- LightGBM 教程
- LightGBM - 首页
- LightGBM - 概述
- LightGBM - 架构
- LightGBM - 安装
- LightGBM - 核心参数
- LightGBM - Boosting 算法
- LightGBM - 树生长策略
- LightGBM - 数据集结构
- LightGBM - 二分类
- LightGBM - 回归
- LightGBM - 排序
- LightGBM - Python 实现
- LightGBM - 参数调优
- LightGBM - 绘图功能
- LightGBM - 早停训练
- LightGBM - 特征交互约束
- LightGBM 与其他 Boosting 算法对比
- LightGBM 有用资源
- LightGBM - 有用资源
- LightGBM - 讨论
LightGBM - 参数调优
优化 LightGBM 的参数对于提升模型性能至关重要,无论是在速度还是准确性方面。本章详细介绍如何调整 LightGBM 最必要的参数。
什么是参数调优?
参数调优是指调整机器学习模型的超参数或参数以最大化性能的过程。在 LightGBM 等模型中,控制模型学习过程的超参数包括叶子节点数量、学习率和树的深度。
参数调优的必要性在于:
提高准确率 - 在新的、未测试的数据上,经过微调的模型会生成更准确的预测。
防止过拟合/欠拟合 - 它确保模型既不太复杂也不太简单。
优化速度 - 通过使用更少的内存或处理器功率,调优可以减少训练时间而不会影响性能。
因此,让我们看看如何调整 LightGBM 模型的参数:
1. 控制模型复杂度
这些方法用于调节模型复杂度,通过调整诸如 num_leaves 和 max_depth 等参数来平衡欠拟合和过拟合。调整这些参数有助于我们管理 LightGBM 模型的复杂度。
num_leaves - 用于控制每棵决策树中叶子节点的数量。更多的叶子节点会增加模型复杂度,但太多可能会导致过拟合。将 num_leaves 设置为小于或等于 2(max_depth)。例如,如果 max_depth = 6,则将 num_leaves 设置为 <= 64。
min_data_in_leaf - 显示叶子节点可以包含的最小样本数或数据点数。通过更改此参数,您可以帮助模型减少数据中的噪声。如果深度太低,树可能会生长得太深并导致过拟合。对于大型数据集,数百或数千范围内的值是不错的选择。
max_depth - 用于限制树的深度。这可以通过限制树可以生长的深度来帮助防止过拟合。因此,结合 num_leaves 使用来控制树的复杂度。
2. 加速模型
可以通过使用诸如 bagging、特征子采样和 max_bin 减少等方法来提高训练速度,而不会影响准确性。
Bagging - 在每个循环中使用数据的一个子集来加速训练。通过设置参数。变量 bagging_fraction 给出每次迭代中要使用的数据的百分比。bagging_freq 返回每次频率的 bagging 迭代次数。两个合适的设置是 bagging_fraction = 0.8 和 bagging_freq = 5,以加速模型而不会显着影响准确性。
特征子采样 - 在每次迭代中随机选择特征的一个子集进行训练。使用诸如 feature_fraction 等参数。此参数控制用于训练的特征的分数。最佳实践是将 feature_fraction 设置为 0.8 以减少训练时间。
max_bin - 此参数控制用于连续特征的 bin 的数量。因此,最佳实践是减少 max_bin 以加快模型速度并减少内存消耗,但可能会影响准确性。
save_binary - 存储二进制数据以允许在后续运行中更快地加载。因此,建议在对相同数据集重复运行模型时使用 save_binary=True。
3. 提高准确率
使用更大的数据集、更低的学习率和 Dart 等高级技术可以提高模型的准确性,但可能会以更长的训练时间为代价。
learning_rate 和 num_iterations - 参数 learning_rate 和 num_iterations 控制模型在每次迭代中进行修改的步数和数量。使用较小的学习率(如 0.01)和较大的 num_iterations(如 1000+)是最佳选择。
num_leaves - 增加 num_leaves 使模型更复杂。这可能会提高准确性,但如果使用不当,也可能导致过拟合。因此,最佳实践是在您有足够数据的情况下增加 num_leaves,但请确保将其与正则化技术结合使用以避免过拟合。
