- 数据挖掘教程
- 数据挖掘 - 首页
- 数据挖掘 - 概述
- 数据挖掘 - 任务
- 数据挖掘 - 问题
- 数据挖掘 - 评估
- 数据挖掘 - 术语
- 数据挖掘 - 知识发现
- 数据挖掘 - 系统
- 数据挖掘 - 查询语言
- 分类与预测
- 数据挖掘 - 决策树归纳
- 数据挖掘 - 贝叶斯分类
- 基于规则的分类
- 数据挖掘 - 分类方法
- 数据挖掘 - 聚类分析
- 数据挖掘 - 文本数据挖掘
- 数据挖掘 - 万维网挖掘
- 数据挖掘 - 应用与趋势
- 数据挖掘 - 主题
- 数据挖掘有用资源
- 数据挖掘 - 快速指南
- 数据挖掘 - 有用资源
- 数据挖掘 - 讨论
数据挖掘 - 快速指南
数据挖掘 - 概述
信息产业中存在大量可用数据。在将这些数据转换为有用的信息之前,这些数据毫无用处。有必要分析这些海量数据并从中提取有用的信息。
信息提取并非我们唯一需要执行的过程;数据挖掘还涉及其他过程,例如数据清洗、数据集成、数据转换、数据挖掘、模式评估和数据呈现。一旦所有这些过程完成,我们就可以将这些信息用于许多应用程序,例如欺诈检测、市场分析、生产控制、科学探索等。
什么是数据挖掘?
数据挖掘被定义为从海量数据集中提取信息。换句话说,我们可以说数据挖掘是从数据中挖掘知识的过程。因此提取的信息或知识可用于以下任何应用程序:
- 市场分析
- 欺诈检测
- 客户留存
- 生产控制
- 科学探索
数据挖掘应用
数据挖掘在以下领域非常有用:
- 市场分析和管理
- 公司分析与风险管理
- 欺诈检测
除此之外,数据挖掘还可用于生产控制、客户留存、科学探索、体育、占星术和互联网网络冲浪援助等领域。
市场分析和管理
以下是数据挖掘应用的各个市场领域:
客户画像 - 数据挖掘有助于确定什么样的人购买什么类型的产品。
识别客户需求 - 数据挖掘有助于识别不同客户的最佳产品。它利用预测来寻找可能吸引新客户的因素。
交叉市场分析 - 数据挖掘执行产品销售之间的关联/相关性。
目标营销 - 数据挖掘有助于找到具有相同特征(例如兴趣、消费习惯、收入等)的模式客户群。
确定客户购买模式 - 数据挖掘有助于确定客户购买模式。
提供汇总信息 - 数据挖掘为我们提供了各种多维汇总报告。
公司分析和风险管理
数据挖掘应用于公司部门的以下领域:
财务规划和资产评估 - 它涉及现金流量分析和预测,使用或有债权分析来评估资产。
资源规划 - 它涉及总结和比较资源和支出。
竞争 - 它涉及监控竞争对手和市场方向。
欺诈检测
数据挖掘也用于信用卡服务和电信领域以检测欺诈。在欺诈电话呼叫中,它有助于找到呼叫目的地、呼叫时长、一天或一周中的时间等。它还会分析偏离预期规范的模式。
数据挖掘 - 任务
数据挖掘处理可以挖掘的模式类型。根据要挖掘的数据类型,数据挖掘中涉及两种类型的功能:
- 描述性
- 分类和预测
描述性功能
描述性功能处理数据库中数据的通用属性。以下是描述性功能的列表:
- 类/概念描述
- 频繁模式挖掘
- 关联挖掘
- 相关性挖掘
- 聚类挖掘
类/概念描述
类/概念是指与类或概念相关联的数据。例如,在一个公司中,销售项目的类别包括计算机和打印机,客户的概念包括大额支出者和预算支出者。这类或概念的描述称为类/概念描述。这些描述可以通过以下两种方式得出:
数据特征化 - 这指的是总结所研究类别的的数据。这个被研究的类别称为目标类别。
数据区分 - 它指的是将一个类别与一些预定义的组或类别进行映射或分类。
频繁模式挖掘
频繁模式是指在事务数据中频繁出现的模式。以下是频繁模式类型的列表:
频繁项集 - 它指的是一组经常一起出现的项目,例如牛奶和面包。
频繁子序列 - 经常出现的模式序列,例如购买相机后接着购买存储卡。
频繁子结构 - 子结构指的是不同的结构形式,例如图、树或格,它们可以与项集或子序列组合。
关联挖掘
关联用于零售销售,以识别经常一起购买的模式。此过程指的是揭示数据之间关系并确定关联规则的过程。
例如,零售商生成一条关联规则,表明 70% 的时间牛奶与面包一起销售,只有 30% 的时间饼干与面包一起销售。
相关性挖掘
这是一种附加分析,用于揭示关联属性值对或两个项目集之间有趣的统计相关性,以分析它们是否对彼此产生积极、消极或没有影响。
聚类挖掘
聚类是指一组类似的对象。聚类分析是指形成彼此非常相似但与其他聚类中的对象高度不同的对象组。
分类和预测
分类是寻找描述数据类别或概念的模型的过程。目的是能够使用此模型来预测类标签未知的对象的类别。此派生模型基于对训练数据集的分析。派生模型可以以下列形式呈现:
- 分类(IF-THEN)规则
- 决策树
- 数学公式
- 神经网络
参与这些过程的功能列表如下:
分类 - 它预测类标签未知的对象的类别。其目标是找到一个派生模型来描述和区分数据类别或概念。派生模型基于训练数据集的分析,即类标签众所周知的 data 对象。
预测 - 它用于预测缺失或不可用的数值数据值,而不是类标签。回归分析通常用于预测。预测也可用于根据可用数据识别分布趋势。
异常值分析 - 异常值可以定义为不符合可用数据的通用行为或模型的数据对象。
演化分析 - 演化分析指的是描述和模拟行为随时间变化的对象的规律或趋势。
数据挖掘任务基元
- 我们可以以数据挖掘查询的形式指定数据挖掘任务。
- 此查询是输入到系统的。
- 数据挖掘查询是根据数据挖掘任务基元定义的。
注意 - 这些基元允许我们以交互方式与数据挖掘系统进行通信。以下是数据挖掘任务基元的列表:
- 要挖掘的任务相关数据集。
- 要挖掘的知识类型。
- 要在发现过程中使用的背景知识。
- 模式评估的有趣性度量和阈值。
- 可视化发现模式的表示。
要挖掘的任务相关数据集
这是用户感兴趣的数据库部分。此部分包括以下内容:
- 数据库属性
- 感兴趣的数据仓库维度
要挖掘的知识类型
它指的是要执行的功能类型。这些功能是:
- 特征化
- 区分
- 关联和相关性分析
- 分类
- 预测
- 聚类
- 异常值分析
- 演化分析
背景知识
背景知识允许在多个抽象级别挖掘数据。例如,概念层次结构是允许在多个抽象级别挖掘数据的背景知识之一。
模式评估的有趣性度量和阈值
这用于评估知识发现过程发现的模式。不同类型的知识有不同的有趣性度量。
可视化发现模式的表示
这指的是要显示发现模式的形式。这些表示可能包括以下内容:
- 规则
- 表格
- 图表
- 图形
- 决策树
- 多维数据集
数据挖掘 - 问题
数据挖掘并非易事,因为所使用的算法可能非常复杂,而且数据并不总是位于一个地方。它需要从各种异构数据源集成。这些因素也带来了一些问题。在本教程中,我们将讨论以下主要问题:
- 挖掘方法和用户交互
- 性能问题
- 各种数据类型问题
下图描述了主要问题。
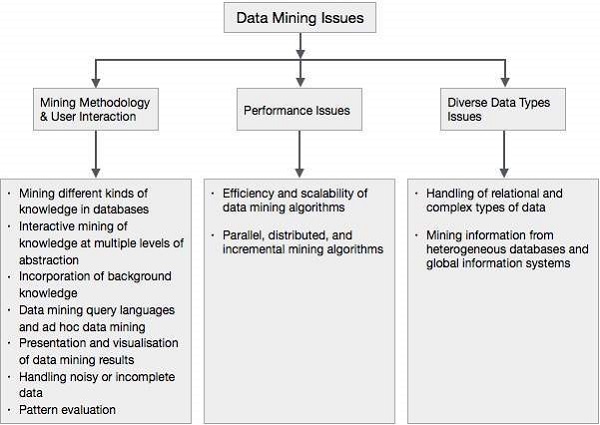
挖掘方法和用户交互问题
它指的是以下几种问题:
挖掘数据库中不同类型的知识 - 不同的用户可能对不同类型的知识感兴趣。因此,数据挖掘需要涵盖广泛的知识发现任务。
在多个抽象级别上交互式挖掘知识 - 数据挖掘过程需要是交互式的,因为它允许用户专注于模式搜索,根据返回的结果提供和改进数据挖掘请求。
结合背景知识 - 为指导发现过程并表达发现的模式,可以使用背景知识。背景知识不仅可以用简洁的术语表达发现的模式,而且可以在多个抽象级别上表达。
数据挖掘查询语言和 ad hoc 数据挖掘 - 允许用户描述 ad hoc 挖掘任务的数据挖掘查询语言应与数据仓库查询语言集成,并针对高效灵活的数据挖掘进行优化。
