- PyBrain 教程
- PyBrain - 首页
- PyBrain - 概述
- PyBrain - 环境设置
- PyBrain - PyBrain 网络简介
- PyBrain - 使用网络
- PyBrain - 使用数据集
- PyBrain - 数据集类型
- PyBrain - 导入数据集数据
- PyBrain - 在网络上训练数据集
- PyBrain - 测试网络
- 使用前馈网络
- PyBrain - 使用循环网络
- 使用优化算法训练网络
- PyBrain - 层
- PyBrain - 连接
- PyBrain - 强化学习模块
- PyBrain - API 和工具
- PyBrain - 示例
- PyBrain 有用资源
- PyBrain - 快速指南
- PyBrain - 有用资源
- PyBrain - 讨论
PyBrain - 数据集类型
数据集是用于在网络上进行测试、验证和训练的数据。要使用的数据集类型取决于我们将使用机器学习执行的任务。我们将在本章中讨论各种数据集类型。
我们可以通过添加以下包来使用数据集:
pybrain.dataset
SupervisedDataSet
SupervisedDataSet 包含输入和目标字段。它是数据集的最简单形式,主要用于监督学习任务。
以下是您如何在代码中使用它的示例:
from pybrain.datasets import SupervisedDataSet
SupervisedDataSet 上可用的方法如下:
addSample(inp, target)
此方法将添加一个新的输入和目标样本。
splitWithProportion(proportion=0.10)
这会将数据集分成两部分。第一部分将包含作为输入给定的数据集的百分比,即,如果输入为 .10,则为数据集的 10% 和 90% 的数据。您可以根据自己的选择决定比例。划分后的数据集可用于测试和训练您的网络。
copy() - 返回数据集的深度副本。
clear() - 清空数据集。
saveToFile(filename, format=None, **kwargs)
将对象保存到由 filename 指定的文件中。
示例
这是一个使用 SupervisedDataset 的工作示例:
testnetwork.py
from pybrain.tools.shortcuts import buildNetwork from pybrain.structure import TanhLayer from pybrain.datasets import SupervisedDataSet from pybrain.supervised.trainers import BackpropTrainer # Create a network with two inputs, three hidden, and one output nn = buildNetwork(2, 3, 1, bias=True, hiddenclass=TanhLayer) # Create a dataset that matches network input and output sizes: norgate = SupervisedDataSet(2, 1) # Create a dataset to be used for testing. nortrain = SupervisedDataSet(2, 1) # Add input and target values to dataset # Values for NOR truth table norgate.addSample((0, 0), (1,)) norgate.addSample((0, 1), (0,)) norgate.addSample((1, 0), (0,)) norgate.addSample((1, 1), (0,)) # Add input and target values to dataset # Values for NOR truth table nortrain.addSample((0, 0), (1,)) nortrain.addSample((0, 1), (0,)) nortrain.addSample((1, 0), (0,)) nortrain.addSample((1, 1), (0,)) #Training the network with dataset norgate. trainer = BackpropTrainer(nn, norgate) # will run the loop 1000 times to train it. for epoch in range(1000): trainer.train() trainer.testOnData(dataset=nortrain, verbose = True)
输出
上述程序的输出如下:
python testnetwork.py
C:\pybrain\pybrain\src>python testnetwork.py
Testing on data:
('out: ', '[0.887 ]')
('correct:', '[1 ]')
error: 0.00637334
('out: ', '[0.149 ]')
('correct:', '[0 ]')
error: 0.01110338
('out: ', '[0.102 ]')
('correct:', '[0 ]')
error: 0.00522736
('out: ', '[-0.163]')
('correct:', '[0 ]')
error: 0.01328650
('All errors:', [0.006373344564625953, 0.01110338071737218, 0.005227359234093431
, 0.01328649974219942])
('Average error:', 0.008997646064572746)
('Max error:', 0.01328649974219942, 'Median error:', 0.01110338071737218)
ClassificationDataSet
此数据集主要用于处理分类问题。它接收输入、目标字段,以及一个名为“class”的额外字段,该字段是给定目标的自动备份。例如,输出将为 1 或 0,或者输出将根据给定的输入将值组合在一起,即,它将属于一个特定的类。
