- Snowflake 教程
- Snowflake - 首页
- Snowflake - 简介
- Snowflake - 数据架构
- Snowflake - 功能架构
- Snowflake - 如何访问
- Snowflake - 版本
- Snowflake - 定价模型
- Snowflake - 对象
- Snowflake - 表和视图类型
- Snowflake - 登录
- Snowflake - 数据仓库
- Snowflake - 数据库
- Snowflake - 模式
- Snowflake - 表和列
- Snowflake - 从文件加载数据
- Snowflake - 有用的示例查询
- Snowflake - 监控使用情况和存储
- Snowflake - 缓存
- 将数据从 Snowflake 卸载到本地
- 外部数据加载(从 AWS S3)
- 外部数据卸载(到 AWS S3)
- Snowflake 资源
- Snowflake 快速指南
- Snowflake - 有用资源
- Snowflake - 讨论
Snowflake 快速指南
Snowflake - 简介
Snowflake 是一个基于云的先进数据平台系统,作为软件即服务 (SaaS) 提供。Snowflake 提供了从 AWS S3、Azure、Google Cloud 存储数据、处理复杂查询和不同分析解决方案的功能。Snowflake 提供的分析解决方案比传统的数据库及其分析功能更快、更易于使用且更灵活。Snowflake 存储和提供近实时数据,而不是实际实时数据。
Snowflake 是 OLAP(联机分析处理)技术的先进解决方案。OLAP 也被称为使用历史数据的联机数据检索和数据分析系统。它处理具有少量事务的复杂和聚合查询。例如:获取公司上个月的订单数量、销售额、上季度公司的新用户列表数量等。Snowflake 不用作 OLTP(联机事务处理)数据库。OLTP 数据库通常包含具有大量小型数据事务的实时数据。例如:插入客户的订单详情、注册新客户、跟踪订单交付状态等。
为什么要使用 Snowflake?
Snowflake 提供数据平台作为云服务。
客户无需选择、安装、配置或管理任何硬件(虚拟或物理)。
无需安装、配置或管理任何软件即可访问它。
所有持续的维护、管理、升级和修补都由 Snowflake 本身负责。
传统的分析解决方案数据库架构复杂、成本高且受限,而 Snowflake 则在数据工程、数据湖概念、数据仓库、数据科学、数据应用和数据交换或共享方面非常丰富。它易于访问和使用,不受数据大小和存储容量的限制。用户只需管理自己的数据;所有与数据平台相关的管理都由 Snowflake 本身完成。
除此之外,Snowflake 还具有以下功能:
使用多种语言(如 Java、Python、PHP、Spark、Ruby 等)构建简单可靠的数据管道。
安全访问、非常好的性能和数据湖的安全性。
工具、数据存储和数据大小的零管理。
使用任何框架进行建模的简单数据准备。
构建数据密集型应用程序的零运营负担。
在公司生态系统中共享和协作实时数据。
Snowflake - 数据架构
Snowflake 数据架构重新发明了一种新的 SQL 查询引擎。它仅针对云设计。Snowflake 不使用也不基于任何现有的数据库技术。它甚至不使用 Hadoop 等大数据软件平台。Snowflake 提供了分析数据库的所有功能,以及许多额外的独特功能和能力。
Snowflake 拥有用于存储结构化和半结构化数据的中央数据存储库。可以从 Snowflake 平台中的所有可用计算节点访问这些数据。它使用虚拟仓库作为计算环境来处理查询。在处理查询时,它利用多集群、微分区和高级缓存概念。Snowflake 的云服务负责为用户提供端到端解决方案,例如用户的登录验证到 select 查询的结果。
Snowflake 的数据架构**具有三个主要层**:
- 数据库存储
- 查询处理
- 云服务
以下是 Snowflake 的**数据架构**图:
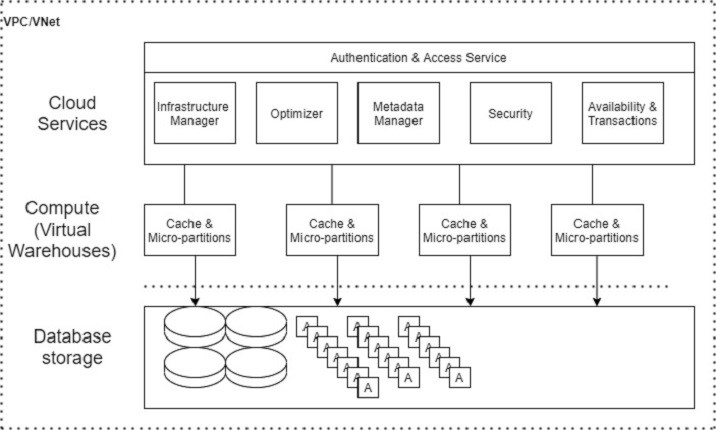
数据库存储
Snowflake 支持 Amazon S3、Azure 和 Google Cloud 使用文件系统将数据加载到 Snowflake 中。用户应将文件(.csv、.txt、.xlsx 等)上传到云端,然后在 Snowflake 中创建连接以导入数据。数据大小不限,但根据云服务,文件大小最多为 5GB。一旦数据加载到 Snowflake 中,它就会利用其内部优化和压缩技术将数据以列格式存储到中央存储库中。中央存储库基于数据存储的云。
Snowflake 负责数据管理的所有方面,例如如何使用自动数据集群存储数据、数据的组织和结构、通过将数据保存在许多微分区中的压缩技术、元数据、统计数据等等。Snowflake 将数据存储为数据对象,用户无法直接查看或访问它们。用户可以通过 SQL 查询(在 Snowflake 的 UI 中或使用 Java、Python、PHP、Ruby 等编程语言)访问这些数据。
查询处理
查询执行是处理层或计算层的一部分。要处理查询,Snowflake 需要计算环境,在 Snowflake 中称为“虚拟仓库”。虚拟仓库是一个计算集群。虚拟仓库由 CPU、内存和临时存储系统组成,以便它可以执行 SQL 执行和 DML(数据操作语言)操作。
SQL SELECT 执行
使用 Update、Insert、Update 更新数据
使用 COPY INTO
将数据加载到表中 使用 COPY INTO
从表中卸载数据
但是,服务器的数量取决于虚拟仓库的大小。例如,XSmall 仓库每个集群有 1 台服务器,而 Small 仓库每个集群有 2 台服务器,并且随着大小(例如 Large、XLarge 等)的增加而加倍。
在执行查询时,Snowflake 会分析请求的查询,并使用最新的微分区并在不同阶段评估缓存以提高性能并减少获取数据的时间。减少时间意味着用户使用的积分更少。
云服务
云服务是 Snowflake 的“大脑”。它协调和管理 Snowflake 的活动。它将 Snowflake 的所有组件整合在一起,以处理从登录验证到交付查询响应的用户请求。
此层管理以下服务:
它是所有存储的集中式管理。
它管理与存储一起工作的计算环境。
它负责云中 Snowflake 的升级、更新、修补和配置。
它对 SQL 查询执行基于成本的优化。
它自动收集统计信息,例如使用的积分、存储容量利用率
安全性,例如基于角色和用户的身份验证、访问控制
它执行加密以及密钥管理服务。
它在数据加载到系统时存储元数据。
还有更多……
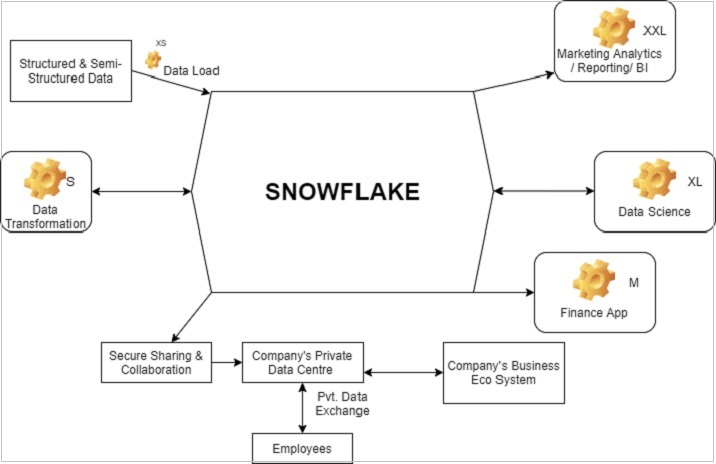
Snowflake - 功能架构
Snowflake 支持结构化和半结构化数据。数据加载完成后,Snowflake 会自动组织和构造数据。在存储数据时,Snowflake 会根据其智能将其划分并保存到不同的微分区中。Snowflake 甚至将数据存储在不同的集群中。
在功能级别上,要从 Snowflake 访问数据,需要以下组件:
登录后选择合适的角色
Snowflake 中称为数据仓库的虚拟仓库,用于执行任何活动
数据库模式
数据库
表和列
Snowflake 提供以下高级分析功能:
数据转换
支持业务应用程序
商业分析/报告/BI
数据科学
与其他数据系统共享数据
数据克隆
下图显示了 Snowflake 的功能架构:
每个块中的“设置”符号可以指数据仓库,XS、XXL、XL、L、S 指的是执行不同操作所需的数据仓库大小。根据需求和使用情况,可以增加或减少数据仓库的大小;甚至可以将其从单集群转换为多集群。
Snowflake - 如何访问
Snowflake 是一个许可数据平台。它使用积分的概念向客户收费。但是,它提供 30 天免费试用,包含 400 美元的积分用于学习目的。
请按照以下步骤在 30 天内免费访问 Snowflake:
打开 URL "www.snowflake.com" 并单击页面右上角的“免费开始”。
它将导航到注册页面,用户需要在其中提供姓名、电子邮件、公司和国家/地区等详细信息。填写表格后,单击“继续”按钮。
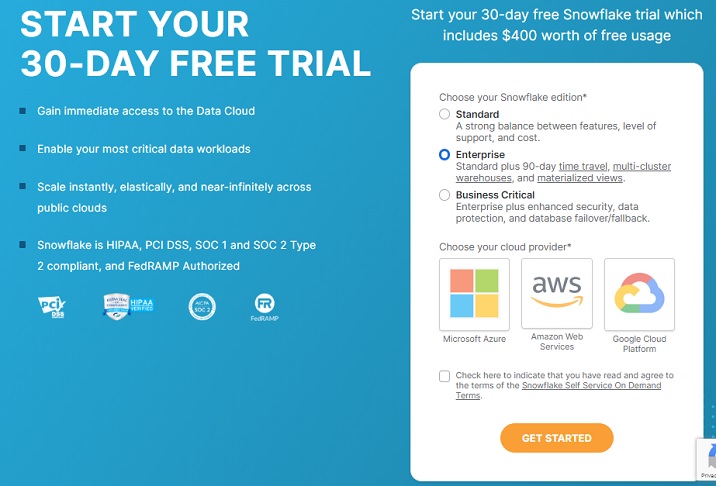
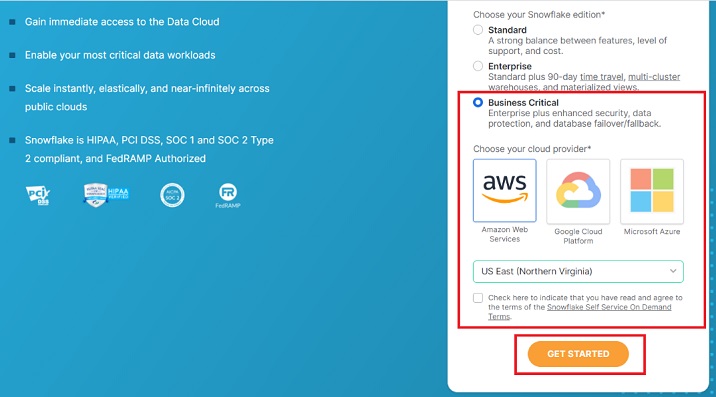
在下一个屏幕上,系统会要求您选择 Snowflake 版本。根据您要执行的功能选择版本。对于本教程,标准版就足够了,但对于使用 AWS S3 加载数据,我们需要业务关键版。
选择**业务关键版**,然后单击**AWS**。选择 AWS 所在的区域。
选中“条款和条件”框,然后单击“开始”按钮。
以下屏幕截图演示了上述步骤:
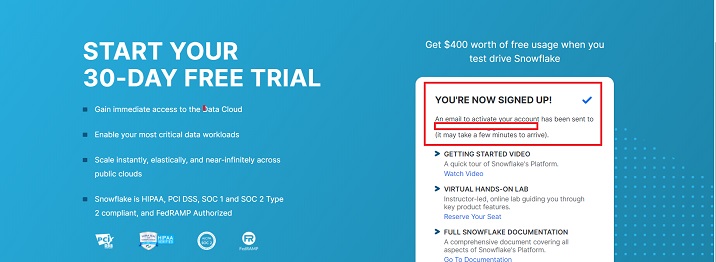
您将收到一条消息,提示帐户创建正在进行中,并且已向您的地址发送电子邮件,如下所示。
检查您的电子邮件收件箱。收到来自 Snowflake 的电子邮件后(通常在 2-3 分钟内),单击“点击激活”按钮。
它将导航到 Snowflake 的页面,用户需要在其中设置用户名和密码。此凭据将用于登录 Snowflake。
您的电子邮件中将提供一个 URL,例如:**“https://ABC12345.us-east-1.snowflakecomputing.com/console/login”**。这是一个用户特定的 URL,用于访问云中的 Snowflake。无论何时要在 Snowflake 中工作,请使用个人 URL 并登录。
Snowflake - 版本
Snowflake 根据用户/公司的需求提供四个不同的版本。
- 标准版
- 企业版
- 业务关键版
- 虚拟私有 Snowflake (VPS) 版
标准版
这是 Snowflake 的基本版本。此版本提供以下功能:
- 支持完整的 SQL 数据仓库
- 安全数据共享
- 全天候优质支持
- 1 天的数据时光机
- 数据加密
- 专用虚拟仓库
- 联合身份验证
- 数据库复制
- 支持外部函数
- Snowsight
- 支持用户创建自己的数据交换
- 数据市场访问
企业版
它是标准版+,即标准版的所有功能以及以下附加功能:
- 多集群仓库
- 长达 90 天的数据时光机
- 每年更改加密密钥
- 物化视图
- 搜索优化服务
- 动态数据屏蔽
- 外部数据令牌化
业务关键版
它是企业版+,即企业版和标准版的所有功能以及以下附加功能:
- HIPAA 支持
- PCI 合规性
- 无处不在的数据加密
- AWS 私有链路支持
- Azure 私有链路支持
- 数据库故障转移和回退
虚拟私有 Snowflake (VPS) 版
它是业务关键版+,也是最先进的版本。它支持 Snowflake 的所有产品。
客户专用的虚拟服务器,其中加密密钥位于内存中。
客户专用的元数据存储。
Snowflake - 定价模型
Snowflake 使用**三个不同的阶段**或**层级**为最终用户提供服务:
- 存储 (Storage)
- 虚拟仓库 (计算) (Virtual Warehouse (Compute))
- 云服务
Snowflake 没有许可证费用。但是,定价基于这三层的使用情况以及无服务器功能。Snowflake 收取固定金额,加上基于 Snowflake 积分使用情况的任何额外费用。
什么是 Snowflake 积分?(What is Snowflake Credit?)
它是用于消费 Snowflake 资源(通常是虚拟仓库、云服务和无服务器功能)的支付方式。Snowflake 积分是一个计量单位。它是根据使用的资源计算的,如果客户没有使用任何资源或资源处于休眠状态,则不收取任何费用。例如,当虚拟仓库正在运行并且云服务层正在执行某些用户定义的任务时,就会使用 Snowflake 积分。
存储成本 (Storage Cost)
Snowflake 对数据存储收取月费。存储成本以每月在 Snowflake 中存储的数据平均量来衡量。此数据大小是在 Snowflake 执行压缩后计算的。此成本非常低,每月 1TB 数据约 23 美元。
虚拟仓库 (计算) (Virtual Warehouse (Compute))
它是一个或多个用于将数据加载到 Snowflake 并执行查询的集群。Snowflake 使用 Snowflake 积分作为客户的付款方式。
Snowflake 积分的计算基于仓库大小、集群数量和执行查询所花费的时间。仓库的大小决定了查询运行的速度。当虚拟仓库未运行并处于暂停模式时,它不会消耗任何 Snowflake 积分。不同大小的仓库消耗 Snowflake 积分的速度也不同。
| 仓库大小 (Warehouse Size) | 服务器 (Servers) | 每小时积分 (Credit/Hour) | 每秒积分 (Credits/Second) |
|---|---|---|---|
| 超小 (X-Small) | 1 | 1 | 0.0003 |
| 小 (Small) | 2 | 2 | 0.0006 |
| 中 (Medium) | 4 | 4 | 0.0011 |
| 大 (Large) | 8 | 8 | 0.0022 |
| 超大 (X-Large) | 16 | 16 | 0.0044 |
| 2 倍超大 (2X-Large) | 32 | 32 | 0.0089 |
| 3 倍超大 (3X-Large) | 64 | 64 | 0.0178 |
| 4 倍超大 (4X-Large) | 128 | 128 | 0.0356 |
云服务
云服务管理用户任务的端到端解决方案。它会根据任务的要求自动分配资源。Snowflake 提供高达每日计算积分 10% 的免费云服务使用量。
例如,如果用户每天在计算方面花费 100 积分,则用于云服务的 10 积分免费。
无服务器功能 (Serverless Features)
Snowflake 提供许多额外的无服务器功能。这些是托管的计算资源,Snowflake 在使用时会消耗积分。
Snowpipe、数据库复制、物化视图维护、自动集群和搜索优化服务都是 Snowflake 提供的无服务器功能。
Snowflake - 对象
Snowflake 在逻辑上将数据组织到三个阶段:帐户、数据库和模式。
数据库和模式在逻辑上组织 Snowflake 帐户中的数据。一个帐户可以有多个数据库和模式,但一个数据库必须只与一个模式绑定,反之亦然。
Snowflake 对象 (Snowflake Objects)
以下是 Snowflake 对象的列表:
- 帐户 (Account)
- 用户 (User)
- 角色 (Role)
- 虚拟仓库 (Virtual Warehouse)
- 资源监控器 (Resource Monitor)
- 集成 (Integration)
- 数据库
- 模式 (Schema)
- 表 (Table)
- 视图 (View)
- 存储过程 (Stored Procedure)
- 用户自定义函数 (UDF) (User Defined Functions (UDF))
- 阶段 (Stage)
- 文件格式 (File Format)
- 管道 (Pipe)
- 序列 (Sequence)
模式之后的对象与模式绑定,模式与数据库绑定。其他实体(如用户和角色)用于身份验证和访问管理。
与 Snowflake 对象相关的要点 (Important Points Related to Snowflake Objects)
以下是一些关于 Snowflake 对象的重要事项,您应该了解:
所有 Snowflake 对象都属于逻辑容器,顶级容器是帐户,即所有内容都在 Snowflake 的帐户下。
Snowflake 单独保护所有对象。
用户可以根据授予角色的权限对对象执行操作和任务。
权限示例 (Privileges Example):
- 创建虚拟仓库 (Create a virtual warehouse)
- 列出模式中的表 (List Tables in a schema)
- 将数据插入表中 (Insert data into a table)
- 从表中选择数据 (Select data from a table)
- 不允许删除/截断表 (Not delete/truncate a table)
Snowflake - 表和视图类型 (Snowflake - Table & View Types)
表类型 (Table Types)
Snowflake 根据表的用途和性质将其分为不同类型。共有四种类型的表:
永久表 (Permanent Table)
永久表是在**数据库**中创建的。
这些表会一直存在,直到从数据库中**删除**或**删除**。
这些表旨在存储需要最高级别数据保护和恢复的数据。
这些是默认的表类型。
这些表可以进行时间旅行,最长可达 90 天,即某人可以获取最多 90 天前的数。
它是故障安全的,如果由于故障而丢失数据,可以恢复数据。
临时表 (Temporary Table)
顾名思义,临时表的存在时间较短。
这些表在一个会话中存在。
如果用户需要为后续查询和分析使用临时表,则会话完成后,它会自动删除临时表。
它主要用于短暂的数据,例如 ETL/ELT。
临时表可以进行时间旅行,但只有 0 到 1 天。
它不是故障安全的,这意味着无法自动恢复数据。
瞬态表 (Transient Table)
这些表会一直存在,直到用户删除或删除它们。
多个用户可以访问瞬态表。
它用于需要“数据持久性”但不需求长期“数据保留”的情况。例如,网站访客的详细信息、访问和注册网站的用户详细信息,因此注册后,可能不需要将详细信息存储在两个不同的表中。
瞬态表可以进行时间旅行,但只有 0 到 1 天。
它也不是故障安全的。
外部表 (External Table)
这些表会一直存在,直到被移除。
这里使用“移除”一词,因为外部表就像 Snowflake 的外部,它们不能被删除或删除。它应该被移除。
可以将其视为 Snowflake 位于外部数据湖之上,即数据湖的主要来源指向 Snowflake 以根据用户的需求利用数据。
无法直接访问数据。可以通过外部阶段在 Snowflake 中访问它。
外部表仅用于读取。
外部表无法进行时间旅行。
在 Snowflake 环境中它不是故障安全的。
视图类型 (View Types)
Snowflake 中主要有三类视图:
标准视图 (Standard View)
这是默认的视图类型。
选择表中的查询以查看数据。
用户可以根据角色和权限执行查询。
底层 DDL 可供任何有权访问这些视图的角色使用。
安全视图 (Secure View)
安全视图意味着只有授权用户才能访问。
授权用户可以查看定义和详细信息。
拥有适当角色的授权用户可以访问这些表并执行查询。
在安全视图中,Snowflake 查询优化器会绕过用于常规视图的优化。
物化视图 (Materialized View)
物化视图更像一张表。
这些视图使用过滤器条件存储来自主数据源的结果。例如,一家公司拥有自公司成立以来所有在职、离职或已故员工的记录。现在,如果用户只需要在职员工的详细信息,则可以查询主表并将结果存储为物化视图以进行进一步的分析。
物化视图会自动刷新,即每当主表获得额外/新的员工记录时,它也会刷新物化视图。
Snowflake 也支持安全物化视图。
物化视图会自动维护,它可能会消耗大量的计算资源。
物化视图的总成本基于“数据存储 + 计算 + 无服务器服务”。
每个物化视图的计算费用是根据数据变化量计算的。
Snowflake - 登录
登录 Snowflake 非常容易,因为它是一个基于云的平台。登录 Snowflake 帐户需要执行以下步骤:
转到您在注册时收到的来自 Snowflake 的电子邮件,并复制唯一的 URL(每个用户唯一)。
转到浏览器并导航到该 URL。它将导航到**登录**页面。
提供您在注册过程中设置的用户名和密码。最后,单击登录按钮。
以下屏幕截图显示了登录屏幕:
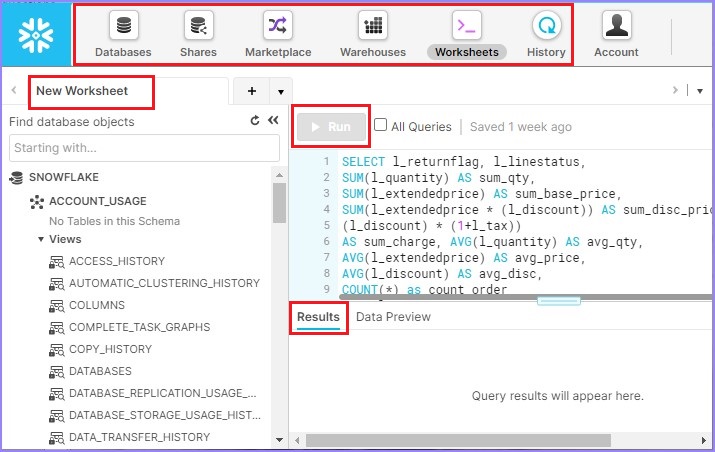
成功登录会将用户导航到 Snowflake 数据平台。用户可以在右上角看到他们的姓名,如下图所示。除了姓名外,他们还可以看到分配给他们的角色。
在左上角,有一些图标,例如**数据库、共享、数据市场、仓库、工作表**和**历史记录**。用户可以单击它们并查看这些项目的详细信息。
