- Ruby 基础
- Ruby - 首页
- Ruby - 概述
- Ruby - 环境设置
- Ruby - 语法
- Ruby - 类和对象
- Ruby - 变量
- Ruby - 运算符
- Ruby - 注释
- Ruby - IF...ELSE
- Ruby - 循环
- Ruby - 方法
- Ruby - 代码块
- Ruby - 模块
- Ruby - 字符串
- Ruby - 数组
- Ruby - 哈希表
- Ruby - 日期和时间
- Ruby - 范围
- Ruby - 迭代器
- Ruby - 文件 I/O
- Ruby - 异常
- Ruby 高级
- Ruby - 面向对象
- Ruby - 正则表达式
- Ruby - 数据库访问
- Ruby - Web 应用
- Ruby - 发送邮件
- Ruby - 套接字编程
- Ruby - Ruby/XML, XSLT
- Ruby - Web 服务
- Ruby - Tk 指南
- Ruby - Ruby/LDAP 教程
- Ruby - 多线程
- Ruby - 内置函数
- Ruby - 预定义变量
- Ruby - 预定义常量
- Ruby - 相关工具
- Ruby 有用资源
- Ruby 快速指南
- Ruby - 有用资源
- Ruby - 讨论
- Ruby - Ruby on Rails 教程
Ruby 快速指南
Ruby - 概述
Ruby 是一种纯面向对象的编程语言。它由日本程序员松本行弘于 1993 年创建。
您可以在 Ruby 邮件列表 www.ruby-lang.org 上找到松本行弘的名字。在 Ruby 社区中,松本行弘也被称为 Matz。
Ruby 是“程序员的最佳朋友”。
Ruby 的功能类似于 Smalltalk、Perl 和 Python。Perl、Python 和 Smalltalk 都是脚本语言。Smalltalk 是一种真正的面向对象语言。Ruby 与 Smalltalk 一样,是一种完美的面向对象语言。使用 Ruby 语法比使用 Smalltalk 语法容易得多。
Ruby 的特性
Ruby 是开源的,并且可以在 Web 上免费获得,但它受许可证约束。
Ruby 是一种通用的解释型编程语言。
Ruby 是一种真正面向对象的编程语言。
Ruby 是一种类似于 Python 和 PERL 的服务器端脚本语言。
Ruby 可用于编写通用网关接口 (CGI) 脚本。
Ruby 可以嵌入到超文本标记语言 (HTML) 中。
Ruby 具有简洁易懂的语法,使新开发者能够非常快速和轻松地学习。
Ruby 的语法类似于许多编程语言,如 C++ 和 Perl。
Ruby 具有很强的可扩展性,用 Ruby 编写的庞大程序易于维护。
Ruby 可用于开发 Internet 和 Intranet 应用程序。
Ruby 可以安装在 Windows 和 POSIX 环境中。
Ruby 支持许多 GUI 工具,如 Tcl/Tk、GTK 和 OpenGL。
Ruby 可以轻松连接到 DB2、MySQL、Oracle 和 Sybase。
Ruby 有一套丰富的内置函数,可以直接在 Ruby 脚本中使用。
您需要的工具
要执行本教程中讨论的示例,您需要一台最新的计算机,例如英特尔酷睿 i3 或 i5,至少 2GB RAM(建议 4GB RAM)。您还需要以下软件:
Linux 或 Windows 95/98/2000/NT 或 Windows 7 操作系统。
Apache 1.3.19-5 Web 服务器。
Internet Explorer 5.0 或更高版本的 Web 浏览器。
Ruby 1.8.5
本教程将提供创建使用 Ruby 的 GUI、网络和 Web 应用程序所需的必要技能。它还将讨论扩展和嵌入 Ruby 应用程序。
接下来是什么?
下一章将指导您如何获取 Ruby 及其文档。最后,它将指导您如何安装 Ruby 并准备一个开发 Ruby 应用程序的环境。
Ruby - 环境设置
本地环境设置
如果您仍然希望为 Ruby 编程语言设置您的环境,那么让我们继续。本教程将教您所有与环境设置相关的重点主题。我们建议您首先浏览以下主题,然后再继续:
在 Linux/Unix 上安装 Ruby - 如果您计划在 Linux/Unix 机器上建立开发环境,请阅读本章。
在 Windows 上安装 Ruby - 如果您计划在 Windows 机器上建立开发环境,请阅读本章。
Ruby 命令行选项 - 本章列出了所有可以与 Ruby 解释器一起使用的命令行选项。
Ruby 环境变量 - 本章列出了所有需要设置的重要环境变量,以使 Ruby 解释器正常工作。
流行的 Ruby 编辑器
要编写 Ruby 程序,您需要一个编辑器:
如果您在 Windows 机器上工作,则可以使用任何简单的文本编辑器,如记事本或 Edit plus。
VIM (Vi IMproved) 是一款非常简单的文本编辑器。它几乎存在于所有 Unix 机器上,现在也适用于 Windows。否则,您可以使用您喜欢的 vi 编辑器来编写 Ruby 程序。
RubyWin 是 Windows 的 Ruby 集成开发环境 (IDE)。
Ruby 开发环境 (RDE) 也是 Windows 用户的非常好的 IDE。
交互式 Ruby (IRb)
交互式 Ruby (IRb) 提供了一个用于实验的 Shell。在 IRb Shell 中,您可以立即逐行查看表达式的结果。
此工具随 Ruby 安装一起提供,因此您无需执行任何额外操作即可使用 IRb。
只需在命令提示符下键入irb,即可启动交互式 Ruby 会话,如下所示:
$irb irb 0.6.1(99/09/16) irb(main):001:0> def hello irb(main):002:1> out = "Hello World" irb(main):003:1> puts out irb(main):004:1> end nil irb(main):005:0> hello Hello World nil irb(main):006:0>
不要担心我们在这里做了什么。您将在后续章节中学习所有这些步骤。
接下来是什么?
我们现在假设您有一个可用的 Ruby 环境,并且您已准备好编写第一个 Ruby 程序。下一章将教您如何编写 Ruby 程序。
Ruby - 语法
让我们在 Ruby 中编写一个简单的程序。所有 Ruby 文件都将具有扩展名.rb。因此,将以下源代码放入 test.rb 文件中。
实时演示#!/usr/bin/ruby -w puts "Hello, Ruby!";
这里,我们假设您在 /usr/bin 目录中提供了 Ruby 解释器。现在,尝试按如下方式运行此程序:
$ ruby test.rb
这将产生以下结果:
Hello, Ruby!
您已经看到了一个简单的 Ruby 程序,现在让我们了解一些与 Ruby 语法相关的基本概念。
Ruby 程序中的空白字符
空格和制表符等空白字符通常在 Ruby 代码中被忽略,除非它们出现在字符串中。但是,有时它们用于解释模棱两可的语句。当启用 -w 选项时,此类解释会产生警告。
示例
a + b is interpreted as a+b ( Here a is a local variable) a +b is interpreted as a(+b) ( Here a is a method call)
Ruby 程序中的行尾
Ruby 将分号和换行符解释为语句的结束。但是,如果 Ruby 在行尾遇到运算符(如 +、- 或反斜杠),则表示语句的继续。
Ruby 标识符
标识符是变量、常量和方法的名称。Ruby 标识符区分大小写。这意味着 Ram 和 RAM 在 Ruby 中是两个不同的标识符。
Ruby 标识符名称可以由字母数字字符和下划线字符(_)组成。
保留字
以下列表显示了 Ruby 中的保留字。这些保留字不能用作常量或变量名。但是,它们可以用作方法名。
| BEGIN | do | next | then |
| END | else | nil | true |
| alias | elsif | not | undef |
| and | end | or | unless |
| begin | ensure | redo | until |
| break | false | rescue | when |
| case | for | retry | while |
| class | if | return | while |
| def | in | self | __FILE__ |
| defined? | module | super | __LINE__ |
Ruby 中的文档
“文档”指的是从多行构建字符串。在 << 后,您可以指定一个字符串或一个标识符来终止字符串文字,并且从当前行到终止符的所有行都是字符串的值。
如果终止符被引用,则引号的类型确定面向行的字符串文字的类型。请注意,<< 和终止符之间不能有空格。
以下是一些不同的示例:
实时演示#!/usr/bin/ruby -w print <<EOF This is the first way of creating here document ie. multiple line string. EOF print <<"EOF"; # same as above This is the second way of creating here document ie. multiple line string. EOF print <<`EOC` # execute commands echo hi there echo lo there EOC print <<"foo", <<"bar" # you can stack them I said foo. foo I said bar. bar
这将产生以下结果:
This is the first way of creating
her document ie. multiple line string.
This is the second way of creating
her document ie. multiple line string.
hi there
lo there
I said foo.
I said bar.
Ruby BEGIN 语句
语法
BEGIN {
code
}
声明在程序运行之前调用的代码。
示例
实时演示#!/usr/bin/ruby
puts "This is main Ruby Program"
BEGIN {
puts "Initializing Ruby Program"
}
这将产生以下结果:
Initializing Ruby Program This is main Ruby Program
Ruby END 语句
语法
END {
code
}
声明在程序结束时调用的代码。
示例
实时演示#!/usr/bin/ruby
puts "This is main Ruby Program"
END {
puts "Terminating Ruby Program"
}
BEGIN {
puts "Initializing Ruby Program"
}
这将产生以下结果:
Initializing Ruby Program This is main Ruby Program Terminating Ruby Program
Ruby 注释
注释隐藏了 Ruby 解释器的一行、一行的一部分或几行。您可以在行的开头使用井号 (#):
# I am a comment. Just ignore me.
或者,注释可以位于语句或表达式之后的同一行:
name = "Madisetti" # This is again comment
您可以按如下方式注释多行:
# This is a comment. # This is a comment, too. # This is a comment, too. # I said that already.
这是另一种形式。此块注释使用 =begin/=end 隐藏了几个解释器行:
=begin This is a comment. This is a comment, too. This is a comment, too. I said that already. =end
Ruby - 类和对象
Ruby 是一种完美的面向对象编程语言。面向对象编程语言的特性包括:
- 数据封装
- 数据抽象
- 多态性
- 继承
这些特性已在 面向对象 Ruby 一章中讨论。
面向对象程序涉及类和对象。类是创建单个对象的蓝图。用面向对象的术语来说,我们说您的自行车是称为自行车的对象类的一个实例。
以任何车辆为例,它包含车轮、马力和燃油或油箱容量。这些特征构成了类 Vehicle 的数据成员。您可以借助这些特征来区分不同的车辆。
车辆还可以具有一些功能,例如停止、驾驶和加速。即使这些功能也构成了类 Vehicle 的数据成员。因此,您可以将类定义为特征和功能的组合。
类 Vehicle 可以定义为 -
Class Vehicle {
Number no_of_wheels
Number horsepower
Characters type_of_tank
Number Capacity
Function speeding {
}
Function driving {
}
Function halting {
}
}
通过为这些数据成员分配不同的值,您可以形成类 Vehicle 的多个实例。例如,飞机有三个轮子,马力为 1000,燃料为油箱类型,容量为 100 升。同样,汽车有四个轮子,马力为 200,汽油为油箱类型,容量为 25 升。
在 Ruby 中定义类
要使用 Ruby 实现面向对象编程,您首先需要学习如何在 Ruby 中创建对象和类。
Ruby 中的类总是以关键字class开头,后跟类名。名称始终应以大写字母开头。类Customer可以显示为 -
class Customer end
您使用关键字end终止类。class中的所有数据成员都位于类定义和end关键字之间。
Ruby 类中的变量
Ruby 提供四种类型的变量 -
局部变量 - 局部变量是在方法中定义的变量。局部变量在方法外部不可用。您将在后续章节中看到有关方法的更多详细信息。局部变量以小写字母或 _ 开头。
实例变量 - 实例变量在任何特定实例或对象的各种方法中都可用。这意味着实例变量因对象而异。实例变量前面是 at 符号 (@),后跟变量名。
类变量 - 类变量在不同的对象之间可用。类变量属于类,是类的特征。它们前面是符号 @@,后跟变量名。
全局变量 - 类变量在类之间不可用。如果要有一个在类之间可用的单个变量,则需要定义一个全局变量。全局变量始终以美元符号 ($) 开头。
示例
使用类变量 @@no_of_customers,您可以确定正在创建的对象的数量。这使得能够推导出客户的数量。
class Customer @@no_of_customers = 0 end
使用 new 方法在 Ruby 中创建对象
对象是类的实例。您现在将学习如何在 Ruby 中创建类的对象。您可以使用类的new方法在 Ruby 中创建对象。
new方法是一种独特的类型方法,它是在 Ruby 库中预定义的。new 方法属于class方法。
以下是如何创建类 Customer 的两个对象 cust1 和 cust2 的示例 -
cust1 = Customer. new cust2 = Customer. new
这里,cust1 和 cust2 是两个对象的名。您在对象名称后写上等号 (=),然后是类名。然后,点运算符和关键字new将紧随其后。
创建 Ruby 对象的自定义方法
您可以将参数传递给new方法,这些参数可用于初始化类变量。
当您计划声明带有参数的new方法时,需要在类创建时声明initialize方法。
initialize方法是一种特殊类型的方法,当使用参数调用类的new方法时,它将被执行。
以下是如何创建 initialize 方法的示例 -
class Customer
@@no_of_customers = 0
def initialize(id, name, addr)
@cust_id = id
@cust_name = name
@cust_addr = addr
end
end
在此示例中,您声明了initialize方法,其中id、name和addr作为局部变量。这里,def和end用于定义 Ruby 方法initialize。您将在后续章节中学习更多有关方法的信息。
在initialize方法中,您将这些局部变量的值传递给实例变量 @cust_id、@cust_name 和 @cust_addr。这里局部变量保存与 new 方法一起传递的值。
现在,您可以按如下方式创建对象 -
cust1 = Customer.new("1", "John", "Wisdom Apartments, Ludhiya")
cust2 = Customer.new("2", "Poul", "New Empire road, Khandala")
Ruby 类中的成员函数
在 Ruby 中,函数称为方法。class中的每个方法都以关键字def开头,后跟方法名。
方法名始终以小写字母为佳。您使用关键字end结束 Ruby 中的方法。
以下是如何定义 Ruby 方法的示例 -
class Sample
def function
statement 1
statement 2
end
end
这里,statement 1和statement 2是类 Sample 内function方法主体的一部分。这些语句可以是任何有效的 Ruby 语句。例如,我们可以使用方法puts打印Hello Ruby,如下所示 -
class Sample
def hello
puts "Hello Ruby!"
end
end
现在在以下示例中,创建一个 Sample 类的对象并调用hello方法,查看结果 -
实时演示#!/usr/bin/ruby
class Sample
def hello
puts "Hello Ruby!"
end
end
# Now using above class to create objects
object = Sample. new
object.hello
这将产生以下结果:
Hello Ruby!
简单案例研究
如果您想对类和对象进行更多练习,以下是一个案例研究。
Ruby - 变量、常量和字面量
变量是内存位置,用于保存任何程序要使用的数据。
Ruby 支持五种类型的变量。您已经在上一章中了解了这些变量的简要说明。本章将详细解释这五种类型的变量。
Ruby 全局变量
全局变量以 $ 开头。未初始化的全局变量的值为 nil,并且在使用 -w 选项时会产生警告。
对全局变量的赋值会更改全局状态。不建议使用全局变量。它们使程序变得难以理解。
以下是一个显示全局变量用法的示例。
实时演示#!/usr/bin/ruby
$global_variable = 10
class Class1
def print_global
puts "Global variable in Class1 is #$global_variable"
end
end
class Class2
def print_global
puts "Global variable in Class2 is #$global_variable"
end
end
class1obj = Class1.new
class1obj.print_global
class2obj = Class2.new
class2obj.print_global
这里 $global_variable 是一个全局变量。这将产生以下结果 -
注意 - 在 Ruby 中,您可以通过在变量或常量之前放置一个哈希 (#) 字符来访问任何变量或常量的值。
Global variable in Class1 is 10 Global variable in Class2 is 10
Ruby 实例变量
实例变量以 @ 开头。未初始化的实例变量的值为nil,并且在使用 -w 选项时会产生警告。
以下是一个显示实例变量用法的示例。
实时演示#!/usr/bin/ruby
class Customer
def initialize(id, name, addr)
@cust_id = id
@cust_name = name
@cust_addr = addr
end
def display_details()
puts "Customer id #@cust_id"
puts "Customer name #@cust_name"
puts "Customer address #@cust_addr"
end
end
# Create Objects
cust1 = Customer.new("1", "John", "Wisdom Apartments, Ludhiya")
cust2 = Customer.new("2", "Poul", "New Empire road, Khandala")
# Call Methods
cust1.display_details()
cust2.display_details()
这里,@cust_id、@cust_name 和 @cust_addr 是实例变量。这将产生以下结果 -
Customer id 1 Customer name John Customer address Wisdom Apartments, Ludhiya Customer id 2 Customer name Poul Customer address New Empire road, Khandala
Ruby 类变量
类变量以 @@ 开头,并且必须在可以在方法定义中使用之前进行初始化。
引用未初始化的类变量会产生错误。类变量在定义类变量的类或模块的后代之间共享。
覆盖类变量会产生带有 -w 选项的警告。
以下是一个显示类变量用法的示例 -
实时演示#!/usr/bin/ruby
class Customer
@@no_of_customers = 0
def initialize(id, name, addr)
@cust_id = id
@cust_name = name
@cust_addr = addr
end
def display_details()
puts "Customer id #@cust_id"
puts "Customer name #@cust_name"
puts "Customer address #@cust_addr"
end
def total_no_of_customers()
@@no_of_customers += 1
puts "Total number of customers: #@@no_of_customers"
end
end
# Create Objects
cust1 = Customer.new("1", "John", "Wisdom Apartments, Ludhiya")
cust2 = Customer.new("2", "Poul", "New Empire road, Khandala")
# Call Methods
cust1.total_no_of_customers()
cust2.total_no_of_customers()
这里 @@no_of_customers 是一个类变量。这将产生以下结果 -
Total number of customers: 1 Total number of customers: 2
Ruby 局部变量
局部变量以小写字母或 _ 开头。局部变量的作用域从类、模块、def 或 do 到相应的 end,或从块的起始花括号到结束花括号 {}。
当引用未初始化的局部变量时,它会被解释为对没有参数的方法的调用。
对未初始化的局部变量的赋值也充当变量声明。变量从存在到当前作用域结束。局部变量的生命周期由 Ruby 在解析程序时确定。
在上面的示例中,局部变量是 id、name 和 addr。
Ruby 常量
常量以大写字母开头。在类或模块内定义的常量可以从该类或模块内部访问,在类或模块外部定义的常量可以在全局范围内访问。
常量不能在方法内定义。引用未初始化的常量会产生错误。对已初始化的常量进行赋值会产生警告。
实时演示#!/usr/bin/ruby
class Example
VAR1 = 100
VAR2 = 200
def show
puts "Value of first Constant is #{VAR1}"
puts "Value of second Constant is #{VAR2}"
end
end
# Create Objects
object = Example.new()
object.show
这里 VAR1 和 VAR2 是常量。这将产生以下结果 -
Value of first Constant is 100 Value of second Constant is 200
Ruby 伪变量
它们是具有局部变量外观但行为类似于常量的特殊变量。您不能为这些变量分配任何值。
self - 当前方法的接收者对象。
true - 表示真的值。
false - 表示假的的值。
nil - 表示未定义的值。
__FILE__ - 当前源文件的名称。
__LINE__ - 源文件中的当前行号。
Ruby 基本字面量
Ruby 用于字面量的规则简单直观。本节解释所有基本的 Ruby 字面量。
整数
Ruby 支持整数。整数的范围可以从 -230 到 230-1 或 -262 到 262-1。在此范围内的整数是类Fixnum的对象,在此范围之外的整数存储在类Bignum的对象中。
您可以使用可选的前导符号、可选的基数指示符(0 表示八进制、0x 表示十六进制或 0b 表示二进制),后跟适当基数的数字字符串来编写整数。下划线字符在数字字符串中被忽略。
您还可以获取与 ASCII 字符对应的整数值,或者通过在其前面加上问号来转义该序列。
示例
123 # Fixnum decimal 1_234 # Fixnum decimal with underline -500 # Negative Fixnum 0377 # octal 0xff # hexadecimal 0b1011 # binary ?a # character code for 'a' ?\n # code for a newline (0x0a) 12345678901234567890 # Bignum
注意 - 类和对象在本教程的单独章节中进行了解释。
浮点数
Ruby 支持浮点数。它们也是数字,但带有小数。浮点数是类Float的对象,可以是以下任何一种 -
示例
123.4 # floating point value 1.0e6 # scientific notation 4E20 # dot not required 4e+20 # sign before exponential
字符串字面量
Ruby 字符串只是 8 位字节的序列,它们是类 String 的对象。双引号字符串允许替换和反斜杠表示法,但单引号字符串不允许替换,仅允许对 \\ 和 \' 使用反斜杠表示法。
示例
实时演示#!/usr/bin/ruby -w puts 'escape using "\\"'; puts 'That\'s right';
这将产生以下结果:
escape using "\" That's right
您可以使用序列#{ expr }将任何 Ruby 表达式的值替换到字符串中。这里,expr 可以是任何 Ruby 表达式。
实时演示#!/usr/bin/ruby -w
puts "Multiplication Value : #{24*60*60}";
这将产生以下结果:
Multiplication Value : 86400
反斜杠表示法
以下是 Ruby 支持的反斜杠表示法列表 -
| 符号表示 | 表示的字符 |
|---|---|
| \n | 换行符 (0x0a) |
| \r | 回车符 (0x0d) |
| \f | 换页符 (0x0c) |
| \b | 退格符 (0x08) |
| \a | 响铃 (0x07) |
| \e | 转义符 (0x1b) |
| \s | 空格 (0x20) |
| \nnn | 八进制表示法 (n 为 0-7) |
| \xnn | 十六进制表示法 (n 为 0-9、a-f 或 A-F) |
| \cx, \C-x | 控制-x |
| \M-x | Meta-x (c | 0x80) |
| \M-\C-x | Meta-Control-x |
| \x | 字符 x |
有关 Ruby 字符串的更多详细信息,请参阅 Ruby 字符串。
Ruby 数组
Ruby 数组的字面量是通过将一系列以逗号分隔的对象引用放在方括号之间创建的。尾随逗号将被忽略。
示例
实时演示#!/usr/bin/ruby ary = [ "fred", 10, 3.14, "This is a string", "last element", ] ary.each do |i| puts i end
这将产生以下结果:
fred 10 3.14 This is a string last element
有关 Ruby 数组的更多详细信息,请参阅 Ruby 数组。
Ruby 哈希
Ruby 哈希的字面量是通过将键/值对列表放在大括号之间创建的,键和值之间可以使用逗号或序列 =>。尾随逗号将被忽略。
示例
实时演示#!/usr/bin/ruby
hsh = colors = { "red" => 0xf00, "green" => 0x0f0, "blue" => 0x00f }
hsh.each do |key, value|
print key, " is ", value, "\n"
end
这将产生以下结果:
red is 3840 green is 240 blue is 15
有关 Ruby 哈希的更多详细信息,请参阅 Ruby 哈希。
Ruby 范围
范围表示一个区间,它是一组具有起始值和结束值的数值。可以使用 s..e 和 s...e 字面量或 Range.new 构造范围。
使用 .. 构造的范围从起始值到结束值(包括结束值)。使用 ... 创建的范围不包括结束值。当用作迭代器时,范围将返回序列中的每个值。
范围 (1..5) 表示它包含 1、2、3、4、5 个值,范围 (1...5) 表示它包含 1、2、3、4 个值。
示例
实时演示#!/usr/bin/ruby (10..15).each do |n| print n, ' ' end
这将产生以下结果:
10 11 12 13 14 15
有关 Ruby 范围的更多详细信息,请参阅 Ruby 范围。
Ruby - 运算符
Ruby 支持丰富的运算符集,正如您对现代语言的期望一样。大多数运算符实际上是方法调用。例如,a + b 被解释为 a.+(b),其中变量 a 所引用的对象中的 + 方法被调用,b 作为其参数。
对于每个运算符 (+ - * / % ** & | ^ << >> && ||),都有一种相应的简写赋值运算符形式(+= -= 等)。
Ruby 算术运算符
假设变量 a 为 10,变量 b 为 20,则 −
| 运算符 | 描述 | 示例 |
|---|---|---|
| + | 加法 − 将运算符两侧的值相加。 | a + b 将得到 30 |
| 减法 | 减法 − 从左操作数中减去右操作数。 | a - b 将得到 -10 |
| * | 乘法 − 将运算符两侧的值相乘。 | a * b 将得到 200 |
| / | 除法 − 将左操作数除以右操作数。 | b / a 将得到 2 |
| % | 取模 − 将左操作数除以右操作数并返回余数。 | b % a 将得到 0 |
| ** | 指数 − 对运算符执行指数(幂)计算。 | a**b 将得到 10 的 20 次幂 |
Ruby 比较运算符
假设变量 a 为 10,变量 b 为 20,则 −
| 运算符 | 描述 | 示例 |
|---|---|---|
| == | 检查两个操作数的值是否相等,如果相等,则条件为真。 | (a == b) 不为真。 |
| != | 检查两个操作数的值是否不相等,如果不相等,则条件为真。 | (a != b) 为真。 |
| > | 检查左操作数的值是否大于右操作数的值,如果大于,则条件为真。 | (a > b) 不为真。 |
| < | 检查左操作数的值是否小于右操作数的值,如果小于,则条件为真。 | (a < b) 为真。 |
| >= | 检查左操作数的值是否大于或等于右操作数的值,如果大于或等于,则条件为真。 | (a >= b) 不为真。 |
