- LightGBM教程
- LightGBM - 首页
- LightGBM - 概述
- LightGBM - 架构
- LightGBM - 安装
- LightGBM - 核心参数
- LightGBM - Boosting算法
- LightGBM - 树生长策略
- LightGBM - 数据集结构
- LightGBM - 二分类
- LightGBM - 回归
- LightGBM - 排序
- LightGBM - Python实现
- LightGBM - 参数调优
- LightGBM - 绘图功能
- LightGBM - 早停训练
- LightGBM - 特征交互约束
- LightGBM 与其他Boosting算法对比
- LightGBM 有用资源
- LightGBM - 有用资源
- LightGBM - 讨论
LightGBM - 与其他Boosting算法对比
LightGBM 在处理分类数据集方面也表现出色,因为它使用分裂或分组方法处理分类特征。我们将所有分类特征转换为类别数据类型,以便与LightGBM中的分类特征进行交互。完成后,分类数据将由LightGBM自动处理,无需手动管理。
LightGBM 使用GOSS方法在训练决策树时对数据进行采样。此方法设置每个数据样本的方差,并按降序排列。方差较低的数据样本已经表现良好,因此在对数据集进行采样时,它们的权重会较低。
因此,在本章中,我们将重点关注Boosting算法之间的差异,并将它们与LightGBM进行比较。
您应该使用哪种Boosting算法?
现在,问题很简单:如果所有这些机器学习算法都表现良好、速度快且精度更高,那么您应该选择哪一个?!!
这些问题的答案不能是单一的Boosting策略,因为每种策略最适合您将要处理的特定问题类型。
例如,如果您认为您的数据集需要正则化,那么您可以肯定地使用XGBoost。CatBoost和LightGBM是处理分类数据的不错选择。如果您需要更多关于该方法的社区支持,可以探索诸如XGBoost或Gradient Boosting之类的算法,这些算法是在几年前开发的。
Boosting算法之间的比较
将数据拟合到模型后,所有策略都提供了相对相似的结果。与其他算法相比,LightGBM的性能似乎较差,但在这种情况下,XGBoost的性能良好。
为了展示每个算法在相同数据上的表现,我们可以显示其y_test和y_pred值的图形。
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
# Example data
y_test = np.linspace(0, 100, 100)
# Predictions with some noise
y_pred1 = y_test + np.random.normal(0, 10, 100)
y_pred2 = y_test + np.random.normal(0, 8, 100)