在左侧面板中,Snowflake 提供了一些数据库和模式用于实践,例如“DEMO_DB、SNOWFLAKE_SAMPLE_DATA、UTILDB”。
数据库详细信息旁边的空白屏幕称为**工作表**,用户可以在其中编写查询并使用**运行**按钮执行它们。
底部是**结果**面板。查询的结果将显示在此处。
以下屏幕截图显示了登录后屏幕的不同部分:
Snowflake - 数据仓库
由于仓库对于计算很重要。让我们讨论如何创建仓库、更改它以及查看仓库的详细信息。
Snowflake 提供两种创建/修改/查看仓库的方法:第一种方法是 UI,另一种方法是**SQL**语句。
使用 Snowflake 的 UI 操作仓库 (Working on Warehouses using Snowflake's UI)
让我们从创建仓库开始:
创建仓库 (Create Warehouse)
使用唯一的 URL 登录 Snowflake。单击顶部功能区中显示的**仓库**,如下图所示:
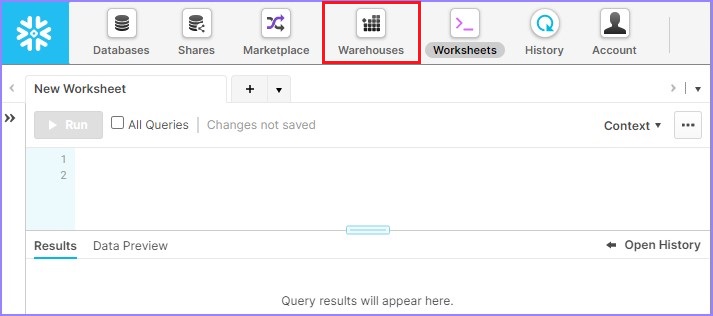
它会导航到下一个屏幕。单击仓库列表上方的**创建**,如下所示。
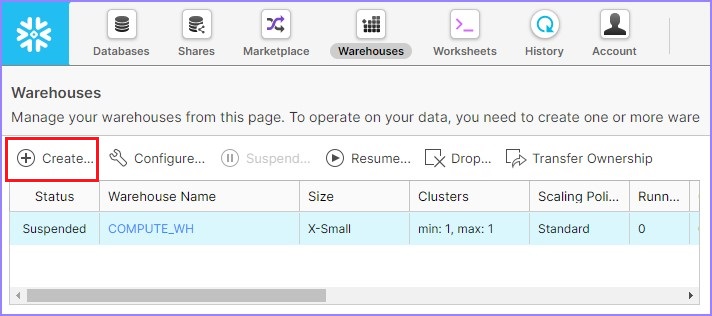
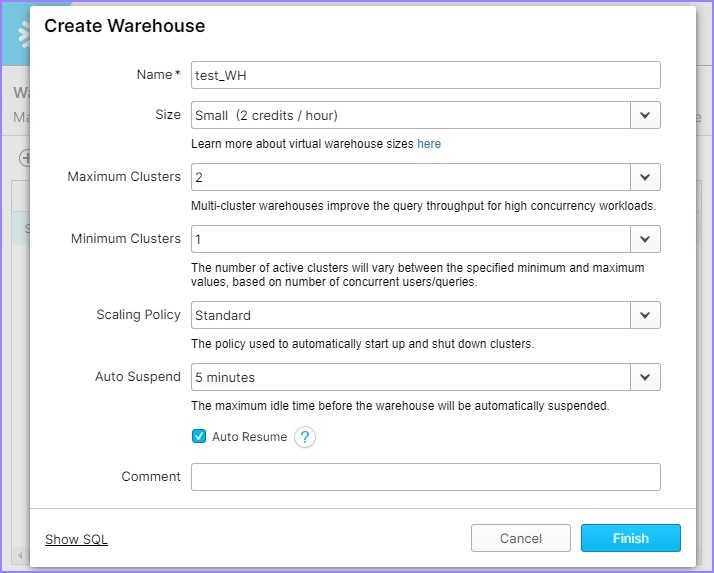
它将打开**创建**仓库对话框。应输入以下字段以创建仓库。
- **名称** - test_WH
- **大小** - 小 (Small)
- 将**自动暂停**设置为**5 分钟**
然后单击**完成**按钮。
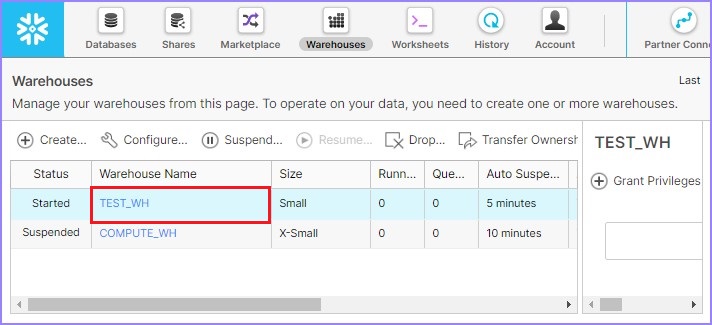
创建仓库后,用户可以在列表中查看它,如下图所示:
编辑/修改/更改仓库 (Edit/Modify/Alter Warehouse)
Snowflake 提供了根据需求修改或更改**仓库**的功能。例如,创建和使用后,用户可以更新仓库大小、集群和暂停时间。
点击顶部功能区中显示的仓库按钮。它将显示仓库页面详细信息。从仓库列表中选择需要修改的仓库。单击配置,如下面的屏幕截图所示:
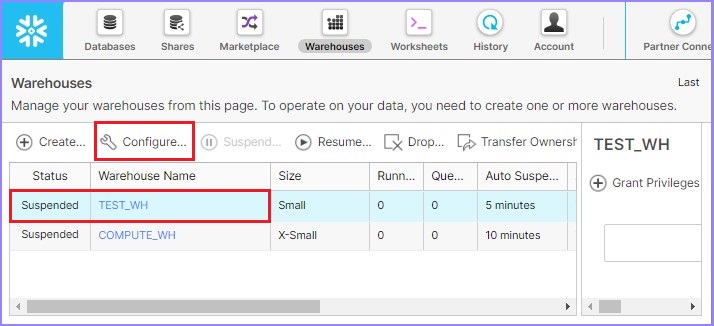
将弹出配置仓库对话框。用户可以修改除名称之外的所有详细信息。将自动暂停时间从5分钟更改为10分钟。单击完成按钮,如下面的屏幕截图所示。
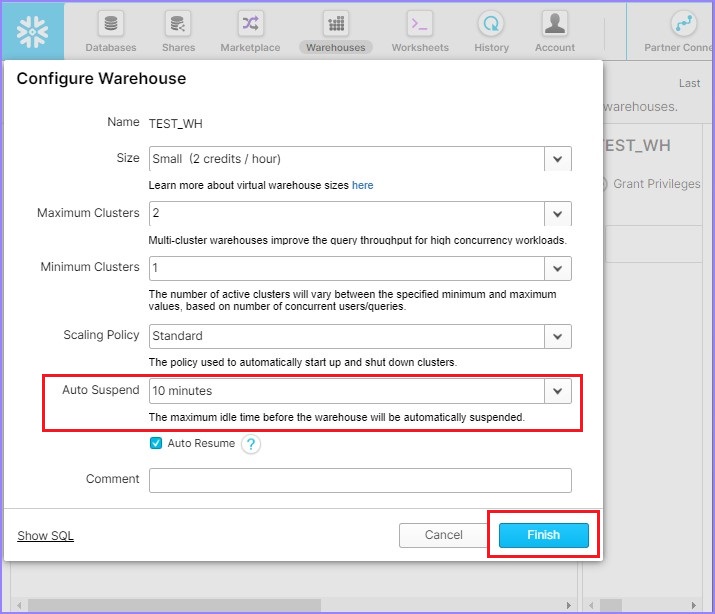
用户单击完成按钮后,将能够在视图面板中看到更新的详细信息。
查看仓库
点击顶部功能区中显示的仓库按钮。它将显示仓库的视图面板,其中包含所有已创建的仓库。
使用创建按钮创建新的仓库。
使用配置按钮更改/修改现有仓库。
如果所选仓库处于暂停模式,则使用恢复按钮激活它。
下面的屏幕截图演示了如何恢复处于暂停模式的仓库:
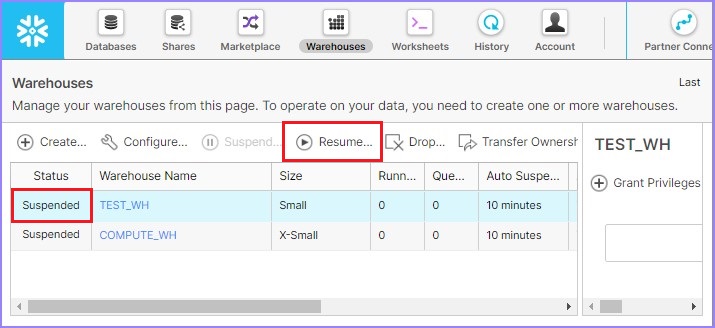
单击恢复按钮后,将弹出一个对话框。单击那里的完成按钮,如下面的屏幕截图所示:
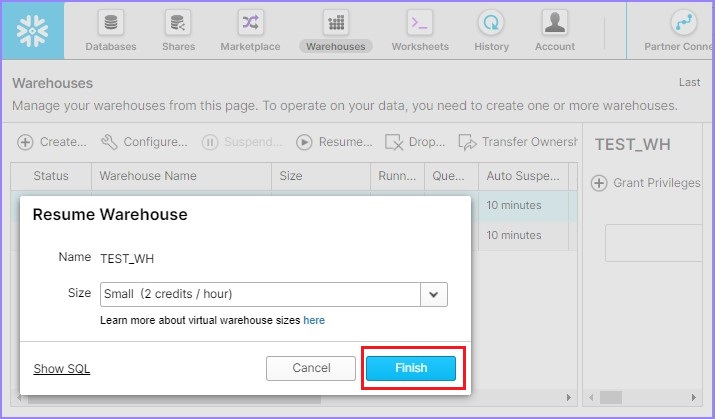
现在,用户可以看到仓库已启动,如下面的屏幕截图所示:
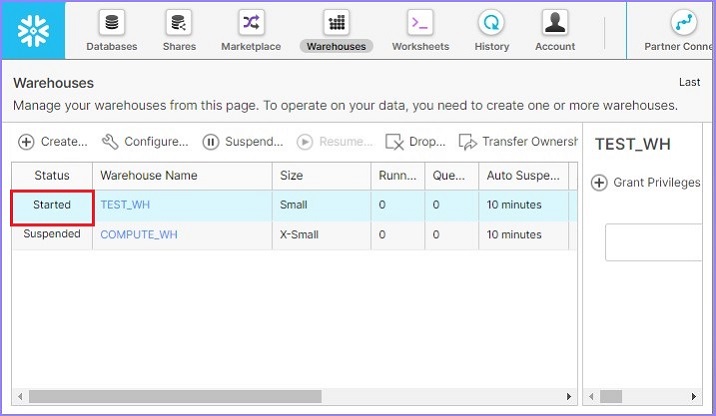
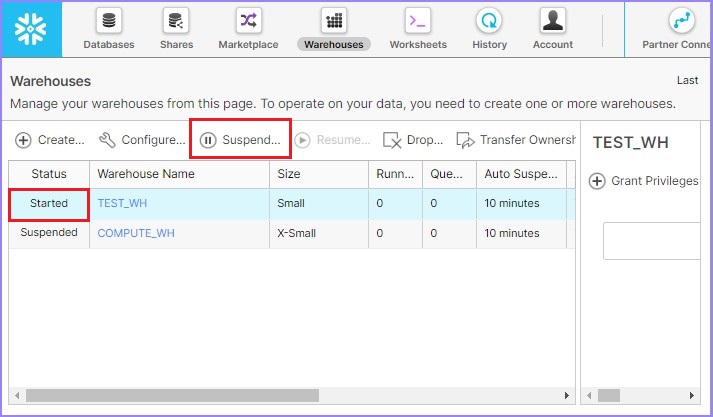
同样,用户可以使用暂停按钮立即暂停仓库。如果任何仓库处于已启动模式,则此按钮可用。选择要暂停的仓库并单击暂停按钮。将弹出一个对话框,单击是以暂停,否则单击否。
下面的屏幕截图显示了暂停功能:
用户还可以通过选择仓库并单击删除按钮来删除仓库,如下面的屏幕截图所示:
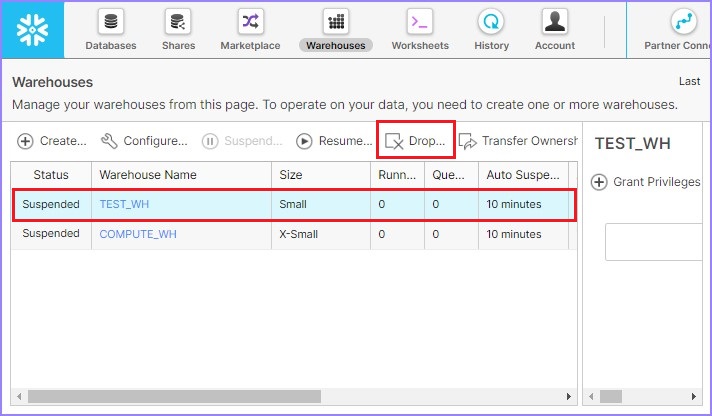
将弹出一个对话框以确认。单击“是”以删除,否则单击“否”。
使用Snowflake的SQL界面操作仓库
现在让我们检查如何使用Snowflake的SQL界面操作仓库。
创建仓库 (Create Warehouse)
登录Snowflake并导航到工作表。用户登录后,默认情况下会打开工作表,否则单击顶部功能区中显示的工作表,如下面的屏幕截图所示。
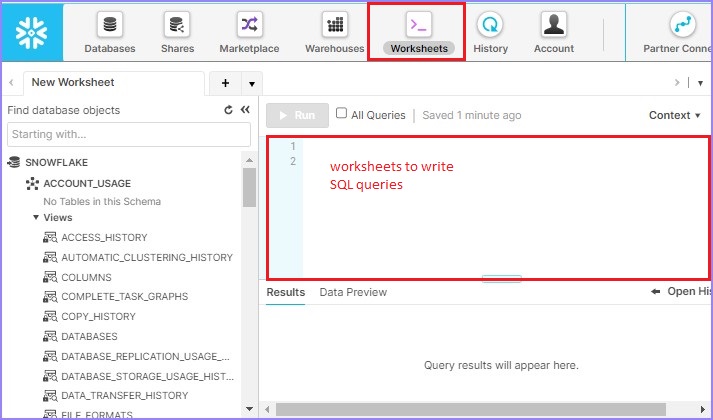
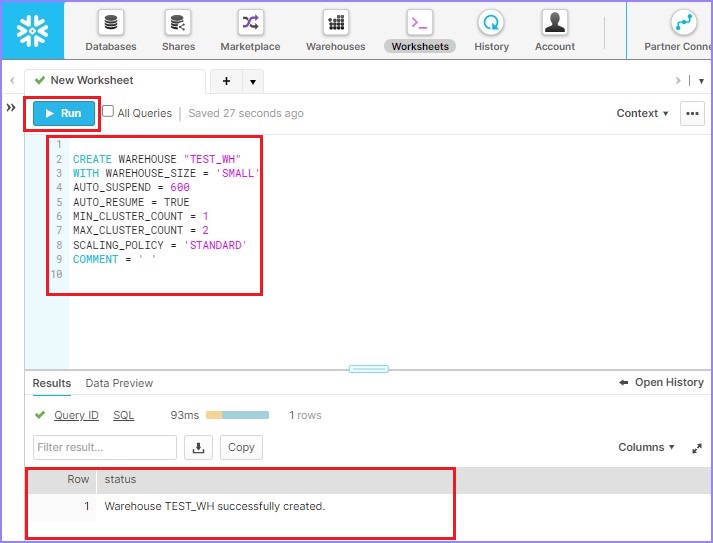
使用以下查询创建仓库TEST_WH:
CREATE WAREHOUSE "TEST_WH" WITH WAREHOUSE_SIZE = 'SMALL' AUTO_SUSPEND = 600 AUTO_RESUME = TRUE MIN_CLUSTER_COUNT = 1 MAX_CLUSTER_COUNT = 2 SCALING_POLICY = 'STANDARD' COMMENT = ' '
单击运行以执行查询。结果将显示在结果面板中,因为仓库“TEST_WH”已成功创建。
下面的屏幕截图显示了使用SQL处理的输出:
编辑/修改/更改仓库 (Edit/Modify/Alter Warehouse)
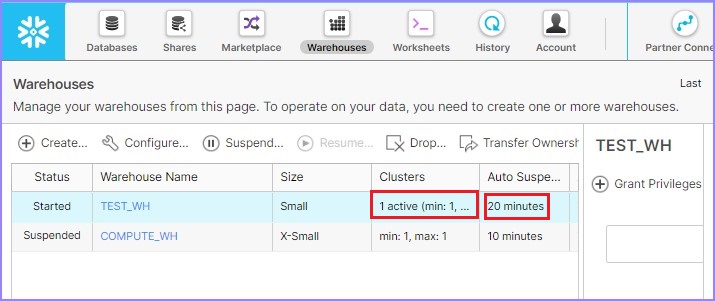
要更改/修改仓库,请使用以下查询并运行它:
ALTER WAREHOUSE "TEST_WH" SET WAREHOUSE_SIZE = 'SMALL' AUTO_SUSPEND = 1200 AUTO_RESUME = TRUE MIN_CLUSTER_COUNT = 1 MAX_CLUSTER_COUNT = 1 SCALING_POLICY = 'STANDARD' COMMENT = ' '
用户可以转到视图面板并验证更新的详细信息,如下所示:
查看仓库
要查看所有列出的仓库,用户可以使用以下SQL。它会显示所有列出仓库的详细信息。
SHOW WAREHOUSES
要暂停仓库,请使用以下SQL:
ALTER WAREHOUSE TEST_WH SUSPEND
要恢复仓库,请使用以下SQL:
ALTER WAREHOUSE "TEST_WH" RESUME If SUSPENDED
要删除仓库,请使用以下SQL:
DROP WAREHOUSE "TEST_WH"
Snowflake - 数据库
数据库是模式的逻辑分组,其中包含表和列。在本章中,我们将讨论如何创建数据库以及查看详细信息。
Snowflake为用户提供了两种创建数据库的方法,第一种是使用用户界面,第二种是应用SQL查询。
使用Snowflake的UI操作数据库
Snowflake中的所有数据都保存在数据库中。每个数据库都包含一个或多个模式,这些模式是数据库对象的逻辑分组,例如表和视图。Snowflake不对数据库的数量设置限制,您可以创建模式(在数据库内)或对象(在模式内)。
创建数据库
使用唯一的URL登录Snowflake帐户。单击顶部功能区中显示的数据库,如下面的屏幕截图所示:
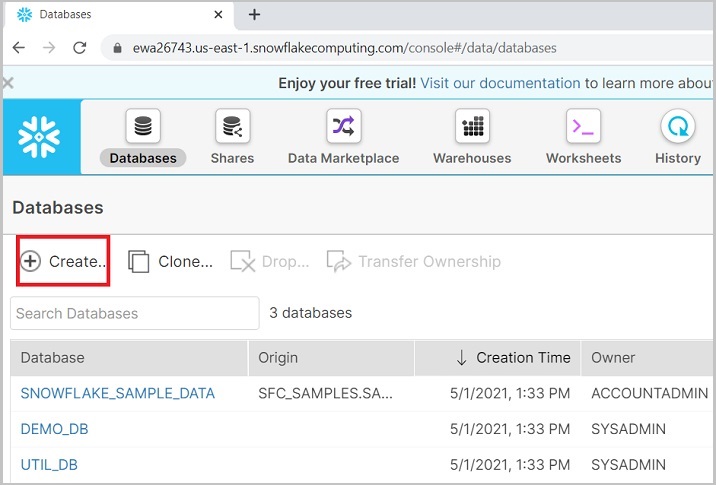
它将导航到下一个屏幕。单击数据库列表上方的创建按钮,如下所示。
它将带您进入创建数据库对话框。输入数据库名称和注释,然后单击完成按钮。
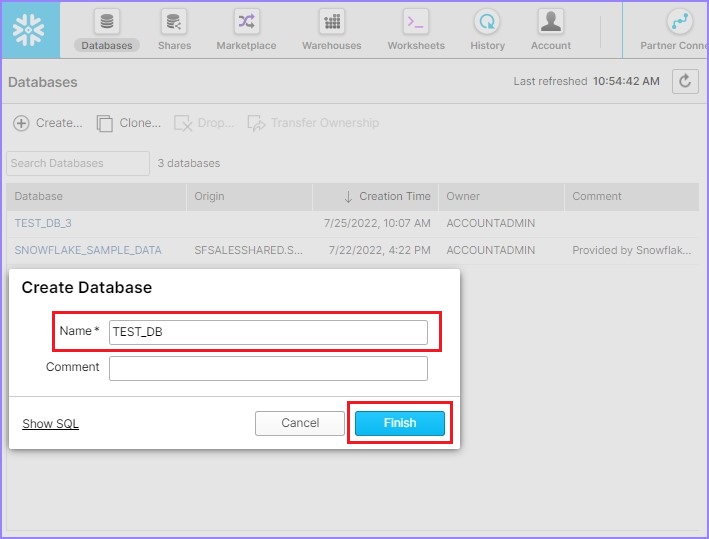
创建数据库后,用户可以在列表中查看它,如下面的屏幕截图所示:
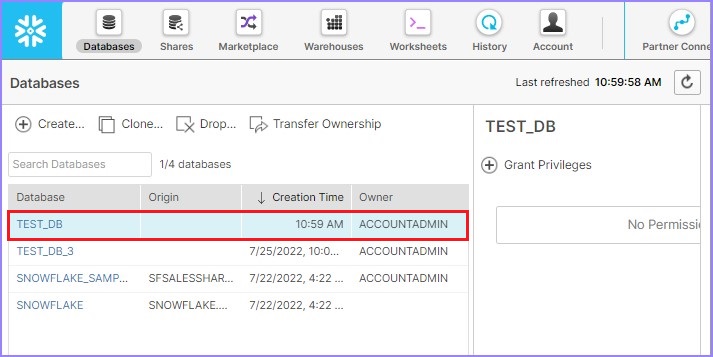
查看仓库
现在,要查看所有已创建的数据库,请单击顶部功能区中显示的数据库。它将显示数据库的视图面板,其中包含所有已创建的数据库。
使用创建按钮创建新的仓库。用户还可以通过选择数据库并单击克隆来克隆数据库,如下面的屏幕截图所示:
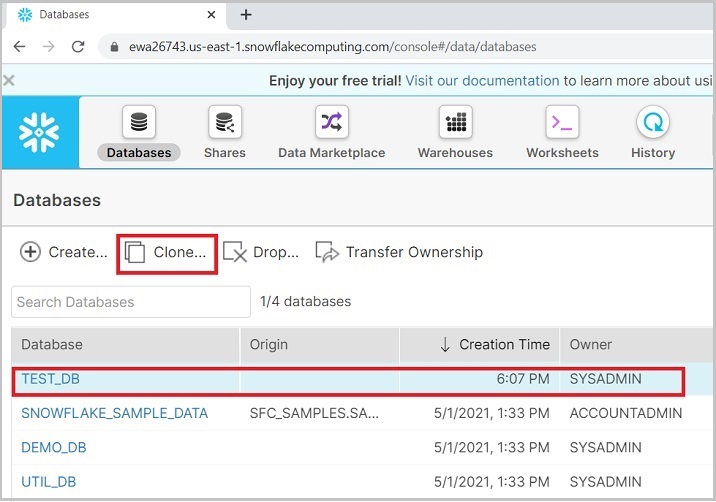
将弹出一个克隆数据库对话框,用于输入一些信息,例如名称、源和注释。输入这些详细信息后,单击完成按钮,如下面的屏幕截图所示:
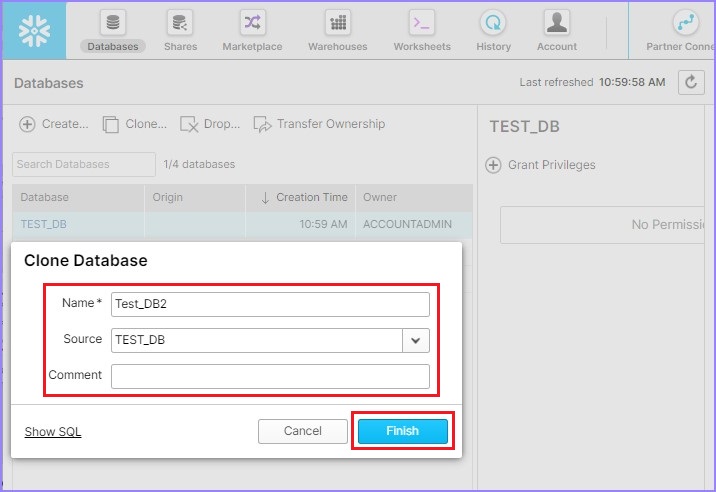
用户可以看到创建了另一个数据库,它将显示在视图面板中。用户还可以通过选择数据库并单击删除按钮来删除数据库,如下面的屏幕截图所示:
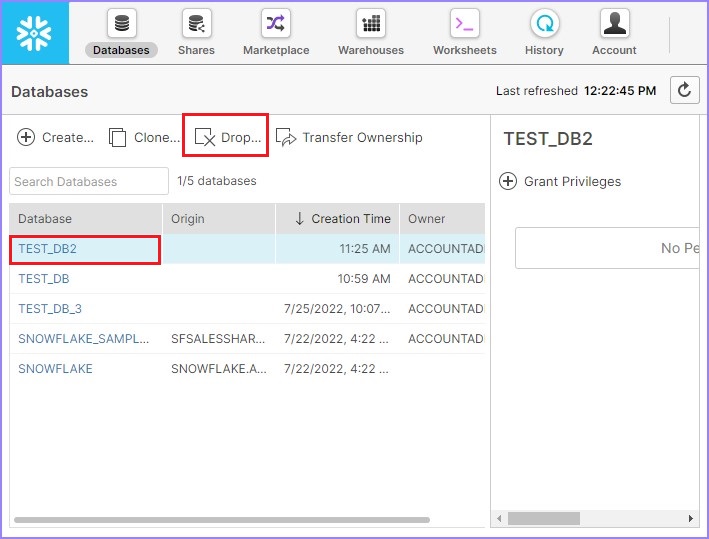
将弹出一个对话框以确认。单击是以删除,否则单击否。
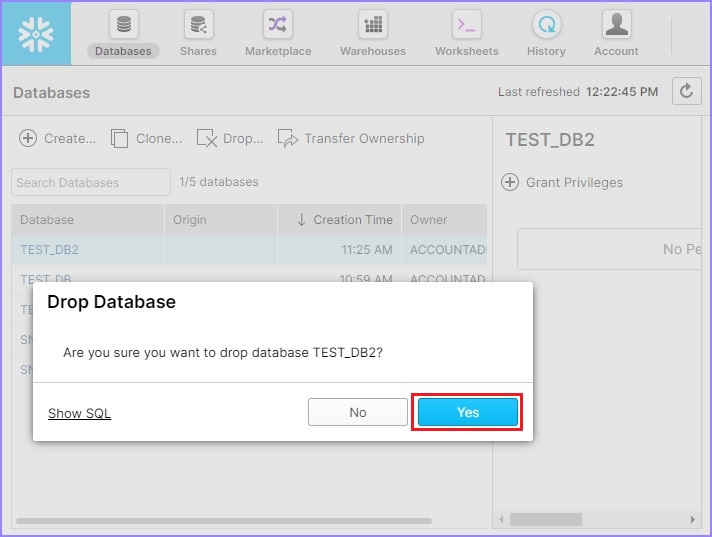
使用Snowflake的SQL界面操作数据库
在这里,我们将学习如何使用Snowflake的SQL界面创建和查看数据库。
创建数据库
要创建数据库,首先需要登录Snowflake并导航到工作表。用户登录后,默认情况下会打开工作表,否则单击顶部功能区中显示的工作表图标。
编写以下查询以创建数据库“TEST_DB_2”
CREATE DATABASE "TEST_DB_2"
