- Snowflake 教程
- Snowflake - 首页
- Snowflake - 简介
- Snowflake - 数据架构
- Snowflake - 功能架构
- Snowflake - 如何访问
- Snowflake - 版本
- Snowflake - 定价模式
- Snowflake - 对象
- Snowflake - 表和视图类型
- Snowflake - 登录
- Snowflake - 数据仓库
- Snowflake - 数据库
- Snowflake - 模式
- Snowflake - 表和列
- Snowflake - 从文件加载数据
- Snowflake - 有用查询示例
- Snowflake - 监控使用情况和存储
- Snowflake - 缓存
- 从 Snowflake 卸载数据到本地
- 外部数据加载(来自 AWS S3)
- 外部数据卸载(到 AWS S3)
- Snowflake 资源
- Snowflake - 快速指南
- Snowflake - 有用资源
- Snowflake - 讨论
Snowflake - 缓存
Snowflake 具有独特的缓存功能。它基于此缓存提供快速的结果,并减少数据扫描量。它甚至可以帮助客户降低账单。
Snowflake 中基本上有三种类型的缓存。
- 元数据缓存
- 查询结果缓存
- 数据缓存
默认情况下,所有 Snowflake 会话都启用缓存。但是用户可以根据需要禁用它。但是,用户只能禁用查询结果缓存,无法禁用**元数据缓存**和**数据缓存**。
在本章中,我们将讨论不同类型的缓存以及 Snowflake 如何决定缓存。
元数据缓存
元数据存储在云服务层,因此缓存也在同一层。这些元数据缓存始终对所有人启用。
它基本上包含以下详细信息:
表中的行数。
列的 MIN/MAX 值
列中 DISTINCT 值的数量
列中 NULL 值的数量
不同表版本的详细信息
物理文件的引用
SQL 优化器主要使用这些信息来更快地执行查询。一些查询可以直接通过元数据本身来回答。对于此类查询,不需要虚拟仓库,但可能适用云服务费用。
此类查询例如:
**所有 SHOW** 命令
**MIN,MAX**,但仅限于列的整数/数字/日期数据类型。
COUNT
让我们运行一个查询来了解元数据缓存的工作原理,用户可以进行验证。
登录 Snowflake 并转到工作表。通过运行以下查询暂停数据仓库:
ALTER WAREHOUSE COMPUTE_WH SUSPEND;
现在,按顺序运行以下查询:
USE SCHEMA SNOWFLAKE_SAMPLE_DATA.TPCH_SF100; SELECT MIN(L_orderkey), MAX(l_orderkey), COUNT(*) FROM lineitem;
用户将能够在不到 100 毫秒的时间内看到结果,如下面的屏幕截图所示。单击查询 ID。它将显示查询 ID 的链接。然后单击如下所示的链接:
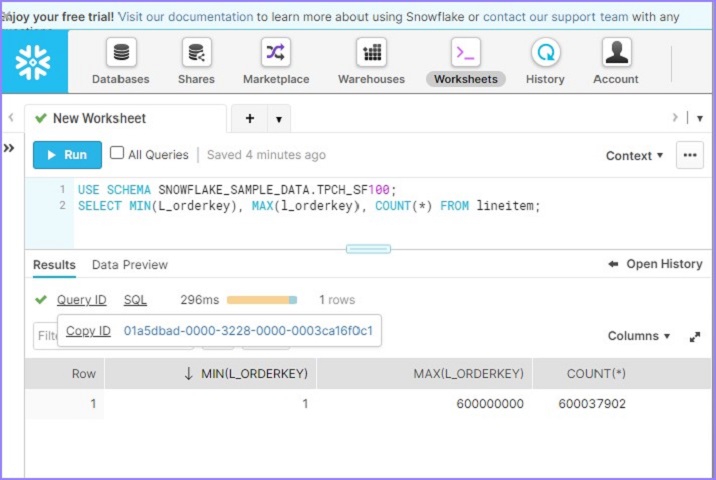
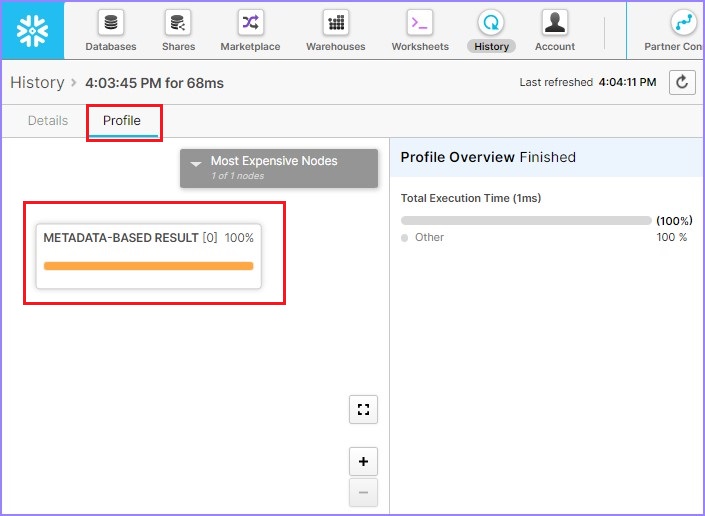
默认情况下,它会打开显示 SQL 的详细信息页面。单击“**概要文件**”选项卡。它显示 100% 基于元数据的的结果。这意味着它无需任何计算仓库即可运行结果并根据元数据缓存获取详细信息。
以下屏幕截图显示了上述步骤:
查询结果缓存
查询结果由云服务层存储和管理。如果多次运行相同的查询,这将非常有用,但前提是在多次运行查询的时间段内底层数据或基表没有更改。此缓存具有一个独特的功能,即同一帐户内的其他用户也可以使用。
例如,如果用户 1 第一次运行查询,结果将存储在缓存中。当用户 2 也尝试运行相同的查询(假设基表和数据没有更改)时,它将从查询结果缓存中获取结果。
缓存的结果可用 24 小时。但是,每次重新运行相同的查询时,24 小时的计数器都会重置。例如,如果一个查询在上午 10 点运行,则其缓存将可用到第二天上午 10 点。如果在同一天下午 2 点重新运行相同的查询,则缓存将可用到第二天的下午 2 点。
要使用查询结果缓存,需要满足一些条件:
必须重新运行完全相同的**SQL** 查询。
SQL 中不应有任何随机函数。
用户必须具有使用它的权限。
运行查询时应启用查询结果。默认情况下,除非另行设置,否则它是启用的。
查询结果缓存的一些情况:
需要大量计算的查询,例如聚合函数和半结构化数据分析。
非常频繁运行的查询。
复杂的查询。
重构另一个查询的输出,例如“USE TABLE function RESULT_SCAN(<query_id>)”。
让我们运行一个查询来了解查询结果缓存的工作原理,用户可以进行验证。
登录 Snowflake 并转到工作表。通过运行以下查询恢复数据仓库:
ALTER WAREHOUSE COMPUTE_WH Resume;
现在,按顺序运行以下查询:
USE SCHEMA SNOWFLAKE_SAMPLE_DATA.TPCH_SF100;
SELECT l_returnflag, l_linestatus,
SUM(l_quantity) AS sum_qty,
SUM(l_extendedprice) AS sum_base_price,
SUM(l_extendedprice * (l_discount)) AS sum_disc_price,
SUM(l_extendedprice * (l_discount) * (1+l_tax)) AS sum_charge,
AVG(l_quantity) AS avg_qty,
AVG(l_extendedprice) AS avg_price,
AVG(l_discount) AS avg_disc,
COUNT(*) AS count_order
FROM lineitem
WHERE l_shipdate <= dateadd(day, 90, to_date('1998-12-01'))
GROUP BY l_returnflag, l_linestatus
ORDER BY l_returnflag, l_linestatus;
单击查询 ID。它将显示查询 ID 的链接。然后单击前面示例(元数据缓存)中所示的链接。检查查询概要文件,它将显示如下:
