- Requests 教程
- Requests - 首页
- Requests - 概述
- Requests - 环境设置
- Requests - HTTP 请求是如何工作的?
- Requests - 使用 Requests
- 处理 HTTP 请求的响应
- Requests - HTTP 请求头
- Requests - 处理 GET 请求
- 处理 POST、PUT、PATCH 和 DELETE 请求
- Requests - 文件上传
- Requests - 使用 Cookie
- Requests - 处理错误
- Requests - 处理超时
- Requests - 处理重定向
- Requests - 处理历史记录
- Requests - 处理会话
- Requests - SSL 证书
- Requests - 身份验证
- Requests - 事件钩子
- Requests - 代理
- Requests - 使用 Requests 进行网页抓取
- Requests 有用资源
- Requests 快速指南
- Requests - 有用资源
- Requests - 讨论
Requests 快速指南
Requests - 概述
Requests 是一个 HTTP 库,它提供了易于使用的功能来处理 Web 应用程序中的 HTTP 请求/响应。该库是用 Python 开发的。
Python Requests 的官方网站位于 https://2.python-requests.org/en/master/,其定义如下:
Requests 是一个优雅而简单的 Python HTTP 库,专为人类而设计。
Requests 的特性
下面将讨论 Requests 的特性:
请求
Python Requests 库提供了易于使用的处理 HTTP 请求的方法。传递参数和处理请求类型(如 GET、POST、PUT、DELETE 等)非常简单。
响应
您可以根据需要获取响应,支持的格式包括文本格式、二进制响应、JSON 响应和原始响应。
头信息
该库允许您根据需要读取、更新或发送新的头信息。
超时
您可以使用 Python Requests 库轻松地为要请求的 URL 添加超时。例如,您正在使用第三方 URL 并等待响应。
始终建议为 URL 设置超时,因为我们可能希望 URL 在超时时间内以响应或因超时导致的错误进行响应。否则可能会导致无限期地等待该请求。
错误处理
Requests 模块支持错误处理,其中一些错误包括连接错误、超时错误、TooManyRedirects、Response.raise_for_status 错误等。
Cookie
该库允许您读取、写入和更新请求 URL 的 Cookie。
会话
为了在请求之间维护数据,您需要使用会话。因此,如果反复调用同一个主机,您可以重用 TCP 连接,从而提高性能。
SSL 证书
SSL 证书是安全 URL 的一项安全功能。当您使用 Requests 时,它还会验证提供的 HTTPS URL 的 SSL 证书。Requests 库默认启用 SSL 验证,如果证书不存在,则会抛出错误。
身份验证
HTTP 身份验证是在服务器端,当客户端请求 URL 时,要求提供一些身份验证信息,例如用户名和密码。这是对客户端和服务器之间交换的请求和响应的额外安全措施。
使用 Python Requests 库的优势
以下是使用 Python Requests 库的优势:
易于使用并从给定的 URL 获取数据。
Requests 库可用于从网站抓取数据。
使用 Requests,您可以获取、发布、删除和更新给定 URL 的数据。
Cookie 和会话的处理非常简单。
借助身份验证模块的支持,也确保了安全性。
Requests - 环境设置
在本章中,我们将学习 Requests 的安装。要开始使用 Requests 模块,我们需要先安装 Python。因此,我们将执行以下操作:
- 安装 Python
- 安装 Requests
安装 Python
访问 Python 官方网站:https://pythonlang.cn/downloads/(如下所示),并点击适用于 Windows、Linux/Unix 和 Mac OS 的最新版本。根据您的 64 位或 32 位操作系统下载 Python。
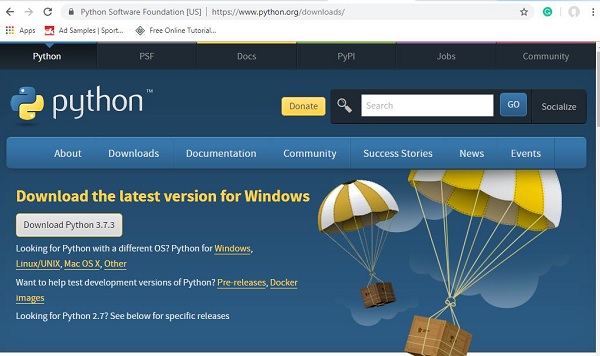
下载完成后,点击 .exe 文件并按照步骤在您的系统上安装 Python。
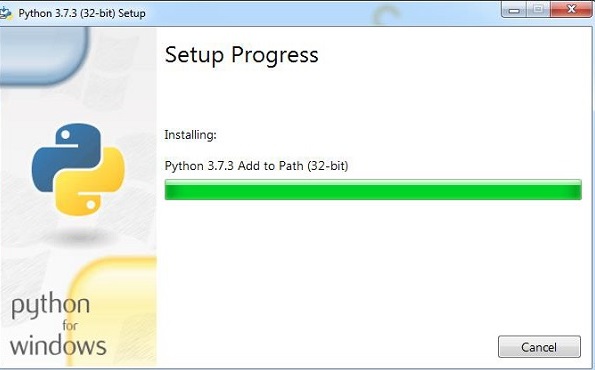
Python 包管理器 pip 会在上述安装过程中默认安装。为了使其在您的系统上全局生效,请将 Python 的路径直接添加到 PATH 环境变量中。在安装开始时会显示相同的提示,请务必选中“添加到 PATH”复选框。如果您忘记选中它,请按照以下步骤将其添加到 PATH。
要添加到 PATH,请按照以下步骤操作:
右键点击“此电脑”图标,然后点击“属性”>“高级系统设置”。
将显示如下屏幕:
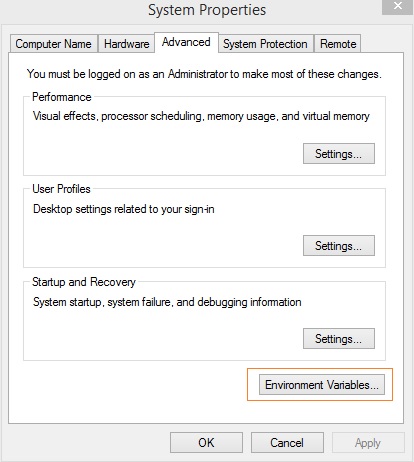
点击“环境变量”,将显示如下屏幕:
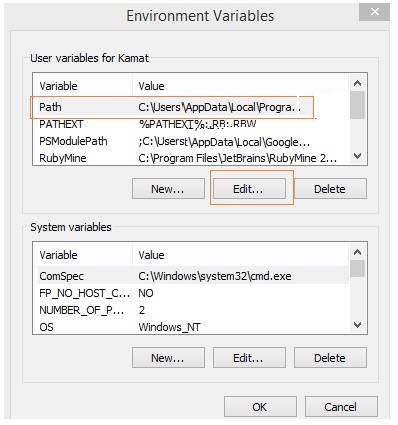
选择“Path”并点击“编辑”按钮,在末尾添加 Python 的路径。现在,让我们检查 Python 版本。
检查 Python 版本
E:\prequests>python --version Python 3.7.3
安装 Requests
现在我们已经安装了 Python,接下来我们将安装 Requests。
安装 Python 后,Python 包管理器 pip 也会安装。以下是检查 pip 版本的命令。
E:\prequests>pip --version pip 19.1.1 from c:\users\xxxxx\appdata\local\programs\python\python37\lib\site-p ackages\pip (python 3.7)
我们已经安装了 pip,版本为 19.1.1。现在,我们将使用 pip 安装 Requests 模块。
命令如下:
pip install requests
E:\prequests>pip install requests Requirement already satisfied: requests in c:\users\xxxx\appdata\local\programs \python\python37\lib\site-packages (2.22.0) Requirement already satisfied: certifi>=2017.4.17 in c:\users\kamat\appdata\loca l\programs\python\python37\lib\site-packages (from requests) (2019.3.9) Requirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in c:\use rs\xxxxx\appdata\local\programs\python\python37\lib\site-packages (from requests ) (1.25.3) Requirement already satisfied: idna<2.9,>=2.5 in c:\users\xxxxxxx\appdata\local\pr ograms\python\python37\lib\site-packages (from requests) (2.8) Requirement already satisfied: chardet<3.1.0,>=3.0.2 in c:\users\xxxxx\appdata\l ocal\programs\python\python37\lib\site-packages (from requests) (3.0.4)
我们已经安装了该模块,因此在命令提示符中显示“Requirement already satisfied”;如果未安装,它将下载安装所需的软件包。
要检查已安装的 Requests 模块的详细信息,可以使用以下命令:
pip show requests E:\prequests>pip show requests Name: requests Version: 2.22.0 Summary: Python HTTP for Humans. Home-page: http://python-requests.org Author: Kenneth Reitz Author-email: me@kennethreitz.org License: Apache 2.0 Location: c:\users\xxxxx\appdata\local\programs\python\python37\lib\site-package S Requires: certifi, idna, urllib3, chardet Required-by:
Requests 模块的版本为 2.22.0。
Requests - HTTP 请求是如何工作的?
