- 数据挖掘教程
- 数据挖掘 - 首页
- 数据挖掘 - 概述
- 数据挖掘 - 任务
- 数据挖掘 - 问题
- 数据挖掘 - 评估
- 数据挖掘 - 术语
- 数据挖掘 - 知识发现
- 数据挖掘 - 系统
- 数据挖掘 - 查询语言
- 分类与预测
- 数据挖掘 - 决策树归纳
- 数据挖掘 - 贝叶斯分类
- 基于规则的分类
- 数据挖掘 - 分类方法
- 数据挖掘 - 聚类分析
- 数据挖掘 - 挖掘文本数据
- 数据挖掘 - 挖掘WWW
- 数据挖掘 - 应用与趋势
- 数据挖掘 - 主题
- 数据挖掘有用资源
- 数据挖掘 - 快速指南
- 数据挖掘 - 有用资源
- 数据挖掘 - 讨论
数据挖掘 - 挖掘万维网
万维网包含大量信息,为数据挖掘提供了丰富的来源。
Web挖掘中的挑战
基于以下观察,Web对基于资源和知识的发现提出了巨大挑战:
Web规模庞大 - Web的规模非常庞大,并且正在迅速增长。这似乎表明Web对于数据仓库和数据挖掘来说过于庞大。
网页的复杂性 - 网页没有统一的结构。与传统的文本文档相比,它们非常复杂。Web数字图书馆中存在大量文档。这些库没有按照任何特定的排序顺序排列。
Web是动态信息源 - Web上的信息正在快速更新。诸如新闻、股票市场、天气、体育、购物等数据会定期更新。
用户社区的多样性 - Web上的用户社区正在迅速扩大。这些用户具有不同的背景、兴趣和使用目的。有超过1亿个工作站连接到互联网,并且仍在快速增长。
信息的关联性 - 认为特定的人通常只对Web的一小部分感兴趣,而Web的其余部分包含与用户无关的信息,可能会淹没所需的结果。
挖掘网页布局结构
网页的基本结构基于文档对象模型 (DOM)。DOM结构指的是树状结构,其中页面中的HTML标签对应于DOM树中的节点。我们可以使用HTML中的预定义标签来分割网页。HTML语法灵活,因此网页不遵循W3C规范。不遵循W3C规范可能会导致DOM树结构错误。
DOM结构最初是为了在浏览器中进行呈现而引入的,而不是为了描述网页的语义结构。DOM结构无法正确识别网页不同部分之间的语义关系。
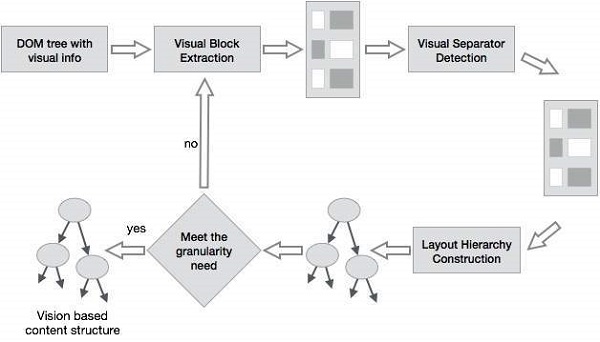
基于视觉的页面分割 (VIPS)
VIPS的目的是根据其视觉呈现提取网页的语义结构。
这种语义结构对应于树状结构。在这棵树中,每个节点对应于一个块。
为每个节点分配一个值。此值称为连贯度。分配此值是为了根据视觉感知指示块中连贯的内容。
VIPS算法首先从HTML DOM树中提取所有合适的块。之后,它找到这些块之间的分隔符。
分隔符指的是网页中水平或垂直的线条,这些线条在视觉上交叉且没有块。
网页的语义是基于这些块构建的。
下图显示了VIPS算法的过程: