
- 编译器设计教程
- 编译器设计 - 首页
- 编译器设计 - 概述
- 编译器设计 - 架构
- 编译器设计 - 编译器的阶段
- 编译器设计 - 词法分析
- 编译器 - 正则表达式
- 编译器设计 - 有限自动机
- 编译器设计 - 语法分析
- 编译器设计 - 解析类型
- 编译器设计 - 自顶向下解析器
- 编译器设计 - 自底向上解析器
- 编译器设计 - 错误恢复
- 编译器设计 - 语义分析
- 编译器 - 运行时环境
- 编译器设计 - 符号表
- 编译器 - 中间代码
- 编译器设计 - 代码生成
- 编译器设计 - 代码优化
- 编译器设计有用资源
- 编译器设计 - 快速指南
- 编译器设计 - 有用资源
编译器设计 - 运行时环境
程序作为源代码仅仅是文本(代码、语句等)的集合,要使其运行,需要在目标机器上执行操作。程序需要内存资源来执行指令。程序包含过程的名称、标识符等,这些需要在运行时与实际内存位置进行映射。
运行时是指正在执行的程序。运行时环境是目标机器的状态,可能包括软件库、环境变量等,以向系统中运行的进程提供服务。
运行时支持系统是一个包,大部分与可执行程序本身一起生成,并促进进程与运行时环境之间的进程通信。它在程序执行期间负责内存分配和释放。
激活树
程序是由组合成多个过程的指令序列组成的。过程中的指令按顺序执行。过程有开始和结束分隔符,其内部的所有内容都称为过程的主体。过程标识符和其中的有限指令序列构成了过程的主体。
过程的执行称为其激活。激活记录包含调用过程所需的所有必要信息。激活记录可能包含以下单元(取决于使用的源语言)。
| 临时变量 | 存储表达式的临时值和中间值。 |
| 局部数据 | 存储被调用过程的局部数据。 |
| 机器状态 | 在调用过程之前存储机器状态,例如寄存器、程序计数器等。 |
| 控制链接 | 存储调用过程的激活记录的地址。 |
| 访问链接 | 存储超出局部范围的数据信息。 |
| 实际参数 | 存储实际参数,即用于向被调用过程发送输入的参数。 |
| 返回值 | 存储返回值。 |
每当执行一个过程时,它的激活记录都存储在堆栈上,也称为控制堆栈。当一个过程调用另一个过程时,调用者的执行将暂停,直到被调用过程完成执行。此时,被调用过程的激活记录存储在堆栈上。
我们假设程序控制以顺序方式流动,当调用一个过程时,其控制将转移到被调用过程。当被调用过程执行完毕后,它将控制返回给调用者。这种类型的控制流使更容易以树的形式表示一系列激活,称为**激活树**。
为了理解这个概念,我们以一段代码为例
. . .
printf(“Enter Your Name: “);
scanf(“%s”, username);
show_data(username);
printf(“Press any key to continue…”);
. . .
int show_data(char *user)
{
printf(“Your name is %s”, username);
return 0;
}
. . .
以下是给定代码的激活树。
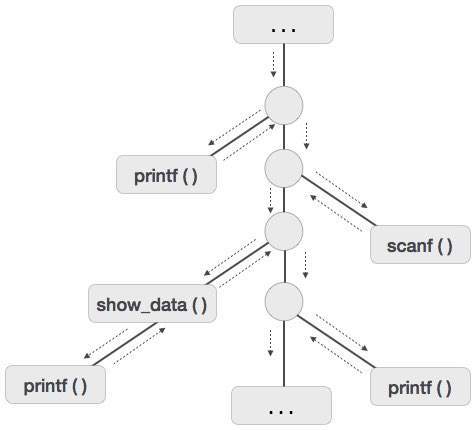
现在我们了解到过程是以深度优先的方式执行的,因此堆栈分配是最适合过程激活的存储形式。
存储分配
运行时环境管理以下实体的运行时内存需求
代码:它被称为程序的文本部分,在运行时不会改变。它的内存需求在编译时已知。
过程:它们的文本部分是静态的,但它们以随机方式被调用。这就是为什么使用堆栈存储来管理过程调用和激活。
变量:变量只有在运行时才知道,除非它们是全局变量或常量。堆内存分配方案用于管理运行时变量的内存分配和释放。
静态分配
在这种分配方案中,编译数据绑定到内存中的固定位置,并且在程序执行时不会更改。由于内存需求和存储位置是预先知道的,因此不需要用于内存分配和释放的运行时支持包。
堆栈分配