| <= | 检查左操作数的值是否小于或等于右操作数的值,如果小于或等于,则条件为真。 | (a <= b) 为真。 |
| <=> | 组合比较运算符。如果第一个操作数等于第二个操作数,则返回 0;如果第一个操作数大于第二个操作数,则返回 1;如果第一个操作数小于第二个操作数,则返回 -1。 | (a <=> b) 返回 -1。 |
| === | 用于在 case 语句的 when 子句中测试相等性。 | (1...10) === 5 返回 true。 |
| .eql? | 如果接收者和参数具有相同的类型和相等的值,则返回 true。 | 1 == 1.0 返回 true,但 1.eql?(1.0) 返回 false。 |
| equal? | 如果接收者和参数具有相同的对象 ID,则返回 true。 | 如果 aObj 是 bObj 的副本,则 aObj == bObj 为 true,a.equal?bObj 为 false,但 a.equal?aObj 为 true。 |
Ruby 赋值运算符
假设变量 a 为 10,变量 b 为 20,则 −
| 运算符 | 描述 | 示例 |
|---|---|---|
| = | 简单赋值运算符,将值从右侧操作数赋值给左侧操作数。 | c = a + b 将 a + b 的值赋给 c |
| += | 加法并赋值运算符,将右操作数加到左操作数上并将结果赋值给左操作数。 | c += a 等价于 c = c + a |
| -= | 减法并赋值运算符,从左操作数中减去右操作数并将结果赋值给左操作数。 | c -= a 等价于 c = c - a |
| *= | 乘法并赋值运算符,将右操作数乘以左操作数并将结果赋值给左操作数。 | c *= a 等价于 c = c * a |
| /= | 除法并赋值运算符,将左操作数除以右操作数并将结果赋值给左操作数。 | c /= a 等价于 c = c / a |
| %= | 取模并赋值运算符,使用两个操作数进行取模并将结果赋值给左操作数。 | c %= a 等价于 c = c % a |
| **= | 指数并赋值运算符,对运算符执行指数(幂)计算并将值赋值给左操作数。 | c **= a 等价于 c = c ** a |
Ruby 并行赋值
Ruby 还支持变量的并行赋值。这使得可以使用一行 Ruby 代码初始化多个变量。例如 −
a = 10 b = 20 c = 30
可以使用并行赋值更快地声明此内容 −
a, b, c = 10, 20, 30
并行赋值也可用于交换两个变量中保存的值 −
a, b = b, c
Ruby 位运算符
位运算符作用于位并执行逐位运算。
假设 a = 60;b = 13;现在,以二进制格式,它们将如下所示 −
a = 0011 1100 b = 0000 1101 ------------------ a&b = 0000 1100 a|b = 0011 1101 a^b = 0011 0001 ~a = 1100 0011
Ruby 语言支持以下位运算符。
| 运算符 | 描述 | 示例 |
|---|---|---|
| & | 二进制 AND 运算符如果位同时存在于两个操作数中,则将其复制到结果中。 | (a & b) 将得到 12,即 0000 1100 |
| | | 二进制 OR 运算符如果位存在于任何一个操作数中,则将其复制。 | (a | b) 将得到 61,即 0011 1101 |
| ^ | 二进制 XOR 运算符如果位在一个操作数中设置,但在另一个操作数中未设置,则将其复制。 | (a ^ b) 将得到 49,即 0011 0001 |
| ~ | 二进制一补码运算符是单目运算符,其作用是“翻转”位。 | (~a ) 将得到 -61,由于带符号二进制数,因此在 2 的补码形式中为 1100 0011。 |
| << | 二进制左移运算符。左操作数的值向左移动由右操作数指定的位数。 | a << 2 将得到 240,即 1111 0000 |
| >> | 二进制右移运算符。左操作数的值向右移动由右操作数指定的位数。 | a >> 2 将得到 15,即 0000 1111 |
Ruby 逻辑运算符
Ruby 语言支持以下逻辑运算符
假设变量 a 为 10,变量 b 为 20,则 −
| 运算符 | 描述 | 示例 |
|---|---|---|
| and | 称为逻辑 AND 运算符。如果两个操作数都为真,则条件为真。 | (a and b) 为真。 |
| or | 称为逻辑 OR 运算符。如果两个操作数中的任何一个非零,则条件为真。 | (a or b) 为真。 |
| && | 称为逻辑 AND 运算符。如果两个操作数都非零,则条件为真。 | (a && b) 为真。 |
| || | 称为逻辑 OR 运算符。如果两个操作数中的任何一个非零,则条件为真。 | (a || b) 为真。 |
| ! | 称为逻辑 NOT 运算符。用于反转其操作数的逻辑状态。如果条件为真,则逻辑 NOT 运算符将使其变为假。 | !(a && b) 为假。 |
| not | 称为逻辑 NOT 运算符。用于反转其操作数的逻辑状态。如果条件为真,则逻辑 NOT 运算符将使其变为假。 | not(a && b) 为假。 |
Ruby 三元运算符
还有一个称为三元运算符的运算符。它首先评估表达式的真假值,然后根据评估结果执行两个给定语句之一。条件运算符具有以下语法 −
| 运算符 | 描述 | 示例 |
|---|---|---|
| ? : | 条件表达式 | 如果条件为真 ? 则为值 X : 否则为值 Y |
Ruby 范围运算符
Ruby 中的序列范围用于创建一系列连续的值 - 由起始值、结束值和介于两者之间的值范围组成。
在 Ruby 中,这些序列是使用 ".." 和 "..." 范围运算符创建的。两点形式创建包含范围,而三点形式创建不包括指定的高值的范围。
| 运算符 | 描述 | 示例 |
|---|---|---|
| .. | 创建从起始点到结束点(包括结束点)的范围。 | 1..10 创建从 1 到 10(包括 10)的范围。 |
| ... | 创建从起始点到结束点(不包括结束点)的范围。 | 1...10 创建从 1 到 9 的范围。 |
Ruby defined? 运算符
defined? 是一个特殊的运算符,它采用方法调用的形式来确定传递的表达式是否已定义。它返回表达式的描述字符串,或者如果表达式未定义,则返回 nil。
defined? 运算符有多种用法
用法 1
defined? variable # True if variable is initialized
例如
foo = 42 defined? foo # => "local-variable" defined? $_ # => "global-variable" defined? bar # => nil (undefined)
用法 2
defined? method_call # True if a method is defined
例如
defined? puts # => "method" defined? puts(bar) # => nil (bar is not defined here) defined? unpack # => nil (not defined here)
用法 3
# True if a method exists that can be called with super user defined? super
例如
defined? super # => "super" (if it can be called) defined? super # => nil (if it cannot be)
用法 4
defined? yield # True if a code block has been passed
例如
defined? yield # => "yield" (if there is a block passed) defined? yield # => nil (if there is no block)
Ruby 点 "." 和双冒号 "::" 运算符
通过在模块方法名称前加上模块名称和一个句点来调用模块方法,并使用模块名称和两个冒号来引用常量。
:: 是一个一元运算符,它允许:在类或模块中定义的常量、实例方法和类方法从类或模块外部的任何地方访问。
请记住在 Ruby 中,类和方法也可以被视为常量。
您只需要在 :: Const_name 前加上返回相应类或模块对象的表达式即可。
如果未使用前缀表达式,则默认使用主 Object 类。
以下提供两个示例 −
MR_COUNT = 0 # constant defined on main Object class module Foo MR_COUNT = 0 ::MR_COUNT = 1 # set global count to 1 MR_COUNT = 2 # set local count to 2 end puts MR_COUNT # this is the global constant puts Foo::MR_COUNT # this is the local "Foo" constant
第二个示例
CONST = ' out there'
class Inside_one
CONST = proc {' in there'}
def where_is_my_CONST
::CONST + ' inside one'
end
end
class Inside_two
CONST = ' inside two'
def where_is_my_CONST
CONST
end
end
puts Inside_one.new.where_is_my_CONST
puts Inside_two.new.where_is_my_CONST
puts Object::CONST + Inside_two::CONST
puts Inside_two::CONST + CONST
puts Inside_one::CONST
puts Inside_one::CONST.call + Inside_two::CONST
Ruby 运算符优先级
下表列出了所有运算符,从最高优先级到最低优先级。
| 方法 | 运算符 | 描述 |
|---|---|---|
| 是 | :: | 常量解析运算符 |
| 是 | [ ] [ ]= | 元素引用、元素设置 |
| 是 | ** | 指数(乘方) |
| 是 | ! ~ + - | 非、补码、一元加号和减号(后两者的方法名称为 +@ 和 -@) |
| 是 | * / % | 乘、除和取模 |
| 是 | + - | 加法和减法 |
| 是 | >> << | 右移和左移 |
| 是 | & | 按位“AND” |
| 是 | ^ | | 按位异或“OR”和常规“OR” |
| 是 | <= < > >= | 比较运算符 |
| 是 | <=> == === != =~ !~ | 相等性和模式匹配运算符(!= 和 !~ 可能未定义为方法) |
| && | 逻辑“AND” | |
| || | 逻辑“OR” | |
| .. ... | 范围(包含和排除) | |
| ? | 三元 if-then-else | |
| = %= { /= -= += |= &= >>= <<= *= &&= ||= **= | 赋值 | |
| defined? | 检查指定的符号是否已定义 | |
| not | 逻辑否定 | |
| or 和 | 逻辑组合 |
注意 − 方法列中为“是”的运算符实际上是方法,因此可以被覆盖。
Ruby - 注释
注释是在 Ruby 代码中运行时被忽略的批注行。单行注释以 # 字符开头,并从 # 扩展到行尾,如下所示 −
实时演示#!/usr/bin/ruby -w # This is a single line comment. puts "Hello, Ruby!"
执行上述程序时,将产生以下结果 −
Hello, Ruby!
Ruby 多行注释
您可以使用 =begin 和 =end 语法注释多行,如下所示 −
实时演示#!/usr/bin/ruby -w puts "Hello, Ruby!" =begin This is a multiline comment and con spwan as many lines as you like. But =begin and =end should come in the first line only. =end
执行上述程序时,将产生以下结果 −
Hello, Ruby!
确保尾随注释与代码之间留有足够的间距,并且易于区分。如果一个代码块中存在多个尾随注释,则应将其对齐。例如:
@counter # keeps track times page has been hit @siteCounter # keeps track of times all pages have been hit
Ruby - if...else、case、unless
Ruby 提供了在现代语言中相当常见的条件结构。在这里,我们将解释 Ruby 中所有可用的条件语句和修饰符。
Ruby if...else 语句
语法
if conditional [then] code... [elsif conditional [then] code...]... [else code...] end
if 表达式用于条件执行。false 和 nil 的值为假,其他所有值都为真。请注意,Ruby 使用 elsif,而不是 else if 或 elif。
如果 条件 为真,则执行 代码。如果 条件 不为真,则执行 else 子句中指定的 代码。
if 表达式的 条件 与代码之间用保留字 then、换行符或分号分隔。
示例
实时演示#!/usr/bin/ruby x = 1 if x > 2 puts "x is greater than 2" elsif x <= 2 and x!=0 puts "x is 1" else puts "I can't guess the number" end
x is 1
Ruby if 修饰符
语法
code if condition
如果 条件 为真,则执行 代码。
示例
实时演示#!/usr/bin/ruby $debug = 1 print "debug\n" if $debug
这将产生以下结果:
debug
Ruby unless 语句
语法
unless conditional [then] code [else code ] end
如果 条件 为假,则执行 代码。如果 条件 为真,则执行 else 子句中指定的代码。
示例
实时演示#!/usr/bin/ruby x = 1 unless x>=2 puts "x is less than 2" else puts "x is greater than 2" end
这将产生以下结果:
x is less than 2
Ruby unless 修饰符
语法
code unless conditional
如果 条件 为假,则执行 代码。
示例
实时演示#!/usr/bin/ruby $var = 1 print "1 -- Value is set\n" if $var print "2 -- Value is set\n" unless $var $var = false print "3 -- Value is set\n" unless $var
这将产生以下结果:
1 -- Value is set 3 -- Value is set
Ruby case 语句
语法
case expression [when expression [, expression ...] [then] code ]... [else code ] end
使用 === 运算符比较 case 指定的 表达式 和 when 指定的 表达式,并执行与之匹配的 when 子句的 代码。
when 子句指定的 表达式 作为左操作数进行评估。如果没有任何 when 子句匹配,则 case 执行 else 子句的代码。
when 语句的表达式与代码之间用保留字 then、换行符或分号分隔。因此:
case expr0 when expr1, expr2 stmt1 when expr3, expr4 stmt2 else stmt3 end
基本上类似于以下内容:
_tmp = expr0 if expr1 === _tmp || expr2 === _tmp stmt1 elsif expr3 === _tmp || expr4 === _tmp stmt2 else stmt3 end
示例
实时演示#!/usr/bin/ruby $age = 5 case $age when 0 .. 2 puts "baby" when 3 .. 6 puts "little child" when 7 .. 12 puts "child" when 13 .. 18 puts "youth" else puts "adult" end
这将产生以下结果:
little child
Ruby - 循环
Ruby 中的循环用于执行相同的代码块指定的次数。本章详细介绍了 Ruby 支持的所有循环语句。
Ruby while 语句
语法
while conditional [do] code end
当 条件 为真时执行 代码。while 循环的 条件 与 代码 之间用保留字 do、换行符、反斜杠 \ 或分号 ; 分隔。
示例
实时演示#!/usr/bin/ruby
$i = 0
$num = 5
while $i < $num do
puts("Inside the loop i = #$i" )
$i +=1
end
这将产生以下结果:
Inside the loop i = 0 Inside the loop i = 1 Inside the loop i = 2 Inside the loop i = 3 Inside the loop i = 4
Ruby while 修饰符
语法
code while condition OR begin code end while conditional
当 条件 为真时执行 代码。
如果 while 修饰符跟随 begin 语句,并且没有 rescue 或 ensure 子句,则在评估条件之前会执行一次 代码。
示例
实时演示#!/usr/bin/ruby
$i = 0
$num = 5
begin
puts("Inside the loop i = #$i" )
$i +=1
end while $i < $num
这将产生以下结果:
Inside the loop i = 0 Inside the loop i = 1 Inside the loop i = 2 Inside the loop i = 3 Inside the loop i = 4
Ruby until 语句
until conditional [do] code end
当 条件 为假时执行 代码。until 语句的条件与代码之间用保留字 do、换行符或分号分隔。
示例
实时演示#!/usr/bin/ruby
$i = 0
$num = 5
until $i > $num do
puts("Inside the loop i = #$i" )
$i +=1;
end
这将产生以下结果:
Inside the loop i = 0 Inside the loop i = 1 Inside the loop i = 2 Inside the loop i = 3 Inside the loop i = 4 Inside the loop i = 5
Ruby until 修饰符
语法
code until conditional OR begin code end until conditional
当 条件 为假时执行 代码。
如果 until 修饰符跟随 begin 语句,并且没有 rescue 或 ensure 子句,则在评估条件之前会执行一次 代码。
示例
实时演示#!/usr/bin/ruby
$i = 0
$num = 5
begin
puts("Inside the loop i = #$i" )
$i +=1;
end until $i > $num
这将产生以下结果:
Inside the loop i = 0 Inside the loop i = 1 Inside the loop i = 2 Inside the loop i = 3 Inside the loop i = 4 Inside the loop i = 5
Ruby for 语句
语法
for variable [, variable ...] in expression [do] code end
为 表达式 中的每个元素执行一次 代码。
示例
实时演示#!/usr/bin/ruby
for i in 0..5
puts "Value of local variable is #{i}"
end
在这里,我们定义了范围 0..5。语句 for i in 0..5 将允许 i 取 0 到 5(包括 5)范围内的值。这将产生以下结果:
Value of local variable is 0 Value of local variable is 1 Value of local variable is 2 Value of local variable is 3 Value of local variable is 4 Value of local variable is 5
for...in 循环几乎完全等效于以下内容:
(expression).each do |variable[, variable...]| code end
除了 for 循环不会为局部变量创建新的作用域之外。for 循环的 表达式 与 代码 之间用保留字 do、换行符或分号分隔。
示例
实时演示#!/usr/bin/ruby
(0..5).each do |i|
puts "Value of local variable is #{i}"
end
这将产生以下结果:
Value of local variable is 0 Value of local variable is 1 Value of local variable is 2 Value of local variable is 3 Value of local variable is 4 Value of local variable is 5
Ruby break 语句
语法
break
终止最内部的循环。如果在块内调用(方法返回 nil),则终止与关联块关联的方法。
示例
实时演示#!/usr/bin/ruby
for i in 0..5
if i > 2 then
break
end
puts "Value of local variable is #{i}"
end
这将产生以下结果:
Value of local variable is 0 Value of local variable is 1 Value of local variable is 2
Ruby next 语句
语法
next
跳到最内部循环的下一个迭代。如果在块内调用(yield 或调用返回 nil),则终止块的执行。
示例
实时演示#!/usr/bin/ruby
for i in 0..5
if i < 2 then
next
end
puts "Value of local variable is #{i}"
end
这将产生以下结果:
Value of local variable is 2 Value of local variable is 3 Value of local variable is 4 Value of local variable is 5
Ruby redo 语句
语法
redo
重新启动最内部循环的此迭代,而不检查循环条件。如果在块内调用,则重新启动 yield 或 call。
示例
#!/usr/bin/ruby
for i in 0..5
if i < 2 then
puts "Value of local variable is #{i}"
redo
end
end
这将产生以下结果,并将进入无限循环:
Value of local variable is 0 Value of local variable is 0 ............................
Ruby retry 语句
语法
retry
如果 retry 出现在 begin 表达式的 rescue 子句中,则从 begin 主体的开头重新开始。
begin do_something # exception raised rescue # handles error retry # restart from beginning end
如果 retry 出现在迭代器、块或 for 表达式的正文中,则重新启动迭代器调用的调用。迭代器的参数将重新评估。
for i in 1..5 retry if some_condition # restart from i == 1 end
示例
#!/usr/bin/ruby
for i in 0..5
retry if i > 2
puts "Value of local variable is #{i}"
end
这将产生以下结果,并将进入无限循环:
Value of local variable is 1 Value of local variable is 2 Value of local variable is 1 Value of local variable is 2 Value of local variable is 1 Value of local variable is 2 ............................
Ruby - 方法
Ruby 方法与任何其他编程语言中的函数非常相似。Ruby 方法用于将一个或多个可重复语句捆绑到一个单元中。
方法名称应以小写字母开头。如果使用方法名称以大写字母开头,Ruby 可能会认为它是一个常量,因此可能会错误地解析调用。
应在调用方法之前定义方法,否则 Ruby 将引发未定义方法调用的异常。
语法
def method_name [( [arg [= default]]...[, * arg [, &expr ]])] expr.. end
因此,您可以按如下方式定义一个简单的方法:
def method_name expr.. end
您可以这样表示接受参数的方法:
def method_name (var1, var2) expr.. end
您可以为参数设置默认值,如果在不传递所需参数的情况下调用方法,则将使用这些默认值:
def method_name (var1 = value1, var2 = value2) expr.. end
无论何时调用简单方法,都只需编写方法名称,如下所示:
method_name
但是,当您使用方法和参数调用方法时,您需要编写方法名称以及参数,例如:
method_name 25, 30
使用带参数的方法最重要的缺点是,无论何时调用此类方法,都需要记住参数的数量。例如,如果一个方法接受三个参数,而您只传递了两个,则 Ruby 会显示错误。
示例
实时演示#!/usr/bin/ruby
def test(a1 = "Ruby", a2 = "Perl")
puts "The programming language is #{a1}"
puts "The programming language is #{a2}"
end
test "C", "C++"
test
这将产生以下结果:
The programming language is C The programming language is C++ The programming language is Ruby The programming language is Perl
方法的返回值
Ruby 中的每个方法默认都返回一个值。此返回值将是最后一条语句的值。例如:
def test i = 100 j = 10 k = 0 end
此方法在被调用时将返回最后声明的变量 k。
Ruby return 语句
ruby 中的 return 语句用于从 Ruby 方法返回一个或多个值。
语法
return [expr[`,' expr...]]
如果给出了两个以上的表达式,则包含这些值的数组将是返回值。如果没有给出表达式,则 nil 将是返回值。
示例
return OR return 12 OR return 1,2,3
请查看此示例:
实时演示#!/usr/bin/ruby def test i = 100 j = 200 k = 300 return i, j, k end var = test puts var
这将产生以下结果:
100 200 300
可变数量的参数
假设您声明一个接受两个参数的方法,无论何时调用此方法,都需要同时传递两个参数。
但是,Ruby 允许您声明可以使用可变数量的参数的方法。让我们检查一下这个示例:
实时演示#!/usr/bin/ruby
def sample (*test)
puts "The number of parameters is #{test.length}"
for i in 0...test.length
puts "The parameters are #{test[i]}"
end
end
sample "Zara", "6", "F"
sample "Mac", "36", "M", "MCA"
在此代码中,您声明了一个接受一个参数 test 的方法 sample。但是,此参数是一个可变参数。这意味着此参数可以接收任意数量的变量。因此,以上代码将产生以下结果:
The number of parameters is 3 The parameters are Zara The parameters are 6 The parameters are F The number of parameters is 4 The parameters are Mac The parameters are 36 The parameters are M The parameters are MCA
类方法
当在类定义之外定义方法时,默认情况下该方法被标记为 private。另一方面,在类定义中定义的方法默认标记为 public。方法的默认可见性和 private 标记可以通过模块的 public 或 private 进行更改。
无论何时要访问类的某个方法,都需要先实例化该类。然后,使用该对象,您可以访问类的任何成员。
Ruby 提供了一种无需实例化类即可访问方法的方式。让我们看看如何声明和访问类方法:
class Accounts def reading_charge end def Accounts.return_date end end
请参阅方法 return_date 的声明方式。它以类名称后跟一个点声明,后跟方法名称。您可以直接访问此类方法,如下所示:
Accounts.return_date
要访问此方法,您无需创建 Accounts 类的对象。
Ruby alias 语句
这为方法或全局变量提供别名。别名不能在方法体内定义。即使方法被覆盖,方法的别名也会保留方法的当前定义。
禁止为编号的全局变量($1、$2 等)创建别名。覆盖内置全局变量可能会导致严重问题。
语法
alias method-name method-name alias global-variable-name global-variable-name
示例
alias foo bar alias $MATCH $&
在这里,我们为 bar 定义了 foo 别名,而 $MATCH 是 $& 的别名。
Ruby undef 语句
这取消了方法定义。undef 不能出现在方法体内。
通过使用 undef 和 alias,可以独立于超类修改类的接口,但请注意,它可能会因对 self 的内部方法调用而破坏程序。
语法
undef method-name
示例
要取消定义名为 bar 的方法,请执行以下操作:
undef bar
Ruby - 代码块
您已经了解了 Ruby 如何定义方法,您可以在其中放置多个语句,然后调用该方法。同样,Ruby 也有一个块的概念。
块由代码块组成。
您为块分配一个名称。
块中的代码始终括在括号 ({}) 内。
块始终从与块名称相同的函数中调用。这意味着,如果您有一个名为 test 的块,那么您将使用函数 test 来调用此块。
您可以使用 yield 语句调用块。
语法
block_name {
statement1
statement2
..........
