- 数据挖掘教程
- 数据挖掘 - 首页
- 数据挖掘 - 概述
- 数据挖掘 - 任务
- 数据挖掘 - 问题
- 数据挖掘 - 评估
- 数据挖掘 - 术语
- 数据挖掘 - 知识发现
- 数据挖掘 - 系统
- 数据挖掘 - 查询语言
- 分类与预测
- 数据挖掘 - 决策树归纳
- 数据挖掘 - 贝叶斯分类
- 基于规则的分类
- 数据挖掘 - 分类方法
- 数据挖掘 - 聚类分析
- 数据挖掘 - 文本数据挖掘
- 数据挖掘 - 万维网挖掘
- 数据挖掘 - 应用与趋势
- 数据挖掘 - 主题
- 数据挖掘有用资源
- 数据挖掘 - 快速指南
- 数据挖掘 - 有用资源
- 数据挖掘 - 讨论
数据挖掘 - 分类与预测
有两种形式的数据分析可用于提取描述重要类别或预测未来数据趋势的模型。这两种形式如下:
- 分类
- 预测
分类模型预测类别类标签;预测模型预测连续值函数。例如,我们可以构建一个分类模型来将银行贷款申请分类为安全或有风险,或者构建一个预测模型来预测潜在客户在计算机设备上的支出(美元),给定他们的收入和职业。
什么是分类?
以下是数据分析任务为分类的示例:
银行贷款员希望分析数据,以了解哪些客户(贷款申请人)是有风险的,哪些是安全的。
公司的一位市场经理需要分析具有给定个人资料的客户,这些人会购买新电脑。
在以上两个例子中,都构建了一个模型或分类器来预测类别标签。这些标签对于贷款申请数据是“有风险”或“安全”,对于市场数据是“是”或“否”。
什么是预测?
以下是数据分析任务为预测的示例:
假设市场经理需要预测给定客户在其公司促销期间将花费多少钱。在这个例子中,我们关心的是预测一个数值。因此,数据分析任务是数值预测的一个例子。在这种情况下,将构建一个模型或预测器来预测一个连续值函数或有序值。
注意 - 回归分析是一种最常用于数值预测的统计方法。
分类是如何工作的?
借助我们上面讨论的银行贷款申请,让我们了解分类的工作原理。数据分类过程包括两个步骤:
- 构建分类器或模型
- 使用分类器进行分类
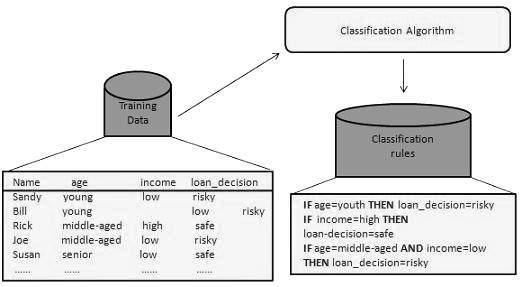
构建分类器或模型
此步骤是学习步骤或学习阶段。
在此步骤中,分类算法构建分类器。
分类器是由训练集构建的,训练集由数据库元组及其相关的类标签组成。
构成训练集的每个元组都被称为类别或类。这些元组也可以被称为样本、对象或数据点。
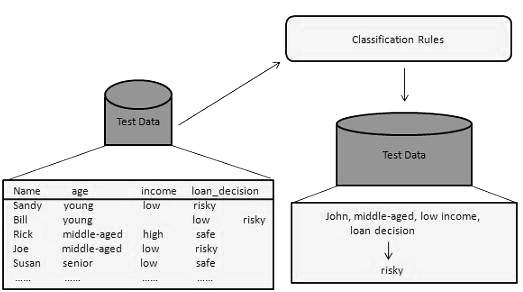
使用分类器进行分类
在此步骤中,分类器用于分类。这里使用测试数据来估计分类规则的准确性。如果准确性被认为是可以接受的,则可以将分类规则应用于新的数据元组。
分类和预测问题
主要问题是准备用于分类和预测的数据。准备数据涉及以下活动:
数据清洗 - 数据清洗包括去除噪声和处理缺失值。通过应用平滑技术去除噪声,并通过用该属性中最常出现的值替换缺失值来解决缺失值问题。
相关性分析 - 数据库也可能包含不相关的属性。相关性分析用于了解任何两个给定属性是否相关。
数据转换和约简 - 数据可以通过以下任何方法进行转换。
归一化 - 使用归一化转换数据。归一化涉及缩放给定属性的所有值,以使它们落在一个小指定的范围内。当在学习步骤中使用神经网络或涉及测量的方法时,使用归一化。
泛化 - 数据也可以通过将其泛化到更高的概念来转换。为此,我们可以使用概念层次结构。
注意 - 数据也可以通过其他一些方法进行约简,例如小波变换、分箱、直方图分析和聚类。
分类和预测方法的比较
以下是比较分类和预测方法的标准:
准确性 - 分类器的准确性是指分类器的能力。它正确预测类标签,预测器的准确性是指给定预测器能够多好地猜测新数据的预测属性的值。
速度 - 这指的是生成和使用分类器或预测器的计算成本。
稳健性 - 它指的是分类器或预测器从给定噪声数据中进行正确预测的能力。
可扩展性 - 可扩展性是指有效构建分类器或预测器的能力;给定大量数据。
可解释性 - 它指的是分类器或预测器在多大程度上易于理解。