过程调用及其激活通过堆栈内存分配来管理。它采用后进先出 (LIFO) 方法,这种分配策略对于递归过程调用非常有用。
堆分配
过程的局部变量仅在运行时分配和释放。堆分配用于动态地为变量分配内存,并在不再需要变量时将其回收。
除了静态分配的内存区域外,堆栈和堆内存都可以动态且意外地增长和缩小。因此,系统不能为它们提供固定数量的内存。
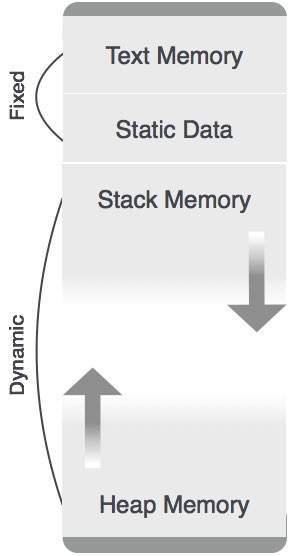
如上图所示,代码的文本部分分配了固定数量的内存。堆栈和堆内存排列在分配给程序的总内存的两端。两者都彼此相对地收缩和增长。
参数传递
过程之间的通信媒介称为参数传递。调用过程的变量值通过某种机制传递给被调用过程。在继续之前,首先了解一些与程序中值相关的基本术语。
右值 (r-value)
表达式的值称为其右值。如果单个变量出现在赋值运算符的右侧,则其包含的值也成为右值。右值总是可以赋值给其他变量。
左值 (l-value)
存储表达式的内存位置(地址)称为该表达式的左值。它总是出现在赋值运算符的左侧。
例如
day = 1; week = day * 7; month = 1; year = month * 12;
从这个例子中,我们了解到像 1、7、12 这样的常量值,以及像 day、week、month 和 year 这样的变量,都具有右值。只有变量具有左值,因为它们也表示分配给它们的内存位置。
例如
7 = x + y;
是一个左值错误,因为常量 7 不代表任何内存位置。
形式参数
接收调用过程传递的信息的变量称为形式参数。这些变量在被调用函数的定义中声明。
实际参数
其值或地址被传递给被调用过程的变量称为实际参数。这些变量在函数调用中作为参数指定。
示例
fun_one()
{
int actual_parameter = 10;
call fun_two(int actual_parameter);
}
fun_two(int formal_parameter)
{
print formal_parameter;
}
形式参数根据使用的参数传递技术持有实际参数的信息。它可以是值或地址。
按值传递
在按值传递机制中,调用过程传递实际参数的右值,编译器将其放入被调用过程的激活记录中。然后,形式参数持有调用过程传递的值。如果形式参数持有的值发生更改,则它不应影响实际参数。
按引用传递
在按引用传递机制中,实际参数的左值被复制到被调用过程的激活记录中。这样,被调用过程现在拥有实际参数的地址(内存位置),而形式参数指向相同的内存位置。因此,如果形式参数指向的值发生更改,则应该在实际参数上看到影响,因为它们也应该指向相同的值。
按复制-恢复传递
这种参数传递机制与“按引用传递”类似,只是实际参数的更改是在被调用过程结束时进行的。在函数调用时,实际参数的值被复制到被调用过程的激活记录中。如果操作形式参数,则不会对实际参数产生实时影响(因为传递了左值),但是当被调用过程结束时,形式参数的左值将被复制到实际参数的左值。
示例
int y;
calling_procedure()
{
y = 10;
copy_restore(y); //l-value of y is passed
printf y; //prints 99
}
copy_restore(int x)
{
x = 99; // y still has value 10 (unaffected)
y = 0; // y is now 0
}
当此函数结束时,形式参数 x 的左值将被复制到实际参数 y。即使在过程结束之前 y 的值发生更改,x 的左值也会被复制到 y 的左值,使其行为类似于按引用调用。
按名称传递
像 Algol 这样的语言提供了一种新的参数传递机制,它类似于 C 语言中的预处理器。在按名称传递机制中,被调用的过程的名称将被其实际主体替换。按名称传递在文本上将过程调用中的参数表达式替换为过程主体中的相应参数,以便它现在可以处理实际参数,就像按引用传递一样。