现在单击运行按钮以执行查询。结果将显示在结果面板中,表明TEST_DB_2数据库已成功创建。下面的屏幕截图显示了使用SQL处理的输出:

查看数据库
要查看所有列出的仓库,用户可以使用以下SQL。它会显示所有列出仓库的详细信息。
SHOW DATABASES
要克隆数据库,用户可以使用以下SQL,这里“TEST_DB_3”是新数据库的名称,而DEMO_DB用于克隆它:
CREATE DATABASE TEST_DB_3 CLONE "DEMO_DB"
要删除数据库,请使用以下SQL:
DROP DATABASE "TEST_DB_3"
用户可以在每次操作后运行SHOW DATABASE查询以验证操作是否已完成。
Snowflake - 模式
模式是数据库对象的集合,例如表、视图等。每个模式都属于单个数据库。“Database.Schema”是Snowflake中的命名空间。执行任何操作时,都需要直接在查询中提供命名空间或在Snowflake的UI中进行设置。
在本章中,我们将讨论如何创建数据库以及查看详细信息。Snowflake为用户提供了两种创建数据库的方法,第一种是使用用户界面,第二种是使用SQL查询。
使用Snowflake的UI操作模式
让我们看看如何使用GUI功能创建模式。
创建模式
使用唯一的URL登录Snowflake帐户。现在单击顶部功能区中显示的数据库图标。它将导航到数据库视图屏幕。然后单击要创建新模式的数据库名称,如下面的屏幕截图所示:
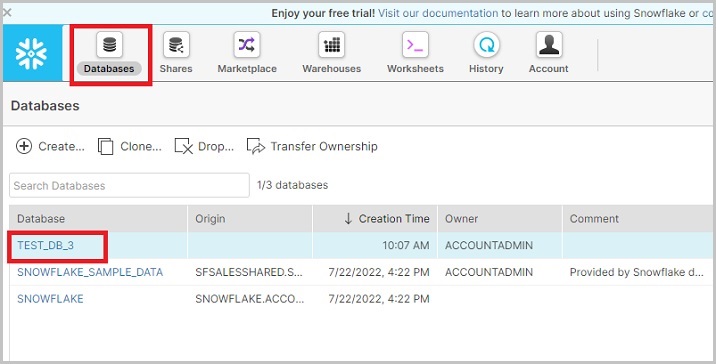
单击数据库名称后,它将导航您到数据库属性页面,您可以在其中查看在数据库内创建的表/视图/模式等。现在单击模式图标,默认情况下,选择“表”,如下面的屏幕截图所示:
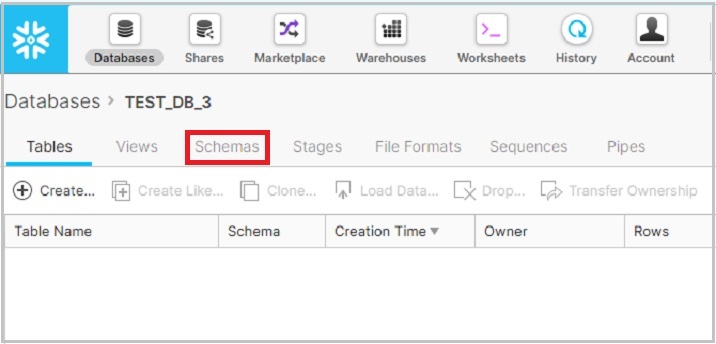
它显示已为所选数据库创建的模式列表。现在单击模式列表上方的创建图标以创建新模式,如下面的屏幕截图所示:
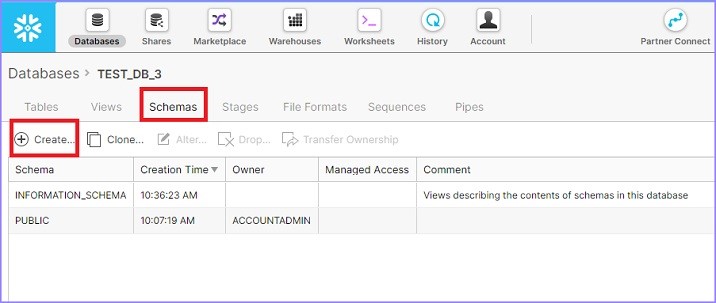
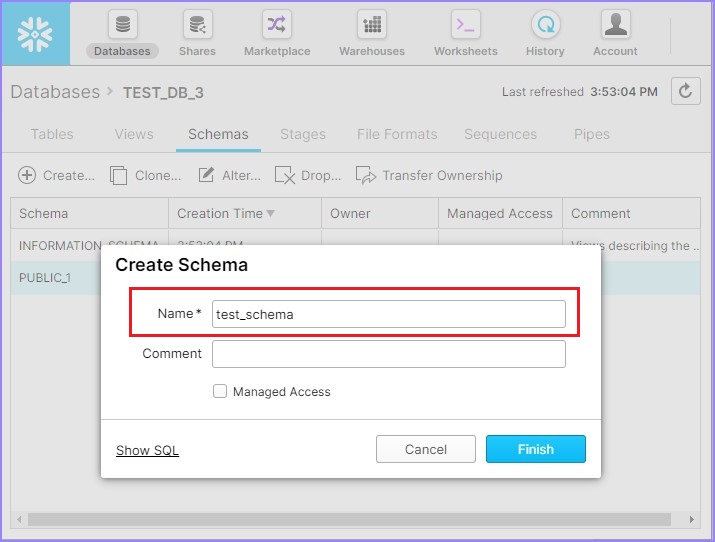
单击创建图标后,您将看到创建模式对话框。输入模式名称并单击完成按钮,如下面的屏幕截图所示:
将创建一个新的模式,并与其他模式一起列出。
编辑/修改/更改模式
Snowflake提供了修改或更改模式名称的功能。让我们看看如何修改模式名称。
单击顶部功能区中显示的数据库图标。它将显示数据库页面详细信息。现在单击数据库的名称。它将导航您到数据库属性视图页面。单击模式以查看可用模式的列表。选择一个模式以更改其名称,然后单击更改图标,如下所示。
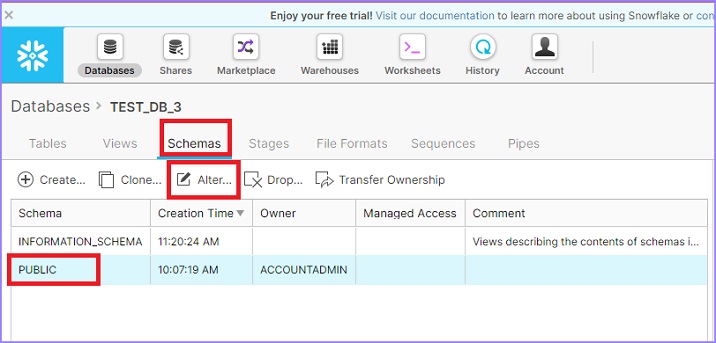
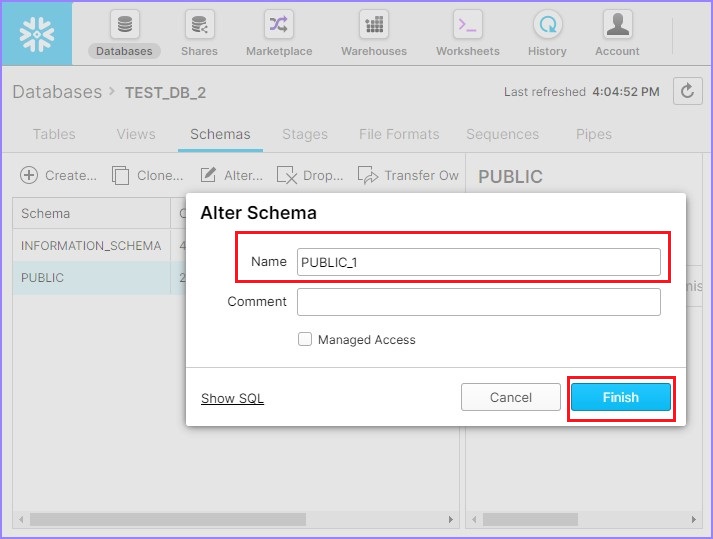
将弹出更改模式对话框。用户可以修改名称。单击完成按钮,如下所示。
现在,它显示更新的模式名称。
查看模式
模式位于数据库内。要查看模式,我们必须导航到数据库。让我们看看如何使用UI查看模式。
单击顶部功能区中显示的数据库图标。它将显示数据库的视图面板,其中包含所有已创建的数据库。选择一个数据库并单击其名称以查看其下的模式。
单击模式列表上方的模式。它将显示所有可用的模式。创建数据库后,它将默认生成两个模式 – 信息模式和公共模式。信息模式包含数据库的所有元数据。
使用创建按钮在同一数据库下创建新的模式。用户可以创建N个模式。
使用克隆按钮创建现有模式的另一个副本。要执行此操作,请选择一个模式并单击克隆图标。
下面的屏幕截图演示了此功能:
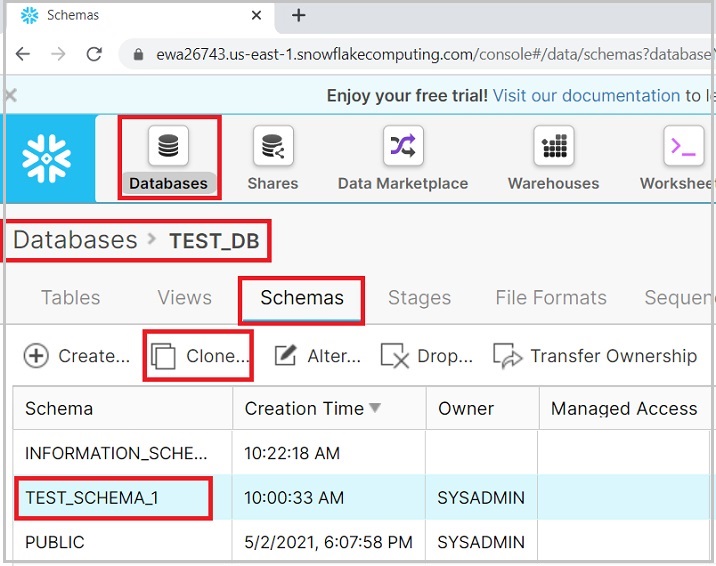
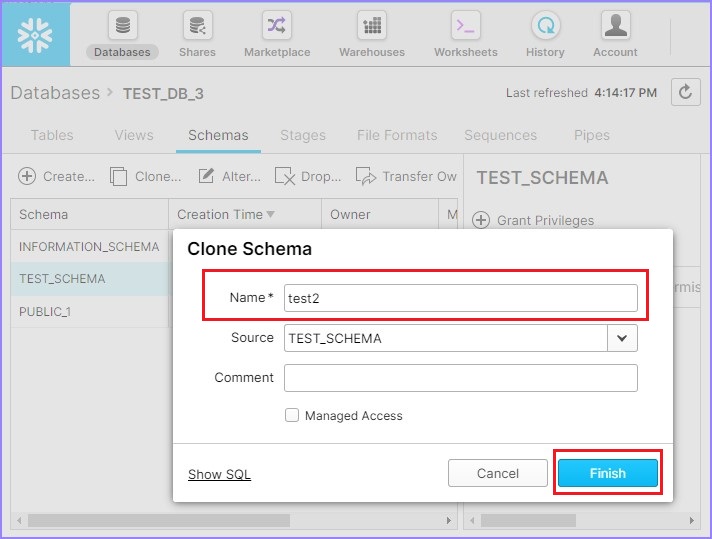
将弹出克隆模式对话框,输入新模式的名称并单击完成按钮。
下面的屏幕截图显示了克隆功能:
在视图面板中,您可以看到克隆的模式。用户还可以通过选择模式并单击删除图标来删除模式,如下面的屏幕截图所示:
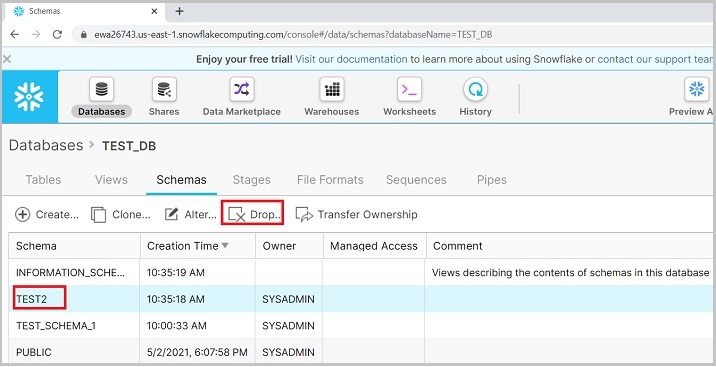
将弹出一个对话框以确认。单击“是”以删除,否则单击“否”。
使用Snowflake的SQL界面操作模式
让我们看看如何使用SQL界面功能创建模式。
创建模式
首先登录Snowflake并导航到工作表。用户登录后,默认情况下会打开工作表,否则单击顶部功能区中显示的工作表图标。
编写以下查询以在数据库TSET_DB下创建模式TEST_SCHEMA:
CREATE SCHEMA "TEST_DB"."TEST_SCHEMA"
单击运行按钮以执行查询。结果将显示在结果面板中,表明“模式TEST_SCHEMA”已成功创建。
编辑/修改/更改模式
要更改/修改模式名称,请使用以下查询并运行它:
ALTER SCHEMA "TEST_DB"."TEST_SCHEMA" RENAME TO "TEST_DB"."TEST_SCHEMA_RENAME"
用户可以转到视图面板并验证更新的名称。
查看模式
要查看所有列出的模式,用户可以使用以下SQL。它会显示所有列出模式的详细信息。
SHOW SCHEMAS
要克隆模式,请使用以下SQL:
CREATE SCHEMA "TEST_DB"."TEST2" CLONE "TEST_DB"."TEST_SCHEMA_RENAME"
要删除模式,请使用以下SQL:
DROP SCHEMA "TEST_DB"."TEST2"
用户可以在每次操作后运行SHOW SCHEMAS查询以验证操作是否已完成。
Snowflake - 表和列
在数据库中,创建模式,它们是表的逻辑分组。表包含列。表和列是数据库中低级别且最重要的对象。在本章中,我们将讨论如何在Snowflake中创建表和列。
Snowflake为用户提供了两种方法来创建表和相应的列,分别使用用户界面和SQL查询。不提供列的详细信息,用户无法创建表。
使用Snowflake的UI操作表和列
让我们看看如何使用Snowflake的UI操作表和列。
创建表和列
使用唯一的URL登录Snowflake帐户。单击顶部功能区中显示的数据库按钮。它将导航到数据库视图屏幕。
单击要在其中创建新表的数据库名称。它将导航到数据库属性页面,您可以在其中查看在数据库内创建的表/视图/模式等。
如果未选中,请单击表,默认情况下,选择“表”。您可以看到在同一数据库中创建的表列表,否则为空白。
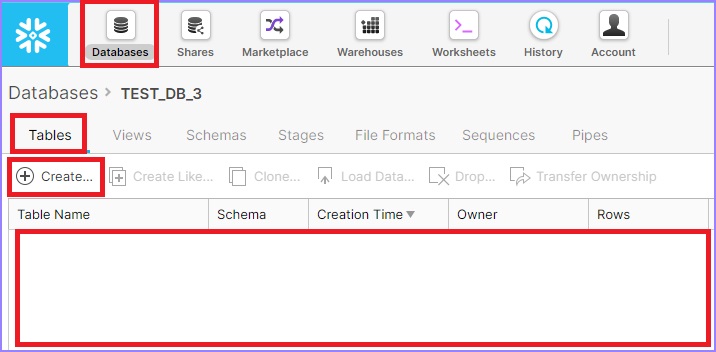
点击创建按钮添加表格。将弹出创建表格对话框。输入以下字段:
表名 - test_table
模式名 - 从可用列表中选择 – PUBLIC
列 - 点击添加按钮,然后输入名称、类型、非空或任何默认值。
要添加多列,请继续点击添加按钮,然后输入详细信息。现在,点击完成按钮。
以下屏幕截图显示了如何添加表和列:
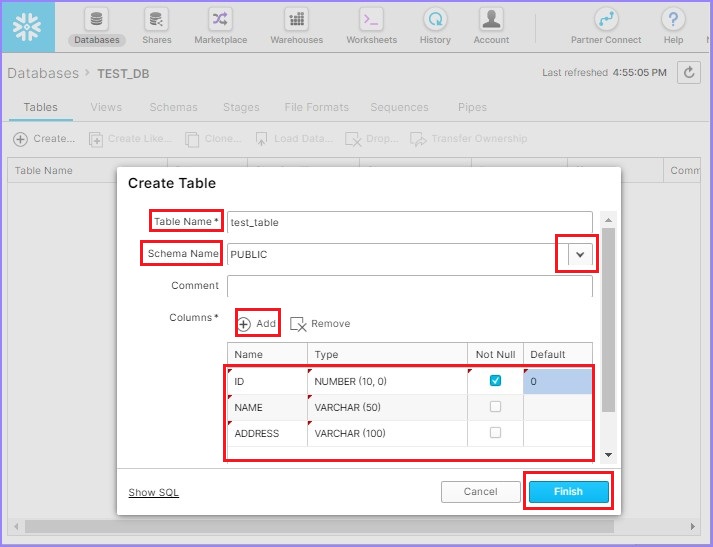
您可以在视图面板中看到已创建的表。
查看表和列
在本节中,我们将讨论如何查看表和列的详细信息,如何创建类似的表,如何克隆它以及如何删除表。
点击顶部功能区上的数据库。它将显示数据库的视图面板,其中列出了所有数据库。点击存在表的数据库的名称。例如,以下屏幕截图中显示的TEST_DB:
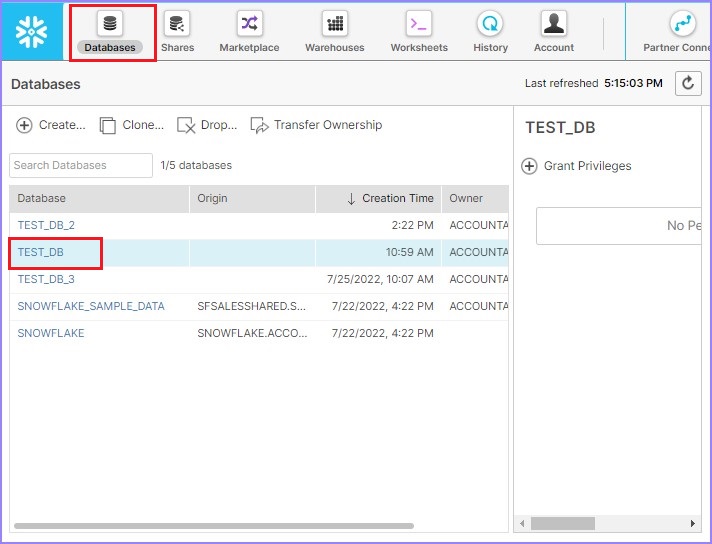
它将显示数据库中列出的所有表。使用创建按钮创建新表。使用创建类似按钮创建具有与现有表相同的元数据的表。
点击创建类似按钮,将弹出创建类似表对话框。输入新表名称并点击完成按钮。
以下屏幕截图解释了此功能:
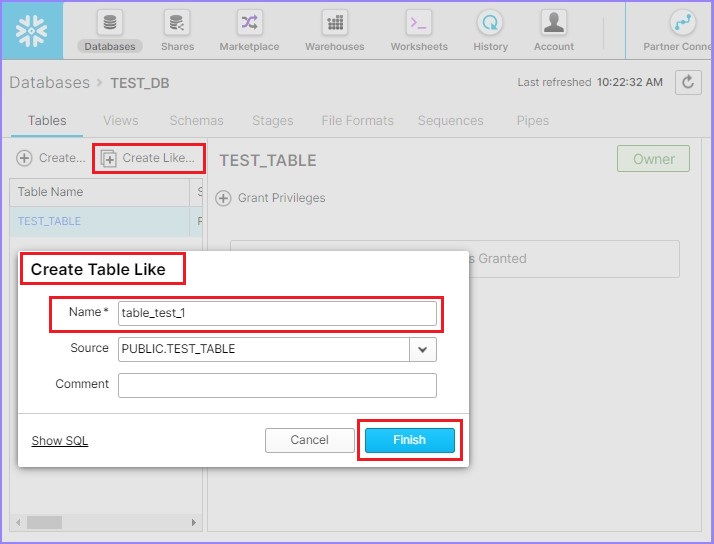
在视图面板中,您可以看到新表。在本例中为 TABLE_TEST_1。
使用克隆按钮创建现有表的另一个副本。要执行此操作,请选择一个表并点击克隆按钮。
克隆表对话框将弹出到屏幕上。输入新表名称并点击完成按钮。
以下屏幕截图显示了克隆功能。
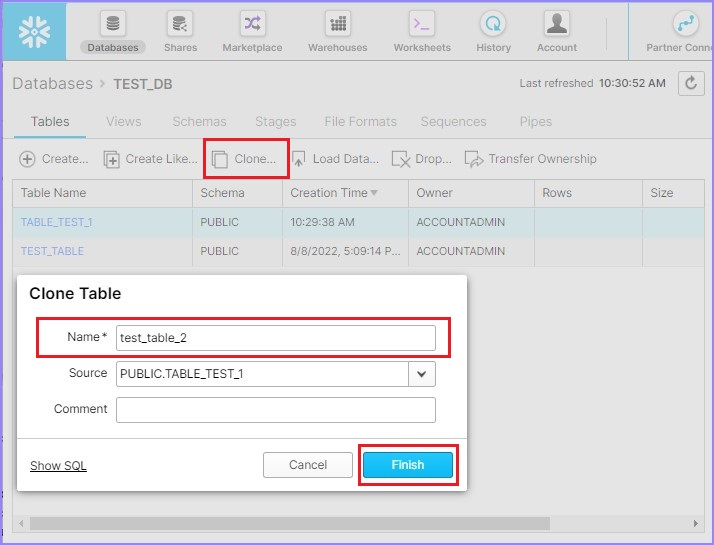
您可以在视图面板中看到新表。
克隆和创建类似的区别在于“列数据”。克隆会从现有表中提取实际数据,而创建类似只会复制表的元数据。它不会复制表中存在的现有数据。
用户也可以通过选择一个表并点击删除按钮来删除表。将弹出删除表对话框以确认。点击“是”进行删除,否则点击“否”。
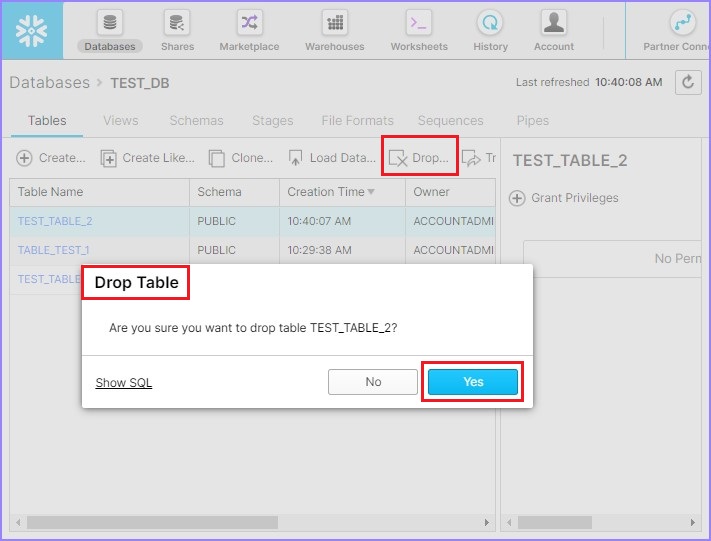
使用 Snowflake 的 SQL 接口操作表和列
一旦用户开始操作表和列,相应的数据库和模式就成为重要因素。如果未提供数据库和模式的详细信息,则查询将无法成功执行。
有两种方法可以设置数据库和模式详细信息:一种使用 Snowflake 的 UI,另一种是在查询中表名前提供数据库名称和模式名称,如下例所示:
SELECT * FROM DATABSE_NAME.SCHEMA_NAME.TABLE_NAME.
