- ArangoDB 教程
- ArangoDB - 首页
- 一款多模型优先数据库
- ArangoDB – 优势
- 基本概念和术语
- ArangoDB – 系统要求
- ArangoDB – 命令行
- ArangoDB - Web 界面
- ArangoDB - 案例场景
- 数据模型和建模
- ArangoDB - 数据库方法
- ArangoDB - CRUD 操作
- 使用 Web 界面进行 CRUD 操作
- 使用 AQL 查询数据
- ArangoDB - AQL 示例查询
- ArangoDB – 如何部署
- ArangoDB 有用资源
- ArangoDB 快速指南
- ArangoDB - 有用资源
- ArangoDB - 讨论
ArangoDB 快速指南
ArangoDB - 一款多模型优先数据库
ArangoDB 被其开发者誉为原生多模型数据库。这与其他 NoSQL 数据库不同。在这个数据库中,数据可以存储为文档、键值对或图。并且可以使用单一的声明式查询语言访问所有或任何数据。此外,不同的模型可以在单个查询中组合。而且,由于其多模型风格,可以创建精简的应用程序,这些应用程序可以使用所有或任何三种数据模型进行水平扩展。
分层与原生多模型数据库
在本节中,我们将重点介绍原生多模型数据库和分层多模型数据库之间的关键区别。
许多数据库厂商称他们的产品为“多模型”,但是向键值或文档存储添加图层并不算作原生多模型。
使用 ArangoDB,可以使用相同的核心和相同的查询语言,将不同的数据模型和特性组合到单个查询中,正如我们在上一节中已经提到的那样。在 ArangoDB 中,数据模型之间没有“切换”,并且没有将数据从 A 移动到 B 来执行查询。与“分层”方法相比,这带来了 ArangoDB 的性能优势。
对多模型数据库的需求
解释 [Fowler 的] 基本思想使我们认识到,对持久层(它是更大软件架构的一部分)的不同部分使用各种合适的数据模型的好处。
根据此,例如,可以使用关系数据库来持久化结构化的表格数据;使用文档存储来存储非结构化的、类似对象的数据;使用键值存储来存储哈希表;使用图数据库来存储高度关联的引用数据。
但是,这种方法的传统实现会导致在同一个项目中使用多个数据库。这会导致一些操作摩擦(更复杂的部署,更频繁的升级),以及数据一致性和重复性问题。
在统一三种数据模型的数据之后,下一个挑战是设计和实现一种通用的查询语言,允许数据管理员表达各种查询,例如文档查询、键值查找、图查询以及这些查询的任意组合。
通过 **图查询**,我们的意思是涉及图论考虑的查询。特别是,这些可能涉及来自边的特定连接特性。例如,**最短路径、图遍历**和**邻居**。
图是作为关系数据模型的完美选择。在许多现实世界的案例中,例如社交网络、推荐系统等,一个非常自然的数据模型是一个图。它捕获关系,并且可以在每个边和每个顶点上保存标签信息。此外,JSON 文档非常适合存储这种类型的顶点和边数据。
ArangoDB ─ 特性
ArangoDB 有各种显著的特性。我们将在下面重点介绍突出的特性:
- 多模型范式
- ACID 属性
- HTTP API
ArangoDB 支持所有流行的数据库模型。以下是 ArangoDB 支持的一些模型:
- 文档模型
- 键值模型
- 图模型
只需要一种查询语言就可以从数据库中检索数据
四个属性 **原子性、一致性、隔离性** 和 **持久性** (ACID) 描述了数据库事务的保证。ArangoDB 支持符合 ACID 的事务。
ArangoDB 允许客户端(例如浏览器)使用 HTTP API 与数据库交互,该 API 是面向资源的,并且可以使用 JavaScript 进行扩展。
ArangoDB - 优势
以下是使用 ArangoDB 的优势:
整合
作为一个原生多模型数据库,ArangoDB 消除了部署多个数据库的需要,从而减少了组件数量及其维护。因此,它降低了应用程序的技术栈复杂性。除了整合您的整体技术需求之外,这种简化还导致更低的总拥有成本和更高的灵活性。
简化的性能扩展
随着应用程序随着时间的推移而增长,ArangoDB 可以通过使用不同的数据模型独立扩展来应对不断增长的性能和存储需求。由于 ArangoDB 可以垂直和水平扩展,因此当您的性能需求下降(故意、期望的减速)时,您的后端系统可以轻松缩减规模以节省硬件和运营成本。
降低运营复杂性
多语言持久化的法令是为您承担的每一项工作采用最佳工具。某些任务需要文档数据库,而其他任务可能需要图数据库。由于使用单模型数据库,它会导致多个操作挑战。集成单模型数据库本身就是一项困难的工作。但最大的挑战是在不同的、不相关的数据库系统之间构建具有数据一致性和容错能力的大型内聚结构。这可能被证明几乎是不可能的。
原生多模型数据库可以处理多语言持久化,因为它允许轻松地拥有多语言数据,但同时在容错系统上保持数据一致性。使用 ArangoDB,我们可以为复杂的工作使用正确的数据模型。
强大的数据一致性
如果使用多个单模型数据库,数据一致性可能会成为一个问题。这些数据库并非设计为相互通信,因此需要实现某种形式的事务功能来保持不同模型之间的数据一致性。
ArangoDB 支持 ACID 事务,它使用单个后端管理不同的数据模型,在单个实例上提供强一致性,并在集群模式下操作时提供原子操作。
容错
使用许多不相关的组件构建容错系统是一项挑战。在使用集群时,这个挑战变得更加复杂。需要专业知识才能部署和维护此类系统,使用不同的技术和/或技术栈。此外,集成旨在独立运行的多个子系统会造成巨大的工程和运营成本。
作为整合的技术栈,多模型数据库提供了一个优雅的解决方案。ArangoDB 设计用于支持具有不同数据模型的现代模块化架构,也适用于集群使用。
降低总拥有成本
每种数据库技术都需要持续的维护、错误修复补丁和其他由供应商提供的代码更改。采用多模型数据库只需消除应用程序设计中的数据库技术数量,就可以显著降低相关的维护成本。
事务
在多台机器上提供事务保证是一项真正的挑战,很少有 NoSQL 数据库提供这些保证。ArangoDB 作为原生多模型数据库,强制执行事务以保证数据一致性。
基本概念和术语
在本章中,我们将讨论 ArangoDB 的基本概念和术语。了解我们正在处理的技术主题相关的基本术语非常重要。
ArangoDB 的术语如下:
- 文档
- 集合
- 集合标识符
- 集合名称
- 数据库
- 数据库名称
- 数据库组织
从数据模型的角度来看,ArangoDB 可以被认为是一个面向文档的数据库,因为文档的概念是后者的数学概念。面向文档的数据库是 NoSQL 数据库的主要类别之一。
层次结构如下:文档分组到集合中,集合存在于数据库中
标识符和名称是集合和数据库的两个属性,这一点应该很明显。
通常,存储在文档集合中的两个文档(顶点)通过存储在边集合中的文档(边)链接。这是 ArangoDB 的图数据模型。它遵循有向标记图的数学概念,只是边不仅有标签,而且是完整的文档。
熟悉了该数据库的核心术语后,我们开始理解 ArangoDB 的图数据模型。在这个模型中,存在两种类型的集合:文档集合和边集合。边集合存储文档,还包括两个特殊属性:第一个是 **_from** 属性,第二个是 **_to** 属性。这些属性用于创建图数据库中必不可少的文档之间的边(关系)。在图的上下文中,文档集合也称为顶点集合(参见任何图论书籍)。
现在让我们看看数据库有多重要。它们很重要,因为集合存在于数据库中。在一个 ArangoDB 实例中,可以存在一个或多个数据库。不同的数据库通常用于多租户设置,因为它们内部的不同数据集(集合、文档等)是彼此隔离的。默认数据库 **_system** 是特殊的,因为它不能被删除。用户在这个数据库中进行管理,他们的凭据对服务器实例的所有数据库都有效。
ArangoDB - 系统要求
在本章中,我们将讨论 ArangoDB 的系统要求。
ArangoDB 的系统要求如下:
- 安装了 Ubuntu 的 VPS 服务器
- RAM:1 GB;CPU:2.2 GHz
对于本教程中的所有命令,我们使用了 RAM 为 1GB、一个 CPU 处理能力为 2.2 GHz 的 Ubuntu 16.04 (xenial) 实例。本教程中的所有 arangosh 命令都针对 ArangoDB 3.1.27 版本进行了测试。
如何安装 ArangoDB?
