量角器 - 快速指南
量角器 - 简介
本章将为您介绍量角器,您将了解此测试框架的起源以及为什么要选择它,以及此工具的工作原理和局限性。
什么是量角器?
量角器是一个用于 Angular 和 AngularJS 应用程序的开源端到端测试框架。它由 Google 基于 WebDriver 构建。它也作为现有的 AngularJS E2E 测试框架“Angular Scenario Runner”的替代品。
它还可以作为解决方案集成器,结合 NodeJS、Selenium、Jasmine、WebDriver、Cucumber、Mocha 等强大的技术。除了测试 AngularJS 应用程序外,它还可以为普通 Web 应用程序编写自动化的回归测试。它允许我们像真实用户一样测试我们的应用程序,因为它使用实际浏览器运行测试。
下图将简要概述量角器 -
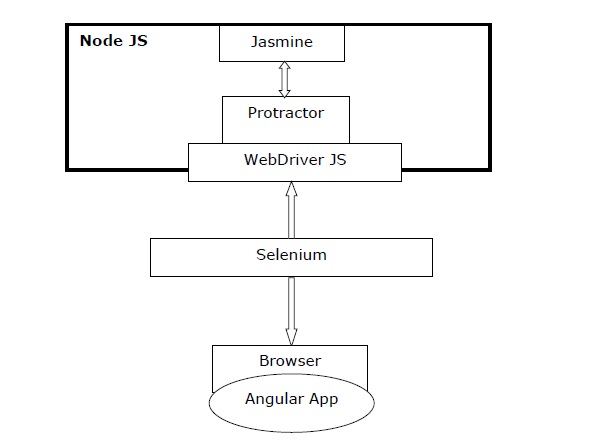
观察上图,我们有 -
量角器 - 如前所述,它是 WebDriver JS 的一个包装器,专门为 Angular 应用程序设计。
Jasmine - 它基本上是一个用于测试 JavaScript 代码的行为驱动开发框架。我们可以使用 Jasmine 轻松编写测试。
WebDriver JS - 它是 Selenium 2.0/WebDriver 的 Node JS 绑定实现。
Selenium - 它只是自动化浏览器。
起源
如前所述,量角器是现有的 AngularJS E2E 测试框架“Angular Scenario Runner”的替代品。基本上,量角器的起源始于 Scenario Runner 的结束。这里出现了一个问题,为什么我们需要构建量角器?要了解这一点,我们首先需要检查其前身 - Scenario Runner。
量角器的起源
Julie Ralph 是量角器开发的主要贡献者,她在 Google 内部其他项目中使用 Angular Scenario Runner 的过程中获得了以下经验。这进一步成为构建量角器的动力,特别是为了填补空白 -
“我们尝试使用 Scenario Runner,发现它真的无法做到我们需要测试的事情。我们需要测试诸如登录之类的事情。您的登录页面不是 Angular 页面,Scenario Runner 无法处理它。它也无法处理诸如弹出窗口和多个窗口、浏览浏览器历史记录等内容。”
量角器最大的优势在于 Selenium 项目的成熟度,它封装了 Selenium 的方法,以便于 Angular 项目使用。量角器的设计方式使其能够测试应用程序的所有层,例如 Web UI、后端服务、持久层等等。
为什么选择量角器?
众所周知,几乎所有应用程序都使用 JavaScript 进行开发。由于应用程序数量的增加,当 JavaScript 的规模增加并变得复杂时,测试人员的任务变得困难。大多数情况下,使用 JUnit 或 Selenium WebDriver 在 AngularJS 应用程序中捕获 Web 元素变得非常困难,使用扩展的 HTML 语法来表达 Web 应用程序组件。
这里的问题是为什么 Selenium Web Driver 无法找到 AngularJS Web 元素?原因是 AngularJS 应用程序具有一些扩展的 HTML 属性,例如 ng-repeater、ng-controller 和 ng-model 等,这些属性未包含在 Selenium 定位器中。
在这里,量角器的重要性就体现出来了,因为量角器在 Selenium 之上可以处理和控制 AngularJS Web 应用程序中的这些扩展 HTML 元素。这就是为什么我们可以说大多数框架专注于对 AngularJS 应用程序进行单元测试,而量角器用于测试应用程序的实际功能。
量角器的工作原理
量角器这个测试框架与 Selenium 协同工作,为模拟用户与在浏览器或移动设备上运行的 AngularJS 应用程序交互提供自动化测试基础设施。
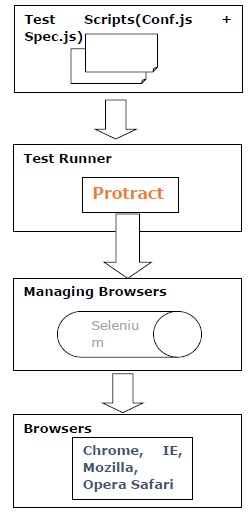
可以通过以下步骤了解量角器的工作原理 -
步骤 1 - 在第一步中,我们需要编写测试。这可以通过 Jasmine 或 Mocha 或 Cucumber 的帮助来完成。
步骤 2 - 现在,我们需要运行测试,这可以通过量角器的帮助来完成。它也称为测试运行器。
步骤 3 - 在此步骤中,Selenium 服务器将帮助管理浏览器。
步骤 4 - 最后,使用 Selenium WebDriver 调用浏览器 API。
优点
这个开源端到端测试框架提供了以下优势 -
作为开源工具,量角器非常易于安装和设置。
与 Jasmine 框架配合良好以创建测试。
支持测试驱动开发 (TDD)。
包含自动等待,这意味着我们不需要在测试中显式添加等待和休眠。
提供 Selenium WebDriver 的所有优势。
支持通过多个浏览器进行并行测试。
提供自动同步的优势。
测试速度快。
局限性
这个开源端到端测试框架具有以下局限性 -
由于它是 WebDriver JS 的包装器,因此不会发现浏览器自动化中的任何垂直领域。
用户必须了解 JavaScript,因为它仅适用于 JavaScript。
仅提供前端测试,因为它是一个 UI 驱动的测试工具。
量角器 - JavaScript 测试的概念
由于了解 JavaScript 对于使用量角器至关重要,因此在本章中,让我们详细了解 JavaScript 测试的概念。
JavaScript 测试和自动化
JavaScript 是最流行的动态类型解释型脚本语言,但最具挑战性的任务是测试代码。这是因为,与 JAVA 和 C++ 等其他编译语言不同,JavaScript 中没有编译步骤可以帮助测试人员找出错误。此外,基于浏览器的测试非常耗时;因此,需要支持 JavaScript 自动化测试的工具。
自动化测试的概念
编写测试始终是一个好习惯,因为它使代码更好;手动测试的问题在于它有点耗时且容易出错。对于程序员来说,手动测试的过程也相当乏味,因为他们需要重复该过程,编写测试规范、更改代码并刷新浏览器多次。此外,手动测试还会减慢开发过程。
由于上述原因,拥有可以自动化这些测试并帮助程序员摆脱这些重复和乏味步骤的工具始终是有用的。开发人员应该如何使测试过程自动化?
基本上,开发人员可以在 CLI(命令行解释器)或开发 IDE(集成开发环境)中实现工具集。然后,即使没有开发人员的输入,这些测试也会在单独的过程中持续运行。JavaScript 的自动化测试也不是什么新鲜事物,并且已经开发了许多工具,例如 Karma、Protractor、CasperJS 等。
JavaScript 测试类型
可以针对不同目的进行不同的测试。例如,一些测试是为了检查程序中函数的行为,而另一些测试是为了测试模块或功能的流程。因此,我们有以下两种类型的测试 -
单元测试
测试是在程序的最小可测试部分(称为单元)上进行的。单元基本上是在隔离状态下进行测试的,而无需该单元依赖于其他部分。在 JavaScript 的情况下,具有特定行为的单个方法或函数可以是代码单元,并且必须以隔离的方式测试这些代码单元。
单元测试的优点之一是可以按任何顺序测试单元,因为单元彼此独立。单元测试的另一个真正重要的优点是,它可以随时运行测试,如下所示 -
- 从开发过程的开始。
- 完成任何模块/功能的开发后。
- 修改任何模块/功能后。
- 在现有应用程序中添加任何新功能后。
对于 JavaScript 应用程序的自动化单元测试,我们可以从许多测试工具和框架中进行选择,例如 Mocha、Jasmine 和 QUnit。
端到端测试
它可以定义为用于测试应用程序从开始到结束(从一端到另一端)的流程是否根据设计正常工作的测试方法。
端到端测试也称为功能/流程测试。与单元测试不同,端到端测试测试各个组件如何作为应用程序协同工作。这是单元测试和端到端测试之间的主要区别。
例如,假设我们有一个注册模块,用户需要提供一些有效信息才能完成注册,那么该特定模块的 E2E 测试将遵循以下步骤来完成测试 -
- 首先,它将加载/编译表单或模块。
- 现在,它将获取表单元素的 DOM(文档对象模型)。
- 接下来,触发提交按钮的点击事件以检查它是否正在工作。
- 现在,出于验证目的,从输入字段中收集值。
- 接下来,应验证输入字段。
- 出于测试目的,调用伪 API 来存储数据。
每个步骤都会给出自己的结果,这些结果将与预期结果集进行比较。
现在,出现的问题是,虽然这种端到端或功能测试也可以手动执行,但为什么我们需要自动化测试呢?主要原因是自动化将使这个测试过程变得更容易。为此,一些可轻松与任何应用程序集成的可用工具包括Selenium、PhantomJS和Protractor。
测试工具与框架
我们有各种用于Angular测试的测试工具和框架。以下是其中一些众所周知的工具和框架:
Karma
Karma 由 Vojta Jina 创建,是一个测试运行器。最初这个项目被称为 Testacular。它不是一个测试框架,这意味着它使我们能够轻松地在真实浏览器上自动运行 JavaScript 单元测试。Karma 是为 AngularJS 构建的,因为在 Karma 出现之前,还没有针对基于 Web 的 JavaScript 开发人员的自动化测试工具。另一方面,通过 Karma 提供的自动化,开发人员可以运行一个简单的单一命令,并确定整个测试套件是否通过或失败。
使用 Karma 的优点
以下是一些与手动流程相比使用 Karma 的优点:
- 自动在多个浏览器以及设备上进行测试。
- 监控文件错误并修复它们。
- 提供在线支持和文档。
- 简化与持续集成服务器的集成。
使用 Karma 的缺点
以下是使用 Karma 的一些缺点:
使用 Karma 的主要缺点是它需要一个额外的工具来配置和维护。
如果你正在将 Karma 测试运行器与 Jasmine 一起使用,那么在处理一个元素具有多个 ID 的情况下,关于如何设置 CSS 的信息可用文档较少。
Jasmine
Jasmine 是一个用于测试 JavaScript 代码的行为驱动开发框架,由 Pivotal Labs 开发。在 Jasmine 框架积极开发之前,Pivotal Labs 还开发了一个类似的单元测试框架 JsUnit,它具有内置的测试运行器。可以通过包含 SpecRunner.html 文件或将其用作命令行测试运行器来通过 Jasmine 测试运行浏览器测试。它也可以与或不与 Karma 一起使用。
使用 Jasmine 的优点
以下是使用 Jasmine 的一些优点:
一个独立于浏览器、平台和语言的框架。
支持测试驱动开发 (TDD) 以及行为驱动开发。
与 Karma 默认集成。
易于理解的语法。
提供测试间谍、模拟和直通功能,作为辅助测试的附加功能。
使用 Jasmine 的缺点
以下是使用 Jasmine 的一个缺点:
测试必须由用户在更改时重新运行,因为 Jasmine 在运行测试时没有文件监视功能。
Mocha
Mocha 是为 Node.js 应用程序编写的,它是一个测试框架,但也支持浏览器测试。它与 Jasmine 非常相似,但它们之间的主要区别在于 Mocha 需要一些插件和库,因为它不能作为测试框架独立运行。另一方面,Jasmine 是独立的。但是,Mocha 比 Jasmine 更灵活。
使用 Mocha 的优点
以下是使用 Mocha 的一些优点:
- Mocha 非常易于安装和配置。
- 用户友好且简单的文档。
- 包含多个节点项目的插件。
使用 Mocha 的缺点
以下是使用 Mocha 的一些缺点:
- 它需要单独的模块进行断言、间谍等操作。
- 它还需要额外的配置才能与 Karma 一起使用。
QUnit
QUnit 最初由 John Resig 于 2008 年作为 jQuery 的一部分开发,是一个强大且易于使用的 JavaScript 单元测试套件。它可用于测试任何通用的 JavaScript 代码。虽然它专注于在浏览器中测试 JavaScript,但它对开发人员来说非常方便使用。
使用 QUnit 的优点
以下是使用 QUnit 的一些优点:
- 易于安装和配置。
- 用户友好且简单的文档。
使用 QUnit 的缺点
以下是使用 QUnit 的一个缺点:
- 它主要为 jQuery 开发,因此不太适合与其他框架一起使用。
Selenium
Selenium 最初由 Jason Huggins 于 2004 年作为 ThoughtWorks 的内部工具开发,是一个开源测试自动化工具。Selenium 将其自身定义为“Selenium 自动化浏览器。仅此而已!”。浏览器的自动化意味着开发人员可以非常轻松地与浏览器交互。
使用 Selenium 的优点
以下是使用 Selenium 的一些优点:
- 包含大量功能集。
- 支持分布式测试。
- 通过 Sauce Labs 等服务提供 SaaS 支持。
- 易于使用,文档简单,资源丰富。
使用 Selenium 的缺点
以下是使用 Selenium 的一些缺点:
- 使用 Selenium 的主要缺点是它必须作为单独的进程运行。
- 配置有点繁琐,因为开发人员需要遵循几个步骤。
量角器 - 入门
在前面的章节中,我们学习了 Protractor 的基础知识。在本章中,让我们学习如何安装和配置它。
先决条件
在计算机上安装 Protractor 之前,我们需要满足以下先决条件:
Node.js
Protractor 是一个 Node.js 模块,因此非常重要的先决条件是我们的计算机上必须安装 Node.js。我们将使用 npm(一个 JavaScript 包管理器)安装 Protractor 包,它与 Node.js 一起提供。
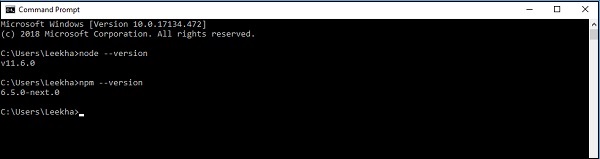
要安装 Node.js,请访问官方链接:https://node.org.cn/en/download/。安装 Node.js 后,您可以通过在命令提示符中写入命令 node --version 和 npm --version 来检查 Node.js 和 npm 的版本,如下所示:
Chrome
Google Chrome 是 Google 构建的 Web 浏览器,它将用于在 Protractor 中运行端到端测试,而无需 Selenium 服务器。您可以通过点击链接下载 Chrome:https://www.google.com/chrome/。
Chrome 的 Selenium WebDriver
此工具随 Protractor npm 模块提供,并允许我们与 Web 应用程序交互。
安装 Protractor
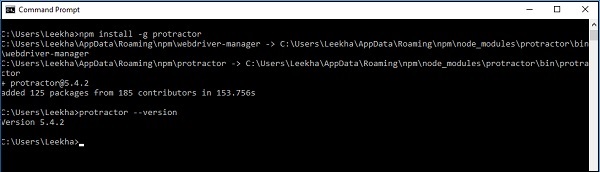
在计算机上安装 Node.js 后,我们可以使用以下命令安装 Protractor:
npm install -g protractor
Protractor 成功安装后,我们可以通过在命令提示符中写入 protractor --version 命令来检查其版本,如下所示:
安装 Chrome 的 WebDriver
安装 Protractor 后,我们需要安装 Chrome 的 Selenium WebDriver。它可以使用以下命令安装:
webdriver-manager update
上述命令将创建一个 Selenium 目录,其中包含项目中使用的必需的 Chrome 驱动程序。
确认安装与配置
我们可以通过稍微更改安装 Protractor 后示例中提供的 conf.js 文件来确认 Protractor 的安装和配置。您可以在根目录 node_modules/Protractor/example 中找到此 conf.js 文件。
为此,首先在同一目录(即 node_modules/Protractor/example)中创建一个名为 testingconfig.js 的新文件。
现在,在 conf.js 文件中,在源文件声明参数下,写入 testingconfig.js。
接下来,保存并关闭所有文件,然后打开命令提示符。运行 conf.js 文件,如以下屏幕截图所示。
如果得到以下输出,则表示 Protractor 的配置和安装成功:
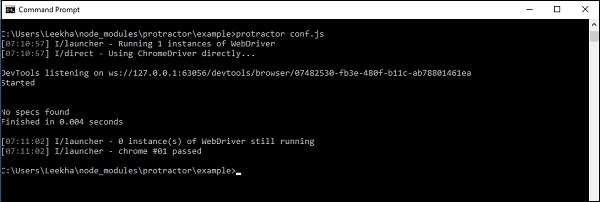
以上输出表明没有规范,因为我们在 conf.js 文件的源文件声明参数中提供了空文件。但从以上输出可以看出,Protractor 和 WebDriver 都成功运行了。
安装与配置中的问题
在安装和配置 Protractor 和 WebDriver 期间,我们可能会遇到以下常见问题:
Selenium 未正确安装
这是安装 WebDriver 时最常见的问题。如果未更新 WebDriver,则会出现此问题。请注意,我们必须更新 WebDriver,否则我们将无法将其引用到 Protractor 安装。
找不到测试
