
- 编译器设计教程
- 编译器设计 - 首页
- 编译器设计 - 概述
- 编译器设计 - 架构
- 编译器设计 - 编译器的阶段
- 编译器设计 - 词法分析
- 编译器 - 正则表达式
- 编译器设计 - 有限自动机
- 编译器设计 - 语法分析
- 编译器设计 - 解析类型
- 编译器设计 - 自顶向下解析器
- 编译器设计 - 自底向上解析器
- 编译器设计 - 错误恢复
- 编译器设计 - 语义分析
- 编译器 - 运行时环境
- 编译器设计 - 符号表
- 编译器 - 中间代码
- 编译器设计 - 代码生成
- 编译器设计 - 代码优化
- 编译器设计有用资源
- 编译器设计 - 快速指南
- 编译器设计 - 有用资源
编译器设计 - 代码生成
代码生成可以被认为是编译的最后阶段。通过代码生成后的优化过程可以应用于代码,但这可以被视为代码生成阶段本身的一部分。编译器生成的代码是某种较低级编程语言的目标代码,例如汇编语言。我们已经看到,用高级语言编写的源代码被转换为低级语言,从而产生低级目标代码,该代码应具有以下最低限度的属性
- 它应该承载源代码的确切含义。
- 它应该在 CPU 使用率和内存管理方面高效。
我们现在将了解如何将中间代码转换为目标对象代码(在本例中为汇编代码)。
有向无环图
有向无环图 (DAG) 是一种工具,它描绘了基本块的结构,有助于查看值在基本块之间流动的过程,并提供优化功能。DAG 提供了对基本块的简单转换。这里可以理解 DAG
叶节点表示标识符、名称或常量。
内部节点表示运算符。
内部节点还表示表达式的结果或将值存储或赋值到的标识符/名称。
示例
t0 = a + b t1 = t0 + c d = t0 + t1
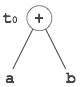
[t0 = a + b] |
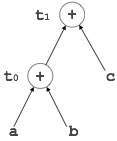
[t1 = t0 + c] |
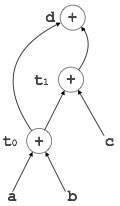
[d = t0 + t1] |
窥孔优化
此优化技术在源代码上本地工作以将其转换为优化后的代码。就本地而言,我们的意思是手头代码块的一小部分。这些方法可以应用于中间代码以及目标代码。分析一系列语句并检查以下可能的优化
冗余指令消除
在源代码级别,用户可以执行以下操作
int add_ten(int x)
{
int y, z;
y = 10;
z = x + y;
return z;
}
|
int add_ten(int x)
{
int y;
y = 10;
y = x + y;
return y;
}
|
int add_ten(int x)
{
int y = 10;
return x + y;
}
|
int add_ten(int x)
{
return x + 10;
}
|
在编译级别,编译器搜索本质上冗余的指令。即使删除其中一些指令,多条加载和存储指令也可能具有相同的含义。例如
- MOV x, R0
- MOV R0, R1
我们可以删除第一条指令并将句子重写为
MOV x, R1
不可达代码
不可达代码是程序代码的一部分,由于编程结构而永远不会被访问。程序员可能意外地编写了一段永远无法到达的代码。
示例
void add_ten(int x)
{
return x + 10;
printf(“value of x is %d”, x);
}
在此代码段中,printf 语句永远不会执行,因为程序控制在执行之前返回,因此可以删除printf。
控制流优化
在某些代码中,程序控制会在不执行任何重要任务的情况下来回跳转。可以删除这些跳转。考虑以下代码块
... MOV R1, R2 GOTO L1 ... L1 : GOTO L2 L2 : INC R1
在此代码中,可以删除标签 L1,因为它将控制权传递给 L2。因此,控制可以直接到达 L2,而不是跳转到 L1 然后跳转到 L2,如下所示