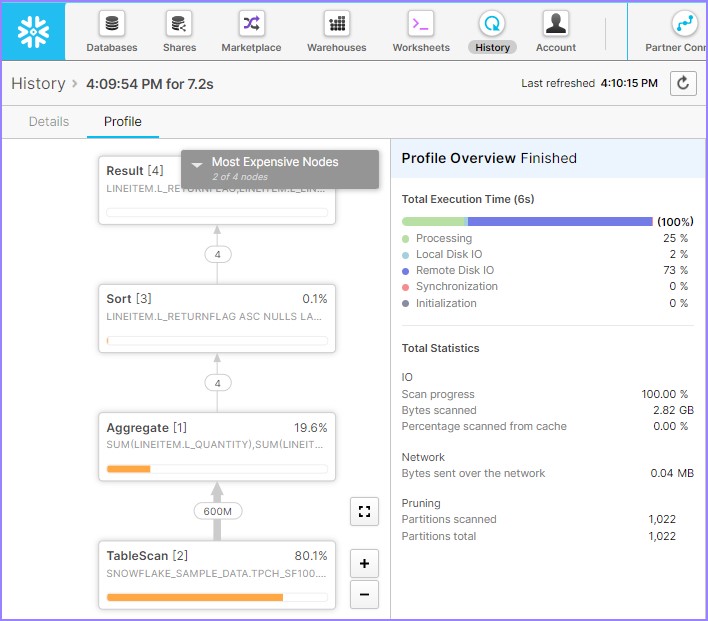
它显示扫描了 80.5% 的数据,因此没有涉及缓存。通过运行以下查询暂停数据仓库:
ALTER WAREHOUSE COMPUTE_WH Suspend;
再次运行与之前相同的查询:
USE SCHEMA SNOWFLAKE_SAMPLE_DATA.TPCH_SF100;
SELECT l_returnflag, l_linestatus,
SUM(l_quantity) AS sum_qty,
SUM(l_extendedprice) AS sum_base_price,
SUM(l_extendedprice * (l_discount)) AS sum_disc_price,
SUM(l_extendedprice * (l_discount) * (1+l_tax)) AS sum_charge,
AVG(l_quantity) AS avg_qty,
AVG(l_extendedprice) AS avg_price,
AVG(l_discount) AS avg_disc,
COUNT(*) AS count_order
FROM lineitem
WHERE l_shipdate <= dateadd(day, 90, to_date('1998-12-01'))
GROUP BY l_returnflag, l_linestatus
ORDER BY l_returnflag, l_linestatus;
单击**查询** ID。它将显示查询 ID 的链接。然后单击前面示例(元数据缓存)中所示的链接。检查查询概要文件,它将显示如下:
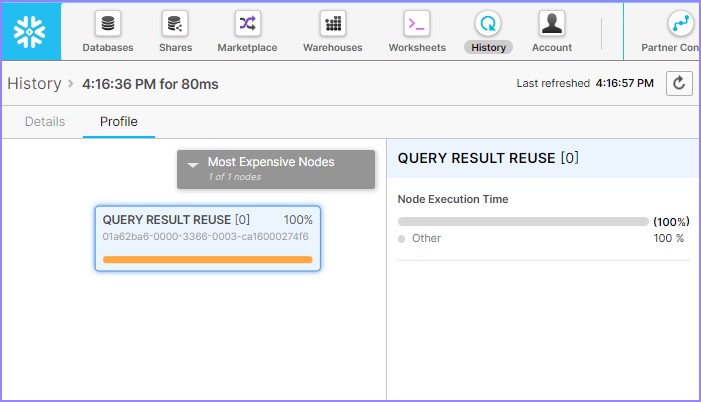
它显示了查询结果重用。这意味着它无需数据仓库即可成功运行查询,并且整个结果集均来自查询结果缓存。
数据缓存
数据缓存发生在存储层。它缓存来自查询的存储文件头和列数据。它存储所有查询的数据,但并非完全作为查询结果。它将这些数据存储到虚拟仓库的 SSD 中。当运行类似的查询时,Snowflake 会尽可能多地使用数据缓存。用户无法禁用数据缓存。数据缓存适用于在同一虚拟仓库上运行的所有查询。这意味着与元数据和查询结果缓存不同,数据缓存无法在没有虚拟仓库的情况下工作。
当查询运行时,其头和列数据将存储在虚拟仓库的 SSD 上。虚拟仓库首先读取本地可用数据(虚拟仓库的 SSD),然后从远程云存储(实际的 Snowflake 存储系统)读取剩余数据。当缓存存储空间已满时,数据将根据最少使用方式删除。
让我们运行一个查询来了解查询结果缓存的工作原理,用户可以进行验证。
登录 Snowflake 并转到**工作表**。通过运行以下查询恢复数据仓库:
ALTER WAREHOUSE COMPUTE_WH Resume;
使用以下 SQL 禁用 Query_Result 缓存:
ALTER SESSION SET USE_CACHED_RESULT = FALSE;
运行以下查询:
SELECT l_returnflag, l_linestatus,
SUM(l_quantity) AS sum_qty,
