- ChatGPT 教程
- ChatGPT - 首页
- ChatGPT - 基础知识
- ChatGPT - 入门指南
- ChatGPT - 工作原理
- ChatGPT - 提示词
- ChatGPT - 竞争对手
- ChatGPT - 内容创作
- ChatGPT - 市场营销
- ChatGPT - 求职者
- ChatGPT - 代码编写
- ChatGPT - 搜索引擎优化 (SEO)
- ChatGPT – 机器学习
- ChatGPT - 生成式AI
- ChatGPT - 构建聊天机器人
- ChatGPT - 插件
- ChatGPT - GPT-4o (Omni)
- ChatGPT 有用资源
- ChatGPT - 快速指南
- ChatGPT - 有用资源
- ChatGPT - 讨论
ChatGPT – 机器学习
赋予 ChatGPT 强大功能的基础模型是什么?
ChatGPT 的功能建立在机器学习的基础之上,其关键贡献来自监督学习、无监督学习和强化学习等类型。本章我们将了解机器学习如何促成 ChatGPT 的强大功能。
什么是机器学习?
机器学习是人工智能 (AI) 的一个动态领域,借助它,计算机系统可以通过算法或模型从原始数据中提取模式。这些算法使计算机能够自主地从经验中学习,并进行预测或决策,而无需进行明确的编程。
现在,让我们了解机器学习的类型及其在塑造 ChatGPT 功能方面的贡献。
监督学习
监督学习是机器学习的一个类别,其中算法或模型使用标记数据集进行训练。在这种方法中,算法被提供输入-输出对,其中每个输入都与相应的输出或标签相关联。监督学习的目标是使模型学习输入和输出之间的映射或关系,以便它能够对新的、未见过的数据进行准确的预测或分类。
ChatGPT 使用监督学习来初步训练其语言模型。在这个第一阶段,语言模型使用包含输入和输出示例对的标记数据进行训练。在 ChatGPT 的上下文中,输入包含一部分文本,相应的输出是对该文本的延续或响应。
这些带注释的数据帮助模型学习不同单词、短语及其上下文相关性之间的关联。ChatGPT 通过接触各种示例,利用这些信息来预测基于给定输入最可能的下一个单词或单词序列。这就是监督学习成为 ChatGPT 理解和生成类似人类文本能力的基础的方式。
无监督学习
无监督学习是一种机器学习方法,其中算法或模型自主地分析和从数据中得出见解,无需标记示例的指导。简而言之,这种方法的目标是在未标记数据中找到固有的模式、结构或关系。
监督学习为 ChatGPT 提供了坚实的基础,但 ChatGPT 的真正魅力在于能够创造性地生成连贯且上下文相关的答案或响应。这就是无监督学习发挥作用的地方。
借助对各种互联网文本进行的大规模预训练,ChatGPT 发展出对事实、推理能力和语言模式的深刻理解。这就是无监督学习释放 ChatGPT 的创造力并使其能够对各种用户输入生成有意义的响应的方式。
强化学习
与监督学习相比,强化学习 (RL) 是一种机器学习范式,其中智能体通过与环境交互来学习决策。智能体在环境中采取行动,以奖励或惩罚的形式接收反馈,并利用此反馈随着时间的推移改进其决策策略。
强化学习就像一个导航指南针,引导 ChatGPT 完成动态且不断发展的对话。在最初的监督学习和无监督学习阶段之后,模型会进行强化学习,以根据用户反馈微调其响应。
大型语言模型 (LLM) 就像超级智能工具,可以从海量文本中获取知识。现在,想象一下,通过使用一种称为强化学习的技术,使这些工具变得更智能。这就像教它们将知识转化为有用的行动。这种智力结合是基于人类反馈的强化学习 (RLHF) 背后的魔力,使这些语言模型在理解和响应我们方面更加出色。