在本节中,我们将了解如何安装 ArangoDB。ArangoDB 预先构建了许多操作系统和发行版。有关更多详细信息,请参阅 ArangoDB 文档。如前所述,在本教程中,我们将使用 Ubuntu 16.04x64。
第一步是下载其存储库的公共密钥:
# wget https://www.arangodb.com/repositories/arangodb31/ xUbuntu_16.04/Release.key
输出
--2017-09-03 12:13:24-- https://www.arangodb.com/repositories/arangodb31/xUbuntu_16.04/Release.key Resolving https://www.arangodb.com/ (www.arangodb.com)... 104.25.1 64.21, 104.25.165.21, 2400:cb00:2048:1::6819:a415, ... Connecting to https://www.arangodb.com/ (www.arangodb.com)|104.25. 164.21|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 3924 (3.8K) [application/pgpkeys] Saving to: ‘Release.key’ Release.key 100%[===================>] 3.83K - .-KB/s in 0.001s 2017-09-03 12:13:25 (2.61 MB/s) - ‘Release.key’ saved [39 24/3924]
重要的是,您应该看到在输出结束时保存的 **Release.key**。
让我们使用以下代码行安装保存的密钥:
# sudo apt-key add Release.key
输出
OK
运行以下命令以添加 apt 存储库并更新索引:
# sudo apt-add-repository 'deb https://www.arangodb.com/repositories/arangodb31/xUbuntu_16.04/ /' # sudo apt-get update
最后一步,我们可以安装 ArangoDB:
# sudo apt-get install arangodb3
输出
Reading package lists... Done Building dependency tree Reading state information... Done The following package was automatically installed and is no longer required: grub-pc-bin Use 'sudo apt autoremove' to remove it. The following NEW packages will be installed: arangodb3 0 upgraded, 1 newly installed, 0 to remove and 17 not upgraded. Need to get 55.6 MB of archives. After this operation, 343 MB of additional disk space will be used.
按 **Enter** 键。现在 ArangoDB 的安装过程将开始:
Get:1 https://www.arangodb.com/repositories/arangodb31/xUbuntu_16.04 arangodb3 3.1.27 [55.6 MB] Fetched 55.6 MB in 59s (942 kB/s) Preconfiguring packages ... Selecting previously unselected package arangodb3. (Reading database ... 54209 files and directories currently installed.) Preparing to unpack .../arangodb3_3.1.27_amd64.deb ... Unpacking arangodb3 (3.1.27) ... Processing triggers for systemd (229-4ubuntu19) ... Processing triggers for ureadahead (0.100.0-19) ... Processing triggers for man-db (2.7.5-1) ... Setting up arangodb3 (3.1.27) ... Database files are up-to-date.
当 ArangoDB 的安装即将完成时,将出现以下屏幕:
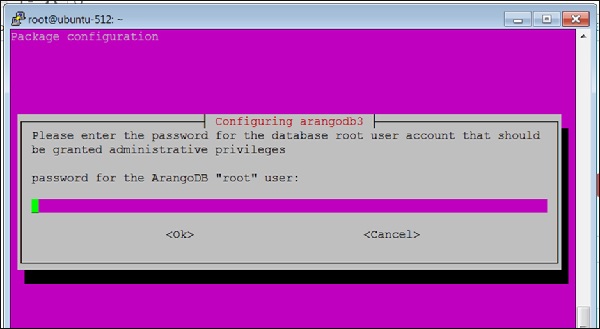
在这里,系统将要求您为 ArangoDB **root** 用户提供密码。请仔细记下它。
当出现以下对话框时,选择 **yes** 选项:
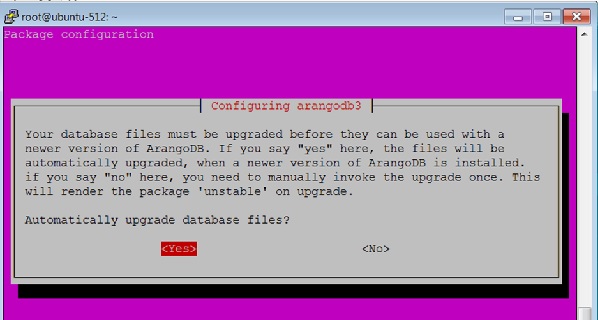
当您像上面对话框中一样单击 **Yes** 时,将出现以下对话框。在此处单击 **Yes**。
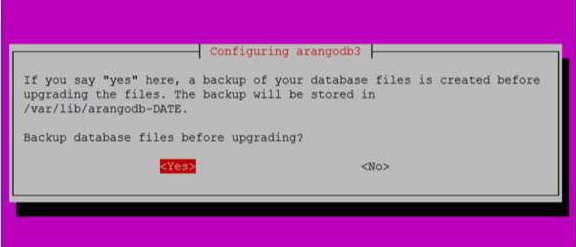
您也可以使用以下命令检查 ArangoDB 的状态:
# sudo systemctl status arangodb3
输出
arangodb3.service - LSB: arangodb
Loaded: loaded (/etc/init.d/arangodb3; bad; vendor pre set: enabled)
Active: active (running) since Mon 2017-09-04 05:42:35 UTC;
4min 46s ago
Docs: man:systemd-sysv-generator(8)
Process: 2642 ExecStart=/etc/init.d/arangodb3 start (code = exited,
status = 0/SUC
Tasks: 22
Memory: 158.6M
CPU: 3.117s
CGroup: /system.slice/arangodb3.service
├─2689 /usr/sbin/arangod --uid arangodb
--gid arangodb --pid-file /va
└─2690 /usr/sbin/arangod --uid arangodb
--gid arangodb --pid-file /va
Sep 04 05:42:33 ubuntu-512 systemd[1]: Starting LSB: arangodb...
Sep 04 05:42:33 ubuntu-512 arangodb3[2642]: * Starting arango database server a
Sep 04 05:42:35 ubuntu-512 arangodb3[2642]: {startup} starting up in daemon mode
Sep 04 05:42:35 ubuntu-512 arangodb3[2642]: changed working directory for child
Sep 04 05:42:35 ubuntu-512 arangodb3[2642]: ...done.
Sep 04 05:42:35 ubuntu-512 systemd[1]: StartedLSB: arang odb.
