- Python 网页抓取教程
- Python 网页抓取 - 主页
- 简介
- Python 入门
- Python 网页抓取模块
- 网页抓取的合法性
- 数据提取
- 数据处理
- 图片与视频处理
- 文字处理
- 动态网页抓取
- 基于表单的网页抓取
- 验证码处理
- 使用抓取工具进行测试
- Python 网页抓取资源
- Python 网页抓取 - 快速指南
- Python 网页抓取 - 资源
- Python 网页抓取 - 讨论
Python 网页抓取 - 文字处理
在上一章中,我们了解了如何处理我们通过网页抓取的内容获取的视频和图片。在本章中,我们将使用 Python 库来处理文本分析,并详细了解这方面的内容。
简介
你可以使用名为自然语言工具包 (NLTK) 的 Python 库来执行文本分析。在深入了解 NLTK 的概念之前,让我们了解文本分析和网页抓取之间的关系。
分析文本中的单词,可以让我们了解哪些单词很重要,哪些单词不寻常以及单词是如何分组的。这种分析可以简化网页抓取的任务。
NLTK 入门
自然语言工具包 (NLTK) 是一个 Python 库的集合,专门设计用于识别和标记英语等自然语言文本中找到的词性。
安装 NLTK
你可以使用以下命令在 Python 中安装 NLTK −
pip install nltk
如果你正在使用 Anaconda,那么可以使用以下命令构建一个针对 NLTK 的 conda 包 −
conda install -c anaconda nltk
下载 NLTK 的数据
在安装 NLTK 之后,我们必须下载预设的文本存储库。但在下载文本预设存储库之前,我们需要使用import命令帮助导入 NLTK,如下所示 −
mport nltk
现在,可以在以下命令的帮助下下载 NLTK 数据 −
nltk.download()
安装 NLTK 的所有可用包需要一些时间,但始终建议安装所有包。
安装其他必要的包
我们还需要一些其他 Python 包,如gensim和pattern,以便通过 NLTK 执行文本分析以及构建自然语言处理应用程序。
gensim − 一个强大的语义建模库,对许多应用程序都很有用。它可以通过以下命令进行安装 −
pip install gensim
pattern − 用于使gensim包正常工作。它可以通过以下命令进行安装 −
pip install pattern
标记化
将给定文本分解为称为标记的较小单元的过程称为标记化。这些标记可以是单词、数字或标点符号。它也称为单词分割。
示例

NLTK 模块提供了不同的包来进行标记化。我们可以根据自己的需要使用这些包。这里描述了其中的一些包 −
sent_tokenize 包 − 此包会将输入文本分成句子。你可以使用以下命令来导入此包 −
from nltk.tokenize import sent_tokenize
word_tokenize 包 − 此包会将输入文本分成单词。你可以使用以下命令来导入此包 −
from nltk.tokenize import word_tokenize
WordPunctTokenizer 包 – 此包将输入文本及标点符号划分为单词。你可以使用以下命令来导入该包 −
from nltk.tokenize import WordPuncttokenizer
词干分析
任何语言中都存在各种形式的单词。一门语言会因语法原因而包含许多变体。例如,考虑单词 democracy、democratic 和 democratization。对于机器学习以及网络抓取项目而言,机器理解这些不同的单词具有相同的基元形式非常重要。因此我们可以说,在分析文本时,提取单词的基元形式非常有用。
这可以通过词干分析来实现,它可以定义为通过切除单词尾部来提取单词基元形式的启发式过程。
NLTK 模块为词干分析提供了不同的包。我们可以根据自己的要求使用这些包。以下对其中一些包进行了说明 −
PorterStemmer 包 – 此 Python 词干分析包使用 Porter 算法来提取基元形式。你可以使用以下命令来导入该包 −
from nltk.stem.porter import PorterStemmer
例如,将单词 “writing” 作为输入形式提供给此词干分析器时,词干分析后得到的输出将是单词 “write”。
LancasterStemmer 包 – 此 Python 词干分析包使用 Lancaster 算法来提取基元形式。你可以使用以下命令来导入该包 −
from nltk.stem.lancaster import LancasterStemmer
例如,将单词 “writing” 作为输入形式提供给此词干分析器时,词干分析后得到的输出将是单词 “writ”。
SnowballStemmer 包 – 此 Python 词干分析包使用 Snowball 算法来提取基元形式。你可以使用以下命令来导入该包 −
from nltk.stem.snowball import SnowballStemmer
例如,将单词 “writing” 作为输入形式提供给此词干分析器时,词干分析后得到的输出将是单词 “write”。
词形还原
另一种提取单词基元形式的方法是词形还原,其通常旨在通过使用词汇和形态分析来移除屈折词尾。词形还原后的任何单词的基元形式都称为词干。
NLTK 模块为词形还原提供了以下包 −
