- 自然语言工具包教程
- 自然语言工具包 - 首页
- 自然语言工具包 - 简介
- 自然语言工具包 - 入门
- 自然语言工具包 - 文本分词
- 训练分词器和过滤停用词
- 在WordNet中查找单词
- 词干提取和词形还原
- 自然语言工具包 - 词语替换
- 同义词和反义词替换
- 语料库读取器和自定义语料库
- 词性标注基础
- 自然语言工具包 - 单词标注器
- 自然语言工具包 - 组合标注器
- 自然语言工具包 - 更多NLTK标注器
- 自然语言工具包 - 语法分析
- 组块和信息提取
- 自然语言工具包 - 变换组块
- 自然语言工具包 - 变换树
- 自然语言工具包 - 文本分类
- 自然语言工具包资源
- 自然语言工具包 - 快速指南
- 自然语言工具包 - 有用资源
- 自然语言工具包 - 讨论
自然语言工具包 - 单词标注器
什么是Unigram标注器?
顾名思义,Unigram标注器只使用单个单词作为其确定词性(Part-of-Speech)标记的上下文。简单来说,Unigram标注器是一个基于上下文的标注器,其上下文是一个单词,即Unigram。
它是如何工作的?
NLTK提供了一个名为UnigramTagger的模块来实现此目的。但在深入了解其工作原理之前,让我们借助下图了解其层次结构:
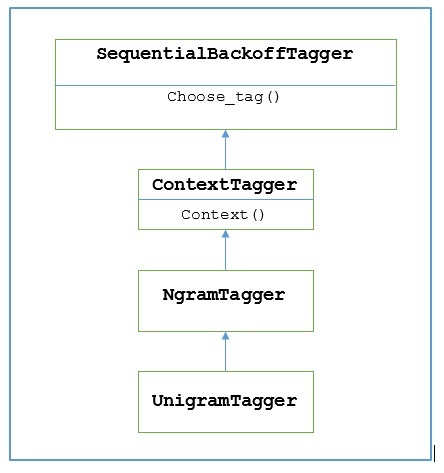
从上图可以看出,UnigramTagger继承自NgramTagger,后者是ContextTagger的子类,而ContextTagger继承自SequentialBackoffTagger。
UnigramTagger的工作原理如下所示:
正如我们所看到的,UnigramTagger继承自ContextTagger,它实现了一个context()方法。此context()方法采用与choose_tag()方法相同的三个参数。
context()方法的结果将是单词标记,该标记将进一步用于创建模型。创建模型后,单词标记还用于查找最佳标记。
通过这种方式,UnigramTagger将根据已标注句子的列表构建上下文模型。
训练Unigram标注器
NLTK的UnigramTagger可以通过在初始化时提供已标注句子的列表来进行训练。在下面的示例中,我们将使用treebank语料库的已标注句子。我们将使用该语料库的前2500个句子。
示例
首先从nltk导入UnigramTagger模块:
from nltk.tag import UnigramTagger
接下来,导入您要使用的语料库。这里我们使用treebank语料库:
from nltk.corpus import treebank
现在,获取用于训练的句子。我们取前2500个句子用于训练,并将它们进行标注:
train_sentences = treebank.tagged_sents()[:2500]
接下来,将UnigramTagger应用于用于训练的句子:
Uni_tagger = UnigramTagger(train_sentences)
取一些句子(等于或少于训练用的2500个句子)用于测试。这里我们取前1500个句子用于测试:
test_sentences = treebank.tagged_sents()[1500:] Uni_tagger.evaluate(test_sents)
输出
0.8942306156033808
在这里,对于使用单个单词查找来确定词性标记的标注器,我们获得了大约89%的准确率。
完整的实现示例
from nltk.tag import UnigramTagger from nltk.corpus import treebank train_sentences = treebank.tagged_sents()[:2500] Uni_tagger = UnigramTagger(train_sentences) test_sentences = treebank.tagged_sents()[1500:] Uni_tagger.evaluate(test_sentences)
输出
0.8942306156033808
覆盖上下文模型
从上面显示UnigramTagger层次结构的图表中,我们知道所有继承自ContextTagger的标注器,都可以使用预建模型,而不是训练自己的模型。这个预建模型只是一个简单的Python字典,它将上下文键映射到标记。对于UnigramTagger,上下文键是单个单词,而对于其他NgramTagger子类,它将是元组。
我们可以通过向UnigramTagger类传递另一个简单的模型来覆盖此上下文模型,而不是传递训练集。让我们通过下面的简单示例来理解它:
示例
from nltk.tag import UnigramTagger
from nltk.corpus import treebank
Override_tagger = UnigramTagger(model = {‘Vinken’ : ‘NN’})
Override_tagger.tag(treebank.sents()[0])
输出
[
('Pierre', None),
('Vinken', 'NN'),
(',', None),
('61', None),
('years', None),
('old', None),
(',', None),
('will', None),
('join', None),
('the', None),
('board', None),
('as', None),
('a', None),
('nonexecutive', None),
('director', None),
('Nov.', None),
('29', None),
('.', None)
]
由于我们的模型只包含'Vinken'作为唯一的上下文键,您可以从上面的输出中观察到,只有这个单词得到了标记,其他所有单词的标记都是None。
设置最小频率阈值
为了确定给定上下文中哪个标记最有可能,ContextTagger类使用出现频率。即使上下文单词和标记只出现一次,它也会默认这样做,但是我们可以通过向UnigramTagger类传递cutoff值来设置最小频率阈值。在下面的示例中,我们在前面训练UnigramTagger的示例中传递了cutoff值:
示例
from nltk.tag import UnigramTagger from nltk.corpus import treebank train_sentences = treebank.tagged_sents()[:2500] Uni_tagger = UnigramTagger(train_sentences, cutoff = 4) test_sentences = treebank.tagged_sents()[1500:] Uni_tagger.evaluate(test_sentences)
输出
0.7357651629613641