另一个常见问题是,运行 Protractor 后,它显示无法找到测试。为此,我们必须确保相对路径、文件名或扩展名正确。我们还需要非常仔细地编写 conf.js 文件,因为它从配置文件本身开始。
Protractor - Protractor 和 Selenium 服务器
如前所述,Protractor 是一个用于 Angular 和 AngularJS 应用程序的开源端到端测试框架。它是一个 Node.js 程序。另一方面,Selenium 是一个浏览器自动化框架,包括 Selenium 服务器、WebDriver API 和 WebDriver 浏览器驱动程序。
Protractor 与 Selenium
如果我们谈论 Protractor 和 Selenium 的结合,Protractor 可以与 Selenium 服务器一起工作以提供自动化的测试基础设施。该基础设施可以模拟用户与在浏览器或移动设备上运行的 Angular 应用程序的交互。Protractor 和 Selenium 的结合可以分为三个部分,即测试、服务器和浏览器,如下图所示:
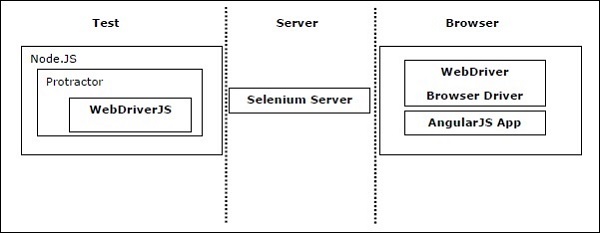
Selenium WebDriver 进程
正如我们在上图中看到的,使用 Selenium WebDriver 进行的测试涉及以下三个过程:
- 测试脚本
- 服务器
- 浏览器
在本节中,让我们讨论这三个过程之间的通信。
测试脚本与服务器之间的通信
前两个过程(测试脚本和服务器)之间的通信取决于 Selenium 服务器的工作方式。换句话说,Selenium 服务器的运行方式将决定测试脚本与服务器之间通信过程的形式。
Selenium 服务器可以在我们的机器上本地运行,作为独立的 Selenium 服务器(selenium-server-standalone.jar),或者可以通过服务(Sauce Labs)远程运行。在独立的 Selenium 服务器的情况下,Node.js 和 Selenium 服务器之间将存在 HTTP 通信。
服务器和浏览器之间的通信
众所周知,服务器负责在解释测试脚本中的命令后将其转发到浏览器。这就是为什么服务器和浏览器也需要一个通信媒介,并且此处通信是借助于**JSON WebDriver Wire 协议**完成的。浏览器扩展了用于解释命令的浏览器驱动程序。
可以通过以下图表了解上述关于 Selenium WebDriver 进程及其通信的概念:
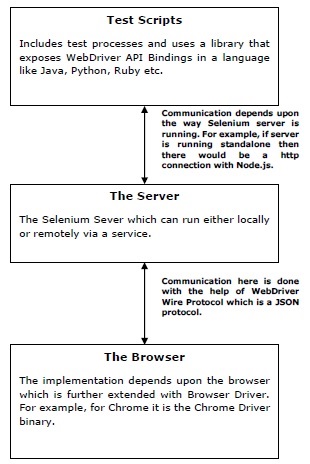
在使用 Protractor 时,第一个进程,即测试脚本使用 Node.js 运行,但在对浏览器执行任何操作之前,它会发送一个额外的命令以确保正在测试的应用程序稳定。
设置 Selenium 服务器
Selenium 服务器充当测试脚本和浏览器驱动程序之间的代理服务器。它基本上将命令从我们的测试脚本转发到 WebDriver,并将 WebDriver 的响应返回到我们的测试脚本。设置 Selenium 服务器有以下几种选项,这些选项包含在测试脚本的**conf.js**文件中:
独立 Selenium 服务器
如果我们想在本地机器上运行服务器,我们需要安装独立的 Selenium 服务器。安装独立 Selenium 服务器的先决条件是 JDK(Java 开发工具包)。我们必须在本地机器上安装 JDK。可以通过从命令行运行以下命令来检查它:
java -version
现在,我们可以选择手动或从测试脚本安装和启动 Selenium 服务器。
手动安装和启动 Selenium 服务器
要手动安装和启动 Selenium 服务器,我们需要使用 Protractor 附带的 WebDriver-Manager 命令行工具。安装和启动 Selenium 服务器的步骤如下:
**步骤 1** - 第一步是安装 Selenium 服务器和 ChromeDriver。可以通过运行以下命令来完成:
webdriver-manager update
**步骤 2** - 接下来,我们需要启动服务器。可以通过运行以下命令来完成:
webdriver-manager start
**步骤 3** - 最后,我们需要在配置文件中将 seleniumAddress 设置为正在运行的服务器的地址。默认地址为**https://:4444/wd/hub**。
从测试脚本启动 Selenium 服务器
要从测试脚本启动 Selenium 服务器,我们需要在配置文件中设置以下选项:
**jar 文件位置** - 我们需要在配置文件中设置独立 Selenium 服务器的 jar 文件位置,方法是设置 seleniumServerJar。
**指定端口** - 我们还需要指定用于启动独立 Selenium 服务器的端口。它可以在配置文件中通过设置 seleniumPort 来指定。默认端口为 4444。
**命令行选项数组** - 我们还需要设置要传递给服务器的命令行选项数组。它可以在配置文件中通过设置 seleniumArgs 来指定。如果需要完整的命令数组列表,则使用**-help**标志启动服务器。
使用远程 Selenium 服务器
运行测试的另一种选择是远程使用 Selenium 服务器。远程使用服务器的先决条件是我们必须拥有托管服务器服务的帐户。在使用 Protractor 时,我们对以下托管服务器的服务有内置支持:
TestObject
要使用 TestObject 作为远程 Selenium 服务器,我们需要设置 testobjectUser(我们的 TestObject 帐户的用户名)和 testobjectKey(我们的 TestObject 帐户的 API 密钥)。
BrowserStack
要使用 BrowserStack 作为远程 Selenium 服务器,我们需要设置 browserstackUser(我们的 BrowserStack 帐户的用户名)和 browserstackKey(我们的 BrowserStack 帐户的 API 密钥)。
Sauce Labs
要使用 Sauce Labs 作为远程 Selenium 服务器,我们需要设置 sauceUser(我们的 Sauce Labs 帐户的用户名)和 SauceKey(我们的 Sauce Labs 帐户的 API 密钥)。
Kobiton
要使用 Kobiton 作为远程 Selenium 服务器,我们需要设置 kobitonUser(我们的 Kobiton 帐户的用户名)和 kobitonKey(我们的 Kobiton 帐户的 API 密钥)。
直接连接到浏览器驱动程序而不使用 Selenium 服务器
运行测试的另一种选择是直接连接到浏览器驱动程序而不使用 Selenium 服务器。Protractor 可以直接测试(无需使用 Selenium 服务器)Chrome 和 Firefox,方法是在配置文件中设置 directConnect: true。
设置浏览器
在配置和设置浏览器之前,我们需要知道 Protractor 支持哪些浏览器。以下是 Protractor 支持的浏览器列表:
- ChromeDriver
- FirefoxDriver
- SafariDriver
- IEDriver
- Appium-iOS/Safari
- Appium-Android/Chrome
- Selendroid
- PhantomJS
要设置和配置浏览器,我们需要转到 Protractor 的配置文件,因为浏览器设置是在配置文件的 capabilities 对象中完成的。
设置 Chrome
要设置 Chrome 浏览器,我们需要如下设置 capabilities 对象:
capabilities: {
'browserName': 'chrome'
}
我们还可以添加 Chrome 特定的选项,这些选项嵌套在 chromeOptions 中,其完整列表可以在https://sites.google.com/a/chromium.org/chromedriver/capabilities中查看。
例如,如果要在右上角添加 FPS 计数器,则可以在配置文件中如下操作:
capabilities: {
'browserName': 'chrome',
'chromeOptions': {
'args': ['show-fps-counter=true']
}
},
设置 Firefox
要设置 Firefox 浏览器,我们需要如下设置 capabilities 对象:
capabilities: {
'browserName': 'firefox'
}
我们还可以添加 Firefox 特定的选项,这些选项嵌套在 moz:firefoxOptions 对象中,其完整列表可以在https://github.com/mozilla/geckodriver#firefox-capabilities中查看。
例如,如果要在安全模式下在 Firefox 上运行测试,则可以在配置文件中如下操作:
capabilities: {
'browserName': 'firefox',
'moz:firefoxOptions': {
'args': ['—safe-mode']
}
},
设置其他浏览器
要设置除 Chrome 或 Firefox 之外的任何其他浏览器,我们需要从https://docs.seleniumhq.org/download/安装单独的二进制文件。
设置 PhantonJS
实际上,由于 PhantomJS 存在崩溃问题,因此不再受支持。建议改用无头 Chrome 或无头 Firefox。它们可以如下设置:
要设置无头 Chrome,我们需要使用 –headless 标志启动 Chrome,如下所示:
capabilities: {
'browserName': 'chrome',
'chromeOptions': {
'args': [“--headless”, “--disable-gpu”, “--window-size=800,600”]
}
},
要设置无头 Firefox,我们需要使用**–headless**标志启动 Firefox,如下所示:
capabilities: {
'browserName': 'firefox',
'moz:firefoxOptions': {
'args': [“--headless”]
}
},
设置多个浏览器进行测试
我们还可以针对多个浏览器进行测试。为此,我们需要使用 multiCapabilities 配置选项,如下所示:
multiCapabilities: [{
'browserName': 'chrome'
},{
'browserName': 'firefox'
}]
哪个框架?
