
 数据结构
数据结构 网络
网络 关系数据库管理系统 (RDBMS)
关系数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 编程
C 编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHPPython 中的客户流失预测
每个企业都依赖于客户的忠诚度。来自客户的重复业务是企业盈利的基础之一。因此,了解客户离开企业的原因非常重要。客户流失被称为客户流失率。通过观察过去的趋势,我们可以判断哪些因素会影响客户流失率,以及如何预测特定客户是否会离开企业。在本文中,我们将使用机器学习算法来研究客户流失率的过去趋势,然后判断哪些客户可能会流失。
数据准备
作为示例,本文将考虑电信客户流失率。源数据可在 Kaggle 上获取。下载数据的 URL 在下面的程序中提到。我们使用 Pandas 库将 csv 文件加载到 Python 程序中,并查看一些示例行。
示例
import pandas as pd
#Loading the Telco-Customer-Churn.csv dataset
#https://www.kaggle.com/blastchar/telco-customer-churn
datainput = pd.read_csv('E:\Telecom_customers.csv')
print("Given input data :\n",datainput)输出
运行以上代码将得到以下结果:
Given input data : customerID gender SeniorCitizen ... MonthlyCharges TotalCharges Churn 0 7590-VHVEG Female 0 ... 29.85 29.85 No 1 5575-GNVDE Male 0 ... 56.95 1889.5 No 2 3668-QPYBK Male 0 ... 53.85 108.15 Yes 3 7795-CFOCW Male 0 ... 42.30 1840.75 No 4 9237-HQITU Female 0 ... 70.70 151.65 Yes ... ... ... ... ... ... ... ... 7038 6840-RESVB Male 0 ... 84.80 1990.5 No 7039 2234-XADUH Female 0 ... 103.20 7362.9 No 7040 4801-JZAZL Female 0 ... 29.60 346.45 No 7041 8361-LTMKD Male 1 ... 74.40 306.6 Yes 7042 3186-AJIEK Male 0 ... 105.65 6844.5 No [7043 rows x 21 columns]
研究现有模式
接下来,我们研究数据集以查找流失发生的现有模式。我们还删除一些对条件没有影响的数据列。例如,客户 ID 列不会影响客户是否离开,因此我们使用 drop 方法删除此类列。然后,我们绘制一个图表,显示给定数据集中流失的百分比。
示例 2
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import rcParams
#Loading the Telco-Customer-Churn.csv dataset
#https://www.kaggle.com/blastchar/telco-customer-churn
datainput = pd.read_csv('E:\Telecom_customers.csv')
print("Given input data :\n",datainput)
#Dropping columns
datainput.drop(['customerID'], axis=1, inplace=True)
datainput.pop('TotalCharges')
datainput['OnlineBackup'].unique()
data = datainput['Churn'].value_counts(sort = True)
chroma = ["#BDFCC9","#FFDEAD"]
rcParams['figure.figsize'] = 9,9
explode = [0.2,0.2]
plt.pie(data, explode=explode, colors=chroma, autopct='%1.1f%%', shadow=True, startangle=180,)
plt.title('Percentage of Churn in the given Data')
plt.show()输出
运行以上代码将得到以下结果:
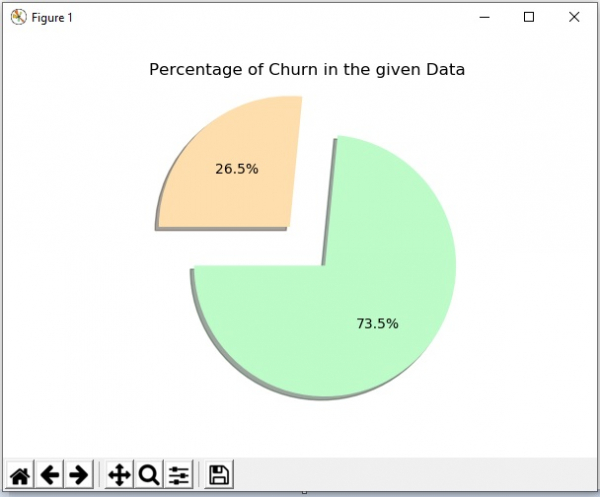
数据预处理
为了使数据能够被机器学习算法使用,我们对所有字段进行标记。我们还将文本值转换为数字标记。例如,性别列中的值将更改为 0 和 1,而不是男性和女性。这有助于在计算和算法中使用这些字段,这些计算和算法将评估这些字段对流失值的影响。我们使用 sklearn 中的 LabelEncoder 方法。
示例 3
import pandas as pd
from sklearn import preprocessing
label_encoder = preprocessing.LabelEncoder()
datainput['gender'] = label_encoder.fit_transform(datainput['gender'])
datainput['Partner'] = label_encoder.fit_transform(datainput['Partner'])
datainput['Dependents'] = label_encoder.fit_transform(datainput['Dependents'])
datainput['PhoneService'] = label_encoder.fit_transform(datainput['PhoneService'])
datainput['MultipleLines'] = label_encoder.fit_transform(datainput['MultipleLines'])
datainput['InternetService'] = label_encoder.fit_transform(datainput['InternetService'])
datainput['OnlineSecurity'] = label_encoder.fit_transform(datainput['OnlineSecurity'])
datainput['OnlineBackup'] = label_encoder.fit_transform(datainput['OnlineBackup'])
datainput['DeviceProtection'] = label_encoder.fit_transform(datainput['DeviceProtection'])
datainput['TechSupport'] = label_encoder.fit_transform(datainput['TechSupport'])