数据挖掘结果的呈现和可视化 - 一旦发现模式,就需要用高级语言和可视化表示来表达。这些表示应该易于理解。
处理噪声或不完整数据 - 在挖掘数据规律时,需要数据清洗方法来处理噪声和不完整对象。如果没有数据清洗方法,则发现模式的准确性会很差。
模式评估 − 发现的模式应该是有趣的,因为它们要么代表常识,要么缺乏新颖性。
性能问题
可能存在以下与性能相关的問題:
数据挖掘算法的效率和可扩展性 − 为了有效地从数据库中海量数据中提取信息,数据挖掘算法必须高效且可扩展。
并行、分布式和增量挖掘算法 − 数据库规模巨大、数据广泛分布以及数据挖掘方法复杂等因素推动了并行和分布式数据挖掘算法的发展。这些算法将数据划分成多个分区,然后并行处理。之后,将各个分区的结果合并。增量算法则更新数据库,而无需从头开始重新挖掘数据。
各种数据类型问题
关系型和复杂类型数据的处理 − 数据库可能包含复杂数据对象、多媒体数据对象、空间数据、时间数据等。一个系统不可能挖掘所有这些类型的数据。
从异构数据库和全球信息系统中挖掘信息 − 数据存在于局域网或广域网上不同的数据源中。这些数据源可能是结构化的、半结构化的或非结构化的。因此,从中挖掘知识给数据挖掘带来了挑战。
数据挖掘 - 评估
数据仓库
数据仓库具有以下特性,以支持管理层的决策过程:
面向主题 − 数据仓库面向主题,因为它提供围绕某个主题的信息,而不是组织的日常运营信息。这些主题可以是产品、客户、供应商、销售额、收入等。数据仓库不关注日常运营,而是关注数据的建模和分析以进行决策。
集成 − 数据仓库通过整合来自异构数据源(如关系数据库、平面文件等)的数据构建而成。这种集成增强了数据的有效分析。
随时间变化 − 数据仓库中收集的数据与特定时间段相关联。数据仓库中的数据提供了从历史角度来看的信息。
非易失性 − 非易失性意味着在添加新数据时不会删除以前的数据。数据仓库与操作数据库分开,因此操作数据库中的频繁更改不会反映在数据仓库中。
数据仓库技术
数据仓库技术是构建和使用数据仓库的过程。数据仓库通过整合来自多个异构数据源的数据构建而成。它支持分析报告、结构化和/或临时查询以及决策制定。
数据仓库技术涉及数据清洗、数据集成和数据整合。为了集成异构数据库,我们有以下两种方法:
- 查询驱动方法
- 更新驱动方法
查询驱动方法
这是集成异构数据库的传统方法。此方法用于在多个异构数据库之上构建包装器和集成器。这些集成器也称为中介器。
查询驱动方法的过程
当向客户端发出查询时,元数据字典会将查询转换为适合所涉及各个异构站点的查询。
现在这些查询被映射并发送到本地查询处理器。
来自异构站点的结果被集成到全局答案集中。
缺点
此方法具有以下缺点:
查询驱动方法需要复杂的集成和过滤过程。
对于频繁查询,它非常低效且非常昂贵。
对于需要聚合的查询,此方法成本很高。
更新驱动方法
当今的数据仓库系统遵循更新驱动方法,而不是前面讨论的传统方法。在更新驱动方法中,来自多个异构数据源的信息会预先集成并存储在仓库中。此信息可用于直接查询和分析。
优点
此方法具有以下优点:
此方法提供高性能。
数据可以在语义数据存储中预先复制、处理、集成、注释、汇总和重组。
查询处理不需要与本地源的处理进行交互。
从数据仓库 (OLAP) 到数据挖掘 (OLAM)
联机分析挖掘 (OLAM) 将联机分析处理 (OLAP) 与数据挖掘和多维数据库中的知识挖掘相结合。下图显示了 OLAP 和 OLAM 的集成:
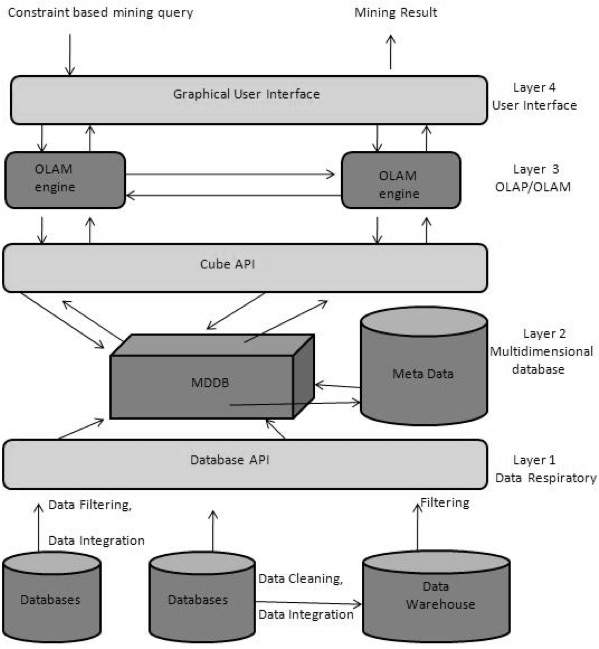
OLAM 的重要性
OLAM 重要的原因如下:
数据仓库中的高质量数据 − 数据挖掘工具需要处理集成、一致和清洗后的数据。这些步骤在数据预处理中非常昂贵。通过这种预处理构建的数据仓库是 OLAP 和数据挖掘的宝贵高质量数据源。
数据仓库周围可用的信息处理基础设施 − 信息处理基础设施是指访问、集成、整合和转换多个异构数据库、网络访问和服务设施、报告和 OLAP 分析工具。
基于 OLAP 的探索性数据分析 − 需要进行探索性数据分析才能有效进行数据挖掘。OLAM 提供了在不同数据子集和不同抽象级别上进行数据挖掘的功能。
数据挖掘功能的在线选择 − 将 OLAP 与多个数据挖掘功能和联机分析挖掘相结合,使用户能够灵活地选择所需的数据挖掘功能并动态地切换数据挖掘任务。
数据挖掘 - 术语
数据挖掘
数据挖掘定义为从海量数据集中提取信息。换句话说,我们可以说数据挖掘是从数据中挖掘知识。此信息可用于以下任何应用程序:
- 市场分析
- 欺诈检测
- 客户留存
- 生产控制
- 科学探索
数据挖掘引擎
数据挖掘引擎对于数据挖掘系统至关重要。它包含一组执行以下功能的功能模块:
- 特征化
- 关联和相关性分析
- 分类
- 预测
- 聚类分析
- 异常值分析
- 演化分析
知识库
这是领域知识。此知识用于指导搜索或评估结果模式的趣味性。
知识发现
有些人将数据挖掘与知识发现视为相同,而另一些人则将数据挖掘视为知识发现过程中的一个重要步骤。以下是知识发现过程涉及的步骤列表:
- 数据清洗
- 数据集成
- 数据选择
- 数据转换
- 数据挖掘
- 模式评估
- 知识呈现
用户界面
用户界面是数据挖掘系统中的模块,它有助于用户与数据挖掘系统之间的通信。用户界面允许以下功能:
- 通过指定数据挖掘查询任务来与系统交互。
- 提供信息以帮助集中搜索。
- 基于中间数据挖掘结果进行挖掘。
- 浏览数据库和数据仓库模式或数据结构。
- 评估挖掘的模式。
- 以不同的形式可视化模式。
数据集成
数据集成是一种数据预处理技术,它将来自多个异构数据源的数据合并到一个一致的数据存储中。数据集成可能涉及不一致的数据,因此需要数据清洗。
数据清洗
数据清洗是一种用于去除噪声数据和纠正数据中不一致性的技术。数据清洗涉及转换以纠正错误数据。数据清洗是在准备数据仓库的数据时作为数据预处理步骤执行的。
数据选择
数据选择是从数据库中检索与分析任务相关的数据的过程。有时在数据选择过程之前会执行数据转换和整合。
聚类
聚类是指一组类似的对象。聚类分析是指形成彼此非常相似但与其他聚类中的对象高度不同的对象组。
数据转换
在此步骤中,通过执行汇总或聚合操作,将数据转换为或整合为适合挖掘的形式。
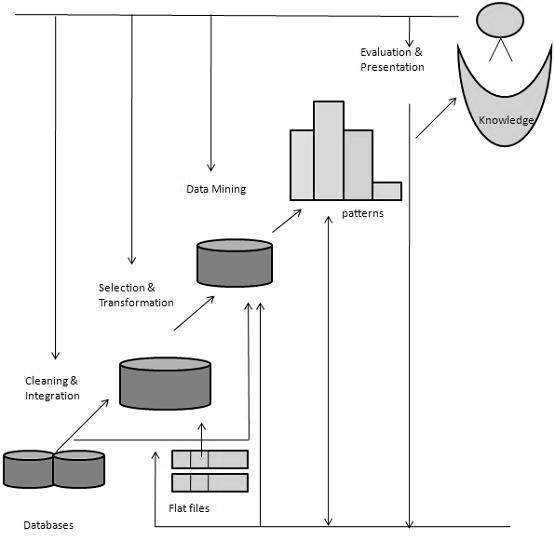
数据挖掘 - 知识发现
什么是知识发现?
有些人不会区分数据挖掘和知识发现,而另一些人则将数据挖掘视为知识发现过程中的一个重要步骤。以下是知识发现过程涉及的步骤列表:
数据清洗 − 在此步骤中,将删除噪声和不一致的数据。
数据集成 − 在此步骤中,将组合多个数据源。
数据选择 − 在此步骤中,将从数据库中检索与分析任务相关的数据。
数据转换 − 在此步骤中,通过执行汇总或聚合操作,将数据转换为或整合为适合挖掘的形式。
数据挖掘 − 在此步骤中,将应用智能方法以提取数据模式。
模式评估 − 在此步骤中,将评估数据模式。
知识呈现 − 在此步骤中,将表示知识。
下图显示了知识发现的过程:
数据挖掘 - 系统
有各种各样的数据挖掘系统可用。数据挖掘系统可以集成以下技术:
- 空间数据分析
- 信息检索
- 模式识别
- 图像分析
- 信号处理
- 计算机图形学
- Web 技术
- 商业
- 生物信息学
数据挖掘系统分类
数据挖掘系统可以根据以下标准进行分类:
- 数据库技术
- 统计学
- 机器学习
- 信息科学
- 可视化
- 其他学科
