- 自然语言工具包教程
- 自然语言工具包 - 首页
- 自然语言工具包 - 简介
- 自然语言工具包 - 快速入门
- 自然语言工具包 - 文本分词
- 训练分词器和过滤停用词
- 在Wordnet中查找单词
- 词干提取与词形还原
- 自然语言工具包 - 单词替换
- 同义词和反义词替换
- 语料库读取器和自定义语料库
- 词性标注基础
- 自然语言工具包 - 单词标注器
- 自然语言工具包 - 组合标注器
- 自然语言工具包 - 更多NLTK标注器
- 自然语言工具包 - 语法分析
- 分块与信息抽取
- 自然语言工具包 - 转换分块
- 自然语言工具包 - 转换树
- 自然语言工具包 - 文本分类
- 自然语言工具包资源
- 自然语言工具包 - 快速指南
- 自然语言工具包 - 有用资源
- 自然语言工具包 - 讨论
分块与信息抽取
什么是分块?
分块是自然语言处理中一个重要的过程,用于识别词性(POS)和短语。简单来说,通过分块,我们可以得到句子的结构。它也称为部分语法分析。
分块模式和非分块
分块模式是词性(POS)标签的模式,定义了构成分块的词语类型。我们可以借助修改后的正则表达式来定义分块模式。
此外,我们还可以定义哪些词语不应该出现在分块中的模式,这些未被分块的词语称为非分块。
实现示例
在下面的例子中,除了解析句子“这本书有很多章节”的结果外,还有一个用于名词短语的语法,它结合了分块和非分块模式:
import nltk
sentence = [
("the", "DT"),
("book", "NN"),
("has","VBZ"),
("many","JJ"),
("chapters","NNS")
]
chunker = nltk.RegexpParser(
r'''
NP:{<DT><NN.*><.*>*<NN.*>}
}<VB.*>{
'''
)
chunker.parse(sentence)
Output = chunker.parse(sentence)
Output.draw()
输出
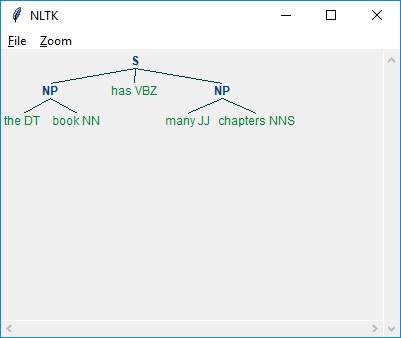
如上所示,指定分块的模式是使用大括号,如下所示:
{<DT><NN>}
要指定非分块,我们可以反转大括号,如下所示:
}<VB>{.
现在,对于特定类型的短语,这些规则可以组合成一个语法。
信息抽取
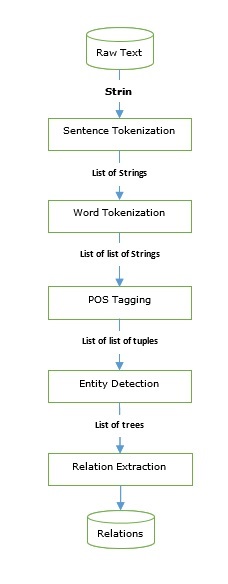
我们已经学习了可以用来构建信息抽取引擎的标注器和解析器。让我们来看一个基本的信息抽取流程:
信息抽取有很多应用,包括:
- 商业智能
- 简历收集
- 媒体分析
- 情感检测
- 专利检索
- 邮件扫描
命名实体识别 (NER)
命名实体识别 (NER) 实际上是一种提取一些最常见的实体(如姓名、组织、位置等)的方法。让我们来看一个例子,它包含了所有预处理步骤,例如句子分词、词性标注、分块、NER,并遵循上图中提供的流程。
示例
Import nltk file = open ( # provide here the absolute path for the file of text for which we want NER ) data_text = file.read() sentences = nltk.sent_tokenize(data_text) tokenized_sentences = [nltk.word_tokenize(sentence) for sentence in sentences] tagged_sentences = [nltk.pos_tag(sentence) for sentence in tokenized_sentences] for sent in tagged_sentences: print nltk.ne_chunk(sent)
一些修改后的命名实体识别 (NER) 也可以用来提取诸如产品名称、生物医学实体、品牌名称等等的实体。
关系抽取
关系抽取是另一个常用的信息抽取操作,它是提取不同实体之间不同关系的过程。可能存在不同的关系,例如继承、同义词、类似物等,其定义取决于信息需求。例如,如果我们要查找一本书的作者,那么作者身份就是作者姓名和书名之间的一种关系。
示例
在下面的例子中,我们使用与上图相同的IE流程,一直用到命名实体关系 (NER),并用基于NER标签的关系模式对其进行扩展。
import nltk
import re
IN = re.compile(r'.*\bin\b(?!\b.+ing)')
for doc in nltk.corpus.ieer.parsed_docs('NYT_19980315'):
for rel in nltk.sem.extract_rels('ORG', 'LOC', doc, corpus = 'ieer',
pattern = IN):
print(nltk.sem.rtuple(rel))
输出
[ORG: 'WHYY'] 'in' [LOC: 'Philadelphia'] [ORG: 'McGlashan & Sarrail'] 'firm in' [LOC: 'San Mateo'] [ORG: 'Freedom Forum'] 'in' [LOC: 'Arlington'] [ORG: 'Brookings Institution'] ', the research group in' [LOC: 'Washington'] [ORG: 'Idealab'] ', a self-described business incubator based in' [LOC: 'Los Angeles'] [ORG: 'Open Text'] ', based in' [LOC: 'Waterloo'] [ORG: 'WGBH'] 'in' [LOC: 'Boston'] [ORG: 'Bastille Opera'] 'in' [LOC: 'Paris'] [ORG: 'Omnicom'] 'in' [LOC: 'New York'] [ORG: 'DDB Needham'] 'in' [LOC: 'New York'] [ORG: 'Kaplan Thaler Group'] 'in' [LOC: 'New York'] [ORG: 'BBDO South'] 'in' [LOC: 'Atlanta'] [ORG: 'Georgia-Pacific'] 'in' [LOC: 'Atlanta']
在上例代码中,我们使用了一个名为ieer的内置语料库。在这个语料库中,句子已经被标记到命名实体关系 (NER)。在这里,我们只需要指定我们想要的关系模式以及我们想要关系定义的NER类型。在我们的例子中,我们定义了组织和位置之间的关系。我们提取了所有这些模式的组合。