Python 的 Requests 是一个 HTTP 库,它将帮助我们在客户端和服务器之间交换数据。假设您有一个带有表单的 UI,您需要在其中输入用户详细信息,那么一旦输入完成后,您需要提交数据,这实际上是客户端向服务器发送的 HTTP POST 或 PUT 请求,以保存数据。
当您需要数据时,您需要从服务器获取它,这又是一个 HTTP GET 请求。客户端请求数据时以及服务器以所需数据响应之间的这种数据交换,客户端和服务器之间的这种关系非常重要。
请求发送到给定的 URL,该 URL 可以是安全或非安全 URL。
可以使用 GET、POST、PUT、DELETE 方法向 URL 发送请求。最常用的方法是 GET 方法,主要用于从服务器获取数据。
您还可以将数据作为查询字符串发送到 URL,例如:
https://jsonplaceholder.typicode.com/users?id=9&username=Delphine
因此,这里我们将 id=9 和 username=Delphine 传递给 URL。所有值都在问号 (?) 后以键值对的形式发送,多个参数通过 & 分隔传递给 URL。
使用 Requests 库,可以使用字符串字典如下调用 URL。
其中,数据以字符串字典的形式发送到 URL。如果要传递 id=9 和 username=Delphine,可以执行以下操作:
payload = {'id': '9', 'username': 'Delphine'}
Requests 库的调用方式如下:
res = requests.get('https://jsonplaceholder.typicode.com/users', params=payload')
使用 POST,我们可以执行以下操作:
res = requests.post('https://jsonplaceholder.typicode.com/users', data = {'id':'9', 'username':'Delphine'})
使用 PUT
res = requests.put('https://jsonplaceholder.typicode.com/users', data = {'id':'9', 'username':'Delphine'})
使用 DELETE
res = requests.delete('https://jsonplaceholder.typicode.com/users')
HTTP 请求的响应可以是文本编码形式、二进制编码、JSON 格式或原始响应。请求和响应的详细信息将在后续章节中详细解释。
Requests - 使用 Requests
在本章中,我们将了解如何使用 Requests 模块。我们将研究以下内容:
- 发出 HTTP 请求。
- 向 HTTP 请求传递参数。
发出 HTTP 请求
要发出 HTTP 请求,我们需要首先导入 Requests 模块,如下所示:
import requests
现在让我们看看如何使用 Requests 模块调用 URL。
让我们在代码中使用 URL https://jsonplaceholder.typicode.com/users 来测试 Requests 模块。
示例
import requests
getdata = requests.get('https://jsonplaceholder.typicode.com/users')
print(getdata.status_code)
使用 requests.get() 方法调用 URL https://jsonplaceholder.typicode.com/users。URL 的响应对象存储在 getdata 变量中。当我们打印变量时,它会给出 200 响应代码,这意味着我们已成功获取响应。
输出
E:\prequests>python makeRequest.py <Response [200]>
要从响应中获取内容,可以使用 getdata.content,如下所示:
示例
import requests
getdata = requests.get('https://jsonplaceholder.typicode.com/users')
print(getdata.content)
getdata.content 将打印响应中所有可用的数据。
输出
E:\prequests>python makeRequest.py
b'[\n {\n "id": 1,\n "name": "Leanne Graham",\n "username": "Bret",\n
"email": "Sincere@april.biz",\n "address": {\n "street": "Kulas Light
",\n "suite": "Apt. 556",\n "city": "Gwenborough",\n "zipcode": "
92998-3874",\n "geo": {\n "lat": "-37.3159",\n "lng": "81.149
6"\n }\n },\n "phone": "1-770-736-8031 x56442",\n "website": "hild
egard.org",\n "company": {\n "name": "Romaguera-Crona",\n "catchPhr
ase": "Multi-layered client-server neural-net",\n "bs": "harness real-time
e-markets"\n }\n }
向 HTTP 请求传递参数
仅请求 URL 是不够的,我们还需要向 URL 传递参数。
参数通常以键值对的形式传递,例如:
https://jsonplaceholder.typicode.com/users?id=9&username=Delphine
因此,我们有 id=9 和 username=Delphine。现在,我们将了解如何将此类数据传递给 Requests HTTP 模块。
示例
import requests
payload = {'id': 9, 'username': 'Delphine'}
getdata = requests.get('https://jsonplaceholder.typicode.com/users', params=payload)
print(getdata.content)
详细信息存储在对象 payload 的键值对中,并传递给 get() 方法中的 params。
输出
E:\prequests>python makeRequest.py
b'[\n {\n "id": 9,\n "name": "Glenna Reichert",\n "username": "Delphin
e",\n "email": "Chaim_McDermott@dana.io",\n "address": {\n "street":
"Dayna Park",\n "suite": "Suite 449",\n "city": "Bartholomebury",\n
"zipcode": "76495-3109",\n "geo": {\n "lat": "24.6463",\n
"lng": "-168.8889"\n }\n },\n "phone": "(775)976-6794 x41206",\n "
website": "conrad.com",\n "company": {\n "name": "Yost and Sons",\n
"catchPhrase": "Switchable contextually-based project",\n "bs": "aggregate
real-time technologies"\n }\n }\n]'
我们现在在响应中获取了 id=9 和 username=Delphine 的详细信息。
如果您想查看传递参数后 URL 的外观,可以使用响应对象到 URL。
示例
import requests
payload = {'id': 9, 'username': 'Delphine'}
getdata = requests.get('https://jsonplaceholder.typicode.com/users', params=payload)
print(getdata.url)
输出
E:\prequests>python makeRequest.py https://jsonplaceholder.typicode.com/users?id=9&username=Delphine
处理 HTTP 请求的响应
在本章中,我们将深入了解从 Requests 模块接收到的响应的更多细节。我们将讨论以下内容:
- 获取响应
- JSON 响应
- 原始响应
- 二进制响应
获取响应
我们将使用 request.get() 方法向 URL 发出请求。
import requests getdata = requests.get('https://jsonplaceholder.typicode.com/users');
getdata 函数拥有 response 对象。它包含响应的所有详细信息。我们可以使用 (.text) 和 (.content) 以两种方式获取响应。使用 response.text 将以文本格式返回数据,如下所示:
示例
E:\prequests>python makeRequest.py
[
{
"id": 1,