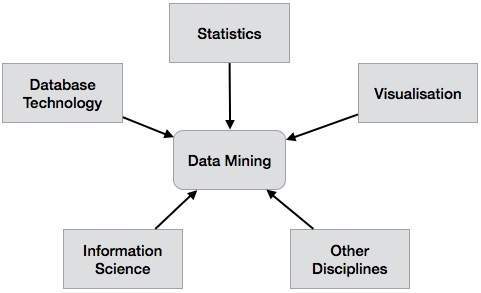
除此之外,数据挖掘系统还可以根据(a)挖掘的数据库类型、(b)挖掘的知识类型、(c)使用的技术以及(d)采用的应用程序进行分类。
基于挖掘的数据库的分类
我们可以根据挖掘的数据库类型对数据挖掘系统进行分类。数据库系统可以根据不同的标准进行分类,例如数据模型、数据类型等。数据挖掘系统也可以相应地进行分类。
例如,如果我们根据数据模型对数据库进行分类,那么我们可能会有关系型、事务型、对象关系型或数据仓库挖掘系统。
基于挖掘的知识类型的分类
我们可以根据挖掘的知识类型对数据挖掘系统进行分类。这意味着数据挖掘系统是根据以下功能进行分类的:
- 特征化
- 区分
- 关联和相关性分析
- 分类
- 预测
- 异常值分析
- 演化分析
基于所用技术的分类
我们可以根据使用的技术类型对数据挖掘系统进行分类。我们可以根据所涉及的用户交互程度或所采用的分析方法来描述这些技术。
基于所采用应用程序的分类
我们可以根据所采用的应用程序对数据挖掘系统进行分类。这些应用程序如下:
- 金融
- 电信
- DNA
- 股票市场
- 电子邮件
将数据挖掘系统与数据库/数据仓库系统集成
如果数据挖掘系统没有与数据库或数据仓库系统集成,那么将没有系统可以进行通信。这种方案被称为非耦合方案。在这种方案中,主要关注的是数据挖掘设计以及为挖掘可用数据集而开发高效且有效的算法。
集成方案列表如下:
无耦合 - 在此方案中,数据挖掘系统不使用任何数据库或数据仓库功能。它从特定来源获取数据,并使用一些数据挖掘算法处理这些数据。数据挖掘结果存储在另一个文件中。
松耦合 - 在此方案中,数据挖掘系统可能会使用数据库和数据仓库系统的一些功能。它从这些系统管理的数据存储库中获取数据,并对这些数据执行数据挖掘。然后,它将挖掘结果存储在文件中,或数据库或数据仓库中的指定位置。
半紧耦合 - 在此方案中,数据挖掘系统与数据库或数据仓库系统链接,此外,可以在数据库中提供一些数据挖掘原语的高效实现。
紧耦合 - 在这种耦合方案中,数据挖掘系统被平滑地集成到数据库或数据仓库系统中。数据挖掘子系统被视为信息系统的一个功能组件。
数据挖掘 - 查询语言
Han、Fu、Wang 等人针对 DBMiner 数据挖掘系统提出了数据挖掘查询语言 (DMQL)。数据挖掘查询语言实际上是基于结构化查询语言 (SQL) 的。可以设计数据挖掘查询语言来支持临时和交互式数据挖掘。此 DMQL 提供用于指定原语的命令。DMQL 也可以与数据库和数据仓库一起使用。DMQL 可用于定义数据挖掘任务。我们特别研究了如何在 DMQL 中定义数据仓库和数据仓储。
任务相关数据规范的语法
以下是用于指定任务相关数据的 DMQL 语法:
use database database_name or use data warehouse data_warehouse_name in relevance to att_or_dim_list from relation(s)/cube(s) [where condition] order by order_list group by grouping_list
指定知识类型的语法
在这里,我们将讨论表征、区分、关联、分类和预测的语法。
特征化
表征的语法是:
mine characteristics [as pattern_name]
analyze {measure(s) }
analyze 子句指定聚合度量,例如 count、sum 或 count%。
例如:
Description describing customer purchasing habits. mine characteristics as customerPurchasing analyze count%
区分
区分的语法是:
mine comparison [as {pattern_name]}
For {target_class } where {t arget_condition }
{versus {contrast_class_i }
where {contrast_condition_i}}
analyze {measure(s) }
例如,用户可以将大额消费者定义为平均每次购买商品价格超过 100 美元的顾客;将预算消费者定义为平均每次购买商品价格低于 100 美元的顾客。可以使用 DMQL 指定对来自这些类别中每个类别的客户的判别性描述的挖掘:
mine comparison as purchaseGroups for bigSpenders where avg(I.price) ≥$100 versus budgetSpenders where avg(I.price)< $100 analyze count
关联
关联的语法是:
mine associations [ as {pattern_name} ]
{matching {metapattern} }
例如:
mine associations as buyingHabits matching P(X:customer,W) ^ Q(X,Y) ≥ buys(X,Z)
其中 X 是客户关系的键;P 和 Q 是谓词变量;W、Y 和 Z 是对象变量。
分类
分类的语法是:
mine classification [as pattern_name] analyze classifying_attribute_or_dimension
例如,要挖掘模式,对客户信用评级进行分类,其中类别由属性 credit_rating 确定,并确定挖掘分类为 classifyCustomerCreditRating。
analyze credit_rating
预测
预测的语法是:
mine prediction [as pattern_name]
analyze prediction_attribute_or_dimension
{set {attribute_or_dimension_i= value_i}}
概念层次结构规范的语法
要指定概念层次结构,请使用以下语法:
use hierarchy <hierarchy> for <attribute_or_dimension>
我们使用不同的语法来定义不同类型的层次结构,例如:
-schema hierarchies
define hierarchy time_hierarchy on date as [date,month quarter,year]
-
set-grouping hierarchies
define hierarchy age_hierarchy for age on customer as
level1: {young, middle_aged, senior} < level0: all
level2: {20, ..., 39} < level1: young
level3: {40, ..., 59} < level1: middle_aged
level4: {60, ..., 89} < level1: senior
-operation-derived hierarchies
define hierarchy age_hierarchy for age on customer as
{age_category(1), ..., age_category(5)}
:= cluster(default, age, 5) < all(age)
