- 自然语言工具包教程
- 自然语言工具包 - 首页
- 自然语言工具包 - 简介
- 自然语言工具包 - 入门
- 自然语言工具包 - 文本分词
- 训练分词器和过滤停用词
- 在WordNet中查找单词
- 词干提取和词形还原
- 自然语言工具包 - 单词替换
- 同义词和反义词替换
- 语料库读取器和自定义语料库
- 词性标注基础
- 自然语言工具包 - 一元语法标注器
- 自然语言工具包 - 组合标注器
- 自然语言工具包 - 更多NLTK标注器
- 自然语言工具包 - 解析
- 组块和信息提取
- 自然语言工具包 - 变换组块
- 自然语言工具包 - 变换树
- 自然语言工具包 - 文本分类
- 自然语言工具包资源
- 自然语言工具包 - 快速指南
- 自然语言工具包 - 有用资源
- 自然语言工具包 - 讨论
自然语言工具包 - 快速指南
自然语言工具包 - 简介
什么是自然语言处理 (NLP)?
人类借助语言进行交流,包括说、读和写。换句话说,我们人类可以用自然语言进行思考、计划和决策。那么,在人工智能、机器学习和深度学习时代,人类能否用自然语言与计算机/机器进行交流呢?开发NLP应用对我们来说是一个巨大的挑战,因为计算机需要结构化数据,而另一方面,人类语言是非结构化的,往往具有歧义性。
自然语言处理是计算机科学的一个子领域,更具体地说,是人工智能的一个子领域,它使计算机/机器能够理解、处理和操纵人类语言。简单来说,NLP是机器分析、理解和推导出像印地语、英语、法语、荷兰语等人类自然语言意义的一种方式。
它是如何工作的?
在深入研究NLP的工作原理之前,我们必须了解人类如何使用语言。每天,我们人类使用数百或数千个单词,其他人类会对其进行解释并做出相应的回答。对人类来说,这是一种简单的交流,不是吗?但我们知道,单词的含义远不止于此,我们总是从我们所说的内容和我们所说的方式中推导出上下文。这就是为什么我们可以说,NLP并非专注于语音调制,而是利用上下文模式。
让我们用一个例子来理解:
Man is to woman as king is to what? We can interpret it easily and answer as follows: Man relates to king, so woman can relate to queen. Hence the answer is Queen.
人类如何知道哪个词是什么意思?这个问题的答案是,我们通过经验学习。但是,机器/计算机如何学习相同的内容呢?
让我们通过以下简单的步骤来理解:
首先,我们需要用足够的数据来喂养机器,以便机器能够从经验中学习。
然后,机器将使用深度学习算法,从我们之前提供的数据以及其周围的数据中创建单词向量。
然后,通过对这些单词向量进行简单的代数运算,机器将能够像人类一样提供答案。
NLP的组成部分
下图表示自然语言处理 (NLP) 的组成部分:
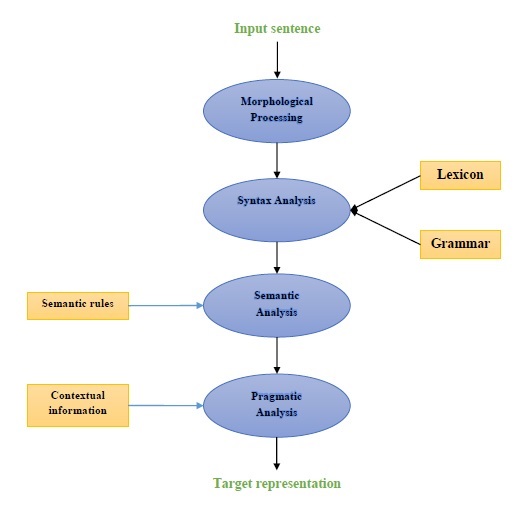
形态分析
形态分析是NLP的第一个组成部分。它包括将语言输入的块分解成对应于段落、句子和单词的标记集。例如,像“everyday”这样的单词可以分解成两个子词标记,“every-day”。
句法分析
句法分析是第二个组成部分,也是NLP最重要的组成部分之一。这个组成部分的目的如下:
检查句子是否格式良好。
将其分解成一个结构,该结构显示不同单词之间的句法关系。
例如,“学校去学生那里”之类的句子会被句法分析器拒绝。
语义分析
语义分析是NLP的第三个组成部分,用于检查文本是否有意义。它包括从文本中提取确切的含义,或者我们可以说字典含义。例如,“这是一个热的冰淇淋”之类的句子会被语义分析器丢弃。
语用分析
语用分析是NLP的第四个组成部分。它包括将先前组成部分(即语义分析)获得的对象引用与每个上下文中存在的实际对象或事件相匹配。例如,“把水果放在桌子上的篮子里”这句话可能有两种语义解释,因此语用分析器将在这两种可能性之间进行选择。
NLP应用示例
NLP作为一项新兴技术,衍生出各种我们现在经常看到的人工智能形式。对于当今和未来日益复杂的认知应用,在人机之间创建无缝交互界面将继续成为NLP的首要任务。以下是NLP的一些非常有用的应用。
机器翻译
机器翻译 (MT) 是自然语言处理最重要的应用之一。MT基本上是一个将一种源语言或文本翻译成另一种语言的过程。机器翻译系统可以是双语的或多语的。
反垃圾邮件
由于不需要的电子邮件数量急剧增加,垃圾邮件过滤器变得非常重要,因为它构成了抵御此问题的首要防线。通过将误报和漏报问题视为主要问题,NLP的功能可用于开发垃圾邮件过滤系统。
N元语法建模、词干提取和贝叶斯分类是一些现有的可用于垃圾邮件过滤的NLP模型。
信息检索和网络搜索
大多数搜索引擎(如谷歌、雅虎、必应、WolframAlpha等)都将其机器翻译 (MT) 技术建立在NLP深度学习模型之上。这种深度学习模型允许算法阅读网页上的文本,解释其含义并将其翻译成另一种语言。
自动文本摘要
自动文本摘要是一种创建较长文本文档的简短、准确摘要的技术。因此,它有助于我们更快地获取相关信息。在这个数字时代,我们迫切需要自动文本摘要,因为互联网上的信息泛滥成灾,而且这种情况不会停止。NLP及其功能在开发自动文本摘要中发挥着重要作用。
语法纠正
拼写检查和语法纠正是Microsoft Word等文字处理软件的一个非常有用的功能。自然语言处理 (NLP) 被广泛用于此目的。
问答
问答是自然语言处理 (NLP) 的另一个主要应用,它专注于构建能够自动回答用户用自然语言提出的问题的系统。
情感分析
情感分析是自然语言处理 (NLP) 的另一个重要应用。顾名思义,情感分析用于:
识别多个帖子中的情感,以及
识别未明确表达情感的地方的情感。
亚马逊、eBay等在线电子商务公司正在使用情感分析来识别客户在线的意见和情感。这将帮助他们了解客户对他们的产品和服务的看法。
语音引擎
Siri、Google Voice、Alexa等语音引擎都建立在NLP之上,以便我们可以用自然语言与它们进行交流。
实施NLP
为了构建上述应用程序,我们需要具备特定技能,并对语言以及高效处理语言的工具有很好的理解。为此,我们有各种可用的开源工具。其中一些是开源的,而另一些则是由组织开发的,用于构建他们自己的NLP应用程序。以下是某些NLP工具的列表:
自然语言工具包 (NLTK)
Mallet
GATE
OpenNLP
UIMA
Gensim
斯坦福工具包
这些工具大多数是用Java编写的。
自然语言工具包 (NLTK)
在上述NLP工具中,NLTK在易用性和概念解释方面得分很高。Python的学习曲线非常快,而NLTK是用Python编写的,因此NLTK也有非常好的学习工具包。NLTK集成了大多数任务,如分词、词干提取、词形还原、标点符号、字符计数和单词计数。它非常优雅且易于使用。
自然语言工具包 - 入门
为了安装NLTK,我们必须在计算机上安装Python。您可以访问链接www.python.org/downloads并为您的操作系统(即Windows、Mac和Linux/Unix)选择最新版本。有关Python的基本教程,您可以参考链接www.tutorialspoint.com/python3/index.htm。
现在,一旦您在计算机系统上安装了Python,让我们了解如何安装NLTK。
安装NLTK
我们可以在不同的操作系统上安装NLTK,如下所示:
在Windows上
为了在Windows操作系统上安装NLTK,请按照以下步骤操作:
首先,打开Windows命令提示符并导航到pip文件夹的位置。
接下来,输入以下命令来安装NLTK:
pip3 install nltk
现在,从Windows开始菜单打开PythonShell,并键入以下命令来验证NLTK的安装:
Import nltk
如果没有任何错误,则表示您已成功在安装了Python3的Windows操作系统上安装了NLTK。
在Mac/Linux上
为了在Mac/Linux操作系统上安装NLTK,请编写以下命令:
sudo pip install -U nltk
如果您的计算机上没有安装pip,请按照以下说明首先安装pip:
首先,使用以下命令更新包索引:
sudo apt update
现在,键入以下命令来安装python 3的pip:
sudo apt install python3-pip
通过Anaconda
为了通过Anaconda安装NLTK,请按照以下步骤操作:
首先,要安装Anaconda,请访问链接https://anaconda.net.cn/download,然后选择您需要安装的Python版本。
在你的电脑系统上安装好Anaconda后,打开它的命令提示符并输入以下命令:
conda install -c anaconda nltk
你需要查看输出结果并输入“yes”。NLTK 将被下载并安装到你的 Anaconda 包中。
下载 NLTK 的数据集和包
现在我们已经在电脑上安装了 NLTK,但为了使用它,我们需要下载其中可用的数据集(语料库)。一些重要的可用数据集包括 **stpwords、gutenberg、framenet_v15** 等等。
我们可以使用以下命令下载所有 NLTK 数据集:
import nltk nltk.download()
你将看到以下 NLTK 下载窗口。
现在,点击下载按钮下载数据集。
如何运行 NLTK 脚本?
下面是一个例子,我们使用 **PorterStemmer** nltk 类实现 Porter Stemmer 算法。通过这个例子,你可以理解如何运行 NLTK 脚本。
首先,我们需要导入自然语言工具包 (nltk)。
import nltk
现在,导入 **PorterStemmer** 类来实现 Porter Stemmer 算法。
from nltk.stem import PorterStemmer
接下来,创建一个 Porter Stemmer 类的实例,如下所示:
word_stemmer = PorterStemmer()
现在,输入你想要进行词干提取的单词:
word_stemmer.stem('writing')
输出
'write'
word_stemmer.stem('eating')
输出
'eat'
自然语言工具包 - 文本分词
什么是分词?
它可以定义为将一段文本分解成更小部分的过程,例如句子和单词。这些更小的部分称为词元。例如,在一个句子中,单词是一个词元,在一个段落中,句子是一个词元。
众所周知,NLP 用于构建情感分析、问答系统、语言翻译、智能聊天机器人、语音系统等应用程序,因此,为了构建这些应用程序,理解文本中的模式至关重要。上面提到的词元在查找和理解这些模式方面非常有用。我们可以将分词视为其他步骤(例如词干提取和词形还原)的基础步骤。
NLTK 包
**nltk.tokenize** 是 NLTK 模块提供的用于实现分词过程的包。
将句子分词为单词
将句子分割成单词或从字符串创建单词列表是每个文本处理活动的重要组成部分。让我们借助 **nltk.tokenize** 包提供的各种函数/模块来理解它。
word_tokenize 模块
**word_tokenize** 模块用于基本的分词。以下示例将使用此模块将句子分割成单词。
示例
import nltk
from nltk.tokenize import word_tokenize
word_tokenize('Tutorialspoint.com provides high quality technical tutorials for free.')
输出
['Tutorialspoint.com', 'provides', 'high', 'quality', 'technical', 'tutorials', 'for', 'free', '.']
TreebankWordTokenizer 类
上面使用的 **word_tokenize** 模块基本上是一个包装函数,它将 tokenize() 函数作为 **TreebankWordTokenizer** 类的实例调用。它将给出与使用 word_tokenize() 模块将句子分割成单词时相同的输出。让我们看看上面实现的相同示例:
示例
首先,我们需要导入自然语言工具包 (nltk)。
import nltk
现在,导入 **TreebankWordTokenizer** 类来实现分词算法:
from nltk.tokenize import TreebankWordTokenizer
接下来,创建一个 TreebankWordTokenizer 类的实例,如下所示:
Tokenizer_wrd = TreebankWordTokenizer()
现在,输入你想要转换成词元的句子:
Tokenizer_wrd.tokenize( 'Tutorialspoint.com provides high quality technical tutorials for free.' )
输出
[ 'Tutorialspoint.com', 'provides', 'high', 'quality', 'technical', 'tutorials', 'for', 'free', '.' ]
完整的实现示例
让我们看看下面的完整实现示例
import nltk
from nltk.tokenize import TreebankWordTokenizer
tokenizer_wrd = TreebankWordTokenizer()
tokenizer_wrd.tokenize('Tutorialspoint.com provides high quality technical
tutorials for free.')
输出
[ 'Tutorialspoint.com', 'provides', 'high', 'quality', 'technical', 'tutorials','for', 'free', '.' ]
分词器最重要的约定是分开处理缩写词。例如,如果我们为此目的使用 word_tokenize() 模块,它将给出如下输出:
示例
import nltk
from nltk.tokenize import word_tokenize
word_tokenize('won’t')
输出
['wo', "n't"]]
**TreebankWordTokenizer** 的这种约定是不可接受的。这就是为什么我们有两个替代的分词器,即 **PunktWordTokenizer** 和 **WordPunctTokenizer**。
WordPunktTokenizer 类
另一种分词器,它将所有标点符号分成单独的词元。让我们通过以下简单的示例来理解它:
示例
from nltk.tokenize import WordPunctTokenizer
tokenizer = WordPunctTokenizer()
tokenizer.tokenize(" I can't allow you to go home early")
输出
['I', 'can', "'", 't', 'allow', 'you', 'to', 'go', 'home', 'early']
将文本分词为句子
在本节中,我们将文本/段落分割成句子。NLTK 提供 **sent_tokenize** 模块来实现此目的。
为什么需要它?