Protractor 支持两个 BDD(行为驱动开发)测试框架,即 Jasmine 和 Mocha。这两个框架都基于 JavaScript 和 Node.js。这些框架提供了编写和管理测试所需的语法、报告和脚手架。
接下来,我们将了解如何安装各种框架:
Jasmine 框架
它是 Protractor 的默认测试框架。安装 Protractor 时,会随附 Jasmine 2.x 版本。我们无需单独安装它。
Mocha 框架
Mocha 是另一个 JavaScript 测试框架,基本上运行在 Node.js 上。要使用 Mocha 作为我们的测试框架,我们需要使用 BDD(行为驱动开发)接口和 Chai 断言以及 Chai As Promised。安装可以通过以下命令完成:
npm install -g mocha npm install chai npm install chai-as-promised
如您所见,在安装 mocha 时使用了 -g 选项,这是因为我们使用 -g 选项全局安装了 Protractor。安装后,我们需要在测试文件中引入并设置 Chai。可以如下操作:
var chai = require('chai');
var chaiAsPromised = require('chai-as-promised');
chai.use(chaiAsPromised);
var expect = chai.expect;
此后,我们可以像这样使用 Chai As Promised:
expect(myElement.getText()).to.eventually.equal('some text');
现在,我们需要将配置文件的 framework 属性设置为 mocha,方法是在配置文件中添加 framework: ‘mocha’。mocha 的“reporter”和“slow”等选项可以如下添加到配置文件中:
mochaOpts: {
reporter: "spec", slow: 3000
}
Cucumber 框架
要使用 Cucumber 作为我们的测试框架,我们需要使用 framework 选项**custom**将其与 Protractor 集成。安装可以通过以下命令完成
npm install -g cucumber npm install --save-dev protractor-cucumber-framework
如您所见,在安装 Cucumber 时使用了 -g 选项,这是因为我们全局安装了 Protractor,即使用 -g 选项。接下来,我们需要将配置文件的 framework 属性设置为**custom**,方法是将 framework: ‘custom’ 和 frameworkPath: ‘Protractor-cucumber-framework’ 添加到名为 cucumberConf.js 的配置文件中。
下面显示的示例代码是一个基本的 cucumberConf.js 文件,可用于使用 Protractor 运行 cucumber 特性文件:
exports.config = {
seleniumAddress: 'https://:4444/wd/hub',
baseUrl: 'https://angularjs.org/',
capabilities: {
browserName:'Firefox'
},
framework: 'custom',
frameworkPath: require.resolve('protractor-cucumber-framework'),
specs: [
'./cucumber/*.feature'
],
// cucumber command line options
cucumberOpts: {
require: ['./cucumber/*.js'],
tags: [],
strict: true,
format: ["pretty"],
'dry-run': false,
compiler: []
},
onPrepare: function () {
browser.manage().window().maximize();
}
};
量角器 - 编写第一个测试
在本章中,让我们了解如何在 Protractor 中编写第一个测试。
Protractor 需要哪些文件
Protractor 需要以下两个文件才能运行:
规范或测试文件
这是运行 Protractor 的重要文件之一。在这个文件中,我们将编写我们的实际测试代码。测试代码是使用测试框架的语法编写的。
例如,如果我们使用**Jasmine**框架,则测试代码将使用**Jasmine**的语法编写。此文件将包含测试的所有功能流程和断言。
简单来说,我们可以说此文件包含与应用程序交互的逻辑和定位器。
示例
以下是简单的脚本 TestSpecification.js,其中包含导航到 URL 并检查页面标题的测试用例:
//TestSpecification.js
describe('Protractor Demo', function() {
it('to check the page title', function() {
browser.ignoreSynchronization = true;
browser.get('https://tutorialspoint.com/tutorialslibrary.htm');
browser.driver.getTitle().then(function(pageTitle) {
expect(pageTitle).toEqual('Free Online Tutorials and Courses');
});
});
});
代码说明
上述规范文件代码的解释如下:
浏览器
它是 Protractor 创建的全局变量,用于处理所有浏览器级别的命令。它基本上是 WebDriver 实例的一个包装器。browser.get() 是一个简单的 Selenium 方法,它会告诉 Protractor 加载特定的页面。
describe 和 it - 都是 Jasmine 测试框架的语法。’Describe’ 用于包含测试用例的端到端流程,而 ‘it’ 包含一些测试场景。我们可以在测试用例程序中有多个 ‘it’ 块。
Expect - 它是一个断言,我们在这里将网页标题与一些预定义数据进行比较。
ignoreSynchronization - 它是浏览器的标签,当我们尝试测试非 Angular 网站时使用。Protractor 期望仅与 Angular 网站一起工作,但如果我们想与非 Angular 网站一起工作,则必须将此标签设置为 “true”。
配置文件
顾名思义,此文件提供所有 Protractor 配置选项的说明。它基本上告诉 Protractor 以下内容:
- 在哪里查找测试或规范文件
- 选择哪个浏览器
- 使用哪个测试框架
- 在哪里与 Selenium 服务器通信
示例
以下是包含测试的简单脚本 config.js
// config.js
exports.config = {
directConnect: true,
// Capabilities to be passed to the webdriver instance.
capabilities: {
'browserName': 'chrome'
},
// Framework to use. Jasmine is recommended.
framework: 'jasmine',
// Spec patterns are relative to the current working directory when
// protractor is called.
specs: ['TestSpecification.js'],
代码说明
上述包含三个基本参数的配置文件代码可以解释如下:
Capabilities 参数
此参数用于指定浏览器的名称。它可以在 conf.js 文件的以下代码块中看到:
exports.config = {
directConnect: true,
// Capabilities to be passed to the webdriver instance.
capabilities: {
'browserName': 'chrome'
},
如上所示,这里给出的浏览器名称是 'chrome',它是 Protractor 的默认浏览器。我们也可以更改浏览器的名称。
Framework 参数
此参数用于指定测试框架的名称。它可以在 config.js 文件的以下代码块中看到:
exports.config = {
directConnect: true,
// Framework to use. Jasmine is recommended.
framework: 'jasmine',
这里我们使用的是 'jasmine' 测试框架。
源文件声明参数
此参数用于指定源文件声明的名称。它可以在 conf.js 文件的以下代码块中看到:
exports.config = {
directConnect: true,
// Spec patterns are relative to the current working
directory when protractor is called.
specs: ['TsetSpecification.js'],
如上所示,这里给出的源文件声明名称是 ‘TestSpecification.js’。这是因为,对于此示例,我们创建的规范文件名为 TestSpecification.js。
执行代码
由于我们已经对运行 Protractor 所需的文件及其编码有了基本的了解,让我们尝试运行该示例。我们可以按照以下步骤执行此示例:
步骤 1 - 首先,打开命令提示符。
步骤 2 - 接下来,我们需要转到保存我们文件的目录,即 config.js 和 TestSpecification.js。
步骤 3 - 现在,通过运行命令 Protrcator config.js 执行 config.js 文件。
下面显示的屏幕截图将解释执行示例的上述步骤:
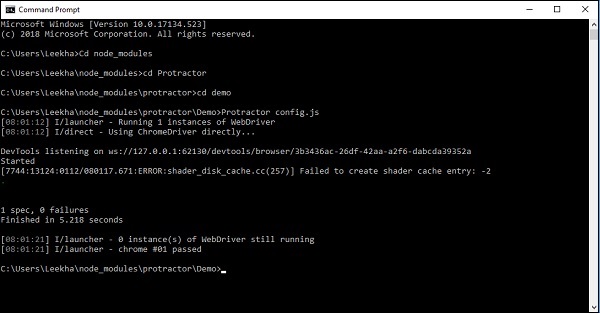
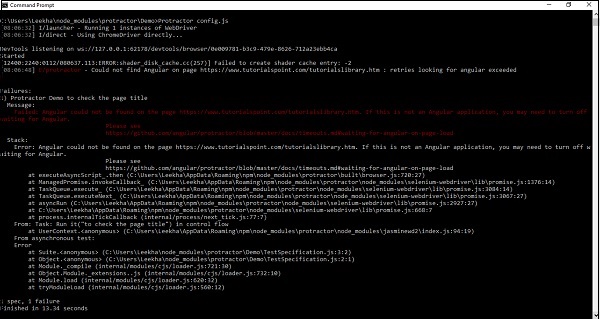
从屏幕截图中可以看出,测试已通过。
现在,假设如果我们正在测试非 Angular 网站并且没有将 ignoreSynchronization 标签设置为 true,那么在执行代码后,我们将收到错误“Angular could not be found on the page”。
它可以在以下屏幕截图中看到:
报告生成
到目前为止,我们已经讨论了运行测试用例所需的文件及其编码。Protractor 也能够为测试用例生成报告。为此,它支持 Jasmine。JunitXMLReporter 可用于自动生成测试执行报告。
但在那之前,我们需要使用以下命令安装 Jasmine 报告程序:
npm install -g jasmine-reporters
如您所见,安装 Jasmine Reporters 时使用了 -g 选项,这是因为我们已全局安装了 Protractor,使用 -g 选项。
成功安装 jasmine-reporters 后,我们需要将以下代码添加到我们之前使用的 config.js 文件中:
onPrepare: function(){ //configure junit xml report
var jasmineReporters = require('jasmine-reporters');
jasmine.getEnv().addReporter(new jasmineReporters.JUnitXmlReporter({
consolidateAll: true,
filePrefix: 'guitest-xmloutput',
savePath: 'test/reports'
}));
现在,我们的新 config.js 文件如下所示:
// An example configuration file.
exports.config = {
directConnect: true,
// Capabilities to be passed to the webdriver instance.
capabilities: {
'browserName': 'chrome'
},
// Framework to use. Jasmine is recommended.
framework: 'jasmine',
// Spec patterns are relative to the current working directory when
// protractor is called.
