试都是独立的,也可以独立运行。
单元测试不会干扰任何其他测试的成功或失败。
单元测试可以以任何顺序运行,并且必须包含至少一个断言。
Unittest - Python 模块
名为 Unittest 的 Python 单元测试模块随所有标准 Python 安装一起提供。我们只需要导入它,其余工作由 unittest.TestCase 类完成,它将执行以下操作:
unittest.TestCase 类提供了 setUp 和 tearDown 函数。这些函数可以在每个单元测试之前和之后运行。
它还提供了 assert 语句,以允许测试通过或失败。
它运行所有以 test_ 开头的函数作为单元测试。
示例
在这个例子中,我们将 Web 爬虫与 **unittest** 结合起来。我们将测试维基百科页面以搜索字符串“Python”。它基本上将执行两个测试,第一个测试是标题页面是否与搜索字符串即“Python”相同,第二个测试确保页面具有内容 div。
首先,我们将导入所需的 Python 模块。我们使用 BeautifulSoup 进行 Web 爬虫,当然也使用 unittest 进行测试。
from urllib.request import urlopen from bs4 import BeautifulSoup import unittest
现在我们需要定义一个类,该类将扩展 unittest.TestCase。全局对象 bs 将在所有测试之间共享。一个 unittest 指定的函数 setUpClass 将实现这一点。在这里,我们将定义两个函数,一个用于测试标题页面,另一个用于测试页面内容。
class Test(unittest.TestCase):
bs = None
def setUpClass():
url = '<a target="_blank" rel="nofollow" href="https://en.wikipedia.org/wiki/Python">https://en.wikipedia.org/wiki/Python'</a>
Test.bs = BeautifulSoup(urlopen(url), 'html.parser')
def test_titleText(self):
pageTitle = Test.bs.find('h1').get_text()
self.assertEqual('Python', pageTitle);
def test_contentExists(self):
content = Test.bs.find('div',{'id':'mw-content-text'})
self.assertIsNotNone(content)
if __name__ == '__main__':
unittest.main()
运行上述脚本后,我们将获得以下输出:
----------------------------------------------------------------------
Ran 2 tests in 2.773s
OK
An exception has occurred, use %tb to see the full traceback.
SystemExit: False
D:\ProgramData\lib\site-packages\IPython\core\interactiveshell.py:2870:
UserWarning: To exit: use 'exit', 'quit', or Ctrl-D.
warn("To exit: use 'exit', 'quit', or Ctrl-D.", stacklevel=1)
使用 Selenium 进行测试
让我们讨论如何使用 Python Selenium 进行测试。它也称为 Selenium 测试。Python **unittest** 和 **Selenium** 之间并没有太多共同点。我们知道 Selenium 将标准 Python 命令发送到不同的浏览器,尽管它们的浏览器设计存在差异。回想一下,我们已经在前面的章节中安装并使用了 Selenium。在这里,我们将创建 Selenium 中的测试脚本并将其用于自动化。
示例
借助以下 Python 脚本,我们正在为 Facebook 登录页面的自动化创建测试脚本。您可以修改此示例以自动化您选择的其他表单和登录,但概念将相同。
首先,为了连接到 Web 浏览器,我们将从 selenium 模块导入 webdriver:
from selenium import webdriver
现在,我们需要从 selenium 模块导入 Keys。
from selenium.webdriver.common.keys import Keys
接下来,我们需要提供用户名和密码才能登录我们的 Facebook 帐户
user = "gauravleekha@gmail.com" pwd = ""
接下来,提供 Chrome 的 Web 驱动程序的路径。
path = r'C:\\Users\\gaurav\\Desktop\\Chromedriver'
driver = webdriver.Chrome(executable_path=path)
driver.get("https://#")
现在,我们将使用 assert 关键字验证条件。
assert "Facebook" in driver.title
借助以下代码行,我们将值发送到电子邮件部分。在这里,我们通过其 ID 搜索它,但可以通过名称搜索它,例如 **driver.find_element_by_name("email")**。
element = driver.find_element_by_id("email")
element.send_keys(user)
借助以下代码行,我们将值发送到密码部分。在这里,我们通过其 ID 搜索它,但可以通过名称搜索它,例如 **driver.find_element_by_name("pass")**。
element = driver.find_element_by_id("pass")
element.send_keys(pwd)
下一行代码用于在电子邮件和密码字段中插入值后按 Enter/登录。
element.send_keys(Keys.RETURN)
现在我们将关闭浏览器。
driver.close()
运行上述脚本后,Chrome Web 浏览器将打开,您可以看到电子邮件和密码正在插入并单击登录按钮。
比较:unittest 或 Selenium
unittest 和 selenium 的比较比较困难,因为如果您想使用大型测试套件,则需要 unites 的语法严格性。另一方面,如果您要测试网站的灵活性,那么 Selenium 测试将是我们的首选。但是,如果我们可以将两者结合起来呢?我们可以将 selenium 导入到 Python unittest 中,并获得两者的优势。Selenium 可用于获取有关网站的信息,而 unittest 可以评估这些信息是否满足通过测试的标准。
例如,我们正在重写上面的 Python 脚本以通过将两者结合起来来自动化 Facebook 登录,如下所示:
import unittest
from selenium import webdriver
class InputFormsCheck(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome(r'C:\Users\gaurav\Desktop\chromedriver')
def test_singleInputField(self):
user = "gauravleekha@gmail.com"
pwd = ""
pageUrl = "https://#"
driver=self.driver
driver.maximize_window()
driver.get(pageUrl)
assert "Facebook" in driver.title
elem = driver.find_element_by_id("email")
elem.send_keys(user)
elem = driver.find_element_by_id("pass")
elem.send_keys(pwd)
elem.send_keys(Keys.RETURN)
def tearDown(self):
self.driver.close()
if __name__ == "__main__":
unittest.main()