我们脑海中出现的一个显而易见的问题是,当我们有分词器时,为什么我们需要句子分词器,或者为什么我们需要将文本分词成句子。假设我们需要计算句子中的平均词数,我们该如何做到这一点?为了完成此任务,我们需要句子分词和分词。
让我们通过以下简单的示例来了解句子分词器和分词器之间的区别:
示例
import nltk from nltk.tokenize import sent_tokenize text = "Let us understand the difference between sentence & word tokenizer. It is going to be a simple example." sent_tokenize(text)
输出
[ "Let us understand the difference between sentence & word tokenizer.", 'It is going to be a simple example.' ]
使用正则表达式进行句子分词
如果你觉得分词器的输出不可接受,并且想要完全控制如何分词文本,我们可以使用正则表达式进行句子分词。NLTK 提供 **RegexpTokenizer** 类来实现这一点。
让我们通过下面的两个例子来理解这个概念。
在第一个示例中,我们将使用正则表达式来匹配字母数字词元加上单引号,这样我们就不会拆分像 **“won’t”** 这样的缩写词。
示例 1
import nltk
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer("[\w']+")
tokenizer.tokenize("won't is a contraction.")
tokenizer.tokenize("can't is a contraction.")
输出
["won't", 'is', 'a', 'contraction'] ["can't", 'is', 'a', 'contraction']
在第一个示例中,我们将使用正则表达式在空格处进行分词。
示例 2
import nltk
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer('/s+' , gaps = True)
tokenizer.tokenize("won't is a contraction.")
输出
["won't", 'is', 'a', 'contraction']
从上面的输出中,我们可以看到标点符号保留在词元中。参数 gaps = True 表示模式将识别要进行分词的间隙。另一方面,如果我们使用 gaps = False 参数,则该模式将用于识别词元,这可以在以下示例中看到:
import nltk
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer('/s+' , gaps = False)
tokenizer.tokenize("won't is a contraction.")
输出
[ ]
它将给我们一个空白输出。
训练分词器和过滤停用词
为什么要训练自己的句子分词器?
这是一个非常重要的问题,如果我们有 NLTK 的默认句子分词器,为什么我们需要训练一个句子分词器?这个问题的答案在于 NLTK 的默认句子分词器的质量。NLTK 的默认分词器基本上是一个通用分词器。虽然它运行良好,但对于非标准文本(也许是我们的文本)或具有独特格式的文本来说,它可能不是一个好的选择。为了分词此类文本并获得最佳结果,我们应该训练自己的句子分词器。
实现示例
对于这个示例,我们将使用 webtext 语料库。我们将从此语料库中使用的文本文件包含如下所示的格式为对话的文本:
Guy: How old are you? Hipster girl: You know, I never answer that question. Because to me, it's about how mature you are, you know? I mean, a fourteen year old could be more mature than a twenty-five year old, right? I'm sorry, I just never answer that question. Guy: But, uh, you're older than eighteen, right? Hipster girl: Oh, yeah.
我们将此文本文件保存为 training_tokenizer。NLTK 提供了一个名为 **PunktSentenceTokenizer** 的类,借助它我们可以对原始文本进行训练以生成自定义句子分词器。我们可以通过读取文件或使用 **raw()** 方法从 NLTK 语料库中获取原始文本。
让我们看看下面的例子,以便更深入地了解它:
首先,从 **nltk.tokenize** 包中导入 **PunktSentenceTokenizer** 类:
from nltk.tokenize import PunktSentenceTokenizer
现在,从 **nltk.corpus** 包中导入 **webtext** 语料库
from nltk.corpus import webtext
接下来,使用 **raw()** 方法,从 **training_tokenizer.txt** 文件中获取原始文本,如下所示:
text = webtext.raw('C://Users/Leekha/training_tokenizer.txt')
现在,创建一个 **PunktSentenceTokenizer** 的实例,并打印文本文件中分词的句子,如下所示:
sent_tokenizer = PunktSentenceTokenizer(text) sents_1 = sent_tokenizer.tokenize(text) print(sents_1[0])
输出
White guy: So, do you have any plans for this evening? print(sents_1[1]) Output: Asian girl: Yeah, being angry! print(sents_1[670]) Output: Guy: A hundred bucks? print(sents_1[675]) Output: Girl: But you already have a Big Mac...
完整的实现示例
from nltk.tokenize import PunktSentenceTokenizer
from nltk.corpus import webtext
text = webtext.raw('C://Users/Leekha/training_tokenizer.txt')
sent_tokenizer = PunktSentenceTokenizer(text)
sents_1 = sent_tokenizer.tokenize(text)
print(sents_1[0])
输出
White guy: So, do you have any plans for this evening?
为了理解 NLTK 的默认句子分词器和我们自己训练的句子分词器之间的区别,让我们使用默认句子分词器,即 sent_tokenize(),对同一个文件进行分词。
from nltk.tokenize import sent_tokenize
from nltk.corpus import webtext
text = webtext.raw('C://Users/Leekha/training_tokenizer.txt')
sents_2 = sent_tokenize(text)
print(sents_2[0])
Output:
White guy: So, do you have any plans for this evening?
print(sents_2[675])
Output:
Hobo: Y'know what I'd do if I was rich?
借助输出结果的差异,我们可以理解为什么训练我们自己的句子分词器是有用的。
什么是停用词?
文本中存在的一些常用词,但在句子的含义中并没有贡献。这些词对于信息检索或自然语言处理的目的来说根本不重要。“the”和“a”是最常见的停用词。
NLTK 停用词语料库
实际上,自然语言工具包带有一个停用词语料库,其中包含许多语言的词表。让我们通过以下示例来了解其用法:
首先,从 nltk.corpus 包中导入 stopwords 语料库:
from nltk.corpus import stopwords
现在,我们将使用英语语言的停用词
english_stops = set(stopwords.words('english'))
words = ['I', 'am', 'a', 'writer']
[word for word in words if word not in english_stops]
输出
['I', 'writer']
完整的实现示例
from nltk.corpus import stopwords
english_stops = set(stopwords.words('english'))
words = ['I', 'am', 'a', 'writer']
[word for word in words if word not in english_stops]
输出
['I', 'writer']
查找支持的语言的完整列表
借助以下 Python 脚本,我们还可以找到 NLTK 停用词语料库支持的语言的完整列表:
from nltk.corpus import stopwords stopwords.fileids()
输出
[ 'arabic', 'azerbaijani', 'danish', 'dutch', 'english', 'finnish', 'french', 'german', 'greek', 'hungarian', 'indonesian', 'italian', 'kazakh', 'nepali', 'norwegian', 'portuguese', 'romanian', 'russian', 'slovene', 'spanish', 'swedish', 'tajik', 'turkish' ]
在WordNet中查找单词
什么是 WordNet?
WordNet 是普林斯顿大学创建的大型英语词汇数据库。它是 NLTK 语料库的一部分。名词、动词、形容词和副词都被分组到同义词集,即认知同义词。这里每个同义词集表达一个不同的含义。以下是 WordNet 的一些用例:
- 它可以用来查找单词的定义
- 我们可以找到一个单词的同义词和反义词
- 可以使用 WordNet 探索词语关系和相似性
- 对于具有多种用途和定义的单词进行词义消歧
如何导入 WordNet?
可以使用以下命令导入 WordNet:
from nltk.corpus import wordnet
对于更简洁的命令,请使用以下命令:
from nltk.corpus import wordnet as wn
Synset 实例
Synset 是表达相同概念的同义词的组合。当你使用 WordNet 来查找单词时,你将得到一个 Synset 实例列表。
wordnet.synsets(word)
为了获取 Synsets 列表,我们可以使用 **wordnet.synsets(word)** 在 WordNet 中查找任何单词。例如,在下一个 Python 示例中,我们将查找“dog”的 Synset 以及 Synset 的一些属性和方法:
示例
首先,导入 wordnet,如下所示:
from nltk.corpus import wordnet as wn
现在,提供你想要查找 Synset 的单词:
syn = wn.synsets('dog')[0]
在这里,我们使用 name() 方法来获取 synset 的唯一名称,该名称可用于直接获取 Synset:
syn.name() Output: 'dog.n.01'
接下来,我们使用 definition() 方法,它将给我们提供单词的定义:
syn.definition() Output: 'a member of the genus Canis (probably descended from the common wolf) that has been domesticated by man since prehistoric times; occurs in many breeds'
另一种方法是 examples(),它将给我们提供与单词相关的示例:
syn.examples() Output: ['the dog barked all night']
完整的实现示例
from nltk.corpus import wordnet as wn
syn = wn.synsets('dog')[0]
syn.name()
syn.definition()
syn.examples()
获取上位词
Synsets 以继承树状结构组织,其中 **上位词** 表示更抽象的术语,而 **下位词** 表示更具体的术语。重要的一点是,这棵树可以一直追溯到根上位词。让我们通过以下示例来理解这个概念:
from nltk.corpus import wordnet as wn
syn = wn.synsets('dog')[0]
syn.hypernyms()
输出
[Synset('canine.n.02'), Synset('domestic_animal.n.01')]
在这里,我们可以看到犬科动物和家养动物是“狗”的上位词。
现在,我们可以找到“狗”的下位词,如下所示:
syn.hypernyms()[0].hyponyms()
输出
[
Synset('bitch.n.04'),
Synset('dog.n.01'),
Synset('fox.n.01'),
Synset('hyena.n.01'),
Synset('jackal.n.01'),
Synset('wild_dog.n.01'),
Synset('wolf.n.01')
]
从上面的输出中,我们可以看到“狗”只是“家养动物”的众多下位词之一。
为了找到所有这些的根,我们可以使用以下命令:
syn.root_hypernyms()
输出
[Synset('entity.n.01')]
从上面的输出中,我们可以看到它只有一个根。
完整的实现示例
from nltk.corpus import wordnet as wn
syn = wn.synsets('dog')[0]
syn.hypernyms()
syn.hypernyms()[0].hyponyms()
syn.root_hypernyms()
输出
[Synset('entity.n.01')]
WordNet 中的词元
在语言学中,单词的规范形式或形态形式称为词元。为了找到一个单词的同义词和反义词,我们也可以在 WordNet 中查找词元。让我们看看如何操作。
查找同义词
使用 lemma() 方法,我们可以找到一个 Synset 的同义词数量。让我们将此方法应用于“dog” synset:
示例
from nltk.corpus import wordnet as wn
syn = wn.synsets('dog')[0]
lemmas = syn.lemmas()
len(lemmas)
输出
3
上述输出显示“dog”有三个词素。
获取第一个词素的名称如下:
lemmas[0].name() Output: 'dog'
获取第二个词素的名称如下:
lemmas[1].name() Output: 'domestic_dog'
获取第三个词素的名称如下:
lemmas[2].name() Output: 'Canis_familiaris'
实际上,一个 Synset 代表一组含义相似的词素,而一个词素代表一个不同的词形。
查找反义词
在 WordNet 中,一些词素也有反义词。例如,单词“good”共有 27 个 synset,其中 5 个的词素有反义词。让我们找到反义词(当单词“good”用作名词和形容词时)。
示例 1
from nltk.corpus import wordnet as wn
syn1 = wn.synset('good.n.02')
antonym1 = syn1.lemmas()[0].antonyms()[0]
antonym1.name()
输出
'evil'
antonym1.synset().definition()
输出
'the quality of being morally wrong in principle or practice'
上面的例子显示,单词“good”用作名词时,第一个反义词是“evil”。
示例 2
from nltk.corpus import wordnet as wn
syn2 = wn.synset('good.a.01')
antonym2 = syn2.lemmas()[0].antonyms()[0]
antonym2.name()
输出
'bad'
antonym2.synset().definition()
输出
'having undesirable or negative qualities’
上面的例子显示,单词“good”用作形容词时,第一个反义词是“bad”。
词干提取和词形还原
什么是词干提取?