}
在这里,您将学习如何使用简单的 yield 语句调用块。您还将学习如何使用方法带参数的 yield 语句来调用块。您将使用这两种类型的 yield 语句检查示例代码。
yield 语句
让我们看一个 yield 语句的示例:
实时演示#!/usr/bin/ruby
def test
puts "You are in the method"
yield
puts "You are again back to the method"
yield
end
test {puts "You are in the block"}
这将产生以下结果:
You are in the method You are in the block You are again back to the method You are in the block
您还可以使用 yield 语句传递参数。这是一个示例:
实时演示#!/usr/bin/ruby
def test
yield 5
puts "You are in the method test"
yield 100
end
test {|i| puts "You are in the block #{i}"}
这将产生以下结果:
You are in the block 5 You are in the method test You are in the block 100
在这里,yield 语句后跟参数。您甚至可以传递多个参数。在块中,您在两个垂直线 (||) 之间放置一个变量来接收参数。因此,在前面的代码中,yield 5 语句将值 5 作为参数传递给 test 块。
现在,看看以下语句:
test {|i| puts "You are in the block #{i}"}
在这里,值 5 将被接收在变量 i 中。现在,观察以下 puts 语句:
puts "You are in the block #{i}"
此 puts 语句的输出为:
You are in the block 5
如果要传递多个参数,则 yield 语句变为:
yield a, b
并且块为:
test {|a, b| statement}
参数将用逗号分隔。
块和方法
您已经了解了块和方法如何相互关联。您通常使用 yield 语句从与块名称相同的名称的方法中调用块。因此,您编写:
实时演示#!/usr/bin/ruby
def test
yield
end
test{ puts "Hello world"}
此示例是实现块的最简单方法。您使用 yield 语句调用 test 块。
但是,如果方法的最后一个参数前面有 &,则可以将块传递给此方法,并且此块将分配给最后一个参数。如果 * 和 & 都出现在参数列表中,则 & 应放在后面。
实时演示#!/usr/bin/ruby
def test(&block)
block.call
end
test { puts "Hello World!"}
这将产生以下结果:
Hello World!
BEGIN 和 END 块
每个 Ruby 源文件都可以声明代码块,以便在加载文件时(BEGIN 块)和程序执行完成后(END 块)运行。
实时演示#!/usr/bin/ruby
BEGIN {
# BEGIN block code
puts "BEGIN code block"
}
END {
# END block code
puts "END code block"
}
# MAIN block code
puts "MAIN code block"
程序可能包含多个 BEGIN 和 END 块。BEGIN 块按遇到的顺序执行。END 块以相反的顺序执行。执行时,上述程序产生以下结果:
BEGIN code block MAIN code block END code block
Ruby - 模块和 Mixin
模块是将方法、类和常量组合在一起的一种方式。模块为您提供了两个主要好处。
模块提供 命名空间 并防止名称冲突。
模块实现 mixin 功能。
模块定义了一个命名空间,一个沙盒,您的方法和常量可以在其中运行,而无需担心会被其他方法和常量覆盖。
语法
module Identifier statement1 statement2 ........... end
模块常量的命名方式与类常量相同,都以大写字母开头。方法定义也类似:模块方法的定义方式与类方法相同。
与类方法一样,您可以通过在方法名称前面加上模块名称和一个点来调用模块方法,并且您可以使用模块名称和两个冒号来引用常量。
示例
#!/usr/bin/ruby # Module defined in trig.rb file module Trig PI = 3.141592654 def Trig.sin(x) # .. end def Trig.cos(x) # .. end end
我们可以使用相同函数名称但功能不同的方式定义另一个模块:
#!/usr/bin/ruby # Module defined in moral.rb file module Moral VERY_BAD = 0 BAD = 1 def Moral.sin(badness) # ... end end
与类方法一样,无论何时在模块中定义方法,都需要指定模块名称,后跟一个点,然后是方法名称。
Ruby require 语句
require 语句类似于 C 和 C++ 的 include 语句以及 Java 的 import 语句。如果第三个程序想要使用任何已定义的模块,它只需使用 Ruby 的require语句加载模块文件即可。
语法
require filename
这里,不需要在文件名后面加上.rb扩展名。
示例
$LOAD_PATH << '.' require 'trig.rb' require 'moral' y = Trig.sin(Trig::PI/4) wrongdoing = Moral.sin(Moral::VERY_BAD)
这里我们使用$LOAD_PATH << '.'让 Ruby 知道包含的文件必须在当前目录中搜索。如果您不想使用 $LOAD_PATH,则可以使用require_relative从相对目录包含文件。
重要 - 这里,两个文件都包含相同的函数名。因此,这会导致在调用程序中包含时出现代码歧义,但模块避免了这种代码歧义,并且我们能够使用模块名称调用相应的函数。
Ruby include 语句
您可以在类中嵌入模块。要在类中嵌入模块,请在类中使用include语句。
语法
include modulename
如果模块在单独的文件中定义,则在将模块嵌入类之前,需要使用require语句包含该文件。
示例
考虑以下在support.rb文件中编写的模块。
module Week
FIRST_DAY = "Sunday"
def Week.weeks_in_month
puts "You have four weeks in a month"
end
def Week.weeks_in_year
puts "You have 52 weeks in a year"
end
end
现在,您可以按如下方式将此模块包含在类中:
#!/usr/bin/ruby
$LOAD_PATH << '.'
require "support"
class Decade
include Week
no_of_yrs = 10
def no_of_months
puts Week::FIRST_DAY
number = 10*12
puts number
end
end
d1 = Decade.new
puts Week::FIRST_DAY
Week.weeks_in_month
Week.weeks_in_year
d1.no_of_months
这将产生以下结果:
Sunday You have four weeks in a month You have 52 weeks in a year Sunday 120
Ruby 中的 Mixin
在阅读本节之前,我们假设您已了解面向对象的概念。
当一个类可以从多个父类继承特性时,该类应该表现出多重继承。
Ruby 不直接支持多重继承,但 Ruby 模块还有另一个奇妙的用途。一举解决了对多重继承的需求,提供了一种称为mixin的功能。
Mixin 为您提供了一种极佳的控制方式来向类添加功能。但是,当 mixin 中的代码开始与使用它的类中的代码交互时,它们真正的力量就会显现出来。
让我们检查以下示例代码以了解 mixin:
module A def a1 end def a2 end end module B def b1 end def b2 end end class Sample include A include B def s1 end end samp = Sample.new samp.a1 samp.a2 samp.b1 samp.b2 samp.s1
模块 A 包含方法 a1 和 a2。模块 B 包含方法 b1 和 b2。类 Sample 包含模块 A 和 B。类 Sample 可以访问所有四个方法,即 a1、a2、b1 和 b2。因此,您可以看到类 Sample 从这两个模块继承。因此,您可以说类 Sample 显示了多重继承或mixin。
Ruby - 字符串
Ruby 中的字符串对象保存和操作一个或多个字节的任意序列,通常表示代表人类语言的字符。
最简单的字符串字面量用单引号(撇号字符)括起来。引号内的文本是字符串的值。
'This is a simple Ruby string literal'
如果需要在单引号字符串字面量中放置撇号,请在其前面加上反斜杠,以便 Ruby 解释器不会认为它终止了字符串。
'Won\'t you read O\'Reilly\'s book?'
反斜杠也可用于转义另一个反斜杠,以便第二个反斜杠本身不被解释为转义字符。
以下是 Ruby 中与字符串相关的功能。
表达式替换
表达式替换是一种使用 #{ 和 } 将任何 Ruby 表达式的值嵌入到字符串中的方法。
实时演示#!/usr/bin/ruby
x, y, z = 12, 36, 72
puts "The value of x is #{ x }."
puts "The sum of x and y is #{ x + y }."
puts "The average was #{ (x + y + z)/3 }."
这将产生以下结果:
The value of x is 12. The sum of x and y is 48. The average was 40.
通用分隔字符串
使用通用分隔字符串,您可以在一对匹配的任意分隔符字符(例如!、(、{、< 等)内创建字符串,这些字符前面是百分号字符 (%)。Q、q 和 x 具有特殊含义。通用分隔字符串可以是:
%{Ruby is fun.} equivalent to "Ruby is fun."
%Q{ Ruby is fun. } equivalent to " Ruby is fun. "
%q[Ruby is fun.] equivalent to a single-quoted string
%x!ls! equivalent to back tick command output `ls`
转义字符
字符编码
Ruby 的默认字符集是 ASCII,其字符可以用单个字节表示。如果您使用 UTF-8 或其他现代字符集,则字符可以用 1 到 4 个字节表示。
您可以在程序开头使用 $KCODE 更改字符集,如下所示:
$KCODE = 'u'
字符串内置方法
我们需要有一个字符串对象的实例才能调用字符串方法。以下是创建字符串对象实例的方法:
new [String.new(str = "")]
这将返回一个新的字符串对象,其中包含str的副本。现在,使用str对象,我们可以使用任何可用的实例方法。例如:
实时演示#!/usr/bin/ruby
myStr = String.new("THIS IS TEST")
foo = myStr.downcase
puts "#{foo}"
这将产生以下结果:
this is test
String 解包指令
示例
尝试以下示例以解包各种数据。
"abc \0\0abc \0\0".unpack('A6Z6') #=> ["abc", "abc "]
"abc \0\0".unpack('a3a3') #=> ["abc", " \000\000"]
"abc \0abc \0".unpack('Z*Z*') #=> ["abc ", "abc "]
"aa".unpack('b8B8') #=> ["10000110", "01100001"]
"aaa".unpack('h2H2c') #=> ["16", "61", 97]
"\xfe\xff\xfe\xff".unpack('sS') #=> [-2, 65534]
"now = 20is".unpack('M*') #=> ["now is"]
"whole".unpack('xax2aX2aX1aX2a') #=> ["h", "e", "l", "l", "o"]
Ruby - 数组
Ruby 数组是有序的、整数索引的任何对象的集合。数组中的每个元素都与一个索引相关联并由其引用。
数组索引从 0 开始,如 C 或 Java 中一样。负索引假定相对于数组的末尾——即,索引 -1 指示数组的最后一个元素,-2 是数组的倒数第二个元素,依此类推。
Ruby 数组可以存储各种对象,例如字符串 (String)、整数 (Integer)、Fixnum、哈希 (Hash)、符号 (Symbol),甚至其他数组对象。Ruby 数组不像其他语言中的数组那样严格。在向 Ruby 数组添加元素时,它会自动增长。
创建数组
有很多方法可以创建或初始化数组。其中一种方法是使用 new 类方法 -
names = Array.new
您可以在创建数组时设置数组的大小 -
names = Array.new(20)
数组 names 现在具有 20 个元素的大小或长度。您可以使用 size 或 length 方法返回数组的大小 -
实时演示#!/usr/bin/ruby names = Array.new(20) puts names.size # This returns 20 puts names.length # This also returns 20
这将产生以下结果:
20 20
您可以如下为数组中的每个元素分配一个值 -
实时演示#!/usr/bin/ruby
names = Array.new(4, "mac")
puts "#{names}"
这将产生以下结果:
["mac", "mac", "mac", "mac"]
您还可以使用带 new 的代码块,用代码块计算出的结果填充每个元素 -
实时演示#!/usr/bin/ruby
nums = Array.new(10) { |e| e = e * 2 }
puts "#{nums}"
这将产生以下结果:
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
数组还有另一种方法,即 []。它的工作方式如下 -
nums = Array.[](1, 2, 3, 4,5)
数组创建的另一种形式如下 -
nums = Array[1, 2, 3, 4,5]
核心 Ruby 中可用的 Kernel 模块有一个 Array 方法,它只接受一个参数。在这里,该方法将范围作为参数来创建一个数字数组 -
实时演示#!/usr/bin/ruby
digits = Array(0..9)
puts "#{digits}"
这将产生以下结果:
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
数组内置方法
我们需要有一个 Array 对象的实例才能调用 Array 方法。正如我们所见,以下是创建 Array 对象实例的方法 -
Array.[](...) [or] Array[...] [or] [...]
这将返回一个使用给定对象填充的新数组。现在,使用创建的对象,我们可以调用任何可用的实例方法。例如 -
实时演示#!/usr/bin/ruby
digits = Array(0..9)
num = digits.at(6)
puts "#{num}"
这将产生以下结果:
6
Array pack 指令
示例
尝试以下示例来打包各种数据。
实时演示a = [ "a", "b", "c" ]
n = [ 65, 66, 67 ]
puts a.pack("A3A3A3") #=> "a b c "
puts a.pack("a3a3a3") #=> "a\000\000b\000\000c\000\000"
puts n.pack("ccc") #=> "ABC"
这将产生以下结果:
a b c abc ABC
Ruby - 哈希表
Hash是一个键值对的集合,例如:"employee" => "salary"。它类似于数组,但索引是通过任何对象类型的任意键完成的,而不是整数索引。
通过键或值遍历哈希的顺序可能看起来是任意的,并且通常不会按插入顺序排列。如果您尝试使用不存在的键访问哈希,则该方法将返回nil。
创建哈希
与数组一样,创建哈希有多种方法。您可以使用new类方法创建空哈希 -
months = Hash.new
您还可以使用new创建具有默认值的哈希,否则默认为nil -
months = Hash.new( "month" ) or months = Hash.new "month"
当您访问具有默认值的哈希中的任何键时,如果键或值不存在,访问哈希将返回默认值 -
实时演示#!/usr/bin/ruby
months = Hash.new( "month" )
puts "#{months[0]}"
puts "#{months[72]}"
这将产生以下结果:
month month实时演示
#!/usr/bin/ruby
H = Hash["a" => 100, "b" => 200]
puts "#{H['a']}"
puts "#{H['b']}"
这将产生以下结果:
100 200
您可以使用任何Ruby对象作为键或值,甚至数组,因此以下示例是有效的 -
[1,"jan"] => "January"
Hash内置方法
我们需要有一个Hash对象的实例才能调用Hash方法。正如我们所见,以下是创建Hash对象实例的方法 -
Hash[[key =>|, value]* ] or
Hash.new [or] Hash.new(obj) [or]
Hash.new { |hash, key| block }
这将返回一个使用给定对象填充的新哈希。现在使用创建的对象,我们可以调用任何可用的实例方法。例如 -
实时演示#!/usr/bin/ruby
$, = ", "
months = Hash.new( "month" )
months = {"1" => "January", "2" => "February"}
keys = months.keys
puts "#{keys}"
这将产生以下结果:
["1", "2"]
以下是公共哈希方法(假设hash是数组对象) -
| 序号 | 方法和描述 |
|---|---|
| 1 | hash == other_hash 测试两个哈希是否相等,基于它们是否具有相同数量的键值对,以及键值对是否与每个哈希中的对应对匹配。 |
| 2 | hash.[key] 使用键从哈希中引用值。如果找不到键,则返回默认值。 |
| 3 | hash.[key] = value 将value给出的值与key给出的键关联。 |
| 4 | hash.clear 从哈希中移除所有键值对。 |
| 5 | hash.default(key = nil) 返回hash的默认值,如果未由default=设置则返回nil。([]如果键不存在于hash中,则返回默认值。) |
| 6 | hash.default = obj 设置hash的默认值。 |
| 7 | hash.default_proc 如果hash是由块创建的,则返回一个块。 |
| 8 | hash.delete(key) [或] array.delete(key) { |key| block } 通过key从hash中删除键值对。如果使用块,则如果未找到对则返回块的结果。比较delete_if。 |
| 9 | hash.delete_if { |key,value| block } 对于块计算结果为true的每个对,从hash中删除键值对。 |
| 10 | hash.each { |key,value| block } 迭代hash,为每个键调用块一次,并将键值作为两个元素的数组传递。 |
| 11 | hash.each_key { |key| block } 迭代hash,为每个键调用块一次,并将key作为参数传递。 |
| 12 | hash.each_key { |key_value_array| block } 迭代hash,为每个key调用块一次,并将key和value作为参数传递。 |
| 13 | hash.each_key { |value| block } 迭代hash,为每个key调用块一次,并将value作为参数传递。 |
| 14 | hash.empty? 测试哈希是否为空(不包含任何键值对),返回true或false。 |
| 15 | hash.fetch(key [, default] ) [或] hash.fetch(key) { | key | block } 从hash中返回给定key的值。如果找不到key,并且没有其他参数,则引发IndexError异常;如果给出了default,则返回它;如果指定了可选块,则返回其结果。 |
| 16 | hash.has_key?(key) [或] hash.include?(key) [或] hash.key?(key) [或] hash.member?(key) 测试给定的key是否出现在哈希中,返回true或false。 |
| 17 | hash.has_value?(value) 测试哈希是否包含给定的value。 |
| 18 | hash.index(value) 返回哈希中给定value的key,如果未找到匹配的值则返回nil。 |
| 19 | hash.indexes(keys) 返回一个新数组,其中包含给定键的值。将为未找到的键插入默认值。此方法已弃用。使用select。 |
| 20 | hash.indices(keys) 返回一个新数组,其中包含给定键的值。将为未找到的键插入默认值。此方法已弃用。使用select。 |
| 21 | hash.inspect 返回哈希的漂亮打印字符串版本。 |
| 22 | hash.invert 创建一个新的hash,反转hash中的keys和values;也就是说,在新哈希中,hash中的键变为值,值变为键。 |
| 23 | hash.keys 创建一个包含hash中键的新数组。 |
| 24 | hash.length 返回hash的大小或长度,作为一个整数。 |
| 25 | hash.merge(other_hash) [或] hash.merge(other_hash) { |key, oldval, newval| block } 返回一个新哈希,其中包含hash和other_hash的内容,用other_hash中的内容覆盖hash中具有重复键的对。 |
| 26 | hash.merge!(other_hash) [或] hash.merge!(other_hash) { |key, oldval, newval| block } 与merge相同,但更改是在原地进行的。 |
| 27 | hash.rehash 根据每个key的当前值重建hash。如果值自插入以来已更改,则此方法会重新索引hash。 |
| 28 | hash.reject { |key, value| block } 为block计算结果为true的每个对创建一个新的hash |
| 29 | hash.reject! { |key, value| block } 与reject相同,但更改是在原地进行的。 |
| 30 | hash.replace(other_hash) 用other_hash的内容替换hash的内容。 |
| 31 | hash.select { |key, value| block } 返回一个新数组,其中包含hash中block返回true的键值对。 |
| 32 | hash.shift 从hash中移除键值对,并将其作为两个元素的数组返回。 |
| 33 | hash.size 返回hash的大小或长度,作为一个整数。 |
| 34 | hash.sort 将hash转换为一个包含键值对数组的二维数组,然后将其作为数组排序。 |
| 35 | hash.store(key, value) 在hash中存储键值对。 |
| 36 | hash.to_a 从哈希创建二维数组。每个键/值对都转换为数组,所有这些数组都存储在一个包含数组中。 |
| 37 | hash.to_hash 返回hash(self)。 |
| 38 | hash.to_s 将hash转换为数组,然后将该数组转换为字符串。 |
| 39 | hash.update(other_hash) [或] hash.update(other_hash) {|key, oldval, newval| block} 返回一个新哈希,其中包含hash和other_hash的内容,用other_hash中的内容覆盖hash中具有重复键的对。 |
| 40 | hash.value?(value) 测试hash是否包含给定的value。 |
| 41 | hash.values 返回一个包含hash所有值的新数组。 |
| 42 | hash.values_at(obj, ...) 返回一个新数组,其中包含与给定键或键关联的hash中的值。 |
Ruby - 日期和时间
Time 类表示 Ruby 中的日期和时间。它是在操作系统提供的系统日期和时间功能之上的一层薄薄的封装。此类可能无法在您的系统上表示 1970 年之前或 2038 年之后的日期。
本章使您熟悉日期和时间的所有最需要的概念。
获取当前日期和时间
以下是获取当前日期和时间的简单示例:
实时演示#!/usr/bin/ruby -w time1 = Time.new puts "Current Time : " + time1.inspect # Time.now is a synonym: time2 = Time.now puts "Current Time : " + time2.inspect
这将产生以下结果:
Current Time : Mon Jun 02 12:02:39 -0700 2008 Current Time : Mon Jun 02 12:02:39 -0700 2008
获取日期和时间的组成部分
我们可以使用Time对象获取日期和时间的各种组成部分。以下是显示相同内容的示例:
实时演示#!/usr/bin/ruby -w time = Time.new # Components of a Time puts "Current Time : " + time.inspect puts time.year # => Year of the date puts time.month # => Month of the date (1 to 12) puts time.day # => Day of the date (1 to 31 ) puts time.wday # => 0: Day of week: 0 is Sunday puts time.yday # => 365: Day of year puts time.hour # => 23: 24-hour clock puts time.min # => 59 puts time.sec # => 59 puts time.usec # => 999999: microseconds puts time.zone # => "UTC": timezone name
这将产生以下结果:
Current Time : Mon Jun 02 12:03:08 -0700 2008 2008 6 2 1 154 12 3 8 247476 UTC
Time.utc、Time.gm 和 Time.local 函数
这两个函数可用于如下格式化日期为标准格式:
# July 8, 2008 Time.local(2008, 7, 8) # July 8, 2008, 09:10am, local time Time.local(2008, 7, 8, 9, 10) # July 8, 2008, 09:10 UTC Time.utc(2008, 7, 8, 9, 10) # July 8, 2008, 09:10:11 GMT (same as UTC) Time.gm(2008, 7, 8, 9, 10, 11)
以下是如何以以下格式获取数组中所有组件的示例:
[sec,min,hour,day,month,year,wday,yday,isdst,zone]
尝试以下操作:
实时演示#!/usr/bin/ruby -w time = Time.new values = time.to_a p values
这将生成以下结果:
[26, 10, 12, 2, 6, 2008, 1, 154, false, "MST"]
此数组可以传递给Time.utc或Time.local函数以获取日期的不同格式,如下所示:
实时演示#!/usr/bin/ruby -w time = Time.new values = time.to_a puts Time.utc(*values)
这将生成以下结果:
Mon Jun 02 12:15:36 UTC 2008
以下是获取自(平台相关的)纪元以来以秒为单位表示的时间的方式:
# Returns number of seconds since epoch time = Time.now.to_i # Convert number of seconds into Time object. Time.at(time) # Returns second since epoch which includes microseconds time = Time.now.to_f
时区和夏令时
您可以使用Time对象获取与时区和夏令时相关的所有信息,如下所示:
time = Time.new # Here is the interpretation time.zone # => "UTC": return the timezone time.utc_offset # => 0: UTC is 0 seconds offset from UTC time.zone # => "PST" (or whatever your timezone is) time.isdst # => false: If UTC does not have DST. time.utc? # => true: if t is in UTC time zone time.localtime # Convert to local timezone. time.gmtime # Convert back to UTC. time.getlocal # Return a new Time object in local zone time.getutc # Return a new Time object in UTC
格式化时间和日期
有多种方法可以格式化日期和时间。以下是一个显示一些示例:
实时演示#!/usr/bin/ruby -w
time = Time.new
puts time.to_s
puts time.ctime
puts time.localtime
puts time.strftime("%Y-%m-%d %H:%M:%S")
这将产生以下结果:
Mon Jun 02 12:35:19 -0700 2008 Mon Jun 2 12:35:19 2008 Mon Jun 02 12:35:19 -0700 2008 2008-06-02 12:35:19
时间格式化指令
下表中的这些指令与Time.strftime方法一起使用。
| 序号 | 指令和描述 |
|---|---|
| 1 | %a 缩写的工作日名称(Sun)。 |
| 2 | %A 完整的工作日名称(Sunday)。 |
| 3 | %b 缩写月份名称(Jan)。 |
| 4 | %B 完整月份名称(January)。 |
| 5 | %c 首选的本地日期和时间表示形式。 |
| 6 | %d 月份中的日期(01 到 31)。 |
| 7 | %H 一天中的小时,24 小时制(00 到 23)。 |
| 8 | %I 一天中的小时,12 小时制(01 到 12)。 |
| 9 | %j 一年中的日期(001 到 366)。 |
| 10 | %m 一年中的月份(01 到 12)。 |
| 11 | %M 小时中的分钟(00 到 59)。 |
| 12 | %p 子午线指示器(AM 或 PM)。 |
| 13 | %S 分钟中的秒(00 到 60)。 |
| 14 | %U 当前年份的星期数,从第一个星期日作为第一周的第一天开始(00 到 53)。 |
| 15 | %W 当前年份的星期数,从第一个星期一作为第一周的第一天开始(00 到 53)。 |
| 16 | %w 一周中的某一天(星期日为 0,0 到 6)。 |
| 17 | %x 仅日期的首选表示形式,没有时间。 |
| 18 | %X 仅时间首选表示形式,没有日期。 |
| 19 | %y 没有世纪的年份(00 到 99)。 |
| 20 | %Y 带世纪的年份。 |
| 21 | %Z 时区名称。 |
| 22 | %% 文字 % 字符。 |
时间算术
您可以对时间执行简单的算术运算,如下所示:
实时演示now = Time.now # Current time puts now past = now - 10 # 10 seconds ago. Time - number => Time puts past future = now + 10 # 10 seconds from now Time + number => Time puts future diff = future - past # => 10 Time - Time => number of seconds puts diff
这将产生以下结果:
Thu Aug 01 20:57:05 -0700 2013 Thu Aug 01 20:56:55 -0700 2013 Thu Aug 01 20:57:15 -0700 2013 20.0
Ruby - 范围
范围无处不在:1 月到 12 月、0 到 9、第 50 行到第 67 行,等等。Ruby 支持范围,并允许我们以各种方式使用范围:
- 范围作为序列
- 范围作为条件
- 范围作为区间
范围作为序列
范围的第一个也是最自然的用途是表达一个序列。序列有起点、终点和生成序列中后续值的方法。
Ruby 使用''..''和''...''范围运算符创建这些序列。两点形式创建包含范围,而三点形式创建排除指定高值的范围。
(1..5) #==> 1, 2, 3, 4, 5
(1...5) #==> 1, 2, 3, 4
('a'..'d') #==> 'a', 'b', 'c', 'd'
序列 1..100 作为包含对两个Fixnum对象引用的 Range 对象来保存。如果需要,可以使用to_a方法将范围转换为列表。尝试以下示例:
实时演示#!/usr/bin/ruby
$, =", " # Array value separator
range1 = (1..10).to_a
range2 = ('bar'..'bat').to_a
puts "#{range1}"
puts "#{range2}"
这将产生以下结果:
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10] ["bar", "bas", "bat"]
范围实现允许您以各种方式迭代它们并测试其内容的方法:
实时演示#!/usr/bin/ruby
# Assume a range
digits = 0..9
puts digits.include?(5)
ret = digits.min
puts "Min value is #{ret}"
ret = digits.max
puts "Max value is #{ret}"
ret = digits.reject {|i| i < 5 }
puts "Rejected values are #{ret}"
digits.each do |digit|
puts "In Loop #{digit}"
end
这将产生以下结果:
true Min value is 0 Max value is 9 Rejected values are 5, 6, 7, 8, 9 In Loop 0 In Loop 1 In Loop 2 In Loop 3 In Loop 4 In Loop 5 In Loop 6 In Loop 7 In Loop 8 In Loop 9
范围作为条件
范围也可以用作条件表达式。例如,以下代码片段打印来自标准输入的行的集合,其中每个集合的第一行包含单词start,最后一行包含单词ends:
while gets print if /start/../end/ end
范围可用于 case 语句中:
实时演示#!/usr/bin/ruby score = 70 result = case score when 0..40 then "Fail" when 41..60 then "Pass" when 61..70 then "Pass with Merit" when 71..100 then "Pass with Distinction" else "Invalid Score" end puts result
这将产生以下结果:
Pass with Merit
范围作为区间
多功能范围的最终用途是作为区间测试:查看某个值是否落在范围表示的区间内。这是使用 ===(情况相等运算符)完成的。
实时演示#!/usr/bin/ruby
if ((1..10) === 5)
puts "5 lies in (1..10)"
end
if (('a'..'j') === 'c')
puts "c lies in ('a'..'j')"
end
if (('a'..'j') === 'z')
puts "z lies in ('a'..'j')"
end
这将产生以下结果:
5 lies in (1..10)
c lies in ('a'..'j')
Ruby - 迭代器
迭代器只不过是集合支持的方法。存储一组数据成员的对象称为集合。在 Ruby 中,数组和哈希可以称为集合。
迭代器依次返回集合的所有元素。我们将在本文中讨论两个迭代器,each和collect。让我们详细了解一下。
Ruby each 迭代器
each 迭代器返回数组或哈希的所有元素。
语法
collection.each do |variable| code end
对collection中的每个元素执行code。此处,collection可以是数组或 Ruby 哈希。
示例
实时演示#!/usr/bin/ruby ary = [1,2,3,4,5] ary.each do |i| puts i end
这将产生以下结果:
1 2 3 4 5
您始终将each迭代器与块关联。它将数组的每个值逐个返回到块中。该值存储在变量i中,然后显示在屏幕上。
Ruby collect 迭代器
collect迭代器返回集合的所有元素。
语法
collection = collection.collect
collect方法并不总是需要与块关联。collect方法返回整个集合,无论它是数组还是哈希。
示例
#!/usr/bin/ruby a = [1,2,3,4,5] b = Array.new b = a.collect puts b
这将产生以下结果:
1 2 3 4 5
注意 - collect方法不是在数组之间进行复制的正确方法。还有另一种称为clone的方法,应使用该方法将一个数组复制到另一个数组中。
当您希望对每个值执行某些操作以获取新数组时,通常使用 collect 方法。例如,此代码生成一个数组b,其中包含a中每个值的 10 倍。
实时演示#!/usr/bin/ruby
a = [1,2,3,4,5]
b = a.collect{|x| 10*x}
puts b
这将产生以下结果:
10 20 30 40 50
Ruby - 文件 I/O
Ruby 提供了一整套在 Kernel 模块中实现的与 I/O 相关的 方法。所有 I/O 方法都派生自 IO 类。
IO类提供所有基本方法,例如read、write、gets、puts、readline、getc和printf。
本章将涵盖 Ruby 中可用的所有基本 I/O 函数。有关更多函数,请参阅 Ruby 类IO。
puts 语句
在前面的章节中,您已将值分配给变量,然后使用puts语句打印输出。
puts语句指示程序显示存储在变量中的值。这将在它写入的每一行的末尾添加一个新行。
示例
实时演示#!/usr/bin/ruby val1 = "This is variable one" val2 = "This is variable two" puts val1 puts val2
这将产生以下结果:
This is variable one This is variable two
gets 语句
gets语句可用于从称为 STDIN 的标准屏幕获取用户的任何输入。
示例
以下代码向您展示了如何使用 gets 语句。此代码将提示用户输入一个值,该值将存储在变量 val 中,最后将打印到 STDOUT。
#!/usr/bin/ruby puts "Enter a value :" val = gets puts val
这将产生以下结果:
Enter a value : This is entered value This is entered value
putc 语句
与输出整个字符串到屏幕上的puts语句不同,putc语句可用于一次输出一个字符。
示例
以下代码的输出仅为字符 H:
实时演示#!/usr/bin/ruby str = "Hello Ruby!" putc str
这将产生以下结果:
H
print 语句
print语句类似于puts语句。唯一的区别是puts语句在打印内容后换行,而print语句的光标位于同一行。
示例
实时演示#!/usr/bin/ruby print "Hello World" print "Good Morning"
这将产生以下结果:
Hello WorldGood Morning
打开和关闭文件
到目前为止,您一直在读取和写入标准输入和输出。现在,我们将了解如何处理实际的数据文件。
File.new 方法
您可以使用File.new方法创建一个File对象,用于读取、写入或同时进行读取和写入,具体取决于模式字符串。最后,您可以使用File.close方法关闭该文件。
语法
aFile = File.new("filename", "mode")
# ... process the file
aFile.close
File.open 方法
您可以使用File.open方法创建一个新的文件对象并将该文件对象分配给一个文件。但是,File.open和File.new方法之间存在一个区别。区别在于File.open方法可以与块关联,而您无法使用File.new方法执行相同的操作。
File.open("filename", "mode") do |aFile|
# ... process the file
end
a+
读写模式。如果文件存在,则文件指针位于文件末尾。文件以追加模式打开。如果文件不存在,则创建一个新文件以进行读取和写入。
读取和写入文件
我们一直在使用的“简单”I/O 的相同方法可用于所有文件对象。因此,gets 从标准输入读取一行,而aFile.gets从文件对象 aFile 读取一行。
但是,I/O 对象提供了一组额外的访问方法,使我们的生活更轻松。
sysread 方法
This is a simple text file for testing purpose.