在 UI 中,需要执行以下步骤:
点击“选择模式”旁边的右上角的下拉箭头。将弹出一个对话框,用户可以在其中提供以下详细信息:
- 角色 (ROLE)
- 仓库 (Warehouse)
- 数据库
- 模式 (Schema)
以下屏幕截图描述了上述步骤:
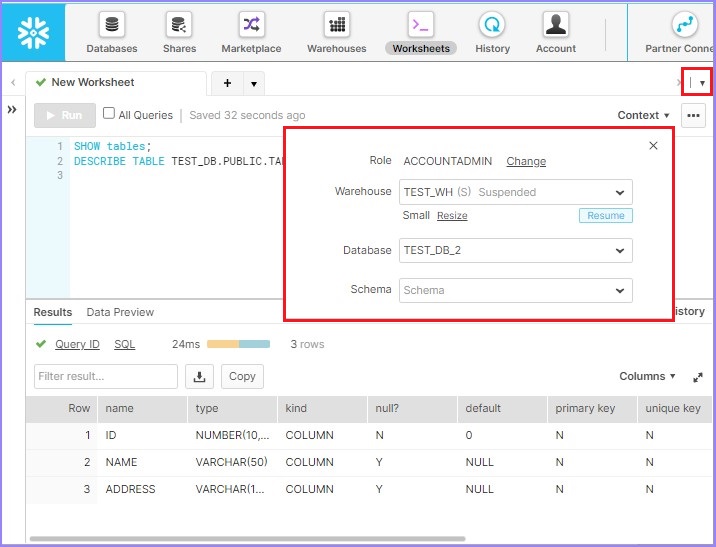
现在,当用户运行查询时,无需在查询中提供数据库名称和模式名称,它将针对如上设置的数据库和模式运行。如果需要切换到另一个数据库/模式,可以频繁更改它。
在 SQL 中设置数据库、仓库和模式
使用以下查询为会话设置仓库:
USE WAREHOUSE <WAREHOUSE_NAME>
使用以下查询为会话设置数据库:
USE DATABASE <DATABASE_NAME>
使用以下查询为会话设置模式:
USE SCHEMA <SCHEMA_NAME>
创建表和列
登录 Snowflake 并导航到工作表。默认情况下,登录后会打开工作表,否则点击顶部功能区上的工作表图标。
使用以下查询在数据库 TEST_DB 和模式 TEST_SCHEMA_1 下创建表和列:
CREATE TABLE "TEST_DB"."TEST_SCHEMA_1"."TEST_TABLE"
("ID" NUMBER (10,0) NOT NULL DEFAULT 0, "NAME" VARCHAR (50), "ADDRESS" VARCHAR (100))
点击运行按钮执行查询。结果将显示在结果面板中,显示 TEST_TABLE 已成功创建。
查看表和列
要查看所有列出的表,可以使用以下 SQL。它显示所有列出的模式的详细信息。
SHOW TABLES
要查看列定义,请使用以下 SQL:
DESCRIBE TABLE TEST_DB.TEST_SCHEMA_1.TEST_TABLE
要克隆表,请使用以下 SQL:
CREATE TABLE "TEST_DB"."TEST_SCHEMA_1".TEST_TABLE_2 CLONE "TEST_DB"."TEST_SCHEMA_1"."TEST_TABL_1"
要创建类似的表,请使用以下查询:
CREATE TABLE "TEST_DB"."TEST_SCHEMA_1".TEST_TABL_1 LIKE "TEST_DB"."TEST_SCHEMA_1"."TEST_TABLE"
要删除表,请使用以下 SQL:
DROP TABLE "TEST_DB"."TEST_SCHEMA_1"."TEST_TABLE_2"
用户可以在每次操作后运行 SHOW TABLES 查询以验证操作是否完成。
Snowflake - 从文件加载数据
在数据库中,创建模式,它们是表的逻辑分组。表包含列。表和列是数据库中低级别且最重要的对象。现在,表和列最重要的功能是存储数据。
在本章中,我们将讨论如何在 Snowflake 中将数据存储到表和列中。
Snowflake 为用户提供了两种方法,可以使用用户界面和 SQL 查询将数据存储到表和相应的列中。
使用 Snowflake 的 UI 将数据加载到表和列中
在本节中,我们将讨论使用 CSV、JSON、XML、Avro、ORC、Parquet 等文件将数据加载到表及其相应列中应遵循的步骤。
此方法仅限于加载少量数据,最多 50 MB。
创建任何格式的示例文件。创建文件时,请确保文件中的列数与表中的列数匹配,否则加载数据时操作将失败。
在 TEST_DB.TEST_SCHEMA.TEST_TABLE 中,有三列:ID、NAME 和 ADDRESS。
以下示例数据在“data.csv”中创建:
| ID | NAME | ADDRESS |
|---|---|---|
| 1 | aa | abcd |
| 2 | ab | abcd |
| 3 | aa | abcd |
| 4 | ab | abcd |
| 5 | aa | abcd |
| 6 | ab | abcd |
| 7 | aa | abcd |
| 8 | ab | abcd |
| 9 | aa | abcd |
现在,点击顶部功能区上的数据库图标。点击要上传数据的表名。它显示列数和定义。
以下屏幕截图显示了加载数据的功能:

重新验证与列相关的示例文件。点击列名顶部的加载表按钮。它将弹出加载数据对话框。在第一个屏幕上,选择仓库名称并点击下一步按钮。
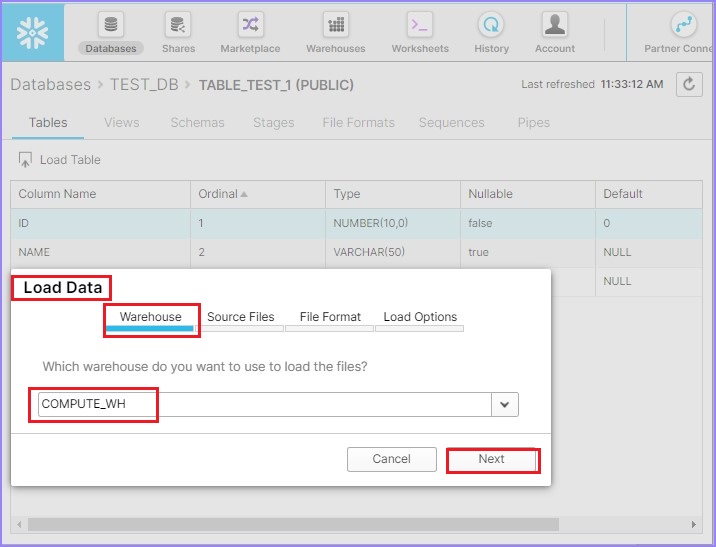
在下一个屏幕上,通过点击选择文件从本地计算机选择文件。上传文件后,您可以看到文件名,如下面的屏幕截图所示。点击下一步按钮。
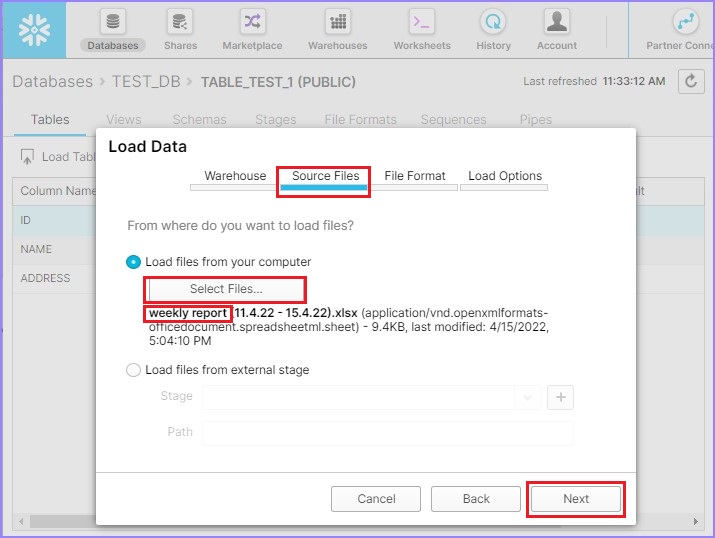
现在通过点击+ 号创建文件格式,如下面的屏幕截图所示:
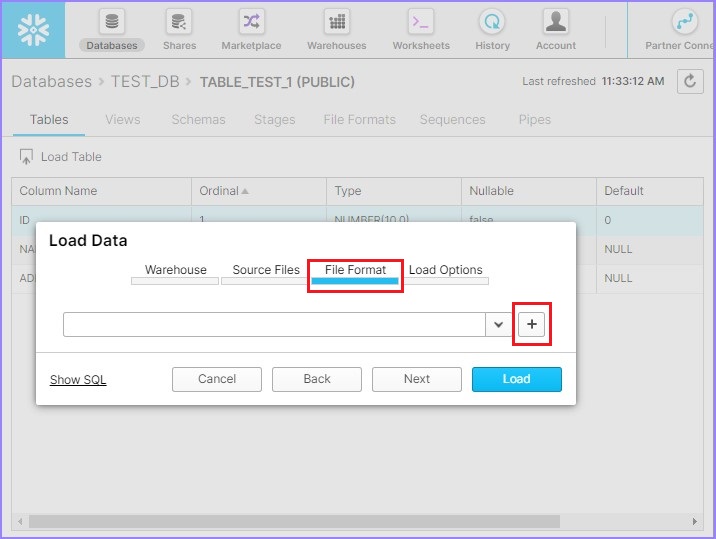
它将弹出创建文件格式对话框。输入以下详细信息:
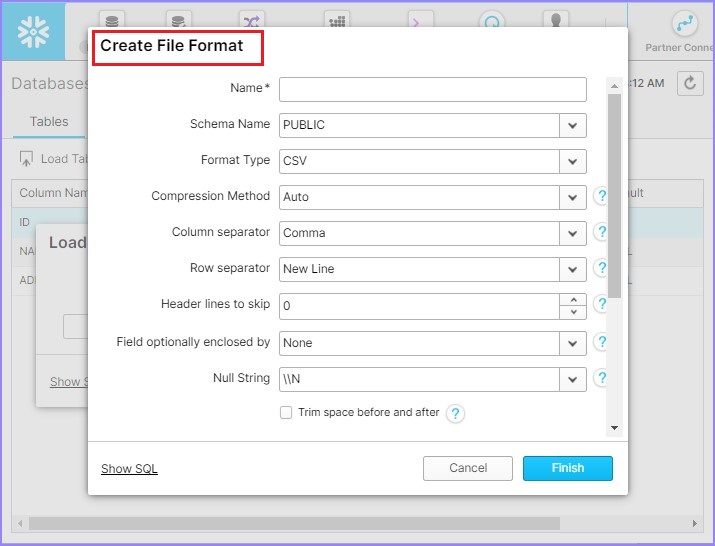
名称 - 文件格式的名称。
模式名称 - 创建的文件格式只能在给定的模式中使用。
格式类型 - 文件格式的名称。
列分隔符 - 如果 CSV 文件已分隔,请提供文件分隔符。
行分隔符 - 如何识别新行。
要跳过的标题行 - 如果提供了标题,则为 1,否则为 0。
其他内容可以保持不变。输入详细信息后,点击完成按钮。
以下屏幕截图显示了上述详细信息:
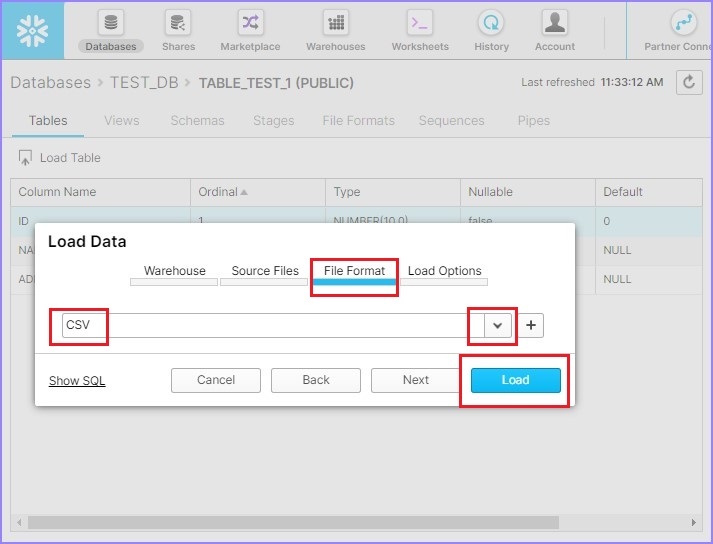
从下拉列表中选择文件格式并点击加载,如下面的屏幕截图所示:
加载结果后,您将获得摘要,如下所示。点击确定按钮。
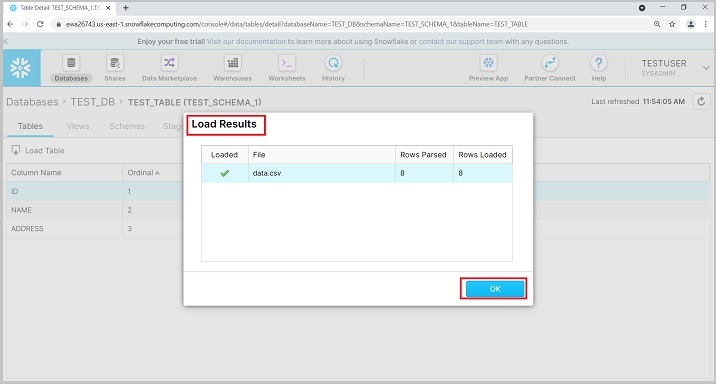
要查看数据,请运行查询“SELECT * from TEST_TABLE”。在左侧面板中,用户还可以看到数据库、模式和表详细信息。
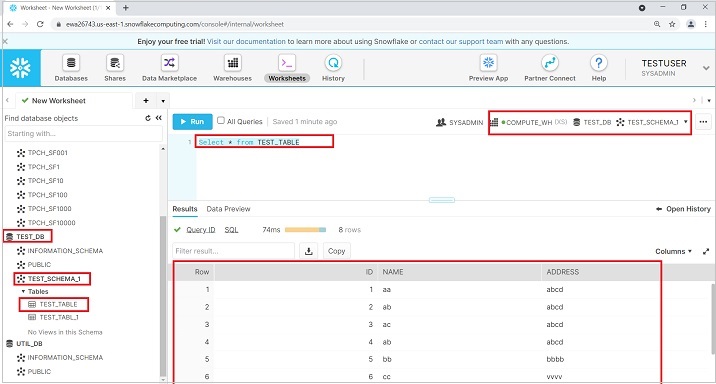
使用 SQL 将数据加载到表和列中
要从本地文件加载数据,您可以执行以下步骤:
使用 Snowflake 提供的插件 SnowSQL 将文件上传到 Snowflake 的暂存区。要执行此操作,请转到帮助并点击下载,如下所示:
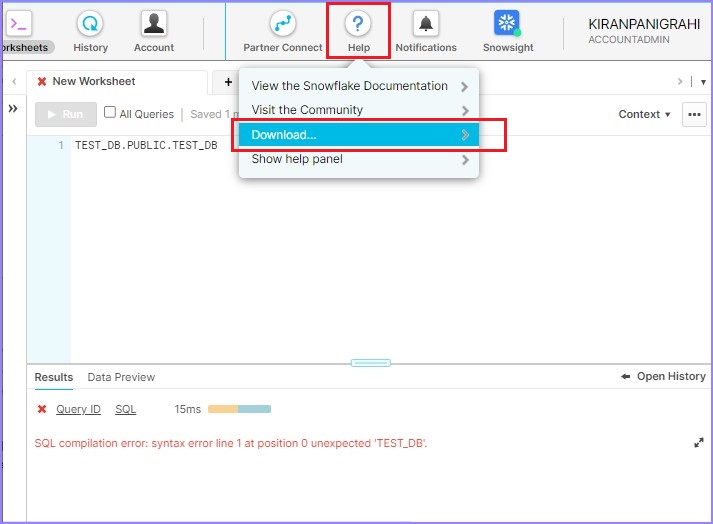
点击 CLI 客户端 (snowsql) 并点击Snowflake 资源库,如下面的屏幕截图所示:
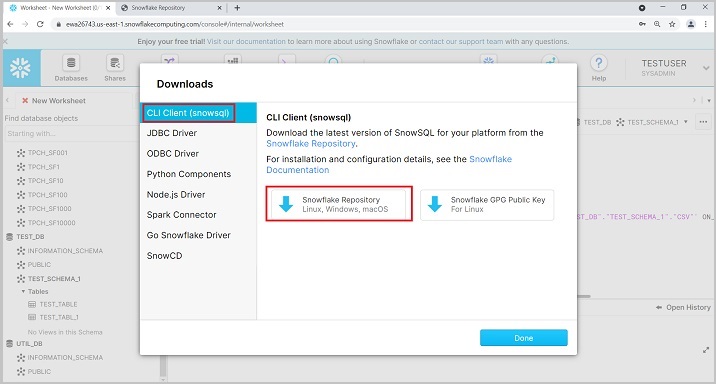
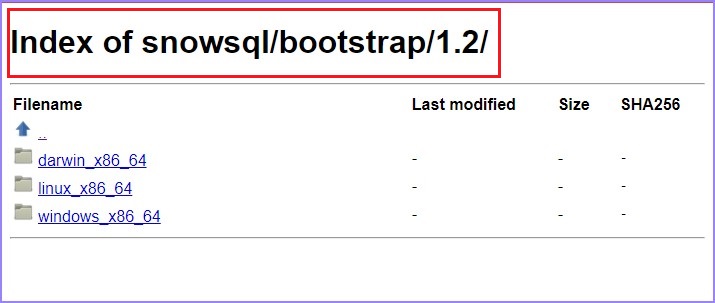
用户可以移动到 bootstrap → 1.2 → windows_x86_64 → 点击下载最新版本。
以下屏幕截图显示了上述步骤:
现在,安装下载的插件。安装后,在您的系统中打开 CMD。运行以下命令以检查连接:
snowsql -a <account_name> -u <username>
它将询问密码。输入您的 Snowflake 密码并按 ENTER。您将看到连接成功。现在使用命令行:
<username>#<warehouse_name>@<db_name>.<schema_name>
现在使用以下命令将文件上传到 Snowflake 的暂存区:
PUT file://C:/Users/*******/Documents/data.csv @csvstage;
不要忘记在末尾加上“分号”,否则它将永远运行。
文件上传后,用户可以在工作表中运行以下命令:
COPY INTO "TEST_DB"."TEST_SCHEMA_1"."TEST_TABLE" FROM @/csvstage ON_ERROR = 'ABORT_STATEMENT' PURGE = TRUE
数据将加载到表中。
Snowflake - 有用的示例查询
在本章中,我们将介绍 Snowflake 中一些有用的示例查询及其输出。
使用以下查询在 Select 语句中提取有限的数据:
"SELECT * from <table_name>" Limit 10
此查询将仅显示前 10 行。
使用以下查询显示过去 10 天的使用情况。
SELECT * FROM TABLE (INFORMATION_SCHEMA.DATABASE_STORAGE_USAGE_HISTORY
(DATEADD('days', -10, CURRENT_DATE()), CURRENT_DATE()))
使用以下查询检查 Snowflake 中创建的暂存区和文件格式:
SHOW STAGES SHOW FILE FORMATS
要检查变量,请按顺序运行以下查询:
SELECT * FROM snowflake_sample_data.tpch_sf1.region JOIN snowflake_sample_data.tpch_sf1.nation ON r_regionkey = n_regionkey;
select * from table(result_scan(last_query_id()));
SELECT * FROM snowflake_sample_data.tpch_sf1.region JOIN snowflake_sample_data.tpch_sf1.nation ON r_regionkey = n_regionkey;
SET q1 = LAST_QUERY_ID();
select $q1;
SELECT * FROM TABLE(result_scan($q1)) ;
SHOW VARIABLES;
使用以下查询查找数据库的登录历史记录:
select * from table(test_db.information_schema.login_history());
结果提供时间戳、用户名、登录方式(使用密码或 SSO)、登录期间的错误等。
使用以下命令查看所有列:
SHOW COLUMNS SHOW COLUMNS in table <table_name>
使用以下命令显示 Snowflake 提供的所有参数:
SHOW PARAMETERS;
以下是一些仅运行查询“SHOW PARAMETERS;”即可查看的详细信息:
| 序号 | 键和说明 |
|---|---|
| 1 | ABORT_DETACHED_QUERY 如果为 true,则 Snowflake 将在检测到客户端消失时自动中止查询。 |
| 2 | AUTOCOMMIT auto-commit 属性决定语句是否应该隐式地包含在事务中。如果 auto-commit 设置为 true,则需要事务的语句将隐式地包含在事务中执行。如果 auto-commit 为 false,则需要显式提交或回滚才能关闭事务。默认的 auto-commit 值为 true。 |
| 3 | AUTOCOMMIT_API_SUPPORTED 此客户端是否启用了 auto-commit 功能。此参数仅供 Snowflake 使用。 |
| 4 | BINARY_INPUT_FORMAT 二进制的输入格式 |
| 5 | BINARY_OUTPUT_FORMAT 二进制的显示格式 |
| 6 | CLIENT_ENABLE_CONSERVATIVE_MEMORY_USAGE 启用 JDBC 的保守内存使用。 |
| 7 | CLIENT_ENABLE_DEFAULT_OVERWRITE_IN_PUT 如果在 sql 命令中未指定 overwrite 选项,则将 overwrite 选项的默认值设置为 true。 |
| 8 | CLIENT_ENABLE_LOG_INFO_STATEMENT_PARAMETERS 启用准备好的语句绑定参数的信息级别日志记录。 |
| 9 | CLIENT_MEMORY_LIMIT 以 MB 为单位限制客户端使用的内存量。 |
| 10 | CLIENT_METADATA_REQUEST_USE_CONNECTION_CTX 对于客户端元数据请求 (getTables()),如果设置为 true,则使用会话目录和模式。 |
| 11 | CLIENT_METADATA_USE_SESSION_DATABASE 对于客户端元数据请求 (getTables()),如果设置为 true(与 CLIENT_METADATA_REQUEST_USE_CONNECTION_CTX 结合使用),则使用会话目录,但使用多个模式。 |
| 12 | CLIENT_PREFETCH_THREADS 控制线程的客户参数,0=自动。 |
| 13 | CLIENT_RESULT_CHUNK_SIZE 设置客户端侧最大结果块大小(以 MB 为单位)。 |
| 14 | CLIENT_RESULT_COLUMN_CASE_INSENSITIVE 客户端中的列名搜索不区分大小写。 |
| 15 | CLIENT_SESSION_CLONE 如果为 true,客户端将从帐户和用户的先前使用令牌克隆一个新会话。 |
| 16 | CLIENT_SESSION_KEEP_ALIVE 如果为 true,客户端会话将不会自动过期。 |
| 17 | CLIENT_SESSION_KEEP_ALIVE_HEARTBEAT_FREQUENCY CLIENT_SESSION_KEEP_ALIVE 的心跳频率(以秒为单位)。 |