Sep 04 05:46:59 ubuntu-512 systemd[1]: Started LSB: arangodb. lines 1-19/19 (END)
ArangoDB 现在可以使用了。
要在终端中调用 arangosh 终端,请在终端中输入以下命令:
# arangosh
输出
Please specify a password:
输入安装时创建的root密码:
_ __ _ _ __ __ _ _ __ __ _ ___ | | / | '__/ _ | ’ \ / ` |/ _ / | ’ | (| | | | (| | | | | (| | () _ \ | | | _,|| _,|| ||_, |_/|/| || |__/
arangosh (ArangoDB 3.1.27 [linux] 64bit, using VPack 0.1.30, ICU 54.1, V8 5.0.71.39, OpenSSL 1.0.2g 1 Mar 2016) Copyright (c) ArangoDB GmbH Pretty printing values. Connected to ArangoDB 'http+tcp://127.0.0.1:8529' version: 3.1.27 [server], database: '_system', username: 'root' Please note that a new minor version '3.2.2' is available Type 'tutorial' for a tutorial or 'help' to see common examples 127.0.0.1:8529@_system> exit

要注销 ArangoDB,请输入以下命令:
127.0.0.1:8529@_system> exit
输出
Uf wiederluege! Na shledanou! Auf Wiedersehen! Bye Bye! Adiau! ¡Hasta luego! Εις το επανιδείν! להתראות ! Arrivederci! Tot ziens! Adjö! Au revoir! さようなら До свидания! Até Breve! !خداحافظ
ArangoDB - 命令行
本章将讨论 Arangosh 如何作为 ArangoDB 的命令行工作。我们将首先学习如何添加数据库用户。
注意 - 请记住,数字键盘可能在 Arangosh 上不起作用。
让我们假设用户名为“harry”,密码为“hpwdb”。
127.0.0.1:8529@_system> require("org/arangodb/users").save("harry", "hpwdb");
输出
{
"user" : "harry",
"active" : true,
"extra" : {},
"changePassword" : false,
"code" : 201
}
ArangoDB - Web 界面
本章,我们将学习如何启用/禁用身份验证,以及如何将 ArangoDB 绑定到公共网络接口。
# arangosh --server.endpoint tcp://127.0.0.1:8529 --server.database "_system"
它将提示您输入之前保存的密码:
Please specify a password:
使用您在配置期间为 root 创建的密码。
您也可以使用 curl 检查您是否确实正在为需要身份验证的请求获取 HTTP 401(未授权)服务器响应:
# curl --dump - http://127.0.0.1:8529/_api/version
输出
HTTP/1.1 401 Unauthorized X-Content-Type-Options: nosniff Www-Authenticate: Bearer token_type = "JWT", realm = "ArangoDB" Server: ArangoDB Connection: Keep-Alive Content-Type: text/plain; charset = utf-8 Content-Length: 0
为了避免在学习过程中每次都输入密码,我们将禁用身份验证。为此,请打开配置文件:
# vim /etc/arangodb3/arangod.conf
如果代码显示不清晰,您应该更改颜色方案。
:colorscheme desert
将身份验证设置为 false,如下面的屏幕截图所示。
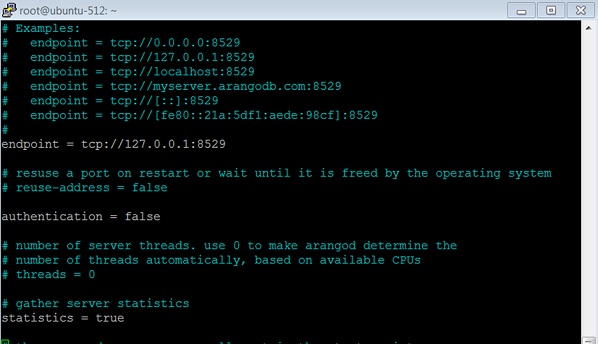
重启服务:
# service arangodb3 restart
将身份验证设置为 false 后,您将能够登录(使用 root 或在此情况下创建的用户,例如Harry),无需在请指定密码中输入任何密码。
让我们在关闭身份验证时检查api版本:
# curl --dump - http://127.0.0.1:8529/_api/version
输出
HTTP/1.1 200 OK
X-Content-Type-Options: nosniff
Server: ArangoDB
Connection: Keep-Alive
Content-Type: application/json; charset=utf-8
Content-Length: 60
{"server":"arango","version":"3.1.27","license":"community"}
ArangoDB - 案例场景
本章将考虑两种示例场景。这些示例更容易理解,并将帮助我们了解 ArangoDB 功能的工作方式。
为了演示 API,ArangoDB 预装了一组易于理解的图形。在您的 ArangoDB 中创建这些图形实例有两种方法:
- 在 Web 界面中的创建图形窗口中添加示例选项卡,
- 或在 Arangosh 中加载模块@arangodb/graph-examples/example-graph。
首先,让我们借助 Web 界面加载一个图形。为此,启动 Web 界面并单击图形选项卡。
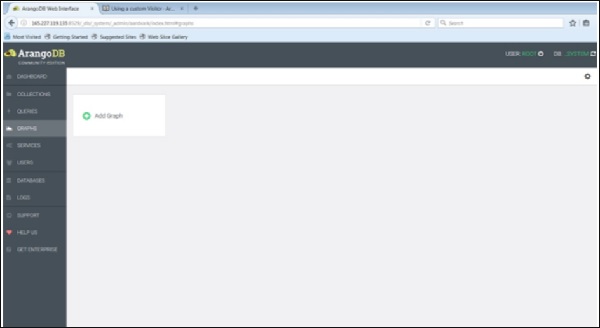
将出现创建图形对话框。向导包含两个选项卡 - 示例和图形。默认情况下打开图形选项卡;假设我们要创建一个新图形,它会询问图形的名称和其他定义。
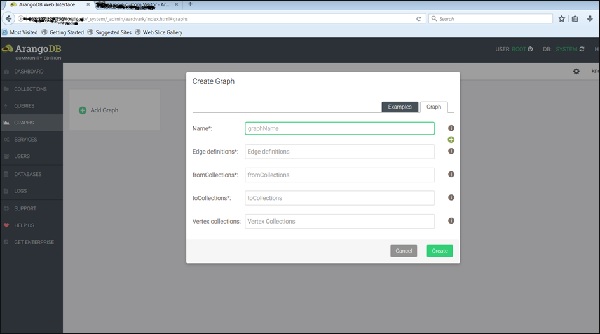
现在,我们将上传已创建的图形。为此,我们将选择示例选项卡。
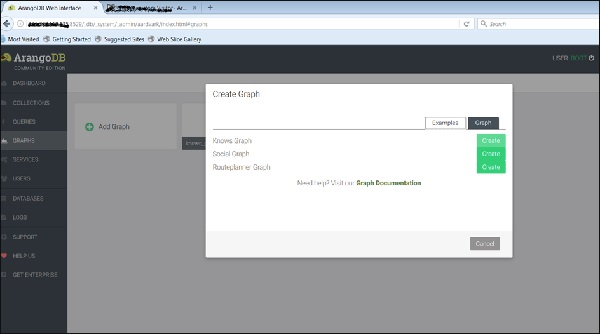
我们可以看到三个示例图形。选择Knows_Graph并单击绿色按钮“创建”。
创建后,您可以在 Web 界面中检查它们 - 用于创建以下图片的界面。
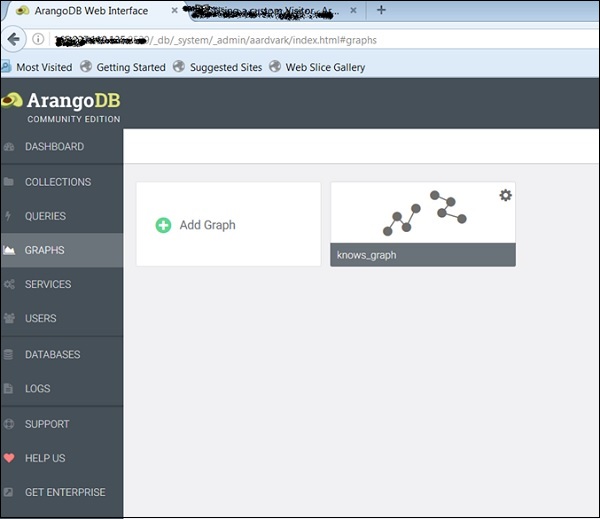
Knows_Graph
现在让我们看看Knows_Graph是如何工作的。选择 Knows_Graph,它将获取图形数据。
Knows_Graph 由一个顶点集合persons组成,通过一个边集合knows连接。它将包含五个顶点:Alice、Bob、Charlie、Dave 和 Eve。我们将有以下有向关系
Alice knows Bob Bob knows Charlie Bob knows Dave Eve knows Alice Eve knows Bob
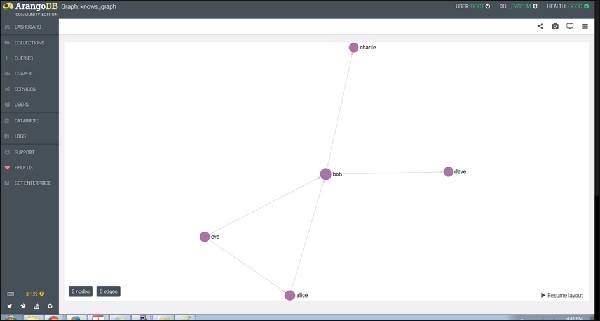
如果单击一个节点(顶点),例如“bob”,它将显示 ID(persons/bob)属性名称。
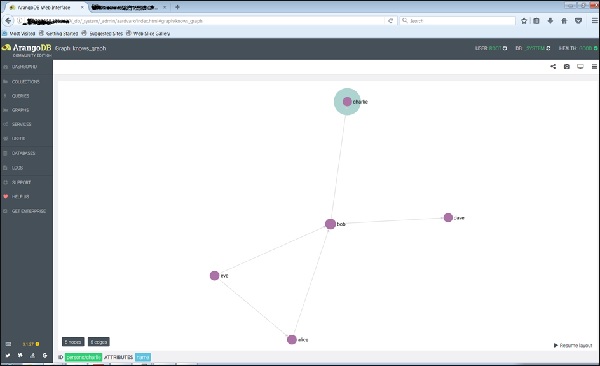
单击任何边时,它将显示 ID(knows/4590)属性。

这就是我们创建、检查其顶点和边的方法。
让我们再添加一个图形,这次使用 Arangosh。为此,我们需要在 ArangoDB 配置文件中包含另一个端点。
如何添加多个端点
打开配置文件:
# vim /etc/arangodb3/arangod.conf
添加另一个端点,如下面的终端屏幕截图所示。
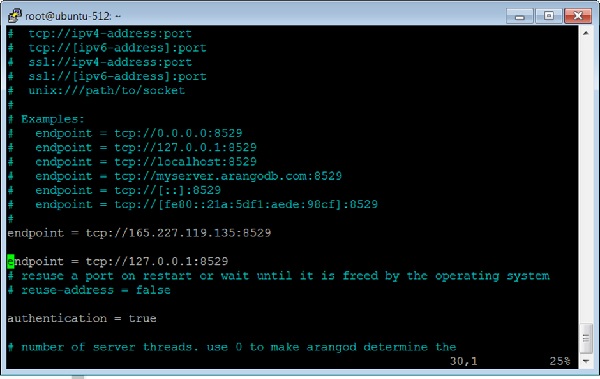
重启 ArangoDB:
# service arangodb3 restart
启动 Arangosh:
# arangosh Please specify a password: _ __ _ _ __ __ _ _ __ __ _ ___ ___| |__ / _` | '__/ _` | '_ \ / _` |/ _ \/ __| '_ \ | (_| | | | (_| | | | | (_| | (_) \__ \ | | | \__,_|_| \__,_|_| |_|\__, |\___/|___/_| |_| |___/ arangosh (ArangoDB 3.1.27 [linux] 64bit, using VPack 0.1.30, ICU 54.1, V8 5.0.71.39, OpenSSL 1.0.2g 1 Mar 2016) Copyright (c) ArangoDB GmbH Pretty printing values. Connected to ArangoDB 'http+tcp://127.0.0.1:8529' version: 3.1.27 [server], database: '_system', username: 'root' Please note that a new minor version '3.2.2' is available Type 'tutorial' for a tutorial or 'help' to see common examples 127.0.0.1:8529@_system>
Social_Graph
现在让我们了解 Social_Graph 是什么以及它是如何工作的。该图显示了一组人员及其关系:
此示例在两个顶点集合(女性和男性)中具有女性和男性作为顶点。边是它们在关系边集合中的连接。我们已经描述了如何使用 Arangosh 创建此图。读者可以围绕它进行操作并探索其属性,就像我们对 Knows_Graph 所做的那样。
ArangoDB - 数据模型和建模
本章将重点介绍以下主题:
- 数据库交互
- 数据模型
- 数据检索
ArangoDB 支持基于文档的数据模型以及基于图形的数据模型。让我们首先描述基于文档的数据模型。
ArangoDB 的文档非常类似于 JSON 格式。文档中包含零个或多个属性,每个属性都附加一个值。值可以是原子类型,例如数字、布尔值或 null、文字字符串,也可以是复合数据类型,例如嵌入式文档/对象或数组。数组或子对象可以由这些数据类型组成,这意味着单个文档可以表示非平凡的数据结构。
在层次结构中,文档被排列成集合,这些集合可能不包含任何文档(理论上)或包含多个文档。您可以将文档与行进行比较,将集合与表进行比较(这里的表和行指的是关系数据库管理系统 - RDBMS 的表和行)。
但是,在 RDBMS 中,定义列是将记录存储到表中的先决条件,这些定义称为模式。然而,作为一个新颖的功能,ArangoDB 是无模式的——没有先验的理由来指定文档将具有哪些属性。
与 RDBMS 不同的是,每个文档的结构都可以与其他文档完全不同。这些文档可以一起保存在一个集合中。实际上,集合中的文档可能存在共同特征,但是数据库系统,即 ArangoDB 本身,不会将您绑定到特定的数据结构。
现在我们将尝试理解 ArangoDB 的[图形数据模型],它需要两种类型的集合——第一种是文档集合(在群论语言中称为顶点集合),第二种是边集合。这两种类型之间存在细微的差别。边集合也存储文档,但它们的特征是包含两个唯一属性_from和_to,用于创建文档之间的关系。实际上,一个文档(读取边)链接两个文档(读取顶点),两者都存储在其各自的集合中。这种架构源自标记有向图的图论概念,不包括那些不仅可以有标签,而且本身可以是一个完整的 JSON 文档的边。
为了计算新数据、删除文档或操作它们,使用查询来根据给定条件选择或过滤文档。无论是像“示例查询”那样简单,还是像“联接”那样复杂,查询都使用 AQL(ArangoDB 查询语言)编写。
ArangoDB - 数据库方法
本章将讨论 ArangoDB 中的不同数据库方法。
首先,让我们获取数据库的属性:
- 名称
- ID
- 路径
首先,我们调用 Arangosh。一旦调用 Arangosh,我们将列出我们迄今为止创建的数据库:
我们将使用以下代码行来调用 Arangosh:
127.0.0.1:8529@_system> db._databases()
输出
[ "_system", "song_collection" ]
我们看到两个数据库,一个是由默认创建的_system,第二个是我们创建的song_collection。
现在让我们使用以下代码行切换到 song_collection 数据库:
127.0.0.1:8529@_system> db._useDatabase("song_collection")
输出
true 127.0.0.1:8529@song_collection>
我们将探索 song_collection 数据库的属性。
要查找名称
我们将使用以下代码行来查找名称。
127.0.0.1:8529@song_collection> db._name()
输出
song_collection
要查找 id:
我们将使用以下代码行来查找 id。
127.0.0.1:8529@song_collection> db._id()
输出
4838
要查找路径:
我们将使用以下代码行来查找路径。
127.0.0.1:8529@song_collection> db._path()
输出
/var/lib/arangodb3/databases/database-4838
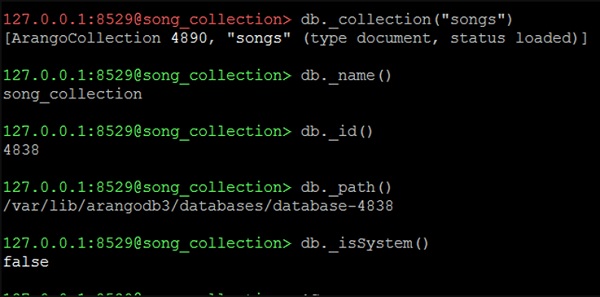
现在让我们使用以下代码行检查我们是否在系统数据库中:
127.0.0.1:8529@song_collection&t; db._isSystem()
输出
false
这意味着我们不在系统数据库中(因为我们已经创建并切换到 song_collection)。以下屏幕截图将帮助您理解这一点。
要获取特定集合,例如 songs:
我们将使用以下代码行获取特定集合。
127.0.0.1:8529@song_collection> db._collection("songs")
输出
[ArangoCollection 4890, "songs" (type document, status loaded)]
该代码行返回单个集合。
让我们在后续章节中讨论数据库操作的要点。
ArangoDB - CRUD 操作
本章将学习 Arangosh 的不同操作。
以下是 Arangosh 的可能操作:
- 创建文档集合
- 创建文档
- 读取文档
- 更新文档
让我们从创建一个新数据库开始。我们将使用以下代码行创建一个新数据库:
127.0.0.1:8529@_system> db._createDatabase("song_collection")
true
以下代码行将帮助您切换到新数据库:
127.0.0.1:8529@_system> db._useDatabase("song_collection")
true
提示将切换到“@@song_collection”
127.0.0.1:8529@song_collection>

从这里我们将学习 CRUD 操作。让我们在新数据库中创建一个集合:
127.0.0.1:8529@song_collection> db._createDocumentCollection('songs')
输出
[ArangoCollection 4890, "songs" (type document, status loaded)] 127.0.0.1:8529@song_collection>
让我们向我们的 'songs' 集合中添加一些文档(JSON 对象)。
我们按以下方式添加第一个文档:
127.0.0.1:8529@song_collection> db.songs.save({title: "A Man's Best Friend",
lyricist: "Johnny Mercer", composer: "Johnny Mercer", Year: 1950, _key:
"A_Man"})
输出
{
"_id" : "songs/A_Man",
"_key" : "A_Man",
"_rev" : "_VjVClbW---"
}