specs: ['TestSpecification.js'],
//framework: "jasmine2", //must set it if you use JUnitXmlReporter
onPrepare: function(){ //configure junit xml report
var jasmineReporters = require('jasmine-reporters');
jasmine.getEnv().addReporter(new jasmineReporters.JUnitXmlReporter({
consolidateAll: true,
filePrefix: 'guitest-xmloutput',
savePath: 'reports'
}));
},
};
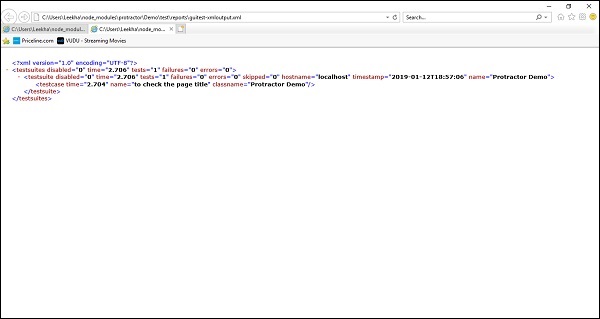
以与之前相同的方式运行上述配置文件后,它将在根目录下的 reports 文件夹中生成一个包含报告的 XML 文件。如果测试成功,则报告将如下所示:
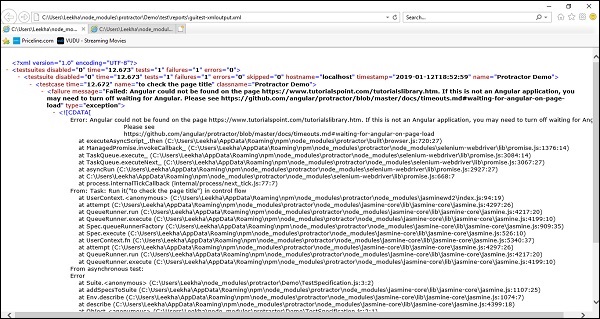
但是,如果测试失败,则报告将如下所示:
Protractor - 核心 API
本章让您了解各种核心 API,这些 API 是 Protractor 运行的关键。
Protractor API 的重要性
Protractor 为我们提供了广泛的 API,这些 API 对于执行以下操作以获取网站的当前状态非常重要:
- 获取我们将要测试的网页的 DOM 元素。
- 与 DOM 元素交互。
- 为它们分配操作。
- 与它们共享信息。
为了执行上述任务,了解 Protractor API 非常重要。
各种 Protractor API
众所周知,Protractor 是 Selenium-WebDriver 的一个包装器,Selenium-WebDriver 是 Node.js 的 WebDriver 绑定。Protractor 具有以下 API:
浏览器
它是 WebDriver 实例的一个包装器,用于处理浏览器级别的命令,例如导航、页面范围的信息等。例如,browser.get 方法加载页面。
元素
它用于搜索和交互我们正在测试的页面上的 DOM 元素。为此,它需要一个参数来定位元素。
定位器 (by)
它是一组元素定位器策略。例如,可以通过 CSS 选择器、ID 或任何其他它们与 ng-model 绑定的属性来查找元素。
接下来,我们将详细讨论这些 API 及其功能。
浏览器 API
如上所述,它是 WebDriver 实例的一个包装器,用于处理浏览器级别的命令。它执行各种功能,如下所示:
函数及其描述
ProtractorBrowser API 的函数如下:
browser.angularAppRoot
此 Browser API 函数设置我们将要查找 Angular 的元素的 CSS 选择器。通常,此函数位于 'body' 中,但如果我们的 ng-app 位于页面的子部分,则它也可能是一个子元素。
browser.waitForAngularEnabled
此 Browser API 函数可以设置为 true 或 false。顾名思义,如果此函数设置为 false,则 Protractor 不会等待 Angular $http 和 $timeout 任务完成,然后再与浏览器交互。我们也可以在不更改当前状态的情况下通过调用 waitForAngularEnabled() 而不传递值来读取当前状态。
browser.getProcessedConfig
借助此 browser API 函数,我们可以获取当前正在运行的已处理配置对象,包括规范和功能。
browser.forkNewDriverInstance
顾名思义,此函数将派生另一个浏览器实例,用于交互式测试。它可以在启用和禁用控制流的情况下运行。以下分别给出两种情况的示例:
示例 1
运行 browser.forkNewDriverInstance() 且控制流已启用:
var fork = browser.forkNewDriverInstance(); fork.get(‘page1’);
示例 2
运行 browser.forkNewDriverInstance() 且控制流已禁用:
var fork = await browser.forkNewDriverInstance().ready; await forked.get(‘page1’);
browser.restart
顾名思义,它将通过关闭浏览器实例并创建新实例来重新启动浏览器。它也可以在启用和禁用控制流的情况下运行。以下分别给出两种情况的示例:
示例 1 - 运行 browser.restart() 且控制流已启用:
browser.get(‘page1’); browser.restart(); browser.get(‘page2’);
示例 2 - 运行 browser.forkNewDriverInstance() 且控制流已禁用:
await browser.get(‘page1’); await browser.restart(); await browser.get(‘page2’);
browser.restartSync
它类似于 browser.restart() 函数。唯一的区别在于它直接返回新的浏览器实例,而不是返回一个解析为新浏览器实例的 Promise。它只能在启用控制流时运行。
示例 - 运行 browser.restartSync() 且控制流已启用:
browser.get(‘page1’); browser.restartSync(); browser.get(‘page2’);
browser.useAllAngular2AppRoots
顾名思义,它仅与 Angular2 兼容。在查找元素或等待稳定性时,它将搜索页面上所有可用的 Angular 应用程序。
browser.waitForAngular
此 browser API 函数指示 WebDriver 等待 Angular 完成渲染并且没有未完成的 $http 或 $timeout 调用,然后再继续。
browser.findElement
顾名思义,此 browser API 函数会在搜索元素之前等待 Angular 完成渲染。
browser.isElementPresent
顾名思义,此 browser API 函数将测试元素是否存在于页面上。
browser.addMockModule
它将在每次调用 Protractor.get 方法时添加一个模块以在 Angular 之前加载。
示例
browser.addMockModule('modName', function() {
angular.module('modName', []).value('foo', 'bar');
});
browser.clearMockModules
与 browser.addMockModule 不同,它将清除已注册的模拟模块列表。
browser.removeMockModule
顾名思义,它将删除注册的模拟模块。例如:browser.removeMockModule('modName');
browser.getRegisteredMockModules
与 browser.clearMockModule 相反,它将获取已注册的模拟模块列表。
browser.get
我们可以使用 browser.get() 将浏览器导航到特定网络地址,并在 Angular 加载之前为该页面加载模拟模块。
示例
browser.get(url);
browser.get('https://:3000');
// This will navigate to the localhost:3000 and will load mock module if needed
browser.refresh
顾名思义,这将重新加载当前页面并在 Angular 之前加载模拟模块。
browser.navigate
顾名思义,它用于将导航方法混合到导航对象中,以便像以前一样调用它们。例如:driver.navigate().refresh()。
browser.setLocation
它用于使用页面内导航浏览到另一个页面。
示例
browser.get('url/ABC');
browser.setLocation('DEF');
expect(browser.getCurrentUrl())
.toBe('url/DEF');
它将从 ABC 页面导航到 DEF 页面。
browser.debugger
顾名思义,这必须与 protractor debug 一起使用。此函数基本上向控制流添加一项任务,以暂停测试并将辅助函数注入浏览器,以便可以在浏览器控制台中进行调试。
browser.pause
它用于调试 WebDriver 测试。我们可以在测试中使用 browser.pause() 以从控制流中的该点进入 protractor 调试器。
示例
element(by.id('foo')).click();
browser.pause();
// Execution will stop before the next click action.
element(by.id('bar')).click();
browser.controlFlowEnabled
它用于确定控制流是否已启用。
Protractor - 核心 API(续…)
在本章中,让我们学习更多 Protractor 的核心 API。
元素 API
Element 是 Protractor 公开的全局函数之一。此函数接受一个定位器并返回以下内容:
- ElementFinder,它根据定位器查找单个元素。
- ElementArrayFinder,它根据定位器查找元素数组。
以上两者都支持如下所述的链式方法。
ElementArrayFinder 的链式函数及其描述
以下是 ElementArrayFinder 的函数 -
element.all(locator).clone
顾名思义,此函数将创建元素数组(即 ElementArrayFinder)的浅拷贝。
element.all(locator).all(locator)
此函数基本上返回一个新的 ElementArrayFinder,它可能为空或包含子元素。它可以用于如下选择多个元素作为数组
示例
element.all(locator).all(locator) elementArr.all(by.css(‘.childselector’)); // it will return another ElementFindArray as child element based on child locator.