datainput['StreamingTV'] = label_encoder.fit_transform(datainput['StreamingTV'])
datainput['StreamingMovies'] = label_encoder.fit_transform(datainput['StreamingMovies'])
datainput['Contract'] = label_encoder.fit_transform(datainput['Contract'])
datainput['PaperlessBilling'] = label_encoder.fit_transform(datainput['PaperlessBilling'])
datainput['PaymentMethod'] = label_encoder.fit_transform(datainput['PaymentMethod'])
datainput['Churn'] = label_encoder.fit_transform(datainput['Churn'])
print("input data after label encoder :\n",datainput)
#separating features(X) and label(y)
datainput["Churn"] = datainput["Churn"].astype(int)
y = datainput["Churn"].values
X = datainput.drop(labels = ["Churn"],axis = 1)
print("\nseparated X and y :")
print("y -",y)
print("X -",X)输出
运行以上代码将得到以下结果:
input data after label encoder customerID gender SeniorCitizen ... MonthlyCharges TotalCharges Churn 0 7590-VHVEG 0 0 ... 29.85 29.85 0 1 5575-GNVDE 1 0 ... 56.95 1889.5 0 2 3668-QPYBK 1 0 ... 53.85 108.15 1 3 7795-CFOCW 1 0 ... 42.30 1840.75 0 4 9237-HQITU 0 0 ... 70.70 151.65 1 ... ... ... ... ... ... ... ... 7038 6840-RESVB 1 0 ... 84.80 1990.5 0 7039 2234-XADUH 0 0 ... 103.20 7362.9 0 7040 4801-JZAZL 0 0 ... 29.60 346.45 0 7041 8361-LTMKD 1 1 ... 74.40 306.6 1 7042 3186-AJIEK 1 0 ... 105.65 6844.5 0 [7043 rows x 21 columns] separated X and y : y - [0 0 1 ... 0 1 0] X - customerID gender ... MonthlyCharges TotalCharges 0 7590-VHVEG 0 ... 29.85 29.85 1 5575-GNVDE 1 ... 56.95 1889.5 2 3668-QPYBK 1 ... 53.85 108.15 3 7795-CFOCW 1 ... 42.30 1840.75 4 9237-HQITU 0 ... 70.70 151.65 ... ... ... ... ... ... 7038 6840-RESVB 1 ... 84.80 1990.5 7039 2234-XADUH 0 ... 103.20 7362.9 7040 4801-JZAZL 0 ... 29.60 346.45 7041 8361-LTMKD 1 ... 74.40 306.6 7042 3186-AJIEK 1 ... 105.65 6844.5 [7043 rows x 20 columns]
训练和测试数据
现在我们将数据集分成两部分。一个是用于训练,另一个是用于测试。test_size 参数用于决定将有多少百分比的数据集仅用于测试。此练习将帮助我们对正在创建的模型更有信心。然后我们应用逻辑回归算法并找出预测值。
示例
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
from sklearn.linear_model import LogisticRegression
#Loading the Telco-Customer-Churn.csv dataset with pandas
datainput = pd.read_csv('E:\Telecom_customers.csv')
datainput.drop(['customerID'], axis=1, inplace=True)
datainput.pop('TotalCharges')
datainput['OnlineBackup'].unique()
#LabelEncoder()
from sklearn import preprocessing
label_encoder = preprocessing.LabelEncoder()
datainput['gender'] = label_encoder.fit_transform(datainput['gender'])
datainput['Partner'] = label_encoder.fit_transform(datainput['Partner'])
datainput['Dependents'] = label_encoder.fit_transform(datainput['Dependents'])
datainput['PhoneService'] = label_encoder.fit_transform(datainput['PhoneService'])
datainput['MultipleLines'] = label_encoder.fit_transform(datainput['MultipleLines'])
datainput['InternetService'] = label_encoder.fit_transform(datainput['InternetService'])
datainput['OnlineSecurity'] = label_encoder.fit_transform(datainput['OnlineSecurity'])
datainput['OnlineBackup'] = label_encoder.fit_transform(datainput['OnlineBackup'])
datainput['DeviceProtection'] = label_encoder.fit_transform(datainput['DeviceProtection'])
datainput['TechSupport'] = label_encoder.fit_transform(datainput['TechSupport'])
datainput['StreamingTV'] = label_encoder.fit_transform(datainput['StreamingTV'])