"name": "Leanne Graham",
"username": "Bret",
"email": "Sincere@april.biz",
"address": {
"street": "Kulas Light",
"suite": "Apt. 556",
"city": "Gwenborough",
"zipcode": "92998-3874",
"geo": {
"lat": "-37.3159",
"lng": "81.1496"
}
},
"phone": "1-770-736-8031 x56442",
"website": "hildegard.org",
"company": {
"name": "Romaguera-Crona",
"catchPhrase": "Multi-layered client-server neural-net",
"bs": "harness real-time e-markets"
}
},
您会看到响应与在浏览器中查看 URL 源代码时显示的相同,如下所示:
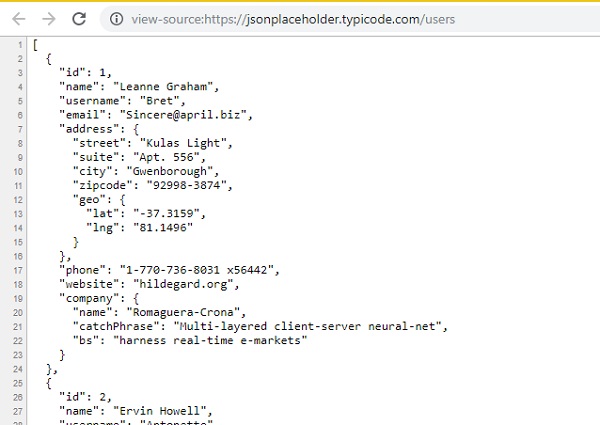
您也可以尝试 .html URL 并使用 response.text 查看内容,它将与浏览器中 .html URL 的源代码内容相同。
现在,让我们尝试对同一个 URL 使用 response.content 并查看输出。
示例
import requests
getdata = requests.get('https://jsonplaceholder.typicode.com/users')
print(getdata.content)
输出
E:\prequests>python makeRequest.py
b'[\n {\n "id": 1,\n "name": "Leanne Graham",\n "username": "Bret",\n
"email": "Sincere@april.biz",\n "address": {\n "street": "Kulas Light
",\n "suite": "Apt. 556",\n "city": "Gwenborough",\n "zipcode": "
92998-3874",\n "geo": {\n "lat": "-37.3159",\n "lng": "81.149
6"\n }\n },\n "phone": "1-770-736-8031 x56442",\n "website": "hild
egard.org",\n "company": {\n "name": "Romaguera-Crona",\n "catchPhr
ase": "Multi-layered client-server neural-net",\n "bs": "harness real-time
e-markets"\n }\n },\n {\n "id": 2,\n "name": "Ervin Howell",\n "us
ername": "Antonette",\n "email": "Shanna@melissa.tv",\n "address": {\n
"street": "Victor Plains",\n "suite": "Suite 879",\n "city": "Wisoky
burgh",\n "zipcode": "90566-7771",\n "geo": {\n "lat": "-43.950
9",\n "lng": "-34.4618"\n }\n },\n "phone": "010-692-6593 x091
25",\n "website": "anastasia.net",\n "company": {\n "name": "Deckow-C
rist",\n "catchPhrase": "Proactive didactic contingency",\n "bs": "syn
ergize scalable supply-chains"\n }\n },\n {\n "id": 3,\n "name": "Cle
mentine Bauch",\n "username": "Samantha",\n "email":
"Nathan@yesenia.net",
\n "address": {\n "street": "Douglas Extension",\n "suite": "Suite
847",\n "city": "McKenziehaven",\n "zipcode": "59590-4157",\n "ge
o": {\n "lat": "-68.6102",\n "lng": "-47.0653"\n }\n },\n
响应以字节形式给出。您将在响应的开头看到字母b。使用 requests 模块,您可以获取使用的编码,并在需要时更改编码。例如,要获取编码,您可以使用 response.encoding。
print(getdata.encoding)
输出
utf-8
您可以按如下方式更改编码:您可以使用您选择的编码。
getdata.encoding = 'ISO-8859-1'
JSON 响应
您还可以通过使用 response.json() 方法以 json 格式获取 Http 请求的响应,如下所示:
示例
import requests
getdata = requests.get('https://jsonplaceholder.typicode.com/users')
print(getdata.json())
输出
E:\prequests>python makeRequest.py
[{'id': 1, 'name': 'Leanne Graham', 'username': 'Bret', 'email': 'Sincere@april.
biz', 'address': {'street': 'Kulas Light', 'suite': 'Apt. 556', 'city': 'Gwenbor
ough', 'zipcode': '92998-3874', 'geo': {'lat': '-37.3159', 'lng': '81.1496'}},
'
phone': '1-770-736-8031 x56442', 'website': 'hildegard.org', 'company': {'name':
'Romaguera-Crona', 'catchPhrase': 'Multi-layered client-server neural-net', 'bs
': 'harness real-time e-markets'}}]
原始响应
如果您需要 Http URL 的原始响应,您可以使用 response.raw,并在 get 方法中添加stream=True,如下所示:
示例
import requests
getdata = requests.get('https://jsonplaceholder.typicode.com/users', stream=True)
print(getdata.raw)
输出
E:\prequests>python makeRequest.py <urllib3.response.HTTPResponse object at 0x000000A8833D7B70>
要从原始数据中读取更多内容,您可以按如下方式操作:
print(getdata.raw.read(50))
输出
E:\prequests>python makeRequest.py b'\x1f\x8b\x08\x00\x00\x00\x00\x00\x00\x03\x95\x98[o\xe38\x12\x85\xdf\xe7W\x10y\ xda\x01F\x82.\xd4m\x9f\xdc\x9dd\xba\xb7\x93\xf4\x06q\xef4\x06\x83A@K\x15\x89m'
二进制响应
要获取二进制响应,我们可以使用 response.content。
示例
import requests
getdata = requests.get('https://jsonplaceholder.typicode.com/users')
print(getdata.content)
输出
E:\prequests>python makeRequest.py
b'[\n {\n "id": 1,\n "name": "Leanne Graham",\n "username": "Bret",\n
"email": "Sincere@april.biz",\n "address": {\n "street": "Kulas Light
",\n "suite": "Apt. 556",\n "city": "Gwenborough",\n "zipcode": "
92998-3874",\n "geo": {\n "lat": "-37.3159",\n "lng": "81.149
6"\n }\n },\n "phone": "1-770-736-8031 x56442",\n "website": "hild
egard.org",\n "company": {\n "name": "Romaguera-Crona",\n "catchPhr
ase": "Multi-layered client-server neural-net",\n "bs": "harness real-time
