- ArangoDB 教程
- ArangoDB - 首页
- 多模型首选数据库
- ArangoDB – 优势
- 基本概念和术语
- ArangoDB – 系统要求
- ArangoDB – 命令行
- ArangoDB - Web界面
- ArangoDB - 示例案例
- 数据模型和建模
- ArangoDB - 数据库方法
- ArangoDB - CRUD操作
- 使用Web界面进行CRUD操作
- 使用AQL查询数据
- ArangoDB - AQL 示例查询
- ArangoDB – 如何部署
- ArangoDB 有用资源
- ArangoDB - 快速指南
- ArangoDB - 有用资源
- ArangoDB - 讨论
ArangoDB - AQL 示例查询
本章我们将考虑一些在演员和电影数据库上的AQL示例查询。这些查询基于图。
问题
给定一个演员集合和一个电影集合,以及一个actIn边集合(带有一个year属性)来连接顶点,如下所示:
[演员] <- act in -> [电影]
我们如何获取:
- 所有在“movie1”或“movie2”中演出的演员?
- 所有同时在“movie1”和“movie2”中演出的演员?
- “actor1”和“actor2”之间所有共同出演的电影?
- 所有出演3部或以上电影的演员?
- 所有只有6名演员出演的电影?
- 按电影计算的演员数量?
- 按演员计算的电影数量?
- 演员在2005年到2010年间出演的电影数量?
解决方案
在解决并获得上述查询答案的过程中,我们将使用Arangosh创建数据集并在其上运行查询。所有AQL查询都是字符串,可以简单地复制到您喜欢的驱动程序中,而不是Arangosh。
让我们从在Arangosh中创建一个测试数据集开始。首先,下载此文件:
# wget -O dataset.js https://drive.google.com/file/d/0B4WLtBDZu_QWMWZYZ3pYMEdqajA/view?usp=sharing
输出
... HTTP request sent, awaiting response... 200 OK Length: unspecified [text/html] Saving to: ‘dataset.js’ dataset.js [ <=> ] 115.14K --.-KB/s in 0.01s 2017-09-17 14:19:12 (11.1 MB/s) - ‘dataset.js’ saved [117907]
您可以在上面的输出中看到,我们已经下载了一个JavaScript文件dataset.js。此文件包含在数据库中创建数据集的Arangosh命令。我们不会逐一复制粘贴命令,而是将使用Arangosh上的--javascript.execute选项非交互式地执行多个命令。这可是个救命命令!
现在在shell上执行以下命令:
$ arangosh --javascript.execute dataset.js
出现提示时提供密码,如上面的屏幕截图所示。现在我们已经保存了数据,我们将构造AQL查询来回答本章开头提出的具体问题。
第一个问题
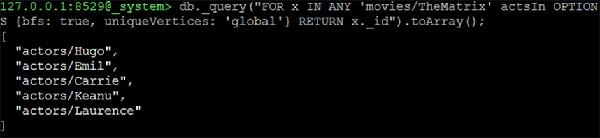
让我们来看第一个问题:所有在“movie1”或“movie2”中演出的演员。假设,我们想找到所有在“The Matrix”或“The Devil's Advocate”中演出的演员的姓名:
我们将一次处理一部电影来获取演员的姓名:
127.0.0.1:8529@_system> db._query("FOR x IN ANY 'movies/TheMatrix' actsIn
OPTIONS {bfs: true, uniqueVertices: 'global'} RETURN x._id").toArray();
输出
我们将收到以下输出:
[ "actors/Hugo", "actors/Emil", "actors/Carrie", "actors/Keanu", "actors/Laurence" ]
现在我们继续形成两个NEIGHBORS查询的UNION_DISTINCT,这将是解决方案:
127.0.0.1:8529@_system> db._query("FOR x IN UNION_DISTINCT ((FOR y IN ANY
'movies/TheMatrix' actsIn OPTIONS {bfs: true, uniqueVertices: 'global'} RETURN
y._id), (FOR y IN ANY 'movies/TheDevilsAdvocate' actsIn OPTIONS {bfs: true,
uniqueVertices: 'global'} RETURN y._id)) RETURN x").toArray();
输出
[ "actors/Charlize", "actors/Al", "actors/Laurence", "actors/Keanu", "actors/Carrie", "actors/Emil", "actors/Hugo" ]

第二个问题
现在让我们考虑第二个问题:所有同时在“movie1”和“movie2”中演出的演员。这与上面的问题几乎相同。但是这次我们对UNION不感兴趣,而对INTERSECTION感兴趣:
127.0.0.1:8529@_system> db._query("FOR x IN INTERSECTION ((FOR y IN ANY
'movies/TheMatrix' actsIn OPTIONS {bfs: true, uniqueVertices: 'global'} RETURN
y._id), (FOR y IN ANY 'movies/TheDevilsAdvocate' actsIn OPTIONS {bfs: true,
uniqueVertices: 'global'} RETURN y._id)) RETURN x").toArray();
输出
我们将收到以下输出:
[ "actors/Keanu" ]

第三个问题
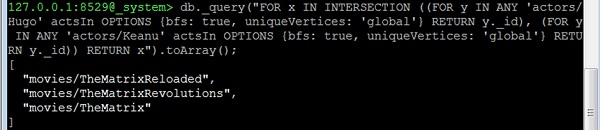
现在让我们考虑第三个问题:“actor1”和“actor2”之间所有共同出演的电影。这实际上与关于movie1和movie2中共同演员的问题相同。我们只需要更改起始顶点。例如,让我们找到雨果·维文(“Hugo”)和基努·里维斯共同出演的所有电影:
127.0.0.1:8529@_system> db._query(
"FOR x IN INTERSECTION (
(
FOR y IN ANY 'actors/Hugo' actsIn OPTIONS
{bfs: true, uniqueVertices: 'global'}
RETURN y._id
),
(
FOR y IN ANY 'actors/Keanu' actsIn OPTIONS
{bfs: true, uniqueVertices:'global'} RETURN y._id
)
)
RETURN x").toArray();
输出
我们将收到以下输出:
[ "movies/TheMatrixReloaded", "movies/TheMatrixRevolutions", "movies/TheMatrix" ]
第四个问题
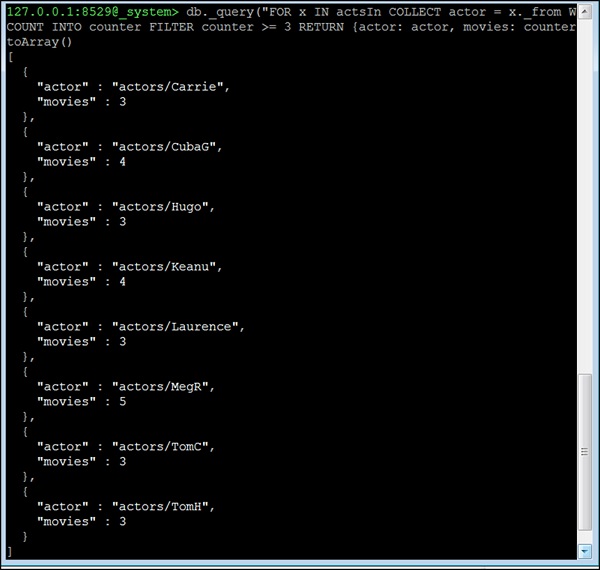
现在让我们考虑第四个问题。所有出演3部或以上电影的演员。这个问题不同;我们不能在这里使用neighbors函数。相反,我们将使用AQL的edge-index和COLLECT语句进行分组。基本思想是按其startVertex(在这个数据集中始终是演员)对所有边进行分组。然后,我们将删除所有出演少于3部电影的演员,因为这里我们包含了演员出演的电影数量:
127.0.0.1:8529@_system> db._query("FOR x IN actsIn COLLECT actor = x._from WITH
COUNT INTO counter FILTER counter >= 3 RETURN {actor: actor, movies:
counter}"). toArray()
输出
[
{
"actor" : "actors/Carrie",
"movies" : 3
},
{
"actor" : "actors/CubaG",
"movies" : 4
},
{
"actor" : "actors/Hugo",
"movies" : 3
},
{
"actor" : "actors/Keanu",
"movies" : 4
},
{
"actor" : "actors/Laurence",
"movies" : 3
},
{
"actor" : "actors/MegR",
"movies" : 5
},
{
"actor" : "actors/TomC",
"movies" : 3
},
{
"actor" : "actors/TomH",
"movies" : 3
}
]
对于其余的问题,我们将讨论查询的形成,并且只提供查询。读者应该在Arangosh终端上自己运行查询。
第五个问题
现在让我们考虑第五个问题:所有只有6名演员出演的电影。与之前的查询相同的思路,但带有等式过滤器。但是,现在我们需要电影而不是演员,所以我们返回_to属性:
db._query("FOR x IN actsIn COLLECT movie = x._to WITH COUNT INTO counter FILTER
counter == 6 RETURN movie").toArray()
按电影计算的演员数量?
我们记得在我们的数据集中,边上的_to对应于电影,所以我们计算相同的_to出现的次数。这就是演员的数量。查询与之前的查询几乎相同,但COLLECT之后没有FILTER:
db._query("FOR x IN actsIn COLLECT movie = x._to WITH COUNT INTO counter RETURN
{movie: movie, actors: counter}").toArray()
第六个问题
现在让我们考虑第六个问题:按演员计算的电影数量。
我们找到上述查询解决方案的方法也将帮助您找到此查询的解决方案。
db._query("FOR x IN actsIn COLLECT actor = x._from WITH COUNT INTO counter
RETURN {actor: actor, movies: counter}").toArray()