您可以使用sysread方法读取文件的内容。在使用sysread方法时,您可以以任何模式打开文件。例如:
#!/usr/bin/ruby
aFile = File.new("input.txt", "r")
if aFile
content = aFile.sysread(20)
puts content
else
puts "Unable to open file!"
end
此语句将输出文件的前 20 个字符。文件指针现在将放置在文件中的第 21 个字符处。
syswrite 方法
您可以使用 syswrite 方法将内容写入文件。使用 syswrite 方法时,需要以写入模式打开文件。例如 -
#!/usr/bin/ruby
aFile = File.new("input.txt", "r+")
if aFile
aFile.syswrite("ABCDEF")
else
puts "Unable to open file!"
end
此语句将“ABCDEF”写入文件。
each_byte 方法
此方法属于 File 类。each_byte 方法始终与一个代码块关联。请考虑以下代码示例 -
#!/usr/bin/ruby
aFile = File.new("input.txt", "r+")
if aFile
aFile.syswrite("ABCDEF")
aFile.each_byte {|ch| putc ch; putc ?. }
else
puts "Unable to open file!"
end
字符逐个传递给变量 ch,然后按如下方式显示在屏幕上 -
s. .a. .s.i.m.p.l.e. .t.e.x.t. .f.i.l.e. .f.o.r. .t.e.s.t.i.n.g. .p.u.r.p.o.s.e... . .
IO.readlines 方法
File 类是 IO 类的子类。IO 类也有一些方法,可用于操作文件。
IO 类方法之一是 IO.readlines。此方法逐行返回文件的内容。以下代码显示了 IO.readlines 方法的使用 -
#!/usr/bin/ruby
arr = IO.readlines("input.txt")
puts arr[0]
puts arr[1]
在此代码中,变量 arr 是一个数组。input.txt 文件的每一行都将是数组 arr 中的一个元素。因此,arr[0] 将包含第一行,而 arr[1] 将包含文件的第二行。
IO.foreach 方法
此方法也逐行返回输出。foreach 方法和 readlines 方法的区别在于 foreach 方法与一个代码块关联。但是,与 readlines 方法不同,foreach 方法不返回数组。例如 -
#!/usr/bin/ruby
IO.foreach("input.txt"){|block| puts block}
此代码将 test 文件的内容逐行传递给变量 block,然后输出将显示在屏幕上。
重命名和删除文件
您可以使用 Ruby 中的 rename 和 delete 方法以编程方式重命名和删除文件。
以下是重命名现有文件 test1.txt 的示例 -
#!/usr/bin/ruby # Rename a file from test1.txt to test2.txt File.rename( "test1.txt", "test2.txt" )
以下是删除现有文件 test2.txt 的示例 -
#!/usr/bin/ruby
# Delete file test2.txt
File.delete("test2.txt")
文件模式和所有权
使用带掩码的 chmod 方法更改文件的模式或权限/访问列表 -
以下是将现有文件 test.txt 的模式更改为掩码值的示例 -
#!/usr/bin/ruby file = File.new( "test.txt", "w" ) file.chmod( 0755 )
文件查询
以下命令在打开文件之前测试文件是否存在 -
#!/usr/bin/ruby
File.open("file.rb") if File::exists?( "file.rb" )
以下命令查询文件是否真的是文件 -
#!/usr/bin/ruby # This returns either true or false File.file?( "text.txt" )
以下命令查找给定的文件名是否为目录 -
#!/usr/bin/ruby # a directory File::directory?( "/usr/local/bin" ) # => true # a file File::directory?( "file.rb" ) # => false
以下命令查找文件是否可读、可写或可执行 -
#!/usr/bin/ruby File.readable?( "test.txt" ) # => true File.writable?( "test.txt" ) # => true File.executable?( "test.txt" ) # => false
以下命令查找文件大小是否为零 -
#!/usr/bin/ruby File.zero?( "test.txt" ) # => true
以下命令返回文件的大小 -
#!/usr/bin/ruby File.size?( "text.txt" ) # => 1002
以下命令可用于查找文件类型 -
#!/usr/bin/ruby File::ftype( "test.txt" ) # => file
ftype 方法通过返回以下之一来识别文件类型:file、directory、characterSpecial、blockSpecial、fifo、link、socket 或 unknown。
以下命令可用于查找文件创建、修改或上次访问的时间 -
#!/usr/bin/ruby File::ctime( "test.txt" ) # => Fri May 09 10:06:37 -0700 2008 File::mtime( "text.txt" ) # => Fri May 09 10:44:44 -0700 2008 File::atime( "text.txt" ) # => Fri May 09 10:45:01 -0700 2008
Ruby 中的目录
所有文件都包含在各种目录中,Ruby 也能很好地处理这些目录。File 类处理文件,而目录由 Dir 类处理。
遍历目录
要在 Ruby 程序中更改目录,请使用 Dir.chdir,如下所示。此示例将当前目录更改为 /usr/bin。
Dir.chdir("/usr/bin")
您可以使用 Dir.pwd 找出当前目录是什么 -
puts Dir.pwd # This will return something like /usr/bin
您可以使用 Dir.entries 获取特定目录中文件和目录的列表 -
puts Dir.entries("/usr/bin").join(' ')
Dir.entries 返回一个包含指定目录中所有条目的数组。Dir.foreach 提供相同的功能 -
Dir.foreach("/usr/bin") do |entry|
puts entry
end
获取目录列表的更简洁方法是使用 Dir 的类数组方法 -
Dir["/usr/bin/*"]
创建目录
Dir.mkdir 可用于创建目录 -
Dir.mkdir("mynewdir")
您还可以使用 mkdir 为新目录(而非已存在的目录)设置权限 -
注意 - 掩码 755 将所有者、组、世界[任何人]的权限设置为 rwxr-xr-x,其中 r = 读取、w = 写入,x = 执行。
Dir.mkdir( "mynewdir", 755 )
删除目录
Dir.delete 可用于删除目录。Dir.unlink 和 Dir.rmdir 执行完全相同的功能,并为了方便而提供。
Dir.delete("testdir")
创建文件和临时目录
临时文件是在程序执行期间可能短暂创建的文件,但不是永久的信息存储。
Dir.tmpdir 提供当前系统上临时目录的路径,尽管默认情况下该方法不可用。要使 Dir.tmpdir 可用,需要使用 require 'tmpdir'。
您可以将 Dir.tmpdir 与 File.join 结合使用以创建与平台无关的临时文件 -
require 'tmpdir' tempfilename = File.join(Dir.tmpdir, "tingtong") tempfile = File.new(tempfilename, "w") tempfile.puts "This is a temporary file" tempfile.close File.delete(tempfilename)
此代码创建了一个临时文件,向其中写入数据,然后将其删除。Ruby 的标准库还包含一个名为 Tempfile 的库,可以为您创建临时文件 -
require 'tempfile'
f = Tempfile.new('tingtong')
f.puts "Hello"
puts f.path
f.close
内置函数
以下是处理文件和目录的 Ruby 内置函数 -
Ruby - 异常
执行和异常总是同时出现。如果您打开一个不存在的文件,那么如果您没有正确处理这种情况,那么您的程序被认为质量不高。
如果发生异常,程序将停止。因此,异常用于处理程序执行期间可能发生的各种类型的错误,并采取适当的措施,而不是完全停止程序。
Ruby 提供了一个很好的机制来处理异常。我们将可能引发异常的代码包含在 begin/end 代码块中,并使用 rescue 子句告诉 Ruby 我们想要处理的异常类型。
语法
begin # - rescue OneTypeOfException # - rescue AnotherTypeOfException # - else # Other exceptions ensure # Always will be executed end
从 begin 到 rescue 的所有内容都受到保护。如果在此代码块执行期间发生异常,则控制权将传递到 rescue 和 end 之间的代码块。
对于 begin 代码块中的每个 rescue 子句,Ruby 依次将引发的异常与每个参数进行比较。如果 rescue 子句中命名的异常与当前抛出的异常的类型相同,或者是的超类,则匹配将成功。
如果异常与指定的任何错误类型都不匹配,则允许在所有 rescue 子句之后使用 else 子句。
示例
实时演示#!/usr/bin/ruby
begin
file = open("/unexistant_file")
if file
puts "File opened successfully"
end
rescue
file = STDIN
end
print file, "==", STDIN, "\n"
这将产生以下结果。您可以看到 STDIN 被替换为 file,因为 open 失败了。
#<IO:0xb7d16f84>==#<IO:0xb7d16f84>
使用 retry 语句
您可以使用 rescue 代码块捕获异常,然后使用 retry 语句从头开始执行 begin 代码块。
语法
begin # Exceptions raised by this code will # be caught by the following rescue clause rescue # This block will capture all types of exceptions retry # This will move control to the beginning of begin end
示例
#!/usr/bin/ruby
begin
file = open("/unexistant_file")
if file
puts "File opened successfully"
end
rescue
fname = "existant_file"
retry
end
以下是流程 -
- 在 open 处发生异常。
- 进入 rescue。fname 已重新分配。
- 通过 retry 返回到 begin 的开头。
- 这次文件成功打开。
- 继续执行必要的过程。
注意 - 请注意,如果重新替换名称的文件不存在,此示例代码将无限期重试。如果您将 retry 用于异常处理,请小心。
使用 raise 语句
您可以使用 raise 语句引发异常。以下方法在每次调用时都会引发异常。将打印其第二个消息。
语法
raise OR raise "Error Message" OR raise ExceptionType, "Error Message" OR raise ExceptionType, "Error Message" condition
第一种形式只是重新引发当前异常(如果当前没有异常,则引发 RuntimeError)。这用于需要在传递异常之前拦截异常的异常处理程序。
第二种形式创建一个新的 RuntimeError 异常,将其消息设置为给定的字符串。然后,此异常将向上抛到调用堆栈。
第三种形式使用第一个参数创建异常,然后将关联的消息设置为第二个参数。
第四种形式类似于第三种形式,但您可以添加任何条件语句(如 unless)来引发异常。
示例
实时演示#!/usr/bin/ruby begin puts 'I am before the raise.' raise 'An error has occurred.' puts 'I am after the raise.' rescue puts 'I am rescued.' end puts 'I am after the begin block.'
这将产生以下结果:
I am before the raise. I am rescued. I am after the begin block.
另一个显示 raise 用法的示例 -
实时演示#!/usr/bin/ruby begin raise 'A test exception.' rescue Exception => e puts e.message puts e.backtrace.inspect end
这将产生以下结果:
A test exception. ["main.rb:4"]
使用 ensure 语句
有时,您需要保证在代码块结束时执行某些处理,无论是否引发了异常。例如,您可能在进入代码块时打开了文件,并且需要确保在代码块退出时关闭文件。
ensure 子句就是这样做的。ensure 在最后一个 rescue 子句之后,并包含一个始终会在代码块终止时执行的代码块。无论代码块是否正常退出、是否引发并捕获异常或是否被未捕获的异常终止,ensure 代码块都将运行。
语法
begin #.. process #..raise exception rescue #.. handle error ensure #.. finally ensure execution #.. This will always execute. end
示例
实时演示begin raise 'A test exception.' rescue Exception => e puts e.message puts e.backtrace.inspect ensure puts "Ensuring execution" end
这将产生以下结果:
A test exception. ["main.rb:4"] Ensuring execution
使用 else 语句
如果存在 else 子句,它将在 rescue 子句之后以及任何 ensure 之前。
只有在代码主体没有引发异常时才会执行 else 子句的主体。
语法
begin #.. process #..raise exception rescue # .. handle error else #.. executes if there is no exception ensure #.. finally ensure execution #.. This will always execute. end
示例
实时演示begin # raise 'A test exception.' puts "I'm not raising exception" rescue Exception => e puts e.message puts e.backtrace.inspect else puts "Congratulations-- no errors!" ensure puts "Ensuring execution" end
这将产生以下结果:
I'm not raising exception Congratulations-- no errors! Ensuring execution
可以使用 $! 变量捕获引发的错误消息。
捕获和抛出
虽然 raise 和 rescue 的异常机制非常适合在出现问题时放弃执行,但在正常处理过程中能够跳出某些深度嵌套的结构有时也很不错。这就是 catch 和 throw 发挥作用的地方。
catch 定义一个用给定名称(可以是 Symbol 或 String)标记的代码块。代码块正常执行,直到遇到 throw。
语法
throw :lablename #.. this will not be executed catch :lablename do #.. matching catch will be executed after a throw is encountered. end OR throw :lablename condition #.. this will not be executed catch :lablename do #.. matching catch will be executed after a throw is encountered. end
示例
以下示例使用 throw 在对任何提示做出响应时键入“!”以终止与用户的交互。
def promptAndGet(prompt)
print prompt
res = readline.chomp
throw :quitRequested if res == "!"
return res
end
catch :quitRequested do
name = promptAndGet("Name: ")
age = promptAndGet("Age: ")
sex = promptAndGet("Sex: ")
# ..
# process information
end
promptAndGet("Name:")
您应该在您的机器上尝试以上程序,因为它需要手动交互。这将产生以下结果 -
Name: Ruby on Rails Age: 3 Sex: ! Name:Just Ruby
Exception 类
Ruby 的标准类和模块会引发异常。所有异常类都形成一个层次结构,Exception 类位于顶部。下一层包含七种不同的类型 -
- Interrupt
- NoMemoryError
- SignalException
- ScriptError
- StandardError
- SystemExit
此级别还有另一个异常 Fatal,但 Ruby 解释器仅在内部使用它。
ScriptError 和 StandardError 都有许多子类,但我们这里无需详细介绍。重要的是,如果我们创建自己的异常类,则它们需要是 Exception 类或其后代之一的子类。
让我们看一个例子 -
class FileSaveError < StandardError
attr_reader :reason
def initialize(reason)
@reason = reason
end
end
现在,看一下以下示例,它将使用此异常 -
File.open(path, "w") do |file| begin # Write out the data ... rescue # Something went wrong! raise FileSaveError.new($!) end end
这里的重要行是 raise FileSaveError.new($!)。我们调用 raise 以发出已发生异常的信号,并将 FileSaveError 的新实例传递给它,原因是导致数据写入失败的特定异常。
Ruby - 面向对象
Ruby 是一种纯面向对象的语言,在 Ruby 中,一切皆对象。Ruby 中的每个值都是对象,即使是最原始的值:字符串、数字,甚至 true 和 false。甚至类本身也是一个对象,它是 Class 类的实例。本章将带您了解与面向对象 Ruby 相关的所有主要功能。
类用于指定对象的形态,它将数据表示和操作该数据的方法组合到一个简洁的包中。类中的数据和方法称为类的成员。
Ruby 类定义
定义类时,您定义了数据类型的蓝图。这实际上并没有定义任何数据,但它确实定义了类名的含义,即类的对象将包含什么以及可以在此类对象上执行哪些操作。
类定义以关键字 class 后跟类名开头,并以end分隔。例如,我们使用关键字 class 定义了 Box 类,如下所示:
class Box code end
名称必须以大写字母开头,按照惯例,包含多个单词的名称会将每个单词的首字母大写并连接在一起,没有分隔字符(驼峰命名法)。
定义 Ruby 对象
类提供了对象的蓝图,因此基本上对象是从类创建的。我们使用new关键字声明类的对象。以下语句声明了 Box 类的两个对象:
box1 = Box.new box2 = Box.new
initialize 方法
initialize 方法是标准的 Ruby 类方法,其工作方式与其他面向对象编程语言中的构造函数几乎相同。当您希望在创建对象时初始化一些类变量时,initialize 方法很有用。此方法可以接受参数列表,并且像任何其他 ruby 方法一样,它将以def关键字开头,如下所示:
class Box
def initialize(w,h)
@width, @height = w, h
end
end
实例变量
实例变量是一种类属性,一旦使用类创建了对象,它们就成为对象的属性。每个对象的属性都是单独分配的,并且与其他对象不共享任何值。在类中使用 @ 运算符访问它们,但要在类外部访问它们,我们使用public方法,称为访问器方法。如果我们采用上面定义的类Box,那么 @width 和 @height 就是 Box 类的实例变量。
class Box
def initialize(w,h)
# assign instance variables
@width, @height = w, h
end
end
访问器和设置器方法
要使变量从类外部可用,必须在访问器方法中定义它们,这些访问器方法也称为 getter 方法。以下示例显示了访问器方法的使用:
实时演示#!/usr/bin/ruby -w
# define a class
class Box
# constructor method
def initialize(w,h)
@width, @height = w, h
end
# accessor methods
def printWidth
@width
end
def printHeight
@height
end
end
# create an object
box = Box.new(10, 20)
# use accessor methods
x = box.printWidth()
y = box.printHeight()
puts "Width of the box is : #{x}"
puts "Height of the box is : #{y}"
执行上述代码时,会产生以下结果:
Width of the box is : 10 Height of the box is : 20
类似于用于访问变量值的访问器方法,Ruby 提供了一种方法,可以通过设置器方法从类外部设置这些变量的值,设置器方法定义如下:
实时演示#!/usr/bin/ruby -w
# define a class
class Box
# constructor method
def initialize(w,h)
@width, @height = w, h
end
# accessor methods
def getWidth
@width
end
def getHeight
@height
end
# setter methods
def setWidth=(value)
@width = value
end
def setHeight=(value)
@height = value
end
end
# create an object
box = Box.new(10, 20)
# use setter methods
box.setWidth = 30
box.setHeight = 50
# use accessor methods
x = box.getWidth()
y = box.getHeight()
puts "Width of the box is : #{x}"
puts "Height of the box is : #{y}"
执行上述代码时,会产生以下结果:
Width of the box is : 30 Height of the box is : 50
实例方法
实例方法也与我们使用def关键字定义任何其他方法的方式相同,并且只能使用类实例来使用,如下所示。它们的功能不仅限于访问实例变量,而且还可以根据您的需求执行更多操作。
实时演示#!/usr/bin/ruby -w
# define a class
class Box
# constructor method
def initialize(w,h)
@width, @height = w, h
end
# instance method
def getArea
@width * @height
end
end
# create an object
box = Box.new(10, 20)
# call instance methods
a = box.getArea()
puts "Area of the box is : #{a}"
执行上述代码时,会产生以下结果:
Area of the box is : 200
类方法和变量
类变量是一个变量,它在类的所有实例之间共享。换句话说,该变量只有一个实例,并且可以通过对象实例访问它。类变量以两个 @ 字符 (@@) 为前缀。类变量必须在类定义中初始化,如下所示。
类方法使用def self.methodname()定义,以 end 分隔符结尾,并将使用类名作为classname.methodname调用,如以下示例所示:
#!/usr/bin/ruby -w
class Box
# Initialize our class variables
@@count = 0
def initialize(w,h)
# assign instance avriables
@width, @height = w, h
@@count += 1
end
def self.printCount()
puts "Box count is : #@@count"
end
end
# create two object
box1 = Box.new(10, 20)
box2 = Box.new(30, 100)
# call class method to print box count
Box.printCount()
执行上述代码时,会产生以下结果:
Box count is : 2
to_s 方法
您定义的任何类都应该有一个to_s实例方法来返回对象的字符串表示形式。以下是一个简单的示例,用于根据宽度和高度表示 Box 对象:
实时演示#!/usr/bin/ruby -w
class Box
# constructor method
def initialize(w,h)
@width, @height = w, h
end
# define to_s method
def to_s
"(w:#@width,h:#@height)" # string formatting of the object.
