- Scikit Learn 教程
- Scikit Learn - 首页
- Scikit Learn - 简介
- Scikit Learn - 建模过程
- Scikit Learn - 数据表示
- Scikit Learn - 估计器 API
- Scikit Learn - 约定
- Scikit Learn - 线性建模
- Scikit Learn - 扩展线性建模
- 随机梯度下降
- Scikit Learn - 支持向量机
- Scikit Learn - 异常检测
- Scikit Learn - K 近邻算法
- Scikit Learn - KNN 学习
- 朴素贝叶斯分类
- Scikit Learn - 决策树
- 随机决策树
- Scikit Learn - 集成方法
- Scikit Learn - 聚类方法
- 聚类性能评估
- 使用 PCA 进行降维
- Scikit Learn 有用资源
- Scikit Learn - 快速指南
- Scikit Learn - 有用资源
- Scikit Learn - 讨论
Scikit Learn - 数据表示
众所周知,机器学习是关于从数据中创建模型的。为此,计算机必须首先理解数据。接下来,我们将讨论各种表示数据的方法,以便计算机能够理解它们 -
数据作为表格
在 Scikit-learn 中表示数据的最佳方法是表格形式。表格表示一个二维数据网格,其中行表示数据集的各个元素,列表示与这些各个元素相关的数量。
示例
通过以下示例,我们可以使用 Python 的 seaborn 库将 鸢尾花数据集 下载为 Pandas DataFrame 的形式。
import seaborn as sns
iris = sns.load_dataset('iris')
iris.head()
输出
sepal_length sepal_width petal_length petal_width species 0 5.1 3.5 1.4 0.2 setosa 1 4.9 3.0 1.4 0.2 setosa 2 4.7 3.2 1.3 0.2 setosa 3 4.6 3.1 1.5 0.2 setosa 4 5.0 3.6 1.4 0.2 setosa
从以上输出可以看出,数据的每一行都代表一朵观察到的花,行数代表数据集中花的总数。通常,我们将矩阵的行称为样本。
另一方面,数据的每一列都代表描述每个样本的定量信息。通常,我们将矩阵的列称为特征。
数据作为特征矩阵
特征矩阵可以定义为表格布局,其中信息可以被认为是二维矩阵。它存储在一个名为 X 的变量中,并假定为二维,形状为 [n_samples, n_features]。大多数情况下,它包含在 NumPy 数组或 Pandas DataFrame 中。如前所述,样本始终表示数据集描述的单个对象,特征以定量方式描述每个样本的不同观察结果。
数据作为目标数组
除了用 X 表示的特征矩阵之外,我们还有目标数组。它也称为标签。它用 y 表示。标签或目标数组通常是一维的,长度为 n_samples。它通常包含在 NumPy 的 数组 或 Pandas 的 序列 中。目标数组可以同时具有连续数值和离散值。
目标数组与特征列有何不同?
我们可以通过一点来区分两者,即目标数组通常是我们想要从数据中预测的数量,即在统计学上它是因变量。
示例
在下面的示例中,从鸢尾花数据集中,我们根据其他测量结果预测花的种类。在这种情况下,Species 列将被视为特征。
import seaborn as sns
iris = sns.load_dataset('iris')
%matplotlib inline
import seaborn as sns; sns.set()
sns.pairplot(iris, hue='species', height=3);
输出
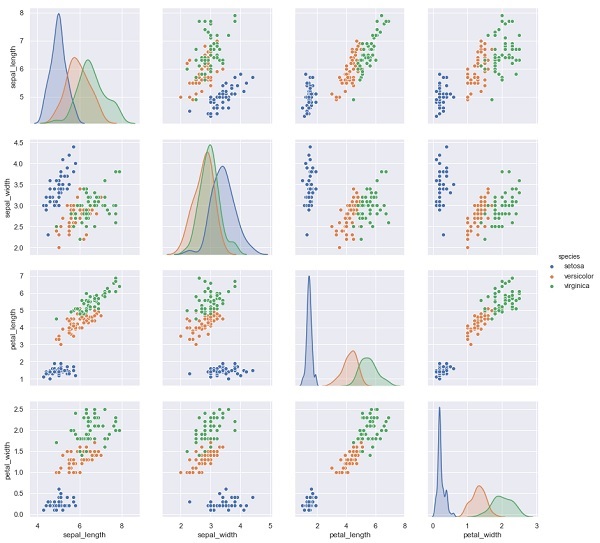
X_iris = iris.drop('species', axis=1)
X_iris.shape
y_iris = iris['species']
y_iris.shape
输出
(150,4) (150,)
广告