让我们向数据库添加其他文档。这将帮助我们学习查询数据的过程。您可以复制这些代码并将它们粘贴到 Arangosh 中以模拟该过程:
127.0.0.1:8529@song_collection> db.songs.save(
{
title: "Accentchuate The Politics",
lyricist: "Johnny Mercer",
composer: "Harold Arlen", Year: 1944,
_key: "Accentchuate_The"
}
)
{
"_id" : "songs/Accentchuate_The",
"_key" : "Accentchuate_The",
"_rev" : "_VjVDnzO---"
}
127.0.0.1:8529@song_collection> db.songs.save(
{
title: "Affable Balding Me",
lyricist: "Johnny Mercer",
composer: "Robert Emmett Dolan",
Year: 1950,
_key: "Affable_Balding"
}
)
{
"_id" : "songs/Affable_Balding",
"_key" : "Affable_Balding",
"_rev" : "_VjVEFMm---"
}
如何读取文档
_key 或文档句柄可用于检索文档。如果不需要遍历集合本身,请使用文档句柄。如果您有集合,则文档函数易于使用:
127.0.0.1:8529@song_collection> db.songs.document("A_Man");
{
"_key" : "A_Man",
"_id" : "songs/A_Man",
"_rev" : "_VjVClbW---",
"title" : "A Man's Best Friend",
"lyricist" : "Johnny Mercer",
"composer" : "Johnny Mercer",
"Year" : 1950
}
如何更新文档
有两种选项可用于更新保存的数据:替换和更新。
更新函数修补文档,将其与给定的属性合并。另一方面,替换函数将用新文档替换之前的文档。即使提供了完全不同的属性,替换仍然会发生。我们首先观察非破坏性更新,更新歌曲中的属性 Production:
127.0.0.1:8529@song_collection> db.songs.update("songs/A_Man",{production:
"Top Banana"});
输出
{
"_id" : "songs/A_Man",
"_key" : "A_Man",
"_rev" : "_VjVOcqe---",
"_oldRev" : "_VjVClbW---"
}
现在让我们读取更新后的歌曲的属性:
127.0.0.1:8529@song_collection> db.songs.document('A_Man');
输出
{
"_key" : "A_Man",
"_id" : "songs/A_Man",
"_rev" : "_VjVOcqe---",
"title" : "A Man's Best Friend",
"lyricist" : "Johnny Mercer",
"composer" : "Johnny Mercer",
"Year" : 1950,
"production" : "Top Banana"
}
可以使用update函数轻松更新大型文档,尤其是在属性很少的情况下。
相反,replace函数在与同一文档一起使用时会消除您的数据。
127.0.0.1:8529@song_collection> db.songs.replace("songs/A_Man",{production:
"Top Banana"});
现在让我们使用以下代码行检查我们刚刚更新的歌曲:
127.0.0.1:8529@song_collection> db.songs.document('A_Man');
输出
{
"_key" : "A_Man",
"_id" : "songs/A_Man",
"_rev" : "_VjVRhOq---",
"production" : "Top Banana"
}
现在,您可以观察到该文档不再具有原始数据。
如何删除文档
删除函数与文档句柄结合使用,用于从集合中删除文档:
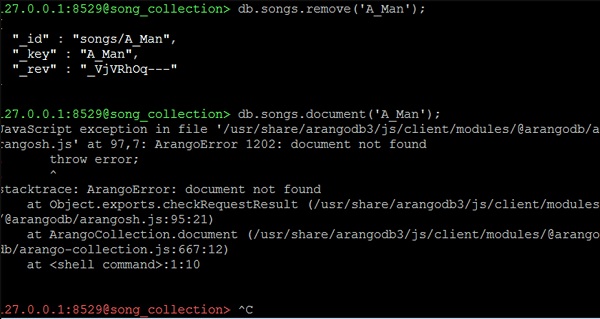
127.0.0.1:8529@song_collection> db.songs.remove('A_Man');
现在让我们使用以下代码行检查我们刚刚删除的歌曲的属性:
127.0.0.1:8529@song_collection> db.songs.document('A_Man');
我们将得到如下异常错误作为输出:
JavaScript exception in file '/usr/share/arangodb3/js/client/modules/@arangodb/arangosh.js' at 97,7: ArangoError 1202: document not found ! throw error; ! ^ stacktrace: ArangoError: document not found at Object.exports.checkRequestResult (/usr/share/arangodb3/js/client/modules/@arangodb/arangosh.js:95:21) at ArangoCollection.document (/usr/share/arangodb3/js/client/modules/@arangodb/arango-collection.js:667:12) at <shell command>:1:10
使用 Web 界面的 CRUD 操作
在上一章中,我们学习了如何使用命令行工具 Arangosh 对文档执行各种操作。现在,我们将学习如何使用 Web 界面执行相同的操作。首先,将以下地址 - http://your_server_ip:8529/_db/song_collection/_admin/aardvark/index.html#login 复制到浏览器地址栏。您将被定向到以下登录页面。
现在,输入用户名和密码。

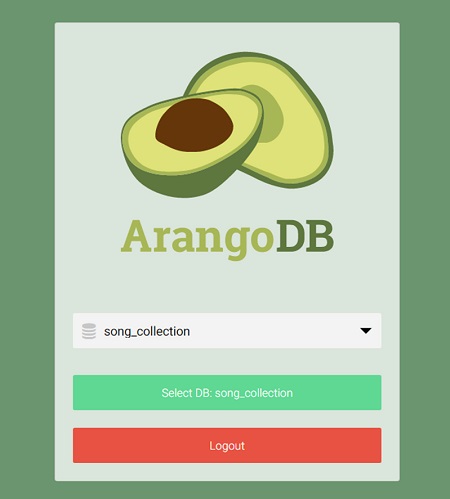
如果成功,将显示以下屏幕。我们需要选择要操作的数据库,默认数据库为_system 数据库。让我们选择song_collection 数据库,然后点击绿色标签 -
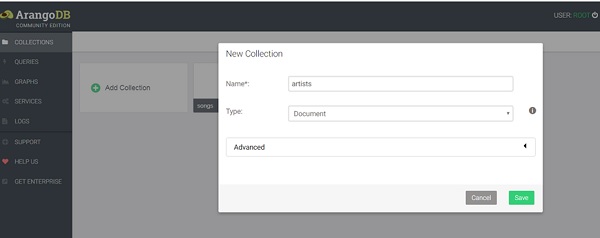
创建集合
在本节中,我们将学习如何创建集合。点击顶部导航栏中的“集合”选项卡。
我们使用命令行添加的 songs 集合可见。点击它将显示条目。我们现在将使用 Web 界面添加一个artists 集合。我们使用 Arangosh 创建的songs 集合已经存在。在出现的“新建集合”对话框的“名称”字段中,输入artists。可以安全地忽略高级选项,默认集合类型(即文档)就可以了。
点击“保存”按钮将最终创建集合,现在这两个集合将在此页面上可见。
使用文档填充新创建的集合
点击artists 集合后,您将看到一个空的集合 -
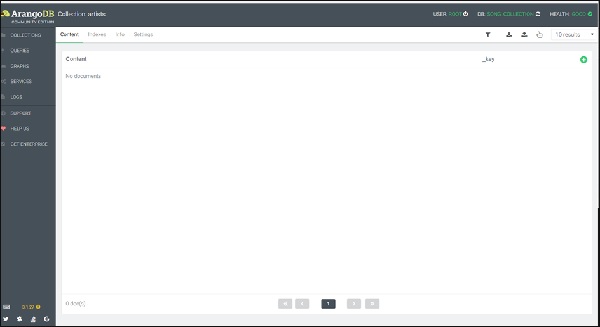
要添加文档,您需要点击右上角的“+”号。当系统提示您输入_key 时,请输入Affable_Balding 作为键。
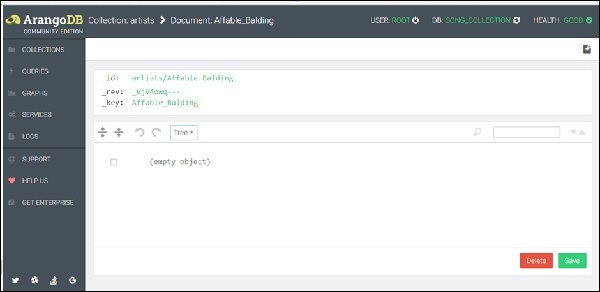
现在,将出现一个表单来添加和编辑文档的属性。添加属性有两种方式:图形化和树状。图形化方式直观但速度慢,因此我们将切换到代码视图,使用树状下拉菜单进行选择 -
为了简化流程,我们创建了一个 JSON 格式的示例数据,您可以复制然后粘贴到查询编辑器区域 -
{"artist": "Johnny Mercer", "title":"Affable Balding Me", "composer": "Robert Emmett Dolan", "Year": 1950}
(注意:只能使用一对花括号;请参见下面的屏幕截图)
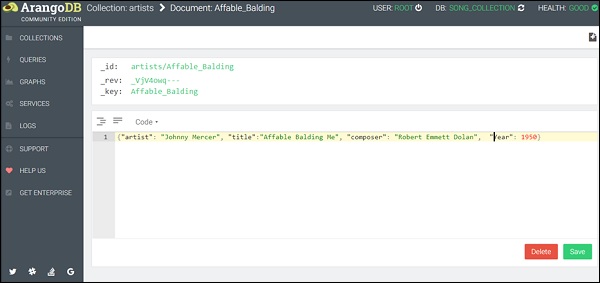