e-markets"\n }\n },\n {\n "id": 2,\n "name": "Ervin Howell",\n "us
ername": "Antonette",\n "email": "Shanna@melissa.tv",\n "address": {\n
"street": "Victor Plains",\n "suite": "Suite 879",\n "city": "Wisoky
burgh",\n "zipcode": "90566-7771",\n "geo": {\n "lat": "-43.950
9",\n "lng": "-34.4618"\n }\n },\n "phone": "010-692-6593 x091
25",\n "website": "anastasia.net",\n "company": {\n "name": "Deckow-C
rist",\n "catchPhrase": "Proactive didactic contingency",\n "bs": "syn
ergize scalable supply-chains"\n }\n },\n {\n "id": 3,\n "name": "Cle
mentine Bauch",\n "username": "Samantha",\n "email": "Nathan@yesenia.net",
\n "address": {\n "street": "Douglas Extension",\n "suite": "Suite
847",\n "city": "McKenziehaven",\n "zipcode": "59590-4157",\n "ge
o": {\n "lat": "-68.6102",\n "lng": "-47.0653"\n }\n },\n
响应以字节形式给出。您将在响应的开头看到字母b。二进制响应主要用于非文本请求。
Requests - HTTP 请求头
在上一章中,我们已经了解了如何发出请求并获取响应。本章将进一步探讨 URL 的标头部分。因此,我们将研究以下内容:
- 理解请求标头
- 自定义标头
- 响应标头
理解请求标头
在浏览器中点击任意 URL,检查它并在开发者工具的网络选项卡中查看。
您将获得响应标头、请求标头、有效负载等。
例如,请考虑以下 URL:
https://jsonplaceholder.typicode.com/users
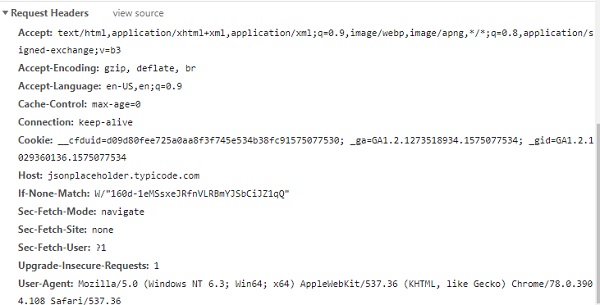
您可以按如下方式获取标头详细信息:
示例
import requests
getdata = requests.get('https://jsonplaceholder.typicode.com/users', stream=True)
print(getdata.headers)
输出
E:\prequests>python makeRequest.py
{'Date': 'Sat, 30 Nov 2019 05:15:00 GMT', 'Content-Type': 'application/json; cha
rset=utf-8', 'Transfer-Encoding': 'chunked', 'Connection': 'keep-alive', 'Set-Co
okie': '__cfduid=d2b84ccf43c40e18b95122b0b49f5cf091575090900; expires=Mon, 30-De
c-19 05:15:00 GMT; path=/; domain=.typicode.com; HttpOnly', 'X-Powered-By': 'Exp
ress', 'Vary': 'Origin, Accept-Encoding', 'Access-Control-Allow-Credentials': 't
rue', 'Cache-Control': 'max-age=14400', 'Pragma': 'no-cache', 'Expires': '-1', '
X-Content-Type-Options': 'nosniff', 'Etag': 'W/"160d-1eMSsxeJRfnVLRBmYJSbCiJZ1qQ
"', 'Content-Encoding': 'gzip', 'Via': '1.1 vegur', 'CF-Cache-Status': 'HIT', 'A
ge': '2271', 'Expect-CT': 'max-age=604800, report-uri="https://report-uri.cloudf
lare.com/cdn-cgi/beacon/expect-ct"', 'Server': 'cloudflare', 'CF-RAY': '53da574f
f99fc331-SIN'}
要读取任何 http 标头,您可以按如下方式操作:
getdata.headers["Content-Encoding"] // gzip
自定义标头
您还可以将标头发送到正在调用的 URL,如下所示。
示例
import requests
headers = {'x-user': 'test123'}
getdata = requests.get('https://jsonplaceholder.typicode.com/users', headers=headers)
传递的标头必须是字符串、字节字符串或 Unicode 格式。请求的行为不会根据传递的自定义标头而改变。
响应标头
当您在浏览器开发者工具的网络选项卡中检查 URL 时,响应标头如下所示:
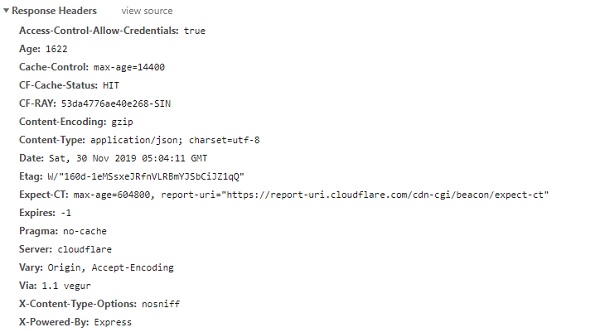
要从 requests 模块获取标头的详细信息,请使用 Response.headers,如下所示:
示例
import requests
getdata = requests.get('https://jsonplaceholder.typicode.com/users')
print(getdata.headers)
输出
E:\prequests>python makeRequest.py
{'Date': 'Sat, 30 Nov 2019 06:08:10 GMT', 'Content-Type': 'application/json; cha
rset=utf-8', 'Transfer-Encoding': 'chunked', 'Connection': 'keep-alive', 'Set-Co
okie': '__cfduid=de1158f1a5116f3754c2c353055694e0d1575094090; expires=Mon, 30-De
c-19 06:08:10 GMT; path=/; domain=.typicode.com; HttpOnly', 'X-Powered-By': 'Exp
ress', 'Vary': 'Origin, Accept-Encoding', 'Access-Control-Allow-Credentials': 't
rue', 'Cache-Control': 'max-age=14400', 'Pragma': 'no-cache', 'Expires': '-1', '
X-Content-Type-Options': 'nosniff', 'Etag': 'W/"160d-1eMSsxeJRfnVLRBmYJSbCiJZ1qQ
"', 'Content-Encoding': 'gzip', 'Via': '1.1 vegur', 'CF-Cache-Status': 'HIT', 'A
ge': '5461', 'Expect-CT': 'max-age=604800, report-uri="https://report-uri.cloudf
lare.com/cdn-cgi/beacon/expect-ct"', 'Server': 'cloudflare', 'CF-RAY': '53daa52f
3b7ec395-SIN'}
您可以按如下方式获取任何所需的特定标头:
print(getdata.headers["Expect-CT"])
输出
max-age=604800, report-uri="https://report-uri.cloudflare.com/cdn-cgi/beacon/exp ect-ct
您还可以使用 get() 方法获取标头详细信息。
print(getdata.headers.get("Expect-CT"))
输出
max-age=604800, report-uri="https://report-uri.cloudflare.com/cdn-cgi/beacon/exp ect-ct
Requests - 处理 GET 请求
本章将重点关注 GET 请求,它是最常见且使用频率最高的请求。GET 在 requests 模块中的工作原理非常简单。以下是一个关于使用 GET 方法处理 URL 的简单示例。
示例
import requests
getdata = requests.get('https://jsonplaceholder.typicode.com/users')
print(getdata.content)
getdata.content, will print all the data available in the response.
输出
E:\prequests>python makeRequest.py
b'[\n {\n "id": 1,\n "name": "Leanne Graham",\n "username": "Bret",\n
"email": "Sincere@april.biz",\n "address": {\n "street": "Kulas Light
",\n "suite": "Apt. 556",\n "city": "Gwenborough",\n "zipcode": "
92998-3874",\n "geo": {\n "lat": "-37.3159",\n "lng": "81.149
6"\n }\n },\n "phone": "1-770-736-8031 x56442",\n "website": "hild
egard.org",\n "company": {\n "name": "Romaguera-Crona",\n "catchPhr
ase": "Multi-layered client-server neural-net",\n "bs": "harness real-time
e-markets"\n }\n }
您还可以使用 param 属性将参数传递给 get 方法,如下所示:
import requests
payload = {'id': 9, 'username': 'Delphine'}
getdata = requests.get('https://jsonplaceholder.typicode.com/users',
params=payload)
print(getdata.content)
详细信息存储在对象 payload 的键值对中,并传递给 get() 方法中的 params。
输出
E:\prequests>python makeRequest.py
b'[\n {\n "id": 9,\n "name": "Glenna Reichert",\n "username": "Delphin
e",\n "email": "Chaim_McDermott@dana.io",\n "address": {\n "street":
"Dayna Park",\n "suite": "Suite 449",\n "city": "Bartholomebury",\n
"zipcode": "76495-3109",\n "geo": {\n "lat": "24.6463",\n
"lng": "-168.8889"\n }\n },\n "phone": "(775)976-6794 x41206",\n "
website": "conrad.com",\n "company": {\n "name": "Yost and Sons",\n
"catchPhrase": "Switchable contextually-based project",\n "bs": "aggregate
real-time technologies"\n }\n }\n]'
处理 POST、PUT、PATCH 和 DELETE 请求
在本章中,我们将了解如何使用 requests 库使用 POST 方法,以及如何将参数传递给 URL。
使用 POST
对于 PUT 请求,Requests 库具有 requests.post() 方法,其示例如下所示
import requests
myurl = 'https://postman-echo.com/post'
myparams = {'name': 'ABC', 'email':'xyz@gmail.com'}
res = requests.post(myurl, data=myparams)
print(res.text)
输出
E:\prequests>python makeRequest.py
{"args":{},"data":"","files":{},"form":{"name":"ABC","email":"xyz@gmail.com"},"headers":{"x-forwarded-proto":"https","host":"postman-echo.com","content-length":"30","accept":"*/*","accept-encoding":"gzip,deflate","content-type":"application/x-www-form-urlencoded","user-agent":"python-requests/2.22.0","x-forwarded-port":"443"},"json":{"name":"ABC","email":"xyz@gmail.com"},"url":"https://postman-echo.com/post"}
在上面显示的示例中,您可以将表单数据作为键值对传递到 requests.post() 中的 data 参数。我们还将了解如何在 requests 模块中使用 PUT、PATCH 和 DELETE。
使用 PUT
对于 PUT 请求,Requests 库具有 requests.put() 方法,其示例如下所示。
import requests
myurl = 'https://postman-echo.com/put'
myparams = {'name': 'ABC', 'email':'xyz@gmail.com'}
res = requests.put(myurl, data=myparams)
print(res.text)
输出
E:\prequests>python makeRequest.py
{"args":{},"data":"","files":{},"form":{"name":"ABC","email":"xyz@gmail.com"},"h
eaders":{"x-forwarded-proto":"https","host":"postman-echo.com","content-length":
"30","accept":"*/*","accept-encoding":"gzip, deflate","content-type":"applicatio
n/x-www-form-urlencoded","user-agent":"python-requests/2.22.0","x-forwarded-port
":"443"},"json":{"name":"ABC","email":"xyz@gmail.com"},"url":"https://postman-ec
ho.com/put"}
使用 PATCH
对于 PATCH 请求,Requests 库具有 requests.patch() 方法,其示例如下所示。
import requests myurl = https://postman-echo.com/patch' res = requests.patch(myurl, data="testing patch") print(res.text)
输出
E:\prequests>python makeRequest.py
{"args":{},"data":{},"files":{},"form":{},"headers":{"x-forwarded-proto":"https"
,"host":"postman-echo.com","content-length":"13","accept":"*/*","accept-encoding
":"gzip, deflate","user-agent":"python-requests/2.22.0","x-forwarded-port":"443"
},"json":null,"url":"https://postman-echo.com/patch"}
使用 DELETE
对于 DELETE 请求,Requests 库具有 requests.delete() 方法,其示例如下所示。
import requests myurl = 'https://postman-echo.com/delete' res = requests.delete(myurl, data="testing delete") print(res.text)
输出
E:\prequests>python makeRequest.py
{"args":{},"data":{},"files":{},"form":{},"headers":{"x-forwarded-proto":"https"
,"host":"postman-echo.com","content-length":"14","accept":"*/*","accept-encoding
":"gzip, deflate","user-agent":"python-requests/2.22.0","x-forwarded-port":"443"
},"json":null,"url":"https://postman-echo.com/delete"}
Requests - 文件上传
在本章中,我们将使用 request 上传文件并读取上传的文件内容。我们可以使用files 参数来实现,如下面的示例所示。
我们将使用http://httpbin.org/post 来上传文件。
示例
import requests myurl = 'https://httpbin.org/post' files = {'file': open('test.txt', 'rb')} getdata = requests.post(myurl, files=files) print(getdata.text)
Test.txt
File upload test using Requests
示例
var total = [0, 1, 2, 3].reduceRight(function(a, b){ return a + b; });
console.log("total is : " + total );
输出
E:\prequests>python makeRequest.py
{
"args": {},
"data": "",
"files": {
"file": "File upload test using Requests"
},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "175",
"Content-Type": "multipart/form-data;
boundary=28aee3a9d15a3571fb80d4d2a94bf
d33",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.22.0"
},
"json": null,
"origin": "117.223.63.135, 117.223.63.135",
"url": "https://httpbin.org/post"
}
也可以按如下方式发送文件内容:
示例
import requests myurl = 'https://httpbin.org/post' files = {'file': ('test1.txt', 'Welcome to TutorialsPoint')} getdata = requests.post(myurl, files=files) print(getdata.text)
输出
E:\prequests>python makeRequest.py
{
"args": {},
"data": "",
"files": {
"file": "Welcome to TutorialsPoint"
},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "170",
"Content-Type": "multipart/form-data; boundary=f2837238286fe40e32080aa7e172b
e4f",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.22.0"
},
"json": null,
"origin": "117.223.63.135, 117.223.63.135",
"url": "https://httpbin.org/post"
}
Requests - 使用 Cookie
本章将讨论如何处理使用 Http 请求库时出现的错误。始终建议对所有可能的情况进行错误管理。
URL https://jsonplaceholder.typicode.com/users 在浏览器中访问时,我们可以获取 cookie 的详细信息,如下所示:
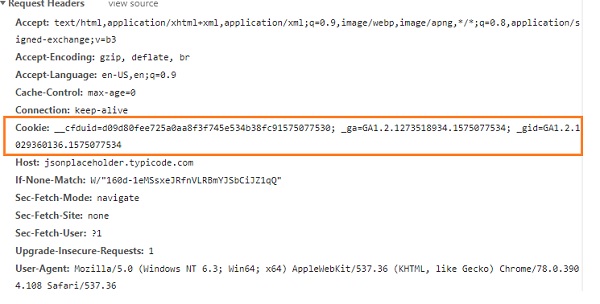
您可以按如下方式读取 cookie:
示例
import requests
getdata = requests.get('https://jsonplaceholder.typicode.com/users')
print(getdata.cookies["__cfduid"])
输出
E:\prequests>python makeRequest.py d1733467caa1e3431fb7f768fa79ed3741575094848
您也可以在发出请求时发送 cookie。
示例
import requests
cookies = dict(test='test123')
getdata = requests.get('https://httpbin.org/cookies',cookies=cookies)
print(getdata.text)
输出
E:\prequests>python makeRequest.py
{
"cookies": {
"test": "test123"
}
}
Requests - 处理错误
本章将讨论如何处理使用 Http 请求库时出现的错误。始终建议对所有可能的情况进行错误管理。
错误异常
requests 模块给出以下类型的错误异常:
ConnectionError - 如果出现任何连接错误,将引发此错误。例如,网络故障、DNS 错误,因此 Request 库将引发 ConnectionError 异常。
Response.raise_for_status() - 基于状态代码(例如 401、404),它将为请求的 URL 引发 HTTPError。
HTTPError - 此错误将针对发出的请求返回的无效响应引发。
Timeout - 为请求的 URL 超时引发的错误。
TooManyRedirects - 如果超过最大重定向限制,则将引发 TooManyRedirects 错误。
示例
以下是一个显示超时错误的示例:
import requests
getdata = requests.get('https://jsonplaceholder.typicode.com/users',timeout=0.001)
print(getdata.text)
输出
raise ConnectTimeout(e, request=request) requests.exceptions.ConnectTimeout: HTTPSConnectionPool(host='jsonplaceholder.ty picode.com', port=443): Max retries exceeded with url: /users (Caused by Connect TimeoutError(<urllib3.connection.VerifiedHTTPSConnection object at 0x000000B02AD E76A0>, 'Connection to jsonplaceholder.typicode.com timed out. (connect timeout= 0.001)'))
Requests - 处理超时
超时可以轻松地添加到您正在请求的 URL 中。有时您使用的是第三方 URL 并等待响应。始终建议在 URL 上设置超时,因为我们可能希望 URL 在一定时间内以响应或错误进行响应。如果不这样做,可能会导致无限期地等待该请求。
我们可以使用 timeout 参数为 URL 设置超时,并将值以秒为单位传递,如下面的示例所示:
示例
import requests
getdata = requests.get('https://jsonplaceholder.typicode.com/users',timeout=0.001)
print(getdata.text)
输出
raise ConnectTimeout(e, request=request) requests.exceptions.ConnectTimeout: HTTPSConnectionPool(host='jsonplaceholder.ty picode.com', port=443): Max retries exceeded with url: /users (Caused by Connect TimeoutError(<urllib3.connection.VerifiedHTTPSConnection object at 0x000000B02AD E76A0>, 'Connection to jsonplaceholder.typicode.com timed out. (connect timeout= 0.001)'))
给定的超时如下:
getdata = requests.get('https://jsonplaceholder.typicode.com/users',timeout=0.001)
执行将抛出连接超时错误,如输出所示。给定的超时为 0.001,这对于请求获取响应并抛出错误是不可能的。现在,我们将增加超时时间并检查。
示例
import requests
getdata = requests.get('https://jsonplaceholder.typicode.com/users',timeout=1.000)
print(getdata.text)
输出
E:\prequests>python makeRequest.py
[
{
"id": 1,
"name": "Leanne Graham",
"username": "Bret",
"email": "Sincere@april.biz",
"address": {
"street": "Kulas Light",
"suite": "Apt. 556",
"city": "Gwenborough",
"zipcode": "92998-3874",
"geo": {
"lat": "-37.3159",
"lng": "81.1496"
}
},
"phone": "1-770-736-8031 x56442",
"website": "hildegard.org",
"company": {
"name": "Romaguera-Crona",
"catchPhrase": "Multi-layered client-server neural-net",
"bs": "harness real-time e-markets"
}
使用 1 秒的超时,我们可以获取请求的 URL 的响应。
Requests - 处理重定向
本章将探讨 Request 库如何处理 URL 重定向情况。
示例
import requests
getdata = requests.get('http://google.com/')
print(getdata.status_code)
print(getdata.history)
URL - http://google.com 将使用状态代码 301(永久移动)重定向到 https://www.google.com/。重定向将保存在历史记录中。
输出
执行上述代码时,我们将获得以下结果:
E:\prequests>python makeRequest.py 200 [<Response [301]>]
您可以使用allow_redirects=False停止 URL 的重定向。这可以在使用的 GET、POST、OPTIONS、PUT、DELETE、PATCH 方法上完成。
示例
以下是一个关于此的示例。import requests
getdata = requests.get('http://google.com/', allow_redirects=False)
print(getdata.status_code)
print(getdata.history)
print(getdata.text)
现在,如果您检查输出,则不会允许重定向,并且将获得 301 的状态代码。
输出
E:\prequests>python makeRequest.py 301 [] <HTML><HEAD><meta http-equiv="content-type" content="text/html;charset=utf-8"> <TITLE>301 Moved</TITLE></HEAD><BODY> <H1>301 Moved</H1> The document has moved <A HREF="http://www.google.com/">here</A>. </BODY></HTML>
Requests - 处理历史记录
您可以使用response.history获取给定 URL 的历史记录。如果给定 URL 存在任何重定向,则它将存储在历史记录中。
对于历史记录
import requests
getdata = requests.get('http://google.com/')
print(getdata.status_code)
print(getdata.history)
输出
E:\prequests>python makeRequest.py 200 [<Response [301]>]
response.history属性将包含基于请求完成的响应对象的详细信息。存在的值将按从旧到新的顺序排序。response.history属性跟踪在请求的 URL 上完成的所有重定向。
Requests - 处理会话
要维护请求之间的数据,您需要会话。因此,如果反复调用同一个主机,您可以重用 TCP 连接,这将提高性能。现在让我们看看如何使用会话维护跨请求的 cookie。
使用会话添加 cookie
import requests
req = requests.Session()
cookies = dict(test='test123')
getdata = req.get('https://httpbin.org/cookies',cookies=cookies)
print(getdata.text)
输出
E:\prequests>python makeRequest.py
{
"cookies": {
"test": "test123"
}
}
使用会话,您可以跨请求保留 cookie 数据。还可以使用会话传递标头数据,如下所示:
示例
import requests
req = requests.Session()
req.headers.update({'x-user1': 'ABC'})
headers = {'x-user2': 'XYZ'}
getdata = req.get('https://httpbin.org/headers', headers=headers)
print(getdata.headers)
Requests - SSL 证书
SSL 证书是安全 URL 附带的安全功能。当您使用 Requests 库时,它还会验证给定的 https URL 的 SSL 证书。SSL 验证在 requests 模块中默认启用,如果证书不存在,它将引发错误。
使用安全 URL
以下是使用安全 URL 的示例:
import requests getdata = requests.get(https://jsonplaceholder.typicode.com/users) print(getdata.text)
输出
E:\prequests>python makeRequest.py
[
{
"id": 1,
"name": "Leanne Graham",
"username": "Bret",
"email": "Sincere@april.biz",
"address": {
"street": "Kulas Light",
"suite": "Apt. 556",