词干提取是一种通过去除词缀来提取单词基本形式的技术。就像把树的枝条砍掉到树干一样。例如,单词eating、eats、eaten的词干是eat。
搜索引擎使用词干提取来索引单词。这就是为什么搜索引擎可以只存储词干,而不是存储单词的所有形式。这样,词干提取减少了索引的大小并提高了检索精度。
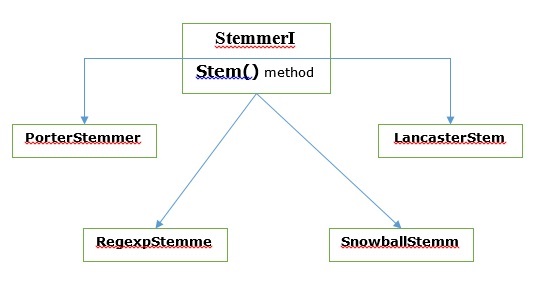
各种词干提取算法
在 NLTK 中,stemmerI(具有stem()方法)接口包含我们将接下来介绍的所有词干提取器。让我们通过下图来理解它
Porter 词干提取算法
这是最常见的词干提取算法之一,它基本上旨在去除和替换英语单词的常用后缀。
PorterStemmer 类
NLTK 具有PorterStemmer类,借助它我们可以轻松地为想要提取词干的单词实现 Porter 词干提取算法。此类知道几种常用的词形和后缀,借助这些后缀,它可以将输入词转换为最终词干。生成的词干通常是一个较短的单词,具有相同的词根含义。让我们来看一个例子:
首先,我们需要导入自然语言工具包 (nltk)。
import nltk
现在,导入 **PorterStemmer** 类来实现 Porter Stemmer 算法。
from nltk.stem import PorterStemmer
接下来,创建一个 Porter Stemmer 类的实例,如下所示:
word_stemmer = PorterStemmer()
现在,输入您想要提取词干的单词。
word_stemmer.stem('writing')
输出
'write'
word_stemmer.stem('eating')
输出
'eat'
完整的实现示例
import nltk
from nltk.stem import PorterStemmer
word_stemmer = PorterStemmer()
word_stemmer.stem('writing')
输出
'write'
Lancaster 词干提取算法
它是在兰开斯特大学开发的,也是另一种非常常见的词干提取算法。
LancasterStemmer 类
NLTK 具有LancasterStemmer类,借助它我们可以轻松地为想要提取词干的单词实现 Lancaster 词干提取算法。让我们来看一个例子:
首先,我们需要导入自然语言工具包 (nltk)。
import nltk
现在,导入LancasterStemmer类来实现 Lancaster 词干提取算法
from nltk.stem import LancasterStemmer
接下来,创建一个LancasterStemmer类的实例,如下所示:
Lanc_stemmer = LancasterStemmer()
现在,输入您想要提取词干的单词。
Lanc_stemmer.stem('eats')
输出
'eat'
完整的实现示例
import nltk
from nltk.stem import LancatserStemmer
Lanc_stemmer = LancasterStemmer()
Lanc_stemmer.stem('eats')
输出
'eat'
正则表达式词干提取算法
借助这种词干提取算法,我们可以构建我们自己的词干提取器。
RegexpStemmer 类
NLTK 具有RegexpStemmer类,借助它我们可以轻松地实现正则表达式词干提取算法。它基本上接受一个正则表达式,并去除与表达式匹配的任何前缀或后缀。让我们来看一个例子:
首先,我们需要导入自然语言工具包 (nltk)。
import nltk
现在,导入RegexpStemmer类来实现正则表达式词干提取算法。
from nltk.stem import RegexpStemmer
接下来,创建一个RegexpStemmer类的实例,并提供要从单词中去除的后缀或前缀,如下所示:
Reg_stemmer = RegexpStemmer(‘ing’)
现在,输入您想要提取词干的单词。
Reg_stemmer.stem('eating')
输出
'eat'
Reg_stemmer.stem('ingeat')
输出
'eat'
Reg_stemmer.stem('eats')
输出
'eat'
完整的实现示例
import nltk
from nltk.stem import RegexpStemmer
Reg_stemmer = RegexpStemmer()
Reg_stemmer.stem('ingeat')
输出
'eat'
Snowball 词干提取算法
这是另一个非常有用的词干提取算法。
SnowballStemmer 类
NLTK 具有SnowballStemmer类,借助它我们可以轻松地实现 Snowball 词干提取算法。它支持 15 种非英语语言。为了使用这个词干提取类,我们需要使用我们正在使用的语言的名称创建一个实例,然后调用 stem() 方法。让我们来看一个例子:
首先,我们需要导入自然语言工具包 (nltk)。
import nltk
现在,导入SnowballStemmer类来实现 Snowball 词干提取算法
from nltk.stem import SnowballStemmer
让我们看看它支持的语言:
SnowballStemmer.languages
输出
( 'arabic', 'danish', 'dutch', 'english', 'finnish', 'french', 'german', 'hungarian', 'italian', 'norwegian', 'porter', 'portuguese', 'romanian', 'russian', 'spanish', 'swedish' )
接下来,使用您想要使用的语言创建一个 SnowballStemmer 类的实例。这里,我们正在为“法语”创建词干提取器。
French_stemmer = SnowballStemmer(‘french’)
现在,调用 stem() 方法并输入您想要提取词干的单词。
French_stemmer.stem (‘Bonjoura’)
输出
'bonjour'
完整的实现示例
import nltk from nltk.stem import SnowballStemmer French_stemmer = SnowballStemmer(‘french’) French_stemmer.stem (‘Bonjoura’)
输出
'bonjour'
什么是词形还原?
词形还原技术类似于词干提取。词形还原后得到的输出称为“词素”,它是词根词,而不是词干提取的输出。词形还原后,我们将得到一个含义相同的有效单词。
NLTK 提供WordNetLemmatizer类,它是wordnet语料库的简单包装器。此类使用morphy()函数到WordNet CorpusReader类来查找词素。让我们用一个例子来理解它:
示例
首先,我们需要导入自然语言工具包 (nltk)。
import nltk
现在,导入WordNetLemmatizer类来实现词形还原技术。
from nltk.stem import WordNetLemmatizer
接下来,创建一个WordNetLemmatizer类的实例。
lemmatizer = WordNetLemmatizer()
现在,调用 lemmatize() 方法并输入您想要查找词素的单词。
lemmatizer.lemmatize('eating')
输出
'eating'
lemmatizer.lemmatize('books')
输出
'book'
完整的实现示例
import nltk
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
lemmatizer.lemmatize('books')
输出
'book'
词干提取和词形还原的区别
让我们借助以下示例来了解词干提取和词形还原之间的区别:
import nltk
from nltk.stem import PorterStemmer
word_stemmer = PorterStemmer()
word_stemmer.stem('believes')
输出
believ
import nltk
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
lemmatizer.lemmatize(' believes ')
输出
believ
两个程序的输出都说明了词干提取和词形还原之间的主要区别。PorterStemmer类从单词中去除“es”。另一方面,WordNetLemmatizer类查找一个有效的单词。简单来说,词干提取技术只关注单词的形式,而词形还原技术关注单词的含义。这意味着应用词形还原后,我们将始终得到一个有效的单词。
自然语言工具包 - 单词替换
词干提取和词形还原可以被认为是一种语言压缩。同样,词语替换可以被认为是文本规范化或错误校正。
但是为什么我们需要词语替换?假设如果我们谈论分词,那么它在处理缩写(如 can’t、won’t 等)时存在问题。因此,为了处理此类问题,我们需要词语替换。例如,我们可以用它们的扩展形式替换缩写。
使用正则表达式的词语替换
首先,我们将替换与正则表达式匹配的单词。但是为此,我们必须对正则表达式以及 python re 模块有基本的了解。在下面的示例中,我们将使用正则表达式将缩写替换为其扩展形式(例如,“can’t”将被替换为“cannot”)。
示例
首先,导入必要的包 re 来处理正则表达式。
import re from nltk.corpus import wordnet
接下来,定义您选择的替换模式,如下所示:
R_patterns = [ (r'won\'t', 'will not'), (r'can\'t', 'cannot'), (r'i\'m', 'i am'), r'(\w+)\'ll', '\g<1> will'), (r'(\w+)n\'t', '\g<1> not'), (r'(\w+)\'ve', '\g<1> have'), (r'(\w+)\'s', '\g<1> is'), (r'(\w+)\'re', '\g<1> are'), ]
现在,创建一个可用于替换单词的类:
class REReplacer(object):
def __init__(self, pattern = R_patterns):
self.pattern = [(re.compile(regex), repl) for (regex, repl) in patterns]
def replace(self, text):
s = text
for (pattern, repl) in self.pattern:
s = re.sub(pattern, repl, s)
return s
保存此 python 程序(例如 repRE.py)并从 python 命令提示符运行它。运行后,当您想替换单词时,导入 REReplacer 类。让我们看看怎么做。
from repRE import REReplacer
rep_word = REReplacer()
rep_word.replace("I won't do it")
Output:
'I will not do it'
rep_word.replace("I can’t do it")
Output:
'I cannot do it'
完整的实现示例
import re
from nltk.corpus import wordnet
R_patterns = [
(r'won\'t', 'will not'),
(r'can\'t', 'cannot'),
(r'i\'m', 'i am'),
r'(\w+)\'ll', '\g<1> will'),
(r'(\w+)n\'t', '\g<1> not'),
(r'(\w+)\'ve', '\g<1> have'),
(r'(\w+)\'s', '\g<1> is'),
(r'(\w+)\'re', '\g<1> are'),
]
class REReplacer(object):
def __init__(self, patterns=R_patterns):
self.patterns = [(re.compile(regex), repl) for (regex, repl) in patterns]
def replace(self, text):
s = text
for (pattern, repl) in self.patterns:
s = re.sub(pattern, repl, s)
return s
现在,一旦您保存了上述程序并运行它,您可以导入该类并按如下方式使用它:
from replacerRE import REReplacer
rep_word = REReplacer()
rep_word.replace("I won't do it")
输出
'I will not do it'
文本处理前的替换
在处理自然语言处理 (NLP) 时,一种常见的做法是在文本处理之前清理文本。在这方面,我们也可以使用我们在前面示例中创建的REReplacer类作为文本处理(即分词)之前的初步步骤。
示例
from nltk.tokenize import word_tokenize
from replacerRE import REReplacer
rep_word = REReplacer()
word_tokenize("I won't be able to do this now")
Output:
['I', 'wo', "n't", 'be', 'able', 'to', 'do', 'this', 'now']
word_tokenize(rep_word.replace("I won't be able to do this now"))
Output:
['I', 'will', 'not', 'be', 'able', 'to', 'do', 'this', 'now']
在上面的 Python 代码中,我们可以轻松理解在不使用和使用正则表达式替换的情况下,单词分词器的输出之间的区别。
重复字符的删除
我们在日常语言中是否严格遵循语法?不,我们不是。例如,有时我们会写“Hiiiiiiiiiiii Mohan”来强调“Hi”这个词。但是计算机系统不知道“Hiiiiiiiiiiii”是“Hi”这个词的变体。在下面的示例中,我们将创建一个名为rep_word_removal的类,该类可用于删除重复的单词。
示例
首先,导入必要的包 re 来处理正则表达式
import re from nltk.corpus import wordnet
现在,创建一个可用于删除重复单词的类:
class Rep_word_removal(object):
def __init__(self):
self.repeat_regexp = re.compile(r'(\w*)(\w)\2(\w*)')
self.repl = r'\1\2\3'
def replace(self, word):
if wordnet.synsets(word):
return word
repl_word = self.repeat_regexp.sub(self.repl, word)
if repl_word != word:
return self.replace(repl_word)
else:
return repl_word
保存此 python 程序(例如 removalrepeat.py)并从 python 命令提示符运行它。运行后,当您想删除重复的单词时,导入Rep_word_removal类。让我们看看怎么做?
from removalrepeat import Rep_word_removal
rep_word = Rep_word_removal()
rep_word.replace ("Hiiiiiiiiiiiiiiiiiiiii")
Output:
'Hi'
rep_word.replace("Hellooooooooooooooo")
Output:
'Hello'
完整的实现示例
import re
from nltk.corpus import wordnet
class Rep_word_removal(object):
def __init__(self):
self.repeat_regexp = re.compile(r'(\w*)(\w)\2(\w*)')
self.repl = r'\1\2\3'
def replace(self, word):
if wordnet.synsets(word):
return word
replace_word = self.repeat_regexp.sub(self.repl, word)
if replace_word != word:
return self.replace(replace_word)
else:
return replace_word
现在,一旦您保存了上述程序并运行它,您可以导入该类并按如下方式使用它:
from removalrepeat import Rep_word_removal
rep_word = Rep_word_removal()
rep_word.replace ("Hiiiiiiiiiiiiiiiiiiiii")
输出
'Hi'
同义词和反义词替换
用常见的同义词替换单词
在处理 NLP 时,尤其是在频率分析和文本索引的情况下,在不丢失含义的情况下压缩词汇总是很有益的,因为它节省了大量的内存。为了实现这一点,我们必须定义单词与其同义词的映射。在下面的示例中,我们将创建一个名为word_syn_replacer的类,该类可用于用其常见的同义词替换单词。
示例
首先,导入必要的包re来处理正则表达式。
import re from nltk.corpus import wordnet
接下来,创建一个接受单词替换映射的类:
class word_syn_replacer(object): def __init__(self, word_map): self.word_map = word_map def replace(self, word): return self.word_map.get(word, word)
保存此 python 程序(例如 replacesyn.py)并从 python 命令提示符运行它。运行后,当您想用常见的同义词替换单词时,导入word_syn_replacer类。让我们看看怎么做。
from replacesyn import word_syn_replacer
rep_syn = word_syn_replacer ({‘bday’: ‘birthday’)
rep_syn.replace(‘bday’)
输出
'birthday'
完整的实现示例
import re from nltk.corpus import wordnet class word_syn_replacer(object): def __init__(self, word_map): self.word_map = word_map def replace(self, word): return self.word_map.get(word, word)
现在,一旦您保存了上述程序并运行它,您可以导入该类并按如下方式使用它:
from replacesyn import word_syn_replacer
rep_syn = word_syn_replacer ({‘bday’: ‘birthday’)
rep_syn.replace(‘bday’)
输出
'birthday'
上述方法的缺点是,我们必须在 Python 字典中硬编码同义词。我们有两种更好的替代方案,即 CSV 和 YAML 文件。我们可以将我们的同义词词汇表保存在上述任何文件中,并可以从中构建word_map字典。让我们借助示例来理解这个概念。
使用 CSV 文件
为了为此目的使用 CSV 文件,该文件应包含两列,第一列包含单词,第二列包含用于替换它的同义词。让我们将此文件保存为syn.csv。在下面的示例中,我们将创建一个名为CSVword_syn_replacer的类,它将扩展replacesyn.py文件中的word_syn_replacer,并将用于从syn.csv文件构建word_map字典。
示例
首先,导入必要的包。
import csv
接下来,创建一个接受单词替换映射的类:
class CSVword_syn_replacer(word_syn_replacer):
def __init__(self, fname):
word_map = {}
for line in csv.reader(open(fname)):
word, syn = line
word_map[word] = syn
super(Csvword_syn_replacer, self).__init__(word_map)
运行后,当您想用常见的同义词替换单词时,导入CSVword_syn_replacer类。让我们看看怎么做?
from replacesyn import CSVword_syn_replacer rep_syn = CSVword_syn_replacer (‘syn.csv’) rep_syn.replace(‘bday’)
输出
'birthday'
完整的实现示例
import csv
class CSVword_syn_replacer(word_syn_replacer):
def __init__(self, fname):
word_map = {}
for line in csv.reader(open(fname)):
word, syn = line
word_map[word] = syn
super(Csvword_syn_replacer, self).__init__(word_map)
现在,一旦您保存了上述程序并运行它,您可以导入该类并按如下方式使用它:
from replacesyn import CSVword_syn_replacer rep_syn = CSVword_syn_replacer (‘syn.csv’) rep_syn.replace(‘bday’)
输出
'birthday'
使用 YAML 文件
正如我们使用 CSV 文件一样,我们也可以为此目的使用 YAML 文件(我们必须安装 PyYAML)。让我们将文件保存为syn.yaml。在下面的示例中,我们将创建一个名为YAMLword_syn_replacer的类,它将扩展replacesyn.py文件中的word_syn_replacer,并将用于从syn.yaml文件构建word_map字典。
示例
首先,导入必要的包。
import yaml
接下来,创建一个接受单词替换映射的类:
class YAMLword_syn_replacer(word_syn_replacer): def __init__(self, fname): word_map = yaml.load(open(fname)) super(YamlWordReplacer, self).__init__(word_map)
运行后,当您想用常见的同义词替换单词时,导入YAMLword_syn_replacer类。让我们看看怎么做?