end
end
# create an object
box = Box.new(10, 20)
# to_s method will be called in reference of string automatically.
puts "String representation of box is : #{box}"
执行上述代码时,会产生以下结果:
String representation of box is : (w:10,h:20)
访问控制
Ruby 在实例方法级别为您提供了三种级别的保护,可以是public、private 或 protected。Ruby 不会对实例变量和类变量应用任何访问控制。
公共方法 - 公共方法可以被任何人调用。方法默认情况下是公共的,初始化方法除外,初始化方法始终是私有的。
私有方法 - 无法从类外部访问或查看私有方法。只有类方法可以访问私有成员。
受保护的方法 - 受保护的方法只能由定义类及其子类的对象调用。访问权限保持在家族内部。
以下是一个简单的示例,用于显示所有三个访问修饰符的语法:
实时演示#!/usr/bin/ruby -w
# define a class
class Box
# constructor method
def initialize(w,h)
@width, @height = w, h
end
# instance method by default it is public
def getArea
getWidth() * getHeight
end
# define private accessor methods
def getWidth
@width
end
def getHeight
@height
end
# make them private
private :getWidth, :getHeight
# instance method to print area
def printArea
@area = getWidth() * getHeight
puts "Big box area is : #@area"
end
# make it protected
protected :printArea
end
# create an object
box = Box.new(10, 20)
# call instance methods
a = box.getArea()
puts "Area of the box is : #{a}"
# try to call protected or methods
box.printArea()
执行上述代码时,会产生以下结果。这里,第一个方法成功调用,但第二个方法出现了问题。
Area of the box is : 200 test.rb:42: protected method `printArea' called for # <Box:0xb7f11280 @height = 20, @width = 10> (NoMethodError)
类继承
面向对象编程中最重要的概念之一是继承。继承允许我们根据另一个类来定义一个类,这使得创建和维护应用程序变得更加容易。
继承还提供了重用代码功能和加快实现时间的机会,但不幸的是,Ruby 不支持多级继承,但 Ruby 支持mixin。Mixin 就像多重继承的一种专门实现,其中只继承接口部分。
创建类时,程序员可以指定新类应该继承现有类的成员,而不是完全编写新的数据成员和成员函数。这个现有类称为基类或超类,新类称为派生类或子类。
Ruby 还支持子类化概念,即继承,以下示例解释了该概念。扩展类的语法很简单。只需在类语句中添加 < 字符和超类的名称即可。例如,以下将BigBox类定义为Box类的子类:
实时演示#!/usr/bin/ruby -w
# define a class
class Box
# constructor method
def initialize(w,h)
@width, @height = w, h
end
# instance method
def getArea
@width * @height
end
end
# define a subclass
class BigBox < Box
# add a new instance method
def printArea
@area = @width * @height
puts "Big box area is : #@area"
end
end
# create an object
box = BigBox.new(10, 20)
# print the area
box.printArea()
执行上述代码时,会产生以下结果:
Big box area is : 200
方法重写
虽然您可以在派生类中添加新功能,但有时您可能希望更改父类中已定义方法的行为。您可以简单地保留相同的方法名并重写方法的功能,如下面的示例所示:
实时演示#!/usr/bin/ruby -w
# define a class
class Box
# constructor method
def initialize(w,h)
@width, @height = w, h
end
# instance method
def getArea
@width * @height
end
end
# define a subclass
class BigBox < Box
# change existing getArea method as follows
def getArea
@area = @width * @height
puts "Big box area is : #@area"
end
end
# create an object
box = BigBox.new(10, 20)
# print the area using overriden method.
box.getArea()
运算符重载
我们希望 + 运算符使用 + 执行两个 Box 对象的向量加法,* 运算符将 Box 的宽度和高度乘以一个标量,而一元 - 运算符则对 Box 的宽度和高度取反。以下是定义了数学运算符的 Box 类版本:
class Box
def initialize(w,h) # Initialize the width and height
@width,@height = w, h
end
def +(other) # Define + to do vector addition
Box.new(@width + other.width, @height + other.height)
end
def -@ # Define unary minus to negate width and height
Box.new(-@width, -@height)
end
def *(scalar) # To perform scalar multiplication
Box.new(@width*scalar, @height*scalar)
end
end
冻结对象
有时,我们希望阻止对象被更改。Object 中的 freeze 方法允许我们执行此操作,有效地将对象转换为常量。通过调用Object.freeze可以冻结任何对象。冻结的对象不能修改:您不能更改其实例变量。
您可以使用Object.frozen?方法检查给定对象是否已冻结,如果对象已冻结,则该方法返回 true,否则返回 false 值。以下示例阐明了这个概念:
实时演示#!/usr/bin/ruby -w
# define a class
class Box
# constructor method
def initialize(w,h)
@width, @height = w, h
end
# accessor methods
def getWidth
@width
end
def getHeight
@height
end
# setter methods
def setWidth=(value)
@width = value
end
def setHeight=(value)
@height = value
end
end
# create an object
box = Box.new(10, 20)
# let us freez this object
box.freeze
if( box.frozen? )
puts "Box object is frozen object"
else
puts "Box object is normal object"
end
# now try using setter methods
box.setWidth = 30
box.setHeight = 50
# use accessor methods
x = box.getWidth()
y = box.getHeight()
puts "Width of the box is : #{x}"
puts "Height of the box is : #{y}"
执行上述代码时,会产生以下结果:
Box object is frozen object test.rb:20:in `setWidth=': can't modify frozen object (TypeError) from test.rb:39
类常量
您可以通过将直接的数字或字符串值分配给未使用 @ 或 @@ 定义的变量来定义类中的常量。按照惯例,我们将常量名称保持为大写。
定义常量后,您无法更改其值,但可以在类内部像变量一样直接访问常量,但如果要从类外部访问常量,则必须使用classname::constant,如下面的示例所示。
实时演示#!/usr/bin/ruby -w
# define a class
class Box
BOX_COMPANY = "TATA Inc"
BOXWEIGHT = 10
# constructor method
def initialize(w,h)
@width, @height = w, h
end
# instance method
def getArea
@width * @height
end
end
# create an object
box = Box.new(10, 20)
# call instance methods
a = box.getArea()
puts "Area of the box is : #{a}"
puts Box::BOX_COMPANY
puts "Box weight is: #{Box::BOXWEIGHT}"
执行上述代码时,会产生以下结果:
Area of the box is : 200 TATA Inc Box weight is: 10
类常量是继承的,并且可以像实例方法一样被覆盖。
使用 Allocate 创建对象
可能存在您希望在不调用其构造函数initialize(即不使用 new 方法)的情况下创建对象的情况,在这种情况下,您可以调用allocate,它将为您创建一个未初始化的对象,如以下示例所示:
实时演示#!/usr/bin/ruby -w
# define a class
class Box
attr_accessor :width, :height
# constructor method
def initialize(w,h)
@width, @height = w, h
end
# instance method
def getArea
@width * @height
end
end
# create an object using new
box1 = Box.new(10, 20)
# create another object using allocate
box2 = Box.allocate
# call instance method using box1
a = box1.getArea()
puts "Area of the box is : #{a}"
# call instance method using box2
a = box2.getArea()
puts "Area of the box is : #{a}"
执行上述代码时,会产生以下结果:
Area of the box is : 200 test.rb:14: warning: instance variable @width not initialized test.rb:14: warning: instance variable @height not initialized test.rb:14:in `getArea': undefined method `*' for nil:NilClass (NoMethodError) from test.rb:29
类信息
如果类定义是可执行代码,这意味着它们在某个对象的上下文中执行:self 必须引用某些内容。让我们找出它是什么。
#!/usr/bin/ruby -w
class Box
# print class information
puts "Type of self = #{self.type}"
puts "Name of self = #{self.name}"
end
执行上述代码时,会产生以下结果:
Type of self = Class Name of self = Box
这意味着类定义是在该类作为当前对象的情况下执行的。这意味着元类及其超类中的方法将在方法定义的执行期间可用。
Ruby - 正则表达式
正则表达式是一系列特殊的字符,它可以帮助您使用包含在模式中的专门语法匹配或查找其他字符串或字符串集。
正则表达式字面量是在斜杠之间或在任意分隔符之间以及 %r 之后的模式,如下所示:
语法
/pattern/ /pattern/im # option can be specified %r!/usr/local! # general delimited regular expression
示例
实时演示#!/usr/bin/ruby line1 = "Cats are smarter than dogs"; line2 = "Dogs also like meat"; if ( line1 =~ /Cats(.*)/ ) puts "Line1 contains Cats" end if ( line2 =~ /Cats(.*)/ ) puts "Line2 contains Dogs" end
这将产生以下结果:
Line1 contains Cats
正则表达式修饰符
正则表达式字面量可以包含一个可选的修饰符来控制匹配的各个方面。修饰符在第二个斜杠字符之后指定,如前所述,可以用以下字符之一表示:
| 序号 | 修饰符和说明 |
|---|---|
| 1 | i i |
| 2 | 匹配文本时忽略大小写。 o |
| 3 | x 仅执行一次 #{} 插值,即在第一次评估正则表达式字面量时。 |
| 4 | m m |
| 5 | 忽略空格并在正则表达式中允许注释。 n |
匹配多行,将换行符识别为普通字符。
# Following matches a single slash character, no escape required %r|/| # Flag characters are allowed with this syntax, too %r[</(.*)>]i
u,e,s,n
除了控制字符(**(+ ? . * ^ $ ( ) [ ] { } | \)**)外,所有字符都匹配自身。您可以通过在控制字符前面加上反斜杠来转义它。
正则表达式示例
搜索和替换
使用正则表达式的一些最重要的 String 方法是sub和gsub,以及它们的原位变体sub!和gsub!。
所有这些方法都使用 Regexp 模式执行搜索和替换操作。sub & sub! 替换模式的第一次出现,而gsub & gsub! 替换所有出现。
sub和gsub返回一个新字符串,保持原始字符串不变,而sub!和gsub!修改其调用的字符串。
以下是示例 -
实时演示#!/usr/bin/ruby
phone = "2004-959-559 #This is Phone Number"
# Delete Ruby-style comments
phone = phone.sub!(/#.*$/, "")
puts "Phone Num : #{phone}"
# Remove anything other than digits
phone = phone.gsub!(/\D/, "")
puts "Phone Num : #{phone}"
这将产生以下结果:
Phone Num : 2004-959-559 Phone Num : 2004959559
以下是另一个示例 -
实时演示#!/usr/bin/ruby
text = "rails are rails, really good Ruby on Rails"
# Change "rails" to "Rails" throughout
text.gsub!("rails", "Rails")
# Capitalize the word "Rails" throughout
text.gsub!(/\brails\b/, "Rails")
puts "#{text}"
这将产生以下结果:
Rails are Rails, really good Ruby on Rails
Ruby/DBI 教程
本章将教你如何使用 Ruby 访问数据库。Ruby DBI模块为 Ruby 脚本提供了一个与 Perl DBI 模块类似的数据库无关接口。
DBI 代表 Ruby 的数据库独立接口,这意味着 DBI 在 Ruby 代码和底层数据库之间提供了一个抽象层,允许你非常轻松地切换数据库实现。它定义了一组方法、变量和约定,这些方法、变量和约定提供了与数据库一致的接口,而与使用的实际数据库无关。
DBI 可以与以下接口交互 -
- ADO (ActiveX 数据对象)
- DB2
- Frontbase
- mSQL
- MySQL
- ODBC
- Oracle
- OCI8 (Oracle)
- PostgreSQL
- 代理/服务器
- SQLite
- SQLRelay
DBI 应用程序的体系结构
DBI 独立于后端可用的任何数据库。无论你是在使用 Oracle、MySQL 还是 Informix 等,都可以使用 DBI。从下面的架构图可以清楚地看出这一点。
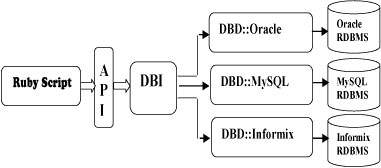
Ruby DBI 的通用架构使用两层 -
数据库接口 (DBI) 层。此层与数据库无关,并提供了一组通用的访问方法,无论你与之通信的数据库服务器类型如何,这些方法的使用方式都相同。
数据库驱动程序 (DBD) 层。此层与数据库相关;不同的驱动程序提供对不同数据库引擎的访问。MySQL 有一个驱动程序,PostgreSQL 有另一个驱动程序,InterBase 有另一个驱动程序,Oracle 有另一个驱动程序,依此类推。每个驱动程序都解释来自 DBI 层的请求,并将它们映射到适合给定类型数据库服务器的请求。
先决条件
如果你想编写 Ruby 脚本以访问 MySQL 数据库,则需要安装 Ruby MySQL 模块。
如上所述,此模块充当 DBD,可以从 https://www.tmtm.org/en/mysql/ruby/ 下载。
获取和安装 Ruby/DBI
你可以使用 Ruby Gems 包管理器安装 ruby DBI
gem install dbi
在开始此安装之前,请确保你具有 root 权限。现在,按照以下步骤操作 -
步骤 1
$ tar zxf dbi-0.2.0.tar.gz
步骤 2
进入发行版目录dbi-0.2.0并使用该目录中的setup.rb脚本对其进行配置。最通用的配置命令如下所示,在 config 参数后面没有参数。此命令将配置发行版以默认安装所有驱动程序。
$ ruby setup.rb config
更具体地说,提供一个 --with 选项,该选项列出要使用的发行版的特定部分。例如,要仅配置主 DBI 模块和 MySQL DBD 级驱动程序,请发出以下命令 -
$ ruby setup.rb config --with = dbi,dbd_mysql
步骤 3
最后一步是使用以下命令构建驱动程序并安装它 -
$ ruby setup.rb setup $ ruby setup.rb install
数据库连接
假设我们将要使用 MySQL 数据库,在连接到数据库之前,请确保以下事项 -
你已创建了一个数据库 TESTDB。
你已在 TESTDB 中创建了 EMPLOYEE。
此表具有字段 FIRST_NAME、LAST_NAME、AGE、SEX 和 INCOME。
用户 ID“testuser”和密码“test123”已设置为访问 TESTDB。
Ruby 模块 DBI 已正确安装在你的机器上。
你已阅读 MySQL 教程以了解 MySQL 基础知识。
以下是连接 MySQL 数据库“TESTDB”的示例
#!/usr/bin/ruby -w
require "dbi"
begin
# connect to the MySQL server
dbh = DBI.connect("DBI:Mysql:TESTDB:localhost", "testuser", "test123")
# get server version string and display it
row = dbh.select_one("SELECT VERSION()")
puts "Server version: " + row[0]
rescue DBI::DatabaseError => e
puts "An error occurred"
puts "Error code: #{e.err}"
puts "Error message: #{e.errstr}"
ensure
# disconnect from server
dbh.disconnect if dbh
end
在运行此脚本时,它会在我们的 Linux 机器上产生以下结果。
Server version: 5.0.45
如果与数据源建立了连接,则返回数据库句柄并将其保存到dbh以供进一步使用,否则dbh设置为 nil 值,e.err和e::errstr分别返回错误代码和错误字符串。
最后,在退出之前,请确保数据库连接已关闭并释放了资源。
INSERT 操作
当你想将记录创建到数据库表中时,需要使用 INSERT 操作。
一旦建立了数据库连接,我们就可以使用do方法或prepare和execute方法在数据库表中创建表或记录。
使用 do 语句
可以通过调用**do**数据库句柄方法来执行不返回行的语句。此方法接受一个语句字符串参数,并返回该语句影响的行数。
dbh.do("DROP TABLE IF EXISTS EMPLOYEE")
dbh.do("CREATE TABLE EMPLOYEE (
FIRST_NAME CHAR(20) NOT NULL,
LAST_NAME CHAR(20),
AGE INT,
SEX CHAR(1),
INCOME FLOAT )" );
类似地,您可以执行SQL的INSERT语句以在EMPLOYEE表中创建记录。
#!/usr/bin/ruby -w
require "dbi"
begin
# connect to the MySQL server
dbh = DBI.connect("DBI:Mysql:TESTDB:localhost", "testuser", "test123")
dbh.do( "INSERT INTO EMPLOYEE(FIRST_NAME, LAST_NAME, AGE, SEX, INCOME)
VALUES ('Mac', 'Mohan', 20, 'M', 2000)" )
puts "Record has been created"
dbh.commit
rescue DBI::DatabaseError => e
puts "An error occurred"
puts "Error code: #{e.err}"
puts "Error message: #{e.errstr}"
dbh.rollback
ensure
# disconnect from server
dbh.disconnect if dbh
end
使用prepare和execute
您可以使用DBI类的prepare和execute方法通过Ruby代码执行SQL语句。
记录创建需要以下步骤:
使用INSERT语句准备SQL语句。这将使用prepare方法完成。
执行SQL查询以从数据库中选择所有结果。这将使用execute方法完成。
释放语句句柄。这将使用finish API完成
如果一切顺利,则**commit**此操作,否则您可以**rollback**整个事务。
以下是使用这两种方法的语法:
sth = dbh.prepare(statement) sth.execute ... zero or more SQL operations ... sth.finish
这两种方法可以用来将**bind**值传递给SQL语句。可能存在需要输入的值事先未给出的情况。在这种情况下,使用绑定值。在实际值的位置使用问号(?),然后通过execute() API传递实际值。
以下是在EMPLOYEE表中创建两条记录的示例:
#!/usr/bin/ruby -w
require "dbi"
begin
# connect to the MySQL server
dbh = DBI.connect("DBI:Mysql:TESTDB:localhost", "testuser", "test123")
sth = dbh.prepare( "INSERT INTO EMPLOYEE(FIRST_NAME, LAST_NAME, AGE, SEX, INCOME)
VALUES (?, ?, ?, ?, ?)" )
sth.execute('John', 'Poul', 25, 'M', 2300)
sth.execute('Zara', 'Ali', 17, 'F', 1000)
sth.finish
dbh.commit
puts "Record has been created"
rescue DBI::DatabaseError => e
puts "An error occurred"
puts "Error code: #{e.err}"
puts "Error message: #{e.errstr}"
dbh.rollback
ensure
# disconnect from server
dbh.disconnect if dbh
end
如果一次有多个INSERT,那么先准备语句,然后在循环中多次执行它,比每次通过循环调用do更有效。
读取操作
任何数据库上的读取操作都意味着从数据库中获取一些有用的信息。
一旦我们的数据库连接建立,我们就可以对该数据库进行查询。我们可以使用do方法或prepare和execute方法从数据库表中获取值。
记录获取需要以下步骤:
根据所需条件准备SQL查询。这将使用prepare方法完成。
执行SQL查询以从数据库中选择所有结果。这将使用execute方法完成。
逐一获取所有结果并打印这些结果。这将使用fetch方法完成。
释放语句句柄。这将使用finish方法完成。
以下是查询EMPLOYEE表中所有工资超过1000的记录的过程。
#!/usr/bin/ruby -w
require "dbi"
begin
# connect to the MySQL server
dbh = DBI.connect("DBI:Mysql:TESTDB:localhost", "testuser", "test123")
sth = dbh.prepare("SELECT * FROM EMPLOYEE WHERE INCOME > ?")
sth.execute(1000)
sth.fetch do |row|
printf "First Name: %s, Last Name : %s\n", row[0], row[1]
printf "Age: %d, Sex : %s\n", row[2], row[3]
printf "Salary :%d \n\n", row[4]
end
sth.finish
rescue DBI::DatabaseError => e
puts "An error occurred"
puts "Error code: #{e.err}"
puts "Error message: #{e.errstr}"
ensure
# disconnect from server
dbh.disconnect if dbh
end
这将产生以下结果:
First Name: Mac, Last Name : Mohan Age: 20, Sex : M Salary :2000 First Name: John, Last Name : Poul Age: 25, Sex : M Salary :2300
还有更多从数据库中获取记录的快捷方法。如果您感兴趣,请参阅获取结果,否则继续下一节。
更新操作
任何数据库上的UPDATE操作都意味着更新数据库中已存在的一条或多条记录。以下是更新所有SEX为'M'的记录的过程。在这里,我们将所有男性的AGE增加一年。这将分三个步骤进行:
根据所需条件准备SQL查询。这将使用prepare方法完成。
执行SQL查询以从数据库中选择所有结果。这将使用execute方法完成。
释放语句句柄。这将使用finish方法完成。
如果一切顺利,则**commit**此操作,否则您可以**rollback**整个事务。
#!/usr/bin/ruby -w
require "dbi"
begin
# connect to the MySQL server
dbh = DBI.connect("DBI:Mysql:TESTDB:localhost", "testuser", "test123")
sth = dbh.prepare("UPDATE EMPLOYEE SET AGE = AGE + 1 WHERE SEX = ?")
sth.execute('M')
sth.finish
dbh.commit
rescue DBI::DatabaseError => e
puts "An error occurred"
puts "Error code: #{e.err}"
puts "Error message: #{e.errstr}"
dbh.rollback
ensure
# disconnect from server
dbh.disconnect if dbh
end
删除操作
当您想从数据库中删除一些记录时,需要DELETE操作。以下是删除EMPLOYEE中所有AGE大于20的记录的过程。此操作将执行以下步骤。
根据所需条件准备SQL查询。这将使用prepare方法完成。
执行SQL查询以从数据库中删除所需的记录。这将使用execute方法完成。
释放语句句柄。这将使用finish方法完成。
如果一切顺利,则**commit**此操作,否则您可以**rollback**整个事务。
#!/usr/bin/ruby -w
require "dbi"
begin
# connect to the MySQL server
dbh = DBI.connect("DBI:Mysql:TESTDB:localhost", "testuser", "test123")
sth = dbh.prepare("DELETE FROM EMPLOYEE WHERE AGE > ?")
sth.execute(20)
sth.finish
dbh.commit
rescue DBI::DatabaseError => e
puts "An error occurred"
puts "Error code: #{e.err}"
puts "Error message: #{e.errstr}"
dbh.rollback
ensure
# disconnect from server
dbh.disconnect if dbh
end
执行事务
事务是一种确保数据一致性的机制。事务应具有以下四个属性:
原子性 - 事务要么完成,要么什么也不发生。
一致性 - 事务必须从一致的状态开始,并使系统处于一致的状态。
隔离性 - 事务的中间结果在当前事务之外不可见。
持久性 - 一旦事务提交,其效果将是持久的,即使在系统故障后也是如此。
DBI提供了两种方法来commit或rollback事务。还有一个名为transaction的方法可用于实现事务。有两种简单的方法来实现事务:
方法一
第一种方法使用DBI的commit和rollback方法显式提交或取消事务:
dbh['AutoCommit'] = false # Set auto commit to false.
begin
dbh.do("UPDATE EMPLOYEE SET AGE = AGE+1 WHERE FIRST_NAME = 'John'")
dbh.do("UPDATE EMPLOYEE SET AGE = AGE+1 WHERE FIRST_NAME = 'Zara'")
dbh.commit
rescue
puts "transaction failed"
dbh.rollback
end
dbh['AutoCommit'] = true
方法二
第二种方法使用transaction方法。这更简单,因为它接受一个包含构成事务的语句的代码块。transaction方法执行该块,然后自动调用commit或rollback,具体取决于该块成功还是失败:
dbh['AutoCommit'] = false # Set auto commit to false.