y_pred3 = y_test + np.random.normal(0, 6, 100)
y_pred4 = y_test + np.random.normal(0, 4, 100)
y_pred5 = y_test + np.random.normal(0, 2, 100)
fig, ax = plt.subplots(figsize=(11, 5))
# Plot each model's predictions
sns.lineplot(x=y_test, y=y_pred1, label='GradientBoosting', ax=ax)
sns.lineplot(x=y_test, y=y_pred2, label='XGBoost', ax=ax)
sns.lineplot(x=y_test, y=y_pred3, label='AdaBoost', ax=ax)
sns.lineplot(x=y_test, y=y_pred4, label='CatBoost', ax=ax)
sns.lineplot(x=y_test, y=y_pred5, label='LightGBM', ax=ax)
# Set labels
ax.set_xlabel('y_test', color='g')
ax.set_ylabel('y_pred', color='g')
# Display the plot
plt.show()
输出
以下是上述代码的结果 -
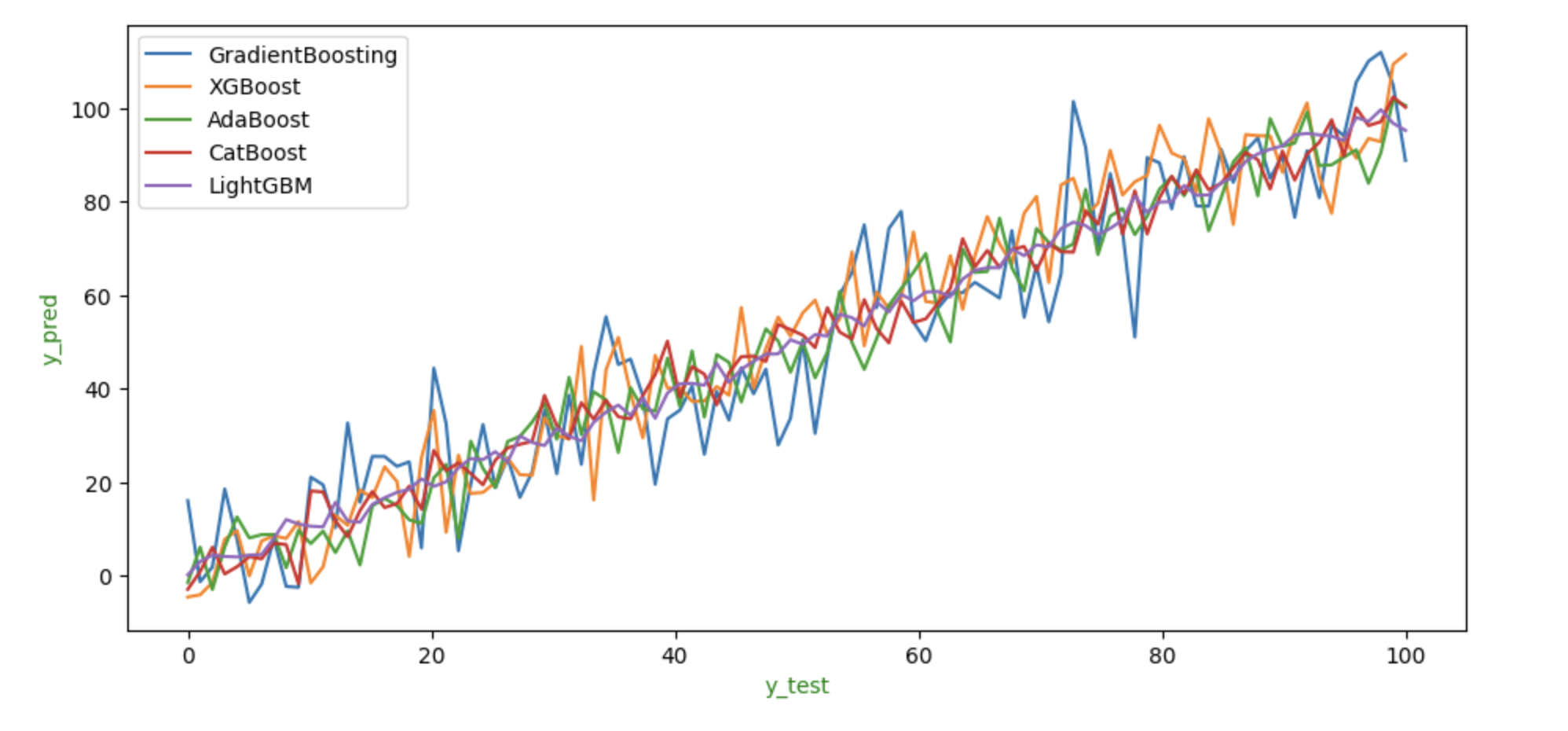
上图显示了每种方法预期的y_test和y_pred值。我们可以看到,与其他算法相比,LightGBM和CatBoost的性能较差,因为它们预测的y_pred值远高于或低于其他方法。从图中可以看出,XGBoost和GradientBoosting在这组数据上优于所有其他算法,其预测值似乎是所有算法的平均值。
不同Boosting算法之间的区别
以下是不同Boosting算法之间的表格差异 -
| 特征 | 梯度提升 | LightGBM | XGBoost | CatBoost | AdaBoost |
|---|---|---|---|---|---|
| 引入年份 | 不确定 | 2017 | 2014 | 2017 | 1995 |
| 处理分类数据 | 需要额外步骤,例如独热编码 | 需要额外步骤 | 无需特殊步骤 | 自动处理 | 无需特殊步骤 |
| 速度/可扩展性 | 中等 | 快速 | 快速 | 中等 | 快速 |
| 内存使用 | 中等 | 低 | 中等 | 高 | 低 |
| 正则化(防止过拟合) | 否 | 是 | 是 | 是 | 否 |
| 并行处理(同时运行多个任务) | 否 | 是 | 是 | 是 | 否 |
| GPU支持(可以使用显卡) | 否 | 是 | 是 | 是 | 否 |
| 特征重要性(显示哪些特征重要) | 是 | 是 | 是 | 是 | 是 |