element.all(locator).filter(filterFn)
顾名思义,在将过滤器函数应用于 ElementArrayFinder 中的每个元素后,它将返回一个新的 ElementArrayFinder,其中包含通过过滤器函数的所有元素。它基本上有两个参数,第一个是 ElementFinder,第二个是索引。它也可以在页面对象中使用。
示例
查看
<ul class = "items"> <li class = "one">First</li> <li class = "two">Second</li> <li class = "three">Third</li> </ul>
代码
element.all(by.css('.items li')).filter(function(elem, index) {
return elem.getText().then(function(text) {
return text === 'Third';
});
}).first().click();
element.all(locator).get(index)
借助它,我们可以通过索引获取 ElementArrayFinder 中的元素。请注意,索引从 0 开始,负索引会被包装。
示例
查看
<ul class = "items"> <li>First</li> <li>Second</li> <li>Third</li> </ul>
代码
let list = element.all(by.css('.items li'));
expect(list.get(0).getText()).toBe('First');
expect(list.get(1).getText()).toBe('Second');
element.all(locator).first()
顾名思义,这将获取 ElementArrayFinder 的第一个元素。它不会检索底层元素。
示例
查看
<ul class = "items"> <li>First</li> <li>Second</li> <li>Third</li> </ul>
代码
let first = element.all(by.css('.items li')).first();
expect(first.getText()).toBe('First');
element.all(locator).last()
顾名思义,这将获取 ElementArrayFinder 的最后一个元素。它不会检索底层元素。
示例
查看
<ul class = "items"> <li>First</li> <li>Second</li> <li>Third</li> </ul>
代码
let first = element.all(by.css('.items li')).last();
expect(last.getText()).toBe('Third');
element.all(locator).all(selector)
当调用 $$ 时可能需要链接时,它用于查找父级内的元素数组。
示例
查看
<div class = "parent">
<ul>
<li class = "one">First</li>
<li class = "two">Second</li>
<li class = "three">Third</li>
</ul>
</div>
代码
let items = element(by.css('.parent')).$$('li');
element.all(locator).count()
顾名思义,这将计算 ElementArrayFinder 表示的元素数量。它不会检索底层元素。
示例
查看
<ul class = "items"> <li>First</li> <li>Second</li> <li>Third</li> </ul>
代码
let list = element.all(by.css('.items li'));
expect(list.count()).toBe(3);
element.all(locator).isPresent()
它将使用查找器匹配元素。它可以返回 true 或 false。如果存在任何与查找器匹配的元素,则为 true,否则为 false。
示例
expect($('.item').isPresent()).toBeTruthy();
element.all(locator).locator
顾名思义,它将返回最相关的定位器。
示例
$('#ID1').locator();
// returns by.css('#ID1')
$('#ID1').$('#ID2').locator();
// returns by.css('#ID2')
$$('#ID1').filter(filterFn).get(0).click().locator();
// returns by.css('#ID1')
element.all(locator).then(thenFunction)
它将检索 ElementArrayFinder 表示的元素。
示例
查看
<ul class = "items"> <li>First</li> <li>Second</li> <li>Third</li> </ul>
代码
element.all(by.css('.items li')).then(function(arr) {
expect(arr.length).toEqual(3);
});
element.all(locator).each(eachFunction)
顾名思义,它将对 ElementArrayFinder 表示的每个 ElementFinder 调用输入函数。
示例
查看
<ul class = "items"> <li>First</li> <li>Second</li> <li>Third</li> </ul>
代码
element.all(by.css('.items li')).each(function(element, index) {
// It will print First 0, Second 1 and Third 2.
element.getText().then(function (text) {
console.log(index, text);
});
});
element.all(locator).map(mapFunction)
顾名思义,它将在 ElementArrayFinder 中的每个元素上应用映射函数。它有两个参数。第一个是 ElementFinder,第二个是索引。
示例
查看
<ul class = "items"> <li>First</li> <li>Second</li> <li>Third</li> </ul>
代码
let items = element.all(by.css('.items li')).map(function(elm, index) {
return {
index: index,
text: elm.getText(),
class: elm.getAttribute('class')
};
});
expect(items).toEqual([
{index: 0, text: 'First', class: 'one'},
{index: 1, text: 'Second', class: 'two'},
{index: 2, text: 'Third', class: 'three'}
]);
element.all(locator).reduce(reduceFn)
顾名思义,它将对累加器和使用定位器找到的每个元素应用归约函数。此函数将每个元素归约为单个值。
示例
查看
<ul class = "items"> <li>First</li> <li>Second</li> <li>Third</li> </ul>
代码
let value = element.all(by.css('.items li')).reduce(function(acc, elem) {
return elem.getText().then(function(text) {
return acc + text + ' ';
});
}, '');
expect(value).toEqual('First Second Third ');
element.all(locator).evaluate
顾名思义,它将评估输入是否在当前底层元素的范围内。
示例
查看
<span class = "foo">{{letiableInScope}}</span>
代码
let value =
element.all(by.css('.foo')).evaluate('letiableInScope');
element.all(locator).allowAnimations
顾名思义,它将确定当前底层元素是否允许动画。
示例
element(by.css('body')).allowAnimations(false);
ElementFinder 的链式函数及其描述
ElementFinder 的链式函数及其描述 -
element(locator).clone
顾名思义,此函数将创建 ElementFinder 的浅拷贝。
element(locator).getWebElement()
它将返回此 ElementFinder 表示的 WebElement,如果元素不存在,则会抛出 WebDriver 错误。
示例
查看
<div class="parent"> some text </div>
代码
// All the four following expressions are equivalent.
$('.parent').getWebElement();
element(by.css('.parent')).getWebElement();
browser.driver.findElement(by.css('.parent'));
browser.findElement(by.css('.parent'));
element(locator).all(locator)
它将在父级内查找元素数组。
示例
查看
<div class = "parent">
<ul>
<li class = "one">First</li>
<li class = "two">Second</li>
<li class = "three">Third</li>
</ul>
</div>
代码
let items = element(by.css('.parent')).all(by.tagName('li'));
element(locator).element(locator)
它将在父级内查找元素。
示例
查看
<div class = "parent">
<div class = "child">
Child text
<div>{{person.phone}}</div>
</div>
</div>
代码
// Calls Chain 2 element.
let child = element(by.css('.parent')).
element(by.css('.child'));
expect(child.getText()).toBe('Child text\n981-000-568');
// Calls Chain 3 element.
let triple = element(by.css('.parent')).
element(by.css('.child')).
element(by.binding('person.phone'));
expect(triple.getText()).toBe('981-000-568');
element(locator).all(selector)
当调用 $$ 时可能需要链接时,它用于查找父级内的元素数组。
示例
查看
<div class = "parent">
<ul>
<li class = "one">First</li>
<li class = "two">Second</li>
<li class = "three">Third</li>
</ul>
</div>
代码
let items = element(by.css('.parent')).$$('li'));
element(locator).$(locator)
当调用 $ 时可能需要链接时,它将在父级内查找元素。
示例
查看
<div class = "parent">
<div class = "child">
Child text
<div>{{person.phone}}</div>
</div>
</div>
代码
// Calls Chain 2 element.
let child = element(by.css('.parent')).
$('.child'));
expect(child.getText()).toBe('Child text\n981-000-568');
// Calls Chain 3 element.
let triple = element(by.css('.parent')).
$('.child')).
element(by.binding('person.phone'));
expect(triple.getText()).toBe('981-000-568');
element(locator).isPresent()
它将确定元素是否显示在页面上。
示例
查看
<span>{{person.name}}</span>
代码
expect(element(by.binding('person.name')).isPresent()).toBe(true);
// will check for the existence of element
expect(element(by.binding('notPresent')).isPresent()).toBe(false);
// will check for the non-existence of element
element(locator).isElementPresent()
它与 element(locator).isPresent() 相同。唯一的区别是它将检查由子定位器标识的元素是否存在,而不是当前元素查找器。
element.all(locator).evaluate
顾名思义,它将评估输入是否在当前底层元素的范围内。
示例
查看
<span id = "foo">{{letiableInScope}}</span>
代码
let value = element(by.id('.foo')).evaluate('letiableInScope');
element(locator).allowAnimations
顾名思义,它将确定当前底层元素是否允许动画。
示例
element(by.css('body')).allowAnimations(false);
element(locator).equals
顾名思义,它将比较元素是否相等。
定位器 (by) API
它基本上是元素定位器策略的集合,通过绑定、模型等提供在 Angular 应用程序中查找元素的方法。
函数及其描述
ProtractorLocators API 的函数如下 -
by.addLocator(locatorName,fuctionOrScript)
它将向此 ProtrcatorBy 实例添加一个定位器,该定位器可以进一步与 element(by.locatorName(args)) 一起使用。
示例
查看
<button ng-click = "doAddition()">Go!</button>
代码
// Adding the custom locator.
by.addLocator('buttonTextSimple',
function(buttonText, opt_parentElement, opt_rootSelector) {
var using = opt_parentElement || document,
buttons = using.querySelectorAll('button');
return Array.prototype.filter.call(buttons, function(button) {
return button.textContent === buttonText;
});
});
element(by.buttonTextSimple('Go!')).click();// Using the custom locator.
by.binding
顾名思义,它将通过文本绑定查找元素。将进行部分匹配,以便返回绑定到包含输入字符串的变量的任何元素。
示例
查看
<span>{{person.name}}</span>
<span ng-bind = "person.email"></span>
代码
var span1 = element(by.binding('person.name'));
expect(span1.getText()).toBe('Foo');
var span2 = element(by.binding('person.email'));
expect(span2.getText()).toBe('foo@bar.com');
by.exactbinding
顾名思义,它将通过精确绑定查找元素。
示例
查看
<spangt;{{ person.name }}</spangt;
<span ng-bind = "person-email"gt;</spangt;
<spangt;{{person_phone|uppercase}}</span>
代码
expect(element(by.exactBinding('person.name')).isPresent()).toBe(true);
expect(element(by.exactBinding('person-email')).isPresent()).toBe(true);
expect(element(by.exactBinding('person')).isPresent()).toBe(false);
expect(element(by.exactBinding('person_phone')).isPresent()).toBe(true);
expect(element(by.exactBinding('person_phone|uppercase')).isPresent()).toBe(true);
expect(element(by.exactBinding('phone')).isPresent()).toBe(false);
by.model(modelName)
顾名思义,它将通过 ng-model 表达式查找元素。
示例
查看
<input type = "text" ng-model = "person.name">
代码
var input = element(by.model('person.name'));
input.sendKeys('123');
expect(input.getAttribute('value')).toBe('Foo123');
by.buttonText
顾名思义,它将通过文本查找按钮。
示例
查看
<button>Save</button>
代码
element(by.buttonText('Save'));
by.partialButtonText
顾名思义,它将通过部分文本查找按钮。
示例
查看
<button>Save my file</button>
代码
element(by.partialButtonText('Save'));
by.repeater
顾名思义,它将在 ng-repeat 内查找元素。
示例
查看
<div ng-repeat = "cat in pets">
<span>{{cat.name}}</span>
<span>{{cat.age}}</span>
<</div>
<div class = "book-img" ng-repeat-start="book in library">
<span>{{$index}}</span>
</div>
<div class = "book-info" ng-repeat-end>
<h4>{{book.name}}</h4>
<p>{{book.blurb}}</p>
</div>
代码
var secondCat = element(by.repeater('cat in
pets').row(1)); // It will return the DIV for the second cat.