from replacesyn import YAMLword_syn_replacer rep_syn = YAMLword_syn_replacer (‘syn.yaml’) rep_syn.replace(‘bday’)
输出
'birthday'
完整的实现示例
import yaml class YAMLword_syn_replacer(word_syn_replacer): def __init__(self, fname): word_map = yaml.load(open(fname)) super(YamlWordReplacer, self).__init__(word_map)
现在,一旦您保存了上述程序并运行它,您可以导入该类并按如下方式使用它:
from replacesyn import YAMLword_syn_replacer rep_syn = YAMLword_syn_replacer (‘syn.yaml’) rep_syn.replace(‘bday’)
输出
'birthday'
反义词替换
众所周知,反义词是与另一个单词具有相反含义的单词,同义词替换的反义词称为反义词替换。在本节中,我们将处理反义词替换,即使用 WordNet 用明确的反义词替换单词。在下面的示例中,我们将创建一个名为word_antonym_replacer的类,它具有两种方法,一种用于替换单词,另一种用于删除否定词。
示例
首先,导入必要的包。
from nltk.corpus import wordnet
接下来,创建名为word_antonym_replacer的类:
class word_antonym_replacer(object):
def replace(self, word, pos=None):
antonyms = set()
for syn in wordnet.synsets(word, pos=pos):
for lemma in syn.lemmas():
for antonym in lemma.antonyms():
antonyms.add(antonym.name())
if len(antonyms) == 1:
return antonyms.pop()
else:
return None
def replace_negations(self, sent):
i, l = 0, len(sent)
words = []
while i < l:
word = sent[i]
if word == 'not' and i+1 < l:
ant = self.replace(sent[i+1])
if ant:
words.append(ant)
i += 2
continue
words.append(word)
i += 1
return words
保存此 python 程序(例如 replaceantonym.py)并从 python 命令提示符运行它。运行后,当您想用明确的反义词替换单词时,导入word_antonym_replacer类。让我们看看怎么做。
from replacerantonym import word_antonym_replacer rep_antonym = word_antonym_replacer () rep_antonym.replace(‘uglify’)
输出
['beautify''] sentence = ["Let us", 'not', 'uglify', 'our', 'country'] rep_antonym.replace _negations(sentence)
输出
["Let us", 'beautify', 'our', 'country']
完整的实现示例
nltk.corpus import wordnet
class word_antonym_replacer(object):
def replace(self, word, pos=None):
antonyms = set()
for syn in wordnet.synsets(word, pos=pos):
for lemma in syn.lemmas():
for antonym in lemma.antonyms():
antonyms.add(antonym.name())
if len(antonyms) == 1:
return antonyms.pop()
else:
return None
def replace_negations(self, sent):
i, l = 0, len(sent)
words = []
while i < l:
word = sent[i]
if word == 'not' and i+1 < l:
ant = self.replace(sent[i+1])
if ant:
words.append(ant)
i += 2
continue
words.append(word)
i += 1
return words
现在,一旦您保存了上述程序并运行它,您可以导入该类并按如下方式使用它:
from replacerantonym import word_antonym_replacer rep_antonym = word_antonym_replacer () rep_antonym.replace(‘uglify’) sentence = ["Let us", 'not', 'uglify', 'our', 'country'] rep_antonym.replace _negations(sentence)
输出
["Let us", 'beautify', 'our', 'country']
语料库读取器和自定义语料库
什么是语料库?
语料库是在自然交流环境中产生的,以结构化格式的大型机器可读文本集合。Corpora 是 Corpus 的复数形式。语料库可以以多种方式派生,如下所示:
- 来自最初为电子的文本
- 来自口语的记录
- 来自光学字符识别等等
语料库代表性、语料库平衡、抽样、语料库大小是设计语料库时起重要作用的因素。一些最流行的用于 NLP 任务的语料库是 TreeBank、PropBank、VarbNet 和 WordNet。
如何构建自定义语料库?
下载NLTK时,我们也安装了NLTK数据包。因此,我们的计算机上已经安装了NLTK数据包。如果讨论Windows系统,我们假设此数据包安装在**C:\natural_language_toolkit_data**;如果讨论Linux、Unix和Mac OS X系统,我们假设此数据包安装在**/usr/share/natural_language_toolkit_data**。
在下面的Python示例中,我们将创建自定义语料库,它必须位于NLTK定义的路径之一中,因为NLTK才能找到它。为了避免与官方NLTK数据包冲突,让我们在我们的主目录中创建一个名为custom_natural_language_toolkit_data的目录。
import os, os.path
path = os.path.expanduser('~/natural_language_toolkit_data')
if not os.path.exists(path):
os.mkdir(path)
os.path.exists(path)
输出
True
现在,让我们检查我们的主目录中是否存在natural_language_toolkit_data目录:
import nltk.data path in nltk.data.path
输出
True
由于输出为True,这意味着我们的主目录中存在**nltk_data**目录。
现在,我们将创建一个名为**wordfile.txt**的词表文件,并将其放在**nltk_data**目录下的名为corpus的文件夹中**(~/nltk_data/corpus/wordfile.txt)**,然后使用**nltk.data.load**加载它:
import nltk.data nltk.data.load(‘corpus/wordfile.txt’, format = ‘raw’)
输出
b’tutorialspoint\n’
语料库读取器
NLTK提供各种CorpusReader类。我们将在接下来的Python示例中介绍它们。
创建词表语料库
NLTK具有**WordListCorpusReader**类,该类提供对包含单词列表的文件的访问。对于下面的Python示例,我们需要创建一个词表文件,可以是CSV文件或普通文本文件。例如,我们创建了一个名为“list”的文件,其中包含以下数据:
tutorialspoint Online Free Tutorials
现在,让我们实例化一个**WordListCorpusReader**类,从我们创建的文件“list”中生成单词列表。
from nltk.corpus.reader import WordListCorpusReader
reader_corpus = WordListCorpusReader('.', ['list'])
reader_corpus.words()
输出
['tutorialspoint', 'Online', 'Free', 'Tutorials']
创建词性标注语料库
NLTK具有**TaggedCorpusReader**类,我们可以用它来创建一个词性标注语料库。实际上,词性标注是识别单词词性标签的过程。
标注语料库最简单的格式之一是“word/tag”的形式,例如brown语料库中的以下摘录:
The/at-tl expense/nn and/cc time/nn involved/vbn are/ber astronomical/jj ./.
在上面的摘录中,每个单词都有一个标签表示其词性。例如,**vb**表示动词。
现在,让我们实例化一个**TaggedCorpusReader**类,从包含上述摘录的文件“list.pos”中生成词性标注词。
from nltk.corpus.reader import TaggedCorpusReader
reader_corpus = TaggedCorpusReader('.', r'.*\.pos')
reader_corpus.tagged_words()
输出
[('The', 'AT-TL'), ('expense', 'NN'), ('and', 'CC'), ...]
创建分块短语语料库
NLTK具有**ChunkedCorpusReader**类,我们可以用它来创建一个分块短语语料库。实际上,一个分块是句子中的一个短语。
例如,我们有以下来自标注的treebank语料库的摘录:
[Earlier/JJR staff-reduction/NN moves/NNS] have/VBP trimmed/VBN about/ IN [300/CD jobs/NNS] ,/, [the/DT spokesman/NN] said/VBD ./.
在上面的摘录中,每个分块都是一个名词短语,但不在括号中的单词是句子树的一部分,而不是任何名词短语子树的一部分。
现在,让我们实例化一个**ChunkedCorpusReader**类,从包含上述摘录的文件“list.chunk”中生成分块短语。
from nltk.corpus.reader import ChunkedCorpusReader
reader_corpus = TaggedCorpusReader('.', r'.*\.chunk')
reader_corpus.chunked_words()
输出
[
Tree('NP', [('Earlier', 'JJR'), ('staff-reduction', 'NN'), ('moves', 'NNS')]),
('have', 'VBP'), ...
]
创建分类文本语料库
NLTK具有**CategorizedPlaintextCorpusReader**类,我们可以用它来创建一个分类文本语料库。当我们拥有大量的文本语料库并希望将其分成不同的部分时,它非常有用。
例如,brown语料库有几个不同的类别。让我们使用以下Python代码找出它们:
from nltk.corpus import brown^M brown.categories()
输出
[ 'adventure', 'belles_lettres', 'editorial', 'fiction', 'government', 'hobbies', 'humor', 'learned', 'lore', 'mystery', 'news', 'religion', 'reviews', 'romance', 'science_fiction' ]
对语料库进行分类最简单的方法之一是为每个类别创建一个文件。例如,让我们看看来自**movie_reviews**语料库的两个摘录:
movie_pos.txt
The thin red line is flawed but it provokes.
movie_neg.txt
A big-budget and glossy production cannot make up for a lack of spontaneity that permeates their tv show.
因此,从以上两个文件中,我们有两个类别,即**pos**和**neg**。
现在让我们实例化一个**CategorizedPlaintextCorpusReader**类。
from nltk.corpus.reader import CategorizedPlaintextCorpusReader
reader_corpus = CategorizedPlaintextCorpusReader('.', r'movie_.*\.txt',
cat_pattern = r'movie_(\w+)\.txt')
reader_corpus.categories()
reader_corpus.fileids(categories = [‘neg’])
reader_corpus.fileids(categories = [‘pos’])
输出
['neg', 'pos'] ['movie_neg.txt'] ['movie_pos.txt']
词性标注基础
什么是词性标注?
标注,一种分类,是对词元的描述进行自动赋值。我们将描述符称为“标签”,它表示词性的一部分(名词、动词、副词、形容词、代词、连接词及其子类别)、语义信息等等。
另一方面,如果我们谈论词性(POS)标注,它可以定义为将句子从单词列表的形式转换为元组列表的过程。这里,元组的形式为(单词,标签)。我们也可以将词性标注称为为给定单词分配词性之一的过程。
下表显示了Penn Treebank语料库中使用的最常见的词性标注:
| 序号 | 标签 | 描述 |
|---|---|---|
| 1 | NNP | 专有名词,单数 |
| 2 | NNPS | 专有名词,复数 |
| 3 | PDT | 前限定词 |
| 4 | POS | 所有格结尾 |
| 5 | PRP | 人称代词 |
| 6 | PRP$ | 所有格代词 |
| 7 | RB | 副词 |
| 8 | RBR | 副词,比较级 |
| 9 | RBS | 副词,最高级 |
| 10 | RP | 语气助词 |
| 11 | SYM | 符号(数学或科学符号) |
| 12 | TO | to |
| 13 | UH | 感叹词 |
| 14 | VB | 动词,原型 |
| 15 | VBD | 动词,过去时 |
| 16 | VBG | 动词,现在分词/动名词 |
| 17 | VBN | 动词,过去分词 |
| 18 | WP | 疑问代词 |
| 19 | WP$ | 所有格疑问代词 |
| 20 | WRB | 疑问副词 |
| 21 | # | 磅符号 |
| 22 | $ | 美元符号 |
| 23 | . | 句末标点 |
| 24 | , | 逗号 |
| 25 | : | 冒号,分号 |
| 26 | ( | 左括号 |
| 27 | ) | 右括号 |
| 28 | " | 直双引号 |
| 29 | ' | 左单引号 |
| 30 | " | 左双引号 |
| 31 | ' | 右单引号 |
| 32 | " | 右双引号 |
示例
让我们通过一个Python实验来理解它:
import nltk from nltk import word_tokenize sentence = "I am going to school" print (nltk.pos_tag(word_tokenize(sentence)))
输出
[('I', 'PRP'), ('am', 'VBP'), ('going', 'VBG'), ('to', 'TO'), ('school', 'NN')]
为什么要进行词性标注?
词性标注是NLP的重要组成部分,因为它作为进一步NLP分析的先决条件,如下所示:
- 分块
- 句法分析
- 信息提取
- 机器翻译
- 情感分析
- 语法分析和词义消歧
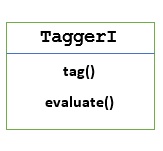
TaggerI - 基类
所有标注器都位于NLTK的nltk.tag包中。这些标注器的基类是**TaggerI**,这意味着所有标注器都继承自此类。
**方法** - TaggerI类具有以下两种方法,所有子类都必须实现:
**tag()方法** - 正如其名称所示,此方法将单词列表作为输入,并返回标注单词列表作为输出。
**evaluate()方法** - 使用此方法,我们可以评估标注器的准确性。
词性标注的基线
词性标注的基线或基本步骤是**默认标注**,可以使用NLTK的DefaultTagger类执行。默认标注只是为每个词元分配相同的词性标签。默认标注还提供了一个基线来衡量准确性改进。
DefaultTagger类
默认标注是使用**DefaultTagging**类执行的,它只接受一个参数,即我们要应用的标签。
它是如何工作的?
如前所述,所有标注器都继承自**TaggerI**类。**DefaultTagger**继承自**SequentialBackoffTagger**,它是**TaggerI类**的子类。让我们通过下图来了解它:
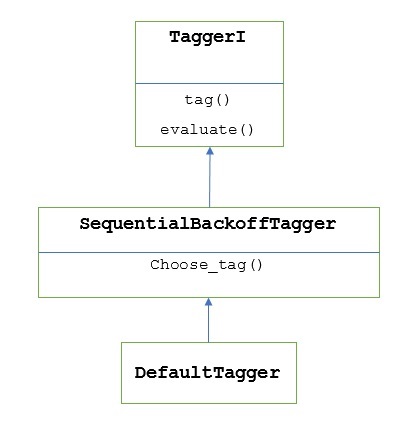
作为**SeuentialBackoffTagger**的一部分,**DefaultTagger**必须实现choose_tag()方法,该方法接受以下三个参数。
- 词元列表
- 当前词元的索引
- 前一个词元列表,即历史记录
示例
import nltk
from nltk.tag import DefaultTagger
exptagger = DefaultTagger('NN')
exptagger.tag(['Tutorials','Point'])
输出
[('Tutorials', 'NN'), ('Point', 'NN')]
在这个例子中,我们选择了一个名词标签,因为它是最常见的词类。此外,当我们选择最常见的词性标签时,**DefaultTagger**也最有用。
准确性评估
**DefaultTagger**也是评估标注器准确性的基线。这就是为什么我们可以将它与**evaluate()**方法一起使用来衡量准确性的原因。**evaluate()**方法将标记词元列表作为黄金标准来评估标注器。
以下是一个例子,我们使用上面创建的默认标注器exptagger来评估treebank语料库标记句子的子集的准确性:
示例
import nltk
from nltk.tag import DefaultTagger
exptagger = DefaultTagger('NN')
from nltk.corpus import treebank
testsentences = treebank.tagged_sents() [1000:]
exptagger.evaluate (testsentences)
输出
0.13198749536374715
上面的输出显示,通过为每个标签选择NN,我们可以对treebank语料库的1000个条目进行测试,实现大约13%的准确率。
标记句子列表
NLTK的**TaggerI**类除了标记单个句子之外,还提供了一个**tag_sents()**方法,我们可以用它来标记句子列表。以下是在其中我们标记了两个简单句子的示例
示例
import nltk
from nltk.tag import DefaultTagger
exptagger = DefaultTagger('NN')
exptagger.tag_sents([['Hi', ','], ['How', 'are', 'you', '?']])