使用更大的数据 - 更多的数据通常会导致更高的准确性,因为模型可以获取更大范围的模式。因此,最佳实践是,如果过拟合是一个问题,请尽可能多地使用数据以提高模型的泛化能力。
Dart(Dropouts meet Multiple Additive Regression Trees) - 这种特殊的梯度提升技术通过在训练期间随机删除树来提高模型的准确性。因此,最佳实践是对于您看到过拟合的问题或您正在寻找额外准确性的问题,使用 boosting_type='dart'。
使用类别特征 - 通过消除将类别特征转换为虚拟变量的需要,LightGBM 可以直接处理它们,从而可能提高性能。因此,最好通过使用 categorical_feature 选项来识别哪些属性是类别属性来提高模型准确性。
4. 处理过拟合
本节介绍如何使用子采样技术、树深度限制和正则化来防止模型过度拟合训练集。
max_bin - 使用较小的 max_bin 可以减少过拟合,因为它限制了特征分箱中的细节量。
num_leaves - 减少模型中的叶子节点数量,以防止过度拟合训练集并防止模型变得过于复杂。
min_data_in_leaf 和 min_sum_hessian_in_leaf - 这些设置通过确保每个叶子节点包含最小二阶导数之和(min_sum_hessian_in_leaf)和最小数据点数(min_data_in_leaf)来帮助防止树变得过深。增加 min_data_in_leaf 和 min_sum_hessian_in_leaf 以避免过拟合,尤其是在小型数据集上。
Bagging 和特征子采样 - 使用特征子采样(feature_fraction)和 bagging(bagging_fraction 和 bagging_freq)来增加模型中的不确定性并减少过拟合。
正则化 - 定义诸如 lambda_l1(L1 正则化,通常称为 Lasso)等参数以降低模型的复杂度。lambda_l2 用于通过基于岭的 L2 正则化来减少过拟合。变量 min_gain_to_split 指示拆分树节点所需的最小增益。尝试增加 lambda_l1 和 lambda_l2 以向模型添加正则化,并调整 min_gain_to_split 以控制模型创建新分支的难易程度。
max_depth - 设置合理的 max_depth 以限制树的深度并避免过拟合,尤其是在较小的数据集上。
Python 中的参数调优示例
以下是在 Python 中执行 LightGBM 参数调优的小示例:
# Import necessary libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split, RandomizedSearchCV
import lightgbm as lgb
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
sns.set(style="whitegrid", color_codes=True, font_scale=1.3)
import warnings
warnings.filterwarnings('ignore')
# Load dataset
data = pd.read_csv('/Python/breast_cancer_data.csv')
data.head()
# 1. Preprocessing
# Drop unnecessary columns
data = data.drop(columns=['id', 'Unnamed: 32'])
# Convert 'diagnosis' column to numerical (0: Benign, 1: Malignant)
data['diagnosis'] = data['diagnosis'].map({'B': 0, 'M': 1})
# Split the data into features (X) and target (y)
X = data.drop(columns=['diagnosis'])
y = data['diagnosis']
# Clean column names to avoid LightGBM error
X.columns = X.columns.str.replace('[^A-Za-z0-9_]+', '', regex=True)