SUM(l_extendedprice) AS sum_base_price,
SUM(l_extendedprice * (l_discount)) AS sum_disc_price, SUM(l_extendedprice *
(l_discount) * (1+l_tax))
AS sum_charge, AVG(l_quantity) AS avg_qty,
AVG(l_extendedprice) AS avg_price,
AVG(l_discount) AS avg_disc,
COUNT(*) as count_order
FROM lineitem
WHERE l_shipdate <= dateadd(day, 90, to_date('1998-12-01'))
GROUP BY l_returnflag, l_linestatus
ORDER BY l_returnflag, l_linestatus;
单击**查询** ID。它将显示查询 ID 的链接。然后单击前面示例(元数据缓存)中所示的链接。检查查询概要文件,它将显示如下:
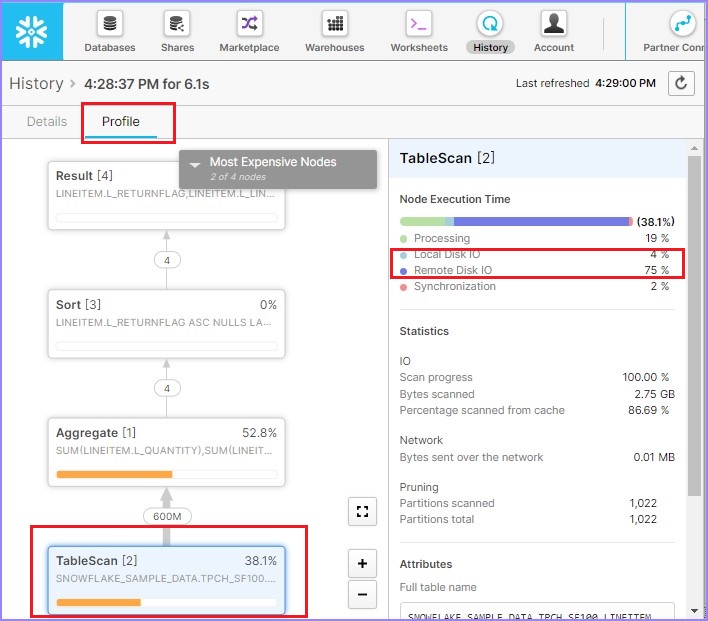
根据查询概要文件,扫描了 88.6% 的数据。如果您注意到右侧,本地磁盘 I/O = 2%,而远程磁盘 I/O = 80%。这意味着几乎没有或没有使用数据缓存。现在,运行以下查询。WHERE 子句略有不同:
SELECT l_returnflag, l_linestatus,
SUM(l_quantity) AS sum_qty,
SUM(l_extendedprice) AS sum_base_price,
SUM(l_extendedprice * (l_discount)) AS sum_disc_price, SUM(l_extendedprice *
(l_discount) * (1+l_tax))
AS sum_charge,
AVG(l_quantity) AS avg_qty,
AVG(l_extendedprice) AS avg_price,
AVG(l_discount) AS avg_disc,
COUNT(*) as count_order
FROM lineitem
WHERE l_shipdate <= dateadd(day, 90, to_date('1998-12-01'))
and l_extendedprice <= 20000
GROUP BY l_returnflag, l_linestatus
ORDER BY l_returnflag, l_linestatus;
单击**查询** ID。它将显示查询 ID 的链接。然后单击前面示例(元数据缓存)中所示的链接。检查查询概要文件,它将显示如下:
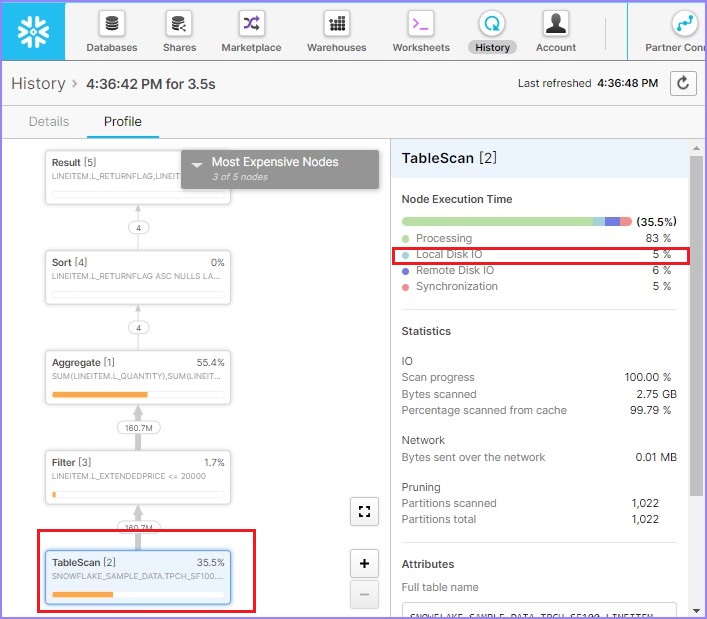
根据查询概要文件,扫描了 58.9% 的数据,这比第一次要低得多。如果您注意到右侧,本地磁盘 I/O 增加到 4%,而远程磁盘 I/O = 0%。这意味着几乎没有或没有使用来自远程的数据。