
 数据结构
数据结构 网络
网络 关系数据库管理系统 (RDBMS)
关系数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C语言编程
C语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHPPython中的局部加权线性回归
局部加权线性回归是一种非参数方法/算法。在线性回归中,数据应呈线性分布,而局部加权回归适用于非线性分布的数据。通常,在局部加权回归中,距离查询点较近的点比距离较远的点权重更大。
参数模型和非参数模型
参数模型
参数模型是将函数简化为已知形式的模型。它具有一组参数,通过这些参数来总结数据。
这些参数的数量是固定的,这意味着模型已经知道这些参数,并且它们不依赖于数据。它们在训练样本方面也是独立的。
例如,让我们假设一个如下所述的映射函数。
b0+b1x1+b2x2=0
从等式中,b0、b1和b2是控制截距和斜率的直线系数。输入变量由x1和x2表示。
非参数模型
非参数算法不对映射函数的类型做出特别的假设。这些算法不接受输入和输出数据之间特定形式的映射函数为真。
它们可以自由地从训练数据中选择任何函数形式。因此,与参数模型相比,参数模型需要更多的数据来估计映射函数。
代价函数和权重的推导
线性回归的代价函数是
$$\mathrm{\displaystyle\sum\limits_{i=1}^m (y^{{(i)}} \:-\:\Theta^Tx)^2}$$
在局部加权线性回归中,代价函数被修改为
$$\mathrm{\displaystyle\sum\limits_{i=1}^m w^i(y^{{(i)}} \:-\:\Theta^Tx)^2}$$
其中𝑤(𝑖)表示第i个训练样本的权重。
权重函数可以定义为
$$\mathrm{w(i)\:=\:exp\:(-\frac{(x^i-x)^2}{2\tau^2})}$$
x是我们想要进行预测的点。x(i)是第i个训练样本
τ可以称为权重函数的高斯钟形曲线的带宽。
τ的值可以调整以根据与查询点的距离改变w的值。
τ 的小值意味着数据点到查询点的距离较小,w 的值变大(权重更大),反之亦然。
w 的值通常在 0 到 1 之间。
局部加权回归算法没有训练阶段。所有权重θ都在预测阶段确定。
示例
让我们考虑一个包含以下点的dataset
2,5,10,17,26,37,50,65,82
将查询点设为 x = 7,并从数据集中取三个点 5, 10, 26
因此 x(1) = 5, x(2) = 10, x(3) = 26。设 τ = 0.5
因此,
$$\mathrm{w(1) = exp( - ( 5 – 7 )^2 / (2 x 0.5^2)) = 0.00061}$$
$$\mathrm{w(2) = exp( - (10 – 7 )^2 / (2 x 0.5^2)) = 5.92196849e-8}$$
$$\mathrm{w(3) = exp( - (26 – 7 )^2 / (2 x 0.5^2)) = 1.24619e-290}$$
$$\mathrm{J(\Theta) = 0.00061 * (\Theta^ T x(1) – y(1) ) + 5.92196849e-8 * (\Theta^ T x(2) – y(2) ) + 1.24619e-290 *( \Theta^ T x(3) – y(3) )}$$
从上面的例子可以看出,查询点 (x) 与特定数据点/样本x(1), x(2), x(3)等的距离越近,w 的值越大。对于远离查询点的数 据点,权重呈指数下降。
随着 x(i) 和 x 之间距离的增加,权重减小。这减少了误差项对代价函数的贡献,反之亦然。
Python 实现
下面的代码片段演示了局部加权线性回归算法。
tips 数据集可以从 这里 下载
示例
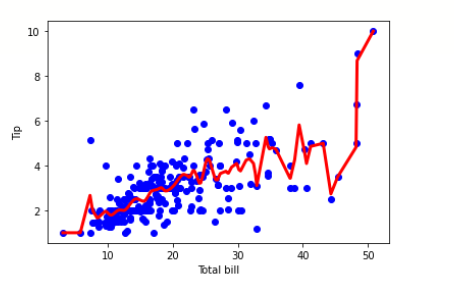
import pandas as pd import numpy as np import matplotlib.pyplot as plt %matplotlib inline df = pd.read_csv('/content/tips.csv') features = np.array(df.total_bill) labels = np.array(df.tip) def kernel(data, point, xmat, k): m,n = np.shape(xmat) ws = np.mat(np.eye((m))) for j in range(m): diff = point - data[j] ws[j,j] = np.exp(diff*diff.T/(-2.0*k**2)) return ws def local_weight(data, point, xmat, ymat, k): wei = kernel(data, point, xmat, k) return (data.T*(wei*data)).I*(data.T*(wei*ymat.T)) def local_weight_regression(xmat, ymat, k): m,n = np.shape(xmat) ypred = np.zeros(m) for i in range(m): ypred[i] = xmat[i]*local_weight(xmat, xmat[i],xmat,ymat,k) return ypred m = features.shape[0] mtip = np.mat(labels) data = np.hstack((np.ones((m, 1)), np.mat(features).T)) ypred = local_weight_regression(data, mtip, 0.5) indices = data[:,1].argsort(0) xsort = data[indices][:,0] fig = plt.figure() ax = fig.add_subplot(1,1,1) ax.scatter(features, labels, color='blue') ax.plot(xsort[:,1],ypred[indices], color = 'red', linewidth=3) plt.xlabel('Total bill') plt.ylabel('Tip') plt.show()
输出
什么时候可以使用局部加权线性回归?
当特征数量较少时。
当不需要特征选择时。
局部加权线性回归的优点。
在局部加权线性回归中,局部权重是相对于每个数据点计算的,因此出现较大误差的可能性较小。
我们拟合一条曲线,因此误差最小化。
在这个算法中,有很多小的局部函数,而不是一个要最小化的全局函数。局部函数在调整变化和误差方面更有效。
局部加权线性回归的缺点。
这个过程非常耗时,可能会消耗大量的资源。
对于线性相关的简单问题,我们可以简单地避免使用局部加权算法。
无法容纳大量的特征。
结论
因此,简而言之,局部加权线性回归更适合于数据呈非线性分布,并且我们仍然希望使用回归模型拟合数据而不会影响预测质量的情况。

浏览量:5000+