| 18 | CLIENT_TIMESTAMP_TYPE_MAPPING 如果使用绑定 API 将变量绑定到 TIMESTAMP 数据类型,则确定它应映射到的 TIMESTAMP* 类型。 |
| 19 | C_API_QUERY_RESULT_FORMAT 用于将查询结果序列化后发送回 C API 的格式 |
| 20 | DATE_INPUT_FORMAT 日期输入格式 |
| 21 | DATE_OUTPUT_FORMAT 日期显示格式 |
| 22 | ENABLE_UNLOAD_PHYSICAL_TYPE_OPTIMIZATION 启用Snowflake中使用的物理类型优化以影响Parquet输出 |
| 23 | ERROR_ON_NONDETERMINISTIC_MERGE 尝试合并更新连接多行的行时引发错误 |
| 24 | ERROR_ON_NONDETERMINISTIC_UPDATE 尝试更新连接多行的行时引发错误 |
| 25 | GEOGRAPHY_OUTPUT_FORMAT 地理位置显示格式:GeoJSON、WKT 或 WKB(不区分大小写) |
| 26 | GO_QUERY_RESULT_FORMAT 用于将查询结果序列化后发送回 Golang 驱动程序的格式 |
| 27 | JDBC_FORMAT_DATE_WITH_TIMEZONE 如果为 true,则 ResultSet#getDate(int columnIndex, Calendar cal) 和 getDate(String columnName, Calendar cal) 将使用 Calendar 的输出显示日期。 |
| 28 | JDBC_QUERY_RESULT_FORMAT 用于将查询结果序列化后发送回 JDBC 的格式 |
| 29 | JDBC_TREAT_DECIMAL_AS_INT 当 scale 为 0 时,是否在 JDBC 中将 Decimal 视为 Int |
| 30 | JDBC_TREAT_TIMESTAMP_NTZ_AS_UTC 如果为 true,则 Timestamp_NTZ 值始终以 UTC 时区存储 |
| 31 | JDBC_USE_SESSION_TIMEZONE 如果为 true,JDBC 驱动程序将不显示 JVM 和会话之间的时区偏移量。 |
| 32 | JSON_INDENT JSON 输出的缩进宽度(0 表示紧凑) |
| 33 | JS_TREAT_INTEGER_AS_BIGINT 如果为 true,则 nodejs 客户端会将所有整数列转换为 bigint 类型 |
| 34 | LANGUAGE UI、GS、查询协调和 XP 将使用的所选语言。输入语言应采用 BCP-47 格式,即短划线格式。有关详细信息,请参阅 LocaleUtil.java。 |
| 35 | LOCK_TIMEOUT 尝试锁定资源时等待的秒数,在此之后超时并中止语句。值为 0 将关闭锁定等待,即 |
| 36 | MULTI_STATEMENT_COUNT 提交的查询文本中包含的语句数。此参数由用户提交以避免 SQL 注入。值为 1 表示一个语句,值 > 1 表示可以执行 N 个语句,如果不等于该值,则会引发异常。值为 0 表示可以执行任意数量的语句。 |
| 37 | ODBC_QUERY_RESULT_FORMAT 用于将查询结果序列化后发送回 ODBC 的格式 |
| 38 | ODBC_SCHEMA_CACHING 如果为 true,则启用 ODBC 中的模式缓存。这可以加快 SQL Columns API 调用的速度。 |
| 39 | ODBC_USE_CUSTOM_SQL_DATA_TYPES ODBC 在结果集元数据中返回 Snowflake 特定的 SQL 数据类型 |
| 40 | PYTHON_CONNECTOR_QUERY_RESULT_FORMAT 用于将查询结果序列化后发送回 Python 连接器的格式 |
| 41 | QA_TEST_NAME 如果在 QA 模式下运行,则为测试名称。用作共享池的区分符 |
| 42 | QUERY_RESULT_FORMAT 用于将查询结果序列化后发送回客户端的格式 |
| 43 | QUERY_TAG 用于标记会话执行的语句的字符串(最多 2000 个字符) |
| 44 | QUOTED_IDENTIFIERS_IGNORE_CASE 如果为 true,则忽略带引号的标识符的大小写 |
| 45 | ROWS_PER_RESULTSET 结果集中的最大行数 |
| 46 | SEARCH_PATH 未限定对象引用的搜索路径。 |
| 47 | SHOW_EXTERNAL_TABLE_KIND_AS_TABLE 更改 SHOW TABLES 和 SHOW OBJECTS 显示外部表 KIND 信息的方式。如果为 true,则外部表的 KIND 列显示为 TABLE,否则显示为 EXTERNAL_TABLE。 |
| 48 | SIMULATED_DATA_SHARING_CONSUMER 数据共享视图将返回在指定的使用者帐户中执行时相同的行。 |
| 49 | SNOWPARK_LAZY_ANALYSIS 为 Snowpark 启用延迟结果模式分析 |
| 50 | STATEMENT_QUEUED_TIMEOUT_IN_SECONDS 排队语句的超时时间(秒):如果语句在仓库中排队的时间超过此时间,则会自动取消语句;如果设置为零,则禁用。 |
| 51 | STATEMENT_TIMEOUT_IN_SECONDS 语句的超时时间(秒):如果语句运行时间过长,则会自动取消语句;如果设置为零,则强制使用最大值 (604800)。 |
| 52 | STRICT_JSON_OUTPUT JSON 输出严格符合规范 |
| 53 | TIMESTAMP_DAY_IS_ALWAYS_24H 如果设置,则对日期的算术运算始终使用每天 24 小时,可能不会保留时间(由于夏令时变化) |
| 54 | TIMESTAMP_INPUT_FORMAT 时间戳输入格式 |
| 55 | TIMESTAMP_LTZ_OUTPUT_FORMAT TIMESTAMP_LTZ 值的显示格式。如果为空,则使用 TIMESTAMP_OUTPUT_FORMAT。 |
| 56 | TIMESTAMP_NTZ_OUTPUT_FORMAT TIMESTAMP_NTZ 值的显示格式。如果为空,则使用 TIMESTAMP_OUTPUT_FORMAT。 |
| 57 | TIMESTAMP_OUTPUT_FORMAT 所有时间戳类型的默认显示格式。 |
| 58 | TIMESTAMP_TYPE_MAPPING 如果使用 TIMESTAMP 类型,则应将其映射到的特定 TIMESTAMP* 类型 |
| 59 | TIMESTAMP_TZ_OUTPUT_FORMAT TIMESTAMP_TZ 值的显示格式。如果为空,则使用 TIMESTAMP_OUTPUT_FORMAT。 |
| 60 | TIMEZONE 时区 |
| 61 | TIME_INPUT_FORMAT 时间输入格式 |
| 62 | TIME_OUTPUT_FORMAT 时间显示格式 |
| 63 | TRANSACTION_ABORT_ON_ERROR 如果此参数为 true,并且在非自动提交事务中发出的语句返回错误,则非自动提交事务将被中止。在此事务内发出的所有语句都将失败,直到执行 commit 或 rollback 语句以关闭该事务为止。 |
| 64 | TRANSACTION_DEFAULT_ISOLATION_LEVEL 启动事务时的默认隔离级别,在未指定隔离级别时 |
| 65 | TWO_DIGIT_CENTURY_START 对于两位数日期,定义一个世纪起始年份。 |
| 66 | UI_QUERY_RESULT_FORMAT 用于将查询结果序列化后发送回 Python 连接器的格式 |
| 67 | UNSUPPORTED_DDL_ACTION 遇到不受支持的 DDL 语句时要采取的操作 |
| 68 | USE_CACHED_RESULT 如果启用,则只要原始结果未过期,就可以在相同查询的连续调用之间重用查询结果 |
| 69 | WEEK_OF_YEAR_POLICY 定义将周分配给年份的策略 |
| 70 | WEEK_START 定义一周的第一天 |
Snowflake - 监控使用情况和存储
Snowflake 根据**存储**、**使用情况**和**云服务**向客户收费。监控存储数据和使用情况变得非常重要。
单个用户可以查看长时间运行的查询的历史记录,而帐户管理员可以查看每个用户的账单、每个用户或按日期的服务消耗和使用情况等。
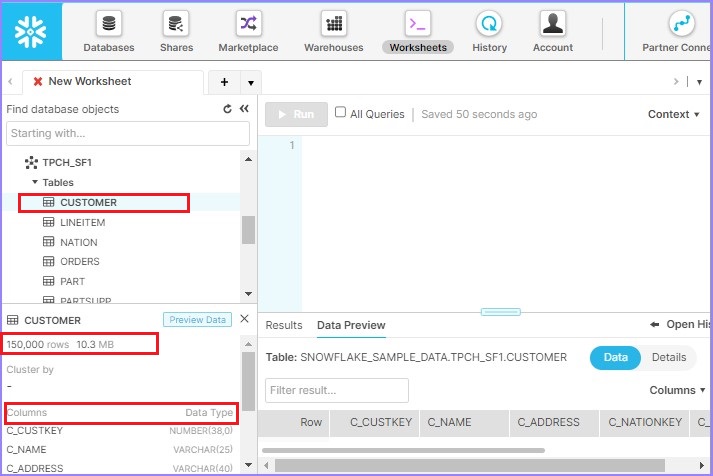
检查存储
用户可以检查各个表有多少行以及数据大小。如果用户有权访问表,则只需选择一个表即可查看这些详细信息。在左下侧面板中,用户可以看到**表名**,然后是行数和数据存储大小。之后,它显示表的列定义。
以下屏幕截图显示了如何检查存储详细信息:
历史记录
在本节中,用户可以检查他们在 Snowflake 中的活动,例如他们使用哪些查询、查询的当前状态、运行查询花费了多少时间等。
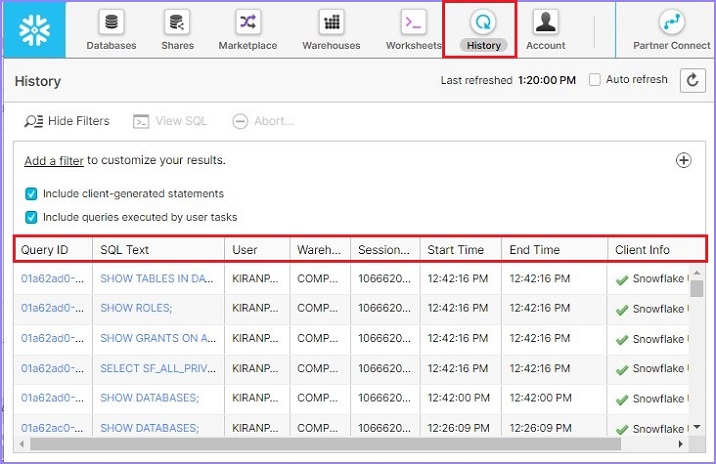
要查看历史记录,请单击顶部功能区中的**历史记录**选项卡。它将显示用户历史记录。如果用户已以帐户管理员身份访问或登录,他们可以根据单个用户过滤历史记录。它显示以下信息:
查询状态为运行中/失败/成功
**查询 ID** - 查询 ID 对所有执行的查询都是唯一的
**SQL 文本** - 它显示用户运行的查询。
**用户** - 执行该操作的用户。
**仓库** - 用于运行查询的仓库。
**集群** - 如果是多集群,则为使用的集群数量
**大小** - 仓库大小
**会话 ID** - 每个工作表都有唯一的会话 ID。
**开始时间** - 查询开始执行的时间
**结束时间** - 查询完成执行的时间
**总持续时间** - 查询运行的总持续时间。
**扫描的字节数** - 它显示扫描了多少数据才能获得结果
**行数** - 扫描的行数
以下屏幕截图显示历史记录视图:
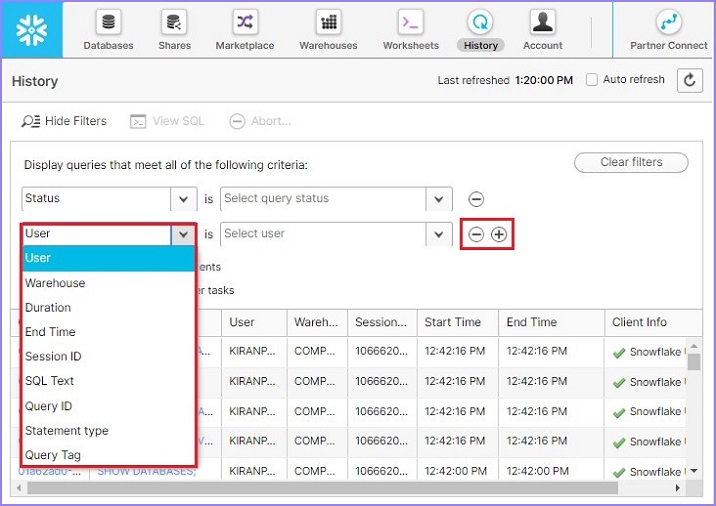
在过滤器中,用户可以通过单击**“+”**号来放置一个或多个过滤器,并使用**“-”**号来删除过滤器。以下屏幕截图显示可用过滤器的列表:
监控
要执行帐户级别监控,用户必须以 ACCOUNTADMIN 角色登录。
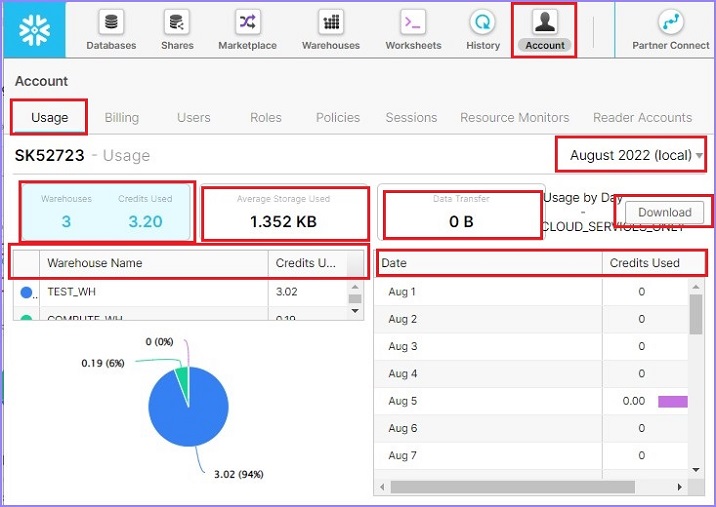
出于监控目的,请以**帐户管理员**身份登录。单击顶部功能区中的**帐户链接**。默认情况下,它将显示帐户使用情况。用户可以看到创建的仓库数量、使用了多少信用额度、平均存储使用量(这意味着在运行查询期间我们扫描了多少数据与总体存储量相比),以及传输了多少数据。
它还显示每个仓库使用的信用额度,并显示一个饼图。在右侧,用户可以看到表格形式的**日期**与**使用的信用额度**。用户甚至可以通过单击“下载数据”来下载数据。可以通过更改右上角的月份来查看月度使用情况。
以下屏幕截图显示“使用情况”选项卡信息:
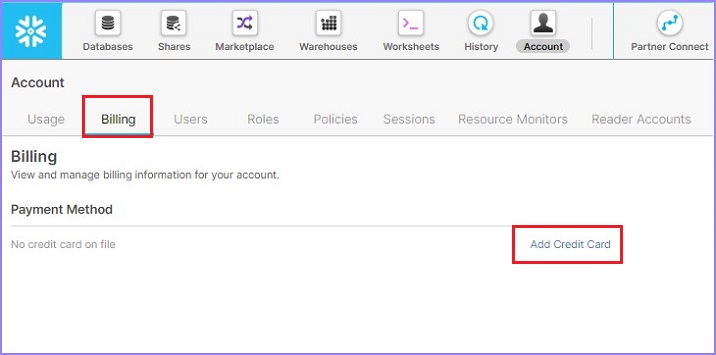
单击下一个选项卡**账单**。在这里,用户可以看到之前添加的任何付款方式。用户还可以通过单击“添加信用卡”链接,然后提供信用卡号、CVV、有效期、姓名等常规详细信息来添加新的付款方式。
以下屏幕截图显示账单部分:
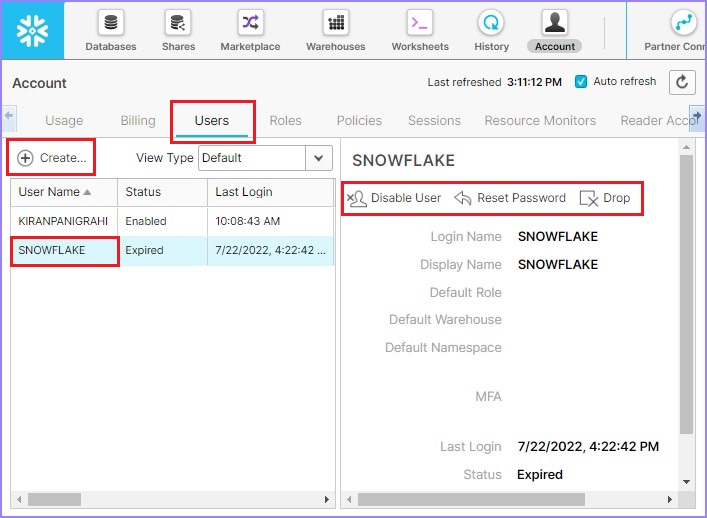
单击下一个选项卡**用户**。它显示帐户中所有用户的名称。
通过选择**用户**,帐户管理员可以使用**重置密码**、**禁用用户**和**删除**按钮分别重置用户密码、禁用用户或删除用户。通过单击用户列表顶部的“创建”按钮,帐户管理员可以创建新用户。
以下屏幕截图显示“用户”选项卡的功能:
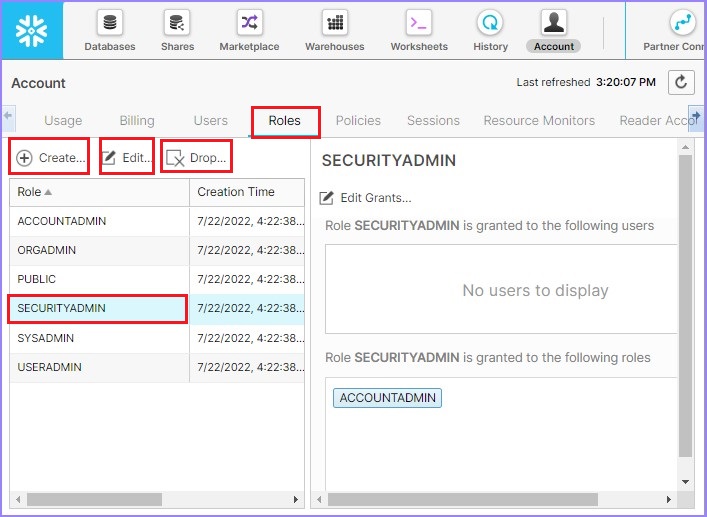
现在单击下一个选项卡**角色**。可以通过单击角色列表顶部的**创建**按钮在此处创建新角色。通过选择角色,它还提供启用或删除角色的选项,分别通过单击**编辑**按钮和**删除**按钮。
以下屏幕截图显示**角色**选项卡的功能:
除此之外,还有策略、会话、资源监视器和阅读器帐户选项卡。帐户管理员可以创建/编辑/删除策略,创建/编辑/删除会话,创建/编辑/删除资源监视器,以及类似于阅读器帐户的操作。
Snowflake - 缓存
Snowflake 具有独特的缓存功能。它基于此缓存提供快速的结果和较少的数据扫描。它甚至可以帮助客户降低账单。
Snowflake中主要有三种缓存类型。
- 元数据缓存
- 查询结果缓存
- 数据缓存
默认情况下,所有Snowflake会话都启用缓存。但用户可以根据需要禁用它。但是,用户只能禁用**查询结果缓存**,无法禁用**元数据缓存**和**数据缓存**。
本章将讨论不同类型的缓存以及Snowflake如何决定缓存策略。
元数据缓存
元数据存储在云服务层,因此缓存也在同一层。这些元数据缓存对所有人始终启用。
它主要包含以下详细信息:
表中的行数。
列的最小/最大值