-rule-based hierarchies
define hierarchy profit_margin_hierarchy on item as
level_1: low_profit_margin < level_0: all
if (price - cost)< $50
level_1: medium-profit_margin < level_0: all
if ((price - cost) > $50) and ((price - cost) ≤ $250))
level_1: high_profit_margin < level_0: all
兴趣度量规范的语法
用户可以使用以下语句指定兴趣度量和阈值:
with <interest_measure_name> threshold = threshold_value
例如:
with support threshold = 0.05 with confidence threshold = 0.7
模式呈现和可视化规范的语法
我们有一种语法,允许用户指定以一种或多种形式显示已发现的模式。
display as <result_form>
例如:
display as table
DMQL 的完整规范
作为一家公司的市场经理,您希望根据客户的年龄、购买的商品类型和购买商品的地点,来描述能够购买价格不低于 100 美元的商品的客户的购买习惯。您想知道拥有该特征的客户的百分比。特别是,您只对在加拿大购买并使用美国运通信用卡支付的商品感兴趣。您希望以表格形式查看生成的描述。
use database AllElectronics_db use hierarchy location_hierarchy for B.address mine characteristics as customerPurchasing analyze count% in relevance to C.age,I.type,I.place_made from customer C, item I, purchase P, items_sold S, branch B where I.item_ID = S.item_ID and P.cust_ID = C.cust_ID and P.method_paid = "AmEx" and B.address = "Canada" and I.price ≥ 100 with noise threshold = 5% display as table
数据挖掘语言标准化
数据挖掘语言的标准化将具有以下目的:
有助于系统地开发数据挖掘解决方案。
提高多个数据挖掘系统和功能之间的互操作性。
促进教育和快速学习。
促进数据挖掘系统在工业和社会中的应用。
数据挖掘 - 分类与预测
有两种形式的数据分析可用于提取描述重要类别或预测未来数据趋势的模型。这两种形式如下:
- 分类
- 预测
分类模型预测类别类别标签;预测模型预测连续值函数。例如,我们可以构建一个分类模型,将银行贷款申请分类为安全或有风险,或者构建一个预测模型,根据潜在客户的收入和职业来预测他们在计算机设备上的支出(美元)。
什么是分类?
以下是数据分析任务为分类的情况示例:
银行贷款经理想要分析数据,以了解哪些客户(贷款申请人)有风险,哪些客户安全。
公司市场经理需要分析具有给定配置文件的客户,哪些客户会购买新电脑。
在以上两个示例中,都构建了一个模型或分类器来预测类别标签。这些标签对于贷款申请数据来说是风险或安全,对于营销数据来说是肯定或否定。
什么是预测?
以下是数据分析任务为预测的情况示例:
假设市场经理需要预测给定客户在其公司促销期间将花费多少。在这个例子中,我们关心的是预测一个数值。因此,数据分析任务是数值预测的示例。在这种情况下,将构建一个模型或预测器,该模型或预测器预测一个连续值函数或有序值。
注意 - 回归分析是一种统计方法,最常用于数值预测。
分类是如何工作的?
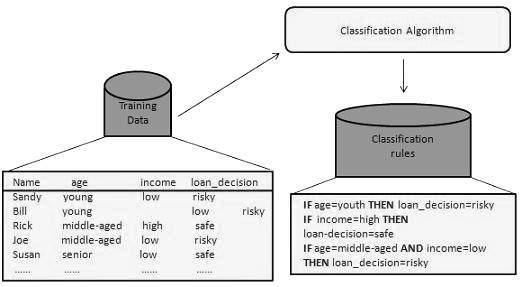
借助我们上面讨论过的银行贷款申请,让我们了解分类的工作原理。数据分类过程包括两个步骤:
- 构建分类器或模型
- 使用分类器进行分类
构建分类器或模型
此步骤是学习步骤或学习阶段。
在此步骤中,分类算法构建分类器。
分类器是由训练集构建的,训练集由数据库元组及其相关的类别标签组成。
构成训练集的每个元组被称为类别。这些元组也可以被称为样本、对象或数据点。
使用分类器进行分类
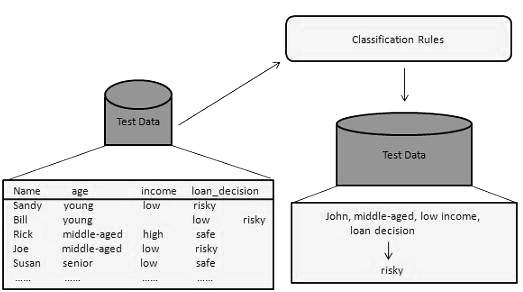
在此步骤中,分类器用于分类。在这里,测试数据用于估计分类规则的准确性。如果准确性被认为是可以接受的,则可以将分类规则应用于新的数据元组。
分类和预测问题
主要问题是准备用于分类和预测的数据。准备数据涉及以下活动:
数据清洗 - 数据清洗包括去除噪声和处理缺失值。通过应用平滑技术去除噪声,并通过用该属性中最常出现的值替换缺失值来解决缺失值问题。
相关性分析 - 数据库也可能包含不相关的属性。相关性分析用于了解任何两个给定属性是否相关。
数据转换和约简 - 数据可以通过以下任何方法进行转换。
归一化 - 使用归一化转换数据。归一化包括缩放给定属性的所有值,以使它们落在一个小指定的范围内。当在学习步骤中使用神经网络或涉及测量的方法时,使用归一化。
泛化 - 数据也可以通过将其泛化到更高的概念来转换。为此,我们可以使用概念层次结构。
注意 - 数据也可以通过其他一些方法进行约简,例如小波变换、分箱、直方图分析和聚类。
分类和预测方法的比较
以下是比较分类和预测方法的标准:
准确性 - 分类器的准确性是指分类器的能力。它可以正确预测类别标签,预测器的准确性是指给定预测器能够多好地猜测新数据的预测属性的值。
速度 - 这指的是生成和使用分类器或预测器的计算成本。
鲁棒性 - 它指的是分类器或预测器从给定噪声数据中进行正确预测的能力。
可扩展性 - 可扩展性是指有效构建分类器或预测器;给定大量数据。
可解释性 - 它指的是分类器或预测器理解的程度。
数据挖掘 - 决策树归纳
决策树是一种包含根节点、分支和叶节点的结构。每个内部节点表示对属性的测试,每个分支表示测试的结果,每个叶节点都包含一个类别标签。树中最顶部的节点是根节点。
以下决策树用于概念 buy_computer,该概念指示公司客户是否可能购买电脑。每个内部节点表示对属性的测试。每个叶节点都表示一个类别。
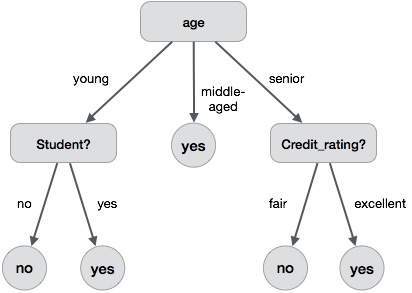
决策树的优点如下:
- 它不需要任何领域知识。
- 易于理解。
- 决策树的学习和分类步骤简单快速。
决策树归纳算法
1980年,一位名叫J. Ross Quinlan的机器学习研究人员开发了一种名为ID3(迭代二分器)的决策树算法。后来,他提出了C4.5,它是ID3的继任者。ID3和C4.5采用贪婪算法。在这个算法中,没有回溯;树木以自顶向下的递归分治方式构建。
Generating a decision tree form training tuples of data partition D
Algorithm : Generate_decision_tree
Input:
Data partition, D, which is a set of training tuples
and their associated class labels.