输出
[
[
('Hi', 'NN'),
(',', 'NN')
],
[
('How', 'NN'),
('are', 'NN'),
('you', 'NN'),
('?', 'NN')
]
]
在上面的例子中,我们使用了我们之前创建的名为exptagger的默认标注器。
取消标记句子
我们也可以取消标记句子。NLTK为此提供nltk.tag.untag()方法。它将接收一个标记的句子作为输入,并提供一个没有标签的单词列表。让我们看一个例子:
示例
import nltk
from nltk.tag import untag
untag([('Tutorials', 'NN'), ('Point', 'NN')])
输出
['Tutorials', 'Point']
自然语言工具包 - 一元语法标注器
什么是Unigram标注器?
顾名思义,unigram标注器只使用单个单词作为其上下文来确定词性(Part-of-Speech)标签。简单来说,Unigram标注器是一个基于上下文的标注器,其上下文是一个单词,即Unigram。
它是如何工作的?
NLTK为此提供了一个名为**UnigramTagger**的模块。但在深入了解其工作原理之前,让我们借助下图了解其层次结构:
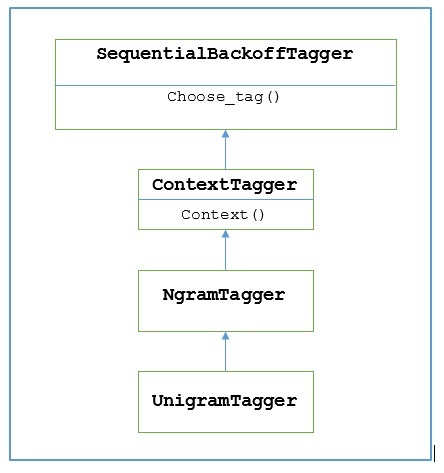
从上图可以看出,**UnigramTagger**继承自**NgramTagger**,它是**ContextTagger**的子类,后者继承自**SequentialBackoffTagger**。
**UnigramTagger**的工作原理通过以下步骤解释:
正如我们所看到的,**UnigramTagger**继承自**ContextTagger**,它实现了一个**context()**方法。此**context()**方法与**choose_tag()**方法接受相同的三个参数。
**context()**方法的结果将是单词词元,它将进一步用于创建模型。创建模型后,单词词元也用于查找最佳标签。
通过这种方式,**UnigramTagger**将从标记的句子列表中构建上下文模型。
训练Unigram标注器
NLTK 的UnigramTagger可以通过在初始化时提供已标注句子的列表来进行训练。在下面的例子中,我们将使用树库语料库的已标注句子。我们将使用该语料库的前 2500 个句子。
示例
首先从 nltk 导入 UniframTagger 模块:
from nltk.tag import UnigramTagger
接下来,导入您想要使用的语料库。这里我们使用的是 treebank 语料库:
from nltk.corpus import treebank
现在,获取用于训练的句子。我们将前 2500 个句子用于训练,并将对其进行标注:
train_sentences = treebank.tagged_sents()[:2500]
接下来,将 UnigramTagger 应用于用于训练的句子:
Uni_tagger = UnigramTagger(train_sentences)
取一些句子,数量等于或少于训练目的的句子数(即 2500 个),用于测试。这里我们取前 1500 个句子用于测试:
test_sentences = treebank.tagged_sents()[1500:] Uni_tagger.evaluate(test_sents)
输出
0.8942306156033808
在这里,我们得到了大约 89% 的准确率,这是一个使用单个词查找来确定词性标签的标注器。
完整的实现示例
from nltk.tag import UnigramTagger from nltk.corpus import treebank train_sentences = treebank.tagged_sents()[:2500] Uni_tagger = UnigramTagger(train_sentences) test_sentences = treebank.tagged_sents()[1500:] Uni_tagger.evaluate(test_sentences)
输出
0.8942306156033808
覆盖上下文模型
从上图显示的UnigramTagger 层次结构中,我们知道所有继承自ContextTagger的标注器,而不是训练它们自己的模型,都可以使用预构建的模型。这个预构建的模型只是一个简单的 Python 字典,它将上下文键映射到标签。对于UnigramTagger,上下文键是单个单词;对于其他NgramTagger子类,它将是元组。
我们可以通过向UnigramTagger类传递另一个简单的模型来覆盖此上下文模型,而不是传递训练集。让我们通过下面的一个简单示例来了解它:
示例
from nltk.tag import UnigramTagger
from nltk.corpus import treebank
Override_tagger = UnigramTagger(model = {‘Vinken’ : ‘NN’})
Override_tagger.tag(treebank.sents()[0])
输出
[
('Pierre', None),
('Vinken', 'NN'),
(',', None),
('61', None),
('years', None),
('old', None),
(',', None),
('will', None),
('join', None),
('the', None),
('board', None),
('as', None),
('a', None),
('nonexecutive', None),
('director', None),
('Nov.', None),
('29', None),
('.', None)
]
由于我们的模型只包含“Vinken”作为唯一的上下文键,您可以从上面的输出中观察到,只有这个词得到了标注,其他所有词的标签都是 None。
设置最小频率阈值
为了决定给定上下文中哪个标签最有可能,ContextTagger类使用出现频率。即使上下文词和标签只出现一次,它也会默认这样做,但是我们可以通过向UnigramTagger类传递一个cutoff值来设置最小频率阈值。在下面的示例中,我们在之前训练 UnigramTagger 的方法中传递了 cutoff 值:
示例
from nltk.tag import UnigramTagger from nltk.corpus import treebank train_sentences = treebank.tagged_sents()[:2500] Uni_tagger = UnigramTagger(train_sentences, cutoff = 4) test_sentences = treebank.tagged_sents()[1500:] Uni_tagger.evaluate(test_sentences)
输出
0.7357651629613641
自然语言工具包 - 组合标注器
组合标注器
组合标注器或将标注器彼此链接是 NLTK 的重要特性之一。组合标注器背后的主要概念是,如果一个标注器不知道如何标注一个词,它将被传递给链接的标注器。为了实现这个目的,SequentialBackoffTagger为我们提供了回退标注功能。
回退标注
如前所述,回退标注是SequentialBackoffTagger的重要特性之一,它允许我们将标注器组合起来,这样如果一个标注器不知道如何标注一个词,该词将被传递给下一个标注器,依此类推,直到没有剩余的回退标注器可供检查。
它是如何工作的?
实际上,SequentialBackoffTagger的每个子类都可以接受一个“backoff”关键字参数。这个关键字参数的值是另一个SequentialBackoffTagger实例。现在,每当初始化这个SequentialBackoffTagger类时,都会创建一个回退标注器的内部列表(自身作为第一个元素)。此外,如果给定一个回退标注器,则会将此回退标注器的内部列表附加到其中。
在下面的示例中,我们在上面训练UnigramTagger的 Python 方法中使用DefaulTagger作为回退标注器。
示例
在这个例子中,我们使用DefaulTagger作为回退标注器。每当UnigramTagger无法标注一个词时,回退标注器(在本例中为DefaulTagger)将用“NN”对其进行标注。
from nltk.tag import UnigramTagger
from nltk.tag import DefaultTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
back_tagger = DefaultTagger('NN')
Uni_tagger = UnigramTagger(train_sentences, backoff = back_tagger)
test_sentences = treebank.tagged_sents()[1500:]
Uni_tagger.evaluate(test_sentences)
输出
0.9061975746536931
从上面的输出中,您可以看到通过添加回退标注器,准确率提高了大约 2%。
使用 pickle 保存标注器
正如我们所看到的,训练标注器非常繁琐,而且也需要时间。为了节省时间,我们可以将训练好的标注器序列化(pickle),以便以后使用。在下面的示例中,我们将对我们已经训练好的名为“Uni_tagger”的标注器执行此操作。
示例
import pickle
f = open('Uni_tagger.pickle','wb')
pickle.dump(Uni_tagger, f)
f.close()
f = open('Uni_tagger.pickle','rb')
Uni_tagger = pickle.load(f)
NgramTagger 类
从前面单元中讨论的层次结构图中,UnigramTagger继承自NgramTagger类,但我们还有NgramTagger类的另外两个子类:
BigramTagger 子类
实际上,n 元语法是 n 个项目的子序列,因此,顾名思义,BigramTagger子类查看两个项目。第一个项目是前一个已标注的词,第二个项目是当前已标注的词。
TrigramTagger 子类
与BigramTagger类似,TrigramTagger子类查看三个项目,即前两个已标注的词和一个当前已标注的词。
实际上,如果我们像使用 UnigramTagger 子类一样单独应用BigramTagger和TrigramTagger子类,它们的表现都很差。让我们在下面的例子中看看。
使用 BigramTagger 子类
from nltk.tag import BigramTagger from nltk.corpus import treebank train_sentences = treebank.tagged_sents()[:2500] Bi_tagger = BigramTagger(train_sentences) test_sentences = treebank.tagged_sents()[1500:] Bi_tagger.evaluate(test_sentences)
输出
0.44669191071913594
使用 TrigramTagger 子类
from nltk.tag import TrigramTagger from nltk.corpus import treebank train_sentences = treebank.tagged_sents()[:2500] Tri_tagger = TrigramTagger(train_sentences) test_sentences = treebank.tagged_sents()[1500:] Tri_tagger.evaluate(test_sentences)
输出
0.41949863394526193
您可以将我们之前使用的 UnigramTagger(准确率约为 89%)的性能与 BigramTagger(准确率约为 44%)和 TrigramTagger(准确率约为 41%)进行比较。原因是 Bigram 和 Trigram 标注器无法从句子的第一个词学习上下文。另一方面,UnigramTagger 类不关心之前的上下文,并猜测每个词最常见的标签,因此能够具有较高的基准准确率。
组合 n 元语法标注器
从上面的例子可以看出,当我们将 Bigram 和 Trigram 标注器与回退标注结合使用时,它们可以做出贡献。在下面的示例中,我们将 Unigram、Bigram 和 Trigram 标注器与回退标注结合使用。该概念与之前结合 UnigramTagger 和回退标注器的方案相同。唯一的区别是我们使用了来自 tagger_util.py 的名为 backoff_tagger() 的函数(如下所示)来进行回退操作。
def backoff_tagger(train_sentences, tagger_classes, backoff=None):
for cls in tagger_classes:
backoff = cls(train_sentences, backoff=backoff)
return backoff
示例
from tagger_util import backoff_tagger
from nltk.tag import UnigramTagger
from nltk.tag import BigramTagger
from nltk.tag import TrigramTagger
from nltk.tag import DefaultTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
back_tagger = DefaultTagger('NN')
Combine_tagger = backoff_tagger(train_sentences,
[UnigramTagger, BigramTagger, TrigramTagger], backoff = back_tagger)
test_sentences = treebank.tagged_sents()[1500:]
Combine_tagger.evaluate(test_sentences)
输出
0.9234530029238365
从上面的输出中,我们可以看到它将准确率提高了大约 3%。
更多自然语言工具包标注器
词缀标注器
ContextTagger 子类的另一个重要类是 AffixTagger。在 AffixTagger 类中,上下文是单词的前缀或后缀。这就是 AffixTagger 类可以根据单词开头或结尾的固定长度子字符串学习标签的原因。
它是如何工作的?
它的工作取决于名为 affix_length 的参数,该参数指定前缀或后缀的长度。默认值为 3。但它是如何区分 AffixTagger 类学习的是单词的前缀还是后缀的呢?
affix_length=正数 - 如果 affix_lenght 的值为正数,则表示 AffixTagger 类将学习单词的前缀。
affix_length=负数 - 如果 affix_lenght 的值为负数,则表示 AffixTagger 类将学习单词的后缀。
为了更清楚地说明,在下面的示例中,我们将对已标注的 treebank 句子使用 AffixTagger 类。
示例
在这个例子中,AffixTagger 将学习单词的前缀,因为我们没有为 affix_length 参数指定任何值。该参数将采用默认值 3:
from nltk.tag import AffixTagger from nltk.corpus import treebank train_sentences = treebank.tagged_sents()[:2500] Prefix_tagger = AffixTagger(train_sentences) test_sentences = treebank.tagged_sents()[1500:] Prefix_tagger.evaluate(test_sentences)
输出
0.2800492099250667
让我们在下面的例子中看看当我们将 affix_length 参数的值设置为 4 时,准确率是多少:
from nltk.tag import AffixTagger from nltk.corpus import treebank train_sentences = treebank.tagged_sents()[:2500] Prefix_tagger = AffixTagger(train_sentences, affix_length=4 ) test_sentences = treebank.tagged_sents()[1500:] Prefix_tagger.evaluate(test_sentences)
输出
0.18154947354966527
示例
在这个例子中,AffixTagger 将学习单词的后缀,因为我们将为 affix_length 参数指定负值。
from nltk.tag import AffixTagger from nltk.corpus import treebank train_sentences = treebank.tagged_sents()[:2500] Suffix_tagger = AffixTagger(train_sentences, affix_length = -3) test_sentences = treebank.tagged_sents()[1500:] Suffix_tagger.evaluate(test_sentences)
输出
0.2800492099250667
Brill 标注器
Brill 标注器是一种基于转换的标注器。NLTK 提供了BrillTagger类,这是第一个不是SequentialBackoffTagger子类的标注器。与之相反,BrillTagger使用一系列规则来纠正初始标注器的结果。
它是如何工作的?