datainput['StreamingMovies'] = label_encoder.fit_transform(datainput['StreamingMovies'])
datainput['Contract'] = label_encoder.fit_transform(datainput['Contract'])
datainput['PaperlessBilling'] = label_encoder.fit_transform(datainput['PaperlessBilling'])
datainput['PaymentMethod'] = label_encoder.fit_transform(datainput['PaymentMethod'])
datainput['Churn'] = label_encoder.fit_transform(datainput['Churn'])
#print("input data after label encoder :\n",datainput)
#separating features(X) and label(y)
datainput["Churn"] = datainput["Churn"].astype(int)
Y = datainput["Churn"].values
X = datainput.drop(labels = ["Churn"],axis = 1)
#train_test_split method
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2)
#LogisticRegression
classifier=LogisticRegression()
classifier.fit(X_train,Y_train)
Y_pred=classifier.predict(X_test)
print("\npredicted values :\n",Y_pred)输出
运行以上代码将得到以下结果:
predicted values : [0 0 1 ... 0 1 0]
查找评估参数
一旦以上步骤中的准确度水平达到可接受的水平,我们就通过查找不同的参数来进一步评估模型。我们使用准确率和混淆矩阵作为参数来判断此模型的行为有多准确。较高的准确率值表明该模型更适合。类似地,混淆矩阵显示真阳性、真阴性、假阳性和假阴性的矩阵。与假值相比,真值的百分比越高,表明模型越好。
示例
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
from sklearn.metrics import confusion_matrix
#Loading the Telco-Customer-Churn.csv dataset with pandas
datainput = pd.read_csv('E:\Telecom_customers.csv')
datainput.drop(['customerID'], axis=1, inplace=True)
datainput.pop('TotalCharges')
datainput['OnlineBackup'].unique()
#LabelEncoder()
from sklearn import preprocessing
label_encoder = preprocessing.LabelEncoder()
datainput['gender'] = label_encoder.fit_transform(datainput['gender'])
datainput['Partner'] = label_encoder.fit_transform(datainput['Partner'])
datainput['Dependents'] = label_encoder.fit_transform(datainput['Dependents'])
datainput['PhoneService'] = label_encoder.fit_transform(datainput['PhoneService'])
datainput['MultipleLines'] = label_encoder.fit_transform(datainput['MultipleLines'])
datainput['InternetService'] = label_encoder.fit_transform(datainput['InternetService'])
datainput['OnlineSecurity'] = label_encoder.fit_transform(datainput['OnlineSecurity'])
datainput['OnlineBackup'] = label_encoder.fit_transform(datainput['OnlineBackup'])
datainput['DeviceProtection'] = label_encoder.fit_transform(datainput['DeviceProtection'])
datainput['TechSupport'] = label_encoder.fit_transform(datainput['TechSupport'])
datainput['StreamingTV'] = label_encoder.fit_transform(datainput['StreamingTV'])
datainput['StreamingMovies'] = label_encoder.fit_transform(datainput['StreamingMovies'])
datainput['Contract'] = label_encoder.fit_transform(datainput['Contract'])
datainput['PaperlessBilling'] = label_encoder.fit_transform(datainput['PaperlessBilling'])
datainput['PaymentMethod'] = label_encoder.fit_transform(datainput['PaymentMethod'])
datainput['Churn'] = label_encoder.fit_transform(datainput['Churn'])
#print("input data after label encoder :\n",datainput)
#separating features(X) and label(y)
datainput["Churn"] = datainput["Churn"].astype(int)
Y = datainput["Churn"].values
X = datainput.drop(labels = ["Churn"],axis = 1)
#train_test_split method
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2)
#LogisticRegression
classifier=LogisticRegression()
classifier.fit(X_train,Y_train)