attribute_list, the set of candidate attributes.
Attribute selection method, a procedure to determine the
splitting criterion that best partitions that the data
tuples into individual classes. This criterion includes a
splitting_attribute and either a splitting point or splitting subset.
Output:
A Decision Tree
Method
create a node N;
if tuples in D are all of the same class, C then
return N as leaf node labeled with class C;
if attribute_list is empty then
return N as leaf node with labeled
with majority class in D;|| majority voting
apply attribute_selection_method(D, attribute_list)
to find the best splitting_criterion;
label node N with splitting_criterion;
if splitting_attribute is discrete-valued and
multiway splits allowed then // no restricted to binary trees
attribute_list = splitting attribute; // remove splitting attribute
for each outcome j of splitting criterion
// partition the tuples and grow subtrees for each partition
let Dj be the set of data tuples in D satisfying outcome j; // a partition
if Dj is empty then
attach a leaf labeled with the majority
class in D to node N;
else
attach the node returned by Generate
decision tree(Dj, attribute list) to node N;
end for
return N;
树剪枝
进行树剪枝是为了去除训练数据中由于噪声或异常值造成的异常。剪枝后的树更小,更简单。
树剪枝方法
有两种方法可以剪枝一棵树:
预剪枝 - 通过提前停止树的构建来剪枝。
后剪枝 - 此方法从完全生长的树中删除子树。
代价复杂度
代价复杂度由以下两个参数衡量:
- 树中叶子的数量,以及
- 树的错误率。
数据挖掘 - 贝叶斯分类
贝叶斯分类基于贝叶斯定理。贝叶斯分类器是统计分类器。贝叶斯分类器可以预测类成员概率,例如给定元组属于特定类的概率。
贝叶斯定理
贝叶斯定理以托马斯·贝叶斯命名。有两种类型的概率:
- 后验概率 [P(H/X)]
- 先验概率 [P(H)]
其中X是数据元组,H是一些假设。
根据贝叶斯定理,
贝叶斯信念网络
贝叶斯信念网络指定联合条件概率分布。它们也称为信念网络、贝叶斯网络或概率网络。
信念网络允许在变量子集之间定义类条件独立性。
它提供因果关系的图形模型,可以在其上进行学习。
我们可以使用训练好的贝叶斯网络进行分类。
定义贝叶斯信念网络的两个组成部分是:
- 有向无环图
- 一组条件概率表
有向无环图
- 有向无环图中的每个节点代表一个随机变量。
- 这些变量可能是离散值或连续值。
- 这些变量可能对应于数据中给出的实际属性。
有向无环图表示
下图显示了六个布尔变量的有向无环图。
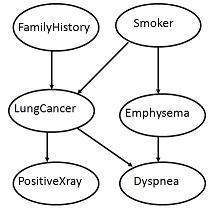
图中的弧允许表示因果知识。例如,肺癌受人的家族肺癌史以及该人是否吸烟的影响。值得注意的是,鉴于我们知道病人患有肺癌,变量PositiveXray与病人是否有家族肺癌史或病人是否吸烟无关。
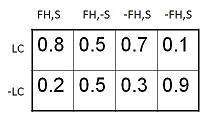
条件概率表
变量LungCancer (LC) 的值的条件概率表显示其父节点FamilyHistory (FH)和Smoker (S) 的值的每种可能组合,如下所示:
数据挖掘 - 基于规则的分类
IF-THEN规则
基于规则的分类器使用一组IF-THEN规则进行分类。我们可以用以下形式表达规则:
让我们考虑规则R1:
R1: IF age = youth AND student = yes THEN buy_computer = yes
要点:
规则的IF部分称为规则前件或前提条件。
规则的THEN部分称为规则后件。
前件部分的条件由一个或多个属性测试组成,这些测试在逻辑上是与操作。
后件部分包含类预测。
注意 - 我们也可以将规则R1写成如下形式:
R1: (age = youth) ^ (student = yes))(buys computer = yes)
如果条件对给定元组成立,则前件满足。
规则提取
在这里,我们将学习如何通过从决策树中提取IF-THEN规则来构建基于规则的分类器。
要点:
要从决策树中提取规则:
为从根节点到叶节点的每条路径创建一个规则。
为了形成规则前件,每个分裂标准都在逻辑上进行与操作。
叶节点保存类预测,形成规则后件。
使用顺序覆盖算法进行规则归纳
顺序覆盖算法可用于从训练数据中提取IF-THEN规则。我们不需要先生成决策树。在这个算法中,给定类的每个规则都覆盖该类的许多元组。
一些顺序覆盖算法包括AQ、CN2和RIPPER。根据一般策略,规则一次学习一个。每次学习规则时,都会删除该规则覆盖的元组,并对其余元组继续此过程。这是因为决策树中通向每个叶子的路径对应于一个规则。
注意 - 决策树归纳可以被认为是同时学习一组规则。
以下是顺序学习算法,其中规则一次学习一个类。当从类Ci学习规则时,我们希望该规则只覆盖来自类C的所有元组,而不覆盖来自任何其他类的任何元组。
Algorithm: Sequential Covering
Input:
D, a data set class-labeled tuples,
Att_vals, the set of all attributes and their possible values.
Output: A Set of IF-THEN rules.