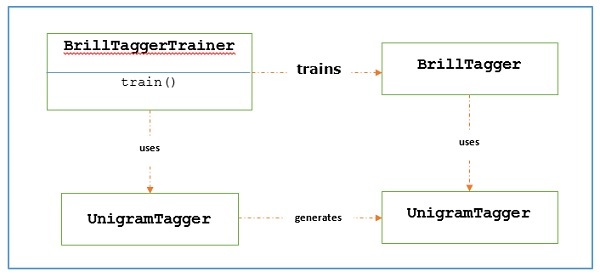
要使用BrillTaggerTrainer训练BrillTagger类,我们定义以下函数:
def train_brill_tagger(initial_tagger, train_sentences, **kwargs) -
templates = [ brill.Template(brill.Pos([-1])), brill.Template(brill.Pos([1])), brill.Template(brill.Pos([-2])), brill.Template(brill.Pos([2])), brill.Template(brill.Pos([-2, -1])), brill.Template(brill.Pos([1, 2])), brill.Template(brill.Pos([-3, -2, -1])), brill.Template(brill.Pos([1, 2, 3])), brill.Template(brill.Pos([-1]), brill.Pos([1])), brill.Template(brill.Word([-1])), brill.Template(brill.Word([1])), brill.Template(brill.Word([-2])), brill.Template(brill.Word([2])), brill.Template(brill.Word([-2, -1])), brill.Template(brill.Word([1, 2])), brill.Template(brill.Word([-3, -2, -1])), brill.Template(brill.Word([1, 2, 3])), brill.Template(brill.Word([-1]), brill.Word([1])), ] trainer = brill_trainer.BrillTaggerTrainer(initial_tagger, templates, deterministic=True) return trainer.train(train_sentences, **kwargs)
正如我们所看到的,此函数需要initial_tagger和train_sentences。它接受一个initial_tagger参数和一个模板列表,这些模板实现了BrillTemplate接口。BrillTemplate接口位于nltk.tbl.template模块中。其中一个实现是brill.Template类。
基于转换的标注器的主要作用是生成转换规则,以纠正初始标注器的输出,使其更符合训练句子。让我们看看下面的工作流程:
示例
对于此示例,我们将使用combine_tagger(我们在组合标注器时创建的,在上一个方法中从NgramTagger类的回退链中),作为initial_tagger。首先,让我们使用Combine.tagger评估结果,然后将其用作initial_tagger来训练 brill 标注器。
from tagger_util import backoff_tagger
from nltk.tag import UnigramTagger
from nltk.tag import BigramTagger
from nltk.tag import TrigramTagger
from nltk.tag import DefaultTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
back_tagger = DefaultTagger('NN')
Combine_tagger = backoff_tagger(
train_sentences, [UnigramTagger, BigramTagger, TrigramTagger], backoff = back_tagger
)
test_sentences = treebank.tagged_sents()[1500:]
Combine_tagger.evaluate(test_sentences)
输出
0.9234530029238365
现在,让我们看看当使用Combine_tagger作为initial_tagger来训练 brill 标注器时的评估结果:
from tagger_util import train_brill_tagger brill_tagger = train_brill_tagger(combine_tagger, train_sentences) brill_tagger.evaluate(test_sentences)
输出
0.9246832510505041
我们可以注意到,BrillTagger类的准确率比Combine_tagger略有提高。
完整的实现示例
from tagger_util import backoff_tagger
from nltk.tag import UnigramTagger
from nltk.tag import BigramTagger
from nltk.tag import TrigramTagger
from nltk.tag import DefaultTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
back_tagger = DefaultTagger('NN')
Combine_tagger = backoff_tagger(train_sentences,
[UnigramTagger, BigramTagger, TrigramTagger], backoff = back_tagger)
test_sentences = treebank.tagged_sents()[1500:]
Combine_tagger.evaluate(test_sentences)
from tagger_util import train_brill_tagger
brill_tagger = train_brill_tagger(combine_tagger, train_sentences)
brill_tagger.evaluate(test_sentences)
输出
0.9234530029238365 0.9246832510505041
TnT 标注器
TnT 标注器(代表 Trigrams’nTags)是一种基于二阶马尔可夫模型的统计标注器。
它是如何工作的?
我们可以通过以下步骤了解 TnT 标注器的工作原理:
首先,基于训练数据,TnT 标注器维护多个内部FreqDist和ConditionalFreqDist实例。
之后,这些频率分布将对 unigrams、bigrams 和 trigrams 进行计数。
现在,在标注过程中,它将使用频率计算每个单词可能标签的概率。
这就是为什么它不构建 NgramTagger 的回退链,而是使用所有 n 元语法模型来选择每个单词的最佳标签。让我们在下面的示例中评估 TnT 标注器的准确率:
from nltk.tag import tnt from nltk.corpus import treebank train_sentences = treebank.tagged_sents()[:2500] tnt_tagger = tnt.TnT() tnt_tagger.train(train_sentences) test_sentences = treebank.tagged_sents()[1500:] tnt_tagger.evaluate(test_sentences)
输出
0.9165508316157791
我们的准确率略低于 Brill 标注器的准确率。
请注意,我们需要先调用train(),然后才能调用evaluate(),否则我们将得到 0% 的准确率。
自然语言工具包 - 解析
句法分析及其在 NLP 中的相关性
单词“句法分析”(其起源于拉丁语单词“pars”(意思是“部分”))用于从文本中提取确切的含义或词典含义。它也称为句法分析或语法分析。通过比较形式语法的规则,句法分析检查文本的意义。例如,“给我热的冰淇淋”这样的句子将被句法分析器或语法分析器拒绝。
从这个意义上说,我们可以将句法分析或语法分析定义如下:
它可以定义为分析符合形式语法规则的自然语言符号串的过程。
我们可以通过以下几点了解句法分析在 NLP 中的相关性:
句法分析器用于报告任何语法错误。
它有助于从常见错误中恢复,以便可以继续处理程序的其余部分。
借助句法分析器可以创建句法树。
句法分析器用于创建符号表,这在 NLP 中起着重要作用。
句法分析器还用于生成中间表示 (IR)。
深度句法分析与浅层句法分析
| 深度句法分析 | 浅层句法分析 |
|---|---|
| 在深度句法分析中,搜索策略将为句子提供完整的句法结构。 | 它是从给定任务中分析句法信息的有限部分的任务。 |
| 它适用于复杂的 NLP 应用。 | 它可以用于不太复杂的 NLP 应用。 |
| 对话系统和摘要是使用深度句法分析的 NLP 应用示例。 | 信息抽取和文本挖掘是使用深度解析的NLP应用示例。 |
| 它也称为完全解析。 | 它也称为分块。 |
各种类型的解析器
如上所述,解析器基本上是对语法的程序化解释。它在搜索各种树的空间后,为给定的句子找到最佳树。让我们看看下面的一些可用解析器:
递归下降解析器
递归下降解析是最直接的解析形式之一。以下是关于递归下降解析器的一些重要几点:
它遵循自顶向下的过程。
它试图验证输入流的语法是否正确。
它从左到右读取输入句子。
递归下降解析器的一个必要操作是从输入流中读取字符并将它们与语法中的终结符匹配。
移进规约解析器
以下是关于移进规约解析器的一些重要几点:
它遵循简单的自底向上的过程。
它试图找到与语法产生式右侧对应的单词和短语序列,并将它们替换为产生式的左侧。
上述寻找单词序列的尝试将持续到整个句子被规约。
简单来说,移进规约解析器从输入符号开始,尝试构建解析树直到起始符号。
图表解析器
以下是关于图表解析器的一些重要几点:
它主要用于或适合于模糊语法,包括自然语言的语法。
它将动态规划应用于解析问题。
由于动态规划,部分假设的结果存储在一个称为“图表”的结构中。
“图表”也可以重复使用。
正则表达式解析器
正则表达式解析是最常用的解析技术之一。以下是关于正则表达式解析器的一些重要几点:
顾名思义,它使用基于词性标注字符串之上的语法形式定义的正则表达式。
它基本上使用这些正则表达式来解析输入句子并从中生成解析树。
示例
以下是正则表达式解析器的实际示例:
import nltk
sentence = [
("a", "DT"),
("clever", "JJ"),
("fox","NN"),
("was","VBP"),
("jumping","VBP"),
("over","IN"),
("the","DT"),
("wall","NN")
]
grammar = "NP:{<DT>?<JJ>*<NN>}"
Reg_parser = nltk.RegexpParser(grammar)
Reg_parser.parse(sentence)
Output = Reg_parser.parse(sentence)
Output.draw()
输出
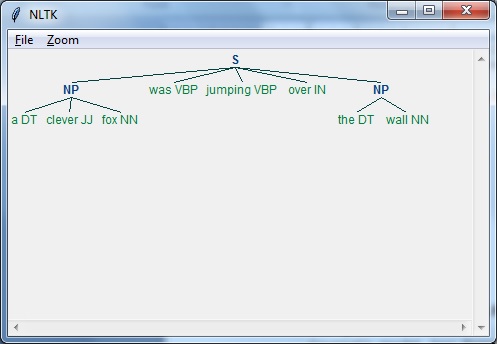
依存句法分析
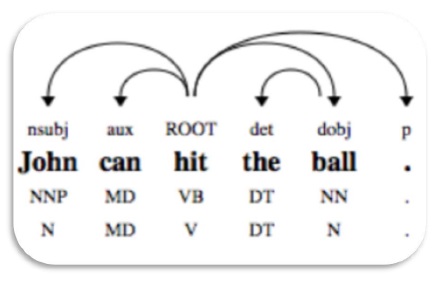
依存句法分析 (DP) 是一种现代解析机制,其主要概念是每个语言单位,即单词,通过直接链接相互关联。这些直接链接实际上是语言学中的“依存关系”。例如,下图显示了句子“John can hit the ball”的依存语法。
NLTK 包
我们有以下两种使用 NLTK 进行依存句法分析的方法:
概率投影依存句法分析器
这是我们可以使用 NLTK 进行依存句法分析的第一种方法。但是这个解析器受限于使用有限的训练数据进行训练。
斯坦福解析器
这是我们可以使用 NLTK 进行依存句法分析的另一种方法。斯坦福解析器是一种最先进的依存句法分析器。NLTK 围绕它有一个包装器。要使用它,我们需要下载以下两样东西:
语言模型(目标语言)。例如,英语语言模型。
示例
下载模型后,我们可以通过 NLTK 按如下方式使用它:
from nltk.parse.stanford import StanfordDependencyParser
path_jar = 'path_to/stanford-parser-full-2014-08-27/stanford-parser.jar'
path_models_jar = 'path_to/stanford-parser-full-2014-08-27/stanford-parser-3.4.1-models.jar'
dep_parser = StanfordDependencyParser(
path_to_jar = path_jar, path_to_models_jar = path_models_jar
)
result = dep_parser.raw_parse('I shot an elephant in my sleep')
depndency = result.next()
list(dependency.triples())
输出
[ ((u'shot', u'VBD'), u'nsubj', (u'I', u'PRP')), ((u'shot', u'VBD'), u'dobj', (u'elephant', u'NN')), ((u'elephant', u'NN'), u'det', (u'an', u'DT')), ((u'shot', u'VBD'), u'prep', (u'in', u'IN')), ((u'in', u'IN'), u'pobj', (u'sleep', u'NN')), ((u'sleep', u'NN'), u'poss', (u'my', u'PRP$')) ]
组块和信息提取
什么是分块?
分块是自然语言处理中的一个重要过程,用于识别词性 (POS) 和短语。简单来说,通过分块,我们可以得到句子的结构。它也称为部分解析。
分块模式和非分块
分块模式是词性 (POS) 标签的模式,用于定义构成分块的单词类型。我们可以借助修改后的正则表达式来定义分块模式。
此外,我们还可以定义分块中不应该包含哪些单词的模式,这些未分块的单词称为非分块。
实现示例
在下面的示例中,除了解析句子“the book has many chapters”的结果外,还有一个用于名词短语的语法,它结合了分块和非分块模式:
import nltk
sentence = [
("the", "DT"),
("book", "NN"),
("has","VBZ"),
("many","JJ"),
("chapters","NNS")
]
chunker = nltk.RegexpParser(
r'''
NP:{<DT><NN.*><.*>*<NN.*>}
}<VB.*>{
'''
)
chunker.parse(sentence)
Output = chunker.parse(sentence)
Output.draw()
输出
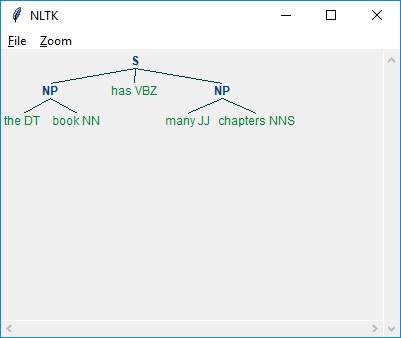
如上所示,指定分块的模式是使用大括号,如下所示:
{<DT><NN>}
要指定非分块,我们可以反转大括号,如下所示:
}<VB>{.
