
 数据结构
数据结构 网络
网络 关系数据库管理系统
关系数据库管理系统 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 编程
C 编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP数据结构中的自适应合并排序
自适应合并排序
自适应合并排序执行的是已排序子列表的合并,就像合并排序一样。但是,初始子列表的大小取决于列表元素之间是否存在顺序,而不是具有大小为 1 的子列表。例如,考虑图中的列表。
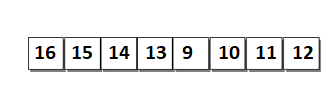
它包含 2 个已排序的子列表。
- 子列表 1 包含元素 16、15、14、13。
- 子列表 2 包含元素 9、10、11、12。

子列表 1 已排序,但顺序相反。因此,子列表 1 反转,如图所示。

一旦找到子列表,合并过程就开始了。自适应合并排序开始合并子列表。自适应合并排序只需要一步合并,因为只有 2 个子列表。合并的结果如图所示。

设计理念
- 首先找到已经按要求或反向排序的子列表
- 如果存在任何元素顺序相反的子列表,则通过交换第一个元素和最后一个元素、第二个元素和倒数第二个元素等来反转子列表。
- 继续合并子列表以生成新的子列表,直到只剩下 1 个子列表。
自适应合并排序分析
自适应合并排序不是从大小为 1 的子列表开始,而是查找已经按要求或反向排序的子列表。最初找到的子列表的大小至少为 2,最大为 m(m 为元素数量)。
但是,如果子列表包含反向顺序的元素,则在开始合并操作之前会反转列表。列表的反转需要 (m/2) 次交换操作。
最佳情况
如果列表已经按顺序或反向顺序排序,则自适应合并排序将只有一个列表,并且不需要任何合并操作。但是,查找列表是否已排序需要 O(m) 次比较操作,如果列表按反向顺序排序,则需要 (m/2) 次交换操作。这使得自适应合并排序即使在列表按反向顺序排序时也能适应。
因此,最佳情况下的时间复杂度计算如下:
T(m) = (m-1)+(m/2) T(m) = (2m-2+m)/2 T(m) = O(m).
但是,与合并排序相比,自适应合并排序实现了 O(m) 的额外空间。
最坏情况
自适应合并排序将找到已按要求或反向排序的子列表。但是,在最坏情况下,没有部分或完全排序的元素。因此,最初找到的子列表的大小将为 2。一旦找到子列表,合并过程就开始了。
- 大小为 2 的子列表的合并会产生大小为 4 的已排序子列表。
- 大小为 4 的子列表的合并会产生大小为 8 的已排序子列表。
- 合并过程持续进行,直到 2k < m。其中 k 是第 k 次合并步骤。
由于自适应合并排序的最坏情况下的合并步骤与合并排序相同。因此,自适应合并排序的最坏情况下的时间复杂度与合并排序类似:
T(m) = O(m log m).

更新于: 2020年1月7日
675 次浏览

广告