以下是您如何在代码中使用它的示例:
from pybrain.datasets import ClassificationDataSet Syntax // ClassificationDataSet(inp, target=1, nb_classes=0, class_labels=None)
ClassificationDataSet 上可用的方法如下:
addSample(inp, target) - 此方法将添加一个新的输入和目标样本。
splitByClass() - 此方法将提供两个新的数据集,第一个数据集将包含选定的类 (0..nClasses-1),第二个数据集将包含其余样本。
_convertToOneOfMany() - 此方法将目标类转换为 1-of-k 表示,并将旧目标保留为字段 class
这是一个ClassificationDataSet的工作示例。
示例
from sklearn import datasets
import matplotlib.pyplot as plt
from pybrain.datasets import ClassificationDataSet
from pybrain.utilities import percentError
from pybrain.tools.shortcuts import buildNetwork
from pybrain.supervised.trainers import BackpropTrainer
from pybrain.structure.modules import SoftmaxLayer
from numpy import ravel
digits = datasets.load_digits()
X, y = digits.data, digits.target
ds = ClassificationDataSet(64, 1, nb_classes=10)
for i in range(len(X)):
ds.addSample(ravel(X[i]), y[i])
test_data_temp, training_data_temp = ds.splitWithProportion(0.25)
test_data = ClassificationDataSet(64, 1, nb_classes=10)
for n in range(0, test_data_temp.getLength()):
test_data.addSample( test_data_temp.getSample(n)[0], test_data_temp.getSample(n)[1] )
training_data = ClassificationDataSet(64, 1, nb_classes=10)
for n in range(0, training_data_temp.getLength()):
training_data.addSample( training_data_temp.getSample(n)[0], training_data_temp.getSample(n)[1] )
test_data._convertToOneOfMany()
training_data._convertToOneOfMany()
net = buildNetwork(training_data.indim, 64, training_data.outdim, outclass=SoftmaxLayer)
trainer = BackpropTrainer(
net, dataset=training_data, momentum=0.1,learningrate=0.01,verbose=True,weightdecay=0.01
)
trnerr,valerr = trainer.trainUntilConvergence(dataset=training_data,maxEpochs=10)
plt.plot(trnerr,'b',valerr,'r')
plt.show()
trainer.trainEpochs(10)
print('Percent Error on testData:',percentError(trainer.testOnClassData(dataset=test_data), test_data['class']))
上述示例中使用的数据集是数字数据集,类从 0 到 9,因此有 10 个类。输入为 64,目标为 1,类为 10。
代码使用数据集训练网络,并输出训练误差和验证误差的图形。它还给出了测试数据的百分比误差,如下所示:
输出
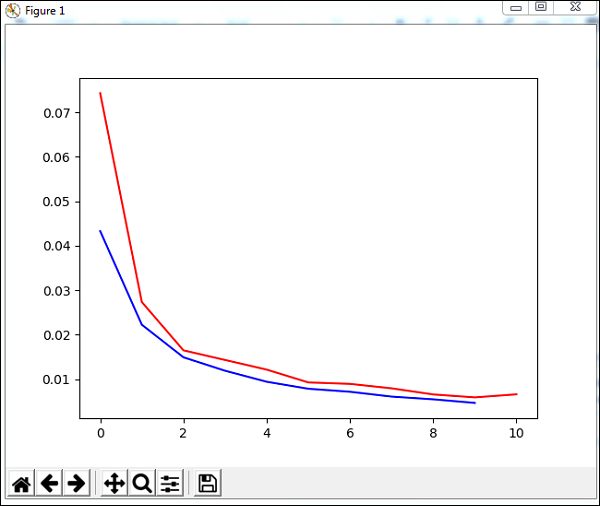
Total error: 0.0432857814358
Total error: 0.0222276374185
Total error: 0.0149012052174
Total error: 0.011876985318
Total error: 0.00939854792853
Total error: 0.00782202445183
Total error: 0.00714707652044
Total error: 0.00606068893793
Total error: 0.00544257958975
Total error: 0.00463929281336
Total error: 0.00441275665294
('train-errors:', '[0.043286 , 0.022228 , 0.014901 , 0.011877 , 0.009399 , 0.007
822 , 0.007147 , 0.006061 , 0.005443 , 0.004639 , 0.004413 ]')
('valid-errors:', '[0.074296 , 0.027332 , 0.016461 , 0.014298 , 0.012129 , 0.009
248 , 0.008922 , 0.007917 , 0.006547 , 0.005883 , 0.006572 , 0.005811 ]')
Percent Error on testData: 3.34075723830735