您可以观察到,我们在代码视图模式下对键和值都加了引号。现在,点击“保存”。成功完成操作后,页面上会短暂出现绿色闪光。
如何读取文档
要读取文档,请返回“集合”页面。
点击artist 集合后,将出现一个新条目。
如何更新文档
编辑文档中的条目很简单;您只需点击文档概述中要编辑的行即可。在这里,与创建新文档时一样,也会显示相同的查询编辑器。
删除文档
您可以通过按“-”图标删除文档。每个文档行在末尾都有此符号。它会提示您确认以避免不安全删除。
此外,对于特定集合,“集合概述”页面上还存在其他操作,例如过滤文档、管理索引和导入数据。
在下一章中,我们将讨论 Web 界面的一个重要功能,即 AQL 查询编辑器。
使用 AQL 查询数据
本章将讨论如何使用 AQL 查询数据。我们已经在之前的章节中讨论过,ArangoDB 开发了自己的查询语言,名为 AQL。
现在让我们开始与 AQL 交互。如下图所示,在 Web 界面中,点击导航栏顶部的AQL 编辑器选项卡。将出现一个空白的查询编辑器。
需要时,您可以通过点击右上角的“查询”或“结果”选项卡在编辑器和结果视图之间切换,如下图所示 -

除其他功能外,编辑器还具有语法高亮显示、撤销/重做功能和查询保存功能。有关详细信息,请参阅官方文档。我们将重点介绍 AQL 查询编辑器的一些基本和常用功能。
AQL 基础知识
在 AQL 中,查询表示要实现的最终结果,而不是实现最终结果的过程。此功能通常被称为该语言的声明式属性。此外,AQL 可以查询和修改数据,因此可以通过组合这两个过程来创建复杂的查询。
请注意,AQL 完全符合 ACID 规范。读取或修改查询要么完全完成,要么完全不完成。即使读取文档数据,也会以一致的数据单元结束。
我们向已经创建的 songs 集合添加两首新歌曲。无需键入,您可以复制以下查询,然后将其粘贴到 AQL 编辑器中 -
FOR song IN [
{
title: "Air-Minded Executive", lyricist: "Johnny Mercer",
composer: "Bernie Hanighen", Year: 1940, _key: "Air-Minded"
},
{
title: "All Mucked Up", lyricist: "Johnny Mercer", composer:
"Andre Previn", Year: 1974, _key: "All_Mucked"
}
]
INSERT song IN songs
点击左下角的“执行”按钮。
它将在songs 集合中写入两个新文档。
此查询描述了 AQL 中 FOR 循环的工作方式;它迭代 JSON 编码文档列表,对集合中的每个文档执行编码操作。不同的操作可以是创建新结构、过滤、选择文档、修改或将文档插入数据库(参考即时示例)。本质上,AQL 可以高效地执行 CRUD 操作。
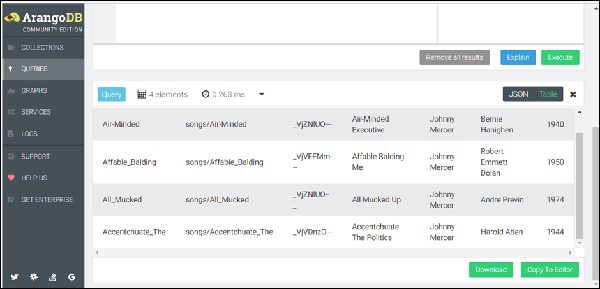
要查找数据库中的所有歌曲,让我们再次运行以下查询,相当于 SQL 类型数据库的SELECT * FROM songs(因为编辑器会记住上次查询,请按*新建*按钮清除编辑器)-
FOR song IN songs RETURN song
结果集将显示迄今为止保存在songs 集合中的歌曲列表,如下图所示。
可以将FILTER、SORT 和LIMIT 等操作添加到For 循环主体中,以缩小和排序结果。
FOR song IN songs FILTER song.Year > 1940 RETURN song
上面的查询将在“结果”选项卡中显示 1940 年以后创作的歌曲(请参见下面的图片)。

本例中使用了文档键,但任何其他属性也可以用作过滤的等效项。由于文档键保证是唯一的,因此最多只有一个文档与该过滤器匹配。对于其他属性,情况可能并非如此。要返回活动用户(由名为 status 的属性确定)的子集,按名称升序排序,我们使用以下语法 -
FOR song IN songs FILTER song.Year > 1940 SORT song.composer RETURN song LIMIT 2
我们特意包含了这个例子。在这里,我们观察到 AQL 以红色突出显示的查询语法错误消息。此语法突出显示错误,有助于调试您的查询,如下图所示。
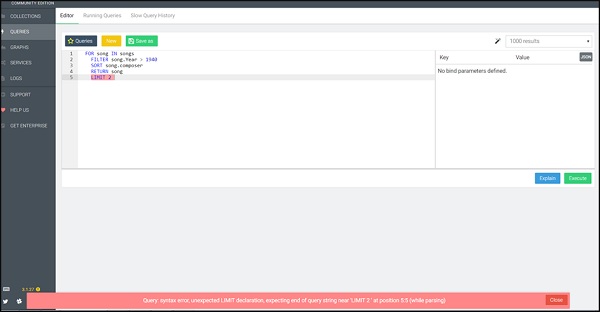
现在让我们运行正确的查询(注意更正)-
FOR song IN songs FILTER song.Year > 1940 SORT song.composer LIMIT 2 RETURN song

AQL 中的复杂查询
AQL 为所有受支持的数据类型配备了多个函数。查询中的变量赋值允许构建非常复杂的嵌套结构。这样,数据密集型操作更靠近后端的数据,而不是客户端(例如浏览器)。为了理解这一点,让我们首先向歌曲添加任意持续时间(长度)。
让我们从第一个函数开始,即 Update 函数 -
UPDATE { _key: "All_Mucked" }
WITH { length: 180 }
IN songs
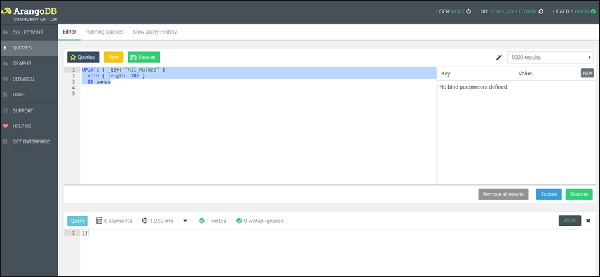
我们可以看到已写入一个文档,如上图所示。
现在让我们也更新其他文档(歌曲)。
UPDATE { _key: "Affable_Balding" }
WITH { length: 200 }
IN songs
现在我们可以检查所有歌曲是否都有一个新的属性length -
FOR song IN songs RETURN song
输出
[
{
"_key": "Air-Minded",
"_id": "songs/Air-Minded",
"_rev": "_VkC5lbS---",
"title": "Air-Minded Executive",
"lyricist": "Johnny Mercer",
"composer": "Bernie Hanighen",
"Year": 1940,
"length": 210
},
{
"_key": "Affable_Balding",
"_id": "songs/Affable_Balding",
"_rev": "_VkC4eM2---",
"title": "Affable Balding Me",
"lyricist": "Johnny Mercer",
"composer": "Robert Emmett Dolan",
"Year": 1950,
"length": 200
},
{
"_key": "All_Mucked",
"_id": "songs/All_Mucked",
"_rev": "_Vjah9Pu---",
"title": "All Mucked Up",
"lyricist": "Johnny Mercer",
"composer": "Andre Previn",
"Year": 1974,
"length": 180
},
{
"_key": "Accentchuate_The",
"_id": "songs/Accentchuate_The",
"_rev": "_VkC3WzW---",
"title": "Accentchuate The Politics",
"lyricist": "Johnny Mercer",
"composer": "Harold Arlen",
"Year": 1944,
"length": 190
}
]
为了说明 AQL 的其他关键字(如 LET、FILTER、SORT 等)的使用,我们现在将歌曲的持续时间格式化为mm:ss 格式。
查询
FOR song IN songs
FILTER song.length > 150
LET seconds = song.length % 60
LET minutes = FLOOR(song.length / 60)
SORT song.composer
RETURN
{
Title: song.title,
Composer: song.composer,
Duration: CONCAT_SEPARATOR(':',minutes, seconds)
}
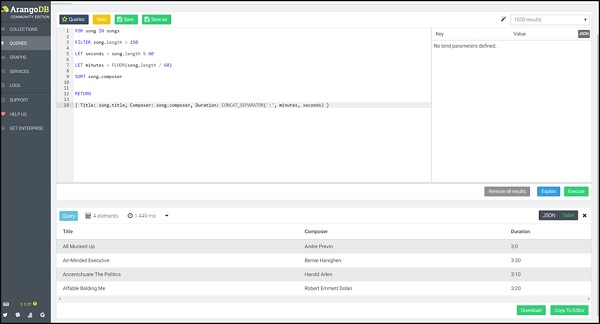
这次我们将返回歌曲标题和持续时间。Return 函数允许您为每个输入文档创建一个新的 JSON 对象以返回。
我们现在将讨论 AQL 数据库的“连接”功能。