var firstCatName = element(by.repeater('cat in pets').
row(0).column('cat.name')); // It will return the SPAN for the first cat's name.
by.exactRepeater
顾名思义,它将通过精确重复查找元素。
示例
查看
<li ng-repeat = "person in peopleWithRedHair"></li> <li ng-repeat = "car in cars | orderBy:year"></li>
代码
expect(element(by.exactRepeater('person in
peopleWithRedHair')).isPresent())
.toBe(true);
expect(element(by.exactRepeater('person in
people')).isPresent()).toBe(false);
expect(element(by.exactRepeater('car in cars')).isPresent()).toBe(true);
by.cssContainingText
顾名思义,它将通过 CSS 查找包含精确字符串的元素。
示例
查看
<ul> <li class = "pet">Dog</li> <li class = "pet">Cat</li> </ul>
代码
var dog = element(by.cssContainingText('.pet', 'Dog'));
// It will return the li for the dog, but not for the cat.
by.options(optionsDescriptor)
顾名思义,它将通过 ng-options 表达式查找元素。
示例
查看
<select ng-model = "color" ng-options = "c for c in colors"> <option value = "0" selected = "selected">red</option> <option value = "1">green</option> </select>
代码
var allOptions = element.all(by.options('c for c in colors'));
expect(allOptions.count()).toEqual(2);
var firstOption = allOptions.first();
expect(firstOption.getText()).toEqual('red');
by.deepCSS(selector)
顾名思义,它将通过影子 DOM 中的 CSS 选择器查找元素。
示例
查看
<div>
<span id = "outerspan">
<"shadow tree">
<span id = "span1"></span>
<"shadow tree">
<span id = "span2"></span>
</>
</>
</div>
代码
var spans = element.all(by.deepCss('span'));
expect(spans.count()).toEqual(3);
量角器 - 对象
本章详细讨论了 Protractor 中的对象。
什么是页面对象?
页面对象是一种设计模式,它已成为编写 e2e 测试的流行方法,以增强测试维护并减少代码重复。它可以定义为一个面向对象的类,充当 AUT(被测应用程序)页面的接口。但是,在深入研究页面对象之前,我们必须了解自动化 UI 测试的挑战以及处理这些挑战的方法。
自动化 UI 测试的挑战
以下是自动化 UI 测试的一些常见挑战 -
UI 更改
在使用 UI 测试时,非常常见的问题是 UI 中发生的更改。例如,大多数情况下按钮或文本框等通常会发生更改,并为 UI 测试带来问题。
缺乏 DSL(领域特定语言)支持
UI 测试的另一个问题是缺乏 DSL 支持。由于此问题,很难理解正在测试的内容。
大量重复/代码重复
UI 测试中的下一个常见问题是存在大量重复或代码重复。可以通过以下几行代码来理解 -
element(by.model(‘event.name’)).sendKeys(‘An Event’); element(by.model(‘event.name’)).sendKeys(‘Module 3’); element(by.model(‘event.name’));
维护困难
由于上述挑战,维护变得令人头疼。这是因为我们必须找到所有实例,替换为新名称、选择器和其他代码。我们还需要花费大量时间来使测试与重构保持一致。
测试中断
UI 测试中的另一个挑战是测试中发生大量故障。
处理挑战的方法
我们已经看到了一些 UI 测试的常见挑战。处理此类挑战的一些方法如下 -
手动更新引用
处理上述挑战的第一个选项是手动更新引用。此选项的问题在于我们必须在代码以及测试中进行手动更改。当您有一个或两个测试文件时,这可以做到,但是如果您的项目中有数百个测试文件怎么办?
使用页面对象
处理上述挑战的另一个选项是使用页面对象。页面对象基本上是一个纯 JavaScript,它封装了 Angular 模板的属性。例如,以下规范文件是在没有和有页面对象的情况下编写的,以了解差异 -
无页面对象
describe('angularjs homepage', function() {
it('should greet the named user', function() {
browser.get('http://www.angularjs.org');
element(by.model('yourName')).sendKeys('Julie');
var greeting = element(by.binding('yourName'));
expect(greeting.getText()).toEqual('Hello Julie!');
});
});
有页面对象
要使用页面对象编写代码,我们需要做的第一件事是创建一个页面对象。因此,上述示例的页面对象可能如下所示 -
var AngularHomepage = function() {
var nameInput = element(by.model('yourName'));
var greeting = element(by.binding('yourName'));
this.get = function() {
browser.get('http://www.angularjs.org');
};
this.setName = function(name) {
nameInput.sendKeys(name);
};
this.getGreetingText = function() {
return greeting.getText();
};
};
module.exports = new AngularHomepage();
使用页面对象组织测试
我们在上面的示例中已经看到了页面对象的使用,以处理 UI 测试的挑战。接下来,我们将讨论如何使用它们来组织测试。为此,我们需要修改测试脚本,而无需修改测试脚本的功能。
示例
为了理解这个概念,我们使用带有页面对象的上述配置文件。我们需要修改测试脚本如下 -
var angularHomepage = require('./AngularHomepage');
describe('angularjs homepage', function() {
it('should greet the named user', function() {
angularHomepage.get();
angularHomepage.setName('Julie');
expect(angularHomepage.getGreetingText()).toEqual
('Hello Julie!');
});
});
这里,请注意页面对象的路径相对于您的规范。
同样,我们还可以将测试套件分离成各种测试套件。然后配置文件可以更改如下
exports.config = {
// The address of a running selenium server.
seleniumAddress: 'https://:4444/wd/hub',
// Capabilities to be passed to the webdriver instance.
capabilities: {
'browserName': 'chrome'
},
// Spec patterns are relative to the location of the spec file. They may
// include glob patterns.
suites: {
homepage: 'tests/e2e/homepage/**/*Spec.js',
search: ['tests/e2e/contact_search/**/*Spec.js',
'tests/e2e/venue_search/**/*Spec.js']
},
// Options to be passed to Jasmine-node.
jasmineNodeOpts: {
showColors: true, // Use colors in the command line report.
}
};
现在,我们可以轻松地在运行一个或另一个测试套件之间切换。以下命令将仅运行测试的主页部分 -
protractor protractor.conf.js --suite homepage
类似地,我们可以使用以下命令运行特定的测试套件 -
protractor protractor.conf.js --suite homepage,search
量角器 - 调试
现在我们已经了解了前几章中 Protractor 的所有概念,让我们在本章中详细了解调试概念。
介绍
端到端 (e2e) 测试非常难以调试,因为它们依赖于该应用程序的整个生态系统。我们已经看到它们依赖于各种操作,或者更准确地说,依赖于先前的操作,例如登录,有时它们还依赖于权限。调试 e2e 测试的另一个困难是它依赖于 WebDriver,因为它在不同的操作系统和浏览器上表现不同。最后,调试 e2e 测试还会生成冗长的错误消息,并且难以区分与浏览器相关的错误和测试过程错误。
故障类型
测试套件失败可能有多种原因,以下是一些众所周知的故障类型 -
WebDriver 故障
当命令无法完成时,WebDriver 会抛出错误。例如,浏览器无法获取定义的地址,或者元素未按预期找到。
WebDriver 意外故障
当 WebDriver 管理器无法更新时,会发生意外的浏览器和操作系统相关的故障。
Protractor Angular 故障
当 Protractor 未能按预期在库中找到 Angular 时,就会发生 Protractor Angular 故障。
Protractor Angular2 故障
在这种类型的故障中,当配置文件中找不到 useAllAngular2AppRoots 参数时,Protractor 会失败。发生这种情况是因为,如果没有它,测试过程将查看单个根元素,而期望在过程中有多个元素。
Protractor 超时故障
当测试规范遇到循环或长时间池并无法及时返回数据时,就会发生这种类型的故障。
期望失败
最常见的测试失败之一,它显示了正常的期望失败是什么样子。
为什么在 Protractor 中调试很重要?