列中不同值的个数
列中NULL值的个数
不同表版本的详细信息
物理文件的引用
SQL优化器主要利用这些信息来更快地执行查询。一些查询可以直接通过元数据本身回答。对于此类查询,不需要虚拟仓库,但可能需要支付云服务费用。
此类查询例如:
**所有SHOW**命令
**MIN,MAX**,但仅限于列的整数/数字/日期数据类型。
COUNT
让我们运行一个查询来了解元数据缓存的工作原理,用户可以进行验证。
登录Snowflake并转到工作表。通过运行以下查询来挂起仓库:
ALTER WAREHOUSE COMPUTE_WH SUSPEND;
现在,按顺序运行以下查询:
USE SCHEMA SNOWFLAKE_SAMPLE_DATA.TPCH_SF100; SELECT MIN(L_orderkey), MAX(l_orderkey), COUNT(*) FROM lineitem;
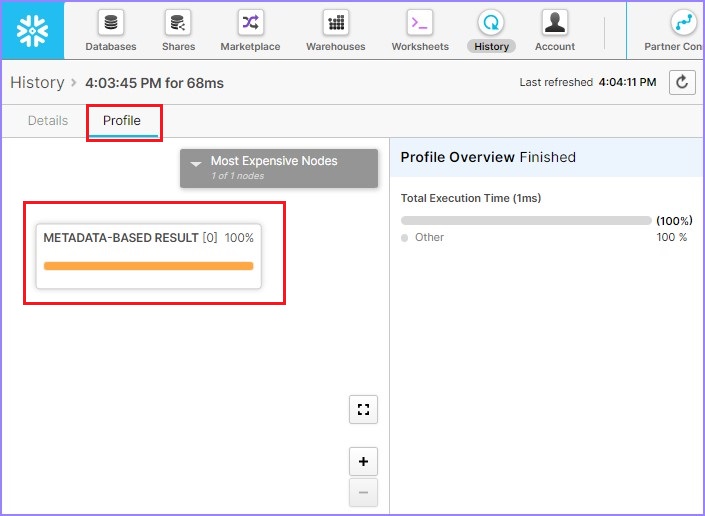
用户将能够在不到100毫秒内看到结果,如下面的屏幕截图所示。单击查询ID,将显示查询ID的链接。然后单击如下所示的链接:
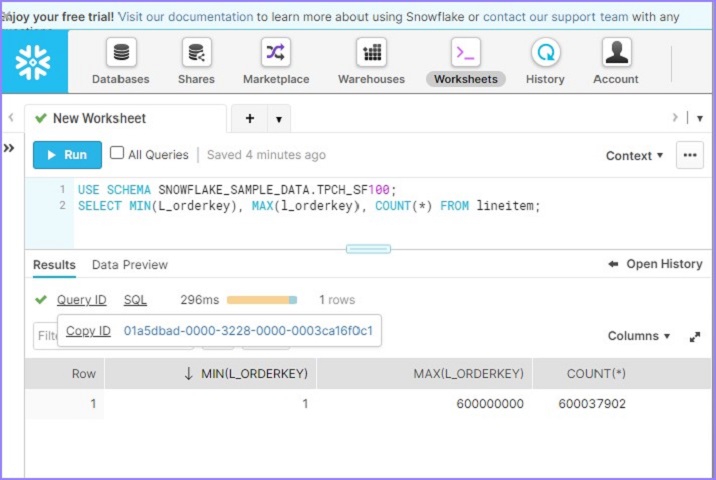
默认情况下,它会打开显示SQL的详细信息页面。单击“**概要(Profile)**”选项卡。它显示100%基于元数据的結果。这意味着它无需任何计算仓库即可运行结果并基于元数据缓存获取详细信息。
下面的屏幕截图显示了上述步骤:
查询结果缓存
查询结果由云服务层存储和管理。如果多次运行相同的查询,这非常有用,但前提是在多次运行查询的时间段内,底层数据或基表没有更改。此缓存具有一个独特的功能,即同一帐户中的其他用户也可以使用。
例如,如果用户1第一次运行查询,结果将存储在缓存中。当用户2也尝试运行相同的查询(假设基表和数据没有更改)时,它将从查询结果缓存中获取结果。
缓存的结果可用24小时。但是,每次重新运行相同的查询时,24小时的计数器都会重置。例如,如果一个查询在上午10点运行,它的缓存将保留到第二天上午10点。如果在同一天下午2点重新运行相同的查询,那么缓存将保留到第二天下午2点。
要使用查询结果缓存,需要满足一些条件:
必须重新运行完全相同的**SQL**查询。
SQL中不应包含任何随机函数。
用户必须拥有使用它的权限。
运行查询时应启用查询结果缓存。默认情况下启用,除非另行设置。
查询结果缓存的一些适用场景:
需要大量计算的查询,例如聚合函数和半结构化数据分析。
非常频繁运行的查询。
复杂的查询。
重构其他查询的输出,例如“USE TABLE function RESULT_SCAN(<query_id>)”。
让我们运行一个查询来了解查询结果缓存的工作原理,用户可以进行验证。
登录Snowflake并转到工作表。通过运行以下查询来恢复仓库:
ALTER WAREHOUSE COMPUTE_WH Resume;
现在,按顺序运行以下查询:
USE SCHEMA SNOWFLAKE_SAMPLE_DATA.TPCH_SF100;
SELECT l_returnflag, l_linestatus,
SUM(l_quantity) AS sum_qty,
SUM(l_extendedprice) AS sum_base_price,
SUM(l_extendedprice * (l_discount)) AS sum_disc_price,
SUM(l_extendedprice * (l_discount) * (1+l_tax)) AS sum_charge,
AVG(l_quantity) AS avg_qty,
AVG(l_extendedprice) AS avg_price,
AVG(l_discount) AS avg_disc,
COUNT(*) AS count_order
FROM lineitem
WHERE l_shipdate <= dateadd(day, 90, to_date('1998-12-01'))
GROUP BY l_returnflag, l_linestatus
ORDER BY l_returnflag, l_linestatus;
单击查询ID,将显示查询ID的链接。然后单击与前面示例(元数据缓存)中相同的链接。查看查询概要,它将显示如下:
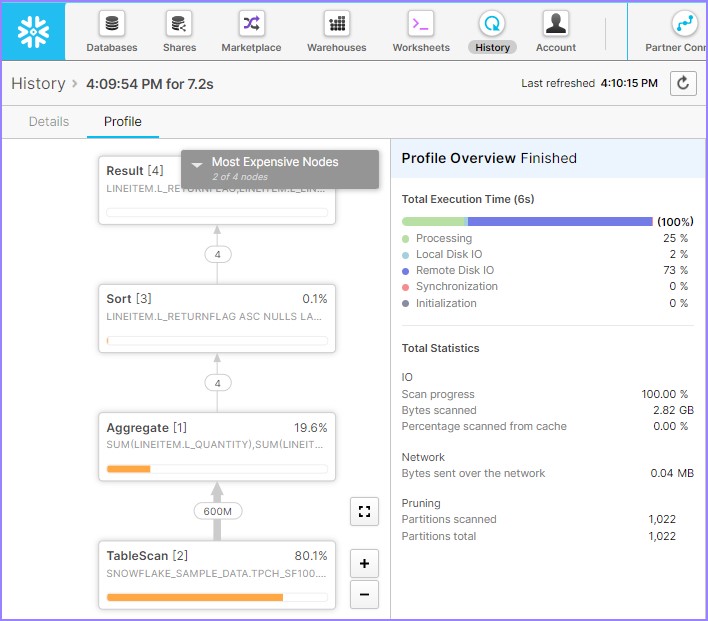
它显示扫描了80.5%的数据,因此没有涉及缓存。通过运行以下查询来挂起仓库:
ALTER WAREHOUSE COMPUTE_WH Suspend;
再次运行我们之前运行的相同查询:
USE SCHEMA SNOWFLAKE_SAMPLE_DATA.TPCH_SF100;
SELECT l_returnflag, l_linestatus,
SUM(l_quantity) AS sum_qty,
SUM(l_extendedprice) AS sum_base_price,
SUM(l_extendedprice * (l_discount)) AS sum_disc_price,
SUM(l_extendedprice * (l_discount) * (1+l_tax)) AS sum_charge,
AVG(l_quantity) AS avg_qty,
AVG(l_extendedprice) AS avg_price,
AVG(l_discount) AS avg_disc,
COUNT(*) AS count_order
FROM lineitem
WHERE l_shipdate <= dateadd(day, 90, to_date('1998-12-01'))
GROUP BY l_returnflag, l_linestatus
ORDER BY l_returnflag, l_linestatus;
单击**查询**ID,将显示查询ID的链接。然后单击与前面示例(元数据缓存)中相同的链接。查看查询概要,它将显示如下:
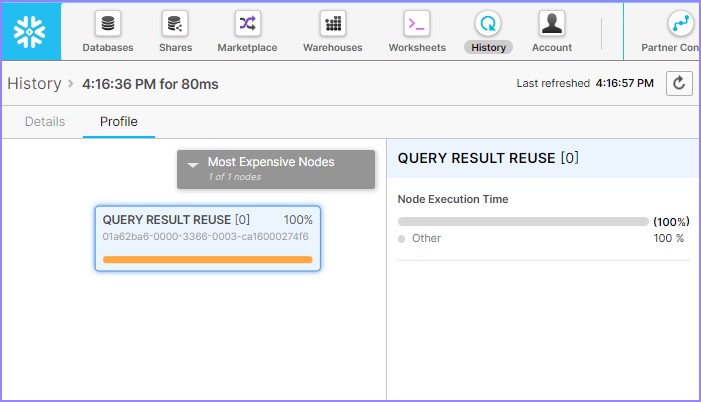
它显示了查询结果重用。这意味着它无需仓库即可成功运行查询,并且整个结果集都来自查询结果缓存。
数据缓存
数据缓存发生在存储层。它缓存来自查询的存储文件头和列数据。它存储所有查询的数据,但并非完全作为查询结果。它将这些数据存储到虚拟仓库的SSD中。当运行类似的查询时,Snowflake会尽可能多地使用数据缓存。用户无法禁用数据缓存。数据缓存适用于在同一虚拟仓库上运行的所有查询。这意味着数据缓存不像元数据和查询结果缓存那样,无需虚拟仓库即可工作。
当查询运行时,它的头和列数据将存储在虚拟仓库的SSD上。虚拟仓库首先读取本地可用数据(虚拟仓库的SSD),然后从远程云存储(实际的Snowflake存储系统)读取剩余数据。当缓存存储空间已满时,数据将根据最少使用原则被丢弃。
让我们运行一个查询来了解查询结果缓存的工作原理,用户可以进行验证。
登录Snowflake并转到**工作表**。通过运行以下查询来恢复仓库:
ALTER WAREHOUSE COMPUTE_WH Resume;
使用以下SQL禁用Query_Result缓存:
ALTER SESSION SET USE_CACHED_RESULT = FALSE;
运行以下查询:
SELECT l_returnflag, l_linestatus,
SUM(l_quantity) AS sum_qty,
SUM(l_extendedprice) AS sum_base_price,
SUM(l_extendedprice * (l_discount)) AS sum_disc_price, SUM(l_extendedprice *
(l_discount) * (1+l_tax))
AS sum_charge, AVG(l_quantity) AS avg_qty,
AVG(l_extendedprice) AS avg_price,
AVG(l_discount) AS avg_disc,
COUNT(*) as count_order
FROM lineitem
WHERE l_shipdate <= dateadd(day, 90, to_date('1998-12-01'))
GROUP BY l_returnflag, l_linestatus
ORDER BY l_returnflag, l_linestatus;
单击**查询**ID,将显示查询ID的链接。然后单击与前面示例(元数据缓存)中相同的链接。查看查询概要,它将显示如下:
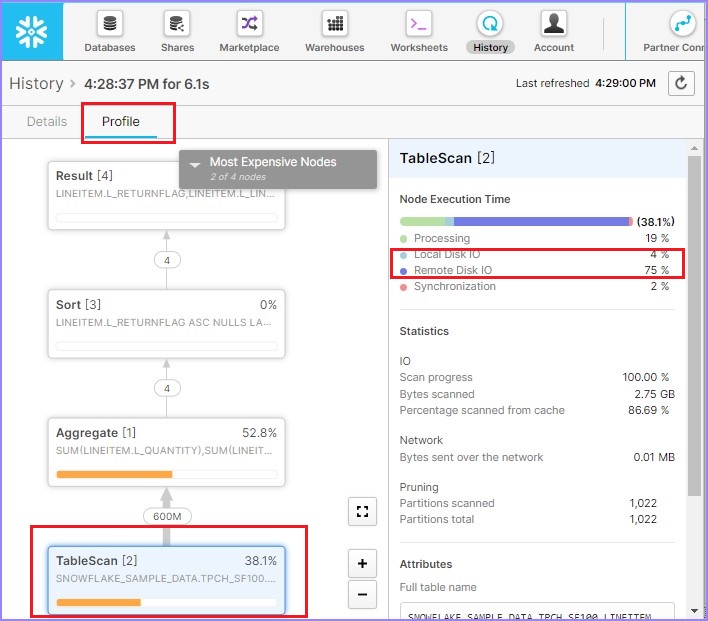
根据查询概要,扫描了88.6%的数据。如果您注意到右侧,本地磁盘IO = 2%,而远程磁盘IO = 80%。这意味着几乎没有或根本没有使用数据缓存。现在,运行以下查询。WHERE子句略有不同:
SELECT l_returnflag, l_linestatus,
SUM(l_quantity) AS sum_qty,
SUM(l_extendedprice) AS sum_base_price,
SUM(l_extendedprice * (l_discount)) AS sum_disc_price, SUM(l_extendedprice *
(l_discount) * (1+l_tax))
AS sum_charge,
AVG(l_quantity) AS avg_qty,
AVG(l_extendedprice) AS avg_price,
AVG(l_discount) AS avg_disc,
COUNT(*) as count_order
FROM lineitem
WHERE l_shipdate <= dateadd(day, 90, to_date('1998-12-01'))
and l_extendedprice <= 20000
GROUP BY l_returnflag, l_linestatus
ORDER BY l_returnflag, l_linestatus;
单击**查询**ID,将显示查询ID的链接。然后单击与前面示例(元数据缓存)中相同的链接。查看查询概要,它将显示如下:
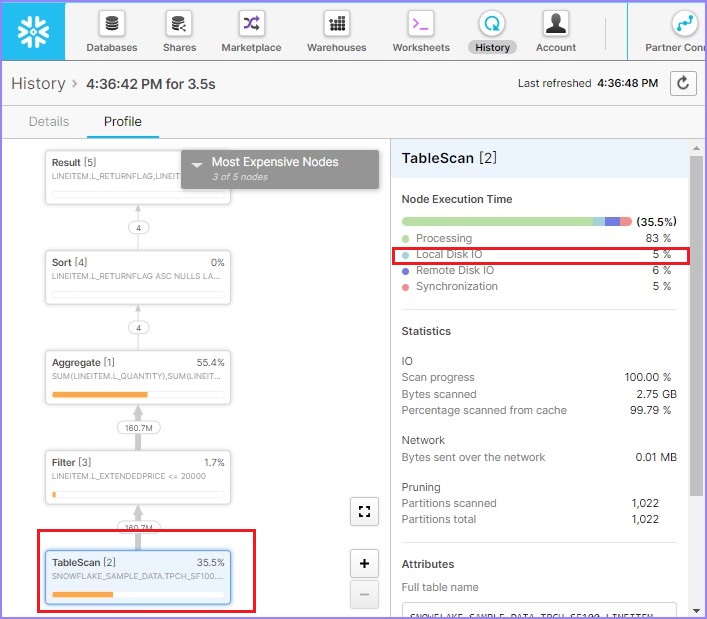
根据查询概要,扫描了58.9%的数据,这比第一次要低得多。如果您注意到右侧,本地磁盘IO增加到4%,而远程磁盘IO = 0%。这意味着几乎没有或根本没有使用远程数据。
将数据从 Snowflake 卸载到本地
在数据库中,创建模式,它是表的逻辑分组。表包含列。表和列是数据库中低级别但最重要的对象。现在,表和列最重要的功能是存储数据。
本章将讨论如何将Snowflake表和列中的数据卸载到本地文件。Snowflake为用户提供了两种将数据卸载到本地文件的方法:使用用户界面和使用SQL查询。
使用Snowflake的UI将数据卸载到本地文件
在本节中,我们将讨论将数据作为csv或tsv卸载到本地文件应遵循的步骤。UI有一个限制,用户不能直接将所有数据保存到本地目录。
要从UI保存数据,用户需要先运行查询,然后才能将结果保存为“.csv”或“.tsv”文件。但是,使用SQL和SNOWSQL,可以将数据直接保存到本地驱动器,而无需运行查询。稍后的过程将在下一节中讨论。
让我们讨论用户界面方法。
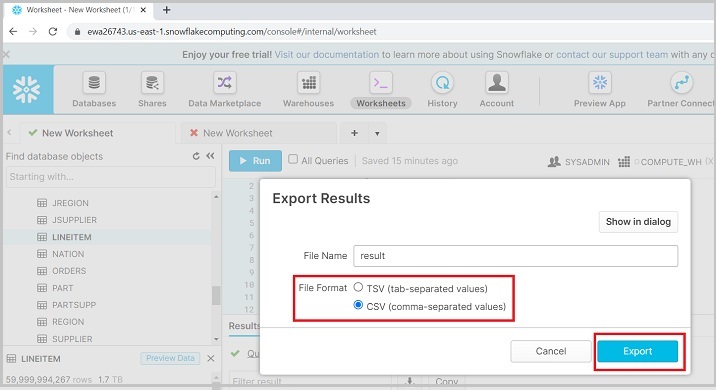
登录Snowflake。运行基于需要保存到本地目录的数据的查询。查询成功运行后,单击如下屏幕截图所示的下载图标:
它会弹出一个对话框,如下面的屏幕截图所示,并要求选择**文件格式**为CSV或TSV。选择后,单击**导出**。它将下载结果文件。
下面的屏幕截图显示了数据卸载功能:
使用SQL卸载表和列中的数据
要将数据卸载到本地文件,首先选择需要卸载数据的列。接下来,运行以下查询:
USE SCHEMA "TEST_DB"."TEST_SCHEMA_1";
COPY INTO @%TEST_TABLE FROM (SELECT * FROM TEST_TABLE) FILE_FORMAT=(FORMAT_NAME=TEST_DB.TEST_SCHEMA_1.CSV);
注意,@%用于Snowflake创建的默认阶段。如果您需要使用您自己的内部阶段,只需传入@<stage_name>。
查询成功执行后,表示数据已复制到内部阶段。Snowflake默认情况下为所有表创建一个表阶段,例如@%<table_name>。
现在运行以下查询以确认文件是否存储在内部阶段:
LIST @%TEST_TABLE;
它显示存储在内部阶段的所有文件,即使是加载数据时不成功的文件。
现在,要将文件导入本地目录,我们需要使用**snowsql**。确保已将其下载到系统中。如果尚未下载,请按照以下屏幕截图中的步骤下载:
单击**CLI客户端(snowsql)**,然后单击Snowflake存储库,如下面的屏幕截图所示:
用户可以转到bootstrap→1.2→windows_x86_64→单击下载最新版本。下面的屏幕截图显示了上述步骤:
现在,安装下载的插件。安装后,在您的系统中打开 CMD。运行以下命令以检查连接:
"snowsql -a <account_name> -u <username>"