dbh.transaction do |dbh|
dbh.do("UPDATE EMPLOYEE SET AGE = AGE+1 WHERE FIRST_NAME = 'John'")
dbh.do("UPDATE EMPLOYEE SET AGE = AGE+1 WHERE FIRST_NAME = 'Zara'")
end
dbh['AutoCommit'] = true
COMMIT操作
Commit是向数据库发出最终确认更改的信号的操作,此操作后,任何更改都无法恢复。
以下是如何调用commit方法的简单示例。
dbh.commit
ROLLBACK操作
如果您对一个或多个更改不满意,并且希望完全恢复这些更改,则使用rollback方法。
以下是如何调用rollback方法的简单示例。
dbh.rollback
断开数据库连接
要断开数据库连接,请使用disconnect API。
dbh.disconnect
如果用户使用disconnect方法关闭了与数据库的连接,则DBI会回滚任何未完成的事务。但是,您的应用程序最好显式调用commit或rollback,而不是依赖任何DBI的实现细节。
处理错误
错误来源很多。一些示例包括执行的SQL语句中的语法错误、连接故障或对已取消或完成的语句句柄调用fetch方法。
如果DBI方法失败,DBI将引发异常。DBI方法可能会引发多种类型的异常,但两种最重要的异常类是DBI::InterfaceError和DBI::DatabaseError。
这些类的异常对象具有三个名为err、errstr和state的属性,分别表示错误号、描述性错误字符串和标准错误代码。属性解释如下:
err - 返回发生的错误的整数表示形式,如果DBD不支持,则返回nil。例如,Oracle DBD返回ORA-XXXX错误消息的数字部分。
errstr - 返回发生的错误的字符串表示形式。
state - 返回发生的错误的SQLSTATE代码。SQLSTATE是一个五字符长的字符串。大多数DBD不支持此功能,而是返回nil。
您在上面大多数示例中都看到了以下代码:
rescue DBI::DatabaseError => e
puts "An error occurred"
puts "Error code: #{e.err}"
puts "Error message: #{e.errstr}"
dbh.rollback
ensure
# disconnect from server
dbh.disconnect if dbh
end
要获取有关脚本在执行过程中执行的操作的调试信息,您可以启用跟踪。为此,您必须首先加载dbi/trace模块,然后调用控制跟踪模式和输出目标的trace方法:
require "dbi/trace" .............. trace(mode, destination)
mode值可以是0(关闭)、1、2或3,destination应该是IO对象。默认值分别为2和STDERR。
带方法的代码块
有一些方法可以创建句柄。这些方法可以与代码块一起调用。将代码块与方法一起使用的好处是,它们将句柄作为参数传递给代码块,并在块终止时自动清理句柄。以下是一些理解该概念的示例。
DBI.connect - 此方法生成一个数据库句柄,建议在块的末尾调用disconnect以断开数据库连接。
dbh.prepare - 此方法生成一个语句句柄,建议在块的末尾finish。在块中,您必须调用execute方法来执行语句。
dbh.execute - 此方法类似,除了我们不需要在块中调用execute。语句句柄会自动执行。
示例1
DBI.connect可以接受一个代码块,将数据库句柄传递给它,并在块的末尾自动断开句柄,如下所示。
dbh = DBI.connect("DBI:Mysql:TESTDB:localhost", "testuser", "test123") do |dbh|
示例2
dbh.prepare可以接受一个代码块,将语句句柄传递给它,并在块的末尾自动调用finish,如下所示。
dbh.prepare("SHOW DATABASES") do |sth|
sth.execute
puts "Databases: " + sth.fetch_all.join(", ")
end
示例3
dbh.execute可以接受一个代码块,将语句句柄传递给它,并在块的末尾自动调用finish,如下所示:
dbh.execute("SHOW DATABASES") do |sth|
puts "Databases: " + sth.fetch_all.join(", ")
end
DBI transaction方法也接受一个代码块,如上所述。
驱动程序特定函数和属性
DBI允许数据库驱动程序提供其他数据库特定函数,用户可以通过任何Handle对象的func方法调用这些函数。
支持驱动程序特定属性,并且可以使用[]=或[]方法设置或获取这些属性。
示例
#!/usr/bin/ruby
require "dbi"
begin
# connect to the MySQL server
dbh = DBI.connect("DBI:Mysql:TESTDB:localhost", "testuser", "test123")
puts dbh.func(:client_info)
puts dbh.func(:client_version)
puts dbh.func(:host_info)
puts dbh.func(:proto_info)
puts dbh.func(:server_info)
puts dbh.func(:thread_id)
puts dbh.func(:stat)
rescue DBI::DatabaseError => e
puts "An error occurred"
puts "Error code: #{e.err}"
puts "Error message: #{e.errstr}"
ensure
dbh.disconnect if dbh
end
这将产生以下结果:
5.0.45 50045 Localhost via UNIX socket 10 5.0.45 150621 Uptime: 384981 Threads: 1 Questions: 1101078 Slow queries: 4 \ Opens: 324 Flush tables: 1 Open tables: 64 \ Queries per second avg: 2.860
Ruby Web应用程序 - CGI编程
Ruby是一种通用语言;它根本不能称为Web语言。即使如此,Web应用程序和Web工具通常是Ruby最常见的用途。
您不仅可以用Ruby编写自己的SMTP服务器、FTP守护程序或Web服务器,还可以使用Ruby执行更常见的任务,例如CGI编程或替换PHP。
请花几分钟时间阅读CGI编程教程以获取有关CGI编程的更多详细信息。
编写CGI脚本
最基本的Ruby CGI脚本如下所示:
实时演示#!/usr/bin/ruby puts "HTTP/1.0 200 OK" puts "Content-type: text/html\n\n" puts "<html><body>This is a test</body></html>"
如果您将此脚本称为test.cgi并将其上传到具有正确权限的基于Unix的Web托管提供商,则可以将其用作CGI脚本。
例如,如果您在Linux Web托管提供商处托管了网站https://www.example.com/,并且您将test.cgi上传到主目录并授予其执行权限,那么访问https://www.example.com/test.cgi应该会返回一个HTML页面,内容为这是一个测试。
在这里,当从Web浏览器请求test.cgi时,Web服务器会在网站上查找test.cgi,然后使用Ruby解释器执行它。Ruby脚本返回一个基本的HTTP标头,然后返回一个基本的HTML文档。
使用cgi.rb
Ruby 自带一个名为 **cgi** 的特殊库,它能够实现比前面 CGI 脚本更复杂的交互。
让我们创建一个使用 cgi 的基本 CGI 脚本 -
实时演示#!/usr/bin/ruby require 'cgi' cgi = CGI.new puts cgi.header puts "<html><body>This is a test</body></html>"
在这里,您创建了一个 CGI 对象并使用它为您打印标题行。
表单处理
使用 CGI 类,您可以通过两种方式访问 HTML 查询参数。假设我们给定一个 URL 为 /cgi-bin/test.cgi?FirstName = Zara&LastName = Ali。
您可以使用 CGI#[] 直接访问参数 *FirstName* 和 *LastName*,如下所示 -
#!/usr/bin/ruby require 'cgi' cgi = CGI.new cgi['FirstName'] # => ["Zara"] cgi['LastName'] # => ["Ali"]
还有另一种访问这些表单变量的方法。此代码将为您提供所有键值对的哈希表 -
#!/usr/bin/ruby
require 'cgi'
cgi = CGI.new
h = cgi.params # => {"FirstName"=>["Zara"],"LastName"=>["Ali"]}
h['FirstName'] # => ["Zara"]
h['LastName'] # => ["Ali"]
以下是检索所有键的代码 -
#!/usr/bin/ruby require 'cgi' cgi = CGI.new cgi.keys # => ["FirstName", "LastName"]
如果表单包含多个具有相同名称的字段,则相应的将作为数组返回给脚本。[] 访问器只返回这些值中的第一个。对 params 方法的结果进行索引以获取所有值。
在此示例中,假设表单包含三个名为“name”的字段,我们输入了三个名称“Zara”、“Huma”和“Nuha” -
#!/usr/bin/ruby
require 'cgi'
cgi = CGI.new
cgi['name'] # => "Zara"
cgi.params['name'] # => ["Zara", "Huma", "Nuha"]
cgi.keys # => ["name"]
cgi.params # => {"name"=>["Zara", "Huma", "Nuha"]}
**注意** - Ruby 会自动处理 GET 和 POST 方法。这两种不同的方法没有单独的处理。
一个相关的基本表单,可以发送正确的数据,其 HTML 代码如下 -
<html>
<body>
<form method = "POST" action = "http://www.example.com/test.cgi">
First Name :<input type = "text" name = "FirstName" value = "" />
<br />
Last Name :<input type = "text" name = "LastName" value = "" />
<input type = "submit" value = "Submit Data" />
</form>
</body>
</html>
创建表单和 HTML
CGI 包含大量用于创建 HTML 的方法。您会发现每个标签对应一个方法。为了启用这些方法,您必须通过调用 CGI.new 创建一个 CGI 对象。
为了使标签嵌套更容易,这些方法将内容作为代码块。代码块应返回一个 *String*,该字符串将用作标签的内容。例如 -
#!/usr/bin/ruby
require "cgi"
cgi = CGI.new("html4")
cgi.out {
cgi.html {
cgi.head { "\n"+cgi.title{"This Is a Test"} } +
cgi.body { "\n"+
cgi.form {"\n"+
cgi.hr +
cgi.h1 { "A Form: " } + "\n"+
cgi.textarea("get_text") +"\n"+
cgi.br +
cgi.submit
}
}
}
}
**注意** - CGI 类的 *form* 方法可以接受一个 method 参数,该参数将设置在表单提交时使用的 HTTP 方法(GET、POST 等)。在此示例中使用的默认值为 POST。
这将产生以下结果:
Content-Type: text/html
Content-Length: 302
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Final//EN">
<HTML>
<HEAD>
<TITLE>This Is a Test</TITLE>
</HEAD>
<BODY>
<FORM METHOD = "post" ENCTYPE = "application/x-www-form-urlencoded">
<HR>
<H1>A Form: </H1>
<TEXTAREA COLS = "70" NAME = "get_text" ROWS = "10"></TEXTAREA>
<BR>
<INPUT TYPE = "submit">
</FORM>
</BODY>
</HTML>
引用字符串
处理 URL 和 HTML 代码时,必须小心地引用某些字符。例如,斜杠字符 (/) 在 URL 中具有特殊含义,因此如果它不是路径名的一部分,则必须对其进行 **转义**。
例如,URL 查询部分中的任何 / 将被转换为字符串 %2F,并且必须将其转换回 / 才能使用它。空格和 & 符号也是特殊字符。为了处理这个问题,CGI 提供了 **CGI.escape** 和 **CGI.unescape** 两个例程。
#!/usr/bin/ruby require 'cgi' puts CGI.escape(Zara Ali/A Sweet & Sour Girl")
这将产生以下结果:
Zara+Ali%2FA Sweet+%26+Sour+Girl")
#!/usr/bin/ruby
require 'cgi'
puts CGI.escapeHTML('<h1>Zara Ali/A Sweet & Sour Girl</h1>')
这将产生以下结果:
<h1>Zara Ali/A Sweet & Sour Girl</h1>'
CGI 类中的常用方法
以下是与 CGI 类相关的方法列表 -
The Ruby CGI - 与标准 CGI 库相关的方法。
Cookie 和会话
我们在不同的部分解释了这两个概念。请参考以下部分 -
The Ruby CGI Cookies - 如何处理 CGI Cookie。
The Ruby CGI Sessions - 如何管理 CGI 会话。
Web 托管服务器
您可以在互联网上查看以下主题,以了解如何在基于 Unix 的服务器上托管您的网站 -
使用 Ruby 发送电子邮件 - SMTP
简单邮件传输协议 (SMTP) 是一种协议,它处理发送电子邮件和在邮件服务器之间路由电子邮件。
Ruby 提供 Net::SMTP 类用于简单邮件传输协议 (SMTP) 客户端连接,并提供两个类方法 *new* 和 *start*。
**new** 接受两个参数 -
服务器名称,默认为 localhost。
端口号,默认为众所周知的端口 25。
**start** 方法接受以下参数 -
服务器 - SMTP 服务器的 IP 名称,默认为 localhost。
端口 - 端口号,默认为 25。
域名 - 邮件发送者的域名,默认为 ENV["HOSTNAME"]。
帐户 - 用户名,默认为 nil。
密码 - 用户密码,默认为 nil。
authtype - 授权类型,默认为 *cram_md5*。
SMTP 对象有一个名为 sendmail 的实例方法,通常用于执行发送邮件的工作。它接受三个参数 -
源 - 字符串或数组或任何具有 *each* 迭代器并一次返回一个字符串的对象。
发送者 - 将出现在电子邮件 *from* 字段中的字符串。
收件人 - 字符串或字符串数组,表示收件人的地址。
示例
以下是如何使用 Ruby 脚本发送一封简单电子邮件的方法。试一试 -
require 'net/smtp'
message = <<MESSAGE_END
From: Private Person <me@fromdomain.com>
To: A Test User <test@todomain.com>
Subject: SMTP e-mail test
This is a test e-mail message.
MESSAGE_END
Net::SMTP.start('localhost') do |smtp|
smtp.send_message message, 'me@fromdomain.com', 'test@todomain.com'
end
在这里,您将基本电子邮件放在 message 中,使用文档,注意正确格式化标头。电子邮件需要 **From**、**To** 和 **Subject** 标头,并用空行与电子邮件正文隔开。
要发送邮件,您可以使用 Net::SMTP 连接到本地机器上的 SMTP 服务器,然后使用 send_message 方法以及邮件、发件人地址和目标地址作为参数(即使发件人和收件人地址在电子邮件本身中,这些并不总是用于路由邮件)。
如果您在机器上没有运行 SMTP 服务器,则可以使用 Net::SMTP 与远程 SMTP 服务器通信。除非您使用的是 Web 邮件服务(例如 Hotmail 或 Yahoo! Mail),否则您的电子邮件提供商将为您提供传出邮件服务器详细信息,您可以将其提供给 Net::SMTP,如下所示 -
Net::SMTP.start('mail.your-domain.com')
此代码行连接到 mail.your-domain.com 端口 25 上的 SMTP 服务器,不使用任何用户名或密码。但是,如果您需要,可以指定端口号和其他详细信息。例如 -
Net::SMTP.start('mail.your-domain.com',
25,
'localhost',
'username', 'password' :plain)
此示例连接到 mail.your-domain.com 上的 SMTP 服务器,使用明文格式的用户名和密码。它将客户端的主机名标识为 localhost。
使用 Ruby 发送 HTML 电子邮件
当您使用 Ruby 发送文本消息时,所有内容都将被视为简单文本。即使您在文本消息中包含 HTML 标签,它也将显示为简单文本,并且 HTML 标签不会根据 HTML 语法进行格式化。但是 Ruby Net::SMTP 提供了将 HTML 消息作为实际 HTML 消息发送的选项。
发送电子邮件消息时,您可以指定 Mime 版本、内容类型和字符集以发送 HTML 电子邮件。
示例
以下是发送 HTML 内容作为电子邮件的示例。试一试 -
require 'net/smtp'
message = <<MESSAGE_END
From: Private Person <me@fromdomain.com>
To: A Test User <test@todomain.com>
MIME-Version: 1.0
Content-type: text/html
Subject: SMTP e-mail test
This is an e-mail message to be sent in HTML format
<b>This is HTML message.</b>
<h1>This is headline.</h1>
MESSAGE_END
Net::SMTP.start('localhost') do |smtp|
smtp.send_message message, 'me@fromdomain.com', 'test@todomain.com'
end
将附件作为电子邮件发送
要发送包含混合内容的电子邮件,需要将 **Content-type** 标头设置为 **multipart/mixed**。然后可以在 **边界** 内指定文本和附件部分。
边界以两个连字符后跟一个唯一数字开头,该数字不能出现在电子邮件的消息部分中。表示电子邮件最终部分的最终边界也必须以两个连字符结尾。
附加文件应使用 **pack("m")** 函数进行编码,以便在传输前进行 base64 编码。
示例
以下示例将文件 ** /tmp/test.txt** 作为附件发送。
require 'net/smtp'
filename = "/tmp/test.txt"
# Read a file and encode it into base64 format
filecontent = File.read(filename)
encodedcontent = [filecontent].pack("m") # base64
marker = "AUNIQUEMARKER"
body = <<EOF
This is a test email to send an attachement.
EOF
# Define the main headers.
part1 = <<EOF
From: Private Person <me@fromdomain.net>
To: A Test User <test@todmain.com>
Subject: Sending Attachement
MIME-Version: 1.0
Content-Type: multipart/mixed; boundary = #{marker}
--#{marker}
EOF
# Define the message action
part2 = <<EOF
Content-Type: text/plain
Content-Transfer-Encoding:8bit
#{body}
--#{marker}
EOF
# Define the attachment section
part3 = <<EOF
Content-Type: multipart/mixed; name = \"#{filename}\"
Content-Transfer-Encoding:base64
Content-Disposition: attachment; filename = "#{filename}"
#{encodedcontent}
--#{marker}--
EOF
mailtext = part1 + part2 + part3
# Let's put our code in safe area
begin
Net::SMTP.start('localhost') do |smtp|
smtp.sendmail(mailtext, 'me@fromdomain.net', ['test@todmain.com'])
end
rescue Exception => e
print "Exception occured: " + e
end
**注意** - 您可以在数组中指定多个目标,但它们应以逗号分隔。
Ruby - 套接字编程
Ruby 提供了两个级别的网络服务访问。在低级别,您可以访问底层操作系统中的基本套接字支持,这允许您为面向连接和无连接协议实现客户端和服务器。
Ruby 还有一些库提供对特定应用程序级网络协议(如 FTP、HTTP 等)的更高级别的访问。
本章使您了解网络中最著名的概念 - 套接字编程。
什么是套接字?
套接字是双向通信通道的端点。套接字可以在一个进程内、同一台机器上的不同进程之间或不同大陆上的不同进程之间通信。
套接字可以在许多不同的通道类型上实现:Unix 域套接字、TCP、UDP 等。*套接字* 为处理常用传输提供了特定的类,以及用于处理其余传输的通用接口。
套接字有自己的词汇表 -
| 序号 | 术语 & 描述 |
|---|---|
| 1 | 域 将用作传输机制的协议族。这些值是常量,例如 PF_INET、PF_UNIX、PF_X25 等。 |
| 2 | 类型 两个端点之间的通信类型,通常对于面向连接的协议为 SOCK_STREAM,对于无连接的协议为 SOCK_DGRAM。 |
| 3 | 协议 通常为零,这可用于识别域和类型内协议的变体。 |
| 4 | 主机名 网络接口的标识符 - 字符串,可以是主机名、点分四段式地址或冒号(可能还有点)表示法的 IPv6 地址 字符串“<broadcast>”指定 INADDR_BROADCAST 地址。 零长度字符串,指定 INADDR_ANY,或 整数,解释为主机字节序中的二进制地址。 |
| 5 | 端口 每个服务器侦听一个或多个端口上的客户端调用。端口可以是 Fixnum 端口号、包含端口号的字符串或服务的名称。 |
一个简单的客户端
在这里,我们将编写一个非常简单的客户端程序,它将打开到给定端口和给定主机的连接。Ruby 类 **TCPSocket** 提供 *open* 函数来打开这样的套接字。
**TCPSocket.open(hosname, port )** 在 *port* 上打开到 *hostname* 的 TCP 连接。
打开套接字后,您可以像处理任何 IO 对象一样从中读取数据。完成后,请记住关闭它,就像关闭文件一样。
以下代码是一个非常简单的客户端,它连接到给定的主机和端口,从套接字读取所有可用数据,然后退出 -
require 'socket' # Sockets are in standard library hostname = 'localhost' port = 2000 s = TCPSocket.open(hostname, port) while line = s.gets # Read lines from the socket puts line.chop # And print with platform line terminator end s.close # Close the socket when done
一个简单的服务器
要编写 Internet 服务器,我们使用 **TCPServer** 类。TCPServer 对象是 TCPSocket 对象的工厂。
现在调用 **TCPServer.open(hostname, port** 函数为您的服务指定一个 *port* 并创建一个 **TCPServer** 对象。
接下来,调用返回的 TCPServer 对象的 accept 方法。此方法等待客户端连接到您指定的端口,然后返回一个表示与该客户端连接的 TCPSocket 对象。
require 'socket' # Get sockets from stdlib
server = TCPServer.open(2000) # Socket to listen on port 2000
loop { # Servers run forever
client = server.accept # Wait for a client to connect
client.puts(Time.now.ctime) # Send the time to the client
client.puts "Closing the connection. Bye!"
client.close # Disconnect from the client
}
现在,在后台运行此服务器,然后运行上述客户端以查看结果。
多客户端 TCP 服务器
互联网上的大多数服务器都设计用于同时处理大量客户端。
Ruby 的 Thread 类使创建多线程服务器变得容易。一个服务器接受请求并立即创建一个新的执行线程来处理连接,同时允许主程序等待更多连接 -
require 'socket' # Get sockets from stdlib
server = TCPServer.open(2000) # Socket to listen on port 2000
loop { # Servers run forever
Thread.start(server.accept) do |client|
client.puts(Time.now.ctime) # Send the time to the client
client.puts "Closing the connection. Bye!"
client.close # Disconnect from the client
end
}
在此示例中,您有一个永久循环,当 server.accept 响应时,会立即创建一个新的线程并启动它以处理刚刚接受的连接,使用传递到线程的连接对象。但是,主程序会立即循环返回并等待新的连接。
以这种方式使用 Ruby 线程意味着代码是可移植的,并且可以在 Linux、OS X 和 Windows 上以相同的方式运行。
一个小型 Web 浏览器
我们可以使用套接字库来实现任何互联网协议。例如,以下是一段获取网页内容的代码 -
require 'socket'
host = 'www.tutorialspoint.com' # The web server
port = 80 # Default HTTP port
path = "/index.htm" # The file we want
# This is the HTTP request we send to fetch a file
request = "GET #{path} HTTP/1.0\r\n\r\n"
socket = TCPSocket.open(host,port) # Connect to server
socket.print(request) # Send request
response = socket.read # Read complete response
# Split response at first blank line into headers and body
headers,body = response.split("\r\n\r\n", 2)
print body # And display it
要实现类似的 Web 客户端,您可以使用预构建的库,如 Net::HTTP,用于处理 HTTP。以下代码等效于前面的代码 -
require 'net/http' # The library we need
host = 'www.tutorialspoint.com' # The web server
path = '/index.htm' # The file we want
http = Net::HTTP.new(host) # Create a connection
headers, body = http.get(path) # Request the file
if headers.code == "200" # Check the status code
print body
else
puts "#{headers.code} #{headers.message}"
end
请检查类似的库以处理 FTP、SMTP、POP 和 IMAP 协议。
进一步阅读
我们为您提供了套接字编程的快速入门。这是一个很大的主题,因此建议您阅读 Ruby 套接字库和类方法 以了解更多详细信息。
Ruby - XML、XSLT 和 XPath 教程
什么是 XML?