假设,如果您编写了测试用例并且它们失败了,那么了解如何调试这些测试用例非常重要,因为找到错误发生的确切位置将非常困难。在使用 Protractor 时,您将在命令行中看到一些红色字体显示的长错误。
暂停和调试测试
以下是 Protractor 中调试的方法 &miuns;
暂停方法
使用暂停方法调试 Protractor 中的测试用例是最简单的方法之一。我们可以在想要暂停测试代码的位置键入以下命令 &miuns;
browser.pause();
当运行的代码遇到上述命令时,它将暂停该点的程序运行。之后,我们可以根据自己的喜好执行以下命令:
键入 C 以继续执行
每当一个命令执行完毕后,我们必须键入 C 以继续执行。如果您不输入 C,测试将无法运行完整代码,并且由于 Jasmine 超时错误而失败。
键入 repl 以进入交互模式
交互模式的好处是可以向浏览器发送 WebDriver 命令。如果要进入交互模式,请键入repl。
键入 Ctrl-C 以退出并继续测试
要从暂停状态退出测试并从停止处继续测试,我们需要键入 Ctrl-C。
示例
在这个例子中,我们有一个名为example_debug.js的规范文件,Protractor 尝试使用定位符by.binding('mmmm') 识别一个元素,但是 URL(https://angularjs.org/)页面没有指定定位符的元素。
describe('Suite for protractor debugger',function(){
it('Failing spec',function(){
browser.get("http://angularjs.org");
element(by.model('yourName')).sendKeys('Vijay');
//Element doesn't exist
var welcomeText =
element(by.binding('mmmm')).getText();
expect('Hello '+welcomeText+'!').toEqual('Hello Ram!')
});
});
现在,要执行上述测试,我们需要在上述规范文件中添加 `browser.pause()` 代码,您希望在该处暂停测试。它将如下所示:
describe('Suite for protractor debugger',function(){
it('Failing spec',function(){
browser.get("http://angularjs.org");
browser.pause();
element(by.model('yourName')).sendKeys('Vijay');
//Element doesn't exist
var welcomeText =
element(by.binding('mmmm')).getText();
expect('Hello '+welcomeText+'!').toEqual('Hello Ram!')
});
});
但在执行之前,我们还需要对配置文件进行一些更改。我们将在前面章节中使用的名为example_configuration.js的配置文件中进行以下更改:
// An example configuration file.
exports.config = {
directConnect: true,
// Capabilities to be passed to the webdriver instance.
capabilities: {
'browserName': 'chrome'
},
// Framework to use. Jasmine is recommended.
framework: 'jasmine',
// Spec patterns are relative to the current working directory when
// protractor is called.
specs: ['example_debug.js'],
allScriptsTimeout: 999999,
jasmineNodeOpts: {
defaultTimeoutInterval: 999999
},
onPrepare: function () {
browser.manage().window().maximize();
browser.manage().timeouts().implicitlyWait(5000);
}
};
现在,运行以下命令:
protractor example_configuration.js
执行以上命令后,调试器将启动。
调试器方法
使用暂停方法调试 Protractor 中的测试用例是一种稍微高级的方法。我们可以在想要中断测试代码的位置键入以下命令:
browser.debugger();
它使用 Node 调试器来调试测试代码。要运行上述命令,我们必须在从测试项目位置打开的单独的命令提示符中键入以下命令:
protractor debug protractor.conf.js
在这种方法中,我们也需要在终端中键入 C 以继续测试代码。但与暂停方法相反,在这种方法中,只需要键入一次。
示例
在这个例子中,我们使用的是与上面相同的规范文件,名为example_debug.js。唯一的区别是,我们需要使用browser.debugger()代替browser.pause()来中断测试代码。它将如下所示:
describe('Suite for protractor debugger',function(){
it('Failing spec',function(){
browser.get("http://angularjs.org");
browser.debugger();
element(by.model('yourName')).sendKeys('Vijay');
//Element doesn't exist
var welcomeText = element(by.binding('mmmm')).getText();
expect('Hello '+welcomeText+'!').toEqual('Hello Ram!')
});
});
我们使用的是与上面示例中相同的配置文件example_configuration.js。
现在,使用以下调试命令行选项运行 Protractor 测试
protractor debug example_configuration.js
执行以上命令后,调试器将启动。
Protractor - Protractor 风格指南
在本章中,让我们详细了解 Protractor 的风格指南。
介绍
该风格指南由两位软件工程师创建,分别是 ING 的前端工程师Carmen Popoviciu和 Google 的软件工程师Andres Dominguez。因此,此风格指南也被称为 Carmen Popoviciu 和 Google 的 Protractor 风格指南。
此风格指南可以分为以下五个要点:
- 通用规则
- 项目结构
- 定位器策略
- 页面对象
- 测试套件
通用规则
以下是一些在使用 Protractor 进行测试时必须注意的通用规则:
不要对已经进行单元测试的内容进行端到端测试
这是 Carmen 和 Andres 给出的第一个通用规则。他们建议我们不要对已经进行单元测试的代码执行端到端测试。其主要原因是单元测试比端到端测试快得多。另一个原因是我们必须避免重复测试(不要同时执行单元测试和端到端测试)以节省时间。
仅使用一个配置文件
另一个重要的建议是,我们必须只使用一个配置文件。不要为每个测试环境创建配置文件。您可以使用grunt-protractor-coverage来设置不同的环境。
避免在测试中使用逻辑
我们必须避免在测试用例中使用 IF 语句或 FOR 循环,因为如果我们这样做,测试可能会在不进行任何测试的情况下通过,或者运行速度非常慢。
使测试在文件级别独立
当启用共享时,Protractor 可以并行运行测试。然后,这些文件会在不同的浏览器中按可用情况执行。Carmen 和 Andres 建议至少在文件级别使测试独立,因为 Protractor 运行它们的顺序是不确定的,而且隔离运行测试非常容易。
项目结构
关于 Protractor 风格指南的另一个重要要点是项目的结构。以下是关于项目结构的建议:
以合理的结构对端到端测试进行分组
Carmen 和 Andres 建议我们必须以对项目结构有意义的方式对端到端测试进行分组。此建议背后的原因是查找文件将变得容易,并且文件夹结构将更易读。此步骤还将端到端测试与单元测试分开。他们建议应避免以下类型的结构:
|-- project-folder
|-- app
|-- css
|-- img
|-- partials
home.html
profile.html
contacts.html
|-- js
|-- controllers
|-- directives
|-- services
app.js
...
index.html
|-- test
|-- unit
|-- e2e
home-page.js
home-spec.js
profile-page.js
profile-spec.js
contacts-page.js
contacts-spec.js
另一方面,他们建议使用以下类型的结构:
|-- project-folder
|-- app
|-- css
|-- img
|-- partials
home.html
profile.html
contacts.html
|-- js
|-- controllers
|-- directives
|-- services
app.js
...
index.html
|-- test
|-- unit
|-- e2e
|-- page-objects
home-page.js
profile-page.js
contacts-page.js
home-spec.js
profile-spec.js
contacts-spec.js
定位器策略
以下是一些在使用 Protractor 进行测试时必须注意的定位器策略:
切勿使用 XPath
这是 Protractor 风格指南中推荐的第一个定位器策略。其背后的原因是 XPath 需要大量维护,因为标记很容易发生变化。此外,XPath 表达式速度最慢且难以调试。
始终优先使用 Protractor 特定的定位器,例如 by.model 和 by.binding
Protractor 特定的定位器(例如 by.model 和 by.binding)简短、具体且易于阅读。借助它们,编写我们的定位器也变得非常容易。
示例
查看
<ul class = "red">
<li>{{color.name}}</li>
<li>{{color.shade}}</li>
<li>{{color.code}}</li>
</ul>
<div class = "details">
<div class = "personal">
<input ng-model = "person.name">
</div>
</div>
对于上面的代码,建议避免以下内容:
var nameElement = element.all(by.css('.red li')).get(0);
var personName = element(by.css('.details .personal input'));
另一方面,建议使用以下内容:
var nameElement = element.all(by.css('.red li')).get(0);
var personName = element(by.css('.details .personal input'));
var nameElement = element(by.binding('color.name'));
var personName = element(by.model('person.name'));
当没有可用的 Protractor 定位器时,建议优先使用 by.id 和 by.css。
始终避免对频繁更改的文本使用文本定位器
我们必须避免使用基于文本的定位器,例如 by.linkText、by.buttonText 和 by.cssContaningText,因为按钮、链接和标签的文本会随着时间的推移而频繁更改。
页面对象
如前所述,页面对象封装了有关应用程序页面上元素的信息,并因此帮助我们编写更清晰的测试用例。页面对象的一个非常有用的优点是它们可以在多个测试中重复使用,如果我们的应用程序模板已更改,我们只需要更新页面对象即可。以下是一些在使用 Protractor 进行测试时必须注意的页面对象的建议:
要与被测页面交互,请使用页面对象
建议使用页面对象与被测页面交互,因为它们可以封装有关被测页面上元素的信息,并且也可以重复使用。
始终为每个文件声明一个页面对象
我们应该在自己的文件中定义每个页面对象,因为它可以使代码保持整洁,并且查找内容变得更容易。
在页面对象文件末尾始终使用单个 module.exports
建议每个页面对象都应该声明一个类,以便我们只需要导出一个类。例如,应避免以下对象文件的使用:
var UserProfilePage = function() {};
var UserSettingsPage = function() {};
module.exports = UserPropertiesPage;
module.exports = UserSettingsPage;
但另一方面,建议使用以下方法:
/** @constructor */
var UserPropertiesPage = function() {};
module.exports = UserPropertiesPage;
在顶部声明所有必需的模块
我们应该在页面对象的顶部声明所有必需的模块,因为它使模块依赖项变得清晰且易于查找。
在测试套件的开头实例化所有页面对象
建议在测试套件的开头实例化所有页面对象,因为这将使依赖项与测试代码分离,并使所有套件规范都可以使用这些依赖项。
不要在页面对象中使用 expect()
我们不应该在页面对象中使用 expect(),即我们不应该在页面对象中进行任何断言,因为所有断言都必须在测试用例中完成。
另一个原因是,测试的阅读者应该能够仅通过阅读测试用例来了解应用程序的行为。