... MOV R1, R2 GOTO L2 ... L2 : INC R1
代数表达式简化
在某些情况下,代数表达式可以变得简单。例如,表达式a = a + 0 可以替换为a 本身,表达式 a = a + 1 可以简单地替换为 INC a。
强度削弱
有些操作会消耗更多时间和空间。可以通过用其他消耗更少时间和空间但产生相同结果的操作替换它们来降低它们的“强度”。
例如,x * 2 可以替换为x << 1,它只涉及一次左移。虽然 a * a 和 a2 的输出相同,但 a2 的实现效率更高。
访问机器指令
目标机器可以部署更复杂的指令,这些指令能够以更高效的方式执行特定操作。如果目标代码可以直接容纳这些指令,这不仅会提高代码质量,还会产生更高效的结果。
代码生成器
代码生成器需要了解目标机器的运行时环境及其指令集。代码生成器应考虑以下事项以生成代码
目标语言:代码生成器必须了解要转换代码的目标语言的性质。该语言可能提供一些特定于机器的指令来帮助编译器以更方便的方式生成代码。目标机器可以具有 CISC 或 RISC 处理器架构。
IR 类型:中间表示形式有多种形式。它可以是抽象语法树 (AST) 结构、逆波兰表示法或 3 地址代码。
指令选择:代码生成器将中间表示作为输入并将其转换为目标机器的指令集。一种表示形式可以有多种(指令)转换方式,因此代码生成器有责任明智地选择合适的指令。
寄存器分配:程序在执行期间需要维护许多值。目标机器的架构可能不允许所有值都保存在 CPU 内存或寄存器中。代码生成器决定将哪些值保存在寄存器中。此外,它决定使用哪些寄存器来保存这些值。
指令排序:最后,代码生成器决定指令的执行顺序。它创建指令调度以执行它们。
描述符
代码生成器在生成代码时必须跟踪寄存器(以获取可用性)和地址(值的存储位置)。对于两者,使用以下两个描述符
寄存器描述符:寄存器描述符用于通知代码生成器寄存器的可用性。寄存器描述符跟踪存储在每个寄存器中的值。每当在代码生成期间需要新寄存器时,都会咨询此描述符以获取寄存器可用性。
地址描述符:程序中使用的名称(标识符)的值在执行期间可能存储在不同的位置。地址描述符用于跟踪存储标识符值的内存位置。这些位置可能包括 CPU 寄存器、堆、栈、内存或上述位置的组合。
代码生成器实时更新这两个描述符。对于加载语句 LD R1, x,代码生成器
- 更新寄存器描述符 R1,其中包含 x 的值,并且
- 更新地址描述符 (x) 以显示 x 的一个实例在 R1 中。
代码生成
基本块包含一系列三地址指令。代码生成器将这些指令序列作为输入。
注意:如果名称的值存在于多个位置(寄存器、缓存或内存),则寄存器的值将优先于缓存和主内存。同样,缓存的值将优先于主内存。主内存几乎没有优先级。
getReg:代码生成器使用getReg 函数来确定可用寄存器的状态和名称值的存储位置。getReg 的工作原理如下
如果变量 Y 已经在寄存器 R 中,则使用该寄存器。
否则,如果某个寄存器 R 可用,则使用该寄存器。
否则,如果以上两种选择都不可能,则选择需要最少加载和存储指令的寄存器。
对于指令 x = y OP z,代码生成器可能会执行以下操作。假设 L 是要将 y OP z 的输出保存到的位置(最好是寄存器)
调用函数 getReg,以确定 L 的位置。
通过查阅y 的地址描述符来确定y 的当前位置(寄存器或内存)。如果y 当前不在寄存器L 中,则生成以下指令以将y 的值复制到L
MOV y’, L
其中y’表示y的复制值。
使用步骤 2 中用于y 的相同方法确定z 的当前位置,并生成以下指令
OP z’, L
其中z’表示z的复制值。
现在 L 包含 y OP z 的值,该值打算分配给x。因此,如果 L 是寄存器,则更新其描述符以指示它包含x的值。更新x的描述符以指示它存储在位置L处。
如果 y 和 z 以后不再使用,则可以将其返还给系统。
其他代码结构(如循环和条件语句)通常以通用汇编方式转换为汇编语言。