Method:
Rule_set={ }; // initial set of rules learned is empty
for each class c do
repeat
Rule = Learn_One_Rule(D, Att_valls, c);
remove tuples covered by Rule form D;
until termination condition;
Rule_set=Rule_set+Rule; // add a new rule to rule-set
end for
return Rule_Set;
规则剪枝
由于以下原因进行规则剪枝:
在原始训练数据集上进行质量评估。该规则在训练数据上可能表现良好,但在后续数据上的表现较差。这就是需要规则剪枝的原因。
通过删除合取来剪枝规则。如果规则R的剪枝版本比在独立元组集上评估的质量更高,则剪枝规则R。
FOIL是一种简单有效的规则剪枝方法。对于给定的规则R,
其中pos和neg分别是R覆盖的正元组和负元组的数量。
注意 - 此值将随着R在剪枝集上的准确性提高而增加。因此,如果R的剪枝版本的FOIL_Prune值更高,则我们剪枝R。
其他分类方法
在这里,我们将讨论其他分类方法,例如遗传算法、粗糙集方法和模糊集方法。
遗传算法
遗传算法的思想源于自然进化。在遗传算法中,首先创建初始种群。这个初始种群由随机生成的规则组成。我们可以用位串表示每个规则。
例如,在给定的训练集中,样本由两个布尔属性(例如A1和A2)描述。这个给定的训练集包含两个类,例如C1和C2。
我们可以将规则IF A1 AND NOT A2 THEN C2编码成位串100。在这个位表示中,最左边的两位分别表示属性A1和A2。
同样,规则IF NOT A1 AND NOT A2 THEN C1可以编码为001。
注意 - 如果属性有K个值,其中K>2,那么我们可以使用K位来编码属性值。类也以相同的方式编码。
要点:
基于适者生存的概念,形成一个新的种群,该种群由当前种群中最适宜的规则及其后代值组成。
规则的适应度通过其在训练样本集上的分类准确性来评估。
应用遗传算子(如交叉和变异)来创建后代。
在交叉中,交换一对规则的子串以形成一对新的规则。
在变异中,规则字符串中随机选择的位被反转。
粗糙集方法
我们可以使用粗糙集方法来发现不精确和噪声数据中的结构关系。
注意 - 此方法只能应用于离散值属性。因此,必须在使用前离散化连续值属性。
粗糙集理论基于在给定的训练数据中建立等价类。构成等价类的元组是不可区分的。这意味着样本在描述数据的属性方面是相同的。
在给定的现实世界数据中,有一些类在可用属性方面无法区分。我们可以使用粗糙集来粗略地定义这些类。
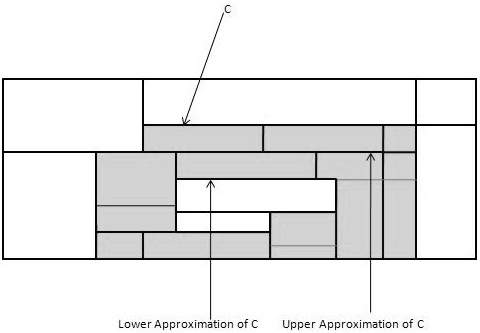
对于给定的类C,粗糙集定义由以下两个集合近似:
C的下近似 - C的下近似由所有数据元组组成,这些元组根据属性的知识,肯定属于类C。
C的上近似 - C的上近似由所有元组组成,这些元组根据属性的知识,不能描述为不属于C。
下图显示了类C的上近似和下近似:
模糊集方法
模糊集理论也称为可能性理论。该理论由Lotfi Zadeh于1965年提出,作为二值逻辑和概率论的替代方案。该理论允许我们在较高的抽象级别上工作。它还为我们处理数据的不精确测量提供了方法。
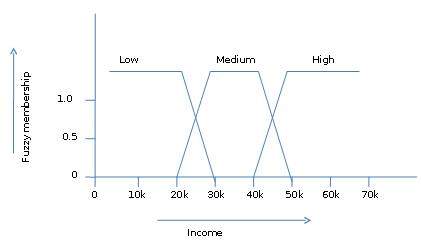
模糊集理论还允许我们处理模糊或不精确的事实。例如,成为高收入者集合的成员是不精确的(例如,如果50,000美元是高的,那么49,000美元和48,000美元呢)。与传统CRISP集不同,在传统CRISP集中,元素要么属于S要么属于其补集,但在模糊集理论中,元素可以属于多个模糊集。
例如,收入值49,000美元属于中等和高模糊集,但程度不同。此收入值的模糊集表示法如下:
mmedium_income($49k)=0.15 and mhigh_income($49k)=0.96
其中“m”是在中等收入和高收入的模糊集上运行的隶属函数。此表示法可以用图表表示如下:
数据挖掘 - 聚类分析
集群是一组属于同一类的对象。换句话说,相似的对象被分组到一个集群中,不相似的对象被分组到另一个集群中。
什么是聚类?
聚类是将一组抽象对象分组到相似对象类别的过程。
要点
数据对象的集群可以作为一个组对待。
在进行聚类分析时,我们首先根据数据相似性将数据集划分为组,然后为组分配标签。
聚类相对于分类的主要优点是它能够适应变化,并有助于挑选出区分不同组的有用特征。
聚类分析的应用
聚类分析广泛应用于许多应用中,例如市场研究、模式识别、数据分析和图像处理。
聚类还可以帮助营销人员发现其客户群中的不同群体。他们可以根据购买模式来描述其客户群体。
在生物学领域,它可以用来推导植物和动物分类法,对具有相似功能的基因进行分类,并深入了解群体中固有的结构。
聚类分析也有助于识别地球观测数据库中具有相似土地利用的区域。它还有助于根据房屋类型、价值和地理位置识别城市中各组房屋。
聚类分析还有助于对网络上的文档进行分类,以进行信息发现。
聚类分析也用于异常值检测应用,例如信用卡欺诈检测。
作为一种数据挖掘功能,聚类分析可作为一种工具来深入了解数据的分布,观察每个聚类的特征。
数据挖掘中聚类的需求
以下几点阐明了为什么数据挖掘中需要聚类:
可扩展性 - 我们需要高度可扩展的聚类算法来处理大型数据库。
处理不同类型属性的能力 - 算法应该能够应用于任何类型的数据,例如基于区间的(数值)数据、分类数据和二元数据。
发现具有属性形状的聚类 - 聚类算法应该能够检测任意形状的聚类。它们不应仅限于倾向于找到小型球形聚类的距离度量。
高维性 - 聚类算法不仅能够处理低维数据,还能够处理高维空间。
处理噪声数据的能力 - 数据库包含噪声、缺失或错误的数据。某些算法对这种数据很敏感,并可能导致质量差的聚类。
可解释性 - 聚类结果应具有可解释性、可理解性和可用性。
聚类方法
聚类方法可以分为以下几类:
- 划分方法
- 层次方法
- 基于密度的聚类方法
- 基于网格的方法
- 基于模型的方法
- 基于约束的方法
划分方法
假设我们得到一个包含“n”个对象的数据库,划分方法构造数据的“k”个划分。每个划分都代表一个聚类,且k ≤ n。这意味着它会将数据分类为k组,这些组满足以下要求:
每组至少包含一个对象。
每个对象必须恰好属于一个组。
要点:
对于给定的分区数(例如k),划分方法将创建一个初始划分。
然后,它使用迭代重定位技术通过将对象从一个组移动到另一个组来改进划分。
层次方法
此方法创建给定数据集对象的层次分解。我们可以根据层次分解的形成方式对层次方法进行分类。这里有两种方法:
- 凝聚法
- 分裂法
凝聚法
这种方法也称为自下而上的方法。在这里,我们从每个对象形成一个单独的组开始。它不断合并彼此靠近的对象或组。它会一直这样做,直到所有组合并成一个组,或者直到满足终止条件。
分裂法
这种方法也称为自上而下的方法。在这里,我们从同一聚类中的所有对象开始。在连续迭代中,一个聚类被分成更小的聚类。它一直向下进行,直到每个对象都在一个聚类中或满足终止条件。此方法是严格的,即一旦合并或拆分完成,就无法撤消。
改进层次聚类质量的方法
以下是用于提高层次聚类质量的两种方法:
仔细分析每个层次划分的对象链接。
通过首先使用层次凝聚算法将对象分组到微聚类,然后对微聚类执行宏聚类来集成层次凝聚。
基于密度的聚类方法
此方法基于密度的概念。其基本思想是,只要邻域中的密度超过某个阈值,就继续增长给定的聚类,即对于给定聚类中的每个数据点,给定聚类的半径必须至少包含最小数量的点。
基于网格的方法
在此方法中,对象一起形成一个网格。对象空间被量化为有限数量的单元格,形成网格结构。
优点
此方法的主要优点是处理速度快。
它仅取决于量化空间中每个维度中的单元格数量。
基于模型的方法
在此方法中,为每个聚类假设一个模型,以找到给定模型数据的最佳拟合。此方法通过聚类密度函数来定位聚类。它反映了数据点的空间分布。
此方法还提供了一种基于标准统计自动确定聚类数量的方法,同时考虑了异常值或噪声。因此,它产生了稳健的聚类方法。
基于约束的方法
在此方法中,通过结合用户或应用程序导向的约束来执行聚类。约束是指用户期望或所需聚类结果的属性。约束为我们提供了一种与聚类过程交互式通信的方法。约束可以由用户或应用程序需求指定。
数据挖掘 - 文本数据挖掘
文本数据库包含大量的文档集合。它们从新闻文章、书籍、数字图书馆、电子邮件、网页等多个来源收集这些信息。由于信息量的增加,文本数据库正在迅速增长。在许多文本数据库中,数据是半结构化的。
例如,文档可能包含一些结构化字段,例如标题、作者、出版日期等。但除了结构化数据外,文档还包含非结构化文本组件,例如摘要和内容。在不知道文档中可能包含什么内容的情况下,很难制定有效的查询来分析和提取数据中的有用信息。用户需要工具来比较文档并对其重要性和相关性进行排名。因此,文本挖掘已成为流行的主题,也是数据挖掘中的一个重要主题。
信息检索
信息检索处理从大量基于文本的文档中检索信息。一些数据库系统通常不存在于信息检索系统中,因为两者处理不同类型的数据。信息检索系统的示例包括:
- 在线图书馆目录系统
- 在线文档管理系统
- 网络搜索系统等。
注意 - 信息检索系统中的主要问题是根据用户的查询在文档集合中找到相关的文档。这种用户的查询包含一些描述信息需求的关键词。
在这种搜索问题中,用户主动从集合中提取相关信息。当用户有临时信息需求(即短期需求)时,这是合适的。但如果用户有长期信息需求,则检索系统也可以主动向用户推送任何新到的信息项。
这种访问信息的方式称为信息过滤。相应的系统被称为过滤系统或推荐系统。
文本检索的基本度量
我们需要检查系统在根据用户的输入检索多个文档时的准确性。将与查询相关的文档集合表示为{Relevant},将检索到的文档集合表示为{Retrieved}。相关且已检索到的文档集合可以表示为{Relevant} ∩ {Retrieved}。这可以用维恩图表示如下:
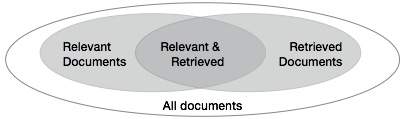
评估文本检索质量有三个基本度量:
- 精确率
- 召回率
- F1值
精确率
精确率是实际与查询相关的检索到的文档的百分比。精确率可以定义为:
Precision= |{Relevant} ∩ {Retrieved}| / |{Retrieved}|
召回率
召回率是实际与查询相关且已检索到的文档的百分比。召回率定义为:
Recall = |{Relevant} ∩ {Retrieved}| / |{Relevant}|
F1值
F1值是常用的权衡指标。信息检索系统通常需要权衡精确率或召回率,反之亦然。F1值定义为召回率或精确率的调和平均数,如下所示:
F-score = recall x precision / (recall + precision) / 2
数据挖掘 - 挖掘万维网
万维网包含大量信息,为数据挖掘提供了丰富的资源。
Web挖掘中的挑战
基于以下观察结果,Web对基于资源和知识的发现提出了巨大的挑战:
Web规模庞大 - Web的规模非常庞大,并且正在迅速增长。这似乎表明Web对于数据仓库和数据挖掘来说过于庞大。
网页的复杂性 - 网页没有统一的结构。与传统的文本文档相比,它们非常复杂。Web数字图书馆中有大量的文档。这些图书馆没有按照任何特定的排序顺序排列。
Web是动态信息源 - Web上的信息会迅速更新。新闻、股票市场、天气、体育、购物等数据会定期更新。
用户社区的多样性 - Web上的用户社区正在迅速扩大。这些用户具有不同的背景、兴趣和使用目的。有超过1亿个工作站连接到互联网,并且仍在迅速增长。
信息的关联性 - 人们认为,特定的人通常只对Web的一小部分感兴趣,而Web的其余部分包含与用户无关的信息,并可能淹没所需的结果。
挖掘网页布局结构
网页的基本结构基于文档对象模型 (DOM)。DOM结构指的是树状结构,其中页面中的HTML标签对应于DOM树中的节点。我们可以使用HTML中的预定义标签来分割网页。HTML语法灵活,因此网页不遵循W3C规范。不遵循W3C规范可能会导致DOM树结构出错。
DOM结构最初是为浏览器中的呈现而引入的,而不是为了描述网页的语义结构。DOM结构无法正确识别网页不同部分之间的语义关系。
基于视觉的页面分割 (VIPS)
VIPS的目的是根据网页的视觉呈现来提取其语义结构。
这种语义结构对应于树状结构。在此树中,每个节点对应于一个块。
为每个节点分配一个值。此值称为连贯性度。分配此值是为了根据视觉感知指示块中连贯的内容。
VIPS算法首先从HTML DOM树中提取所有合适的块。之后,它找到这些块之间的分隔符。
分隔符指的是网页中水平或垂直的线条,这些线条在视觉上与任何块都不相交。
网页的语义是在这些块的基础上构建的。
下图显示了VIPS算法的过程:
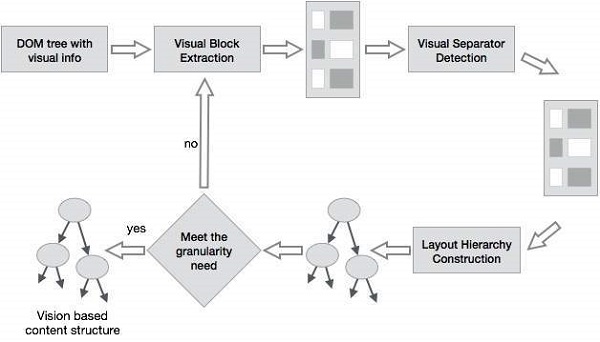
数据挖掘 - 应用与趋势
数据挖掘广泛应用于各个领域。目前有很多商业数据挖掘系统可用,但该领域仍面临许多挑战。在本教程中,我们将讨论数据挖掘的应用和趋势。
数据挖掘应用
以下是数据挖掘广泛应用的领域:
- 金融数据分析
- 零售业
- 电信行业
- 生物数据分析
- 其他科学应用
- 入侵检测
金融数据分析
银行和金融行业中的金融数据通常可靠且高质量,这有利于系统的数 据分析和数据挖掘。一些典型的案例如下:
为多维数据分析和数据挖掘设计和构建数据仓库。
贷款还款预测和客户信用政策分析。
对客户进行分类和聚类以进行目标营销。
检测洗钱和其他金融犯罪。
零售业
数据挖掘在零售业有着广泛的应用,因为它从销售、客户购买历史、商品运输、消费和服务等方面收集大量数据。由于网络的易用性、可用性和普及性不断提高,所收集的数据量自然会继续快速增长。
零售业中的数据挖掘有助于识别客户购买模式和趋势,从而提高客户服务质量,提高客户留存率和满意度。以下是零售业中数据挖掘示例的列表:
基于数据挖掘的优势设计和构建数据仓库。
对销售、客户、产品、时间和区域进行多维分析。
分析销售活动的效果。
客户留存。
产品推荐和商品交叉参考。
电信行业
如今,电信行业是发展最快的行业之一,提供传真、寻呼机、手机、互联网即时通讯、图像、电子邮件、网络数据传输等各种服务。由于新型计算机和通信技术的进步,电信行业正在快速扩张。这就是为什么数据挖掘对于帮助和理解业务变得非常重要的原因。
电信行业中的数据挖掘有助于识别电信模式,发现欺诈活动,更好地利用资源,并提高服务质量。以下是数据挖掘改进电信服务的示例列表:
电信数据的多分维分析。
欺诈模式分析。
识别异常模式。
多分维关联和顺序模式分析。
移动电信服务。
在电信数据分析中使用可视化工具。
生物数据分析
近年来,我们在基因组学、蛋白质组学、功能基因组学和生物医学研究等生物学领域取得了巨大发展。生物数据挖掘是生物信息学中非常重要的一部分。以下是数据挖掘对生物数据分析的贡献方面:
异构分布式基因组学和蛋白质组学数据库的语义集成。
比对、索引、相似性搜索和多个核苷酸序列的比较分析。
发现结构模式和分析基因网络和蛋白质通路。
关联和路径分析。
基因数据分析中的可视化工具。
其他科学应用
上述讨论的应用倾向于处理相对较小且同质的数据集,统计技术适合这些数据集。从地球科学、天文学等科学领域收集了大量数据。由于气候和生态系统建模、化学工程、流体动力学等各个领域的快速数值模拟,正在生成大量数据集。以下是数据挖掘在科学应用领域的应用:
- 数据仓库和数据预处理。
- 基于图的挖掘。
- 可视化和领域特定知识。
入侵检测
入侵是指任何威胁网络资源的完整性、机密性或可用性的行为。在这个互联互通的世界中,安全已成为主要问题。随着互联网使用量的增加以及入侵和攻击网络的工具和技巧的可用性,入侵检测已成为网络管理的关键组成部分。以下是数据挖掘技术可用于入侵检测的领域:
开发用于入侵检测的数据挖掘算法。
关联和相关分析、聚合,有助于选择和构建区分属性。
流数据分析。
分布式数据挖掘。
可视化和查询工具。
数据挖掘系统产品
有很多数据挖掘系统产品和特定领域的数据挖掘应用程序。新的数据挖掘系统和应用程序正在添加到以前的系统中。此外,人们还在努力标准化数据挖掘语言。
选择数据挖掘系统
数据挖掘系统的选择取决于以下特性:
数据类型 - 数据挖掘系统可以处理格式化文本、基于记录的数据和关系数据。数据也可以是ASCII文本、关系数据库数据或数据仓库数据。因此,我们应该检查数据挖掘系统可以处理的确切格式。
系统问题 - 我们必须考虑数据挖掘系统与不同操作系统的兼容性。一个数据挖掘系统可能只在一个操作系统上运行,也可能在多个操作系统上运行。还有一些数据挖掘系统提供基于 Web 的用户界面,并允许 XML 数据作为输入。
数据源 - 数据源指的是数据挖掘系统将运行的数据格式。一些数据挖掘系统可能只在 ASCII 文本文件上工作,而另一些则在多个关系源上工作。数据挖掘系统还应该支持 ODBC 连接或用于 ODBC 连接的 OLE DB。
数据挖掘功能和方法 - 一些数据挖掘系统只提供一种数据挖掘功能,例如分类,而另一些则提供多种数据挖掘功能,例如概念描述、发现驱动的 OLAP 分析、关联挖掘、关联分析、统计分析、分类、预测、聚类、异常值分析、相似性搜索等。
将数据挖掘与数据库或数据仓库系统耦合 - 数据挖掘系统需要与数据库或数据仓库系统耦合。耦合的组件集成到统一的信息处理环境中。以下是列出的耦合类型:
- 无耦合
- 松耦合
- 半紧耦合
- 紧耦合
可扩展性 - 数据挖掘中存在两个可扩展性问题:
行(数据库大小)可扩展性 - 当行数扩大 10 倍时,数据挖掘系统被认为是行可扩展的。执行查询的时间不超过 10 倍。
列(维度)可扩展性 - 如果挖掘查询执行时间随列数线性增加,则数据挖掘系统被认为是列可扩展的。
可视化工具 - 数据挖掘中的可视化可以分为以下几类:
- 数据可视化
- 挖掘结果可视化
- 挖掘过程可视化
- 视觉数据挖掘
数据挖掘查询语言和图形用户界面 - 易于使用的图形用户界面对于促进用户引导的交互式数据挖掘非常重要。与关系数据库系统不同,数据挖掘系统不共享底层数据挖掘查询语言。
数据挖掘趋势
数据挖掘概念仍在不断发展,以下是我们在该领域看到的最新趋势:
应用探索。
可扩展且交互式的数据挖掘方法。
将数据挖掘与数据库系统、数据仓库系统和 Web 数据库系统集成。
数据挖掘查询语言的标准化。
视觉数据挖掘。
挖掘复杂类型数据的新方法。
生物数据挖掘。
数据挖掘和软件工程。
网络挖掘。
分布式数据挖掘。
实时数据挖掘。
多数据库数据挖掘。
数据挖掘中的隐私保护和信息安全。
数据挖掘 - 主题
数据挖掘的理论基础
数据挖掘的理论基础包括以下概念:
数据约简 - 该理论的基本思想是减少数据表示,它以精度换取速度,以响应对非常大的数据库上的查询快速获得近似答案的需求。一些数据约简技术如下:
奇异值分解
小波
回归
对数线性模型
直方图
聚类
抽样
索引树的构建
数据压缩 - 该理论的基本思想是用以下方面进行编码来压缩给定的数据:
位
关联规则
决策树
聚类
模式发现 - 该理论的基本思想是发现数据库中发生的模式。以下是为此理论做出贡献的领域:
机器学习
神经网络
关联挖掘
顺序模式匹配
聚类
概率论 - 该理论基于统计理论。该理论背后的基本思想是发现随机变量的联合概率分布。
概率论 - 根据该理论,数据挖掘发现的模式仅在其可用于某个企业的决策过程中才有意义。
微观经济学观点 - 根据该理论,数据库模式由存储在数据库中的数据和模式组成。因此,数据挖掘是在数据库上执行归纳的任务。
归纳数据库 - 除了面向数据库的技术外,还有用于数据分析的统计技术。这些技术也可以应用于科学数据以及经济和社会科学的数据。
统计数据挖掘
一些统计数据挖掘技术如下:
回归 - 回归方法用于根据一个或多个预测变量预测响应变量的值,其中变量是数值型的。以下是回归的形式:
线性
多元
加权
多项式
非参数
稳健的
广义线性模型 - 广义线性模型包括:
逻辑回归
泊松回归
模型的泛化允许以类似于使用线性回归对数值响应变量进行建模的方式,将分类响应变量与一组预测变量相关联。
方差分析 - 此技术分析:
用数值响应变量描述的两个或多个总体的实验数据。
一个或多个分类变量(因素)。
混合效应模型 - 这些模型用于分析分组数据。这些模型描述了响应变量与根据一个或多个因素分组的数据中的一些协变量之间的关系。
因子分析 - 因子分析用于预测分类响应变量。此方法假设自变量服从多元正态分布。
时间序列分析 -以下是分析时间序列数据的方法:
自回归方法。
单变量ARIMA(自回归积分移动平均)模型。
长记忆时间序列建模。
可视化数据挖掘
可视化数据挖掘利用数据和/或知识可视化技术,从大型数据集中发现隐含知识。可视化数据挖掘可以看作是以下学科的整合:
数据可视化
数据挖掘
可视化数据挖掘与以下密切相关:
计算机图形学
多媒体系统
人机交互
模式识别
高性能计算
通常,数据可视化和数据挖掘可以以以下方式集成:
数据可视化 - 数据库或数据仓库中的数据可以以多种可视化形式查看,如下所示:
箱线图
三维立方体
数据分布图
曲线
曲面
链接图等。
数据挖掘结果可视化 - 数据挖掘结果可视化是以可视化形式呈现数据挖掘结果。这些可视化形式可以是散点图、箱线图等。
数据挖掘过程可视化 - 数据挖掘过程可视化呈现数据挖掘的多个过程。它允许用户查看数据的提取方式。它还允许用户查看数据是从哪个数据库或数据仓库中清洗、集成、预处理和挖掘的。
音频数据挖掘
音频数据挖掘利用音频信号指示数据模式或数据挖掘结果的特征。通过将模式转换为声音和音乐,我们可以聆听音调和旋律,而不是观看图片,以便识别任何有趣的内容。
数据挖掘和协同过滤
如今,消费者在购物时会遇到各种各样的商品和服务。在实时客户交易中,推荐系统通过提供产品推荐来帮助消费者。协同过滤方法通常用于向客户推荐产品。这些推荐基于其他客户的意见。