- 自然语言工具包教程
- 自然语言工具包 - 首页
- 自然语言工具包 - 简介
- 自然语言工具包 - 入门
- 自然语言工具包 - 文本分词
- 训练分词器和过滤停用词
- 在Wordnet中查找单词
- 词干提取和词形还原
- 自然语言工具包 - 词语替换
- 同义词和反义词替换
- 语料库读取器和自定义语料库
- 词性标注基础
- 自然语言工具包 - 一元标注器
- 自然语言工具包 - 组合标注器
- 自然语言工具包 - 更多NLTK标注器
- 自然语言工具包 - 语法分析
- 组块和信息提取
- 自然语言工具包 - 转换组块
- 自然语言工具包 - 转换树
- 自然语言工具包 - 文本分类
- 自然语言工具包资源
- 自然语言工具包 - 快速指南
- 自然语言工具包 - 有用资源
- 自然语言工具包 - 讨论
自然语言工具包 - 语法分析
语法分析及其在NLP中的相关性
单词“Parsing”(源自拉丁语单词‘pars’,意思是‘部分’)用于从文本中提取确切含义或字典含义。它也称为句法分析或语法分析。通过比较形式语法的规则,句法分析检查文本的意义性。例如,句子“给我热冰淇淋”将被语法分析器或句法分析器拒绝。
从这个意义上说,我们可以将语法分析或句法分析定义如下:
可以将其定义为分析自然语言中符合形式语法规则的符号串的过程。
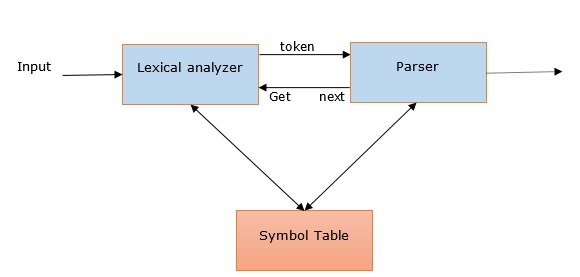
我们可以通过以下几点了解语法分析在NLP中的相关性:
语法分析器用于报告任何语法错误。
它有助于从常见错误中恢复,以便可以继续处理程序的其余部分。
借助语法分析器创建语法树。
语法分析器用于创建符号表,符号表在NLP中起着重要作用。
语法分析器还用于生成中间表示(IR)。
深层语法分析与浅层语法分析
| 深层语法分析 | 浅层语法分析 |
|---|---|
| 在深层语法分析中,搜索策略将为句子提供完整的句法结构。 | 它是从给定任务中解析句法信息的有限部分的任务。 |
| 它适用于复杂的NLP应用。 | 它可用于不太复杂的NLP应用。 |
| 对话系统和摘要是使用深层语法分析的NLP应用示例。 | 信息提取和文本挖掘是使用深层语法分析的NLP应用示例。 |
| 它也称为完全语法分析。 | 它也称为组块。 |
各种类型的语法分析器
如前所述,语法分析器基本上是语法的过程化解释。它在搜索各种树的空间后,为给定句子找到最优树。让我们看看下面一些可用的语法分析器:
递归下降语法分析器
递归下降语法分析是最直接的语法分析形式之一。以下是关于递归下降语法分析器的一些要点:
它遵循自顶向下的过程。
它尝试验证输入流的语法是否正确。
它从左到右读取输入句子。
递归下降语法分析器的一个必要操作是从输入流中读取字符并将它们与语法中的终结符匹配。
移进-归约语法分析器
以下是关于移进-归约语法分析器的一些要点:
它遵循简单的自底向上的过程。
它试图找到与语法产生式的右侧相对应的单词和短语序列,并用产生式的左侧替换它们。
上述查找单词序列的尝试将持续到整个句子被归约。
换句话说,移进-归约语法分析器从输入符号开始,尝试构建语法树直到起始符号。
图表语法分析器
以下是关于图表语法分析器的一些要点:
它主要对歧义语法(包括自然语言语法)有用或适用。
它将动态规划应用于语法分析问题。
由于动态规划,部分假设结果存储在一个称为“图表”的结构中。
“图表”也可以重复使用。
正则表达式语法分析器
正则表达式语法分析是最常用的语法分析技术之一。以下是关于正则表达式语法分析器的一些要点:
顾名思义,它在词性标注字符串之上使用以语法形式定义的正则表达式。