让我们首先创建一个集合composer_dob。此外,我们将通过在查询框中运行以下查询来创建四个文档,其中包含作曲家的假设出生日期 -
FOR dob IN [
{composer: "Bernie Hanighen", Year: 1909}
,
{composer: "Robert Emmett Dolan", Year: 1922}
,
{composer: "Andre Previn", Year: 1943}
,
{composer: "Harold Arlen", Year: 1910}
]
INSERT dob in composer_dob
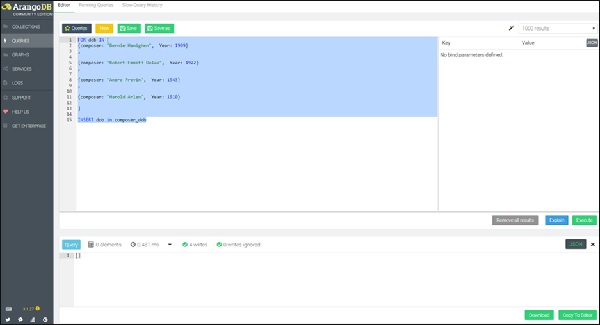
为了突出与 SQL 的相似性,我们在 AQL 中提供了一个嵌套的 FOR 循环查询,从而进行 REPLACE 操作,首先在内部循环中迭代所有作曲家的出生日期,然后迭代所有相关的歌曲,创建一个包含属性song_with_composer_key(而不是song 属性)的新文档。
以下是查询 -
FOR s IN songs
FOR c IN composer_dob
FILTER s.composer == c.composer
LET song_with_composer_key = MERGE(
UNSET(s, 'composer'),
{composer_key:c._key}
)
REPLACE s with song_with_composer_key IN songs

现在让我们再次运行查询FOR song IN songs RETURN song 以查看歌曲集合是如何变化的。
输出
[
{
"_key": "Air-Minded",
"_id": "songs/Air-Minded",
"_rev": "_Vk8kFoK---",
"Year": 1940,
"composer_key": "5501",
"length": 210,
"lyricist": "Johnny Mercer",
"title": "Air-Minded Executive"
},
{
"_key": "Affable_Balding",
"_id": "songs/Affable_Balding",
"_rev": "_Vk8kFoK--_",
"Year": 1950,
"composer_key": "5505",
"length": 200,
"lyricist": "Johnny Mercer",
"title": "Affable Balding Me"
},
{
"_key": "All_Mucked",
"_id": "songs/All_Mucked",
"_rev": "_Vk8kFoK--A",
"Year": 1974,
"composer_key": "5507",
"length": 180,
"lyricist": "Johnny Mercer",
"title": "All Mucked Up"
},
{
"_key": "Accentchuate_The",
"_id": "songs/Accentchuate_The",
"_rev": "_Vk8kFoK--B",
"Year": 1944,
"composer_key": "5509",
"length": 190,
"lyricist": "Johnny Mercer",
"title": "Accentchuate The Politics"
}
]
上面的查询完成了数据迁移过程,将composer_key 添加到每首歌曲中。
现在下一个查询仍然是一个嵌套的 FOR 循环查询,但这次是进行连接操作,将相关的作曲家姓名(使用 `composer_key` 选择)添加到每首歌曲中 -
FOR s IN songs
FOR c IN composer_dob
FILTER c._key == s.composer_key
RETURN MERGE(s,
{ composer: c.composer }
)
输出
[
{
"Year": 1940,
"_id": "songs/Air-Minded",
"_key": "Air-Minded",
"_rev": "_Vk8kFoK---",
"composer_key": "5501",
"length": 210,
"lyricist": "Johnny Mercer",
"title": "Air-Minded Executive",
"composer": "Bernie Hanighen"
},
{
"Year": 1950,
"_id": "songs/Affable_Balding",
"_key": "Affable_Balding",
"_rev": "_Vk8kFoK--_",
"composer_key": "5505",
"length": 200,
"lyricist": "Johnny Mercer",
"title": "Affable Balding Me",
"composer": "Robert Emmett Dolan"
},
{
"Year": 1974,
"_id": "songs/All_Mucked",
"_key": "All_Mucked",
"_rev": "_Vk8kFoK--A",
"composer_key": "5507",
"length": 180,
"lyricist": "Johnny Mercer",
"title": "All Mucked Up",
"composer": "Andre Previn"
},
{
"Year": 1944,
"_id": "songs/Accentchuate_The",
"_key": "Accentchuate_The",
"_rev": "_Vk8kFoK--B",
"composer_key": "5509",
"length": 190,
"lyricist": "Johnny Mercer",
"title": "Accentchuate The Politics",
"composer": "Harold Arlen"
}
]
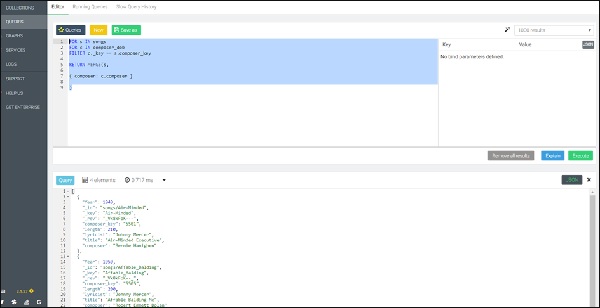
ArangoDB - AQL 示例查询
在本章中,我们将考虑一些关于演员和电影数据库的 AQL 示例查询。这些查询基于图。
问题
给定一个演员集合和一个电影集合,以及一个 actIn 边集合(带有一个 year 属性)来连接顶点,如下所示 -
[演员] <- act in -> [电影]
我们如何获得 -
- 所有在“电影1”或“电影2”中演出的演员?
- 所有同时在“电影1”和“电影2”中演出的演员?
- “演员1”和“演员2”之间所有共同出演的电影?
- 所有出演 3 部或更多电影的演员?
- 所有恰好有 6 位演员出演的电影?
- 按电影划分的演员人数?
- 按演员划分的电影数量?
- 2005 年到 2010 年间演员出演的电影数量?
解决方案
在解决并获得上述查询答案的过程中,我们将使用 Arangosh 创建数据集并在其上运行查询。所有 AQL 查询都是字符串,可以简单地复制到您喜欢的驱动程序(而不是 Arangosh)中。
让我们从在 Arangosh 中创建测试数据集开始。首先,下载此文件 -
# wget -O dataset.js https://drive.google.com/file/d/0B4WLtBDZu_QWMWZYZ3pYMEdqajA/view?usp=sharing
输出
... HTTP request sent, awaiting response... 200 OK Length: unspecified [text/html] Saving to: ‘dataset.js’ dataset.js [ <=> ] 115.14K --.-KB/s in 0.01s 2017-09-17 14:19:12 (11.1 MB/s) - ‘dataset.js’ saved [117907]
您可以在上面的输出中看到我们下载了一个 JavaScript 文件dataset.js。此文件包含在数据库中创建数据集的 Arangosh 命令。我们不会逐个复制粘贴命令,而是将使用 Arangosh 上的--javascript.execute 选项以非交互方式执行多个命令。认为它是救命命令!