基于人类反馈的强化学习 (RLHF)
2017 年,OpenAI 发表了一篇题为Deep reinforcement learning from human preferences 的研究论文,首次推出了基于人类反馈的强化学习 (RLHF)。有时我们需要在使用强化学习的情况下进行操作,但手头的任务难以解释。在这种情况下,人类反馈变得很重要,并且可以产生巨大的影响。
RLHF 通过加入少量的人类反馈来改进智能体的学习过程。让我们借助此图了解其整体训练过程,这基本上是一个三步反馈循环:
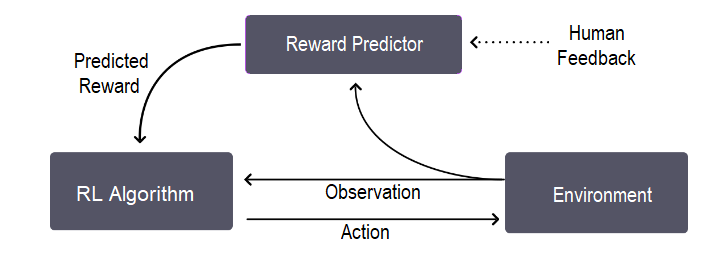
正如我们在图像中看到的,反馈循环发生在智能体对目标的理解、人类反馈和强化学习训练之间。
RLHF 最初用于机器人技术等领域,已被证明可以提供更受控的用户体验。这就是为什么 OpenAI、Meta、Google、亚马逊网络服务、IBM、DeepMind、Anthropic 等主要公司已将其 RLHF 添加到其大型语言模型 (LLM) 中的原因。事实上,RLHF 已成为最流行的 LLM——ChatGPT 的关键组成部分。
ChatGPT 和 RLHF
在本节中,我们将解释 ChatGPT 如何使用 RLHF 来适应人类反馈。
OpenAI 使用循环中的基于人类反馈的强化学习,即 RLHF,来训练其InstructGPT 模型。在此之前,OpenAI API 由 GPT-3 语言模型驱动,该模型倾向于产生可能不真实且具有毒性的输出,因为它们与用户不一致。
另一方面,InstructGPT 模型比 GPT-3 模型要好得多,因为它们:
编造事实的频率较低,并且
显示出生成有害输出的少量减少。
使用 RLHF 微调 ChatGPT 的步骤
对于 ChatGPT,OpenAI 采用了与InstructGPT 模型类似的方法,数据收集设置略有不同。
步骤 1:SFT(监督微调)模型
第一步主要涉及数据收集以训练监督策略模型,称为 SFT 模型。对于数据收集,选择一组提示,然后要求一群人类标记者演示所需的输出。
现在,ChatGPT 等多功能聊天机器人的开发人员决定使用来自 GPT-3.5 系列的预训练模型,而不是微调原始 GPT-3 模型。换句话说,开发人员选择在“代码模型”而不是纯文本模型的基础上进行微调。
此步骤生成的 SFT 模型的一个主要问题是其容易出现错位,导致输出缺乏用户关注。
步骤 2:奖励模型 (RM)
此步骤的主要目标是从数据中直接获取目标函数。此目标函数为 SFT 模型输出分配分数,反映其对人类的期望程度。
让我们看看它是如何工作的:
首先,对提示列表和 SFT 模型输出进行采样。
然后,标记者将这些输出从最好到最差进行排名。现在,数据集的大小是第一步中用于 SFT 模型的基线数据集的 10 倍。
新数据集现在用于训练我们的奖励模型 (RM)。
步骤 3:使用 PPO(近端策略优化)微调 SFT 策略
在此步骤中,应用了一种称为近端策略优化 (PPO) 的特定强化学习算法来微调 SFT 模型,使其能够优化 RM。此步骤的输出是一个名为 PPO 模型的微调模型。让我们了解它是如何工作的:
首先,从数据集中选择一个新的提示。
现在,初始化 PPO 模型以微调 SFT 模型。
此策略现在生成输出,然后 RM 从该输出计算奖励。
然后,使用 PPO 使用此奖励来更新策略。
结论
本章解释了机器学习如何赋予 ChatGPT 强大的功能。我们还了解了机器学习范式(监督学习、无监督学习和强化学习)如何帮助塑造 ChatGPT 的功能。
借助 RLHF(基于人类反馈的强化学习),我们探讨了人类反馈的重要性及其对 ChatGPT 等通用聊天机器人的性能的巨大影响。