它基本上使用这些正则表达式来解析输入句子并从中生成语法树。
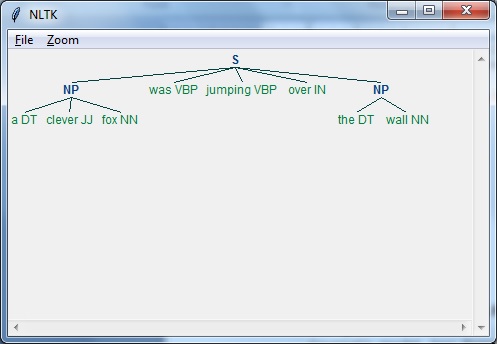
示例
以下是正则表达式语法分析器的示例:
import nltk
sentence = [
("a", "DT"),
("clever", "JJ"),
("fox","NN"),
("was","VBP"),
("jumping","VBP"),
("over","IN"),
("the","DT"),
("wall","NN")
]
grammar = "NP:{<DT>?<JJ>*<NN>}"
Reg_parser = nltk.RegexpParser(grammar)
Reg_parser.parse(sentence)
Output = Reg_parser.parse(sentence)
Output.draw()
输出
依存语法分析
依存语法分析(DP)是一种现代的语法分析机制,其主要概念是每个语言单位(即单词)通过直接链接相互关联。这些直接链接实际上是语言学中的“依存关系”。例如,下图显示了句子“John can hit the ball”的依存语法。
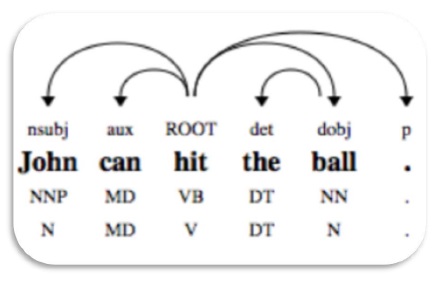
NLTK包
我们有以下两种方法可以使用NLTK进行依存语法分析:
概率投影依存语法分析器
这是我们使用NLTK进行依存语法分析的第一种方法。但是此语法分析器受限于使用有限的训练数据进行训练。
斯坦福语法分析器
这是我们使用NLTK进行依存语法分析的另一种方法。斯坦福语法分析器是最先进的依存语法分析器。NLTK有一个包装器。要使用它,我们需要下载以下两件事:
所需语言的语言模型。例如,英语语言模型。
示例
下载完模型后,我们可以通过NLTK如下使用它:
from nltk.parse.stanford import StanfordDependencyParser
path_jar = 'path_to/stanford-parser-full-2014-08-27/stanford-parser.jar'
path_models_jar = 'path_to/stanford-parser-full-2014-08-27/stanford-parser-3.4.1-models.jar'
dep_parser = StanfordDependencyParser(
path_to_jar = path_jar, path_to_models_jar = path_models_jar
)
result = dep_parser.raw_parse('I shot an elephant in my sleep')
depndency = result.next()
list(dependency.triples())
输出
[ ((u'shot', u'VBD'), u'nsubj', (u'I', u'PRP')), ((u'shot', u'VBD'), u'dobj', (u'elephant', u'NN')), ((u'elephant', u'NN'), u'det', (u'an', u'DT')), ((u'shot', u'VBD'), u'prep', (u'in', u'IN')), ((u'in', u'IN'), u'pobj', (u'sleep', u'NN')), ((u'sleep', u'NN'), u'poss', (u'my', u'PRP$')) ]