可扩展标记语言 (XML) 是一种标记语言,类似于 HTML 或 SGML。这是万维网联盟推荐的,并作为开放标准提供。
XML 是一种可移植的开源语言,允许程序员开发可以被其他应用程序读取的应用程序,而不管操作系统和/或开发语言如何。
XML 在无需基于 SQL 的后端的情况下跟踪少量到中等数量的数据方面非常有用。
XML 解析器架构和 API
XML 解析器有两种不同的类型 -
SAX 式(流接口) - 在这里,您为感兴趣的事件注册回调,然后让解析器遍历文档。当您的文档很大或您有内存限制时,这很有用,它在从磁盘读取文件时解析文件,并且整个文件永远不会存储在内存中。
DOM 式(对象树接口) - 这是万维网联盟的建议,其中整个文件被读入内存并存储在分层(基于树)的形式中,以表示 XML 文档的所有功能。
在处理大型文件时,SAX 的处理速度显然不如 DOM 快。另一方面,仅使用 DOM 可能会严重消耗您的资源,尤其是在处理大量小文件时。
SAX 是只读的,而 DOM 允许更改 XML 文件。由于这两个不同的 API 实际上是互补的,因此您没有理由不能将它们都用于大型项目。
使用 Ruby 解析和创建 XML
操作 XML 最常见的方法是使用 Sean Russell 的 REXML 库。自 2002 年以来,REXML 一直是标准 Ruby 发行版的一部分。
REXML 是一个纯 Ruby XML 处理器,符合 XML 1.0 标准。它是一个非验证处理器,通过了所有 OASIS 非验证一致性测试。
与其他可用的解析器相比,REXML 解析器具有以下优点 -
- 它完全用 Ruby 编写。
- 它可用于 SAX 和 DOM 解析。
- 它很轻量级,代码少于 2000 行。
- 方法和类非常易于理解。
- 基于 SAX2 的 API 和完整的 XPath 支持。
- 随 Ruby 安装一起提供,无需单独安装。
对于我们所有的 XML 代码示例,让我们使用一个简单的 XML 文件作为输入 -
<collection shelf = "New Arrivals">
<movie title = "Enemy Behind">
<type>War, Thriller</type>
<format>DVD</format>
<year>2003</year>
<rating>PG</rating>
<stars>10</stars>
<description>Talk about a US-Japan war</description>
</movie>
<movie title = "Transformers">
<type>Anime, Science Fiction</type>
<format>DVD</format>
<year>1989</year>
<rating>R</rating>
<stars>8</stars>
<description>A schientific fiction</description>
</movie>
<movie title = "Trigun">
<type>Anime, Action</type>
<format>DVD</format>
<episodes>4</episodes>
<rating>PG</rating>
<stars>10</stars>
<description>Vash the Stampede!</description>
</movie>
<movie title = "Ishtar">
<type>Comedy</type>
<format>VHS</format>
<rating>PG</rating>
<stars>2</stars>
<description>Viewable boredom</description>
</movie>
</collection>
DOM 式解析
让我们首先以树状方式解析我们的 XML 数据。我们首先需要 rexml/document 库;通常我们会执行 include REXML 以方便导入到顶层命名空间中。
#!/usr/bin/ruby -w
require 'rexml/document'
include REXML
xmlfile = File.new("movies.xml")
xmldoc = Document.new(xmlfile)
# Now get the root element
root = xmldoc.root
puts "Root element : " + root.attributes["shelf"]
# This will output all the movie titles.
xmldoc.elements.each("collection/movie"){
|e| puts "Movie Title : " + e.attributes["title"]
}
# This will output all the movie types.
xmldoc.elements.each("collection/movie/type") {
|e| puts "Movie Type : " + e.text
}
# This will output all the movie description.
xmldoc.elements.each("collection/movie/description") {
|e| puts "Movie Description : " + e.text
}
这将产生以下结果:
Root element : New Arrivals Movie Title : Enemy Behind Movie Title : Transformers Movie Title : Trigun Movie Title : Ishtar Movie Type : War, Thriller Movie Type : Anime, Science Fiction Movie Type : Anime, Action Movie Type : Comedy Movie Description : Talk about a US-Japan war Movie Description : A schientific fiction Movie Description : Vash the Stampede! Movie Description : Viewable boredom
SAX 式解析
要以面向流的方式处理相同的数据(movies.xml 文件),我们将定义一个侦听器类,其方法将成为解析器回调的目标。
注意 - 不建议对小文件使用 SAX 式解析,这只用于演示示例。
#!/usr/bin/ruby -w
require 'rexml/document'
require 'rexml/streamlistener'
include REXML
class MyListener
include REXML::StreamListener
def tag_start(*args)
puts "tag_start: #{args.map {|x| x.inspect}.join(', ')}"
end
def text(data)
return if data =~ /^\w*$/ # whitespace only
abbrev = data[0..40] + (data.length > 40 ? "..." : "")
puts " text : #{abbrev.inspect}"
end
end
list = MyListener.new
xmlfile = File.new("movies.xml")
Document.parse_stream(xmlfile, list)
这将产生以下结果:
tag_start: "collection", {"shelf"=>"New Arrivals"}
tag_start: "movie", {"title"=>"Enemy Behind"}
tag_start: "type", {}
text : "War, Thriller"
tag_start: "format", {}
tag_start: "year", {}
tag_start: "rating", {}
tag_start: "stars", {}
tag_start: "description", {}
text : "Talk about a US-Japan war"
tag_start: "movie", {"title"=>"Transformers"}
tag_start: "type", {}
text : "Anime, Science Fiction"
tag_start: "format", {}
tag_start: "year", {}
tag_start: "rating", {}
tag_start: "stars", {}
tag_start: "description", {}
text : "A schientific fiction"
tag_start: "movie", {"title"=>"Trigun"}
tag_start: "type", {}
text : "Anime, Action"
tag_start: "format", {}
tag_start: "episodes", {}
tag_start: "rating", {}
tag_start: "stars", {}
tag_start: "description", {}
text : "Vash the Stampede!"
tag_start: "movie", {"title"=>"Ishtar"}
tag_start: "type", {}
tag_start: "format", {}
tag_start: "rating", {}
tag_start: "stars", {}
tag_start: "description", {}
text : "Viewable boredom"
XPath 和 Ruby
查看 XML 的另一种方法是 XPath。这是一种伪语言,描述了如何在 XML 文档中定位特定元素和属性,将该文档视为一个逻辑有序的树。
REXML 通过 XPath 类支持 XPath。正如我们上面所看到的,它假设基于树的解析(文档对象模型)。
#!/usr/bin/ruby -w
require 'rexml/document'
include REXML
xmlfile = File.new("movies.xml")
xmldoc = Document.new(xmlfile)
# Info for the first movie found
movie = XPath.first(xmldoc, "//movie")
p movie
# Print out all the movie types
XPath.each(xmldoc, "//type") { |e| puts e.text }
# Get an array of all of the movie formats.
names = XPath.match(xmldoc, "//format").map {|x| x.text }
p names
这将产生以下结果:
<movie title = 'Enemy Behind'> ... </> War, Thriller Anime, Science Fiction Anime, Action Comedy ["DVD", "DVD", "DVD", "VHS"]
XSLT 和 Ruby
Ruby 可以使用两个可用的 XSLT 解析器。这里简要介绍了每个解析器。
Ruby-Sablotron
此解析器由 Takahashi Masayoshi 编写和维护。它主要为 Linux 操作系统编写,需要以下库 -
- Sablot
- Iconv
- Expat
您可以在 Ruby-Sablotron 中找到此模块。
XSLT4R
XSLT4R 由 Michael Neumann 编写,可以在 RAA 的库部分(XML 下)找到。XSLT4R 使用简单的命令行界面,尽管它也可以在第三方应用程序中使用以转换 XML 文档。
XSLT4R 需要 XMLScan 才能运行,XMLScan 包含在 XSLT4R 存档中,并且也是一个 100% 的 Ruby 模块。可以使用标准的 Ruby 安装方法(即 ruby install.rb)安装这些模块。
XSLT4R 具有以下语法 -
ruby xslt.rb stylesheet.xsl document.xml [arguments]
如果要从应用程序内部使用 XSLT4R,则可以包含 XSLT 并输入所需的参数。以下是一个示例 -
require "xslt"
stylesheet = File.readlines("stylesheet.xsl").to_s
xml_doc = File.readlines("document.xml").to_s
arguments = { 'image_dir' => '/....' }
sheet = XSLT::Stylesheet.new( stylesheet, arguments )
# output to StdOut
sheet.apply( xml_doc )
# output to 'str'
str = ""
sheet.output = [ str ]
sheet.apply( xml_doc )
进一步阅读
有关 REXML 解析器的完整详细信息,请参阅 REXML 解析器文档 的标准文档。
您可以从 RAA 存储库 下载 XSLT4R。
使用 Ruby 的 Web 服务 - SOAP4R
什么是 SOAP?
简单对象访问协议 (SOAP) 是一种基于 XML 的跨平台和语言无关的 RPC 协议,通常(但并非总是)使用 HTTP。
它使用 XML 编码进行远程过程调用的信息,并使用 HTTP 通过网络在客户端和服务器之间传输这些信息,反之亦然。
与其他技术(如 COM、CORBA 等)相比,SOAP 具有若干优势:例如,其相对较低的部署和调试成本、其可扩展性和易用性,以及针对不同语言和平台的多个实现的存在。
请参阅我们的简单教程 SOAP 以详细了解它。
本章使您熟悉 Ruby 的 SOAP 实现 (SOAP4R)。这是一个基本的教程,因此如果您需要深入了解,则需要参考其他资源。
安装 SOAP4R
SOAP4R 是 Nakamura Hiroshi 开发的 Ruby 的 SOAP 实现,可以从以下位置下载 -
注意 - 您很有可能已经安装了此组件。
Download SOAP
如果您了解 gem 实用程序,则可以使用以下命令安装 SOAP4R 和相关包。
$ gem install soap4r --include-dependencies
如果您在 Windows 上工作,则需要从上述位置下载一个压缩文件,并需要通过运行 ruby install.rb 使用标准安装方法安装它。
编写 SOAP4R 服务器
SOAP4R 支持两种不同类型的服务器 -
- 基于 CGI/FastCGI (SOAP::RPC::CGIStub)
- 独立 (SOAP::RPC:StandaloneServer)
本章详细介绍了编写独立服务器。编写 SOAP 服务器涉及以下步骤。
步骤 1 - 继承 SOAP::RPC::StandaloneServer 类
要实现您自己的独立服务器,您需要编写一个新类,它将成为 SOAP::StandaloneServer 的子类,如下所示 -
class MyServer < SOAP::RPC::StandaloneServer ............... end
注意 - 如果要编写基于 FastCGI 的服务器,则需要将 SOAP::RPC::CGIStub 作为父类,其余过程将保持不变。
步骤 2 - 定义处理程序方法
第二步是编写您希望公开给外部世界的 Web 服务方法。
它们可以写成简单的 Ruby 方法。例如,让我们编写两个方法来添加两个数字和除以两个数字 -
class MyServer < SOAP::RPC::StandaloneServer
...............
# Handler methods
def add(a, b)
return a + b
end
def div(a, b)
return a / b
end
end
步骤 3 - 公开处理程序方法
下一步是将我们定义的方法添加到我们的服务器中。initialize 方法用于使用以下两种方法之一公开服务方法 -
class MyServer < SOAP::RPC::StandaloneServer
def initialize(*args)
add_method(receiver, methodName, *paramArg)
end
end
以下是参数的描述 -
| 序号 | 参数 & 说明 |
|---|---|
| 1 | 接收器 包含 methodName 方法的对象。您在与 methodDef 方法相同的类中定义服务方法,此参数为 self。 |
| 2 | 方法名称 由于 RPC 请求而调用的方法的名称。 |
| 3 | 参数参数 指定(如果给出)参数名称和参数模式。 |
要了解 inout 或 out 参数的用法,请考虑以下服务方法,该方法采用两个参数(inParam 和 inoutParam),返回一个普通返回值 (retVal) 和另外两个参数:inoutParam 和 outParam -
def aMeth(inParam, inoutParam) retVal = inParam + inoutParam outParam = inParam . inoutParam inoutParam = inParam * inoutParam return retVal, inoutParam, outParam end
现在,我们可以公开此方法,如下所示 -
add_method(self, 'aMeth', [ %w(in inParam), %w(inout inoutParam), %w(out outParam), %w(retval return) ])
步骤 4 - 启动服务器
最后一步是通过实例化派生类的一个实例并调用 start 方法来启动服务器。
myServer = MyServer.new('ServerName', 'urn:ruby:ServiceName', hostname, port)
myServer.start
以下是所需参数的描述 -
| 序号 | 参数 & 说明 |
|---|---|
| 1 | 服务器名称 服务器名称,您可以随意指定。 |
| 2 | urn:ruby:ServiceName 这里 urn:ruby 是常量,但您可以为此服务器提供唯一的 ServiceName 名称。 |
| 3 | 主机名 指定此服务器将侦听的主机名。 |
| 4 | 端口 用于 Web 服务的可用端口号。 |
示例
现在,使用上述步骤,让我们编写一个独立服务器:
require "soap/rpc/standaloneserver"
begin
class MyServer < SOAP::RPC::StandaloneServer
# Expose our services
def initialize(*args)
add_method(self, 'add', 'a', 'b')
add_method(self, 'div', 'a', 'b')
end
# Handler methods
def add(a, b)
return a + b
end
def div(a, b)
return a / b
end
end
server = MyServer.new("MyServer",
'urn:ruby:calculation', 'localhost', 8080)
trap('INT){
server.shutdown
}
server.start
rescue => err
puts err.message
end
执行此服务器应用程序时,它会在localhost上启动一个独立的 SOAP 服务器,并在端口8080上监听请求。它公开了两种服务方法,add和div,它们接受两个参数并返回结果。
现在,您可以按如下方式在后台运行此服务器:
$ ruby MyServer.rb&
编写 SOAP4R 客户端
SOAP::RPC::Driver类提供对编写 SOAP 客户端应用程序的支持。本章描述了此类,并基于应用程序演示了其用法。
以下是调用 SOAP 服务所需的最少信息:
- SOAP 服务的 URL(SOAP 端点 URL)。
- 服务方法的命名空间(方法命名空间 URI)。
- 服务方法的名称及其参数。
现在,我们将编写一个 SOAP 客户端,它将调用上面示例中定义的服务方法,名为add和div。
以下是创建 SOAP 客户端的主要步骤。
步骤 1 - 创建 SOAP 驱动程序实例
我们通过调用其新方法创建SOAP::RPC::Driver的实例,如下所示:
SOAP::RPC::Driver.new(endPoint, nameSpace, soapAction)
以下是所需参数的描述 -
| 序号 | 参数 & 说明 |
|---|---|
| 1 | endPoint 要连接的 SOAP 服务器的 URL。 |
| 2 | nameSpace 与此 SOAP::RPC::Driver 对象执行的所有 RPC 使用的命名空间。 |
| 3 | soapAction HTTP 标头的 SOAPAction 字段的值。如果为 nil,则默认为空字符串 ""。 |
步骤 2 - 添加服务方法
要将 SOAP 服务方法添加到SOAP::RPC::Driver,我们可以使用SOAP::RPC::Driver实例调用以下方法:
driver.add_method(name, *paramArg)
以下是参数的描述 -
| 序号 | 参数 & 说明 |
|---|---|
| 1 | name 远程 Web 服务方法的名称。 |
| 2 | 参数参数 指定远程过程的参数名称。 |
步骤 3 - 调用 SOAP 服务
最后一步是使用SOAP::RPC::Driver实例调用 SOAP 服务,如下所示:
result = driver.serviceMethod(paramArg...)
这里serviceMethod是实际的 Web 服务方法,paramArg...是传递给服务方法所需的参数列表。
示例
根据上述步骤,我们将编写如下 SOAP 客户端:
#!/usr/bin/ruby -w
require 'soap/rpc/driver'
NAMESPACE = 'urn:ruby:calculation'
URL = 'https://:8080/'
begin
driver = SOAP::RPC::Driver.new(URL, NAMESPACE)
# Add remote sevice methods
driver.add_method('add', 'a', 'b')
# Call remote service methods
puts driver.add(20, 30)
rescue => err
puts err.message
end
进一步阅读
我向您解释了使用 Ruby 的 Web 服务的基本概念。如果您想进一步深入了解,请访问以下链接以查找有关使用 Ruby 的 Web 服务的更多详细信息。
Ruby - Tk 指南
简介
Ruby 的标准图形用户界面 (GUI) 是 Tk。Tk 最初是 John Ousterhout 开发的 Tcl 脚本语言的 GUI。
Tk 具有作为唯一跨平台 GUI 的独特优势。Tk 可以在 Windows、Mac 和 Linux 上运行,并在每个操作系统上提供原生外观和感觉。
基于 Tk 的应用程序的基本组件称为部件。组件有时也称为窗口,因为在 Tk 中,“窗口”和“部件”通常可以互换使用。
Tk 应用程序遵循部件层次结构,其中任意数量的部件可以放置在另一个部件中,而这些部件又可以放置在另一个部件中,以此类推。Tk 程序中的主要部件称为根部件,可以通过创建 TkRoot 类的新的实例来创建。
大多数基于 Tk 的应用程序遵循相同的循环:创建部件、将它们放置在界面中,最后将与每个部件关联的事件绑定到方法。
有三个几何管理器;place、grid和pack负责控制界面中每个部件的大小和位置。
安装
Ruby Tk 绑定与 Ruby 一起分发,但 Tk 是单独安装的。Windows 用户可以从ActiveState 的 ActiveTcl下载一键式 Tk 安装程序。
Mac 和 Linux 用户可能不需要安装它,因为很有可能它已经随操作系统一起安装了,但如果没有,您可以下载预构建的软件包或从Tcl 开发者交换获取源代码。
简单的 Tk 应用程序
Ruby/Tk 程序的典型结构是创建主窗口或根窗口(TkRoot 的实例),向其中添加部件以构建用户界面,然后通过调用Tk.mainloop启动主事件循环。
Ruby/Tk 的传统Hello, World!示例如下所示:
require 'tk'
root = TkRoot.new { title "Hello, World!" }
TkLabel.new(root) do
text 'Hello, World!'
pack { padx 15 ; pady 15; side 'left' }
end
Tk.mainloop
这里,在加载 tk 扩展模块后,我们使用TkRoot.new创建一个根级框架。然后,我们创建一个TkLabel部件作为根框架的子部件,并为标签设置几个选项。最后,我们打包根框架并进入主 GUI 事件循环。
如果您运行此脚本,它将产生以下结果:
Ruby/Tk 部件类
以下是各种 Ruby/Tk 类列表,可以使用它们使用 Ruby/Tk 创建所需的 GUI。
TkFrame 创建和操作框架部件。
TkButton 创建和操作按钮部件。
TkLabel 创建和操作标签部件。
TkEntry 创建和操作输入部件。
TkCheckButton 创建和操作复选框部件。
TkRadioButton 创建和操作单选按钮部件。
TkListbox 创建和操作列表框部件。
TkComboBox 创建和操作组合框部件。
TkMenu 创建和操作菜单部件。
TkMenubutton 创建和操作菜单按钮部件。
Tk.messageBox 创建和操作消息对话框。
TkScrollbar 创建和操作滚动条部件。
TkCanvas 创建和操作画布部件。
TkScale 创建和操作刻度部件。
TkText 创建和操作文本部件。
TkToplevel 创建和操作顶级部件。
TkSpinbox 创建和操作微调框部件。
TkProgressBar 创建和操作进度条部件。
对话框 创建和操作对话框部件。
Tk::Tile::Notebook 使用笔记本隐喻在有限的空间中显示多个窗口。
Tk::Tile::Paned 显示垂直或水平堆叠的多个子窗口。
Tk::Tile::Separator 显示水平或垂直分隔线。
Ruby/Tk 字体、颜色和图像 了解 Ruby/Tk 字体、颜色和图像
标准配置选项
所有部件都具有一些不同的配置选项,这些选项通常控制部件的显示方式或行为方式。可用的选项当然取决于部件类。
以下是所有标准配置选项的列表,这些选项可能适用于任何 Ruby/Tk 部件。
Ruby/Tk 几何管理
几何管理处理根据需要定位不同小部件。Tk 中的几何管理依赖于主小部件和从属小部件的概念。
主小部件是一个小部件,通常是顶级窗口或框架,它将包含其他称为从属小部件的小部件。您可以将几何管理器视为控制主小部件并决定将在其中显示的内容。
几何管理器将询问每个从属小部件其自然大小,或者它理想情况下希望显示多大。然后,它获取该信息并将其与程序在要求几何管理器管理该特定从属小部件时提供的任何参数相结合。
有三个几何管理器 *place*、*grid* 和 *pack* 负责控制界面中每个小部件的大小和位置。
Ruby/Tk 事件处理
Ruby/Tk 支持 *事件循环*,它接收来自操作系统的事件。这些事件包括按钮按下、按键、鼠标移动、窗口调整大小等。
Ruby/Tk 会为您管理此事件循环。它将确定事件适用于哪个小部件(用户是否单击了此按钮?如果按下了键,哪个文本框具有焦点?),并相应地分派它。各个小部件知道如何响应事件,例如,当鼠标移到按钮上时,按钮可能会更改颜色,当鼠标离开时恢复原样。
在更高级别上,Ruby/Tk 在您的程序中调用回调以指示小部件发生了某些重要事件。对于这两种情况,您可以提供一个代码块或一个 *Ruby Proc* 对象,该对象指定应用程序如何响应事件或回调。
让我们看看如何使用 bind 方法将基本窗口系统事件与处理它们的 Ruby 过程关联起来。bind 的最简单形式以字符串(指示事件名称)和代码块(Tk 用于处理事件)作为输入。
例如,要捕获某个小部件上第一个鼠标按钮的 *ButtonRelease* 事件,您可以编写:
someWidget.bind('ButtonRelease-1') {
....code block to handle this event...
}
事件名称可以包含其他修饰符和详细信息。修饰符是一个字符串,如 *Shift*、*Control* 或 *Alt*,表示按下了其中一个修饰键。
因此,例如,要捕获用户按住 *Ctrl* 键并单击鼠标右键时生成的事件。
someWidget.bind('Control-ButtonPress-3', proc { puts "Ouch!" })
许多 Ruby/Tk 小部件在用户激活它们时可以触发 *回调*,并且您可以使用 *command* 回调来指定在发生这种情况时调用某个代码块或过程。如前所述,您可以在创建小部件时指定命令回调过程:
helpButton = TkButton.new(buttonFrame) {
text "Help"
command proc { showHelp }
}
或者,您可以使用小部件的 *command* 方法稍后分配它:
helpButton.command proc { showHelp }
由于 command 方法接受过程或代码块,因此您也可以将前面的代码示例编写为:
helpButton = TkButton.new(buttonFrame) {
text "Help"
command { showHelp }
}
configure 方法
configure 方法可用于设置和检索任何小部件配置值。例如,要更改按钮的宽度,您可以随时调用 configure 方法,如下所示:
require "tk"
button = TkButton.new {
text 'Hello World!'
pack
}
button.configure('activebackground', 'blue')
Tk.mainloop
要获取当前小部件的值,只需在不提供值的情况下提供它,如下所示:
color = button.configure('activebackground')
您还可以完全不带任何选项调用 configure,这将为您提供所有选项及其值的列表。
cget 方法
对于简单地检索选项的值,configure 返回的信息通常比您想要的更多。cget 方法仅返回当前值。
color = button.cget('activebackground')
Ruby - LDAP 教程
Ruby/LDAP 是 Ruby 的扩展库。它提供了一些 LDAP 库(如 OpenLDAP、UMich LDAP、Netscape SDK、ActiveDirectory)的接口。
应用程序开发的通用 API 在 RFC1823 中进行了描述,并且 Ruby/LDAP 支持它。
Ruby/LDAP 安装
您可以从 SOURCEFORGE.NET 下载并安装完整的 Ruby/LDAP 包。
在安装 Ruby/LDAP 之前,请确保您具有以下组件:
- Ruby 1.8.x(如果您想使用 ldap/control,至少为 1.8.2)。
- OpenLDAP、Netscape SDK、Windows 2003 或 Windows XP。
现在,您可以使用标准的 Ruby 安装方法。在开始之前,如果您想查看 extconf.rb 的可用选项,请使用 '--help' 选项运行它。
$ ruby extconf.rb [--with-openldap1|--with-openldap2| \
--with-netscape|--with-wldap32]
$ make
$ make install
注意 - 如果您在 Windows 上构建软件,您可能需要使用 *nmake* 而不是 *make*。
建立 LDAP 连接
这是一个两步过程:
步骤 1 - 创建连接对象
以下是创建与 LDAP 目录的连接的语法。
LDAP::Conn.new(host = 'localhost', port = LDAP_PORT)
host - 这是运行 LDAP 目录的主机 ID。我们将将其作为 *localhost*。
port - 这是用于 LDAP 服务的端口。标准 LDAP 端口为 636 和 389。确保您的服务器上使用了哪个端口,否则您可以使用 LDAP::LDAP_PORT。
此调用返回一个新的 *LDAP::Conn* 连接到服务器 *host*,端口为 *port*。
步骤 2 - 绑定
在这里,我们通常指定将在会话的其余部分使用的用户名和密码。
以下是使用 DN *dn*、凭据 *pwd* 和绑定方法 *method* 绑定 LDAP 连接的语法:
conn.bind(dn = nil, password = nil, method = LDAP::LDAP_AUTH_SIMPLE)do .... end
您可以使用相同的方法而不带代码块。在这种情况下,您需要显式地取消绑定连接,如下所示:
conn.bind(dn = nil, password = nil, method = LDAP::LDAP_AUTH_SIMPLE) .... conn.unbind
如果给出了代码块,则将 *self* 传递给代码块。
现在,我们可以在 bind 方法的代码块内(bind 和 unbind 之间)执行搜索、添加、修改或删除操作,前提是我们具有适当的权限。
示例
假设我们正在本地服务器上工作,让我们将所有内容与相应的主机、域名、用户 ID 和密码等组合在一起。
#/usr/bin/ruby -w
require 'ldap'
$HOST = 'localhost'
$PORT = LDAP::LDAP_PORT
$SSLPORT = LDAP::LDAPS_PORT
conn = LDAP::Conn.new($HOST, $PORT)
conn.bind('cn = root, dc = localhost, dc = localdomain','secret')
....