现在,对于特定的短语类型,这些规则可以组合成一个语法。
信息抽取
我们已经学习了可用于构建信息抽取引擎的词性标注器和解析器。让我们看看一个基本的信息抽取流程:
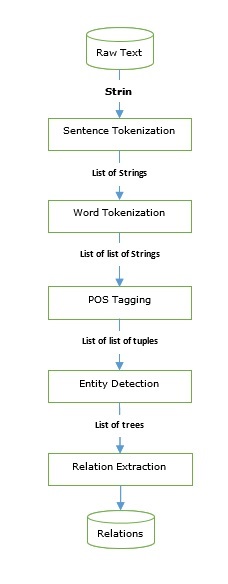
信息抽取有很多应用,包括:
- 商业智能
- 简历收集
- 媒体分析
- 情感检测
- 专利搜索
- 电子邮件扫描
命名实体识别 (NER)
命名实体识别 (NER) 实际上是一种提取一些最常见的实体(如姓名、组织、位置等)的方法。让我们看一个例子,它包含所有预处理步骤,例如句子标记化、词性标注、分块、NER,并遵循上图中提供的流程。
示例
Import nltk file = open ( # provide here the absolute path for the file of text for which we want NER ) data_text = file.read() sentences = nltk.sent_tokenize(data_text) tokenized_sentences = [nltk.word_tokenize(sentence) for sentence in sentences] tagged_sentences = [nltk.pos_tag(sentence) for sentence in tokenized_sentences] for sent in tagged_sentences: print nltk.ne_chunk(sent)
一些修改后的命名实体识别 (NER) 也可以用于提取诸如产品名称、生物医学实体、品牌名称等等之类的实体。
关系抽取
关系抽取是另一个常用的信息抽取操作,它是提取各种实体之间不同关系的过程。可能存在不同的关系,例如继承、同义词、类似物等,其定义取决于信息需求。例如,如果我们想查找一本书的作者,那么作者身份就是作者姓名和书名之间的关系。
示例
在下面的示例中,我们使用与命名实体关系 (NER) 一样在上面图示的 IE 流程,并使用基于 NER 标签的关系模式对其进行扩展。
import nltk
import re
IN = re.compile(r'.*\bin\b(?!\b.+ing)')
for doc in nltk.corpus.ieer.parsed_docs('NYT_19980315'):
for rel in nltk.sem.extract_rels('ORG', 'LOC', doc, corpus = 'ieer',
pattern = IN):
print(nltk.sem.rtuple(rel))
输出
[ORG: 'WHYY'] 'in' [LOC: 'Philadelphia'] [ORG: 'McGlashan & Sarrail'] 'firm in' [LOC: 'San Mateo'] [ORG: 'Freedom Forum'] 'in' [LOC: 'Arlington'] [ORG: 'Brookings Institution'] ', the research group in' [LOC: 'Washington'] [ORG: 'Idealab'] ', a self-described business incubator based in' [LOC: 'Los Angeles'] [ORG: 'Open Text'] ', based in' [LOC: 'Waterloo'] [ORG: 'WGBH'] 'in' [LOC: 'Boston'] [ORG: 'Bastille Opera'] 'in' [LOC: 'Paris'] [ORG: 'Omnicom'] 'in' [LOC: 'New York'] [ORG: 'DDB Needham'] 'in' [LOC: 'New York'] [ORG: 'Kaplan Thaler Group'] 'in' [LOC: 'New York'] [ORG: 'BBDO South'] 'in' [LOC: 'Atlanta'] [ORG: 'Georgia-Pacific'] 'in' [LOC: 'Atlanta']
在上面的代码中,我们使用了名为 ieer 的内置语料库。在这个语料库中,句子已经被标注到命名实体关系 (NER)。在这里,我们只需要指定我们想要的关系模式和我们希望关系定义的 NER 类型。在我们的示例中,我们定义了组织和位置之间的关系。我们提取了所有这些模式的组合。
自然语言工具包 - 变换组块
为什么要转换分块?
到目前为止,我们已经从句子中得到了分块或短语,但是我们应该如何处理它们呢?一项重要的任务是转换它们。但是为什么呢?这是为了做到以下几点:
- 语法纠正和
- 重新排列短语
过滤掉无关/无用的词
例如,如果你想判断一个短语的含义,那么有很多常用的词,例如“the”、“a”,是无关紧要或无用的。例如,请看以下短语:
“The movie was good”。
这里最重要的词是“movie”和“good”。其他词,“the”和“was”都是无用或无关紧要的。因为没有它们,我们也可以得到短语的相同含义。“Good movie”。
在下面的 Python 代码示例中,我们将学习如何借助词性标签去除无用/无关紧要的词并保留重要的词。
示例
首先,通过查看treebank语料库中的停用词,我们需要决定哪些词性标签是重要的,哪些是不重要的。让我们看看以下无关紧要的单词和标签表:
| 单词 | 标签 |
|---|---|
| a | DT |
| All | PDT |
| An | DT |
| And | CC |
| Or | CC |
| That | WDT |
| The | DT |
从上表可以看出,除了 CC 之外,所有其他标签都以 DT 结尾,这意味着我们可以通过查看标签的后缀来过滤掉无关紧要的单词。
对于此示例,我们将使用名为filter()的函数,它接受单个分块并返回一个不包含任何无关紧要标记单词的新分块。此函数会过滤掉以 DT 或 CC 结尾的任何标签。
示例
import nltk
def filter(chunk, tag_suffixes=['DT', 'CC']):
significant = []
for word, tag in chunk:
ok = True
for suffix in tag_suffixes:
if tag.endswith(suffix):
ok = False
break
if ok:
significant.append((word, tag))
return (significant)
现在,让我们在 Python 代码示例中使用此函数 filter() 来删除无关紧要的单词:
from chunk_parse import filter
filter([('the', 'DT'),('good', 'JJ'),('movie', 'NN')])
输出
[('good', 'JJ'), ('movie', 'NN')]
动词修正
很多时候,在现实世界语言中,我们会看到不正确的动词形式。例如,“is you fine?”是不正确的。这个句子中的动词形式不正确。句子应该是“are you fine?”NLTK 为我们提供了一种通过创建动词修正映射来纠正此类错误的方法。这些修正映射根据分块中是否存在复数或单数名词而使用。
示例
要实现 Python 代码示例,我们首先需要定义动词修正映射。让我们创建两个映射,如下所示:
复数到单数映射
plural= {
('is', 'VBZ'): ('are', 'VBP'),
('was', 'VBD'): ('were', 'VBD')
}
单数到复数映射
singular = {
('are', 'VBP'): ('is', 'VBZ'),
('were', 'VBD'): ('was', 'VBD')
}
如上所示,每个映射都有一个标记的动词,它映射到另一个标记的动词。我们示例中的初始映射涵盖了is 到 are,was 到 were的基本映射,反之亦然。
接下来,我们将定义一个名为verbs()的函数,你可以在其中传递带有不正确动词形式的分块,并将得到一个已更正的分块。为了完成此操作,verb()函数使用一个名为index_chunk()的辅助函数,该函数将搜索分块以查找第一个标记单词的位置。
让我们看看这些函数:
def index_chunk(chunk, pred, start = 0, step = 1):
l = len(chunk)
end = l if step > 0 else -1
for i in range(start, end, step):
if pred(chunk[i]):
return i
return None
def tag_startswith(prefix):
def f(wt):
return wt[1].startswith(prefix)
return f
def verbs(chunk):
vbidx = index_chunk(chunk, tag_startswith('VB'))
if vbidx is None:
return chunk
verb, vbtag = chunk[vbidx]
nnpred = tag_startswith('NN')
nnidx = index_chunk(chunk, nnpred, start = vbidx+1)
if nnidx is None:
nnidx = index_chunk(chunk, nnpred, start = vbidx-1, step = -1)
if nnidx is None:
return chunk
noun, nntag = chunk[nnidx]
if nntag.endswith('S'):
chunk[vbidx] = plural.get((verb, vbtag), (verb, vbtag))
else:
chunk[vbidx] = singular.get((verb, vbtag), (verb, vbtag))
return chunk
将这些函数保存在安装了 Python 或 Anaconda 的本地目录中的 Python 文件中并运行它。我将其保存为verbcorrect.py。
现在,让我们在一个词性标注的is you fine分块上调用verbs()函数:
from verbcorrect import verbs
verbs([('is', 'VBZ'), ('you', 'PRP$'), ('fine', 'VBG')])
输出
[('are', 'VBP'), ('you', 'PRP$'), ('fine','VBG')]
消除短语中的被动语态
另一个有用的任务是从短语中消除被动语态。这可以通过围绕动词交换单词来完成。例如,“the tutorial was great”可以转换为“the great tutorial”。
示例
为了实现这一点,我们定义了一个名为eliminate_passive()的函数,它将使用动词作为枢轴点来交换分块的右侧和左侧。为了找到要围绕其旋转的动词,它还将使用上面定义的index_chunk()函数。
def eliminate_passive(chunk):
def vbpred(wt):
word, tag = wt
return tag != 'VBG' and tag.startswith('VB') and len(tag) > 2
vbidx = index_chunk(chunk, vbpred)
if vbidx is None:
return chunk
return chunk[vbidx+1:] + chunk[:vbidx]
现在,让我们在一个词性标注的the tutorial was great分块上调用eliminate_passive()函数:
from passiveverb import eliminate_passive
eliminate_passive(
[
('the', 'DT'), ('tutorial', 'NN'), ('was', 'VBD'), ('great', 'JJ')
]
)
输出
[('great', 'JJ'), ('the', 'DT'), ('tutorial', 'NN')]
交换名词基数
众所周知,像 5 这样的基数词在一个块中被标记为 CD。这些基数词经常出现在名词之前或之后,但出于规范化的目的,始终将它们放在名词之前是有用的。例如,日期 **1月5日** 可以写成 **5月1日**。让我们通过以下示例来理解它。
示例
为了实现这一点,我们定义了一个名为 **swapping_cardinals()** 的函数,它将交换出现在名词之后任何基数词与名词。这样,基数词就会出现在名词的前面。为了与给定的标签进行相等性比较,它使用了一个我们命名为 **tag_eql()** 的辅助函数。
def tag_eql(tag):
def f(wt):
return wt[1] == tag
return f
现在我们可以定义 swapping_cardinals() 了 -
def swapping_cardinals (chunk):
cdidx = index_chunk(chunk, tag_eql('CD'))
if not cdidx or not chunk[cdidx-1][1].startswith('NN'):
return chunk
noun, nntag = chunk[cdidx-1]
chunk[cdidx-1] = chunk[cdidx]
chunk[cdidx] = noun, nntag
return chunk
现在,让我们在日期 **“1月5日”** 上调用 **swapping_cardinals()** 函数 -
from Cardinals import swapping_cardinals()
swapping_cardinals([('Janaury', 'NNP'), ('5', 'CD')])
输出
[('10', 'CD'), ('January', 'NNP')]
10 January
自然语言工具包 - 变换树
以下是转换树的两个原因 -
- 修改深层解析树,以及
- 展平深层解析树
将树或子树转换为句子
我们将要讨论的第一个方法是将树或子树转换回句子或块字符串。这非常简单,让我们在以下示例中看看 -
示例
from nltk.corpus import treebank_chunk tree = treebank_chunk.chunked_sents()[2] ' '.join([w for w, t in tree.leaves()])
输出
'Rudolph Agnew , 55 years old and former chairman of Consolidated Gold Fields PLC , was named a nonexecutive director of this British industrial conglomerate .'
深层树展平
嵌套短语的深层树不能用于训练块,因此我们必须在使用之前展平它们。在下面的示例中,我们将使用 **treebank** 语料库中的第 3 个解析句子,它是一个嵌套短语的深层树。
示例
为了实现这一点,我们定义了一个名为 **deeptree_flat()** 的函数,它将接收单个树,并返回一个新树,该新树只保留最低级别的树。为了完成大部分工作,它使用了一个我们命名为 **childtree_flat()** 的辅助函数。
from nltk.tree import Tree
def childtree_flat(trees):
children = []
for t in trees:
if t.height() < 3:
children.extend(t.pos())
elif t.height() == 3:
children.append(Tree(t.label(), t.pos()))
else:
children.extend(flatten_childtrees([c for c in t]))
return children
def deeptree_flat(tree):
return Tree(tree.label(), flatten_childtrees([c for c in tree]))
现在,让我们在来自 **treebank** 语料库的第 3 个解析句子(它是嵌套短语的深层树)上调用 **deeptree_flat()** 函数。我们将这些函数保存在名为 deeptree.py 的文件中。
from deeptree import deeptree_flat from nltk.corpus import treebank deeptree_flat(treebank.parsed_sents()[2])
输出
Tree('S', [Tree('NP', [('Rudolph', 'NNP'), ('Agnew', 'NNP')]),
(',', ','), Tree('NP', [('55', 'CD'),
('years', 'NNS')]), ('old', 'JJ'), ('and', 'CC'),
Tree('NP', [('former', 'JJ'),
('chairman', 'NN')]), ('of', 'IN'), Tree('NP', [('Consolidated', 'NNP'),
('Gold', 'NNP'), ('Fields', 'NNP'), ('PLC',
'NNP')]), (',', ','), ('was', 'VBD'),
('named', 'VBN'), Tree('NP-SBJ', [('*-1', '-NONE-')]),
Tree('NP', [('a', 'DT'), ('nonexecutive', 'JJ'), ('director', 'NN')]),
('of', 'IN'), Tree('NP',
[('this', 'DT'), ('British', 'JJ'),
('industrial', 'JJ'), ('conglomerate', 'NN')]), ('.', '.')])
构建浅层树
在上一节中,我们通过只保留最低级别的子树来展平嵌套短语的深层树。在本节中,我们将只保留最高级别的子树,即构建浅层树。在下面的示例中,我们将使用 **treebank** 语料库中的第 3 个解析句子,它是一个嵌套短语的深层树。
示例
为了实现这一点,我们定义了一个名为 **tree_shallow()** 的函数,它将通过只保留顶层子树标签来消除所有嵌套子树。
from nltk.tree import Tree
def tree_shallow(tree):
children = []
for t in tree:
if t.height() < 3:
children.extend(t.pos())
else:
children.append(Tree(t.label(), t.pos()))
return Tree(tree.label(), children)
现在,让我们在来自 **treebank** 语料库的第 3 个解析句子(它是嵌套短语的深层树)上调用 **tree_shallow()** 函数。我们将这些函数保存在名为 shallowtree.py 的文件中。
from shallowtree import shallow_tree from nltk.corpus import treebank tree_shallow(treebank.parsed_sents()[2])
输出
Tree('S', [Tree('NP-SBJ-1', [('Rudolph', 'NNP'), ('Agnew', 'NNP'), (',', ','),
('55', 'CD'), ('years', 'NNS'), ('old', 'JJ'), ('and', 'CC'),
('former', 'JJ'), ('chairman', 'NN'), ('of', 'IN'), ('Consolidated', 'NNP'),
('Gold', 'NNP'), ('Fields', 'NNP'), ('PLC', 'NNP'), (',', ',')]),
Tree('VP', [('was', 'VBD'), ('named', 'VBN'), ('*-1', '-NONE-'), ('a', 'DT'),
('nonexecutive', 'JJ'), ('director', 'NN'), ('of', 'IN'), ('this', 'DT'),
('British', 'JJ'), ('industrial', 'JJ'), ('conglomerate', 'NN')]), ('.', '.')])
