
- 编译器设计教程
- 编译器设计——主页
- 编译器设计——概览
- 编译器设计——架构
- 编译器设计——编译器阶段
- 编译器设计——词法分析
- 编译器——正则表达式
- 编译器设计——有限状态机
- 编译器设计——语法分析
- 编译器设计——解析类型
- 编译器设计——自顶向下解析器
- 编译器设计——自底向上解析器
- 编译器设计——错误恢复
- 编译器设计——语义分析
- 编译器——运行时环境
- 编译器设计——符号表
- 编译器——中间代码
- 编译器设计——代码生成
- 编译器设计——代码优化
- 编译器设计有用资源
- 编译器设计——快速指南
- 编译器设计——有用资源
编译器设计——解析类型
语法分析器遵循无上下文文法定义的产生规则。产生规则的实现方式(导出)将解析分为两种类型:自顶向下解析和自底向上解析。
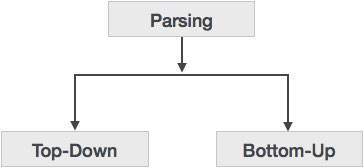
自顶向下解析
如果解析器开始使用起始符构建解析树,然后尝试将起始符转换为输入,则称之为自顶向下解析。
递归下降解析:这是自顶向下解析的一种常见形式。它被称为递归,因为它使用递归过程来处理输入。递归下降解析会回溯。
回溯:这意味着,如果某个产生规则的导出失败,语法分析器会使用同一产生规则的不同规则重新开始这一过程。此技巧可能会多次处理输入字符串以确定正确的产生规则。
自底向上解析
顾名思义,自底向上解析从输入符开始,尝试构建直到起始符的解析树。
示例
输入字符串:a + b * c
产生规则
S → E E → E + T E → E * T E → T T → id
让我们开始自底向上解析
a + b * c
读取输入并检查是否有任何产生规则与该输入匹配
a + b * c T + b * c E + b * c E + T * c E * c E * T E S
广告