现在在shell上执行以下命令:
$ arangosh --javascript.execute dataset.js
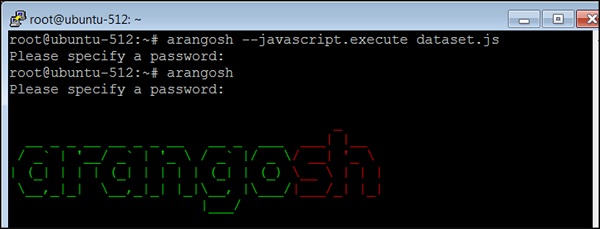
出现提示时输入密码,如上图所示。现在我们已经保存了数据,我们将构建AQL查询来回答本章开头提出的具体问题。
第一个问题
让我们来看第一个问题:**所有在“movie1”或“movie2”中演出的演员**。假设,我们想找到所有在“The Matrix”或“The Devil's Advocate”中演出的演员的姓名:
我们将一次处理一部电影,以获取演员的姓名:
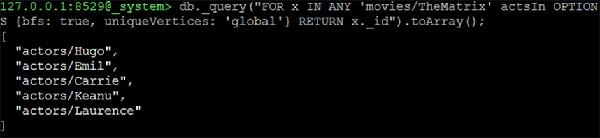
127.0.0.1:8529@_system> db._query("FOR x IN ANY 'movies/TheMatrix' actsIn
OPTIONS {bfs: true, uniqueVertices: 'global'} RETURN x._id").toArray();
输出
我们将收到以下输出:
[ "actors/Hugo", "actors/Emil", "actors/Carrie", "actors/Keanu", "actors/Laurence" ]
现在我们继续形成两个NEIGHBORS查询的UNION_DISTINCT,这将是解决方案:
127.0.0.1:8529@_system> db._query("FOR x IN UNION_DISTINCT ((FOR y IN ANY
'movies/TheMatrix' actsIn OPTIONS {bfs: true, uniqueVertices: 'global'} RETURN
y._id), (FOR y IN ANY 'movies/TheDevilsAdvocate' actsIn OPTIONS {bfs: true,
uniqueVertices: 'global'} RETURN y._id)) RETURN x").toArray();
输出
[ "actors/Charlize", "actors/Al", "actors/Laurence", "actors/Keanu", "actors/Carrie", "actors/Emil", "actors/Hugo" ]

第二个问题
现在让我们考虑第二个问题:**所有同时在“movie1”和“movie2”中演出的演员**。这与上述问题几乎相同。但这次我们不感兴趣的是UNION,而是INTERSECTION:
127.0.0.1:8529@_system> db._query("FOR x IN INTERSECTION ((FOR y IN ANY
'movies/TheMatrix' actsIn OPTIONS {bfs: true, uniqueVertices: 'global'} RETURN
y._id), (FOR y IN ANY 'movies/TheDevilsAdvocate' actsIn OPTIONS {bfs: true,
uniqueVertices: 'global'} RETURN y._id)) RETURN x").toArray();
输出
我们将收到以下输出:
[ "actors/Keanu" ]

第三个问题
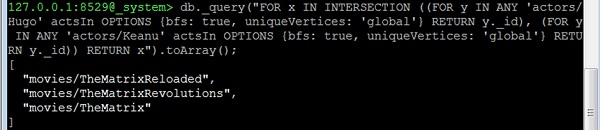
现在让我们考虑第三个问题:**“actor1”和“actor2”共同出演的所有电影**。这实际上与movie1和movie2中共同演员的问题相同。我们只需要更改起始顶点。例如,让我们找到Hugo Weaving(“Hugo”)和Keanu Reeves共同主演的所有电影:
127.0.0.1:8529@_system> db._query(
"FOR x IN INTERSECTION (
(
FOR y IN ANY 'actors/Hugo' actsIn OPTIONS
{bfs: true, uniqueVertices: 'global'}
RETURN y._id
),
(
FOR y IN ANY 'actors/Keanu' actsIn OPTIONS
{bfs: true, uniqueVertices:'global'} RETURN y._id
)
)
RETURN x").toArray();
输出
我们将收到以下输出:
[ "movies/TheMatrixReloaded", "movies/TheMatrixRevolutions", "movies/TheMatrix" ]
第四个问题
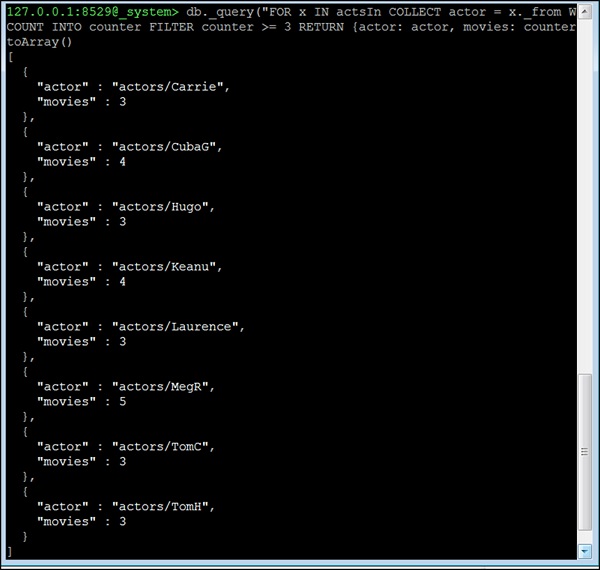
现在让我们考虑第四个问题。**出演3部或更多电影的所有演员**。这个问题不同;我们在这里不能使用neighbors函数。相反,我们将使用AQL的edge-index和COLLECT语句进行分组。基本思想是按其**startVertex**(在此数据集中始终为演员)对所有边进行分组。然后,我们从结果中删除所有出演少于3部电影的演员,因为这里我们包含了演员出演电影的数量:
127.0.0.1:8529@_system> db._query("FOR x IN actsIn COLLECT actor = x._from WITH
COUNT INTO counter FILTER counter >= 3 RETURN {actor: actor, movies:
counter}"). toArray()
输出
[
{
"actor" : "actors/Carrie",
"movies" : 3
},
{
"actor" : "actors/CubaG",
"movies" : 4
},
{
"actor" : "actors/Hugo",
"movies" : 3
},
{
"actor" : "actors/Keanu",
"movies" : 4
},
{
"actor" : "actors/Laurence",
"movies" : 3
},
{
"actor" : "actors/MegR",
"movies" : 5
},
{
"actor" : "actors/TomC",
"movies" : 3
},
{
"actor" : "actors/TomH",
"movies" : 3
}
]
对于其余的问题,我们将讨论查询的构成,并且仅提供查询。读者应该自己在Arangosh终端上运行查询。
第五个问题
现在让我们考虑第五个问题:**恰好有6名演员出演的所有电影**。与之前的查询相同,但使用相等过滤器。但是,现在我们需要电影而不是演员,所以我们返回**_to属性**:
db._query("FOR x IN actsIn COLLECT movie = x._to WITH COUNT INTO counter FILTER
counter == 6 RETURN movie").toArray()
按电影划分的演员人数?
我们记得在我们的数据集中,边上的**_to**对应于电影,所以我们计算相同的**_to**出现的次数。这就是演员的数量。该查询与之前的查询几乎相同,但**COLLECT之后没有FILTER**:
db._query("FOR x IN actsIn COLLECT movie = x._to WITH COUNT INTO counter RETURN
{movie: movie, actors: counter}").toArray()
第六个问题
现在让我们考虑第六个问题:**演员出演的电影数量。**
我们找到上述查询解决方案的方法也将帮助您找到此查询的解决方案。
db._query("FOR x IN actsIn COLLECT actor = x._from WITH COUNT INTO counter
RETURN {actor: actor, movies: counter}").toArray()
ArangoDB - 如何部署
在本章中,我们将描述部署ArangoDB的各种可能性。
部署:单实例
我们已经在之前的章节中学习了如何在Linux(Ubuntu)上部署单实例。现在让我们看看如何使用Docker进行部署。
部署:Docker
对于使用docker进行部署,我们将在我们的机器上安装Docker。有关Docker的更多信息,请参考我们的教程Docker。
安装Docker后,您可以使用以下命令:
docker run -e ARANGO_RANDOM_ROOT_PASSWORD = 1 -d --name agdb-foo -d arangodb/arangodb
它将创建一个ArangoDB的Docker实例,并将其作为Docker后台进程启动,标识名称为**agdbfoo**。
终端也会打印进程标识符。
默认情况下,端口8529保留用于ArangoDB监听请求。此端口也自动可用于您可能已链接的所有Docker应用程序容器。