- Python 网络爬虫教程
- Python 网络爬虫 - 首页
- 简介
- Python 入门
- 用于网络爬虫的 Python 模块
- 网络爬虫的合法性
- 数据提取
- 数据处理
- 处理图像和视频
- 处理文本
- 爬取动态网站
- 爬取基于表单的网站
- 处理验证码
- 使用爬虫进行测试
- Python 网络爬虫资源
- Python 网络爬虫 - 快速指南
- Python 网络爬虫 - 资源
- Python 网络爬虫 - 讨论
Python 网络爬虫 - 简介
网络爬虫是从网络中自动提取信息的过程。本章将深入了解网络爬虫,将其与网络爬取进行比较,并说明为什么要选择网络爬虫。您还将学习网络爬虫的组件和工作原理。
什么是网络爬虫?
“爬取”一词的字典含义是指从网络中获取某些东西。这里出现了两个问题:我们可以从网络中获取什么以及如何获取?
第一个问题的答案是“数据”。数据对于任何程序员来说都是不可或缺的,每个编程项目的根本需求都是大量有用的数据。
第二个问题的答案有点棘手,因为获取数据的方法有很多。通常,我们可以从数据库或数据文件以及其他来源获取数据。但是,如果我们需要大量可在线获取的数据呢?获取此类数据的一种方法是手动搜索(在 Web 浏览器中点击)并保存(复制粘贴到电子表格或文件中)所需的数据。这种方法非常繁琐且耗时。另一种获取此类数据的方法是使用网络爬虫。
网络爬虫,也称为网络数据挖掘或网络采集,是构建一个代理的过程,该代理可以自动从网络中提取、解析、下载和组织有用的信息。换句话说,我们可以说,与其手动从网站保存数据,不如让网络爬虫软件根据我们的需求自动加载和提取来自多个网站的数据。
网络爬虫的起源
网络爬虫起源于屏幕抓取,屏幕抓取用于集成非 Web 应用程序或本机 Windows 应用程序。最初,屏幕抓取在万维网 (WWW) 广泛使用之前就已使用,但随着 WWW 的扩展,它无法扩展。这使得自动化屏幕抓取方法变得必要,并出现了名为“网络爬虫”的技术。
Learn Python in-depth with real-world projects through our Python certification course. Enroll and become a certified expert to boost your career.
网络爬取与网络爬虫
术语“网络爬取”和“网络爬虫”通常可以互换使用,因为它们的根本概念都是提取数据。但是,它们彼此之间存在差异。我们可以从它们的定义中理解基本区别。
网络爬取基本上是使用机器人(又称爬虫)索引页面上的信息。它也称为索引。另一方面,网络爬虫是使用机器人(又称爬虫)自动提取信息的一种方式。它也称为数据提取。
为了理解这两个术语之间的区别,让我们看看下面给出的比较表:
| 网络爬取 | 网络爬虫 |
|---|---|
| 指的是下载和存储大量网站的内容。 | 指的是使用特定于站点的结构从网站提取单个数据元素。 |
| 主要在大规模进行。 | 可以在任何规模上实现。 |
| 产生通用信息。 | 产生特定信息。 |
| 由主要的搜索引擎(如 Google、Bing、Yahoo)使用。Googlebot 是网络爬虫的一个示例。 | 使用网络爬虫提取的信息可以用于复制到其他网站中,或者可以用于执行数据分析。例如,数据元素可以是姓名、地址、价格等。 |
网络爬虫的用途
使用网络爬虫的用途和原因与万维网的用途一样无限。网络爬虫可以执行任何操作,例如在线订购食物、为您扫描在线购物网站以及在门票可用时立即购买比赛门票等,就像人类可以做的那样。这里讨论了一些网络爬虫的重要用途:
电子商务网站 - 网络爬虫可以从各种电子商务网站收集与特定产品价格相关的数据,以便进行比较。
内容聚合器 - 内容聚合器(如新闻聚合器和工作聚合器)广泛使用网络爬虫,以便为其用户提供更新的数据。
营销和销售活动 - 网络爬虫可以用于获取电子邮件、电话号码等数据,以用于销售和营销活动。
搜索引擎优化 (SEO) - SEO 工具(如 SEMRush、Majestic 等)广泛使用网络爬虫来告知企业他们在对其重要的搜索关键词方面的排名情况。
机器学习项目的的数据 - 机器学习项目的检索数据依赖于网络爬虫。
研究数据 - 研究人员可以通过这种自动化过程节省时间,从而收集对其研究工作有用的数据。
网络爬虫的组件
网络爬虫包含以下组件:
网络爬虫模块
网络爬虫模块是网络爬虫中非常必要的组件,用于通过向 URL 发送 HTTP 或 HTTPS 请求来导航目标网站。爬虫下载非结构化数据(HTML 内容)并将其传递给提取器(下一个模块)。
提取器
提取器处理获取的 HTML 内容并将数据提取为半结构化格式。这也被称为解析器模块,并使用不同的解析技术(如正则表达式、HTML 解析、DOM 解析或人工智能)来执行其功能。
数据转换和清理模块
上面提取的数据不适合直接使用。它必须通过一些清理模块,以便我们能够使用它。字符串操作或正则表达式等方法可用于此目的。请注意,提取和转换也可以一步完成。
存储模块
提取数据后,我们需要根据我们的要求存储它。存储模块将以标准格式输出数据,该数据可以存储在数据库或 JSON 或 CSV 格式中。
网络爬虫的工作原理
网络爬虫可以定义为用于下载多个网页的内容并从中提取数据的软件或脚本。
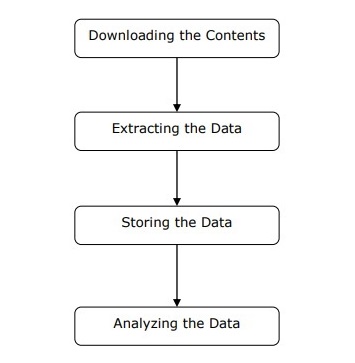
我们可以通过上面给出的图表中的简单步骤了解网络爬虫的工作原理。
步骤 1:从网页下载内容
在此步骤中,网络爬虫将从多个网页下载请求的内容。
步骤 2:提取数据
网站上的数据是 HTML,并且大部分是非结构化的。因此,在此步骤中,网络爬虫将解析并从下载的内容中提取结构化数据。
步骤 3:存储数据
在这里,网络爬虫将以 CSV、JSON 或数据库等任何格式存储和保存提取的数据。
步骤 4:分析数据
在成功完成所有这些步骤后,网络爬虫将分析由此获得的数据。