它将询问密码。输入您的Snowflake密码。输入密码并按ENTER键。用户将看到成功连接的消息。现在命令行显示为:
"<username>#<warehouse_name>@<db_name>.<schema_name>"
现在使用以下命令将文件上传到 Snowflake 的暂存区:
"GET @%TEST_TABLE file://C:/Users/*******/Documents/"
注意,@%用于Snowflake创建的默认阶段,如果用户想使用他们自己的内部阶段,只需传入@<stage_name>。数据将卸载到本地目录。
Snowflake - 外部数据加载
Snowflake也支持客户端的云存储。这意味着客户端可以在其云中拥有数据,并且可以通过引用位置将其加载到Snowflake中。目前,Snowflake支持3个云:AWS S3、Microsoft Azure和Google Cloud Platform位置。这些被称为外部阶段。但是,Snowflake提供Snowflake管理的阶段,这些阶段被称为**内部阶段**。
**外部阶段**是客户端位置,而内部阶段用于用户在其本地系统目录中工作时。
要从外部云上传数据,需要进行以下设置:
Snowflake中现有的数据库和模式,数据必须加载到其中。
指向AWS S3存储桶的外部阶段设置。
文件格式,它定义加载到AWS S3中的文件结构。
本章将讨论如何设置这些要求并将数据加载到表中。
我们已经创建了一个名为TEST_DB的数据库、名为TEST_SCHEMA_1的模式和名为TEST_TABLE的表。如果这些不存在,请按照前面章节中的说明创建它们。
外部阶段可以通过Snowflake的用户界面以及使用SQL进行设置。
使用UI
要创建外部阶段,请按照以下说明操作:
登录Snowflake。单击顶部功能区上的**数据库**。在数据库视图中,单击名为TEST_DB的数据库名称。现在,单击**阶段**选项卡。现在,单击顶部显示的**创建**按钮,如下面的屏幕截图所示:
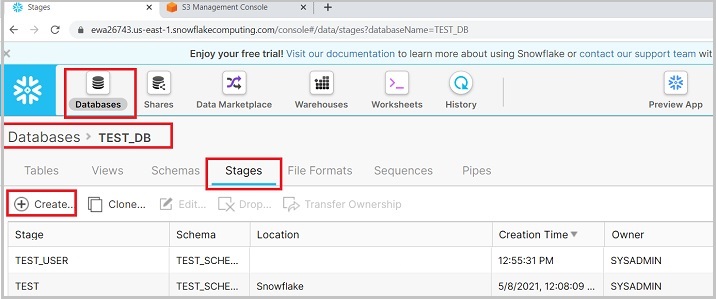
会弹出创建阶段(Create Stage)对话框,在列表中选择amazon|s3,然后点击“下一步”按钮,如下所示:

接下来进入下一个屏幕,用户需要在此输入以下详细信息:
名称(Name)- 用户定义的外部阶段名称。此名称将用于将数据从阶段复制到表。
模式名称(Schema Name)- 选择表所在的模式名称以加载数据。
URL- 提供来自 Amazon 的 S3 URL。它基于存储桶名称和密钥是唯一的。
AWS 密钥 ID(AWS Key ID)- 请输入您的 AWS 密钥 ID。
AWS 密钥(AWS Secret Key)- 输入您的密钥以连接到您的 AWS。
加密主密钥(Encryption Master Key)- 如有,请提供加密密钥。
提供这些详细信息后,单击完成(Finish)按钮。以下屏幕截图描述了上述步骤:
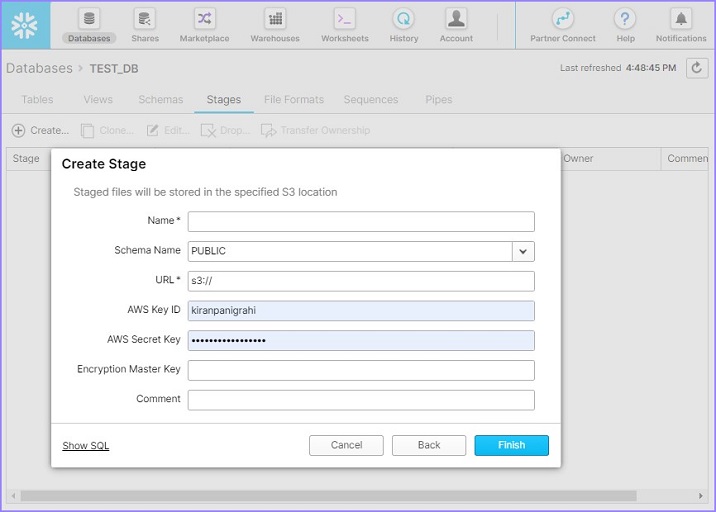
用户可以在“视图”面板中看到新创建的外部阶段。
使用 SQL
使用 SQL 创建外部阶段非常简单。只需运行以下查询并提供所有详细信息(例如名称、AWS 密钥、密码、主密钥),它将创建阶段。
CREATE STAGE "TEST_DB"."TEST_SCHEMA_1".Ext_S3_stage URL = 's3://***/***** CREDENTIALS = (AWS_KEY_ID = '*********' AWS_SECRET_KEY = '********') ENCRYPTION = (MASTER_KEY = '******');
文件格式定义上传到 S3 的文件的结构。如果文件结构与表结构不匹配,则加载将失败。
使用UI
要创建文件格式,请按照以下说明操作。
登录 Snowflake。单击顶部功能区中的数据库(Databases)。在数据库视图中,单击数据库名称 TEST_DB。现在,单击文件格式(File Format)选项卡。然后,单击顶部的创建(Create)按钮。这将弹出创建文件格式(Create File Format)对话框。输入以下详细信息:
名称(Name)- 文件格式的名称
模式名称 - 创建的文件格式只能在给定的模式中使用。
格式类型(Format Type)- 文件格式的名称
列分隔符(Column separator)- 如果 csv 文件已分隔,请提供文件分隔符
行分隔符(Row separator)- 如何识别新行
要跳过的标题行(Header lines to skip)- 如果提供标题,则为 1,否则为 0
其他内容可以保持不变。输入详细信息后,单击完成(Finish)按钮。以下屏幕截图显示了上述详细信息:
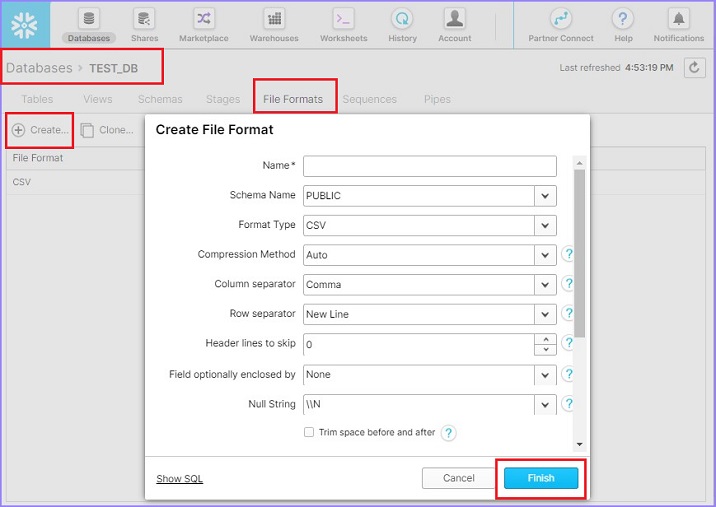
用户将能够在视图面板中看到已创建的文件格式。
使用 SQL
使用 SQL 创建文件格式非常简单。只需运行以下查询并提供所有详细信息,如下所示。
CREATE FILE FORMAT "TEST_DB"."TEST_SCHEMA_1".ext_csv TYPE = 'CSV' COMPRESSION = 'AUTO'
FIELD_DELIMITER = ',' RECORD_DELIMITER = '\n' SKIP_HEADER = 0 FIELD_OPTIONALLY_ENCLOSED_BY =
'NONE' TRIM_SPACE = FALSE ERROR_ON_COLUMN_COUNT_MISMATCH = TRUE ESCAPE = 'NONE'
ESCAPE_UNENCLOSED_FIELD = '\134' DATE_FORMAT = 'AUTO' TIMESTAMP_FORMAT = 'AUTO' NULL_IF = ('\\N');
从 S3 加载数据
本章将讨论如何设置所有必需的参数(如阶段、文件格式、数据库)以从 S3 加载数据。
用户可以运行以下查询以查看给定阶段中存在的所有文件:
LS @<external_stage_name>
现在,要加载数据,请运行以下查询:
语法
COPY INTO @<database_name>.<schema_name>.<table_name>
FROM @<database_name>.<schema_name>.<ext_stage_name>
FILES=('<file_name>')
FILE_FORMAT=(FORMAT_NAME=<database_name>.<schema_name>.<file_format_name>);
示例
COPY INTO @test_db.test_schema_1.TEST_USER
FROM @test_db.test_schema_1.EXT_STAGE
FILES=('data.csv')
FILE_FORMAT=(FORMAT_NAME=test_db.test_schema_1.CSV);
运行上述查询后,用户可以通过运行以下简单查询来验证表中的数据:
Select count(*) from Test_Table
如果用户想要上传外部阶段中存在的所有文件,则无需传递“FILES=(<file_name>)”。
Snowflake - 外部数据卸载
Snowflake 也支持客户端的云存储。这意味着客户端可以从 Snowflake 将数据导出到其云中。目前,Snowflake 支持 3 个云 - AWS S3、Microsoft Azure 和 Google Cloud Platform 位置。这些被称为外部阶段。但是,Snowflake 提供 Snowflake 托管阶段,这些阶段被称为内部阶段。
外部阶段是客户端位置,而内部阶段在用户使用本地系统目录时使用。
要将数据卸载到外部云,需要进行以下设置:
Snowflake 中现有的数据库和模式,数据必须卸载到 AWS S3。
指向AWS S3存储桶的外部阶段设置。
文件格式定义加载到 AWS S3 的文件的结构。
本章将讨论如何设置这些要求并将数据从表卸载到 S3。
我们已经创建了一个名为 TEST_DB 的数据库、名为 TEST_SCHEMA_1 的模式和名为 TEST_TABLE 的表。如果这些不存在,请按照前面章节中的说明创建它们。
外部阶段可以通过Snowflake的用户界面以及使用SQL进行设置。
使用UI
要创建外部阶段,请按照以下说明操作:
登录 Snowflake。单击顶部功能区中的数据库(Databases)。在数据库视图中,单击数据库名称 TEST_DB。接下来,单击阶段(Stages)选项卡,然后单击顶部的创建(Create)按钮,如下面的屏幕截图所示:
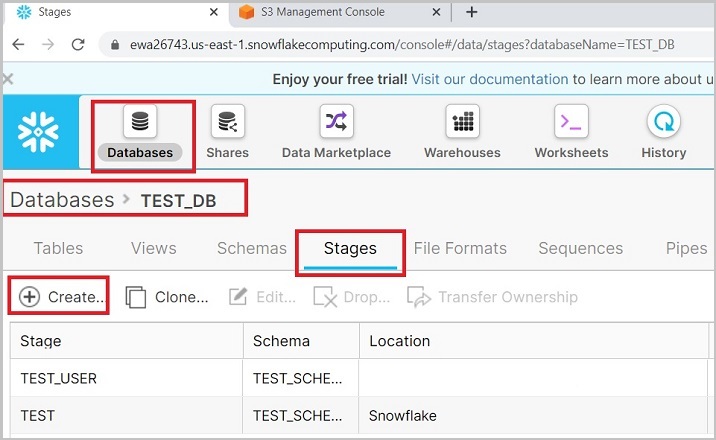
会弹出创建阶段(Create Stage)对话框,在列表中选择 amazon|s3,然后单击“下一步”,如下所示:

接下来进入下一个屏幕,用户需要在此输入以下详细信息:
名称(Name)- 用户定义的外部阶段名称。此名称将用于将数据从阶段复制到表。
模式名称(Schema Name)- 选择表所在的模式名称以加载数据。
URL- 提供来自 Amazon 的 S3 URL。它基于存储桶名称和密钥是唯一的。
AWS 密钥 ID(AWS Key ID)- 请输入您的 AWS 密钥 ID。
AWS 密钥(AWS Secret Key)- 输入您的密钥以连接到您的 AWS。
加密主密钥(Encryption Master Key)- 如有,请提供加密密钥。
提供详细信息后,单击完成(Finish)按钮。以下屏幕截图描述了上述步骤:
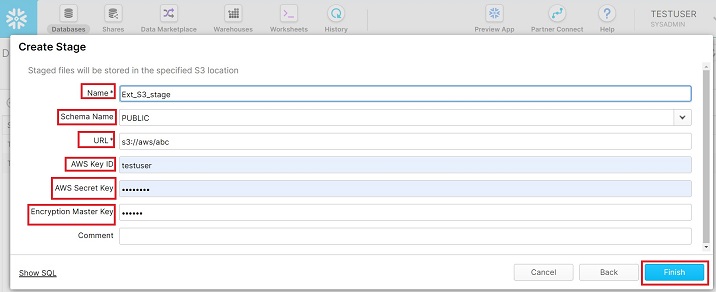
用户可以在“视图”面板中看到新创建的外部阶段。
使用 SQL
使用 SQL 创建外部阶段非常简单。只需运行以下查询并提供所有详细信息(例如名称、AWS 密钥、密码、主密钥),它将创建阶段。
CREATE STAGE "TEST_DB"."TEST_SCHEMA_1".Ext_S3_stage URL = 's3://***/***** CREDENTIALS = (AWS_KEY_ID = '*********' AWS_SECRET_KEY = '********') ENCRYPTION = (MASTER_KEY = '******');
文件格式定义上传到 S3 的文件的结构。如果文件结构与表结构不匹配,则加载将失败。
使用UI
要创建文件格式,请按照以下说明操作。
登录 Snowflake 并单击顶部功能区中的数据库(Databases)。在数据库视图中,单击数据库名称 TEST_DB。
接下来,单击文件格式(File Format)选项卡,然后单击顶部的“创建”按钮。将弹出创建文件格式(Create File Format)对话框。输入以下详细信息:
名称 - 文件格式的名称。
模式名称 - 创建的文件格式只能在给定的模式中使用。
格式类型 - 文件格式的名称。
列分隔符(Column separator)- 如果 csv 文件已分隔,请提供文件分隔符。
行分隔符 - 如何识别新行。
要跳过的标题行(Header lines to skip)- 如果提供标题,则为 1,否则为 0。
其他内容可以保持不变。输入这些详细信息后,单击“完成”按钮。
以下屏幕截图显示了上述详细信息:
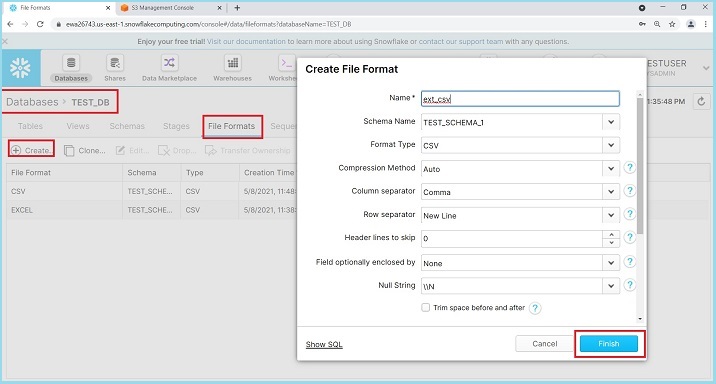
用户将能够在视图面板中看到已创建的文件格式。
使用 SQL
使用 SQL 创建文件格式非常简单。只需运行以下查询并提供所有必要的详细信息,如下所示。
CREATE FILE FORMAT "TEST_DB"."TEST_SCHEMA_1".ext_csv TYPE = 'CSV' COMPRESSION = 'AUTO'
FIELD_DELIMITER = ',' RECORD_DELIMITER = '\n' SKIP_HEADER = 0 FIELD_OPTIONALLY_ENCLOSED_BY =
'NONE' TRIM_SPACE = FALSE ERROR_ON_COLUMN_COUNT_MISMATCH = TRUE ESCAPE = 'NONE'
ESCAPE_UNENCLOSED_FIELD = '\134' DATE_FORMAT = 'AUTO' TIMESTAMP_FORMAT = 'AUTO' NULL_IF = ('\\N');
将数据卸载到 S3
本章讨论了如何设置所有必需的参数(如阶段、文件格式、数据库)以将数据卸载到 S3。
现在,要卸载数据,请运行以下查询:
语法
COPY INTO @<database_name>.<schema_name>.<external_stage_name> FROM (SELECT * FROM <table_name>) FILE_FORMAT=(FORMAT_NAME=<database_name>.<schema_name>.<file_format_name>);
示例
COPY INTO @test_db.test_schema_1.EXT_Stage FROM (SELECT * FROM TEST_TABLE) FILE_FORMAT=(FORMAT_NAME=test_db.test_schema_1.CSV);