- PyBrain 教程
- PyBrain - 首页
- PyBrain概述
- PyBrain - 环境设置
- PyBrain - PyBrain 网络介绍
- PyBrain - 使用网络
- PyBrain - 使用数据集
- PyBrain - 数据集类型
- PyBrain - 导入数据集数据
- PyBrain - 在网络上训练数据集
- PyBrain - 测试网络
- 使用前馈网络
- PyBrain - 使用循环网络
- 使用优化算法训练网络
- PyBrain - 层
- PyBrain - 连接
- PyBrain - 强化学习模块
- PyBrain - API 和工具
- PyBrain - 例子
- PyBrain 有用资源
- PyBrain - 快速指南
- PyBrain - 有用资源
- PyBrain - 讨论
PyBrain概述
Pybrain 是一个使用 Python 实现的开源机器学习库。该库提供了一些易于使用的网络训练算法、数据集和训练器来训练和测试网络。
其官方文档中对 Pybrain 的定义如下:
PyBrain 是一个用于 Python 的模块化机器学习库。其目标是为机器学习任务提供灵活、易于使用且功能强大的算法,以及各种预定义的环境来测试和比较您的算法。
PyBrain 是 Python-Based Reinforcement Learning, Artificial Intelligence, and Neural Network Library 的缩写。事实上,我们首先想出了这个名字,后来才对这个相当具有描述性的“反向缩写”进行了逆向工程。
Pybrain 的特性
以下是 Pybrain 的特性:
网络
网络由模块组成,并使用连接连接起来。Pybrain 支持神经网络,如前馈网络、循环网络等。
前馈网络是一种神经网络,其中节点之间的信息沿前向方向移动,并且永远不会向后传播。前馈网络是人工神经网络中第一个也是最简单的网络。
信息从输入节点传递到隐藏节点,然后传递到输出节点。
循环网络类似于前馈网络;唯一的区别在于它必须记住每个步骤的数据。必须保存每个步骤的历史记录。
数据集
数据集是用于在网络上进行测试、验证和训练的数据。要使用的数据集类型取决于我们将要使用机器学习执行的任务。Pybrain 支持的最常用的数据集是 SupervisedDataSet 和 ClassificationDataSet。
SupervisedDataSet - 它包含输入和目标字段。它是数据集最简单的形式,主要用于监督学习任务。
ClassificationDataSet - 它主要用于处理分类问题。它接收输入、目标字段,以及一个名为“class”的额外字段,它是给定目标的自动备份。例如,输出将是 1 或 0,或者输出将根据给定的输入将值分组在一起,即它将属于一个特定类别。
训练器
当我们创建一个网络(即神经网络)时,它将根据提供给它的训练数据进行训练。网络是否训练得当将取决于在该网络上测试的测试数据的预测结果。Pybrain 训练中最重要的一点是使用 BackpropTrainer 和 TrainUntilConvergence。
BackpropTrainer - 它是一个训练器,它根据监督或 ClassificationDataSet 数据集(可能是顺序的)通过反向传播误差(及时)来训练模块的参数。
TrainUntilConvergence - 它用于在数据集上训练模块,直到它收敛。
工具
Pybrain 提供工具模块,可以帮助通过导入包来构建网络:pybrain.tools.shortcuts.buildNetwork
可视化
无法使用 pybrain 可视化测试数据。但是 Pybrain 可以与其他框架(如 Mathplotlib、pyplot)一起使用来可视化数据。
Pybrain 的优点
Pybrain 的优点包括:
Pybrain 是一个开源免费的机器学习库。对于任何对机器学习感兴趣的新手来说,这是一个很好的开始。
Pybrain 使用 Python 实现,与 Java/C++ 等语言相比,它在开发方面速度更快。
Pybrain 可以轻松地与其他 Python 库一起使用来可视化数据。
Pybrain 支持流行的网络,如前馈网络、循环网络、神经网络等。
在 Pybrain 中使用 .csv 加载数据集非常容易。它还允许使用来自其他库的数据集。
使用 Pybrain 训练器轻松进行数据训练和测试。
Pybrain 的局限性
Pybrain 对遇到的任何问题提供的帮助较少。在stackoverflow和Google Group上有一些未解答的问题。
Pybrain 的工作流程
根据 Pybrain 文档,机器学习流程如下图所示:
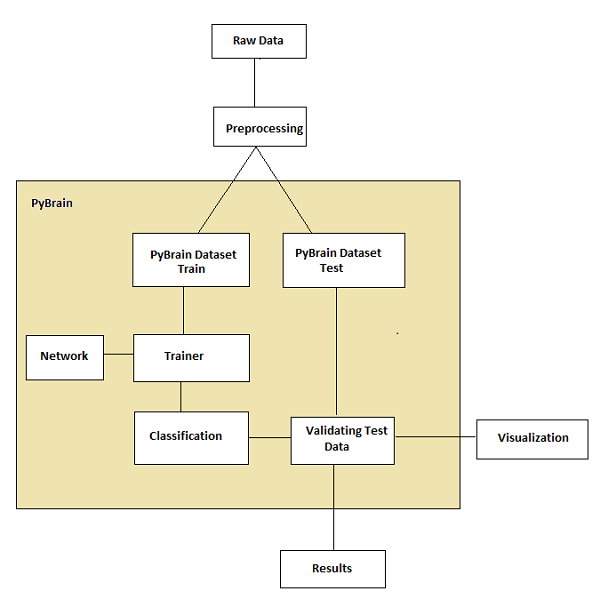
一开始,我们有原始数据,经过预处理后可以与 Pybrain 一起使用。
Pybrain 的流程从数据集开始,数据集分为训练数据和测试数据。
创建网络,并将数据集和网络提供给训练器。
训练器在网络上训练数据,并将输出分类为训练误差和验证误差,这些误差可以可视化。
可以验证测试数据以查看输出是否与训练数据匹配。
术语
使用 Pybrain 进行机器学习时,需要考虑一些重要的术语。它们如下:
总误差 - 指网络训练后显示的误差。如果误差在每次迭代中不断变化,则表示它仍然需要时间来稳定,直到它开始显示每次迭代之间的恒定误差。一旦它开始显示恒定误差数字,就表示网络已收敛,并且无论应用任何额外的训练都将保持不变。
训练数据 - 用于训练 Pybrain 网络的数据。
测试数据 - 用于测试经过训练的 Pybrain 网络的数据。
训练器 - 当我们创建一个网络(即神经网络)时,它将根据提供给它的训练数据进行训练。网络是否训练得当将取决于在该网络上测试的测试数据的预测结果。Pybrain 训练中最重要的一点是使用 BackpropTrainer 和 TrainUntilConvergence。
BackpropTrainer - 它是一个训练器,它根据监督或 ClassificationDataSet 数据集(可能是顺序的)通过反向传播误差(及时)来训练模块的参数。
TrainUntilConvergence - 用于在数据集上训练模块,直到它收敛。
层 - 层基本上是一组用于网络隐藏层的函数。
连接 - 连接的工作方式类似于层;唯一的区别在于它将数据从网络中的一个节点转移到另一个节点。
模块 - 模块是包含输入和输出缓冲区的网络。
监督学习 - 在这种情况下,我们有输入和输出,我们可以使用算法将输入与输出映射起来。该算法被设计为在给定的训练数据上学习并在其上进行迭代,并且当算法预测正确数据时,迭代过程停止。
无监督学习 - 在这种情况下,我们有输入但不知道输出。无监督学习的作用是尽可能多地利用给定的数据进行训练。