WordNetLemmatizer 包 – 它会提取单词的基元形式,具体取决于该单词是作为名词还是动词使用。你可以使用以下命令来导入该包 −
from nltk.stem import WordNetLemmatizer
块分析
块分析是指将数据划分为小块,这是自然语言处理中用于识别词性和短语(例如名词短语)的重要过程之一。块分析是要对标记进行标记。借助块分析过程,我们能够获取句子的结构。
示例
在此示例中,我们将使用 NLTK Python 模块实现名词短语块分析。名词短语块分析是一种块分析分类,它将在句子中查找名词短语块。
实现名词短语块分析的步骤
我们需要按照以下步骤来实现名词短语块分析 −
第 1 步 − 块语法定义
在第一步中,我们将定义块语法。它将包括我们需要遵循的规则。
第 2 步 − 块解析器创建
现在,我们将创建一个块解析器。它将解析语法并给输出。
第 3 步 − 输出
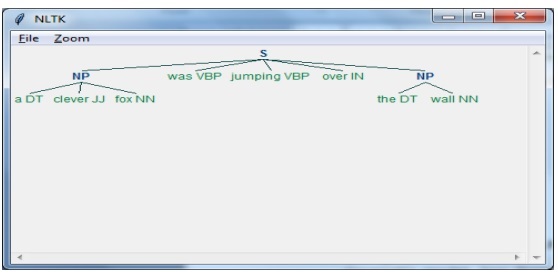
在最后一步中,输出将以树的形式生成。
首先,我们需要如下导入 NLTK 包 −
import nltk
接下来,我们需要定义句子。在此,DT:限定词,VBP:动词,JJ:形容词,IN:介词,NN:名词。
sentence = [("a", "DT"),("clever","JJ"),("fox","NN"),("was","VBP"),("jumping","VBP"),("over","IN"),("the","DT"),("wall","NN")]
接下来,我们要以正则表达式的形式提供语法。
grammar = "NP:{<DT>?<JJ>*<NN>}"
现在,下一行代码将定义用于分析语法的分析器。
parser_chunking = nltk.RegexpParser(grammar)
现在,分析器将分析句子。
parser_chunking.parse(sentence)
接下来,我们将输出放入变量中。
Output = parser_chunking.parse(sentence)
借助以下代码,我们可以绘制输出,形式如下所示的树形结构。
output.draw()
单词袋模型 (BoW) 提取文本并将其转换为数字形式
单词袋 (BoW) 在自然语言处理中是一个有用的模型,基本上用于从文本中提取特征。从文本中提取特征之后,它可用于机器学习算法建模,因为原始数据无法用于 ML 应用程序。
BoW 模型的工作原理
最初,模型从文档中的所有单词中提取词汇表。然后,使用文档术语矩阵,它会建立模型。通过这种方式,BoW 模型将文档表示为一个仅仅由单词组成的词袋,而顺序或结构则被舍弃。
示例
假设我们有以下两个句子 -
句子 1 - 这是一个单词袋模型示例。
句子 2 - 我们可以使用单词袋模型提取特征。
现在,通过考虑这两个句子,我们得到了以下 14 个不同的单词 -
- 这
- 是
- 一个
- 示例
- 词袋
- 的
- 单词
- 模型
- 我们
- 可以
- 提取
- 特征
- 通过
- 使用
在 NLTK 中构建单词袋模型
让我们看一下以下 Python 脚本,它将在 NLTK 中构建 BoW 模型。
首先,导入以下包 -
from sklearn.feature_extraction.text import CountVectorizer
接下来,定义句子集合 -
Sentences=['This is an example of Bag of Words model.', ' We can extract features by using Bag of Words model.'] vector_count = CountVectorizer() features_text = vector_count.fit_transform(Sentences).todense() print(vector_count.vocabulary_)
输出
它表明,在上述两个句子中有 14 个不同的单词 -
{
'this': 10, 'is': 7, 'an': 0, 'example': 4, 'of': 9,
'bag': 1, 'words': 13, 'model': 8, 'we': 12, 'can': 3,
'extract': 5, 'features': 6, 'by': 2, 'using':11
}
主题建模:在文本数据中识别模式
通常情况下,文档会被分组为主题,而主题建模就是一种识别与特定主题相对应的文本中模式的技术。换句话说,主题建模用于揭示给定文档集中的抽象主题或隐藏结构。
你可以在以下场景中使用主题建模 -
文本分类
主题建模可以改善分类,因为它将相似的单词组合在一起,而不是将每个单词单独用作特征。
推荐系统
我们可以利用相似度测量构建推荐系统。
主题建模算法
我们可以通过以下算法实现主题建模 -
潜在狄利克雷分配(LDA) - 这是最流行的算法之一,它使用概率图模型来实现主题建模。
潜在语义分析 (LDA) 或潜在语义索引 (LSI) - 它基于线性代数,并在文档术语矩阵上使用 SVD(奇异值分解)的概念。
非负矩阵分解 (NMF) - 它也基于线性代数,与 LDA 类似。
上述算法将具有以下元素 -
- 主题数量:参数
- 文档-单词矩阵:输入
- WTM(单词主题矩阵)和 TDM(主题文档矩阵):输出