conn.unbind
添加 LDAP 条目
添加 LDPA 条目是一个两步过程 -
步骤 1 - 创建LDAP::Mod对象
我们需要将LDAP::Mod对象传递给conn.add方法来创建一个条目。这是一个创建LDAP::Mod对象的简单语法 -
Mod.new(mod_type, attr, vals)
mod_type - 一个或多个选项 LDAP_MOD_ADD、LDAP_MOD_REPLACE 或 LDAP_MOD_DELETE。
attr - 应该是要操作的属性的名称。
vals - 是与attr相关的值的数组。如果vals包含二进制数据,则mod_type应逻辑或 (|) 与 LDAP_MOD_BVALUES。
此调用返回LDAP::Mod对象,该对象可以传递给 LDAP::Conn 类中的方法,例如 Conn#add、Conn#add_ext、Conn#modify 和 Conn#modify_ext。
步骤 2 - 调用conn.add方法
准备好LDAP::Mod对象后,我们可以调用conn.add方法来创建条目。这是调用此方法的语法 -
conn.add(dn, attrs)
此方法使用 DN(dn)和属性(attrs)添加条目。这里,attrs应该是一个LDAP::Mod对象的数组或一个属性/值数组对的哈希。
示例
这是一个完整的示例,它将创建两个目录条目 -
#/usr/bin/ruby -w
require 'ldap'
$HOST = 'localhost'
$PORT = LDAP::LDAP_PORT
$SSLPORT = LDAP::LDAPS_PORT
conn = LDAP::Conn.new($HOST, $PORT)
conn.bind('cn = root, dc = localhost, dc = localdomain','secret')
conn.perror("bind")
entry1 = [
LDAP.mod(LDAP::LDAP_MOD_ADD,'objectclass',['top','domain']),
LDAP.mod(LDAP::LDAP_MOD_ADD,'o',['TTSKY.NET']),
LDAP.mod(LDAP::LDAP_MOD_ADD,'dc',['localhost']),
]
entry2 = [
LDAP.mod(LDAP::LDAP_MOD_ADD,'objectclass',['top','person']),
LDAP.mod(LDAP::LDAP_MOD_ADD, 'cn', ['Zara Ali']),
LDAP.mod(LDAP::LDAP_MOD_ADD | LDAP::LDAP_MOD_BVALUES, 'sn',
['ttate','ALI', "zero\000zero"]),
]
begin
conn.add("dc = localhost, dc = localdomain", entry1)
conn.add("cn = Zara Ali, dc = localhost, dc = localdomain", entry2)
rescue LDAP::ResultError
conn.perror("add")
exit
end
conn.perror("add")
conn.unbind
修改 LDAP 条目
修改条目类似于添加条目。只需调用modify方法而不是add方法,并使用要修改的属性。这是modify方法的简单语法。
conn.modify(dn, mods)
此方法使用 DN(dn)和属性(mods)修改条目。这里,mods应该是一个LDAP::Mod对象的数组或一个属性/值数组对的哈希。
示例
要修改我们在上一节中添加的条目的姓氏,我们可以编写 -
#/usr/bin/ruby -w
require 'ldap'
$HOST = 'localhost'
$PORT = LDAP::LDAP_PORT
$SSLPORT = LDAP::LDAPS_PORT
conn = LDAP::Conn.new($HOST, $PORT)
conn.bind('cn = root, dc = localhost, dc = localdomain','secret')
conn.perror("bind")
entry1 = [
LDAP.mod(LDAP::LDAP_MOD_REPLACE, 'sn', ['Mohtashim']),
]
begin
conn.modify("cn = Zara Ali, dc = localhost, dc = localdomain", entry1)
rescue LDAP::ResultError
conn.perror("modify")
exit
end
conn.perror("modify")
conn.unbind
删除 LDAP 条目
要删除条目,请使用其可分辨名称作为参数调用delete方法。这是delete方法的简单语法。
conn.delete(dn)
此方法使用 DN(dn)删除条目。
示例
要删除我们在上一节中添加的Zara Mohtashim条目,我们可以编写 -
#/usr/bin/ruby -w
require 'ldap'
$HOST = 'localhost'
$PORT = LDAP::LDAP_PORT
$SSLPORT = LDAP::LDAPS_PORT
conn = LDAP::Conn.new($HOST, $PORT)
conn.bind('cn = root, dc = localhost, dc = localdomain','secret')
conn.perror("bind")
begin
conn.delete("cn = Zara-Mohtashim, dc = localhost, dc = localdomain")
rescue LDAP::ResultError
conn.perror("delete")
exit
end
conn.perror("delete")
conn.unbind
修改可分辨名称
无法使用modify方法修改条目的可分辨名称。相反,请使用modrdn方法。这是modrdn方法的简单语法 -
conn.modrdn(dn, new_rdn, delete_old_rdn)
此方法使用 DN(dn)修改条目的 RDN,并赋予其新的 RDN(new_rdn)。如果delete_old_rdn为true,则旧的 RDN 值将从条目中删除。
示例
假设我们有以下条目 -
dn: cn = Zara Ali,dc = localhost,dc = localdomain cn: Zara Ali sn: Ali objectclass: person
然后,我们可以使用以下代码修改其可分辨名称 -
#/usr/bin/ruby -w
require 'ldap'
$HOST = 'localhost'
$PORT = LDAP::LDAP_PORT
$SSLPORT = LDAP::LDAPS_PORT
conn = LDAP::Conn.new($HOST, $PORT)
conn.bind('cn = root, dc = localhost, dc = localdomain','secret')
conn.perror("bind")
begin
conn.modrdn("cn = Zara Ali, dc = localhost, dc = localdomain", "cn = Zara Mohtashim", true)
rescue LDAP::ResultError
conn.perror("modrdn")
exit
end
conn.perror("modrdn")
conn.unbind
执行搜索
要对 LDAP 目录执行搜索,请使用search方法和三种不同的搜索模式之一 -
LDAP_SCOPE_BASEM - 只搜索基本节点。
LDAP_SCOPE_ONELEVEL - 搜索基本节点的所有子节点。
LDAP_SCOPE_SUBTREE - 搜索整个子树,包括基本节点。
示例
这里,我们将搜索条目dc = localhost, dc = localdomain的整个子树以查找person对象 -
#/usr/bin/ruby -w
require 'ldap'
$HOST = 'localhost'
$PORT = LDAP::LDAP_PORT
$SSLPORT = LDAP::LDAPS_PORT
base = 'dc = localhost,dc = localdomain'
scope = LDAP::LDAP_SCOPE_SUBTREE
filter = '(objectclass = person)'
attrs = ['sn', 'cn']
conn = LDAP::Conn.new($HOST, $PORT)
conn.bind('cn = root, dc = localhost, dc = localdomain','secret')
conn.perror("bind")
begin
conn.search(base, scope, filter, attrs) { |entry|
# print distinguished name
p entry.dn
# print all attribute names
p entry.attrs
# print values of attribute 'sn'
p entry.vals('sn')
# print entry as Hash
p entry.to_hash
}
rescue LDAP::ResultError
conn.perror("search")
exit
end
conn.perror("search")
conn.unbind
这将为每个匹配的条目调用给定的代码块,其中 LDAP 条目由 LDAP::Entry 类的实例表示。使用搜索的最后一个参数,您可以指定您感兴趣的属性,省略所有其他属性。如果您在此处传递 nil,则将返回所有属性,与关系数据库中的“SELECT *”相同。
LDAP::Entry 类的 dn 方法(get_dn 的别名)返回条目的可分辨名称,使用 to_hash 方法,您可以获取其属性(包括可分辨名称)的哈希表示。要获取条目属性的列表,请使用 attrs 方法(get_attributes 的别名)。此外,要获取一个特定属性值的列表,请使用 vals 方法(get_values 的别名)。
处理错误
Ruby/LDAP 定义了两个不同的异常类 -
如果发生错误,新的、绑定或解绑方法将引发 LDAP::Error 异常。
如果添加、修改、删除或搜索 LDAP 目录引发 LDAP::ResultError。
进一步阅读
有关 LDAP 方法的完整详细信息,请参阅LDAP 文档的标准文档。
Ruby - 多线程
传统的程序只有一个执行线程,构成程序的语句或指令按顺序执行,直到程序终止。
多线程程序具有多个执行线程。在每个线程中,语句都是按顺序执行的,但线程本身可以在多核 CPU 上并行执行,例如。通常在单 CPU 机器上,多个线程实际上并不是并行执行的,而是通过交错执行线程来模拟并行性。
Ruby 使用Thread类使编写多线程程序变得容易。Ruby 线程是一种轻量级且高效的方式来实现代码中的并发性。
创建 Ruby 线程
要启动一个新线程,只需将一个代码块与对Thread.new的调用关联起来。将创建一个新线程来执行代码块中的代码,并且原始线程将立即从Thread.new返回,并使用下一条语句恢复执行 -
# Thread #1 is running here
Thread.new {
# Thread #2 runs this code
}
# Thread #1 runs this code
示例
这是一个示例,它展示了我们如何使用多线程 Ruby 程序。
#!/usr/bin/ruby
def func1
i = 0
while i<=2
puts "func1 at: #{Time.now}"
sleep(2)
i = i+1
end
end
def func2
j = 0
while j<=2
puts "func2 at: #{Time.now}"
sleep(1)
j = j+1
end
end
puts "Started At #{Time.now}"
t1 = Thread.new{func1()}
t2 = Thread.new{func2()}
t1.join
t2.join
puts "End at #{Time.now}"
这将产生以下结果 -
Started At Wed May 14 08:21:54 -0700 2008 func1 at: Wed May 14 08:21:54 -0700 2008 func2 at: Wed May 14 08:21:54 -0700 2008 func2 at: Wed May 14 08:21:55 -0700 2008 func1 at: Wed May 14 08:21:56 -0700 2008 func2 at: Wed May 14 08:21:56 -0700 2008 func1 at: Wed May 14 08:21:58 -0700 2008 End at Wed May 14 08:22:00 -0700 2008
线程生命周期
使用Thread.new创建新的线程。您还可以使用同义词Thread.start和Thread.fork。
创建线程后无需启动它,它会在 CPU 资源可用时自动开始运行。
Thread 类定义了许多方法来查询和操作正在运行的线程。线程运行与对Thread.new的调用关联的代码块中的代码,然后停止运行。
该代码块中最后一个表达式的值是线程的值,可以通过调用 Thread 对象的value方法来获取。如果线程已运行完成,则value方法会立即返回值。否则,value方法会阻塞,并且不会返回,直到线程完成。
类方法Thread.current返回表示当前线程的 Thread 对象。这允许线程自行操作。类方法Thread.main返回表示主线程的 Thread 对象。这是在 Ruby 程序启动时开始的初始执行线程。
您可以通过调用该线程的Thread.join方法来等待特定线程完成。调用线程将阻塞,直到给定线程完成。
线程和异常
如果在主线程中引发异常,并且在任何地方都没有处理,则 Ruby 解释器会打印一条消息并退出。在除主线程之外的其他线程中,未处理的异常会导致线程停止运行。
如果线程t由于未处理的异常而退出,并且另一个线程s调用t.join或t.value,则在t中发生的异常将在线程s中引发。
如果Thread.abort_on_exception为false(默认条件),则未处理的异常只会终止当前线程,其余线程将继续运行。
如果您希望任何线程中的任何未处理异常导致解释器退出,请将类方法Thread.abort_on_exception设置为true。
t = Thread.new { ... }
t.abort_on_exception = true
线程变量
线程通常可以访问创建线程时处于作用域内的任何变量。线程代码块中的局部变量是线程的局部变量,并且不共享。
Thread 类提供了一个特殊的功能,允许通过名称创建和访问线程局部变量。您只需将线程对象视为哈希表,使用[]=写入元素,并使用[]读取它们。
在此示例中,每个线程将变量 count 的当前值记录在具有键mycount的线程局部变量中。
实时演示#!/usr/bin/ruby
count = 0
arr = []
10.times do |i|
arr[i] = Thread.new {
sleep(rand(0)/10.0)
Thread.current["mycount"] = count
count += 1
}
end
arr.each {|t| t.join; print t["mycount"], ", " }
puts "count = #{count}"
这将产生以下结果 -
8, 0, 3, 7, 2, 1, 6, 5, 4, 9, count = 10
主线程等待子线程完成,然后打印出每个线程捕获的count值。
线程优先级
影响线程调度的第一个因素是线程优先级:高优先级线程优先于低优先级线程调度。更准确地说,只有在没有更高优先级的线程等待运行时,线程才会获得 CPU 时间。
您可以使用priority =和priority设置和查询 Ruby Thread 对象的优先级。新创建的线程以创建它的线程相同的优先级启动。主线程从优先级 0 开始。
无法在线程开始运行之前设置其优先级。但是,线程可以将其自身的优先级作为其采取的第一个操作提高或降低。
线程互斥
如果两个线程共享对同一数据的访问,并且至少一个线程修改该数据,则必须特别注意确保任何线程都无法看到数据处于不一致的状态。这称为线程互斥。
Mutex是一个实现简单信号量锁的类,用于对某些共享资源进行互斥访问。也就是说,在任何给定时间只有一个线程可以持有锁。其他线程可以选择排队等待锁可用,或者可以选择立即获取一个指示锁不可用的错误。
通过将对共享数据的访问都置于mutex的控制之下,我们确保了一致性和原子操作。让我们尝试两个示例,第一个没有 mutax,第二个有 mutax -
无 Mutex 示例
实时演示#!/usr/bin/ruby
require 'thread'
count1 = count2 = 0
difference = 0
counter = Thread.new do
loop do
count1 += 1
count2 += 1
end
end
spy = Thread.new do
loop do
difference += (count1 - count2).abs
end
end
sleep 1
puts "count1 : #{count1}"
puts "count2 : #{count2}"
puts "difference : #{difference}"
这将产生以下结果:
count1 : 1583766 count2 : 1583766 difference : 0实时演示
#!/usr/bin/ruby
require 'thread'
mutex = Mutex.new
count1 = count2 = 0
difference = 0
counter = Thread.new do
loop do
mutex.synchronize do
count1 += 1
count2 += 1
end
end
end
spy = Thread.new do
loop do
mutex.synchronize do
difference += (count1 - count2).abs
end
end
end
sleep 1
mutex.lock
puts "count1 : #{count1}"
puts "count2 : #{count2}"
puts "difference : #{difference}"
这将产生以下结果:
count1 : 696591 count2 : 696591 difference : 0
处理死锁
当我们开始使用Mutex对象进行线程互斥时,必须小心避免死锁。死锁是指当所有线程都在等待获取另一个线程持有的资源时发生的情况。因为所有线程都被阻塞,所以它们无法释放它们持有的锁。并且因为它们无法释放锁,所以其他线程也无法获取这些锁。
这就是条件变量发挥作用的地方。条件变量只是一个与资源关联的信号量,并在特定mutex的保护下使用。当您需要一个不可用的资源时,您将在条件变量上等待。该操作会释放相应mutex上的锁。当其他一些线程发出信号表明资源可用时,原始线程将停止等待并同时重新获得临界区域上的锁。
示例
实时演示#!/usr/bin/ruby
require 'thread'
mutex = Mutex.new
cv = ConditionVariable.new
a = Thread.new {
mutex.synchronize {
puts "A: I have critical section, but will wait for cv"
cv.wait(mutex)
puts "A: I have critical section again! I rule!"
}
}
puts "(Later, back at the ranch...)"
b = Thread.new {
mutex.synchronize {
puts "B: Now I am critical, but am done with cv"
cv.signal
puts "B: I am still critical, finishing up"
}
}
a.join
b.join
这将产生以下结果:
A: I have critical section, but will wait for cv (Later, back at the ranch...) B: Now I am critical, but am done with cv B: I am still critical, finishing up A: I have critical section again! I rule!
线程状态
有五个可能的返回值对应于五种可能的状态,如下表所示。status方法返回线程的状态。
| 线程状态 | 返回值 |
|---|---|
| 可运行 | run |
| 睡眠 | 睡眠 |
| 中止 | aborting |
| 正常终止 | false |
| 异常终止 | nil |
Thread 类方法
Thread类提供了以下方法,它们适用于程序中所有可用的线程。这些方法将通过使用Thread类名如下调用 -
Thread.abort_on_exception = true
线程实例方法
这些方法适用于线程的实例。这些方法将被调用,如下所示,使用Thread的实例 -
#!/usr/bin/ruby thr = Thread.new do # Calling a class method new puts "In second thread" raise "Raise exception" end thr.join # Calling an instance method join
Ruby - 内置函数
由于Kernel模块被Object类包含,因此它的方法在Ruby程序中的任何地方都可用。它们可以在没有接收者的情况下调用(函数形式)。因此,它们通常被称为函数。
数字函数
以下是与数字相关的内置函数列表。它们应按以下方式使用:
实时演示#!/usr/bin/ruby num = 12.40 puts num.floor # 12 puts num + 10 # 22.40 puts num.integer? # false as num is a float.
这将产生以下结果:
12 22.4 false
浮点数函数
数学函数
转换字段说明符
函数sprintf( fmt[, arg...]) 和 format( fmt[, arg...])返回一个字符串,其中 arg 根据 fmt 进行格式化。格式化规范与 C 编程语言中 sprintf 的格式化规范基本相同。fmt 中的转换说明符(% 后跟转换字段说明符)将替换为对应参数的格式化字符串。
以下是用法示例:
实时演示#!/usr/bin/ruby
str = sprintf("%s\n", "abc") # => "abc\n" (simplest form)
puts str
str = sprintf("d=%d", 42) # => "d=42" (decimal output)
puts str
str = sprintf("%04x", 255) # => "00ff" (width 4, zero padded)
puts str
str = sprintf("%8s", "hello") # => " hello" (space padded)
puts str
str = sprintf("%.2s", "hello") # => "he" (trimmed by precision)
puts str
这将产生以下结果:
abc d = 42 00ff hello he
测试函数参数
函数test( test, f1[, f2])执行以下由字符test指定的其中一个文件测试。为了提高可读性,您应该使用 File 类方法(例如,File::readable?)而不是此函数。
以下是用法示例。假设 main.rb 存在,具有读、写权限,但不具有执行权限:
实时演示#!/usr/bin/ruby puts test(?r, "main.rb" ) # => true puts test(?w, "main.rb" ) # => true puts test(?x, "main.rb" ) # => false
这将产生以下结果:
true false false
Ruby - 预定义变量
Ruby 的预定义变量会影响整个程序的行为,因此不建议在库中使用它们。
大多数预定义变量中的值可以通过其他方式访问。
下表列出了所有 Ruby 的预定义变量。
| 序号 | 变量名和描述 |
|---|---|
| 1 | $! 最后引发的异常对象。也可以在rescue子句中使用=>访问异常对象。 |
| 2 | $@ 最后引发的异常的堆栈回溯。可以通过最后异常的 Exception#backtrace 方法检索堆栈回溯信息。 |
| 3 | $/ 输入记录分隔符(默认为换行符)。gets、readline等将它们可选的参数作为输入记录分隔符。 |
| 4 | $\ 输出记录分隔符(默认为 nil)。 |
| 5 | $, print 和 Array#join 的参数之间的输出分隔符(默认为 nil)。您可以为 Array#join 显式指定分隔符。 |
| 6 | $; split 的默认分隔符(默认为 nil)。您可以为 String#split 显式指定分隔符。 |
| 7 | $. 从当前输入文件读取的最后一行编号。等效于 ARGF.lineno。 |
| 8 | $< ARGF 的同义词。 |
| 9 | $> $defout 的同义词。 |
| 10 | $0 正在执行的当前 Ruby 程序的名称。 |
| 11 | $$ 正在执行的当前 Ruby 程序的进程 pid。 |
| 12 | $? 最后一个终止进程的退出状态。 |
| 13 | $: $LOAD_PATH 的同义词。 |
| 14 | $DEBUG 如果指定了 -d 或 --debug 命令行选项,则为真。 |
| 15 | $defout print 和 printf 的目标输出(默认情况下为 $stdout)。 |
| 16 | $F 当指定 -a 时,接收来自 split 的输出的变量。如果指定了 -a 命令行选项以及 -p 或 -n 选项,则设置此变量。 |
| 17 | $FILENAME 当前从 ARGF 读取的文件的名称。等效于 ARGF.filename。 |
| 18 | $LOAD_PATH 一个数组,其中包含在使用 load 和 require 方法加载文件时要搜索的目录。 |
| 19 | $SAFE 安全级别 0 → 对外部提供的(受污染的)数据不执行任何检查。(默认值) 1 → 禁止使用受污染的数据进行潜在的危险操作。 2 → 禁止对进程和文件的潜在危险操作。 3 → 所有新创建的对象都被视为受污染的。 4 → 禁止修改全局数据。 |
| 20 | $stdin 标准输入(默认为 STDIN)。 |
| 21 | $stdout 标准输出(默认为 STDOUT)。 |
| 22 | $stderr 标准错误(默认为 STDERR)。 |
| 23 | $VERBOSE 如果指定了 -v、-w 或 --verbose 命令行选项,则为真。 |
| 24 | $- x 解释器选项 -x 的值 (x=0, a, d, F, i, K, l, p, v)。这些选项列在下面 |
| 25 | $-0 解释器选项 -x 的值以及 $/ 的别名。 |
| 26 | $-a 解释器选项 -x 的值,如果设置了选项 -a 则为真。只读。 |
| 27 | $-d 解释器选项 -x 的值以及 $DEBUG 的别名 |
| 28 | $-F 解释器选项 -x 的值以及 $; 的别名。 |
| 29 | $-i 解释器选项 -x 的值,在就地编辑模式下,保存扩展名,否则为 nil。可以启用或禁用就地编辑模式。 |
| 30 | $-I 解释器选项 -x 的值以及 $: 的别名。 |
| 31 | $-l 解释器选项 -x 的值,如果设置了选项 -l 则为真。只读。 |
| 32 | $-p 解释器选项 -x 的值,如果设置了选项 -p 则为真。只读。 |
| 33 | $_ 局部变量,当前作用域中 gets 或 readline 读取的最后一个字符串。 |
| 34 | $~ 局部变量,与最后一次匹配相关的 MatchData。Regex#match 方法返回最后一次匹配信息。 |
| 35 | $ n ($1, $2, $3...) 在最后一次模式匹配的第 n 个组中匹配的字符串。等效于 m[n],其中 m 是一个 MatchData 对象。 |
| 36 | $& 在最后一次模式匹配中匹配的字符串。等效于 m[0],其中 m 是一个 MatchData 对象。 |
| 37 | $` 在最后一次模式匹配中匹配之前的字符串。等效于 m.pre_match,其中 m 是一个 MatchData 对象。 |
| 38 | $' 在最后一次模式匹配中匹配之后的字符串。等效于 m.post_match,其中 m 是一个 MatchData 对象。 |
| 39 | $+ 在最后一次模式匹配中与最后成功匹配的组对应的字符串。 |
Ruby - 预定义常量
下表列出了所有 Ruby 的预定义常量 -
注意 - TRUE、FALSE 和 NIL 向后兼容。最好使用 true、false 和 nil。
| 序号 | 常量名称和描述 |
|---|---|
| 1 | TRUE true 的同义词。 |
| 2 | FALSE false 的同义词。 |
| 3 | NIL nil 的同义词。 |
| 4 | ARGF 一个对象,提供对作为命令行参数传递的文件或标准输入的虚拟连接的访问,如果没有任何命令行参数,则为标准输入。$< 的同义词。 |
| 5 | ARGV 一个数组,包含传递给程序的命令行参数。$* 的同义词。 |
| 6 | DATA 用于读取 __END__ 指令后代码行的输入流。如果代码中不存在 __END__,则未定义。 |
| 7 | ENV 一个类似哈希的对象,包含程序的环境变量。ENV 可以作为哈希处理。 |
| 8 | RUBY_PLATFORM 一个字符串,指示 Ruby 解释器的平台。 |
| 9 | RUBY_RELEASE_DATE 一个字符串,指示 Ruby 解释器的发布日期 |
| 10 | RUBY_VERSION 一个字符串,指示 Ruby 解释器的版本。 |
| 11 | STDERR 标准错误输出流。$stderr 的默认值。 |
| 12 | STDIN 标准输入流。$stdin 的默认值。 |
| 13 | STDOUT 标准输出流。$stdout 的默认值。 |
| 14 | TOPLEVEL_BINDING Ruby 顶层的绑定对象。 |
Ruby - 相关工具
标准 Ruby 工具
标准 Ruby 发行版包含有用的工具以及解释器和标准库 -
这些工具可以帮助您调试和改进 Ruby 程序,而无需花费太多精力。本教程将为您提供一个很好的开始。
-
RubyGems 是 Ruby 的一个包实用程序,它安装 Ruby 软件包并保持其最新状态。
-
为了帮助处理错误,Ruby 的标准发行版包含一个调试器。这与 gdb 实用程序非常相似,可用于调试复杂程序。
-
irb(交互式 Ruby)由 Keiju Ishitsuka 开发。它允许您在提示符处输入命令,并让解释器做出响应,就像您正在执行程序一样。irb 可用于实验或探索 Ruby。
-
Ruby 分析器可帮助您通过查找瓶颈来提高缓慢程序的性能。
其他 Ruby 工具
还有一些有用的工具没有与 Ruby 标准发行版捆绑在一起。但是,您需要自己安装它们。
-
eRuby 代表嵌入式 Ruby。它是一个工具,可以将 Ruby 代码片段嵌入到其他文件中,例如 HTML 文件,类似于 ASP、JSP 和 PHP。
-
当您对某个方法的行为有疑问时,您可以调用 ri 来阅读该方法的简要说明。
有关 Ruby 工具和资源的更多信息,请查看 Ruby 有用资源。