- LightGBM 教程
- LightGBM - 首页
- LightGBM - 概述
- LightGBM - 架构
- LightGBM - 安装
- LightGBM - 核心参数
- LightGBM - Boosting 算法
- LightGBM - 树生长策略
- LightGBM - 数据集结构
- LightGBM - 二元分类
- LightGBM - 回归
- LightGBM - 排序
- LightGBM - Python 实现
- LightGBM - 参数调整
- LightGBM - 绘图功能
- LightGBM - 早停训练
- LightGBM - 特征交互约束
- LightGBM 与其他 Boosting 算法的比较
- LightGBM 有用资源
- LightGBM - 有用资源
- LightGBM - 讨论
LightGBM - 绘图功能
LightGBM 提供各种创建绘图的工具,帮助您可视化模型的性能、特征重要性等。因此,在本章中,我们将编写一些您可以与 LightGBM 一起使用的常用绘图函数。
LightGBM 绘图函数
以下是 LightGBM 中常用的绘图函数列表:
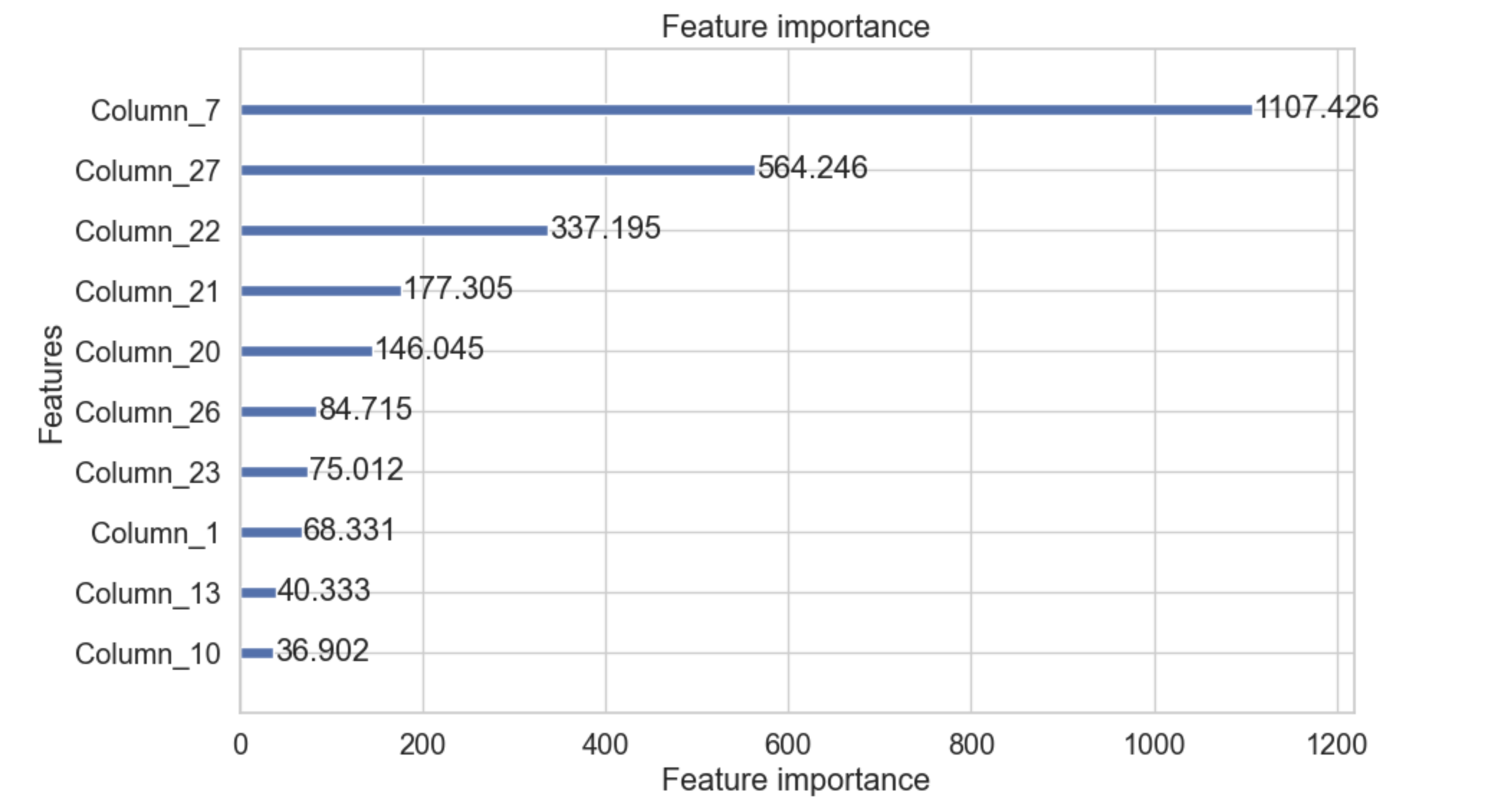
plot_importance()
plot_importance() 方法使用增强器对象,然后绘制特征重要性。此方法使用名为 importance_type 的参数,该参数用于设置为字符串“split”,它将绘制特征用于分割的次数,当设置为字符串“gain”时,它将绘制分割的增益。参数 importance_type 的值为“split”。
该函数还有一个名为 max_num_features 的参数,它接受一个整数,表示我们需要在图中包含多少个特征。我们也可以借助此参数来限制特征的数量。
语法
以下是我们可以用于 plot_importance() 函数的语法:
lightgbm.plot_importance( ax=None, booster, height=0.2, ylim=None, xlim=None, xlabel='Feature importance', title='Feature importance', importance_type='split', ylabel='Features', ignore_zero=True, max_num_features=None, grid=True, figsize=None, precision=3 )
参数
以下是使用 plot_importance() 函数所需的参数:
booster − 它是训练好的 LightGBM 模型。
importance_type − 用于定义如何计算特征重要性。它有两个值:“split”和“gain”。默认值为“split”。
max_num_features − 用于限制顶级特征的数量。
figsize − 它是一个元组,用于显示绘图的大小,例如 (10, 6)。
xlabel, ylabel − 这些是 x 轴和 y 轴的标签。
title − 它定义了绘图的标题。
ignore_zero − 如果设置为 True,它基本上会忽略重要性为零的特征。
grid − 如果设置为 True,则它会在绘图中显示网格。
示例
以下示例演示了 plot_importance() 函数的用法:
import lightgbm as lgb import matplotlib.pyplot as plt # Assuming you have a trained model `gbm` lgb.plot_importance(gbm, importance_type='gain', max_num_features=10, figsize=(10, 6)) plt.show()
输出
以下是上述代码的输出:
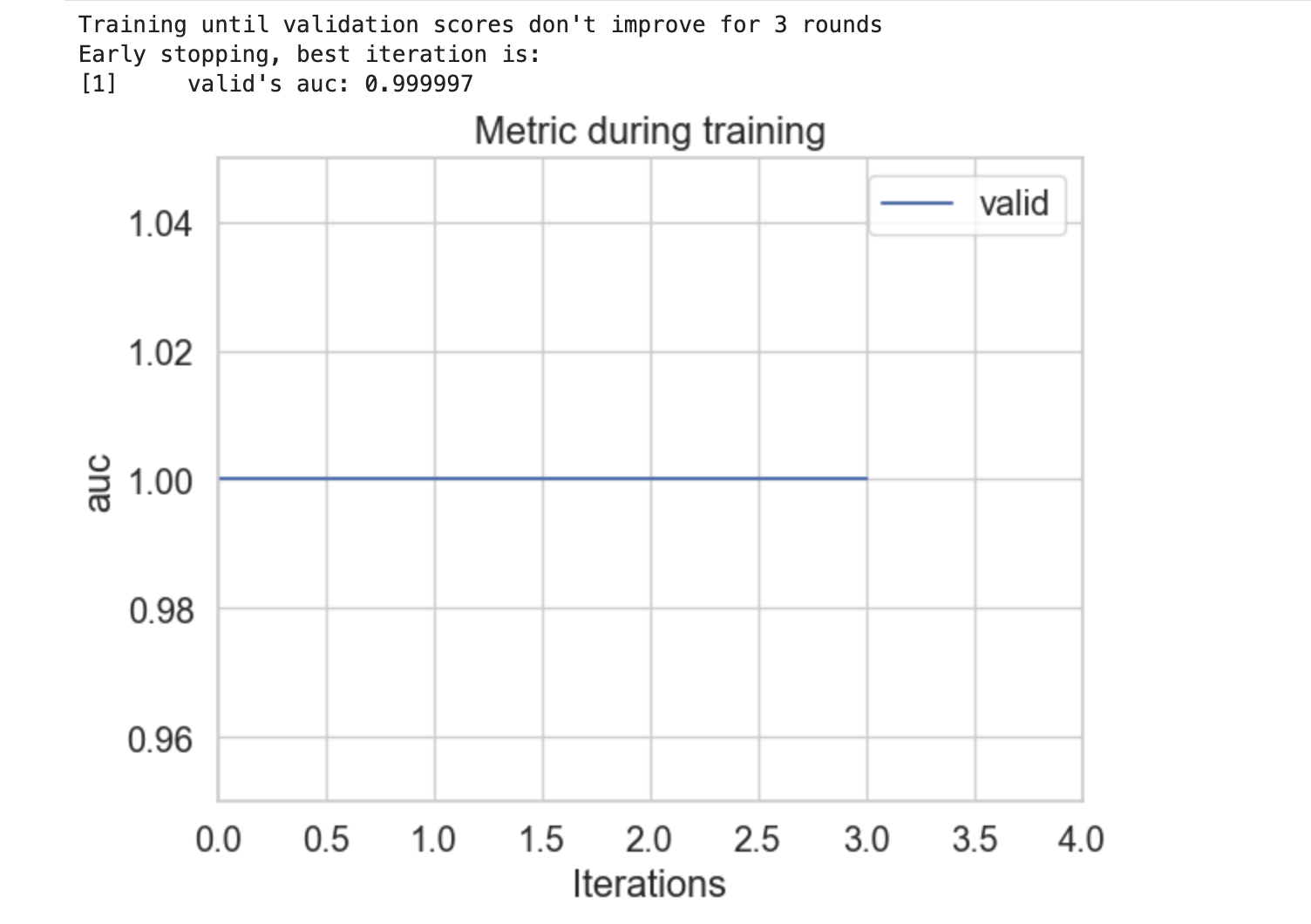
plot_metric()
plot_metric() 函数用于绘制评估指标的结果。要使用此函数,我们必须在方法中提供一个增强器对象才能绘制在数据集上评估的评估指标。
语法
以下是我们可以用于 plot_metric() 函数的语法:
lightgbm.plot_metric( eval_result, metric=None, dataset_names=None, ax=None, title='Metric during training', xlabel='Iterations', ylabel='Auto', figsize=None, grid=True )
参数
以下是 plot_metric() 函数所需的参数:
eval_result − 它是由 train() 方法返回的字典。它基本上包含评估结果。
metric − 您要绘制的评估指标。它是 None,因此会绘制所有指标。
dataset_names − 用于绘图的数据集名称列表。
ax − 用于绘图的 Matplotlib 轴对象。如果设置为 None,则会创建一个新的绘图。
title − 绘图的标题。
xlabel − X 轴的标签。
ylabel − Y 轴的标签。
figsize − 图像大小的元组。
grid − 用于显示网格。其默认值为 True。
示例
以下是使用模型并显示 plot_metric() 函数用法的完整 Python 代码:
import lightgbm as lgb
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.model_selection import train_test_split
# Generate sample binary classification data
X, y = make_blobs(n_samples=10_000, centers=2)
# Split the data
X_train, X_valid, y_train, y_valid = train_test_split(X, y, train_size=0.8)
# Prepare the dataset for LightGBM
dtrain = lgb.Dataset(X_train, label=y_train)
dvalid = lgb.Dataset(X_valid, label=y_valid)
# Dictionary to store results
evals_result = {}
# Train the model
model = lgb.train(
params={
"objective": "binary",
"metric": "auc",
},
train_set=dtrain,
valid_sets=[dvalid],
valid_names=['valid'],
num_boost_round=10,
callbacks=[
lgb.early_stopping(stopping_rounds=3),
lgb.record_evaluation(evals_result)
]
)
# Plot the evaluation metric
lgb.plot_metric(evals_result, metric='auc')
plt.show()
输出
以下是上述代码的结果:
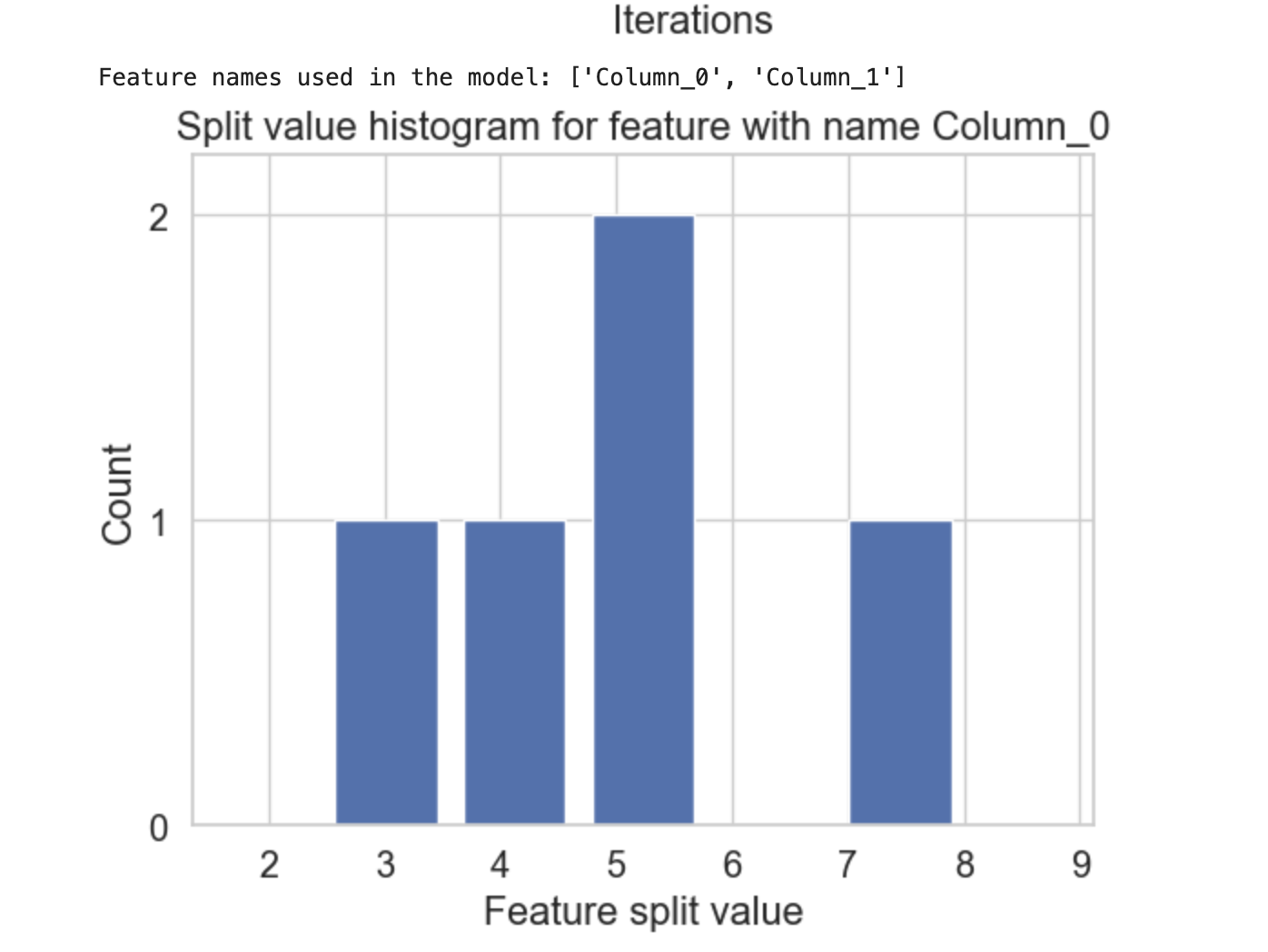
plot_split_value_histogram()
plot_split_value_histogram() 函数基本上接受输入增强器对象和特征名称/索引。之后,它会为给定的特征绘制分割值直方图。
语法
以下是您可以用于 plot_split_value_histogram() 函数的语法:
lightgbm.plot_split_value_histogram( booster, feature, bins=100, ax=None, width_coef=0.8, xlim=None, ylim=None, title=None, xlabel=None, ylabel=None, figsize=None, dpi=None, grid=False, )
参数
以下是 plot_split_value_histogram() 函数的必需和可选参数
booster − 它是训练好的 LightGBM 模型,也称为增强器对象。
feature − 您要绘制的特征的名称。
bins − 您可以用于直方图的箱数。
ax − 它是可选的 Matplotlib 轴对象。如果给出,则绘图将绘制在此轴上。
width_coef − 用于管理直方图中条形宽度系数。
xlim − x 轴限制的元组。
ylim − y 轴限制的元组。
title − 绘图的标题。
xlabel − x 轴的标签。
ylabel − y 轴的标签。
figsize − 图像大小的元组。
dpi − 绘图的每英寸点数。
grid − 此参数使用布尔值在绘图中显示网格。
示例
以下是如何包含 plot_split_value_histogram() 函数并查看结果的方法:
# Complete code is similar to the above mentioned example for plot_metric() # Plot the split value histogram lgb.plot_split_value_histogram(model, feature=feature_to_plot) plt.show()
输出
这将创建以下结果
plot_tree()
plot_tree() 函数允许您绘制集成中的单个树。为此,我们必须提到一个增强器对象以及我们要绘制的树的索引。
语法
以下是您可以用于 plot_split_value_histogram() 函数的语法:
lightgbm.plot_tree( booster, tree_index=0, figsize=(10, 10), dpi=None, show_info=True, precision=3, orientation='horizontal', example_case=None, )
参数
以下是 plot_split_value_histogram() 函数的必需和可选参数
booster − 要绘制的增强器或 LGBMModel 对象。
tree_index − 目标轴对象。如果为 None,则创建新的图形和轴。
figsize − 要绘制的目标树的索引。
dpi − 图像的分辨率。
show_info − 用于显示有关树中每个节点的附加信息。
precision − 用于将浮点值的显示限制在一定的精度。
orientation − 树的方向。其值可以是水平或垂直。
example_case − 与训练数据具有相同结构的单行。
create_tree_digraph()
create_tree_digraph() 方法用于显示来自 LightGBM 模型的给定决策树的结构。它基本上会生成一个图,显示树在每个节点如何分割数据,这使得更容易理解模型的决策过程。
语法
以下是您可以用于 create_tree_digraph() 函数的语法:
lightgbm.create_tree_digraph( booster, tree_index=0, show_info=None, precision=3, orientation='horizontal', example_case=None, max_category_values=10 )
参数
以下是 create_tree_digraph() 函数的必需和可选参数
booster − 要转换的增强器或 LGBMModel 对象。
tree_index − 要转换的目标树的索引。
show_info − 应在节点中显示的信息。值可以是 split_gain、internal_value、internal_count、internal_weight、leaf_count、leaf_weight 和 data_percentage。
precision − 用于将浮点值的显示限制在特定精度。
orientation − 树的方向。值可以是水平或垂直。
example_case − 与训练数据具有相同结构的单行。
max_category_values − 要在树节点中显示的最大类别值数。如果阈值的值大于此值,它将被折叠并在标签工具提示中显示。