# Train-test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 2. Define parameter grid for tuning
param_grid = {
'learning_rate': [0.01, 0.05, 0.1],
'num_leaves': [20, 31, 40],
'max_depth': [-1, 10, 20],
'feature_fraction': [0.6, 0.8, 1.0],
'bagging_fraction': [0.6, 0.8, 1.0],
'bagging_freq': [0, 5, 10],
'lambda_l1': [0, 1, 5],
'lambda_l2': [0, 1, 5]
}
# 3. Set up the LightGBM model
lgb_estimator = lgb.LGBMClassifier(objective='binary', metric='binary_logloss')
# 4. Perform Randomized Search for parameter tuning
random_search = RandomizedSearchCV(estimator=lgb_estimator, param_distributions=param_grid,
n_iter=50, scoring='accuracy', cv=5, verbose=1, random_state=42)
# 5. Fit the model
random_search.fit(X_train, y_train)
# 6. Get the best parameters
print("Best Parameters:", random_search.best_params_)
# 7. Predict and evaluate the model
y_pred = random_search.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy * 100:.2f}%")
# Confusion Matrix
conf_matrix = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:")
print(conf_matrix)
# Classification report
print("Classification Report:")
print(classification_report(y_test, y_pred))
# Optional: Plot Confusion Matrix for visualization
plt.figure(figsize=(8,6))
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues', xticklabels=['Benign', 'Malignant'], yticklabels=['Benign', 'Malignant'])
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.title('Confusion Matrix')
plt.show()
输出
以下是上述 LightGBM 模型参数调优的输出:
Accuracy: 97.37%
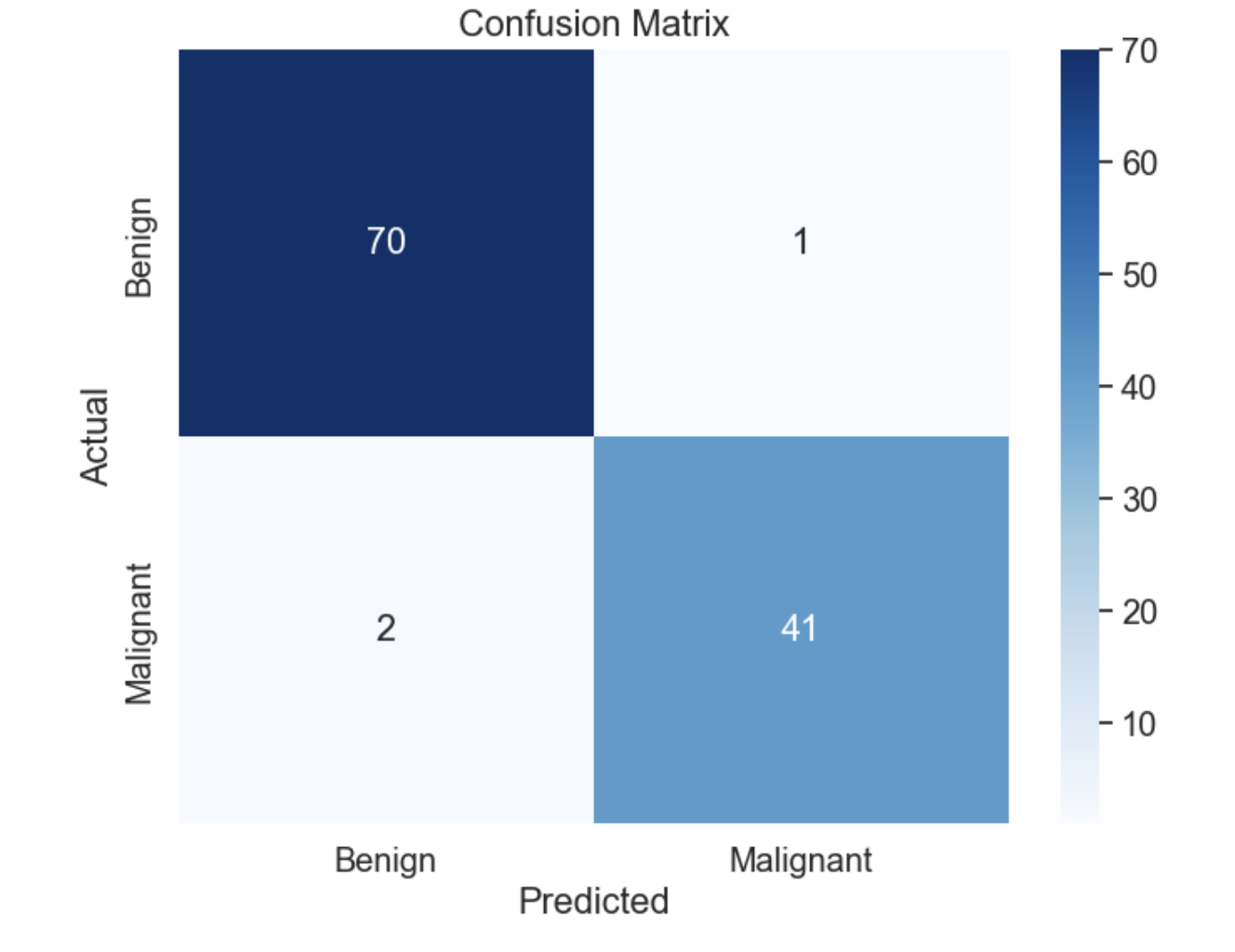
Confusion Matrix:
[[70 1]
[ 2 41]]
Classification Report:
precision recall f1-score support
0 0.97 0.99 0.98 71
1 0.98 0.95 0.96 43
accuracy 0.97 114
macro avg 0.97 0.97 0.97 114
weighted avg 0.97 0.97 0.97 114
混淆矩阵如下:
总结
需要调整 LightGBM 参数以最大化模型性能和训练速度。在速度、精度、复杂度和防止过拟合之间找到平衡是关键。通过仔细调整诸如 num_leaves、min_data_in_leaf、bagging_fraction 和 max_depth 等参数,您可以构建一个在训练数据和未见数据上都表现良好的模型。在此,L1 和 L2 正则化过程可以帮助进一步防止过拟合并增强模型的泛化能力。