
 数据结构
数据结构 网络
网络 关系数据库管理系统
关系数据库管理系统 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 语言编程
C 语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP线性回归假设 - 同方差性
简介
线性回归是机器学习中最常用和最简单的算法之一,它可以帮助预测几乎所有类型问题陈述中的线性数据。虽然线性回归是一种参数化机器学习算法,但该算法假设数据满足某些假设,以便更快更容易地进行预测。同方差性也是线性回归的核心假设之一,在对相应数据集应用线性回归时,假定该假设得到满足。在本文中,我们将讨论线性回归的同方差性假设、其核心思想、其重要性和一些其他相关的重要内容。
在本文中,我们将讨论线性回归的行为模式,为什么它是一种参数化算法,什么是同方差性,以及它为什么很重要。本文将帮助读者了解线性回归的参数化行为,并能够理解线性回归的同方差性假设。
假设的必要性
在开始讨论线性回归所假设的假设之前,有必要了解为什么我们要假设这些东西;这样做的必要性是什么?
要更好地理解这个概念,有必要首先了解参数化模型。参数化模型是机器学习中的一种算法类型,其工作原理是使用用于训练它们的函数,并且它们根据该函数得出输出结果。由于该函数用于训练和预测算法,因此并非每个数据点或数据集都可以直接应用,因此为了使过程更易于访问和更高效,我们假设某些事情,然后构建相应的函数。
例如,线性回归是一种参数化算法,它假设数据是线性和同方差的。
什么是同方差性?
同方差性是线性回归的假设之一,其中残差的方差假定为常数。简单来说,在误差与预测变量的图形或误差中,误差项应具有恒定的方差,并且误差项的值不应随着预测变量值的改变而改变。
同方差性的反面是异方差性,其中误差项或残差根据预测变量并非恒定,并且误差项随着预测变量值的改变而迅速变化。
众所周知,在线性回归中,使用线性方程来解决数据模式问题,即 Y = mX + c,其中 m 和 c 为常数,X 为自变量,y 为因变量。
现在,这里我们将有一些被认为是真实值的因变量 Y 值,并且我们还将使用自变量 X 预测 Y 的值,这将被称为变量 Y 的预测值。
这里的误差项仅仅是变量 Y 的真实值与变量 Y 的预测值之间的差值。其中同方差性表示误差项与预测变量 Y 之间的恒定方差。
同方差性示例
让我们尝试通过举例来理解同方差性的概念,以阐明其背后的所有核心直觉。
假设您想根据特定学生学习该科目所花费的小时数来预测该学生的成绩。因此,在这种情况下,学生的成绩将成为我们的因变量,它将取决于小时数变量,而自变量或变量将是特定学生学习该科目所花费的小时数。
现在,让我们假设我们拥有的是线性数据,并且我们将使用线性回归来解决该问题。在这里,在这种情况下,将生成一条最佳拟合线,这将是回归线,它也可以为未知数据提供学生成绩的线索。
但是,由于您已经创建了一个预测学生成绩的模型,因此您将检查模型的准确性以验证算法并在需要时进行更改。现在,为了验证模型,您将通过计算学生成绩的实际值和学生成绩的预测值之间的差值来计算模型产生的误差。
现在,如果您想检查模型是否遵循同方差性,则可以在误差项(残差)与预测变量 Y(学生的预测成绩)之间绘制图形(散点图)。
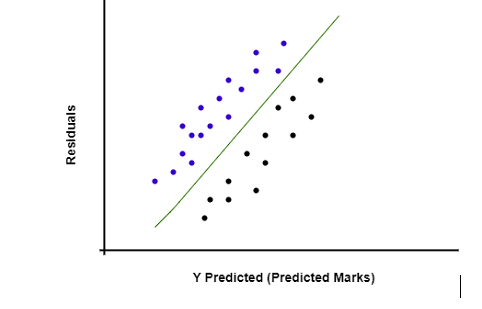
正如我们在上图中看到的,绘制了预测成绩或因变量与残差之间的散点图,其中散布或方差是恒定的,这意味着该模型遵循同方差性并且令人满意。
同方差性的重要性
同方差性是线性回归的假设之一。我们知道线性回归是一种参数化模型,它需要满足其假设,因此如果我们正在应用线性回归。如果该假设不满足,则构建的模型将非常糟糕且准确性较低。
此外,同方差性使我们能够了解误差项相对于预测变量的散布或方差;通过分析同方差性图,我们可以轻松识别模型产生较大误差和错误的位置,这会影响模型的整体性能。
关键要点
线性回归是一种参数化模型,它假设数据和模型满足某些假设。
同方差性是定义误差项与预测变量之间的图形上具有相等方差的术语。
异方差模型在误差与预测变量的图形上没有相等的方差。
同方差性图使我们能够了解模型产生较大误差的位置,并且可以对其进行修复。
遵循同方差性的模型对于线性回归算法来说是令人满意的。
结论
在本文中。我们通过讨论其他重要术语(如参数化模型、为什么需要假设以及相应的示例)来讨论线性回归算法的同方差性假设。本文将帮助读者更好地理解同方差性的概念,并能够非常有效地回答与之相关的面试问题,这些问题通常会被问到。

1K+ 浏览量