"city": "Gwenborough",
"zipcode": "92998-3874",
"geo": {
"lat": "-37.3159",
"lng": "81.1496"
}
},
"phone": "1-770-736-8031 x56442",
"website": "hildegard.org",
"company": {
"name": "Romaguera-Crona",
"catchPhrase": "Multi-layered client-server neural-net",
"bs": "harness real-time e-markets"
}
}
]
我们很容易从上面的 https URL 获取响应,这是因为 request 模块可以验证 SSL 证书。
您可以通过简单地添加 verify=False 来禁用 SSL 验证,如下面的示例所示。
示例
import requests
getdata = requests.get('https://jsonplaceholder.typicode.com/users', verify=False)
print(getdata.text)
您将获得输出,但它也会显示一条警告消息,指出未验证 SSL 证书,建议添加证书验证。
输出
E:\prequests>python makeRequest.py connectionpool.py:851: InsecureRequestWarning: Unverified HTTPS request is being made. Adding certificate verification is strongly advised. See: https://urllib3 .readthedocs.io/en/latest/advanced-usage.htm l#ssl-warnings InsecureRequestWarning) [ { "id": 1, "name": "Leanne Graham", "username": "Bret", "email": "Sincere@april.biz", "address": { "street": "Kulas Light", "suite": "Apt. 556", "city": "Gwenborough", "zipcode": "92998-3874", "geo": { "lat": "-37.3159", "lng": "81.1496" } }, "phone": "1-770-736-8031 x56442", "website": "hildegard.org", "company": { "name": "Romaguera-Crona", "catchPhrase": "Multi-layered client-server neural-net", "bs": "harness real-time e-markets" } } ]
您还可以通过在您的端托管 SSL 证书,并使用verify参数提供路径来验证 SSL 证书,如下所示。
示例
import requests
getdata = requests.get('https://jsonplaceholder.typicode.com/users', verify='C:\Users\AppData\Local\certificate.txt')
print(getdata.text)
输出
E:\prequests>python makeRequest.py
[
{
"id": 1,
"name": "Leanne Graham",
"username": "Bret",
"email": "Sincere@april.biz",
"address": {
"street": "Kulas Light",
"suite": "Apt. 556",
"city": "Gwenborough",
"zipcode": "92998-3874",
"geo": {
"lat": "-37.3159",
"lng": "81.1496"
}
},
"phone": "1-770-736-8031 x56442",
"website": "hildegard.org",
"company": {
"name": "Romaguera-Crona",
"catchPhrase": "Multi-layered client-server neural-net",
"bs": "harness real-time e-markets"
}
}
]
Requests - 身份验证
本章将讨论 Requests 模块中可用的身份验证类型。
我们将讨论以下内容:
HTTP 请求中的身份验证工作原理
基本身份验证
摘要身份验证
OAuth2 身份验证
HTTP 请求中的身份验证工作原理
HTTP 身份验证位于服务器端,当客户端请求 URL 时,它会要求提供一些身份验证信息,例如用户名和密码。这是对交换的请求和响应的额外安全保障。
从客户端方面,这些额外的身份验证信息(即用户名和密码)可以发送到标头中,稍后服务器端将对其进行验证。只有在身份验证有效时,服务器端才会传递响应。
Requests 库在 requests.auth 中提供了最常用的身份验证,即基本身份验证(HTTPBasicAuth)和摘要身份验证(HTTPDigestAuth)。
基本身份验证
这是向服务器提供身份验证的最简单形式。要使用基本身份验证,我们将使用 requests 库提供的 HTTPBasicAuth 类。
示例
以下是如何使用它的工作示例。
import requests
from requests.auth import HTTPBasicAuth
response_data = requests.get('httpbin.org/basic-auth/admin/admin123', auth=HTTPDigestAuth('admin', 'admin123'))
print(response_data.text)
我们正在调用 URL https://httpbin.org/basic-auth/admin/admin123,其中用户为admin,密码为admin123。
因此,此 URL 在没有身份验证(即用户名和密码)的情况下将无法工作。只有在使用 auth 参数提供身份验证后,服务器才会返回响应。
输出
E:\prequests>python makeRequest.py
{
"authenticated": true,
"user": "admin"
}
摘要身份验证
这是 requests 提供的另一种身份验证形式。我们将使用 requests 的 HTTPDigestAuth 类。
示例
import requests
from requests.auth import HTTPDigestAuth
response_data = requests.get('https://httpbin.org/digest-auth/auth/admin/admin123>, auth=HTTPDigestAuth('admin', 'admin123'))
print(response_data.text)
输出
E:\prequests>python makeRequest.py
{
"authenticated": true,
"user": "admin"
}
OAuth2 身份验证
要使用 OAuth2 身份验证,我们需要“requests_oauth2”库。要安装“requests_oauth2”,请执行以下操作:
pip install requests_oauth2
安装过程中,你的终端显示内容将如下所示:
E:\prequests>pip install requests_oauth2 Collecting requests_oauth2 Downloading https://files.pythonhosted.org/packages/52/dc/01c3c75e6e7341a2c7a9 71d111d7105df230ddb74b5d4e10a3dabb61750c/requests-oauth2-0.3.0.tar.gz Requirement already satisfied: requests in c:\users\xyz\appdata\local\programs \python\python37\lib\site-packages (from requests_oauth2) (2.22.0) Requirement already satisfied: six in c:\users\xyz\appdata\local\programs\pyth on\python37\lib\site-packages (from requests_oauth2) (1.12.0) Requirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in c:\use rs\xyz\appdata\local\programs\python\python37\lib\site-packages (from requests ->requests_oauth2) (1.25.3) Requirement already satisfied: certifi>=2017.4.17 in c:\users\xyz\appdata\loca l\programs\python\python37\lib\site-packages (from requests->requests_oauth2) (2 019.3.9) Requirement already satisfied: chardet<3.1.0,>=3.0.2 in c:\users\xyz\appdata\l ocal\programs\python\python37\lib\site-packages (from requests->requests_oauth2) (3.0.4) Requirement already satisfied: idna<2.9,>=2.5 in c:\users\xyz\appdata\local\pr ograms\python\python37\lib\site-packages (from requests->requests_oauth2) (2.8) Building wheels for collected packages: requests-oauth2 Building wheel for requests-oauth2 (setup.py) ... done Stored in directory: C:\Users\xyz\AppData\Local\pip\Cache\wheels\90\ef\b4\43 3743cbbc488463491da7df510d41c4e5aa28213caeedd586 Successfully built requests-oauth2
我们已完成“requests-oauth2”的安装。为了使用Google、Twitter的API,我们需要它们的授权,而这可以通过OAuth2认证来实现。
对于OAuth2认证,我们需要客户端ID和密钥。获取它们的方法详情,请参考https://developers.google.com/identity/protocols/OAuth2。
之后,登录Google API控制台(网址: https://console.developers.google.com/)并获取客户端ID和密钥。
示例
以下是如何使用“requests-oauth2”的示例。
import requests from requests_oauth2.services import GoogleClient google_auth = GoogleClient( client_id="xxxxxxxxxxxxxxxxxxxxxxxxxx.apps.googleusercontent.com", redirect_uri="https:///auth/success.html", ) a = google_auth.authorize_url( scope=["profile", "email"], response_type="code", ) res = requests.get(a) print(res.url)
我们无法重定向到给定的URL,因为它需要登录Gmail账户,但是从这个示例中,你可以看到google_auth工作正常,并且给出了授权的URL。
输出
E:\prequests>python oauthRequest.py https://#/o/oauth2/auth?redirect_uri= http%3A%2F%2Flocalhost%2Fauth%2Fsuccess.html& client_id=xxxxxxxxxxxxxxxxxxxxx.apps.googleusercontent.com& scope=profile+email&response_type=code
Requests - 事件钩子
我们可以使用事件钩子向请求的URL添加事件。在下面的示例中,我们将添加一个回调函数,当响应可用时会调用该函数。
示例
要添加回调,我们需要使用hooks参数,如下例所示:
mport requests
def printData(r, *args, **kwargs):
print(r.url)
print(r.text)
getdata = requests.get('https://jsonplaceholder.typicode.com/users',
hooks={'response': printData})
输出
E:\prequests>python makeRequest.py https://jsonplaceholder.typicode.com/users [ { "id": 1, "name": "Leanne Graham", "username": "Bret", "email": "Sincere@april.biz", "address": { "street": "Kulas Light", "suite": "Apt. 556", "city": "Gwenborough", "zipcode": "92998-3874", "geo": { "lat": "-37.3159", "lng": "81.1496" } }, "phone": "1-770-736-8031 x56442", "website": "hildegard.org", "company": { "name": "Romaguera-Crona", "catchPhrase": "Multi-layered client-server neural-net", "bs": "harness real-time e-markets" } } ]
你还可以调用多个回调函数,如下所示:
示例
import requests
def printRequestedUrl(r, *args, **kwargs):
print(r.url)
def printData(r, *args, **kwargs):
print(r.text)
getdata = requests.get('https://jsonplaceholder.typicode.com/users', hooks={'response': [printRequestedUrl, printData]})
输出
E:\prequests>python makeRequest.py https://jsonplaceholder.typicode.com/users [ { "id": 1, "name": "Leanne Graham", "username": "Bret", "email": "Sincere@april.biz", "address": { "street": "Kulas Light", "suite": "Apt. 556", "city": "Gwenborough", "zipcode": "92998-3874", "geo": { "lat": "-37.3159", "lng": "81.1496" } }, "phone": "1-770-736-8031 x56442", "website": "hildegard.org", "company": { "name": "Romaguera-Crona", "catchPhrase": "Multi-layered client-server neural-net", "bs": "harness real-time e-markets" } } ]
你也可以将钩子添加到创建的Session中,如下所示:
示例
import requests
def printData(r, *args, **kwargs):
print(r.text)
s = requests.Session()
s.hooks['response'].append(printData)
s.get('https://jsonplaceholder.typicode.com/users')
输出
E:\prequests>python makeRequest.py
[
{
"id": 1,
"name": "Leanne Graham",
"username": "Bret",
"email": "Sincere@april.biz",
"address": {
"street": "Kulas Light",
"suite": "Apt. 556",
"city": "Gwenborough",
"zipcode": "92998-3874",
"geo": {
"lat": "-37.3159",
"lng": "81.1496"
}
},
"phone": "1-770-736-8031 x56442",
"website": "hildegard.org",
"company": {
"name": "Romaguera-Crona",
"catchPhrase": "Multi-layered client-server neural-net",
"bs": "harness real-time e-markets"
}
}
]
Requests - 代理
到目前为止,我们已经看到了客户端直接连接并与服务器通信的情况。使用代理,交互过程如下:
客户端向代理发送请求。
代理将请求发送到服务器。
服务器将响应发送回代理。
代理将响应发送回客户端。
使用Http代理可以提供额外的安全措施来管理客户端和服务器之间的数据交换。requests库也提供了处理代理的功能,使用proxies参数,如下所示:
示例
import requests
proxies = {
'http': 'https://:8080'
}
res = requests.get('http://httpbin.org/', proxies=proxies)
print(res.status_code)
请求将路由到('https://:8080 URL。
输出
200
Requests - 使用 Requests 进行网页抓取
我们已经了解了如何使用Python requests库从给定的URL获取数据。我们将尝试使用以下方法从Tutorialspoint网站(网址:https://tutorialspoint.com/tutorialslibrary.htm)抓取数据:
Requests库
Python的Beautiful Soup库
我们已经安装了Requests库,现在让我们安装Beautiful Soup包。如果你想探索Beautiful Soup的更多功能,可以访问其官方网站:https://www.crummy.com/software/BeautifulSoup/bs4/doc/。
安装Beautifulsoup
我们将看到如何安装Beautiful Soup:
E:\prequests>pip install beautifulsoup4 Collecting beautifulsoup4 Downloading https://files.pythonhosted.org/packages/3b/c8/a55eb6ea11cd7e5ac4ba cdf92bac4693b90d3ba79268be16527555e186f0/beautifulsoup4-4.8.1-py3-none-any.whl ( 101kB) |████████████████████████████████| 102kB 22kB/s Collecting soupsieve>=1.2 (from beautifulsoup4) Downloading https://files.pythonhosted.org/packages/81/94/03c0f04471fc245d08d0 a99f7946ac228ca98da4fa75796c507f61e688c2/soupsieve-1.9.5-py2.py3-none-any.whl Installing collected packages: soupsieve, beautifulsoup4 Successfully installed beautifulsoup4-4.8.1 soupsieve-1.9.5
现在我们已经安装了Python requests库和Beautiful Soup。
现在让我们编写代码,从给定的URL抓取数据。
网页抓取
import requests
from bs4 import BeautifulSoup
res = requests.get('https://tutorialspoint.com/tutorialslibrary.htm')
print("The status code is ", res.status_code)
print("\n")
soup_data = BeautifulSoup(res.text, 'html.parser')
print(soup_data.title)
print("\n")
print(soup_data.find_all('h4'))
使用requests库,我们可以获取给定URL的内容,而Beautiful Soup库则可以解析它并按照我们想要的方式获取详细信息。
你可以使用Beautiful Soup库通过Html标签、类、ID、CSS选择器等多种方式获取数据。以下是我们获得的输出,其中我们打印了页面的标题以及页面上的所有h4标签。
输出
E:\prequests>python makeRequest.py The status code is 200 <title>Free Online Tutorials and Courses</title> [<h4>Academic</h4>, <h4>Computer Science</h4>, <h4>Digital Marketing</h4>, <h4>M onuments</h4>,<h4>Machine Learning</h4>, <h4>Mathematics</h4>, <h4>Mobile Devel opment</h4>,<h4>SAP</h4>, <h4>Software Quality</h4>, <h4>Big Data & Analyti cs</h4>, <h4>Databases</h4>, <h4>Engineering Tutorials</h4>, <h4>Mainframe Devel opment</h4>, <h4>Microsoft Technologies</h4>, <h4>Java Technologies</h4>,<h4>XM L Technologies</h4>, <h4>Python Technologies</h4>, <h4>Sports</h4>, <h4>Computer Programming</h4>,<h4>DevOps</h4>, <h4>Latest Technologies</h4>, <h4>Telecom</h4>, <h4>Exams Syllabus</h4>, <h4>UPSC IAS Exams</h4>, <h4>Web Development</h4>, <h4>Scripts</h4>, <h4>Management</h4>,<h4>Soft Skills</h4>, <h4>Selected Readin g</h4>, <h4>Misc</h4>]