我们可以通过获取树的高度来查看差异 -
from nltk.corpus import treebank tree_shallow(treebank.parsed_sents()[2]).height()
输出
3
from nltk.corpus import treebank treebank.parsed_sents()[2].height()
输出
9
树标签转换
在解析树中,存在各种在块树中不存在的 **Tree** 标签类型。但在使用解析树来训练分块器时,我们希望通过将一些树标签转换为更常见的标签类型来减少这种多样性。例如,我们有两个替代的 NP 子树,即 NP-SBL 和 NP-TMP。我们可以将它们都转换为 NP。让我们看看如何在以下示例中做到这一点。
示例
为了实现这一点,我们定义了一个名为 **tree_convert()** 的函数,它接受以下两个参数 -
- 要转换的树
- 标签转换映射
此函数将返回一个新树,其中所有匹配的标签都根据映射中的值进行了替换。
from nltk.tree import Tree
def tree_convert(tree, mapping):
children = []
for t in tree:
if isinstance(t, Tree):
children.append(convert_tree_labels(t, mapping))
else:
children.append(t)
label = mapping.get(tree.label(), tree.label())
return Tree(label, children)
现在,让我们在来自 **treebank** 语料库的第 3 个解析句子(它是嵌套短语的深层树)上调用 **tree_convert()** 函数。我们将这些函数保存在名为 **converttree.py** 的文件中。
from converttree import tree_convert
from nltk.corpus import treebank
mapping = {'NP-SBJ': 'NP', 'NP-TMP': 'NP'}
convert_tree_labels(treebank.parsed_sents()[2], mapping)
输出
Tree('S', [Tree('NP-SBJ-1', [Tree('NP', [Tree('NNP', ['Rudolph']),
Tree('NNP', ['Agnew'])]), Tree(',', [',']),
Tree('UCP', [Tree('ADJP', [Tree('NP', [Tree('CD', ['55']),
Tree('NNS', ['years'])]),
Tree('JJ', ['old'])]), Tree('CC', ['and']),
Tree('NP', [Tree('NP', [Tree('JJ', ['former']),
Tree('NN', ['chairman'])]), Tree('PP', [Tree('IN', ['of']),
Tree('NP', [Tree('NNP', ['Consolidated']),
Tree('NNP', ['Gold']), Tree('NNP', ['Fields']),
Tree('NNP', ['PLC'])])])])]), Tree(',', [','])]),
Tree('VP', [Tree('VBD', ['was']),Tree('VP', [Tree('VBN', ['named']),
Tree('S', [Tree('NP', [Tree('-NONE-', ['*-1'])]),
Tree('NP-PRD', [Tree('NP', [Tree('DT', ['a']),
Tree('JJ', ['nonexecutive']), Tree('NN', ['director'])]),
Tree('PP', [Tree('IN', ['of']), Tree('NP',
[Tree('DT', ['this']), Tree('JJ', ['British']), Tree('JJ', ['industrial']),
Tree('NN', ['conglomerate'])])])])])])]), Tree('.', ['.'])])
自然语言工具包 - 文本分类
什么是文本分类?
文本分类,顾名思义,是将文本或文档片段进行分类的方法。但是这里的问题是为什么我们需要使用文本分类器?一旦检查了文档或文本片段中的词语使用情况,分类器就能决定应该为其分配哪个类别标签。
二元分类器
顾名思义,二元分类器将在两个标签之间进行决策。例如,正面或负面。在这种情况下,文本或文档片段可以是其中一个标签,但不能同时是两个标签。
多标签分类器
与二元分类器相反,多标签分类器可以为文本或文档片段分配一个或多个标签。
标记的与未标记的特征集
特征名到特征值的键值映射称为特征集。标记的特征集或训练数据对于分类训练非常重要,以便它以后可以对未标记的特征集进行分类。
| 标记的特征集 | 未标记的特征集 |
|---|---|
| 它是一个看起来像 (feat, label) 的元组。 | 它本身就是一个特征。 |
| 它是一个具有已知类别标签的实例。 | 如果没有关联的标签,我们可以称之为实例。 |
| 用于训练分类算法。 | 一旦训练完成,分类算法就可以对未标记的特征集进行分类。 |
文本特征提取
文本特征提取,顾名思义,是将单词列表转换为分类器可用的特征集的过程。我们必须将我们的文本转换为 **'dict'** 样式的特征集,因为自然语言工具包 (NLTK) 期望 **'dict'** 样式的特征集。
词袋 (BoW) 模型
BoW 是 NLP 中最简单的模型之一,用于从文本或文档片段中提取特征,以便它可以用于建模,例如在 ML 算法中。它基本上根据实例的所有单词构建单词存在特征集。此方法背后的概念是,它不关心单词出现的次数或单词的顺序,它只关心单词是否存在于单词列表中。
示例
对于此示例,我们将定义一个名为 bow() 的函数 -
def bow(words): return dict([(word, True) for word in words])
现在,让我们在单词上调用 **bow()** 函数。我们将这些函数保存在名为 bagwords.py 的文件中。
from bagwords import bow bow(['we', 'are', 'using', 'tutorialspoint'])
输出
{'we': True, 'are': True, 'using': True, 'tutorialspoint': True}
训练分类器
在前面的章节中,我们学习了如何从文本中提取特征。所以现在我们可以训练一个分类器了。第一个也是最简单的分类器是 **NaiveBayesClassifier** 类。
朴素贝叶斯分类器
为了预测给定特征集属于特定标签的概率,它使用贝叶斯定理。贝叶斯定理的公式如下。
$$P(A|B)=\frac{P(B|A)P(A)}{P(B)}$$这里,
**P(A|B)** - 它也称为后验概率,即给定第二个事件 B 发生的情况下,第一个事件 A 发生的概率。
**P(B|A)** - 它是第一个事件 A 发生后第二个事件 B 发生的概率。
**P(A), P(B)** - 它也称为先验概率,即第一个事件 A 或第二个事件 B 发生的概率。
为了训练朴素贝叶斯分类器,我们将使用来自 NLTK 的 **movie_reviews** 语料库。此语料库包含两类文本,即:**pos** 和 **neg**。这些类别使在其上训练的分类器成为二元分类器。语料库中的每个文件都由两个组成,一个是正面影评,另一个是负面影评。在我们的示例中,我们将每个文件作为训练和测试分类器的单个实例。
示例
为了训练分类器,我们需要一个标记的特征集列表,其形式为 [(**featureset**, **label**)]。这里的 **featureset** 变量是一个 **dict**,而 label 是 **featureset** 的已知类别标签。我们将创建一个名为 **label_corpus()** 的函数,它将接收一个名为 **movie_reviews** 的语料库,以及一个名为 **feature_detector** 的函数(默认为 **词袋**)。它将构建并返回一个 {label: [featureset]} 形式的映射。之后,我们将使用此映射来创建标记的训练实例和测试实例列表。
import collections
def label_corpus(corp, feature_detector=bow):
label_feats = collections.defaultdict(list)
for label in corp.categories():
for fileid in corp.fileids(categories=[label]):
feats = feature_detector(corp.words(fileids=[fileid]))
label_feats[label].append(feats)
return label_feats
在上述函数的帮助下,我们将得到一个 **{label:fetaureset}** 映射。现在我们将定义另一个名为 **split** 的函数,它将接收从 **label_corpus()** 函数返回的映射,并将每个特征集列表拆分为标记的训练实例和测试实例。
def split(lfeats, split=0.75):
train_feats = []
test_feats = []
for label, feats in lfeats.items():
cutoff = int(len(feats) * split)
train_feats.extend([(feat, label) for feat in feats[:cutoff]])
test_feats.extend([(feat, label) for feat in feats[cutoff:]])
return train_feats, test_feats
现在,让我们在我们的语料库 movie_reviews 上使用这些函数 -
from nltk.corpus import movie_reviews from featx import label_feats_from_corpus, split_label_feats movie_reviews.categories()
输出
['neg', 'pos']
示例
lfeats = label_feats_from_corpus(movie_reviews) lfeats.keys()
输出
dict_keys(['neg', 'pos'])
示例
train_feats, test_feats = split_label_feats(lfeats, split = 0.75) len(train_feats)
输出
1500
示例
len(test_feats)
输出
500
我们已经看到,在 **movie_reviews** 语料库中,有 1000 个 pos 文件和 1000 个 neg 文件。我们最终还得到了 1500 个标记的训练实例和 500 个标记的测试实例。
现在让我们使用它的 **train()** 类方法来训练 **NaïveBayesClassifier** -
from nltk.classify import NaiveBayesClassifier NBC = NaiveBayesClassifier.train(train_feats) NBC.labels()
输出
['neg', 'pos']
决策树分类器
另一个重要的分类器是决策树分类器。在这里,为了训练它,**DecisionTreeClassifier** 类将创建一个树结构。在这个树结构中,每个节点对应一个特征名,分支对应特征值。沿着分支向下,我们将到达树的叶子,即分类标签。
为了训练决策树分类器,我们将使用相同的训练和测试特征,即我们从 **movie_reviews** 语料库创建的 **train_feats** 和 **test_feats** 变量。
示例
为了训练这个分类器,我们将调用 **DecisionTreeClassifier.train()** 类方法,如下所示 -
from nltk.classify import DecisionTreeClassifier decisiont_classifier = DecisionTreeClassifier.train( train_feats, binary = True, entropy_cutoff = 0.8, depth_cutoff = 5, support_cutoff = 30 ) accuracy(decisiont_classifier, test_feats)
输出
0.725
最大熵分类器
另一个重要的分类器是 **MaxentClassifier**,它也称为 **条件指数分类器** 或 **逻辑回归分类器**。在这里,为了训练它,**MaxentClassifier** 类将使用编码将标记的特征集转换为向量。
为了训练决策树分类器,我们将使用相同的训练和测试特征,即我们从 **movie_reviews** 语料库创建的 **train_feats** 和 **test_feats** 变量。
示例
为了训练这个分类器,我们将调用 **MaxentClassifier.train()** 类方法,如下所示 -
from nltk.classify import MaxentClassifier maxent_classifier = MaxentClassifier .train(train_feats,algorithm = 'gis', trace = 0, max_iter = 10, min_lldelta = 0.5) accuracy(maxent_classifier, test_feats)
输出
0.786
Scikit-learn 分类器
Scikit-learn 是最好的机器学习 (ML) 库之一。它实际上包含各种用途的各种 ML 算法,但它们都具有以下相同的拟合设计模式 -
- 将模型拟合到数据
- 并使用该模型进行预测
在这里,我们将使用 NLTK 的 **SklearnClassifier** 类,而不是直接访问 scikit-learn 模型。此类是 scikit-learn 模型的包装类,使其符合 NLTK 的 Classifier 接口。
我们将遵循以下步骤来训练 **SklearnClassifier** 类 -
**步骤 1** - 首先,我们将像在之前的配方中那样创建训练特征。
**步骤 2** - 现在,选择并导入 Scikit-learn 算法。
**步骤 3** - 接下来,我们需要使用选择的算法构造一个 **SklearnClassifier** 类。
**步骤 4** - 最后,我们将使用我们的训练特征来训练 **SklearnClassifier** 类。
让我们在下面的 Python 示例中实现这些步骤 -
from nltk.classify.scikitlearn import SklearnClassifier from sklearn.naive_bayes import MultinomialNB sklearn_classifier = SklearnClassifier(MultinomialNB()) sklearn_classifier.train(train_feats) <SklearnClassifier(MultinomialNB(alpha = 1.0,class_prior = None,fit_prior = True))> accuracy(sk_classifier, test_feats)
输出
0.885
测量精度和召回率
在训练各种分类器时,我们也测量了它们的准确性。但是除了准确性之外,还有许多其他指标用于评估分类器。这两个指标是 **精度** 和 **召回率**。
示例
本例将计算前面训练的NaiveBayesClassifier类的精确率和召回率。为此,我们将创建一个名为metrics_PR()的函数,它将接受两个参数:一个是被训练的分类器,另一个是标记的测试特征。这两个参数与计算分类器精度时传递的参数相同。
import collections
from nltk import metrics
def metrics_PR(classifier, testfeats):
refsets = collections.defaultdict(set)
testsets = collections.defaultdict(set)
for i, (feats, label) in enumerate(testfeats):
refsets[label].add(i)
observed = classifier.classify(feats)
testsets[observed].add(i)
precisions = {}
recalls = {}
for label in classifier.labels():
precisions[label] = metrics.precision(refsets[label],testsets[label])
recalls[label] = metrics.recall(refsets[label], testsets[label])
return precisions, recalls
让我们调用此函数来查找精确率和召回率:
from metrics_classification import metrics_PR nb_precisions, nb_recalls = metrics_PR(nb_classifier,test_feats) nb_precisions['pos']
输出
0.6713532466435213
示例
nb_precisions['neg']
输出
0.9676271186440678
示例
nb_recalls['pos']
输出
0.96
示例
nb_recalls['neg']
输出
0.478
分类器与投票的组合
组合分类器是提高分类性能的最佳方法之一。而投票是组合多个分类器的最佳方法之一。对于投票,我们需要奇数个分类器。在下面的Python示例中,我们将组合三个分类器,即NaiveBayesClassifier类、DecisionTreeClassifier类和MaxentClassifier类。
为此,我们将定义一个名为voting_classifiers()的函数,如下所示。
import itertools
from nltk.classify import ClassifierI
from nltk.probability import FreqDist
class Voting_classifiers(ClassifierI):
def __init__(self, *classifiers):
self._classifiers = classifiers
self._labels = sorted(set(itertools.chain(*[c.labels() for c in classifiers])))
def labels(self):
return self._labels
def classify(self, feats):
counts = FreqDist()
for classifier in self._classifiers:
counts[classifier.classify(feats)] += 1
return counts.max()
让我们调用此函数来组合三个分类器并查找精度:
from vote_classification import Voting_classifiers combined_classifier = Voting_classifiers(NBC, decisiont_classifier, maxent_classifier) combined_classifier.labels()
输出
['neg', 'pos']
示例
accuracy(combined_classifier, test_feats)
输出
0.948
从以上输出可以看出,组合分类器的精度高于单个分类器。