Y_pred=classifier.predict(X_test)
#Accuracy
LR = metrics.accuracy_score(Y_test, Y_pred) * 100
print("\nThe accuracy score using the LR is -> ",LR)
#confusion matrix
cm=confusion_matrix(Y_test,Y_pred)
print("\nconfusion matrix : \n",cm)输出
运行以上代码将得到以下结果:
The accuracy score using the LR is -> 80.8374733853797 confusion matrix : [[928 109] [161 211]]
变量权重
接下来,我们判断每个字段或变量如何影响流失值。这将帮助我们确定对流失影响较大的特定变量,并尝试处理这些变量以防止客户流失。为此,我们将分类器中的系数设置为零,并获得每个变量的权重。
示例
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
from sklearn.linear_model import LogisticRegression
#Loading the dataset with pandas
datainput = pd.read_csv('E:\Telecom_customers.csv')
datainput.drop(['customerID'], axis=1, inplace=True)
datainput.pop('TotalCharges')
datainput['OnlineBackup'].unique()
#LabelEncoder()
from sklearn import preprocessing
label_encoder = preprocessing.LabelEncoder()
datainput['gender'] = label_encoder.fit_transform(datainput['gender'])
datainput['Partner'] = label_encoder.fit_transform(datainput['Partner'])
datainput['Dependents'] = label_encoder.fit_transform(datainput['Dependents'])
datainput['PhoneService'] = label_encoder.fit_transform(datainput['PhoneService'])
datainput['MultipleLines'] = label_encoder.fit_transform(datainput['MultipleLines'])
datainput['InternetService'] = label_encoder.fit_transform(datainput['InternetService'])
datainput['OnlineSecurity'] = label_encoder.fit_transform(datainput['OnlineSecurity'])
datainput['OnlineBackup'] = label_encoder.fit_transform(datainput['OnlineBackup'])
datainput['DeviceProtection'] = label_encoder.fit_transform(datainput['DeviceProtection'])
datainput['TechSupport'] = label_encoder.fit_transform(datainput['TechSupport'])
datainput['StreamingTV'] = label_encoder.fit_transform(datainput['StreamingTV'])
datainput['StreamingMovies'] = label_encoder.fit_transform(datainput['StreamingMovies'])
datainput['Contract'] = label_encoder.fit_transform(datainput['Contract'])
datainput['PaperlessBilling'] = label_encoder.fit_transform(datainput['PaperlessBilling'])
datainput['PaymentMethod'] = label_encoder.fit_transform(datainput['PaymentMethod'])
datainput['Churn'] = label_encoder.fit_transform(datainput['Churn'])
#print("input data after label encoder :\n",datainput)
#separating features(X) and label(y)
datainput["Churn"] = datainput["Churn"].astype(int)
Y = datainput["Churn"].values
X = datainput.drop(labels = ["Churn"],axis = 1)
#
#train_test_split method
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2)
#
#LogisticRegression
classifier=LogisticRegression()
classifier.fit(X_train,Y_train)
Y_pred=classifier.predict(X_test)
#weights of all the variables
wt = pd.Series(classifier.coef_[0], index=X.columns.values)
print("\nweight of all the variables :")
print(wt.sort_values(ascending=False))输出
运行以上代码将得到以下结果:
weight of all the variables : PaperlessBilling 0.389379 SeniorCitizen 0.246504 InternetService 0.209283 Partner 0.067855 StreamingMovies 0.054309 MultipleLines 0.042330 PaymentMethod 0.039134 MonthlyCharges 0.027180 StreamingTV -0.008606 gender -0.029547 tenure -0.034668 DeviceProtection -0.052690 OnlineBackup -0.143625 Dependents -0.209667 OnlineSecurity -0.245952 TechSupport -0.254740 Contract -0.729557 PhoneService -0.950555 dtype: float64

浏览量:512
